
Lernpfad
OpenAI Grundlagen
15 Std.
Vor ein paar Jahren war es schon schwierig, ein großes Sprachmodell dazu zu bringen, eine halbwegs gute E-Mail zu schreiben. Als OpenAI sein erstes Open-Source-Modell veröffentlichte, war es beeindruckend, kohärenten Text zu sehen. Nur wenige Jahre später haben wir KI-Modelle, die komplette Softwareprojekte umsetzen, Termine buchen, Produkte auf Amazon kaufen und mehr. 2026 hat sich die Landschaft grundlegend verändert – und Entwicklerinnen und Entwickler fragen sich vor allem: Welches Modell passt zu meinen Use Cases?
GPT-5.4 und Claude Opus 4.6 stehen dabei im Mittelpunkt. Beide sind auf ihre Weise stark und nur wenige Wochen auseinander veröffentlicht worden. Allerdings unterscheiden sie sich im Preis und spielen ihre Stärken in unterschiedlichen Szenarien aus.
Ich habe in der letzten Woche ihre Release-Reports und unabhängige Leaderboards analysiert. In diesem Artikel zeige ich dir, was ich herausgefunden habe – damit du das beste Modell für deinen Workflow wählen kannst.
Claude Opus 4.6 ist bisher das leistungsfähigste Modell von Anthropic. Opus 4.6 baut auf dem Vorgänger auf – mit spürbaren Verbesserungen beim Programmieren und bei langlaufenden agentischen Aufgaben. Anthropic betont bessere Fähigkeiten in Planung, Code-Review und Debugging – inklusive dem Erkennen eigener Fehler.
Anthropic hat Opus 4.6 mit einem Kontextfenster von 1 Mio. Tokens in der Beta veröffentlicht, bei maximal 128K Tokens Ausgabeverlängerung. Damit kann das Modell mit großen Codebasen arbeiten und sehr umfangreiche Dokumente verarbeiten, etwa Dokumentationen.
Das Release bringt außerdem Adaptive Thinking mit: Claude entscheidet nun selbst, wann erweiterte Denkprozesse nötig sind – statt darauf zu warten, dass du sie manuell aktivierst.
Claude Opus 4.6 kann also einschätzen, ob ein schneller Fix reicht oder mehr Zeit zum Nachdenken und Planen sinnvoll ist. Das wird bei komplexen Engineering-Problemen sehr hilfreich sein. Wenig überraschend liegt das Modell an der Spitze des Text- und Coding-Arena-Leaderboards.
In Coding-Benchmarks erzielt Claude Opus 4.6 81,42% auf SWE-Bench Verified, das misst, wie gut ein Modell reale GitHub-Issues löst. Außerdem erreichte das Modell Spitzenwerte bei Humanity’s Last Exam.
Mit Opus 4.6 führt Claude zudem Agent Teams als experimentelles Feature in Claude Code ein. Aktiviert kannst du mehrere Agenten für Aufgaben hochfahren. Die Agenten arbeiten als Team zusammen – mit geteilten Tasks und Inter-Agent-Kommunikation.
Du kannst in unserem Claude Code Tutorial lernen, wie du Anthropic’s Claude Code mit der Supabase-Python-Bibliothek praktisch einsetzt, um Softwareentwicklungs-Workflows zu verbessern.
Claude Opus 4.6 ist ein sehr starkes agentisches Modell. Der Entwickler von OpenClaw empfiehlt es explizit für OpenClaw, weil es sich schwer durch Prompt-Injections vergiften lässt. Das macht das Modell robuster gegenüber bösartigem Code.
Die Agent-Teams, auch wenn noch experimentell, sind ein großer Sprung gegenüber Subagenten. Damit kannst du Aufgaben auf mehrere Claude-Agenten aufteilen – zum Beispiel Backend, Frontend und Testing. Jeder Agent hat sein eigenes Kontextfenster, was das Risiko von Fehlschlägen durch Kontextlimits reduziert.
Claude Opus 4.6 ist stark – aber wie man so sagt: Nichts ist umsonst. Das Modell ist nicht günstig im Betrieb, besonders bei hoher Nutzung.
