
Cursus
Fondamentaux d’OpenAI
15 h
Il y a quelques années, il était déjà difficile d’amener un grand modèle de langage à rédiger un e-mail correct. Quand OpenAI a publié son premier modèle open source, voir une IA produire un texte cohérent semblait incroyable. Quelques années plus tard, nous avons désormais des modèles capables de monter des projets logiciels complets, de programmer des réunions, d’acheter des produits sur Amazon, et plus encore. En 2026, le paysage a totalement changé, et les développeurs se demandent surtout quel modèle correspond le mieux à leurs cas d’usage.
GPT-5.4 et Claude Opus 4.6 sont au cœur de cette question. Tous deux sont performants, mais différemment, et ont été lancés à quelques semaines d’intervalle. Ils n’ont pas les mêmes tarifs et excellent dans des scénarios distincts.
J’ai passé la semaine à décortiquer leurs rapports de sortie et des classements indépendants. Dans cet article, je vous présente mes conclusions pour vous aider à choisir le meilleur modèle pour votre flux de travail.
Claude Opus 4.6 est à ce jour le modèle le plus abouti d’Anthropic. Opus 4.6 améliore la version précédente, avec des progrès clés en programmation et dans les tâches agentiques de longue durée. Anthropic indique qu’il planifie mieux, revoit le code et débogue plus efficacement, jusqu’à repérer ses propres erreurs.
Anthropic a lancé Opus 4.6 avec une fenêtre de contexte d’un million de tokens en bêta, et une sortie maximale de 128K tokens. Le modèle peut ainsi travailler sur de vastes bases de code et ingérer de gros documents, comme de la documentation.
Cette version introduit aussi Adaptive Thinking : Claude peut désormais décider de passer en mode raisonnement étendu sans attendre que vous l’activiez manuellement.
Claude Opus 4.6 sait évaluer si une demande nécessite une correction rapide ou si elle mérite plus de temps pour raisonner et élaborer un plan. C’est très utile pour résoudre des problèmes d’ingénierie complexes. Sans surprise, le modèle figure en tête du classement text and coding arena.
Sur les benchmarks de code, Claude Opus 4.6 obtient 81,42 % sur SWE-Bench Verified, qui évalue la capacité à résoudre de vrais tickets GitHub. Le modèle arrive également en tête sur Humanity’s Last Exam.
Avec Opus 4.6, Claude a aussi introduit Agent Teams comme fonctionnalité expérimentale dans Claude Code. Une fois activée, vous pouvez lancer plusieurs agents pour travailler sur des tâches. Les agents collaborent comme une équipe, avec des tâches partagées et une messagerie inter-agents.
Vous pouvez apprendre à utiliser Claude Code d’Anthropic pour optimiser vos workflows de développement logiciel via un exemple concret avec la bibliothèque Supabase Python dans notre tutoriel Claude Code.
Claude Opus 4.6 est un modèle agentique très robuste. Le créateur d’OpenClaw recommande d’ailleurs de l’utiliser dans OpenClaw car il est difficile à empoisonner via des injections de prompt. Le modèle est donc plus résistant au code malveillant.
La fonctionnalité Agent Teams, bien qu’encore expérimentale, représente une avancée majeure par rapport aux sous-agents. Vous pouvez répartir votre projet entre plusieurs agents Claude : par exemple, l’un gère le back-end, un autre le front-end, un troisième les tests. Chaque agent dispose de sa propre fenêtre de contexte, ce qui réduit le risque d’échec dû aux limites de contexte.
Claude Opus 4.6 est un excellent modèle, mais, comme on dit, rien n’est jamais gratuit. Son exécution peut coûter cher, surtout si vous avez un usage intensif.
Entre-temps, Anthropic a publié son modèle successeur. N’oubliez pas de consulter aussi notre guide sur Claude Opus 4.7 !
GPT-5.4 est le modèle le plus récent et le plus performant d’OpenAI. Il combine les capacités de codage de GPT-5.3-Codex à des capacités de raisonnement pour créer un modèle unique et puissant. Vous n’avez donc plus besoin d’alterner entre des modèles Codex pour le code et d’autres modèles OpenAI pour le reste.
La fonctionnalité la plus marquante de GPT-5.4 est, selon moi, l’usage autonome de l’ordinateur. Sur OSWorld, un benchmark qui mesure la capacité d’un modèle à utiliser un ordinateur de bureau, GPT-5.4 obtient 75,0 % quand la performance humaine est à 72,4 %. À titre de comparaison, GPT-5.2 atteignait 47,3 % au même test.
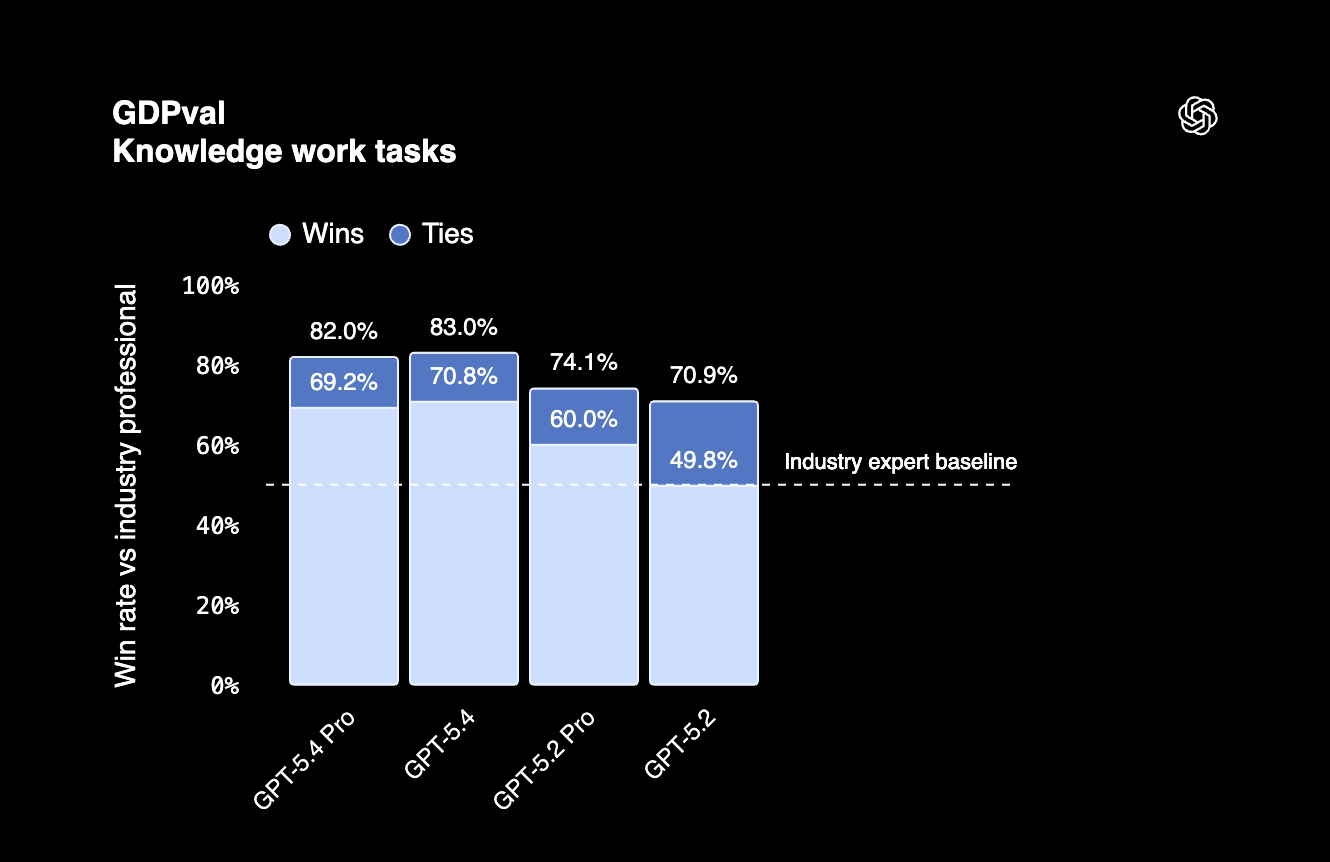
Sur GDPval, un benchmark qui évalue le travail de connaissance professionnel sur 44 métiers, GPT-5.4 atteint 83 %. Le modèle exécute donc des tâches agentiques au niveau d’un professionnel sur les principaux emplois aux États‑Unis.
