
Program
OpenAI Temelleri
15 sa
Birkaç yıl önce, büyük dil modellerinden düzgün bir e-posta yazmalarını istemek bile zordu. OpenAI ilk açık kaynak modelini çıkardığında, tutarlı metin üretmesini görmek şaşırtıcıydı. Aradan sadece birkaç yıl geçti ve artık tam ölçekli yazılım projeleri inşa edebilen, toplantı ayarlayabilen, Amazon’dan ürün satın alabilen ve daha fazlasını yapabilen yapay zeka modellerine sahibiz. 2026’da tablo gerçekten değişti ve geliştiricilerin sorduğu soru şu: Hangi model bizim kullanım senaryolarımız için en iyi çalışacak?
GPT-5.4 ve Claude Opus 4.6 artık bu sorunun merkezinde. İkisi de farklı açılardan yetenekli ve her ikisi de birkaç hafta arayla piyasaya sürüldü. Ancak, iki modelin fiyatları farklı ve en iyi performansı farklı senaryolarda veriyorlar.
Geçtiğimiz hafta boyunca sürüm raporlarını ve bağımsız lider tablolarını derinlemesine inceledim. Bu yazıda, iş akışınız için en iyi modeli seçmenize yardımcı olmak üzere bulgularımı paylaşacağım.
Claude Opus 4.6, Anthropic’in bugüne kadarki en yetenekli modeli. Opus 4.6, özellikle kodlama ve uzun süreli vekil görevlerde önemli iyileştirmeler sunan önceki modelin geliştirilmiş bir sürümü. Anthropic, modelin planlama, kod inceleme ve hata ayıklamada daha iyi performans gösterdiğini, hatta kendi hatalarını yakalayabildiğini söylüyor.
Anthropic, Opus 4.6’yı beta aşamasında 1M token bağlam penceresi ve 128K token maksimum çıktı ile yayınladı. Bu sayede model, büyük kod tabanlarında çalışabilme ve dokümantasyon gibi büyük belgeleri işleyebilme kapasitesine sahip.
Bu sürüm ayrıca Uyarlanabilir Düşünme özelliğini getiriyor; bu, Claude’un artık uzatılmış düşünmeyi ne zaman devreye alacağına kendisinin karar verebildiği anlamına geliyor; manuel olarak açmanızı beklemiyor.
Claude Opus 4.6, bir şeyin hızlı bir düzeltme gerektirip gerektirmediğine ya da üzerinde daha fazla düşünülüp bir çözüm planı oluşturulmasına değip değmediğine karar verebiliyor. Bunun karmaşık mühendislik problemlerini çözmede çok faydalı olacağını düşünüyorum. Modelin metin ve kodlama arena lider tablosunun zirvesinde olması şaşırtıcı değil.
Kodlama kıyaslamalarında, Claude Opus 4.6, gerçek GitHub sorunlarını çözme becerisini test eden SWE-Bench Verified’da %81,42 puan alıyor. Model ayrıca Humanity’s Last Exam’de en iyi skoru elde etti.
Opus 4.6 ile Claude, Claude Code içinde deneysel bir özellik olarak Ajan Takımlarını da tanıttı. Bu özelliği açtığınızda, görevler üzerinde çalışacak birden fazla ajan başlatabilirsiniz. Ajanlar, paylaşılan görevler ve ajanlar arası mesajlaşma ile bir ekip olarak birlikte çalışırlar.
Şuradaki örnek üzerinden Anthropic'in Claude Code aracını kullanarak yazılım geliştirme iş akışlarını nasıl iyileştirebileceğinizi Claude Code eğitimimizden öğrenebilirsiniz; örnekte Supabase Python kütüphanesi kullanılıyor.
Claude Opus 4.6 çok güçlü bir vekil model. Nitekim OpenClaw’un geliştiricisi, istem enjeksiyonlarıyla zehirlemenin zor olması nedeniyle OpenClaw’da bunu kullanmayı öneriyor. Bu da modeli kötü niyetli koda karşı daha dayanıklı kılıyor.
Ajan Takımları özelliği henüz deneysel olsa da alt ajanlara kıyasla büyük bir sıçrama. Bu özellikle görevinizi birden fazla Claude ajanına bölebilirsiniz. Örneğin biri backend’i, biri frontend’i ele alabilir, bir diğeri testleri çalıştırabilir. Her ajanın kendi bağlam penceresi vardır; böylece bağlam penceresi sınırlamaları nedeniyle görev başarısızlığı riski azalır.