Inzwischen hat Anthropic sein Nachfolgemodell veröffentlicht. Schau dir auch unseren Guide zu Claude Opus 4.7 an!
GPT-5.4 ist OpenAIs aktuellstes und leistungsfähigstes Modell. Es kombiniert die Coding-Fähigkeiten von GPT-5.3-Codex mit erweitertem Reasoning zu einem einzigen, starken Modell. Du musst also nicht mehr zwischen Codex-Modellen fürs Programmieren und anderen OpenAI-Modellen für übrige Aufgaben wechseln.
Am spannendsten finde ich die Computer-Use-Fähigkeiten. Auf OSWorld, einem Benchmark für die Desktop-Nutzung, erreicht GPT-5.4 75,0% – der Mensch liegt bei 72,4%. Zum Vergleich: GPT-5.2 kam im selben Test auf 47,3%.
Auf GDPval, einem Benchmark für wissensbasierte Arbeit in 44 Berufen, erzielt GPT-5.4 83%. Heißt: Das Modell bewältigt agentische Aufgaben in Top-US-Berufen auf Profi-Niveau.
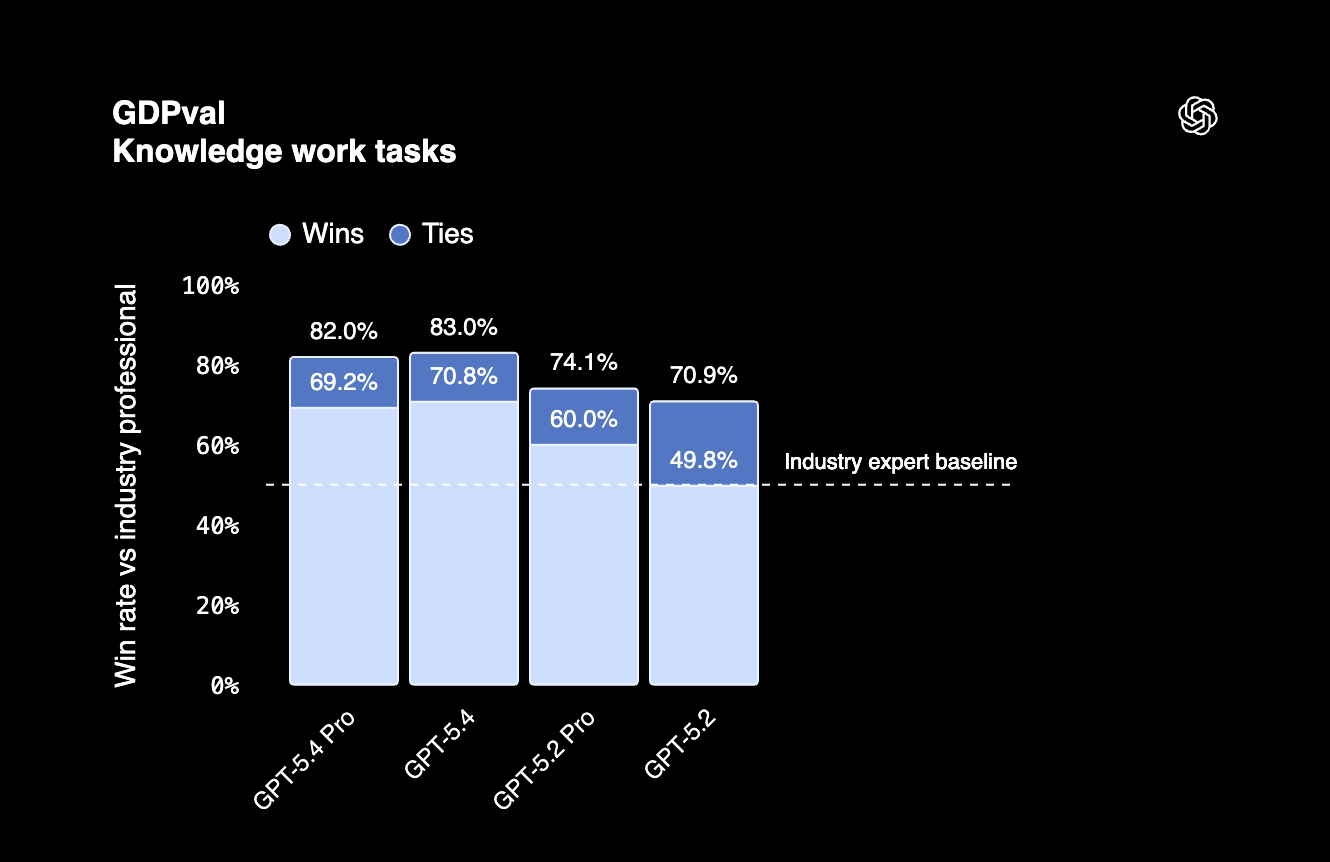
GPT-5.4 zeichnet sich zudem durch Token-Effizienz aus, nutzt also für viele Aufgaben weniger Tokens als Vorgängermodelle. Wichtig, wenn du täglich viele Requests fährst.
