
Cursus
Principes de base de KNIME
17 h
Le nouveau paradoxe de l’IA en entreprise est le suivant : plus nous déléguons l’action à des agents IA, plus nous perdons notre propre pouvoir d’action. À l’ère agentique, l’évaluation et la confiance — pas la génération — deviennent le principal goulot d’étranglement.
Nous nous sommes habitués à des systèmes d’IA qui soutiennent avant tout notre jugement humain. Dans bien des cas, nous nous sommes aussi accoutumés à ce qu’ils confirment nos jugements et biais, sans les remettre réellement en question. Ils génèrent du texte, résument de l’information ou nous donnent des recommandations.
Néanmoins, l’humain restait le décideur et l’approbateur final.
Les agents IA ont changé la donne. Les systèmes agentiques ne se contentent pas de suggérer : ils sont conçus pour planifier, décider et agir au sein d’écosystèmes organisationnels complexes.
Ils déclenchent des workflows, appellent des API, déplacent des fonds et mettent à jour des enregistrements. Ils initient des processus sans nécessairement attendre une confirmation humaine. Cela transforme le paysage des risques de l’entreprise.
Le problème, c’est que lorsque des systèmes agentiques agissent, les conséquences peuvent être coûteuses. Quand un agent commet une erreur d’achat à 300 k$, « l’outil a pris la décision » n’est plus une défense recevable. La perte pour l’entreprise est bien réelle, et quelqu’un doit en répondre. Votre responsabilité ne disparaît pas sous prétexte que l’agent a agi.
Les entreprises veulent la rapidité, l’échelle et l’efficacité d’agents autonomes, mais l’imputabilité ne peut pas être automatisée. Déléguer l’action à un agent ne signifie pas déléguer la responsabilité.
La question centrale est : comment déployer l’IA agentique à grande échelle sans renoncer à notre capacité d’agir ?
Pour y répondre, distinguons l’IA assistive de l’IA agentique.
La différence tient au degré de contrôle. Dans les systèmes assistifs, l’agence réside clairement chez l’humain. Autorité et responsabilité s’alignent davantage : l’humain décide, les systèmes soutiennent. Mais dans les systèmes agentiques, le système agit tandis que la responsabilité finale demeure humaine.
C’est là que le paradoxe s’accentue.
À mesure que l’autonomie augmente, une supervision humaine constante (l’humain dans la boucle) devient impraticable. Mais réduire la supervision accroît l’exposition aux risques : violations de politiques, erreurs et effets indésirables. Et brider excessivement les agents rend l’autonomie théorique — on perd alors en échelle et en efficacité.
Les fournisseurs promettant l’automatisation à grande échelle ne manquent pas. Les agents planifient, décident et agissent plus vite que n’importe quelle équipe humaine.
Mais quand les agents agissent, une nouvelle question se pose aux entreprises : comment savoir si ces actions sont correctes, sûres et conformes à nos politiques ?
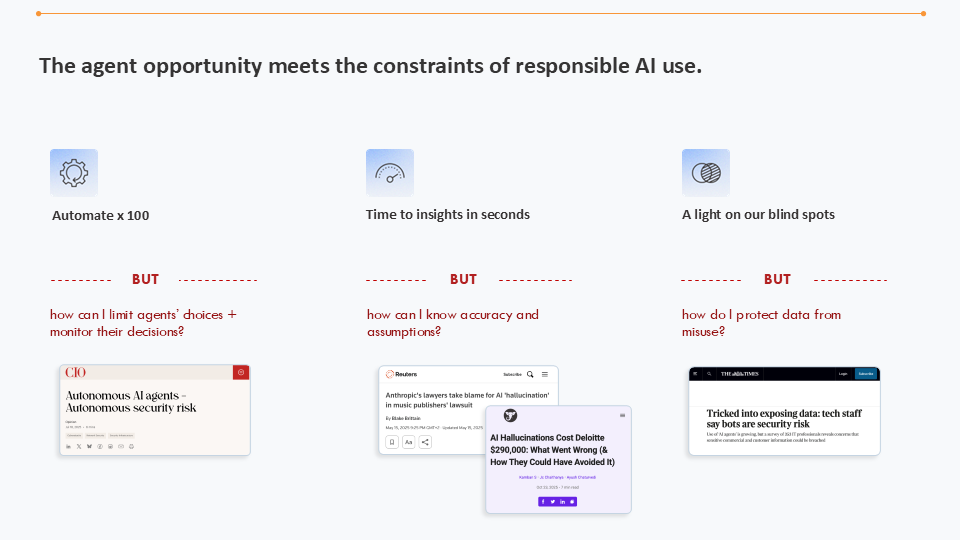
Que se passe-t-il quand les opportunités offertes par les agents rencontrent les contraintes d’un usage responsable de l’IA
Le réflexe courant consiste à ajouter des étapes d’approbation : un relecteur qui valide, des exceptions qui s’escaladent. Pourtant, le schéma traditionnel de « l’humain dans la boucle » ne tient pas l’échelle.