Claude Opus 4.6 güçlü bir model, ancak bilindiği gibi bedavaya öğle yemeği yok. Bu modeli çalıştırmak ucuz değil; özellikle yoğun kullanımda maliyetli olabilir.
GPT-5.4, OpenAI’nin en yeni ve en yetenekli modeli. GPT-5.3-Codex’in kodlama yetenekleri, geliştirilmiş akıl yürütme ile birleştirilerek tek ve güçlü bir model oluşturuldu. Bu da kodlama için codex modelleriyle, diğer görevler için farklı OpenAI modelleri arasında geçiş yapma ihtiyacını ortadan kaldırıyor.
GPT-5.4’te en ilginç bulduğum özellik, bilgisayar kullanma yetenekleri. Bir modelin masaüstü bilgisayarı kullanma becerisini ölçen OSWorld kıyaslamasında GPT-5.4 %75,0 puan alırken, insan performansı %72,4. Karşılaştırma için: GPT-5.2 aynı testte %47,3 puan almıştı.
44 meslek genelinde profesyonel bilgi işini test eden bir kıyaslama olan GDPval’de GPT-5.4 %83 puan aldı. Bu, modelin ABD’deki önde gelen mesleklerde profesyonel düzeyde vekil görevler yürütebildiği anlamına geliyor.
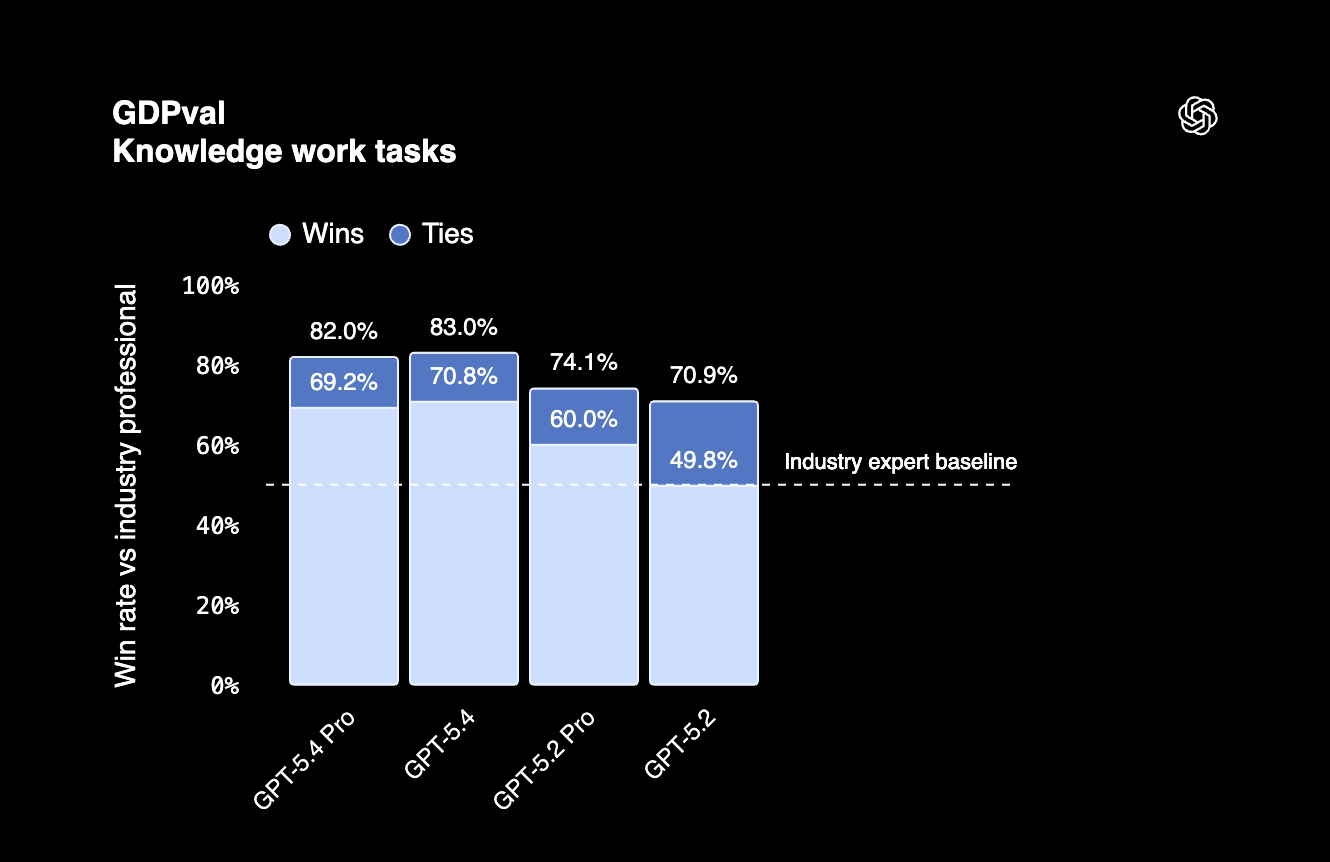
GPT-5.4 ayrıca belirli görevlerde önceki modellere kıyasla daha az token kullandığı anlamına gelen token verimliliği sunuyor. Günde birden fazla istek çalıştırıyorsanız bu önemli bir not.
