
Track
KNIME Fundamentals
17 hr
The new enterprise AI paradox is this: The more we delegate action to AI agents, the more we lose our own agency. In the agentic era, evaluation and trust, not generation, is the bottleneck.
We’ve become used to AI systems that primarily support our own human judgment. In many cases, we’ve also grown accustomed to these systems confirming our human judgment and biases, and not meaningfully challenging them. They generate text, summarize information, or give us recommendations.
Nevertheless, the human remained the decision-maker and approver.
AI agents have changed that. Agentic systems don’t just generate suggestions, but are designed to plan, decide, and act across complex organizational ecosystems.
They trigger workflows, call APIs, move money, and update records. They initiate processes without necessarily waiting for human confirmation. This changes the enterprise’s risk landscape.
The problem is that when agentic systems act, the consequences can be costly. When an agent makes a $300k procurement error, “the tool made the decision” is no longer a viable defence. The loss for the business is real, and someone needs to be accountable. Your responsibility doesn’t disappear just because the agent acted.
Enterprises want the speed, scale, and efficiency of autonomous agents, but accountability can’t be automated away. Delegating action to an agent doesn’t mean delegating responsibility.
The central question is: How do we scale agentic AI usage without giving up agency?
To answer that, we need to distinguish between assistive AI and agentic AI.
The distinction is the level of control. In assistive systems, agency clearly resides with the human. Authority and accountability are more likely to align, with humans deciding and systems supporting. But in agentic systems, the system acts, while the final accountability remains with the human.
This is where the paradox worsens.
As autonomy increases, constant human oversight (the human-in-the-loop) becomes impractical. But reducing supervision increases exposure to risk, such as policy violations, errors, and unintended consequences. And constraining agents too tightly makes autonomy theoretical, and we lose out on scale and efficiency.
There’s no shortage of vendors who can promise automation at scale. Agents produce plans, make decisions, and act faster than any human team.
But when agents act, enterprises face a new question: How do we know those actions are correct, safe, and aligned with our policies?
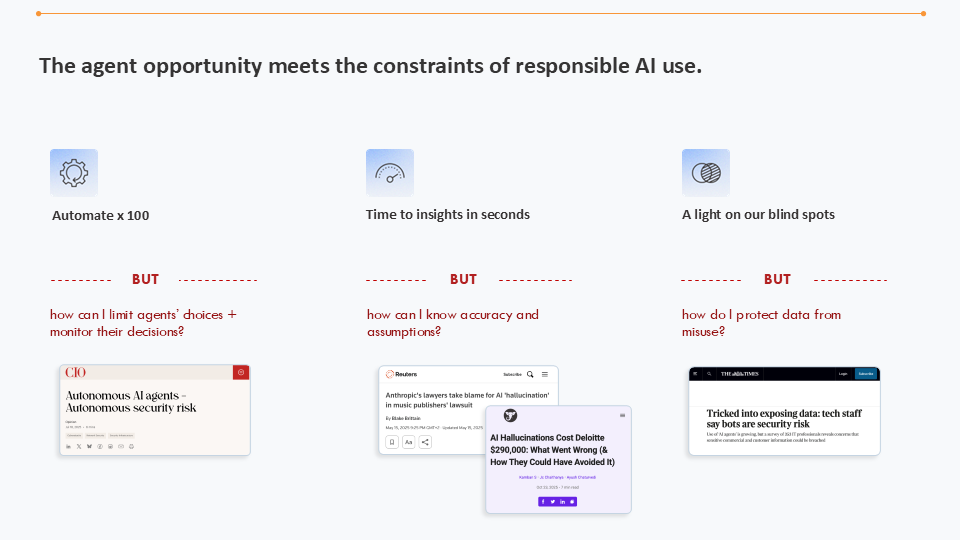
What happens when agent opportunities meet the constraints of responsible AI use
The common instinct here is to add approval steps: a reviewer to sign off, and escalate exceptions. However, the traditional “human-in-the-loop” breaks down at scale.
An agent operating continuously could make hundreds or even thousands of decisions per day. If every action requires manual evaluation, the final “proof work” will outweigh the initial time savings. We’ll have automated execution only to reintroduce a bottleneck in evaluating.
And there’s another complication. We evaluate whether the actions an agent takes are correct, safe, and secure. But what about saying “no”? Does the system know when not to act?
This might be one of the biggest problems of agentic AI: A useful agent needs to be able to detect policy conflicts, for example, and say “I cannot do this” or “I need to forward this to a human.” Without this capability, agents become output machines, generating results whether they should or not.
At scale, this kind of behavior becomes a liability.
This brings us back to the paradox.
If humans can’t review everything and agents can’t reliably assess their own limits, then evaluation can’t remain an informal layer added after deployment. It has to be designed into the system itself
The issue is therefore not whether evaluation is necessary, but how it’s implemented.
At KNIME, we’ve seen this in practice. In one case, we built an agent that generated actions from data insights. It helped tremendously to speed up our work, but we found ourselves questioning nearly every single insight. We shouldn’t blindly trust the agents, but trust needs to exist for scaling.
The turning point came when we integrated feedback into the workflow. By labeling and identifying each “failure,” the agent learned and improved from us, the humans in the loop. Over time, the agent improved, and trust increased.
Our learning here was to build trust into the system: Evaluation and feedback must become part of the system, not an add-on process.
The goal is not unrestricted autonomy or permanent human supervision but “governed autonomy,” where systems act independently within clearly defined boundaries.
Our platforms need to have answers for situations like what happens if the agent is wrong, how many errors are acceptable, and what is the cost of failure vs the benefit of automation.