GPT-5.4 améliore aussi l’efficacité en tokens, c’est‑à‑dire qu’il consomme moins de tokens que les versions précédentes pour de nombreuses tâches. À garder en tête si vous envoyez de multiples requêtes par jour.
GPT-5.4 introduit également un système de recherche d’outils (Tool Search), qui permet au modèle d’utiliser efficacement plusieurs outils. Plutôt que d’inclure la définition des outils dans le prompt (ce qui augmente le nombre de tokens), on fournit au modèle une liste d’outils et une capacité de recherche. Lorsqu’il a besoin d’un outil, il le recherche et l’ajoute à la conversation en cours. Résultat : une meilleure efficacité en tokens.
La prouesse la plus impressionnante est sa capacité à surpasser les humains en usage autonome de l’ordinateur. Il devance Claude Opus 4.6 sur ce point, avec 75 % sur OSWorld contre 72,7 % pour Opus 4.6.
Des recherches indépendantes d’Artificial Analysis montrent que GPT‑5.4 (xhigh) atteint 30 % sur le benchmark CritPt, qui évalue les LLM sur des tâches de raisonnement en physique de niveau recherche, avec 71 défis composites.
GPT-5.4 progresse aussi en précision d’appels d’outils. D’après le rapport de sortie, OpenAI indique qu’il obtient de meilleurs résultats en moins d’étapes sur Toolathlon, un benchmark qui teste la manière dont les agents utilisent des outils et API réels pour mener des tâches multi‑étapes.
Comme Claude Opus 4.6, GPT-5.4 n’est pas un modèle bon marché. Heureusement, OpenAI propose des tarifs plus bas via l’API d’inférence par lots.
Maintenant que vous avez vu les points forts et faibles de GPT-5.4 et d’Opus 4.6, comparons-les pour déterminer lequel convient le mieux à vos cas d’usage.
Globalement, GPT-5.4 est le meilleur modèle selon l’Artificial Analysis Intelligence Index, qui mesure la performance des modèles sur divers benchmarks. Le seul à le devancer est Gemini 3.1 Pro.
Claude Opus 4.6 l’emporte sur l’orchestration multi‑agents. Avec Agent Teams, vous exécutez plusieurs workflows en parallèle avec des agents dédiés à des tâches distinctes.
GPT-5.4 gagne de peu sur l’usage de l’ordinateur. Si votre agent doit manipuler un desktop, naviguer sur un navigateur ou interagir avec des logiciels à interface graphique, GPT-5.4 est pour l’instant le meilleur choix
Claude Opus 4.6 est le meilleur programmeur avec un score de 80,84 % sur SWE-Bench Verified et de 81,4 % avec un prompt modifié.
GPT-5.4 hérite des capacités de codage de GPT-5.3-Codex. Selon OpenAI, GPT-5.4 atteint 57,7 % sur SWE-Bench Pro (Public) avec une latence plus faible sur les tâches de raisonnement.
Dans leur rapport, OpenAI affirme que GPT-5.4 réduit de 47 % l’usage de tokens sur certaines tâches. Bien que plus cher qu’Opus 4.6, GPT-5.4 pourrait donc coûter moins cher à l’échelle grâce à cette réduction.
Cependant, Opus 4.6 peut rester préférable pour exécuter un volume réduit de tâches agentiques complexes.