GPT-5.4, ayrıca bir Araç Arama sistemi tanıtıyor; bu, modele birden fazla araç verildiğinde verimli çalışmasını sağlıyor. Araç tanımını isteme eklemek yerine (ki bu daha fazla token demek), modele araçların bir listesi ve bir araç arama yeteneği veriliyor. Model bir araca ihtiyaç duyduğunda onu arayıp ilgili sohbete ekliyor. Bu da daha iyi token verimliliği sağlıyor.
En etkileyici bulduğum özellik, GPT-5.4’ün otonom bilgisayar kullanımında insanları geride bırakabilmesi. Bu alanda Claude Opus 4.6’yı geçiyor; OSWorld kıyaslamalarında %75 puan alırken, Opus 4.6 %72,7’de kalıyor.
Artificial Analysis’ın bağımsız araştırmasına göre GPT 5.4 (xhigh), 71 bileşik araştırma zorluğu içeren, araştırma düzeyinde fizik akıl yürütme görevlerini test eden CritPt kıyaslamasında %30 puan elde ediyor.
GPT-5.4, araç çağırmada daha iyi ve daha isabetli. Yayın raporunda OpenAI, çok adımlı görevleri tamamlamak için gerçek araçlar ve API’lerin nasıl kullanıldığını test eden Toolathlon’da GPT-5.4’ün daha az adımda daha iyi sonuçlar elde ettiğini belirtiyor.
Claude Opus 4.6 gibi, GPT-5.4 de ucuz bir model değil. Neyse ki OpenAI, toplu çıkarım API’sinde daha uygun fiyatlar sunuyor.
Artık GPT-5.4 ve Opus 4.6’nın artılarını ve eksilerini gördüğünüze göre, kullanım senaryolarınız için hangisinin daha iyi olduğuna karar vermek üzere onları karşılaştıralım.
Genel olarak, çeşitli kıyaslamalar üzerinden modellerin performansını ölçen Artificial Analysis Intelligence Index’e göre en iyi model GPT-5.4. Onu geçen tek model ise Gemini 3.1 Pro.
Çoklu ajan orkestrasyonunda kazanan Claude Opus 4.6. Ajan Takımları özelliğiyle, farklı görevlerde paralel çalışan ajanlarla birden çok iş akışını çalıştırabilirsiniz.
Bilgisayar kullanımında ise kıl payı GPT-5.4 önde. Ajanınız bir masaüstünü işletmek, bir tarayıcıda gezinmek veya GUI tabanlı yazılımlarla etkileşmek zorundaysa, şu anda GPT-5.4 daha iyi bir tercih
Claude Opus 4.6, SWE-Bench Verified’da %80,84 ve değiştirilmiş istem kullanırken %81,4 puanla daha iyi bir programcı.
GPT-5.4, GPT-5.3-Codex’in kodlama yeteneklerini miras alıyor. OpenAI’ye göre, GPT-5.4, akıl yürütme görevlerinde daha düşük gecikmeyle, SWE-Bench Pro (Public) üzerinde %57,7 puan elde ediyor.
OpenAI, raporlarında GPT-5.4’ün belirli görevlerde token kullanımını %47 azalttığını iddia ediyor. Opus 4.6’dan daha pahalı olsa da bu token azaltımı sayesinde büyük ölçekte GPT-5.4’ün işletme maliyeti daha düşük olabilir.
Bununla birlikte, daha az fakat karmaşık vekil görevleri çalıştırmak için Opus 4.6 hâlâ daha iyi model olabilir.