Governed autonomy requires organizations to define, in advance:
|
Clear guardrails and constraints |
For example, the conditions under which an agent may act without intervention |
|
Defined error tolerance levels |
For example, the confidence thresholds needed for autonomous execution |
|
Gradual roll-out strategies |
For example, initial roll-out would involve a high level of human review during the early stages, from which the agents can learn and improve |
An agent could operate autonomously above a defined certainty level. Below that threshold, it must defer to human review. Over time, as trust and performance improve and error rates decrease, those thresholds may adapt, but the escalation mechanism remains in place.
Crucially, human override must always remain possible. Autonomy should reduce routine involvement, but not eliminate it.
This approach reframes the paradox: Agency isn’t lost when delegated, but is exercised based on a guardrail framework.
I believe that trust in agentic systems won’t come from better models, but from better frameworks.
Enterprises need a guardrail framework that’s part of the system infrastructure. It empowers agents while keeping them tied to deterministic logic.
A robust enterprise framework should include:
Agents shouldn’t rely on data alone to determine their next actions. They should operate within predefined rules and constraints, aligned with the enterprise’s regulatory, financial, and organizational policies.
These rules and constraints need to be integrated into workflows. This way, policies become enforceable.
Enterprises need traceability into how decisions are constructed and executed.
It’s not enough to just see the agent's outcome; organizations must be able to inspect its "thinking" process – the reasoning path, as well as tool usage and data sources.
This allows for an audit trail that explains why a decision was made. This creates accountability, supports regulatory compliance, and enables post-incident analysis.
Agents shouldn’t improvise in areas where deterministic logic already exists.
Instead of letting an agent guess how to calculate a complex tax margin every time, give it a fixed, verified tool (a "node" or sub-task) to execute that specific calculation.
This way, the agent becomes an orchestrator of reliable tools rather than a generator of uncertain reasoning in potentially high-risk contexts.
Deep data access isn’t always necessary.
Agents should access data on a “need-to-know” basis. While a support agent needs conversation history and a knowledge base, it probably doesn’t need a customer’s social security number to be effective.
Agentic systems shouldn’t move from pilot to autonomy in a single step.
Early phases may involve higher levels of human review and active monitoring. But over time, as performance stabilizes and failure modes are understood, autonomy can be expanded.
Continuous maintenance is essential. Agents need to be continuously maintained and optimized. Data can shift, become outdated, and regulations can change. If agents aren’t monitored and recalibrated, they will make decisions based on inaccurate or old information.
To implement governed autonomy at scale, an organization’s governance layer should sit above individual models and vendors, avoiding vendor lock-in.
Governance should exist as an architectural layer, allowing you to swap the underlying AI while keeping guardrails intact.
Platforms that combine orchestration, deterministic logic, and transparent execution are strategically important in this context. They allow organizations to decide how agents interact with enterprise data and processes.
There’s a misconception that better models automatically lead to better decisions. The most damaging incidents won’t trace back to model errors, but to humans delegating responsibility without designing responsibility. Control resides in the system, not the model.
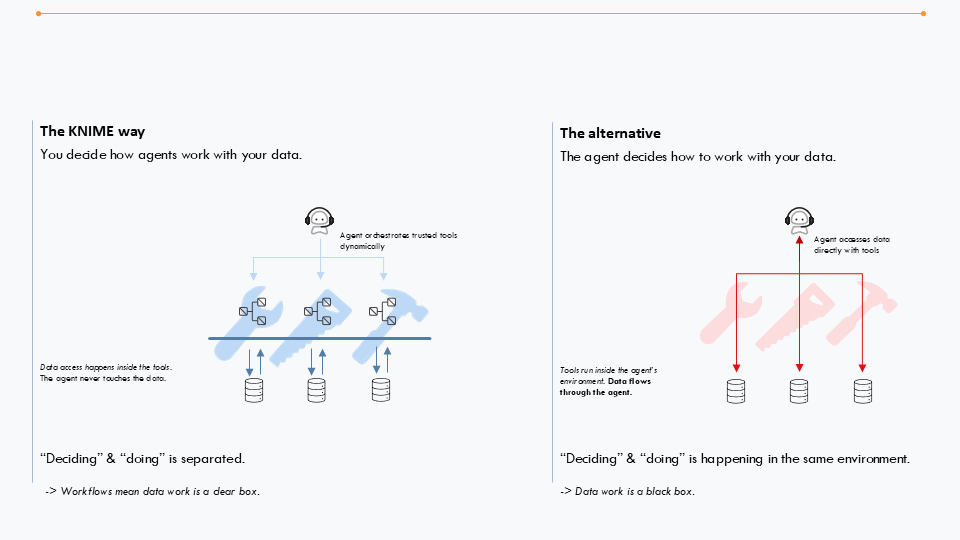
KNIME follows best practices for building agents and ensures the agent never touches the data
The enterprise AI paradox won’t disappear: Organizations will want greater autonomy to benefit from more efficiency and scale, but regulatory inspections and risk will increase.
The key insight is that agency needs to be ensured by design.
The most significant failures of the agentic era are unlikely to come from the technology itself, but from poorly designed governance. The organizations that succeed will be those that design autonomy intentionally and embed oversight structurally.
The cherry on top is when your AI platform provides integrated governance capabilities. This way, organizations get to scale automation and evaluation. You can learn more about developing a playbook for AI governance with this DataCamp webinar.
Top DataCamp Courses
Track
Course
Course
blog
Kurtis Pykes
14 min
blog
François Aubry
10 min
blog
Vinod Chugani
9 min
podcast
podcast
Tutorial
Rahul Sharma


