
Tracks
Những nguyên tắc cơ bản của OpenAI
15 giờ
Vài năm trước, bạn hầu như không thể khiến một mô hình ngôn ngữ lớn viết nổi một email cho ra hồn. Khi OpenAI phát hành mô hình nguồn mở đầu tiên của mình, việc thấy nó tạo ra văn bản mạch lạc thật đáng kinh ngạc. Chỉ sau vài năm, giờ đây chúng ta đã có những mô hình AI có thể xây dựng trọn vẹn các dự án kỹ thuật phần mềm, đặt lịch họp, mua sản phẩm trên Amazon và hơn thế nữa. Đến năm 2026, bức tranh đã thay đổi đáng kể, và câu hỏi các nhà phát triển đặt ra là mẫu nào sẽ phù hợp với các trường hợp sử dụng của họ.
GPT-5.4 và Claude Opus 4.6 đang ở trung tâm của câu hỏi đó. Cả hai đều mạnh theo những cách khác nhau và được ra mắt chỉ cách nhau vài tuần. Tuy nhiên, hai mẫu có mức giá khác nhau và đạt hiệu quả tốt nhất trong những kịch bản khác nhau.
Tuần vừa rồi tôi đã đào sâu vào báo cáo phát hành của họ và các bảng xếp hạng độc lập. Trong bài viết này, tôi sẽ dẫn bạn qua những gì tôi tìm hiểu được để giúp bạn quyết định mẫu tốt nhất cho quy trình làm việc của mình.
Claude Opus 4.6 là mẫu mạnh nhất của Anthropic tính đến nay. Opus 4.6 là bản nâng cấp so với mẫu trước, với những cải tiến quan trọng ở khả năng lập trình và các tác vụ tác nhân dài hơi. Anthropic cho biết nó lập kế hoạch, rà soát mã và gỡ lỗi tốt hơn, thậm chí tự phát hiện lỗi của chính mình.
Anthropic phát hành Opus 4.6 với cửa sổ ngữ cảnh 1M token ở giai đoạn beta, với đầu ra tối đa 128K token. Điều này giúp mẫu có thể làm việc với các codebase lớn và xử lý các tài liệu dung lượng lớn như tài liệu hướng dẫn.
Bản phát hành này cũng giới thiệu Tư duy Thích ứng (Adaptive Thinking), nghĩa là Claude giờ đây có thể tự quyết định khi nào cần tham gia vào quá trình suy nghĩ mở rộng thay vì chờ bạn bật thủ công.
Claude Opus 4.6 có thể quyết định liệu vấn đề chỉ cần sửa nhanh hay cần thêm thời gian để suy luận và lập kế hoạch khắc phục. Tôi nghĩ điều này sẽ rất hữu ích để giải quyết các bài toán kỹ thuật phức tạp. Không có gì bất ngờ khi mẫu này đứng đầu bảng xếp hạng text và coding arena.
Trong các benchmark lập trình, Claude Opus 4.6 đạt 81,42% trên SWE-Bench Verified, bài kiểm tra khả năng giải quyết các issue thực tế trên GitHub. Mẫu này cũng đạt điểm cao nhất ở Humanity’s Last Exam.
Với Opus 4.6, Claude cũng giới thiệu Agent Teams như một tính năng thử nghiệm trong Claude Code. Khi bật lên, bạn có thể khởi tạo nhiều tác nhân cùng xử lý công việc. Các tác nhân phối hợp như một đội, với nhiệm vụ chung và nhắn tin liên tác nhân.
Bạn có thể tìm hiểu cách dùng Claude Code của Anthropic để cải thiện quy trình phát triển phần mềm qua ví dụ thực tế với thư viện Supabase Python trong hướng dẫn Claude Code của chúng tôi.
Claude Opus 4.6 là một mẫu tác nhân rất mạnh. Thực tế, người tạo ra OpenClaw khuyến nghị dùng nó trong OpenClaw vì khó bị đầu độc bằng prompt injection. Điều này giúp mẫu bền vững hơn trước mã độc hại.
Tính năng Agents Teams, dù còn thử nghiệm, là một nâng cấp lớn so với subagent. Với tính năng này, bạn có thể chia nhỏ nhiệm vụ cho nhiều tác nhân Claude. Ví dụ, một tác nhân xử lý backend, một tác nhân xử lý frontend, và một tác nhân chạy kiểm thử. Mỗi tác nhân có cửa sổ ngữ cảnh riêng, từ đó giảm rủi ro thất bại nhiệm vụ do giới hạn ngữ cảnh.
