
Lernpfad
KNIME Grundlagen
17 Std.
Das neue Enterprise-KI-Paradox lautet: Je mehr wir Handlungen an KI-Agenten delegieren, desto mehr verlieren wir unsere eigene Handlungsfähigkeit. In der agentischen Ära sind Bewertung und Vertrauen, nicht die Generierung, der Engpass.
Wir haben uns an KI-Systeme gewöhnt, die vor allem unser menschliches Urteil unterstützen. In vielen Fällen sind wir auch daran gewöhnt, dass diese Systeme unser Urteil und unsere Vorurteile bestätigen und sie nicht ernsthaft hinterfragen. Sie erzeugen Texte, fassen Informationen zusammen oder geben Empfehlungen.
Dennoch blieb der Mensch der Entscheidende und Freigebende.
AI agents haben das geändert. Agentische Systeme generieren nicht nur Vorschläge, sondern sind dafür gebaut, in komplexen Unternehmensökosystemen zu planen, zu entscheiden und zu handeln.
Sie starten Workflows, rufen APIs auf, bewegen Geld und aktualisieren Datensätze. Sie stoßen Prozesse an, ohne unbedingt auf eine menschliche Bestätigung zu warten. Das verändert die Risikolandschaft im Unternehmen.
Das Problem ist: Wenn agentische Systeme handeln, können die Folgen teuer werden. Wenn ein Agent einen Einkaufsfehler über 300.000 $ macht, ist „das Tool hat entschieden“ keine tragfähige Ausrede mehr. Der Verlust für das Unternehmen ist real, und jemand muss die Verantwortung tragen. Deine Verantwortung verschwindet nicht, nur weil der Agent gehandelt hat.
Unternehmen wollen Tempo, Skalierung und Effizienz autonomer Agenten, aber Verantwortlichkeit lässt sich nicht automatisieren. Handlungen an einen Agenten zu delegieren bedeutet nicht, Verantwortung zu delegieren.
Die zentrale Frage lautet: Wie skalieren wir agentische KI, ohne unsere eigene Handlungsfähigkeit aufzugeben?
Um das zu beantworten, müssen wir zwischen assistierender KI und agentischer KI unterscheiden.
Der Unterschied liegt im Maß der Kontrolle. In assistierenden Systemen liegt die Handlungsfähigkeit klar beim Menschen. Autorität und Verantwortlichkeit sind eher deckungsgleich: Menschen entscheiden, Systeme unterstützen. In agentischen Systemen jedoch handelt das System, während die endgültige Verantwortung beim Menschen bleibt.
Hier verschärft sich das Paradox.
Mit wachsender Autonomie wird ständige menschliche Überwachung unpraktikabel. Weniger Aufsicht erhöht jedoch das Risiko für Richtlinienverstöße, Fehler und unbeabsichtigte Folgen. Und werden Agenten zu stark eingeengt, bleibt Autonomie theoretisch – Skalierung und Effizienz gehen verloren.
An Anbietern, die Automatisierung in großem Stil versprechen, mangelt es nicht. Agenten erstellen Pläne, treffen Entscheidungen und handeln schneller als jedes menschliche Team.
Doch wenn Agenten handeln, stellt sich für Unternehmen eine neue Frage: Woher wissen wir, dass diese Handlungen korrekt, sicher und richtlinienkonform sind?
