
Leerpad
OpenAI-basisprincipes
15 Hr
Een paar jaar geleden kreeg je een groot taalmodel nauwelijks zo ver dat het een fatsoenlijke e-mail schreef. Toen OpenAI zijn eerste open-source model uitbracht, was het al bijzonder dat het samenhangende tekst kon genereren. Slechts een paar jaar later hebben we nu AI-modellen die volledige softwareprojecten kunnen bouwen, afspraken kunnen inplannen, producten op Amazon kunnen kopen, en meer. In 2026 is het landschap echt veranderd, en de vraag die ontwikkelaars stellen is welk model het beste werkt voor hun use-cases.
GPT-5.4 en Claude Opus 4.6 staan nu centraal in die vraag. Beide zijn op verschillende manieren capabel, en ze werden met slechts enkele weken verschil gelanceerd. Wel verschillen de prijzen, en presteren ze het best in verschillende scenario's.
Ik heb me de afgelopen week verdiept in hun releasenotities en onafhankelijke leaderboards. In dit artikel neem ik je mee door wat ik heb ontdekt, zodat je het beste model voor jouw workflow kunt kiezen.
Claude Opus 4.6 is tot nu toe het meest capabele model van Anthropic. Opus 4.6 is een verbetering van het vorige model, met belangrijke vooruitgang in coderen en langdurige agent-taken. Volgens Anthropic presteert het beter in plannen, code review en debugging, en kan het zelfs zijn eigen fouten opsporen.
Anthropic bracht Opus 4.6 uit met een contextvenster van 1M tokens in bèta, met een maximale output van 128K tokens. Hierdoor kan het model werken met grote codebases en grote documenten, zoals documentatie.
Deze release introduceert ook Adaptive Thinking, wat betekent dat Claude nu zelf kan beslissen wanneer uitgebreid redeneren nodig is, in plaats van te wachten tot jij dat handmatig inschakelt.
Claude Opus 4.6 kan bepalen of iets een snelle fix nodig heeft of meer tijd verdient om te redeneren en een plan te maken. Ik denk dat dit erg nuttig zal zijn voor het oplossen van complexe engineeringproblemen. Het is geen verrassing dat het model bovenaan de text and coding arena leaderboard staat.
In codebenchmarks scoort Claude Opus 4.6 81,42% op SWE-Bench Verified, dat test hoe goed een model echte GitHub-issues oplost. Het model scoorde ook het best op Humanity’s Last Exam.
Met Opus 4.6 introduceerde Claude ook Agent Teams als experimentele feature in Claude Code. Als je dit inschakelt, kun je meerdere agents opstarten om aan taken te werken. De agents werken samen als een team, met gedeelde taken en berichtenverkeer tussen agents.
Je kunt leren hoe je Anthropic's Claude Code gebruikt om softwareontwikkelingsworkflows te verbeteren aan de hand van een praktisch voorbeeld met de Supabase Python-bibliotheek in onze Claude Code-tutorial.
Claude Opus 4.6 is een zeer sterk agentisch model. De maker van OpenClaw raadt zelfs aan het in OpenClaw te gebruiken omdat het moeilijk te vergiftigen is met promptinjecties. Dit maakt het model robuuster tegen kwaadaardige code.
De Agents Teams-feature, hoewel nog experimenteel, is een enorme upgrade ten opzichte van subagents. Hiermee kun je je taak verdelen over meerdere Claude-agents. Zo kan er één de backend afhandelen, een ander de frontend, en weer een ander tests uitvoeren. Elke agent heeft zijn eigen contextvenster, waardoor de kans op falen door contextlimieten afneemt.
Cladue Opus 4.6 is een sterk model, maar zoals het gezegde luidt: er is niet zoiets als een gratis lunch. Dit model is niet goedkoop om te draaien, zeker niet als je een zware gebruiker bent.
