
Programa
OpenAI Fundamentals
15 h
Há poucos anos, mal dava para fazer um modelo de linguagem escrever um e-mail decente. Quando a OpenAI lançou seu primeiro modelo open source, foi surpreendente ver o texto sair coerente. Pouco tempo depois, já temos modelos de IA que conseguem construir projetos completos de engenharia de software, marcar reuniões, comprar produtos na Amazon e muito mais. Em 2026, o cenário mudou de vez — e a pergunta que os desenvolvedores mais fazem é: qual modelo funciona melhor para os meus casos de uso?
GPT-5.4 e Claude Opus 4.6 estão no centro dessa discussão. Ambos são muito capazes, cada um do seu jeito, e foram lançados com poucas semanas de diferença. Mas os preços são distintos e o desempenho varia conforme o cenário.
Na última semana, analisei em profundidade os relatórios de lançamento e os rankings independentes. Neste artigo, vou compartilhar o que encontrei para ajudar você a decidir o melhor modelo para o seu fluxo de trabalho.
Claude Opus 4.6 é o modelo mais capaz da Anthropic até agora. O Opus 4.6 é uma evolução do anterior, com melhorias importantes em codificação e em tarefas agentic de longa duração. A Anthropic afirma que ele ficou melhor em planejamento, revisão de código e depuração — chegando a identificar os próprios erros.
A Anthropic lançou o Opus 4.6 com janela de contexto de 1M tokens em beta e saída máxima de 128K tokens. Isso permite trabalhar em bases de código extensas e ingerir documentos grandes, como documentação técnica.
Esta versão também traz o Adaptive Thinking, que permite ao Claude decidir quando ativar raciocínio estendido — sem depender de você ligar isso manualmente.
O Claude Opus 4.6 consegue avaliar se algo pede um ajuste rápido ou se merece mais tempo de raciocínio e um plano de correção. Isso deve ser muito útil para problemas de engenharia complexos. Não é surpresa que o modelo esteja no topo do leaderboard do text and coding arena.
Em benchmarks de código, o Claude Opus 4.6 alcança 81,42% no SWE-Bench Verified, que mede a capacidade do modelo em resolver issues reais do GitHub. O modelo também liderou no Humanity’s Last Exam.
Com o Opus 4.6, a Anthropic também apresentou as Agent Teams como recurso experimental no Claude Code. Ao ativar, você pode criar vários agentes para trabalhar em tarefas. Eles colaboram como um time, com tarefas compartilhadas e mensagens entre agentes.
Você pode aprender a usar o Claude Code da Anthropic para melhorar fluxos de desenvolvimento de software com um exemplo prático usando a biblioteca Supabase em Python no nosso tutorial de Claude Code.
O Claude Opus 4.6 é um modelo agentic muito forte. O próprio criador do OpenClaw recomenda usá-lo no OpenClaw por ser difícil de envenenar com prompt injections. Isso o torna mais robusto contra código malicioso.
O recurso Agent Teams, embora ainda experimental, é um salto enorme em relação a subagentes. Com ele, dá para dividir a tarefa entre vários agentes do Claude. Por exemplo: um cuida do backend, outro do front-end e outro executa testes. Cada agente tem sua própria janela de contexto, reduzindo o risco de falha por limitações de contexto.
O Cladue Opus 4.6 é potente, mas, como diz o ditado, não existe almoço grátis. O custo de execução é alto, sobretudo para uso intenso.
Enquanto isso, a Anthropic já publicou o modelo sucessor. Não deixe de conferir também nosso guia sobre Claude Opus 4.7!
GPT-5.4 é o modelo mais recente e mais capaz da OpenAI. Ele combina as habilidades de codificação do GPT-5.3-Codex com capacidades de raciocínio, criando um único modelo poderoso. Ou seja: você não precisa mais alternar entre modelos Codex para código e outros modelos da OpenAI para tarefas diferentes.
O recurso do GPT-5.4 que mais me chamou atenção é a capacidade de uso de computador. No OSWorld, um benchmark que mede a habilidade do modelo em usar um desktop, o GPT-5.4 marcou 75,0%, com humanos em 72,4%. Para contexto, o GPT-5.2 fez 47,3% no mesmo teste.
No GDPval, que avalia trabalho de conhecimento profissional em 44 profissões, o GPT-5.4 marcou 83%. Isso indica que o modelo executa tarefas agentic nos principais empregos dos EUA no nível de um profissional.
