
programa
Fundamentos de OpenAI
15 h
Hace unos años, apenas podías conseguir que un modelo de lenguaje grande escribiera un email decente. Cuando OpenAI lanzó su primer modelo de código abierto, fue increíble verlo generar texto coherente. Solo unos años después, ya tenemos modelos de IA capaces de construir proyectos completos de ingeniería de software, reservar reuniones, comprar productos en Amazon y mucho más. En 2026, el panorama ha cambiado por completo, y la gran pregunta para los desarrolladores es qué modelo encaja mejor con sus casos de uso.
GPT-5.4 y Claude Opus 4.6 están en el centro de esa cuestión. Ambos son muy capaces, aunque de formas distintas, y salieron con pocas semanas de diferencia. Ahora bien, tienen precios distintos y rinden mejor en escenarios diferentes.
He estado profundizando en sus informes de lanzamiento y en rankings independientes durante la última semana. En este artículo, te cuento lo que he descubierto para ayudarte a elegir el mejor modelo para tu flujo de trabajo.
Claude Opus 4.6 es el modelo más capaz de Anthropic hasta la fecha. Opus 4.6 mejora al modelo anterior, con avances clave en programación y en tareas agentivas de larga duración. Anthropic afirma que planifica mejor, hace mejores revisiones de código y depura con más acierto, llegando incluso a detectar sus propios errores.
Anthropic lanzó Opus 4.6 con una ventana de contexto de 1M de tokens en beta, con una salida máxima de 128K tokens. Esto le permite trabajar con bases de código extensas y procesar documentos grandes, como documentación.
Esta versión también incorpora Adaptive Thinking, lo que significa que Claude ahora puede decidir cuándo activar un razonamiento extendido en lugar de esperar a que lo hagas manualmente.
Claude Opus 4.6 puede decidir si algo necesita un arreglo rápido o si merece dedicar más tiempo a razonar y trazar un plan para solucionarlo. Creo que esto será muy útil para resolver problemas complejos de ingeniería. No es de extrañar que el modelo lidere el ranking de text and coding arena.
En benchmarks de programación, Claude Opus 4.6 obtiene un 81,42% en SWE-Bench Verified, que evalúa la capacidad del modelo para resolver issues reales de GitHub. El modelo también logró el mejor resultado en Humanity’s Last Exam.
Con Opus 4.6, Claude también presentó Agent Teams como función experimental en Claude Code. Al activarla, puedes lanzar varios agentes para trabajar en tareas. Los agentes colaboran como un equipo, con tareas compartidas y mensajería entre agentes.
Puedes aprender a usar Claude Code de Anthropic para mejorar flujos de trabajo de desarrollo de software con un ejemplo práctico usando la librería Supabase de Python en nuestro tutorial de Claude Code.
Claude Opus 4.6 es un modelo agentivo muy potente. De hecho, el creador de OpenClaw recomienda usarlo en OpenClaw porque es difícil de envenenar con inyecciones de prompt. Esto hace que el modelo sea más robusto frente a código malicioso.
La función Agent Teams, aunque todavía experimental, es un salto enorme respecto a los subagentes. Con ella, puedes dividir tu trabajo entre varios agentes de Claude. Por ejemplo, uno puede encargarse del backend, otro del frontend y otro de ejecutar tests. Cada agente tiene su propia ventana de contexto, lo que reduce el riesgo de fallos por limitaciones de contexto.
Cladue Opus 4.6 es un gran modelo, pero como suele decirse, nada es gratis. No es barato de ejecutar, especialmente si haces un uso intensivo.
Mientras tanto, Anthropic ha publicado su modelo sucesor. No te pierdas también nuestra guía sobre Claude Opus 4.7.
GPT-5.4 es el modelo más reciente y más capaz de OpenAI. Se construyó combinando las capacidades de programación de GPT-5.3-Codex y añadiendo razonamiento para crear un único modelo potente. Esto significa que ya no necesitas alternar entre modelos Codex para programar y otros modelos de OpenAI para el resto de tareas.
La función de GPT-5.4 que me resulta más interesante es su capacidad de uso del ordenador. En OSWorld, un benchmark que mide la habilidad de un modelo para usar un ordenador de escritorio, GPT-5.4 logró un 75,0%, con el rendimiento humano en 72,4%. En comparación, GPT-5.2 obtuvo un 47,3% en la misma prueba.
En GDPval, un benchmark que evalúa trabajo de conocimiento profesional en 44 profesiones, GPT-5.4 obtuvo un 83%. Esto indica que el modelo puede ejecutar tareas agentivas en los principales empleos de EE. UU. al nivel de un profesional.