GPT-5.4 is OpenAI’s meest recente en meest capabele model. Het is gebouwd door de codeercapaciteiten van GPT-5.3-Codex te combineren en redeneren toe te voegen om zo één krachtig model te creëren. Dat betekent dat je niet langer hoeft te wisselen tussen codex-modellen voor coderen en andere OpenAI-modellen voor andere taken.
De feature van GPT-5.4 die ik het interessantst vind, is het vermogen om een computer te bedienen. Op OSWorld, een benchmark die meet hoe goed een model een desktopcomputer kan gebruiken, scoorde GPT-5.4 75,0%, terwijl menselijke prestaties op 72,4% liggen. Ter vergelijking: GPT-5.2 scoorde 47,3% op dezelfde test.
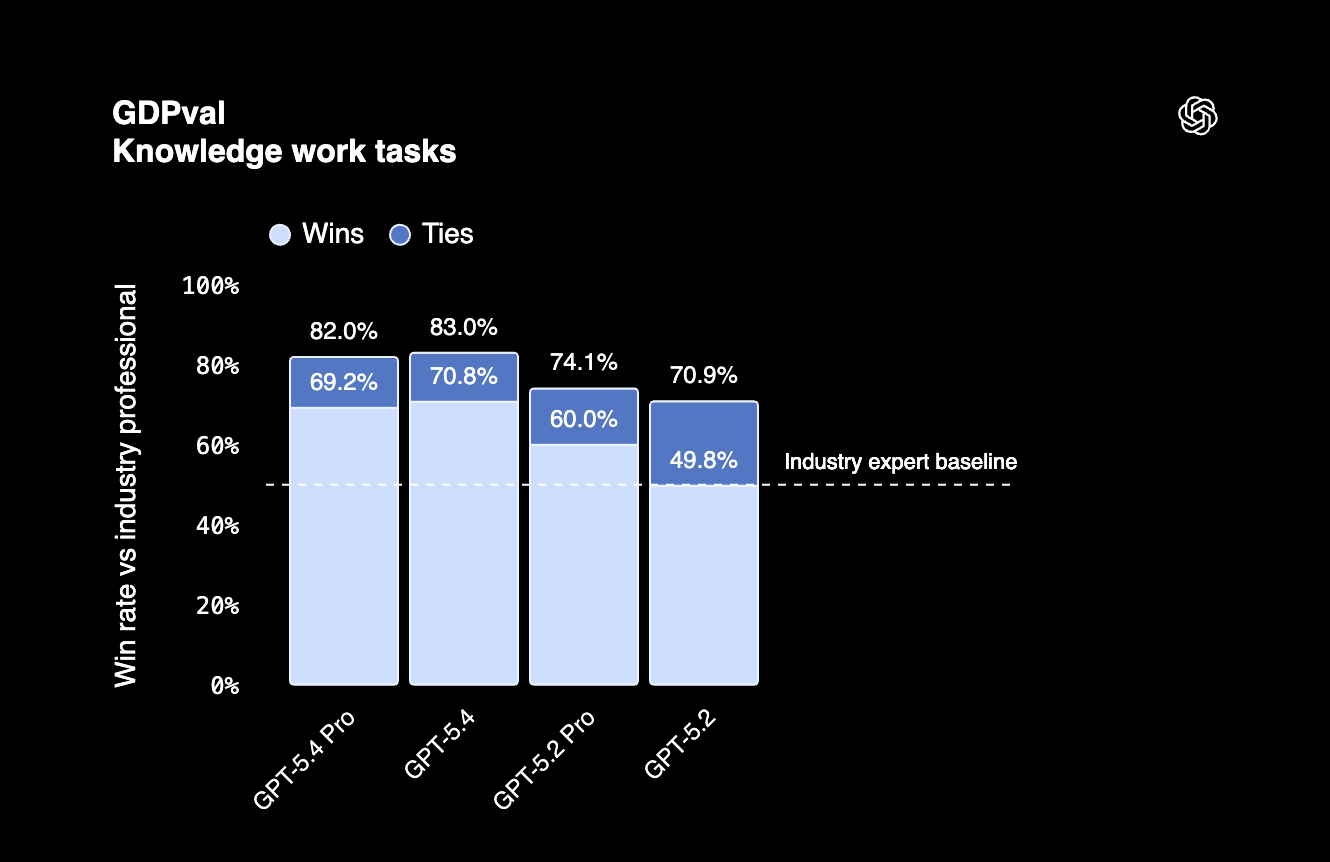
Op GDPval, een benchmark die professionele kenniswerkprestaties over 44 beroepen test, scoorde GPT-5.4 83%. Dit betekent dat het model agent-taken kan uitvoeren op het niveau van een professional in topbanen in de VS.