Cladue Opus 4.6 là một mẫu mạnh, nhưng như người ta vẫn nói, chẳng có bữa trưa nào miễn phí. Mẫu này không rẻ để vận hành, đặc biệt nếu bạn là người dùng nặng.
GPT-5.4 là mẫu mới nhất và mạnh nhất của OpenAI. Nó được xây dựng bằng cách kết hợp khả năng lập trình của GPT-5.3-Codex và bổ sung năng lực suy luận để tạo thành một mẫu đơn nhất, mạnh mẽ. Điều này đồng nghĩa bạn không còn cần chuyển đổi giữa các mẫu codex cho lập trình và các mẫu OpenAI khác cho tác vụ khác.
Tính năng tôi thấy thú vị nhất ở GPT-5.4 là khả năng sử dụng máy tính. Trên OSWorld, một benchmark đo lường khả năng dùng máy tính để bàn của mẫu, GPT-5.4 đạt 75,0% trong khi con người đạt 72,4%. Để so sánh, GPT-5.2 đạt 47,3% ở cùng bài kiểm tra.
Trên GDPval, một benchmark kiểm tra công việc tri thức chuyên nghiệp trên 44 ngành nghề, GPT-5.4 đạt 83%. Điều này có nghĩa mẫu có thể thực hiện các tác vụ tác nhân ở những nghề hàng đầu tại Mỹ ở mức độ chuyên nghiệp.
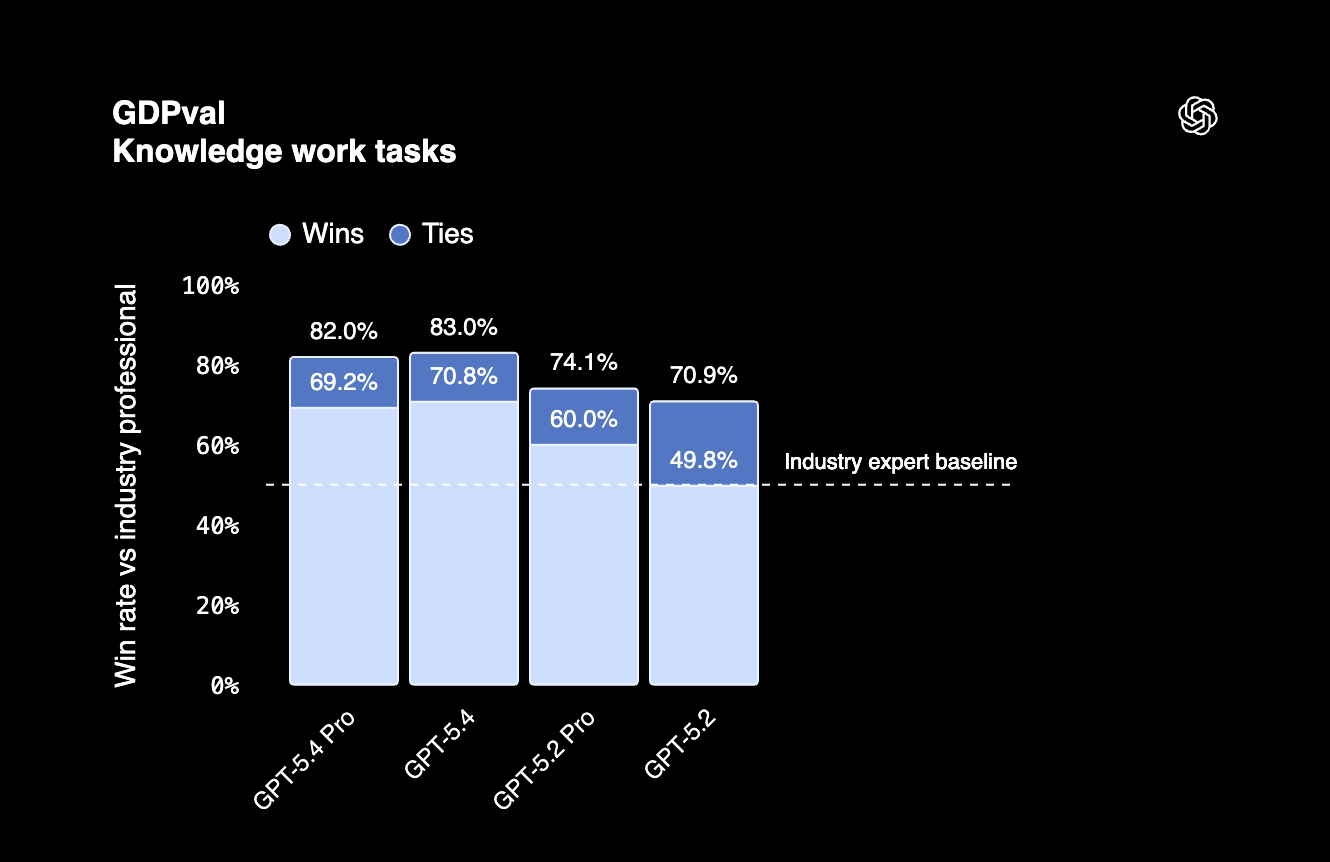
GPT-5.4 cũng có hiệu quả sử dụng token, nghĩa là dùng ít token hơn so với các mẫu trước cho nhiều tác vụ. Đây là điều đáng lưu ý nếu bạn chạy nhiều yêu cầu mỗi ngày.