Außerdem führt GPT-5.4 ein Tool-Search-System ein, das den Einsatz mehrerer Tools effizienter macht. Anstatt Tool-Definitionen in jeden Prompt zu stopfen (und Tokens zu verbrauchen), bekommt das Modell eine Liste mit Tools plus Suchfunktion. Benötigt es ein Tool, schaut es nach und hängt es der Konversation an. Ergebnis: bessere Token-Effizienz.
Am meisten beeindruckt mich, dass GPT-5.4 Menschen bei der autonomen Computernutzung schlägt. Es liegt vor Claude Opus 4.6 – mit 75% auf OSWorld gegenüber 72,7% bei Opus 4.6.
Unabhängige Forschung von Artificial Analysis zeigt, dass GPT‑5.4 (xhigh) auf dem CritPt-Benchmark 30% erreicht – dieser testet LLMs auf Forschungsniveau in Physik mit 71 zusammengesetzten Herausforderungen.
GPT-5.4 ist außerdem besser und genauer beim Tool-Calling. Laut Release-Report erzielt es auf Toolathlon, einem Benchmark zur Nutzung realer Tools und APIs in Multi-Step-Aufgaben, bessere Ergebnisse in weniger Schritten.
Wie Claude Opus 4.6 ist auch GPT-5.4 kein günstiges Modell. OpenAI bietet jedoch günstigere Preise über die Batch-Inference-API.
Nachdem du die Vor- und Nachteile gesehen hast, vergleichen wir die Modelle, um herauszufinden, welches besser zu deinen Use Cases passt.
Insgesamt ist GPT-5.4 laut dem Artificial Analysis Intelligence Index das beste Modell – gemessen über verschiedene Benchmarks. Geschlagen wird es nur von Gemini 3.1 Pro.
Bei Multi-Agent-Orchestrierung hat Claude Opus 4.6 die Nase vorn. Dank Agent Teams kannst du parallele Workflows mit spezialisierten Agenten fahren.
In der Computernutzung gewinnt GPT-5.4 knapp. Muss dein Agent einen Desktop bedienen, durch den Browser navigieren oder mit GUI-Software interagieren, ist GPT-5.4 aktuell die bessere Wahl.
Claude Opus 4.6 ist der bessere Programmierer mit 80,84% auf SWE-Bench Verified und 81,4% mit modifiziertem Prompt.
GPT-5.4 übernimmt die Coding-Fähigkeiten von GPT-5.3-Codex. Laut OpenAI erreicht GPT-5.4 57,7% auf SWE-Bench Pro (Public) – bei geringerer Latenz in Reasoning-Aufgaben.
OpenAI berichtet für GPT-5.4 eine um 47% reduzierte Token-Nutzung bei bestimmten Aufgaben. Obwohl teurer als Opus 4.6, kann GPT-5.4 im großen Maßstab durch diese Einsparung günstiger laufen.
Opus 4.6 kann jedoch die bessere Wahl sein, wenn du wenige, aber sehr komplexe agentische Aufgaben betreibst.