Un agent fonctionnant en continu peut prendre des centaines, voire des milliers de décisions par jour. Si chaque action exige une évaluation manuelle, le « travail de preuve » final annulera le gain de temps initial. Nous aurons automatisé l’exécution pour recréer un goulot d’étranglement côté évaluation.
Et il y a un autre écueil : nous évaluons si les actions d’un agent sont correctes, sûres et sécurisées. Mais qu’en est-il du fait de dire « non » ? Le système sait-il quand ne pas agir ?
C’est peut-être l’un des plus grands défis de l’IA agentique : un agent utile doit pouvoir détecter des conflits avec les politiques, par exemple, et dire « je ne peux pas faire cela » ou « je dois transférer ce cas à un humain ». Sans cette capacité, les agents deviennent des machines à produire, générant des résultats qu’ils le devraient… ou non.
À grande échelle, ce comportement devient un risque majeur.
Nous revoilà face au paradoxe.
Si l’humain ne peut pas tout revoir et si les agents n’évaluent pas fiablement leurs propres limites, alors l’évaluation ne peut pas rester une surcouche informelle ajoutée après coup. Elle doit être conçue au cœur même du système.
La question n’est donc pas de savoir si l’évaluation est nécessaire, mais comment elle est mise en œuvre.
Chez KNIME, nous l’avons constaté concrètement. Dans un cas, nous avons construit un agent qui générait des actions à partir d’insights. Il a considérablement accéléré notre travail, mais nous nous sommes surpris à remettre en question presque chaque insight. Il ne faut pas faire confiance aveuglément aux agents, mais la confiance est indispensable pour passer à l’échelle.
Le déclic est venu quand nous avons intégré les retours directement dans le workflow. En étiquetant et qualifiant chaque « échec », l’agent a appris et s’est amélioré grâce à nous, les humains dans la boucle. Avec le temps, l’agent a progressé et la confiance a grandi.
Notre enseignement : il faut bâtir la confiance dans le système lui-même : évaluation et feedback doivent faire partie intégrante du dispositif, pas d’un processus annexe.
L’objectif n’est ni l’autonomie sans limites, ni la supervision humaine permanente, mais une « autonomie gouvernée », où les systèmes agissent de façon indépendante dans des limites clairement définies.
Nos plateformes doivent apporter des réponses à des situations du type : que se passe-t-il si l’agent se trompe, combien d’erreurs sont acceptables, et quel est le coût d’un échec par rapport au bénéfice de l’automatisation ?
L’autonomie gouvernée suppose de définir en amont :
|
Des garde-fous et contraintes clairs |
Par exemple, les conditions dans lesquelles un agent peut agir sans intervention |
|
Des niveaux de tolérance à l’erreur définis |
Par exemple, les seuils de confiance requis pour une exécution autonome |
|
Des stratégies de déploiement progressif |
Par exemple, un lancement initial avec un fort niveau de revue humaine aux premières étapes, dont les agents pourront apprendre et s’améliorer |
Un agent peut opérer de manière autonome au-dessus d’un certain niveau de certitude. En dessous, il doit se remettre à un examen humain. Avec le temps, au fur et à mesure que la confiance et la performance augmentent et que les taux d’erreur diminuent, ces seuils peuvent évoluer, mais le mécanisme d’escalade reste en place.
Point crucial : une reprise en main humaine doit toujours rester possible. L’autonomie doit réduire l’implication sur les tâches courantes, pas l’éliminer.
Cette approche requalifie le paradoxe : l’agence n’est pas perdue par la délégation, elle s’exerce à l’intérieur d’un cadre de garde-fous.
Je suis convaincue que la confiance dans les systèmes agentiques viendra moins de meilleurs modèles que de meilleurs cadres de gouvernance.
Les entreprises ont besoin d’un cadre de garde-fous intégré à l’infrastructure du système. Il donne du pouvoir aux agents tout en les rattachant à une logique déterministe.
Un cadre robuste pour l’entreprise devrait inclure :
Les agents ne doivent pas s’appuyer uniquement sur les données pour déterminer leurs prochaines actions. Ils doivent opérer selon des règles et contraintes prédéfinies, alignées sur les politiques réglementaires, financières et organisationnelles de l’entreprise.
Ces règles et contraintes doivent être intégrées dans les workflows. Ainsi, les politiques deviennent opposables et applicables.
Les entreprises ont besoin de traçabilité sur la manière dont les décisions sont élaborées et exécutées.
Il ne suffit pas de voir le résultat de l’agent ; les organisations doivent pouvoir examiner son « raisonnement » : le cheminement, ainsi que l’usage des outils et les sources de données.
Cela permet un audit trail expliquant pourquoi une décision a été prise. On crée ainsi de l’imputabilité, on facilite la conformité réglementaire et on rend possible l’analyse post‑incident.
Les agents ne doivent pas improviser là où une logique déterministe existe déjà.