GPT-5.4 biedt ook tokenefficiëntie, wat betekent dat het voor veel taken minder tokens gebruikt dan eerdere modellen. Dat is iets om op te letten als je dagelijks meerdere requests draait.
GPT-5.4 introduceert bovendien een Tool Search-systeem, waardoor het model efficiënter werkt wanneer het meerdere tools krijgt. In plaats van de tooldefinitie in de prompt op te nemen, wat extra tokens kost, krijgt het model nu een lijst met tools en een zoekfunctie voor tools. Wanneer het model een tool nodig heeft, zoekt het die op en voegt hem toe aan dat specifieke gesprek. Dit leidt tot betere tokenefficiëntie.
Wat ik het meest indrukwekkend vind, is GPT-5.4’s vermogen om mensen te verslaan in autonoom computergebruik. Het verslaat Claude Opus 4.6 op dit gebied, met 75% op OSWorld-benchmarks, vergeleken met Opus 4.6' 72,7%.
Onafhankelijk onderzoek van Artificial Analysis toont aan dat GPT 5.4 (xhigh) een score van 30% behaalt op de CritPt-benchmark, die LLM's test op natuurkundige redeneertaken op onderzoeksniveau, met 71 samengestelde onderzoeksuitdagingen.
GPT-5.4 is beter en nauwkeuriger in het aanroepen van tools. In het releaserapport merkt OpenAI op dat het betere resultaten behaalt in minder stappen op Toolathlon, een benchmark om te testen hoe agents echte tools en API's gebruiken om taken met meerdere stappen af te ronden.
Net als Claude Opus 4.6 is GPT-5.4 ook geen goedkoop model. Gelukkig biedt OpenAI goedkopere prijzen via de batch inference API.
Nu je de voor- en nadelen van GPT-5.4 en Opus 4.6 hebt gezien, laten we ze vergelijken om te bepalen welke het beste is voor jouw use-cases.
Over het geheel genomen is GPT-5.4 het beste model volgens de Artificial Analysis Intelligence Index, die de prestaties van modellen over verschillende benchmarks meet. Alleen Gemini 3.1 Pro doet het beter.
Claude Opus 4.6 wint op het gebied van orkestratie met meerdere agents. Met de Agent Teams-feature kun je meerdere workflows draaien met parallelle agents die aan verschillende taken werken.
GPT-5.4 wint nipt in computergebruik. Als je agent een desktop moet bedienen, door een browser moet navigeren of met GUI-software moet interageren, is GPT-5.4 op dit moment de betere keuze
Claude Opus 4.6 is de betere programmeur met een score van 80,84% op SWE-Bench Verified en 81,4% met een aangepaste prompt.
GPT-5.4 erft de codeercapaciteiten van GPT-5.3-Codex. Volgens OpenAI behaalt GPT-5.4 een score van 57,7% op SWE-Bench Pro (Public) met lagere latency bij redeneertaken.
In hun rapport claimt OpenAI dat GPT-5.4 bij bepaalde taken 47% minder tokens verbruikte. Hoewel duurder dan Opus 4.6, kan GPT-5.4 op schaal goedkoper zijn door deze tokenreductie.
Toch kan Opus 4.6 nog steeds het betere model zijn voor minder, maar complexe agent-taken.