Karşılaştırma açısından, en güçlü GPT-5.4 modeli (bağlam uzunluğu>272K) 1M giriş tokenı için 60$, 1M çıkış tokenı için 270$ maliyete sahipken, Claude Opus 4.6, 1M giriş tokenı için 5$, 1M çıkış tokenı için 25$ tutuyor.
Hem GPT-5.4 hem de Claude Opus 4.6, Claude’unki beta olmakla birlikte, 1M tokene kadar bağlamı destekliyor. Bu da iki modeli büyük kod tabanlarında çalışma açısından güçlü rakipler yapıyor.
|
Kategori |
Claude Opus 4.6 |
GPT-5.4 |
|
Vekil görevler |
Güçlü (Ajan Takımları, paralel orkestrasyon) |
Güçlü (bilgisayar kullanımı, OSWorld %75) |
|
Kodlama kıyaslaması |
SWE-Bench %80,2, Düşünme ile |
SWE-Bench Pro (Public) %57,7 |
|
Bilgisayar kullanımı |
OSWorld’da %72,7 |
OSWorld %75 (insan uzmanları geçiyor) |
|
Bağlam penceresi |
1M token (beta), 128K maks. çıktı |
1M token |
|
Bilgi işi |
Humanity's Last Exam lideri |
GDPval %83 |
|
Fiyatlandırma (giriş/çıkış) |
1M Giriş Tokenı için 5$ 1M Çıkış Tokenı için 25$ |
gpt-5.4 (<272K bağlam uzunluğu) 1M giriş tokenı için 2,50$ ve 1M çıkış tokenı için 15,00$ tutar. Daha geniş bağlam penceresine sahip modeller daha pahalıdır. |
|
Token verimliliği |
Standart |
Bazı görevlerde %47 daha az token |
|
En uygunu |
Uzun süreli ajanlar, karmaşık kod tabanları |
Bilgisayar kullanımı, doküman iş akışları, kurumsal |
Sonuç bölümünde, en önemli soruyu yanıtlayalım: İki modelden hangisini seçmelisiniz?
Anthropic’in modelleri uzun süredir kodlama için başvurulan seçenek oldu, ancak yaratıcı yazı gibi beklenmedik alanlarda da parlıyorlar. Hatta birçok kişi bu konuda piyasadaki en iyisi olduklarını savunuyor.
Ancak Anthropic, OpenAI’nin Codex modelini özellikle programlama için konumlandırması gibi, modellerinin belirli görevlere özel olduğunu hiç kamuya açık şekilde iddia etmedi.
OpenAI’nin artık Anthropic’in yönüne doğru ilerlemesini son derece ilginç buluyorum. Son sürümleriyle, çok geniş bir profesyonel görev yelpazesini tek bir birleşik modelle ele alma hedefini zorluyorlar. Bu kullanıcılar için büyük bir kazanç; kimse işini yapmak için sürekli uzman modeller arasında geçiş yapmak istemez.
Öte yandan, Anthropic’in uzun süredir diğer modellerde (ör. Gemini 3) bulunan 1M bağlam penceresini benimsemesini görmek de güzel. Bence gelecekte bu modellerin özellikleri birbirine çok benzeyecek; kullanıcılar için karar değiştiren unsurlar çok az kalacak. Bununla birlikte, modellerin farklı görevlerdeki performansı ana ayrıştırıcı olacak; kullanıcılar kendi iş akışlarında iyi sonuç veren modelleri tercih edecek.
2026’da Anthropic ve OpenAI’nin vekil işler için güçlü modelleri var. Kafa karıştırıcı olan, farklı kıyaslamalar raporlamaları. Muhtemelen modellerinin parlayacağı alanları öne çıkarıyorlar.
Artık size düşen, diğer kıyaslamalar için bağımsız analizlere başvurmak ve onları kendi kullanım senaryolarınızda test etmek. Ancak net olan şu: Modeller daha iyi oluyor. Ve sizin de onları kullanma beceriniz gelişmeli.
Bu vekil dalgasında geride kalmamanın bir yolu, bu modelleri yazılım mühendisliğinde etkili şekilde kullanmayı öğrenmektir. Başlamak için ücretsiz olarak Cursor ile Yazılım Geliştirme kursumuza kaydolmanızı öneririm. Ayrıca Claude Modellerine Giriş kursunu ve OpenAI Temelleri beceri yolunu alabilirsiniz.
Öne Çıkan DataCamp Kursları
Program
Kurs
Kurs
blog
Abid Ali Awan
14 dk.
blog
Dario Radečić
15 dk.
Eğitim
Kurtis Pykes
Eğitim
Adel Nehme