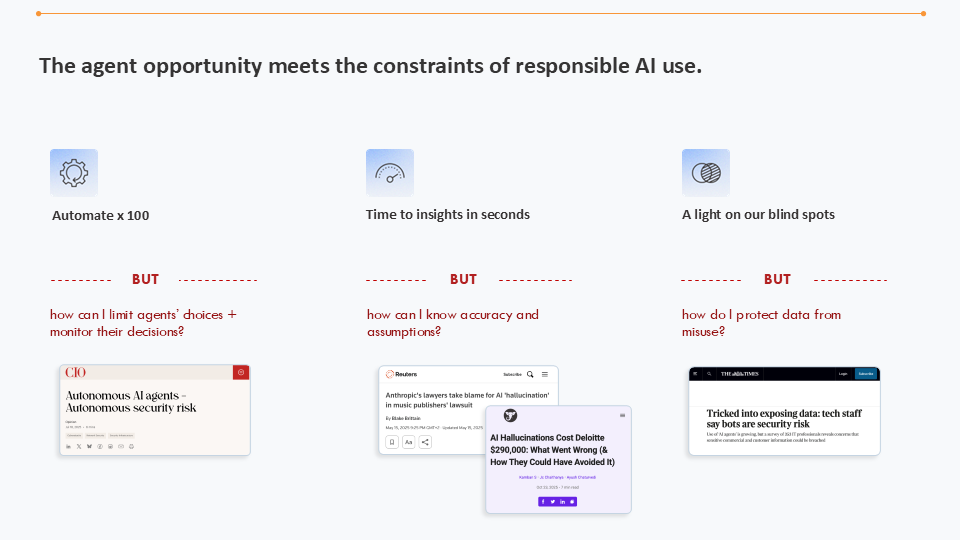
Was passiert, wenn Agenten-Chancen auf die Grenzen verantwortungsvoller KI-Nutzung treffen
Die naheliegende Reaktion ist, Freigabeschritte hinzuzufügen: eine Prüferin, die abzeichnet, und Eskalationen bei Ausnahmen. Doch der klassische „Human-in-the-Loop“ bricht in der Skalierung zusammen.
Ein kontinuierlich laufender Agent kann hunderte oder sogar tausende Entscheidungen pro Tag treffen. Muss jede Aktion manuell bewertet werden, übersteigt der Prüfaufwand schnell den ursprünglichen Zeitgewinn. Wir hätten die Ausführung automatisiert, nur um den Engpass bei der Bewertung wieder einzuführen.
Und es gibt ein weiteres Problem: Wir prüfen, ob die Handlungen eines Agenten korrekt, sicher und geschützt sind. Aber was ist mit dem „Nein“? Weiß das System, wann es nicht handeln soll?
Das ist vielleicht eines der größten Probleme agentischer KI: Ein nützlicher Agent muss Richtlinienkonflikte erkennen und sagen können: „Das darf ich nicht“ oder „Das muss ich an einen Menschen übergeben.“ Ohne diese Fähigkeit werden Agenten zu Ausgabemaschinen, die Ergebnisse produzieren – ob sie sollen oder nicht.
In der Skalierung wird solches Verhalten zum Risiko.
Damit sind wir zurück beim Paradox.
Wenn der Mensch nicht alles überprüfen kann und Agenten ihre eigenen Grenzen nicht zuverlässig einschätzen, dann darf Bewertung kein informeller Nachbau nach dem Deployment bleiben. Sie muss in das System selbst eingebaut sein.
Die Frage ist also nicht, ob Bewertung notwendig ist, sondern wie sie umgesetzt wird.
Bei KNIME haben wir das in der Praxis gesehen. In einem Fall bauten wir einen Agenten, der aus Daten Insights Handlungen ableitete. Er beschleunigte unsere Arbeit enorm, doch wir stellten fast jeden Insight in Frage. Wir sollten Agenten nicht blind vertrauen – aber Vertrauen ist Voraussetzung für Skalierung.
Die Wende kam, als wir Feedback in den Workflow integriert haben. Indem wir jeden „Fehler“ kennzeichneten und einordneten, lernte der Agent von uns Menschen im Loop und verbesserte sich. Mit der Zeit stieg die Leistung – und das Vertrauen.
Unsere Erkenntnis: Vertrauen muss ins System eingebaut werden. Bewertung und Feedback dürfen kein Zusatzprozess sein, sondern Teil des Systems.
Ziel ist nicht unbegrenzte Autonomie oder ständige menschliche Aufsicht, sondern „gesteuerte Autonomie“, bei der Systeme innerhalb klar definierter Grenzen eigenständig handeln.