À titre indicatif, le modèle GPT-5.4 le plus puissant (longueur de contexte >272K) coûte 60 $ pour 1 M de tokens en entrée et 270 $ pour 1 M de tokens en sortie, tandis que Claude Opus 4.6 coûte 5 $ pour 1 M de tokens en entrée et 25 $ pour 1 M de tokens en sortie.
GPT-5.4 et Claude Opus 4.6 prennent tous deux en charge jusqu’à 1 M de tokens de contexte, même si celui de Claude est en bêta. Ils sont donc bien placés pour travailler sur de grandes bases de code.
|
Catégorie |
Claude Opus 4.6 |
GPT-5.4 |
|
Tâches agentiques |
Solide (Agent Teams, orchestration parallèle) |
Solide (usage de l’ordinateur, OSWorld 75 %) |
|
Benchmark de code |
SWE-Bench 80,2 % avec Thinking |
57,7 % sur SWE-Bench Pro (Public) |
|
Usage de l’ordinateur |
72,7 % sur OSWorld |
OSWorld 75 % (dépasse des experts humains) |
|
Fenêtre de contexte |
1 M de tokens (bêta), 128K max en sortie |
1 M de tokens |
|
Travail de connaissance |
Leader sur Humanity’s Last Exam |
GDPval 83 % |
|
Tarification (entrée/sortie) |
5 $ par million de tokens d’entrée 25 $ par million de tokens de sortie |
gpt-5.4 (<272K de contexte) coûte 2,50 $ pour 1 M de tokens d’entrée et 15,00 $ pour 1 M de tokens de sortie. Les modèles avec une fenêtre plus large sont plus chers. |
|
Efficacité en tokens |
Standard |
47 % de tokens en moins sur certaines tâches |
|
Idéal pour |
Agents longue durée, bases de code complexes |
Usage de l’ordinateur, workflows documentaires, entreprise |
Pour conclure, répondons à la question essentielle : lequel des deux choisir ?
Les modèles d’Anthropic sont depuis longtemps des références pour le code, mais ils excellent aussi là où on les attend moins, comme l’écriture créative. Beaucoup diraient même qu’ils sont les meilleurs du marché sur ce terrain.
Anthropic n’a toutefois jamais affirmé publiquement que ses modèles étaient spécialisés sur des tâches spécifiques, là où OpenAI a longtemps présenté Codex comme dédié à la programmation.
Je trouve très intéressant de voir OpenAI se rapprocher aujourd’hui de l’approche d’Anthropic. Avec ses dernières sorties, l’éditeur pousse vers un modèle unifié capable de gérer une grande variété de tâches professionnelles. C’est un vrai plus pour les utilisateurs : personne n’a envie de changer de modèle spécialisé en permanence pour avancer.
À l’inverse, il est positif de voir Anthropic adopter la fenêtre de contexte à 1 M de tokens, que d’autres modèles (comme Gemini 3) proposaient depuis longtemps. À l’avenir, ces modèles auront des fonctionnalités très proches, avec peu de points réellement bloquants pour les utilisateurs. La performance sur différentes tâches restera la principale différenciation, car chacun préférera le modèle le plus adapté à ses workflows.
En 2026, Anthropic et OpenAI proposent tous deux d’excellents modèles pour le travail agentique. Ce qui peut vous dérouter, c’est qu’ils mettent en avant des benchmarks différents — sans doute ceux où leurs modèles brillent le plus.
À vous de consulter des analyses indépendantes pour d’autres benchmarks et de les tester sur vos propres cas d’usage. Une chose est sûre : les modèles progressent. Et vous avez, vous aussi, tout intérêt à progresser dans leur utilisation.
Pour ne pas vous laisser distancer par cette vague agentique, maîtrisez l’usage de ces modèles en ingénierie logicielle. Nous vous recommandons de commencer en vous inscrivant gratuitement à notre cours Software Development with Cursor. Vous pouvez aussi suivre le cours Introduction to Claude Models et le parcours de compétences OpenAI Fundamentals.
Les meilleurs cours DataCamp
Cursus
Cours
Cours