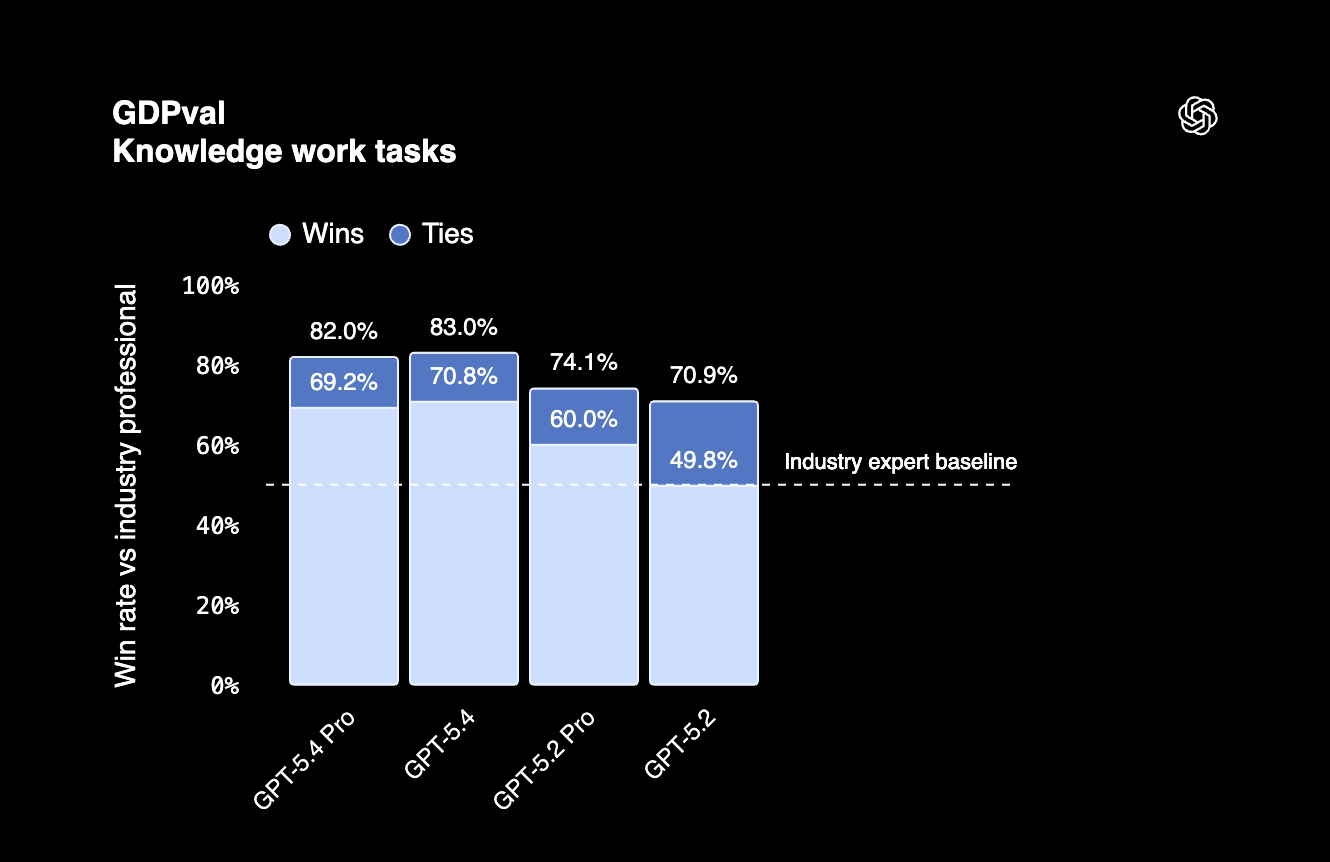
GPT-5.4 también mejora la eficiencia de tokens, es decir, usa menos tokens que modelos anteriores para muchas tareas. Tenlo en cuenta si haces múltiples solicitudes al día.
GPT-5.4 introduce además un sistema de búsqueda de herramientas (Tool Search), que hace que el modelo trabaje de forma más eficiente cuando tiene múltiples herramientas disponibles. En lugar de incluir la definición de cada herramienta en el prompt, lo que suma tokens, ahora el modelo recibe una lista de herramientas y la capacidad de buscarlas. Cuando necesita una herramienta, la localiza y la añade a esa conversación. Esto mejora la eficiencia de tokens.
Lo que más me impresiona es la capacidad de GPT-5.4 para superar a humanos en uso autónomo del ordenador. Supera a Claude Opus 4.6 en este terreno, con un 75% en OSWorld frente al 72,7% de Opus 4.6.
Investigación independiente de Artificial Analysis muestra que GPT 5.4 (xhigh) logra un 30% en el benchmark CritPt, que evalúa a los LLM en tareas de razonamiento de física a nivel de investigación, con 71 retos compuestos.
GPT-5.4 es más eficaz y preciso al llamar herramientas. En su informe de lanzamiento, OpenAI señala que obtiene mejores resultados en menos pasos en Toolathlon, un benchmark que prueba cómo los agentes usan herramientas y APIs del mundo real para completar tareas de varios pasos.
Al igual que Claude Opus 4.6, GPT-5.4 tampoco es un modelo barato. Por suerte, OpenAI ofrece precios más bajos en la API de inferencia por lotes.
Ahora que has visto los pros y contras de GPT-5.4 y Opus 4.6, vamos a compararlos para determinar cuál encaja mejor con tus casos de uso.
En conjunto, GPT-5.4 es el mejor modelo según el Artificial Analysis Intelligence Index, que mide el rendimiento en diversos benchmarks. El único que lo supera es Gemini 3.1 Pro.