Unsere Plattformen müssen Antworten liefern: Was passiert, wenn der Agent falschliegt? Wie viele Fehler sind akzeptabel? Wie stehen Kosten des Scheiterns gegenüber dem Nutzen der Automatisierung?
Gesteuerte Autonomie erfordert, dass Organisationen im Voraus definieren:
|
Klare Leitplanken und Einschränkungen |
Zum Beispiel die Bedingungen, unter denen ein Agent ohne Eingriff handeln darf |
|
Definierte Fehlertoleranzen |
Zum Beispiel die Konfidenzschwellen für autonome Ausführung |
|
Schrittweise Rollout-Strategien |
Zum Beispiel: In der Anfangsphase findet intensive menschliche Prüfung statt, aus der die Agenten lernen und sich verbessern |
Ein Agent könnte oberhalb eines definierten Sicherheitsschwellenwerts autonom handeln. Darunter muss er an eine menschliche Prüfung übergeben. Mit wachsendem Vertrauen, besserer Leistung und sinkenden Fehlerraten können sich diese Schwellen anpassen – der Eskalationsmechanismus bleibt bestehen.
Wichtig ist: Ein menschlicher Override muss immer möglich sein. Autonomie soll Routineaufwand reduzieren, ihn aber nicht abschaffen.
Dieser Ansatz rahmt das Paradox neu: Handlungsfähigkeit geht bei Delegation nicht verloren, sondern wird auf Basis eines Leitplanken-Frameworks ausgeübt.
Ich bin überzeugt, dass Vertrauen in agentische Systeme nicht aus besseren Modellen entsteht, sondern aus besseren Frameworks.
Unternehmen brauchen ein Leitplanken-Framework als Teil der Systeminfrastruktur. Es gibt Agenten Freiraum, bindet sie aber an deterministische Logik.
Ein robustes Enterprise-Framework sollte Folgendes enthalten:
Agenten sollten nicht allein auf Basis von Daten entscheiden, was als Nächstes zu tun ist. Sie müssen innerhalb vordefinierter Regeln und Einschränkungen agieren, die mit regulatorischen, finanziellen und organisatorischen Richtlinien des Unternehmens abgestimmt sind.
Diese Regeln und Einschränkungen müssen in Workflows integriert werden. So werden Richtlinien durchsetzbar.
Unternehmen brauchen Nachvollziehbarkeit, wie Entscheidungen aufgebaut und ausgeführt werden.
Es reicht nicht, nur das Ergebnis des Agenten zu sehen; Organisationen müssen seinen „Denk“-Prozess inspizieren können – den Reasoning-Pfad sowie Toolnutzung und Datenquellen.
Das ermöglicht einen Audit-Trail, der erklärt, warum eine Entscheidung getroffen wurde. Das schafft Verantwortlichkeit, unterstützt Compliance und ermöglicht die Analyse nach Vorfällen.
Agenten sollten nicht improvisieren, wo es bereits deterministische Logik gibt.
Anstatt einen Agenten jedes Mal raten zu lassen, wie eine komplexe Steueraufschlagsberechnung funktioniert, gib ihm ein festes, verifiziertes Tool (einen „Node“ oder Sub-Task), das genau diese Berechnung ausführt.
So wird der Agent zum Orchestrator verlässlicher Tools statt zum Generator unsicherer Überlegungen in potenziell risikoreichen Kontexten.
Tiefer Datenzugriff ist nicht immer nötig.
Agenten sollten Daten nach dem Need-to-know-Prinzip abrufen. Ein Support-Agent braucht Verlauf der Konversationen und eine Wissensdatenbank, aber wahrscheinlich nicht die Sozialversicherungsnummer eines Kunden, um effektiv zu sein.
Agentische Systeme sollten nicht in einem Schritt vom Pilot in die Autonomie übergehen.
Frühe Phasen können mehr menschliche Prüfung und aktives Monitoring erfordern. Wenn sich die Leistung stabilisiert und Fehlermodi verstanden sind, kann die Autonomie ausgebaut werden.
