
Programma
Fondamenti di OpenAI
15 h
Fino a pochi anni fa, era già tanto se un grande modello linguistico riusciva a scrivere un'email decente. Quando OpenAI rilasciò il suo primo modello open source, fu sorprendente vederlo generare testo coerente. Solo qualche anno dopo, oggi abbiamo modelli di AI che possono realizzare interi progetti di ingegneria del software, fissare appuntamenti, acquistare prodotti su Amazon e altro ancora. Nel 2026, lo scenario è davvero cambiato, e la domanda che si pongono gli sviluppatori è quale modello funzioni meglio per i loro casi d'uso.
GPT-5.4 e Claude Opus 4.6 sono ora al centro di questa domanda. Entrambi sono capaci, ma in modi diversi, e sono stati lanciati a poche settimane di distanza. Tuttavia, i due modelli hanno prezzi differenti e rendono al meglio in scenari diversi.
Negli ultimi giorni ho analizzato i report di rilascio e le leaderboard indipendenti. In questo articolo, ti guiderò attraverso ciò che ho scoperto per aiutarti a scegliere il modello migliore per il tuo workflow.
Claude Opus 4.6 è il modello più capace di Anthropic fino a oggi. Opus 4.6 migliora il modello precedente, con progressi chiave nel coding e nei task agentici di lunga durata. Anthropic afferma che pianifica, fa code review e debugging meglio, arrivando persino a individuare i propri errori.
Anthropic ha rilasciato Opus 4.6 con una finestra di contesto da 1M di token in beta, con un output massimo di 128K token. Questo rende il modello in grado di lavorare su grandi codebase e di elaborare documenti voluminosi, come la documentazione.
Questo rilascio introduce anche il ragionamento adattivo (Adaptive Thinking), ossia Claude ora può decidere quando attivare un pensiero esteso invece di aspettare che tu lo abiliti manualmente.
Claude Opus 4.6 può valutare se qualcosa richiede una correzione rapida o merita più tempo per ragionare e formulare un piano. Penso che questo sarà molto utile per risolvere problemi ingegneristici complessi. Non sorprende che il modello sia in cima alla leaderboard di text e coding arena.
Nei benchmark di programmazione, Claude Opus 4.6 ottiene l'81,42% su SWE-Bench Verified, che valuta quanto un modello sia capace di risolvere problemi reali su GitHub. Il modello ha anche ottenuto il miglior punteggio in Humanity’s Last Exam.
Con Opus 4.6, Claude ha anche introdotto le Agent Teams come funzionalità sperimentale in Claude Code. Quando le attivi, puoi avviare più agenti per lavorare sui task. Gli agenti collaborano come una squadra, con attività condivise e messaggistica inter-agente.
Puoi imparare a usare Claude Code di Anthropic per migliorare i workflow di sviluppo software con un esempio pratico che usa la libreria Supabase in Python nella nostra guida a Claude Code.
Claude Opus 4.6 è un modello agentico molto solido. Infatti, il creatore di OpenClaw consiglia di usarlo in OpenClaw perché è difficile da avvelenare con prompt injection. Questo rende il modello più robusto contro codice malevolo.
La funzione Agents Teams, sebbene ancora sperimentale, è un enorme passo avanti rispetto ai subagent. Con questa feature, puoi suddividere il tuo task tra più agenti Claude. Per esempio, uno può gestire il backend, un altro il frontend e un altro ancora eseguire i test. Ogni agente ha la propria finestra di contesto, riducendo così il rischio di fallimento del task dovuto a limiti di contesto.
Cladue Opus 4.6 è un modello potente, ma, come si suol dire, non esistono pranzi gratis. Non è economico da far girare, soprattutto se ne fai un uso intensivo.
GPT-5.4 è il modello più recente e più capace di OpenAI. È stato costruito combinando le capacità di coding di GPT-5.3-Codex e aggiungendo il ragionamento per creare un unico modello potente. Questo significa che non devi più passare tra i modelli Codex per il coding e altri modelli OpenAI per il resto.
La funzionalità che ho trovato più interessante in GPT-5.4 è l'uso del computer. Su OSWorld, un benchmark che misura la capacità di un modello di usare un computer desktop, GPT-5.4 ha ottenuto il 75,0% contro il 72,4% delle prestazioni umane. Per contesto, GPT-5.2 aveva ottenuto il 47,3% nello stesso test.