Plutôt que de laisser un agent « deviner » à chaque fois comment calculer une marge fiscale complexe, fournissez‑lui un outil fixe et vérifié (un « nœud » ou sous‑tâche) pour exécuter ce calcul précis.
Ainsi, l’agent devient un orchestrateur d’outils fiables plutôt qu’un générateur de raisonnements incertains dans des contextes potentiellement à haut risque.
Un accès profond aux données n’est pas toujours nécessaire.
Les agents doivent accéder aux données selon un principe de stricte nécessité. Par exemple, un agent de support a besoin de l’historique de conversation et d’une base de connaissances, mais probablement pas du numéro de sécurité sociale du client pour être efficace.
Les systèmes agentiques ne doivent pas passer du pilote à l’autonomie en une seule étape.
Les phases initiales peuvent impliquer davantage de revue humaine et de supervision active. Mais avec le temps, à mesure que la performance se stabilise et que les modes de défaillance sont compris, l’autonomie peut être étendue.
La maintenance continue est essentielle. Les agents doivent être entretenus et optimisés en continu. Les données peuvent évoluer, devenir obsolètes, et la réglementation peut changer. Sans surveillance ni recalibrage, les agents prendront des décisions sur la base d’informations inexactes ou périmées.
Pour instaurer une autonomie gouvernée à l’échelle, la couche de gouvernance d’une organisation doit se situer au‑dessus des modèles et fournisseurs individuels, afin d’éviter l’enfermement propriétaire.
La gouvernance doit exister comme une couche architecturale, vous permettant de remplacer l’IA sous‑jacente tout en conservant les garde-fous.
Les plateformes qui combinent orchestration, logique déterministe et exécution transparente sont stratégiquement clés dans ce contexte. Elles permettent aux organisations de décider comment les agents interagissent avec les données et processus d’entreprise.
Une idée reçue veut que de meilleurs modèles conduisent automatiquement à de meilleures décisions. Les incidents les plus dommageables ne découleront pas d’erreurs de modèle, mais d’humains qui délèguent la responsabilité sans la concevoir. Le contrôle réside dans le système, pas dans le modèle.
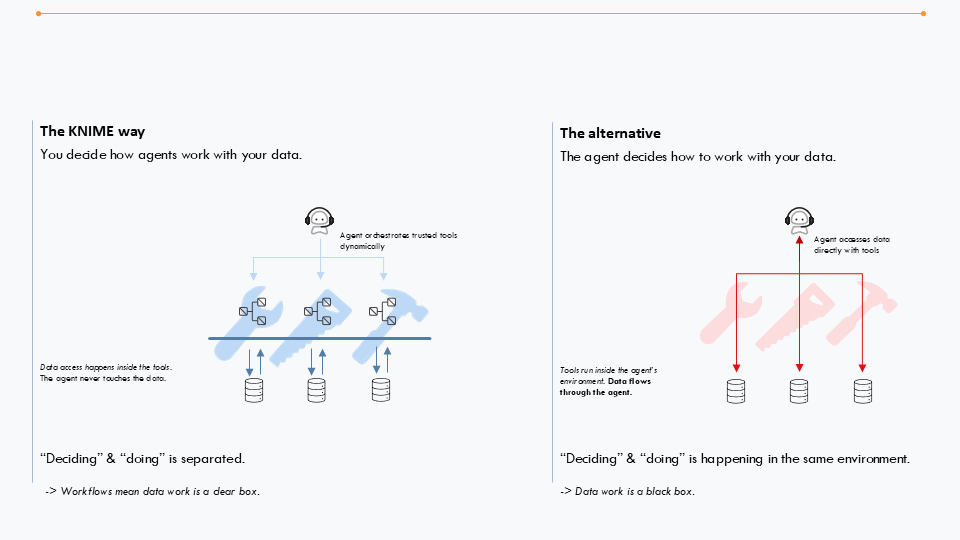
KNIME applique les bonnes pratiques de construction d’agents et garantit que l’agent ne touche jamais aux données
Le paradoxe de l’IA en entreprise ne disparaîtra pas : les organisations chercheront davantage d’autonomie pour gagner en efficacité et en échelle, tandis que les inspections réglementaires et les risques augmenteront.
L’essentiel à retenir : l’agence doit être garantie par la conception.
Les échecs les plus marquants de l’ère agentique viendront moins de la technologie elle‑même que de gouvernances mal conçues. Réussiront celles et ceux qui penseront l’autonomie de manière intentionnelle et inscriront la supervision dans la structure.
La cerise sur le gâteau : lorsque votre plateforme d’IA offre des capacités de gouvernance intégrées. Vous pouvez ainsi faire monter en puissance l’automatisation et l’évaluation. Pour aller plus loin, découvrez comment élaborer un playbook de gouvernance de l’IA dans ce webinar DataCamp.
Les meilleurs cours DataCamp
Cursus
Cours
Cours
blog
blog
Lynn Heidmann
blog
Kurtis Pykes
9 min
blog
Kurtis Pykes
15 min
Tutoriel