Kontinuierliche Wartung ist essenziell. Agenten müssen laufend gepflegt und optimiert werden. Daten können sich verändern oder veralten, Vorschriften können sich ändern. Ohne Monitoring und Neukalibrierung treffen Agenten Entscheidungen auf Basis ungenauer oder veralteter Informationen.
Um gesteuerte Autonomie in der Skalierung umzusetzen, sollte die Governance-Schicht einer Organisation über einzelnen Modellen und Anbietern liegen, um Vendor-Lock-in zu vermeiden.
Governance sollte als Architekturschicht existieren, damit du die zugrunde liegende KI austauschen kannst, während die Leitplanken erhalten bleiben.
Plattformen, die Orchestrierung, deterministische Logik und transparente Ausführung kombinieren, sind hier strategisch wichtig. Sie erlauben es Organisationen zu steuern, wie Agenten mit Unternehmensdaten und -prozessen interagieren.
Es ist ein Irrtum, dass bessere Modelle automatisch zu besseren Entscheidungen führen. Die gravierendsten Vorfälle werden nicht auf Modellfehler zurückzuführen sein, sondern darauf, dass Menschen Verantwortung delegieren, ohne Verantwortung zu gestalten. Kontrolle liegt im System, nicht im Modell.
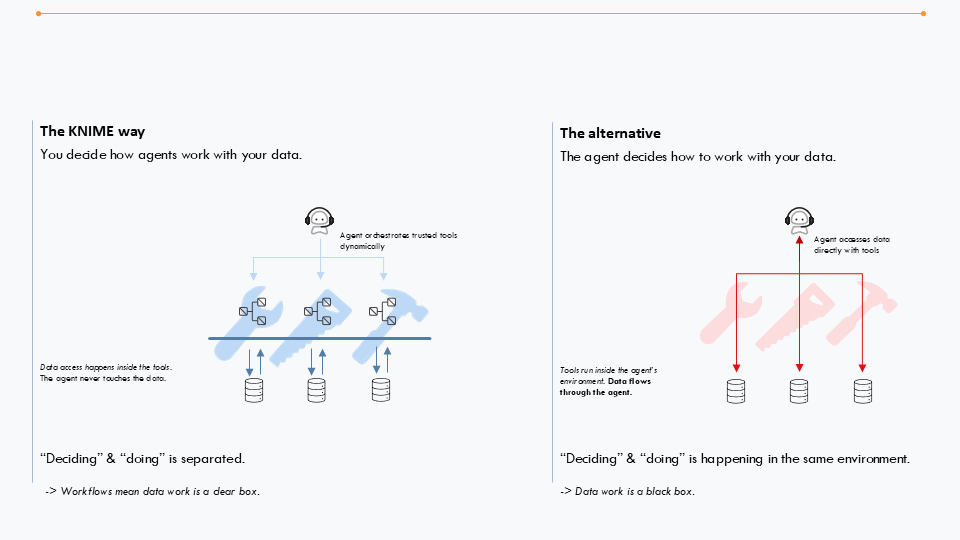
KNIME folgt Best Practices beim Bau von Agenten und stellt sicher, dass der Agent nie direkt die Daten berührt
Das Enterprise-KI-Paradox wird nicht verschwinden: Organisationen wollen mehr Autonomie für mehr Effizienz und Skalierung, gleichzeitig steigen Prüfanforderungen und Risiken.
Die zentrale Erkenntnis: Handlungsfähigkeit muss durch Design sichergestellt werden.
Die schwerwiegendsten Fehlentwicklungen der agentischen Ära werden wohl weniger aus der Technologie selbst kommen, sondern aus schlechter Governance. Erfolgreich sind die Organisationen, die Autonomie bewusst gestalten und Aufsicht strukturell verankern.
Das Sahnehäubchen ist, wenn deine KI-Plattform integrierte Governance-Funktionen bietet. So lassen sich Automatisierung und Bewertung zugleich skalieren. Mehr über die Entwicklung eines Playbooks für KI-Governance erfährst du in diesem DataCamp-Webinar.
Top-DataCamp-Kurse
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Matt Crabtree
14 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Matt Crabtree