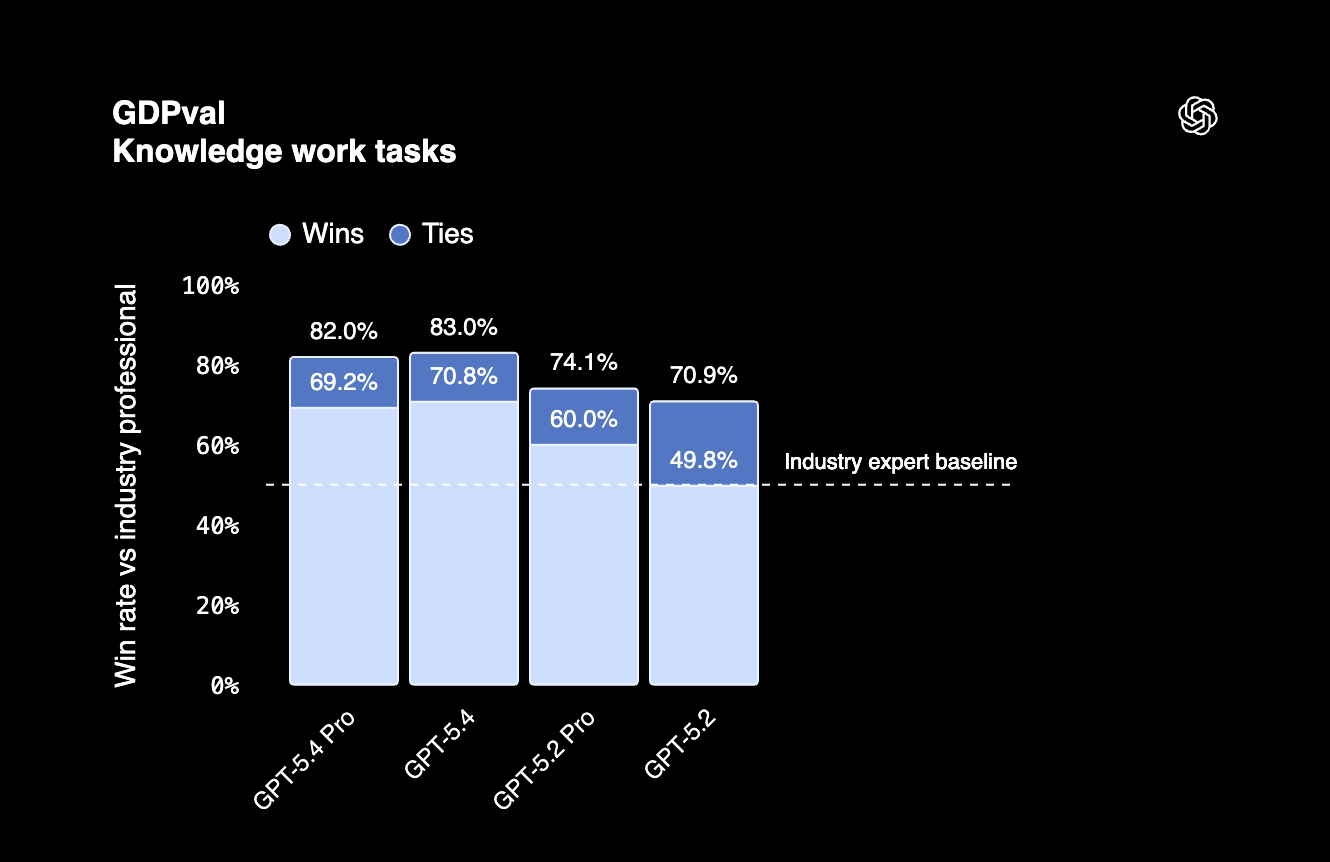
Su GDPval, un benchmark che testa il lavoro di conoscenza professionale in 44 professioni, GPT-5.4 ha ottenuto l'83%. Significa che il modello può svolgere task agentici nei principali lavori statunitensi a livello professionale.
GPT-5.4 offre anche efficienza nell'uso dei token, cioè utilizza meno token rispetto ai modelli precedenti per molti task. È un aspetto da considerare se esegui molte richieste al giorno.
GPT-5.4 introduce anche un sistema di Tool Search, che rende il modello efficiente quando gli vengono forniti più tool. Invece di includere la definizione dello strumento nel prompt, aumentando i token, al modello viene fornito un elenco di tool e una capacità di ricerca degli strumenti. Quando ha bisogno di un tool, lo cerca e lo aggiunge a quella specifica conversazione. Questo porta a una migliore efficienza dei token.
La caratteristica più impressionante, secondo me, è la capacità di GPT-5.4 di superare gli esseri umani nell'uso autonomo del computer. Batte Claude Opus 4.6 in quest'area, con un 75% nei benchmark OSWorld, rispetto al 72,7% di Opus 4.6.
Ricerche indipendenti di Artificial Analysis mostrano che GPT 5.4 (xhigh) ottiene un punteggio del 30% sul benchmark CritPt, che testa gli LLM su task di ragionamento in fisica a livello di ricerca, con 71 sfide composite.
GPT-5.4 è migliore e più accurato nelle chiamate agli strumenti. Nel report di rilascio, OpenAI segnala risultati migliori in meno passaggi su Toolathlon, un benchmark che testa come gli agent utilizzano strumenti e API reali per completare task multi-step.
Come Claude Opus 4.6, anche GPT-5.4 non è un modello economico. Per fortuna, OpenAI offre prezzi più bassi con la batch inference API.
Ora che hai visto pro e contro di GPT-5.4 e Opus 4.6, confrontiamoli per capire quale sia il migliore per i tuoi casi d'uso.