Claude Opus 4.6 gana en orquestación multiagente. Con su función Agent Teams, puedes ejecutar múltiples flujos con agentes en paralelo trabajando en tareas diferentes.
GPT-5.4 gana por poco en uso del ordenador. Si tu agente necesita operar un escritorio, navegar por un navegador o interactuar con software basado en GUI, GPT-5.4 es ahora mismo la mejor opción
Claude Opus 4.6 programa mejor, con un 80,84% en SWE-Bench Verified y un 81,4% usando un prompt modificado.
GPT-5.4 hereda las capacidades de programación de GPT-5.3-Codex. Según OpenAI, GPT-5.4 logra un 57,7% en SWE-Bench Pro (público) con menor latencia en tareas de razonamiento.
En su informe, OpenAI afirma que GPT-5.4 demostró una reducción del 47% en el uso de tokens en ciertas tareas. Aunque es más caro que Opus 4.6, GPT-5.4 podría ser más barato de operar a escala gracias a esta reducción.
Sin embargo, Opus 4.6 podría seguir siendo mejor opción si ejecutas pocas tareas agentivas pero muy complejas.
Como referencia, el modelo más potente de GPT-5.4 (longitud de contexto>272K) cuesta 60 $ por 1M de tokens de entrada y 270 $ por 1M de tokens de salida, mientras que Claude Opus 4.6 cuesta 5 $ por 1M de tokens de entrada y 25 $ por 1M de tokens de salida.
Tanto GPT-5.4 como Claude Opus 4.6 admiten hasta 1M de tokens de contexto, aunque en Claude es beta. Esto convierte a ambos en grandes rivales para trabajar con bases de código extensas.
|
Categoría |
Claude Opus 4.6 |
GPT-5.4 |
|
Tareas agentivas |
Fuerte (Agent Teams, orquestación en paralelo) |
Fuerte (uso del ordenador, OSWorld 75%) |
|
Benchmark de programación |
SWE-Bench 80,2% con Thinking |
57,7% en SWE-Bench Pro (público) |
|
Uso del ordenador |
72,7% en OSWorld |
OSWorld 75% (supera a expertos humanos) |
|
Ventana de contexto |
1M tokens (beta), 128K salida máx. |
1M tokens |
|
Trabajo de conocimiento |
Líder en Humanity's Last Exam |
GDPval 83% |
|
Precios (entrada/salida) |
5 $ por millón de tokens de entrada 25 $ por millón de tokens de salida |
gpt-5.4 (<272K de contexto) cuesta 2,50 $ por 1M de tokens de entrada y 15,00 $ por 1M de tokens de salida. Los modelos con mayor ventana de contexto son más caros. |
|
Eficiencia de tokens |
Estándar |
47% menos tokens en algunas tareas |
|
Ideal para |
Agentes de larga duración, bases de código complejas |
Uso del ordenador, flujos con documentos, empresa |
Para cerrar, respondamos a la pregunta clave: ¿con cuál de los dos deberías quedarte?
Los modelos de Anthropic han sido durante mucho tiempo la referencia para programar, pero también brillan en terrenos inesperados como la escritura creativa. De hecho, muchos dirían que son los mejores del sector en ello.
Pero Anthropic nunca ha afirmado públicamente que sus modelos estén especializados en tareas concretas, como sí hizo OpenAI al indicar que el modelo Codex estaba pensado específicamente para programar.
Me parece muy interesante que OpenAI ahora se mueva en la dirección de Anthropic. Con sus últimos lanzamientos, impulsan un modelo único y unificado que cubre una enorme variedad de tareas profesionales. Es una gran noticia para los usuarios: nadie quiere estar cambiando constantemente entre modelos especializados para sacar adelante su trabajo.
Por otro lado, está bien ver a Anthropic adoptar la ventana de contexto de 1M, que otros modelos ya tenían desde hace tiempo (como Gemini 3). Creo que en el futuro estos modelos tendrán funciones muy similares, de modo que habrá muy pocos factores decisivos. Dicho esto, el rendimiento del modelo en distintas tareas será el principal diferenciador, porque los usuarios preferirán los que mejor se adapten a sus flujos de trabajo específicos.
En 2026, tanto Anthropic como OpenAI cuentan con modelos muy sólidos para trabajo agentivo. Puede que te despiste que reporten benchmarks distintos, probablemente eligiendo aquellos donde más destacan.
Ahora te toca a ti consultar análisis independientes para otros benchmarks y probarlos en tus propios casos de uso. Lo que sí está claro es que los modelos mejoran, y tú también deberías mejorar en cómo los utilizas.
Una forma de no quedarte atrás en este movimiento agentivo es dominar el uso eficaz de estos modelos para ingeniería de software. Te recomiendo empezar inscribiéndote gratis en nuestro curso Software Development with Cursor. También puedes hacer el curso Introduction to Claude Models y el itinerario de habilidades OpenAI Fundamentals.
Los mejores cursos de DataCamp
programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
blog
Abid Ali Awan
9 min
blog
Matt Crabtree
12 min
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan