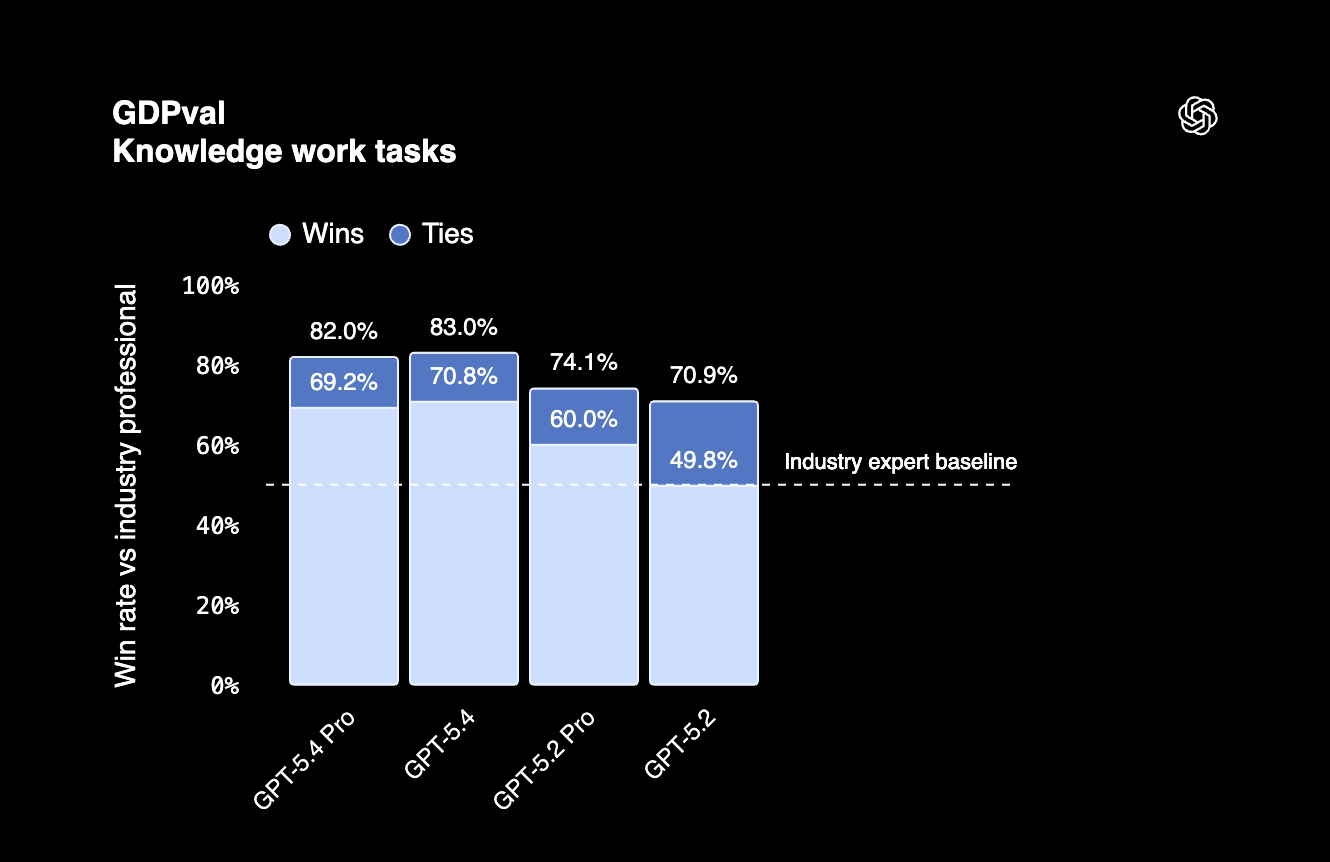
O GPT-5.4 também traz eficiência de tokens, usando menos tokens do que versões anteriores em muitas tarefas. Vale observar isso se você faz várias requisições por dia.
O GPT-5.4 também introduz um sistema de Tool Search, que torna o modelo mais eficiente quando há várias ferramentas disponíveis. Em vez de incluir a definição da ferramenta no prompt — o que consome tokens — o modelo recebe uma lista de ferramentas e um mecanismo de busca. Quando precisa de algo, ele localiza a ferramenta e a acopla àquela conversa. Isso melhora a eficiência de tokens.
O que mais impressiona é a capacidade do GPT-5.4 de superar humanos no uso autônomo de computador. Ele supera o Claude Opus 4.6 nesse quesito, com 75% no OSWorld, contra 72,7% do Opus 4.6.
Pesquisas independentes da Artificial Analysis mostram que o GPT-5.4 (xhigh) atinge 30% no CritPt, benchmark que testa raciocínio em nível de pesquisa em física, com 71 desafios compostos.
O GPT-5.4 também é melhor e mais preciso em tool calling. No relatório de lançamento, a OpenAI destaca resultados superiores em menos passos no Toolathlon, benchmark que avalia como agentes usam ferramentas e APIs reais para concluir tarefas em múltiplas etapas.
Assim como o Claude Opus 4.6, o GPT-5.4 também não é barato. A boa notícia é que a OpenAI oferece preços mais em conta via batch inference API.
Agora que você viu os prós e contras do GPT-5.4 e do Opus 4.6, vamos comparar para entender qual é o melhor para os seus casos de uso.
No geral, o GPT-5.4 é o melhor modelo segundo o Artificial Analysis Intelligence Index, que mede o desempenho em vários benchmarks. O único que o supera é o Gemini 3.1 Pro.