Nel complesso, GPT-5.4 è il modello migliore secondo l'Artificial Analysis Intelligence Index, che misura le prestazioni dei modelli su vari benchmark. L'unico a superarlo è Gemini 3.1 Pro.
Claude Opus 4.6 vince nella orchestrazione multi-agente. Con la funzione Agent Teams, puoi eseguire più workflow con agenti paralleli su task differenti.
GPT-5.4 vince di poco nell'uso del computer. Se il tuo agente deve usare un desktop, navigare un browser o interagire con software basati su GUI, al momento GPT-5.4 è la scelta migliore
Claude Opus 4.6 è il programmatore migliore, con un punteggio dell'80,84% su SWE-Bench Verified e dell'81,4% usando un prompt modificato.
GPT-5.4 eredita le capacità di coding di GPT-5.3-Codex. Secondo OpenAI, GPT-5.4 ottiene il 57,7% su SWE-Bench Pro (Public) con minore latenza nei task di ragionamento.
Nel loro report, OpenAI afferma che GPT-5.4 ha dimostrato una riduzione del 47% dell'uso di token in alcuni task. Pur essendo più costoso di Opus 4.6, GPT-5.4 potrebbe essere più economico da usare su larga scala grazie a questa riduzione.
Tuttavia, Opus 4.6 potrebbe restare il modello migliore per eseguire task agentici meno frequenti ma complessi.
Per contesto, il modello GPT-5.4 più potente (lunghezza del contesto >272K) costa 60$ per 1M di token in input e 270$ per 1M di token in output, mentre Claude Opus 4.6 costa 5$ per 1M di token in input e 25$ per 1M di token in output.
Sia GPT-5.4 che Claude Opus 4.6 supportano fino a 1M di token di contesto, anche se quello di Claude è in beta. Questo rende entrambi i modelli forti concorrenti per lavorare su grandi codebase.
|
Categoria |
Claude Opus 4.6 |
GPT-5.4 |
|
Task agentici |
Solido (Agent Teams, orchestrazione parallela) |
Solido (uso del computer, OSWorld 75%) |
|
Benchmark di coding |
SWE-Bench 80,2% con Thinking |
57,7% su SWE-Bench Pro (Public) |
|
Uso del computer |
72,7% su OSWorld |
OSWorld 75% (supera gli esperti umani) |
|
Finestra di contesto |
1M token (beta), 128K output max |
1M token |
|
Knowledge work |
Leader in Humanity's Last Exam |
GDPval 83% |
|
Prezzi (input/output) |
$5 Base Input Tokens $25 Output Tokens per milione di token |
gpt-5.4 (<272K di lunghezza del contesto) costa $2,50 per 1M di token in input e $15,00 per 1M di token in output. I modelli con una finestra di contesto più ampia costano di più. |
|
Efficienza dei token |
Standard |
47% di token in meno in alcuni task |
|
Ideale per |
Agenti di lunga durata, codebase complesse |
Uso del computer, workflow su documenti, enterprise |
Per concludere, rispondiamo alla domanda più importante: quale dei due dovresti scegliere?
I modelli di Anthropic sono da tempo il punto di riferimento per il coding, ma brillano anche in aree inaspettate come la scrittura creativa. Anzi, molti sostengono che siano i migliori in assoluto in questo ambito.
Tuttavia, Anthropic non ha mai dichiarato pubblicamente che i suoi modelli siano specializzati in task specifici, come invece OpenAI aveva affermato per il modello Codex dedicato alla programmazione.
Trovo estremamente interessante che OpenAI stia ora muovendosi nella direzione di Anthropic. Con gli ultimi rilasci, sta puntando verso un modello unico e unificato che gestisce un'ampia varietà di task professionali. È una grande vittoria per gli utenti: nessuno vuole cambiare continuamente modello specialistico per portare a termine il lavoro.
D'altra parte, è positivo vedere Anthropic abbracciare la finestra di contesto da 1M, che altri modelli hanno da tempo (come Gemini 3). Penso che in futuro questi modelli avranno funzionalità molto simili, al punto che ci saranno pochissimi elementi davvero decisivi per gli utenti. Detto ciò, le prestazioni del modello sui diversi task resteranno il principale elemento di differenziazione, perché gli utenti preferiranno i modelli che funzionano meglio sui loro workflow specifici.
Nel 2026, Anthropic e OpenAI hanno entrambi modelli forti per il lavoro agentico. Ciò che può confonderti è che riportano benchmark diversi, probabilmente selezionando quelli in cui i loro modelli brillano.
Sta a te fare riferimento ad analisi indipendenti per altri benchmark e testarli sui tuoi casi d'uso. Quello che è chiaro, però, è che i modelli stanno migliorando. E anche tu dovresti migliorare nel modo di usarli.
Un modo per non restare indietro in questo movimento agentico è imparare a usare efficacemente questi modelli per l'ingegneria del software. Ti consiglio di iniziare iscrivendoti gratuitamente al nostro corso Software Development with Cursor. Puoi anche seguire il corso Introduction to Claude Models e la skill track OpenAI Fundamentals.
I migliori corsi DataCamp
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