Ter context: het krachtigste GPT-5.4-model (contextlengte>272K) kost $60 per 1M inputtokens en $270 per 1M outputtokens, terwijl Claude Opus 4.6 $5 per 1M inputtokens en $25 per 1M outputtokens kost.
Zowel GPT-5.4 als Claude Opus 4.6 ondersteunen tot 1M tokens aan context, al is dat bij Claude in bèta. Dit maakt beide modellen sterke concurrenten voor werk in grote codebases.
|
Categorie |
Claude Opus 4.6 |
GPT-5.4 |
|
Agent-taken |
Sterk (Agent Teams, parallelle orkestratie) |
Sterk (computergebruik, OSWorld 75%) |
|
Codeerbenchmark |
SWE-Bench 80,2% met Thinking |
57,7% op SWE-Bench Pro (Public) |
|
Computergebruik |
72,7% op OSWorld |
OSWorld 75% (verslaat menselijke experts) |
|
Contextvenster |
1M tokens (bèta), 128K max output |
1M tokens |
|
Kenniswerk |
Leider op Humanity's Last Exam |
GDPval 83% |
|
Prijzen (input/output) |
$5 Base Input Tokens $25 Output Tokens per miljoen tokens |
gpt-5.4 (<272K contextlengte) kost $2,50 per 1M inputtokens en $15,00 per 1M outputtokens. Modellen met een groter contextvenster zijn duurder. |
|
Tokenefficiëntie |
Standaard |
47% minder tokens bij sommige taken |
|
Beste voor |
Langdurig draaiende agents, complexe codebases |
Computergebruik, documentworkflows, enterprise |
Tot slot beantwoorden we de belangrijkste vraag: welke van de twee moet je kiezen?
De modellen van Anthropic zijn al lang favoriet voor coderen, maar ze blinken ook uit in onverwachte gebieden zoals creatief schrijven. Sommigen beweren zelfs dat ze daar de allerbeste in zijn.
Maar Anthropic heeft nooit publiekelijk gesteld dat hun modellen gespecialiseerd zijn in specifieke taken, zoals OpenAI wel zei dat het Codex-model specifiek voor programmeren was.
Ik vind het ontzettend interessant dat OpenAI nu de kant van Anthropic opgaat. Met hun laatste releases streven ze naar één enkel, uniform model dat een enorme variëteit aan professionele taken aankan. Dat is een enorme winst voor gebruikers; niemand wil voortdurend tussen gespecialiseerde modellen wisselen om werk gedaan te krijgen.
Aan de andere kant is het goed om te zien dat Anthropic het contextvenster van 1M omarmt, dat andere modellen (zoals Gemini 3) al lang hebben. Ik denk dat deze modellen in de toekomst erg vergelijkbare features zullen hebben, waardoor de doorslaggevende verschillen voor gebruikers beperkt zijn. Dat gezegd hebbende, zal de prestatie van het model op verschillende taken het belangrijkste onderscheid blijven, omdat gebruikers de voorkeur geven aan modellen die goed scoren op hun specifieke workflows.
In 2026 hebben zowel Anthropic als OpenAI sterke modellen voor agentisch werk. Wat verwarrend kan zijn, is dat ze verschillende benchmarks rapporteren. Waarschijnlijk cherry picking waar hun modellen uitblinken.
Het is nu aan jou om voor andere benchmarks naar onafhankelijke analyses te kijken en ze te testen op je eigen use-cases. Wat wel duidelijk is: de modellen worden beter. En jij zou ook beter moeten worden in het gebruiken ervan.
Een manier om te zorgen dat je niet wordt ingehaald door deze agentische beweging is om te leren hoe je deze modellen effectief inzet voor software engineering. Ik raad je aan om te beginnen met onze cursus Software Development with Cursor gratis te volgen. Je kunt ook de Introduction to Claude Models-cursus en de OpenAI Fundamentals-skilltrack volgen.
Topcursussen op DataCamp
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