O Claude Opus 4.6 vence em orquestração multiagente. Com o Agent Teams, você roda múltiplos fluxos com agentes em paralelo em tarefas diferentes.
O GPT-5.4 ganha por pouco em uso de computador. Se seu agente precisa operar um desktop, navegar no navegador ou interagir com softwares GUI, o GPT-5.4 hoje é a melhor escolha.
O Claude Opus 4.6 é o melhor programador, com 80,84% no SWE-Bench Verified e 81,4% usando um prompt modificado.
O GPT-5.4 herda as habilidades de código do GPT-5.3-Codex. De acordo com a OpenAI, o GPT-5.4 alcança 57,7% no SWE-Bench Pro (Public), com menor latência em tarefas de raciocínio.
No relatório, a OpenAI afirma que o GPT-5.4 reduziu em 47% o uso de tokens em certas tarefas. Embora mais caro que o Opus 4.6, o GPT-5.4 pode sair mais barato em escala por causa dessa redução.
Ainda assim, o Opus 4.6 pode ser a melhor opção para executar menos tarefas, porém mais complexas e agentic.
Para referência: o GPT-5.4 mais poderoso (contexto >272K) custa US$ 60 por 1M tokens de entrada e US$ 270 por 1M tokens de saída, enquanto o Claude Opus 4.6 custa US$ 5 por 1M tokens de entrada e US$ 25 por 1M tokens de saída.
Tanto o GPT-5.4 quanto o Claude Opus 4.6 suportam até 1M de tokens de contexto, embora no Claude isso esteja em beta. Ambos são fortes candidatos para trabalhar em bases de código grandes.
|
Categoria |
Claude Opus 4.6 |
GPT-5.4 |
|
Tarefas agentic |
Forte (Agent Teams, orquestração paralela) |
Forte (uso de computador, OSWorld 75%) |
|
Benchmark de código |
SWE-Bench 80,2% com Thinking |
57,7% no SWE-Bench Pro (Public) |
|
Uso de computador |
72,7% no OSWorld |
OSWorld 75% (supera especialistas humanos) |
|
Janela de contexto |
1M tokens (beta), 128K de saída máxima |
1M tokens |
|
Trabalho de conhecimento |
Líder no Humanity's Last Exam |
GDPval 83% |
|
Preços (entrada/saída) |
US$ 5 em tokens de entrada US$ 25 por milhão de tokens de saída |
gpt-5.4 (<272K de contexto) custa US$ 2,50 por 1M de tokens de entrada e US$ 15,00 por 1M de tokens de saída. Modelos com janela de contexto maior são mais caros. |
|
Eficiência de tokens |
Padrão |
Até 47% menos tokens em algumas tarefas |
|
Melhor para |
Agentes de longa duração, bases de código complexas |
Uso de computador, fluxos com documentos, enterprise |
Para fechar, vamos responder à pergunta principal: qual dos dois você deve escolher?
Os modelos da Anthropic há muito são referência em código, mas também brilham em áreas inesperadas, como escrita criativa. Muita gente, inclusive, diria que são os melhores nessa categoria.
Mas a Anthropic nunca afirmou publicamente que seus modelos são especializados em tarefas específicas, como a OpenAI afirmou que o Codex era focado em programação.
Acho muito interessante ver a OpenAI se aproximando da estratégia da Anthropic. Com os últimos lançamentos, a aposta é em um único modelo unificado que dá conta de uma grande variedade de tarefas profissionais. Excelente para o usuário — ninguém quer ficar alternando entre modelos especializados para concluir o trabalho.
Por outro lado, é bom ver a Anthropic abraçar a janela de contexto de 1M, que outros modelos (como o Gemini 3) já tinham há mais tempo. No futuro, acredito que esses modelos terão recursos muito semelhantes, com poucos deal breakers para os usuários. Dito isso, o desempenho em tarefas específicas deve ser o grande diferencial, já que cada um vai preferir o modelo que funciona melhor no seu fluxo.
Em 2026, Anthropic e OpenAI têm modelos sólidos para trabalho agentic. O que pode confundir é cada uma reportar benchmarks diferentes — provavelmente destacando onde seus modelos se saem melhor.
Agora, cabe a você consultar análises independentes e testar nos seus próprios casos de uso. O que é certo é que os modelos estão evoluindo — e você também precisa evoluir no uso deles.
Uma forma de não ficar para trás nessa onda agentic é dominar o uso desses modelos em engenharia de software. Recomendo começar se inscrevendo gratuitamente no nosso curso Software Development with Cursor. Você também pode fazer o curso Introduction to Claude Models e a trilha de habilidades OpenAI Fundamentals.
Principais cursos da DataCamp
Programa
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Josep Ferrer
8 min
blog
Richie Cotton
7 min
blog
Khalid Abdelaty
15 min
Tutorial
Moez Ali
Tutorial
Arunn Thevapalan