GPT-5.4 cũng giới thiệu hệ thống Tìm kiếm Công cụ (Tool Search), giúp mẫu hoạt động hiệu quả khi được cung cấp nhiều công cụ. Thay vì đưa định nghĩa công cụ vào prompt, làm tăng số token, giờ đây mẫu được cấp danh sách công cụ và khả năng tìm kiếm công cụ. Khi cần, mẫu sẽ tra cứu và gắn công cụ vào chính cuộc hội thoại đó. Điều này dẫn đến hiệu quả token tốt hơn.
Điểm tôi ấn tượng nhất là khả năng của GPT-5.4 vượt qua con người trong việc sử dụng máy tính tự động. Nó vượt Claude Opus 4.6 ở mảng này, đạt 75% trên benchmark OSWorld, so với mức 72,7% của Opus 4.6.
Nghiên cứu độc lập từ Artificial Analysis cho thấy GPT 5.4 (xhigh) đạt 30% trên benchmark CritPt, bài kiểm tra LLM về các tác vụ suy luận vật lý ở cấp độ nghiên cứu, gồm 71 thách thức nghiên cứu tổng hợp.
GPT-5.4 gọi công cụ tốt hơn và chính xác hơn. Trong báo cáo phát hành, OpenAI lưu ý rằng nó đạt kết quả tốt hơn với ít bước hơn trên Toolathlon, một benchmark kiểm tra cách các tác nhân sử dụng công cụ và API thực tế để hoàn thành các tác vụ nhiều bước.
Giống Claude Opus 4.6, GPT-5.4 cũng không phải mẫu rẻ. May mắn là OpenAI cung cấp mức giá rẻ hơn qua batch inference API.
Giờ bạn đã thấy ưu nhược điểm của GPT-5.4 và Opus 4.6, hãy so sánh để xác định mẫu nào phù hợp nhất với trường hợp sử dụng của bạn.
Nhìn chung, GPT-5.4 là mẫu tốt nhất theo Artificial Analysis Intelligence Index, chỉ số đo lường hiệu suất của các mẫu qua nhiều benchmark. Mẫu duy nhất vượt nó là Gemini 3.1 Pro.
Claude Opus 4.6 thắng về điều phối đa tác nhân. Với tính năng Agent Teams, bạn có thể chạy nhiều quy trình với các tác nhân song song xử lý những nhiệm vụ khác nhau.
GPT-5.4 nhỉnh hơn một chút ở khả năng sử dụng máy tính. Nếu tác nhân của bạn cần vận hành máy tính để bàn, điều hướng trình duyệt hoặc tương tác với phần mềm giao diện đồ họa, GPT-5.4 hiện là lựa chọn tốt hơn
Claude Opus 4.6 là lập trình viên tốt hơn với điểm 80,84% trên SWE-Bench Verified và 81,4% khi dùng prompt đã chỉnh sửa.
GPT-5.4 thừa hưởng khả năng lập trình của GPT-5.3-Codex. Theo OpenAI, GPT-5.4 đạt 57,7% trên SWE-Bench Pro (Public) với độ trễ thấp hơn ở các tác vụ suy luận.
Trong báo cáo, OpenAI cho biết GPT-5.4 giảm 47% mức sử dụng token ở một số tác vụ. Dù đắt hơn Opus 4.6, GPT-5.4 có thể rẻ hơn khi vận hành ở quy mô lớn nhờ mức giảm token này.
Tuy nhiên, Opus 4.6 vẫn có thể là mẫu tốt hơn để chạy ít nhưng tác vụ tác nhân phức tạp.
Để tham chiếu, mẫu GPT-5.4 mạnh nhất (độ dài ngữ cảnh >272K) có giá 60 đô cho 1M token đầu vào và 270 đô cho 1M token đầu ra, trong khi Claude Opus 4.6 có giá 5 đô cho 1M token đầu vào và 25 đô cho 1M token đầu ra.