Zur Einordnung: Das stärkste GPT-5.4-Modell (Kontextlänge >272K) kostet $60 pro 1 Mio. Input-Tokens und $270 pro 1 Mio. Output-Tokens, während Claude Opus 4.6 $5 pro 1 Mio. Input-Tokens und $25 pro 1 Mio. Output-Tokens kostet.
Sowohl GPT-5.4 als auch Claude Opus 4.6 unterstützen bis zu 1 Mio. Tokens Kontext, wobei Claude derzeit in Beta ist. Beide sind damit stark für große Codebasen geeignet.
|
Kategorie |
Claude Opus 4.6 |
GPT-5.4 |
|
Agentische Aufgaben |
Stark (Agent Teams, parallele Orchestrierung) |
Stark (Computernutzung, OSWorld 75%) |
|
Coding-Benchmark |
SWE-Bench 80,2% mit Thinking |
57,7% auf SWE-Bench Pro (Public) |
|
Computernutzung |
72,7% auf OSWorld |
OSWorld 75% (schlägt menschliche Expertinnen/Experten) |
|
Kontextfenster |
1 Mio. Tokens (Beta), 128K max. Output |
1 Mio. Tokens |
|
Wissensarbeit |
Leader bei Humanity’s Last Exam |
GDPval 83% |
|
Preise (Input/Output) |
$5 Basis-Input-Tokens $25 Output-Tokens pro 1 Mio. Tokens |
gpt-5.4 (<272K Kontextlänge) kostet $2,50 pro 1 Mio. Input-Tokens und $15,00 pro 1 Mio. Output-Tokens. Modelle mit größerem Kontextfenster sind teurer. |
|
Token-Effizienz |
Standard |
47% weniger Tokens bei manchen Aufgaben |
|
Am besten geeignet für |
Langlaufende Agenten, komplexe Codebasen |
Computernutzung, Doku-Workflows, Enterprise |
Zum Schluss die wichtigste Frage: Für welches der beiden Modelle solltest du dich entscheiden?
Anthropics Modelle waren lange die erste Wahl fürs Programmieren, glänzen aber ebenso überraschend im kreativen Schreiben. Viele würden sogar sagen: die absolut Besten der Branche.
Anthropic hat jedoch nie öffentlich behauptet, dass ihre Modelle für spezifische Aufgaben spezialisiert sind – anders als OpenAI damals mit Codex fürs Programmieren.
Spannend ist, dass OpenAI sich nun in Richtung Anthropic bewegt. Mit den neuesten Releases drängt OpenAI zu einem einheitlichen Modell, das eine enorme Bandbreite professioneller Aufgaben abdeckt. Ein großer Gewinn für Nutzerinnen und Nutzer – niemand will ständig zwischen Spezialmodellen wechseln, um Arbeit zu erledigen.
Auf der anderen Seite ist es gut zu sehen, dass Anthropic das 1M-Kontextfenster übernimmt, das andere Modelle (wie Gemini 3) schon länger haben. Ich denke, künftig werden die Modelle sehr ähnliche Features bieten – echte Dealbreaker werden selten. Der entscheidende Unterschied wird die Performance in konkreten Aufgaben bleiben, denn Teams bevorzugen Modelle, die in ihren speziellen Workflows überzeugen.
2026 haben Anthropic und OpenAI beide starke Modelle für agentische Arbeit. Verwirrend ist, dass sie verschiedene Benchmarks highlighten – vermutlich dort, wo ihre Modelle besonders glänzen.
Du solltest daher unabhängige Analysen heranziehen und vor allem eigene Tests für deine Use Cases machen. Klar ist: Die Modelle werden besser. Und du solltest besser darin werden, sie effektiv zu nutzen.
Eine Möglichkeit, beim agentischen Wandel nicht den Anschluss zu verlieren, ist, diese Modelle gezielt für Software Engineering zu meistern. Starte am besten mit unserem kostenlosen Kurs Software Development with Cursor. Außerdem empfehlen wir den Kurs Introduction to Claude Models sowie den OpenAI Fundamentals Skill Track.
Top-DataCamp-Kurse
Lernpfad
Kurs
Kurs
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Blog
Nisha Arya Ahmed
15 Min.
Tutorial
Matt Crabtree