Cả GPT-5.4 và Claude Opus 4.6 đều hỗ trợ tới 1M token ngữ cảnh, dù của Claude đang ở giai đoạn beta. Điều này khiến cả hai trở thành đối thủ nặng ký khi làm việc với các codebase lớn.
|
Danh mục |
Claude Opus 4.6 |
GPT-5.4 |
|
Tác vụ tác nhân |
Mạnh (Agent Teams, điều phối song song) |
Mạnh (sử dụng máy tính, OSWorld 75%) |
|
Benchmark lập trình |
SWE-Bench 80,2% với Thinking |
57,7% trên SWE-Bench Pro (Public) |
|
Sử dụng máy tính |
72,7% trên OSWorld |
OSWorld 75% (vượt chuyên gia con người) |
|
Cửa sổ ngữ cảnh |
1M token (beta), đầu ra tối đa 128K |
1M token |
|
Công việc tri thức |
Dẫn đầu Humanity's Last Exam |
GDPval 83% |
|
Giá (đầu vào/đầu ra) |
5 đô cho Base Input Tokens 25 đô cho mỗi triệu Output Tokens |
gpt-5.4 (<272K độ dài ngữ cảnh) có giá 2,50 đô cho 1M token đầu vào và 15,00 đô cho 1M token đầu ra. Các mẫu với cửa sổ ngữ cảnh lớn hơn sẽ đắt hơn. |
|
Hiệu quả token |
Tiêu chuẩn |
Ít hơn 47% token ở một số tác vụ |
|
Phù hợp nhất cho |
Tác nhân chạy dài hạn, codebase phức tạp |
Sử dụng máy tính, quy trình tài liệu, doanh nghiệp |
Kết lại, hãy trả lời câu hỏi quan trọng nhất: bạn nên chọn mẫu nào trong hai mẫu này?
Các mẫu của Anthropic từ lâu đã là lựa chọn hàng đầu cho lập trình, nhưng chúng cũng tỏa sáng ở những lĩnh vực bất ngờ như sáng tác. Thực tế, nhiều người cho rằng họ là tốt nhất trong ngành ở mảng này.
Nhưng Anthropic chưa bao giờ công khai tuyên bố rằng các mẫu của họ chuyên biệt cho bất kỳ tác vụ cụ thể nào, như cách OpenAI từng nêu rằng mẫu Codex được thiết kế riêng cho lập trình.
Tôi thấy cực kỳ thú vị khi OpenAI hiện đang dịch chuyển theo hướng của Anthropic. Với các bản phát hành mới nhất, họ đang hướng tới một mẫu thống nhất duy nhất có thể xử lý lượng lớn tác vụ chuyên nghiệp. Đây là một thắng lợi lớn cho người dùng; không ai muốn liên tục chuyển giữa các mẫu chuyên biệt để hoàn thành công việc.
Mặt khác, thật tốt khi thấy Anthropic chấp nhận cửa sổ ngữ cảnh 1M, thứ mà các mẫu khác đã có từ lâu (như Gemini 3). Tôi nghĩ trong tương lai, các mẫu sẽ có tính năng rất giống nhau, đến mức các yếu tố quyết định đối với người dùng sẽ rất ít. Dù vậy, hiệu suất của mẫu trên các tác vụ khác nhau sẽ là điểm khác biệt chính, vì người dùng sẽ ưu tiên những mẫu làm tốt quy trình cụ thể của họ.
Năm 2026, cả Anthropic và OpenAI đều có những mẫu mạnh cho công việc tác nhân. Điều có thể khiến bạn bối rối là họ báo cáo các benchmark khác nhau, có lẽ là chọn lọc những nơi mẫu của họ tỏa sáng.
Giờ là lúc bạn tham khảo các phân tích độc lập cho những benchmark khác và tự kiểm thử trên trường hợp sử dụng của mình. Điều rõ ràng là các mẫu đang ngày càng tốt hơn. Và bạn cũng nên trở nên thành thạo hơn trong việc sử dụng chúng.
Một cách để không bị bỏ lại phía sau bởi làn sóng tác nhân này là thành thạo cách sử dụng hiệu quả các mẫu cho kỹ nghệ phần mềm. Tôi khuyến nghị bạn bắt đầu bằng cách đăng ký khóa Software Development with Cursor miễn phí của chúng tôi. Bạn cũng có thể học khóa Introduction to Claude Models và lộ trình kỹ năng OpenAI Fundamentals.
Các khóa học hàng đầu trên DataCamp
Tracks
Courses
Courses