
Program
Dasar-Dasar OpenAI
15 Hr
Beberapa tahun lalu, model bahasa besar nyaris tidak bisa menulis email yang layak. Saat OpenAI merilis model open-source pertamanya, kemampuan menghasilkan teks yang koheren terasa menakjubkan. Hanya beberapa tahun berselang, kini kita punya model AI yang dapat membangun proyek rekayasa perangkat lunak lengkap, memesan rapat, membeli produk di Amazon, dan banyak lagi. Pada 2026, lanskapnya benar-benar berubah, dan pertanyaan yang diajukan para developer adalah model mana yang paling cocok untuk kasus penggunaan mereka.
GPT-5.4 dan Claude Opus 4.6 kini berada di pusat pertanyaan tersebut. Keduanya sama-sama mumpuni dengan cara yang berbeda, dan keduanya diluncurkan hanya berselang beberapa minggu. Namun, kedua model memiliki harga yang berbeda dan performa terbaiknya di skenario yang berbeda.
Saya mendalami laporan rilis mereka dan papan peringkat independen selama sepekan terakhir. Dalam artikel ini, saya akan mengulas temuan saya untuk membantu Anda menentukan model terbaik bagi alur kerja Anda.
Claude Opus 4.6 adalah model paling mumpuni dari Anthropic hingga saat ini. Opus 4.6 merupakan peningkatan dari model sebelumnya, dengan peningkatan utama pada pengkodean dan tugas agen berdurasi panjang. Anthropic menyatakan model ini lebih baik dalam perencanaan, code review, dan debugging, bahkan mampu menemukan kesalahannya sendiri.
Anthropic merilis Opus 4.6 dengan jendela konteks 1M token dalam versi beta, dengan output maksimum 128K token. Ini membuat model mampu bekerja pada codebase besar dan menangani dokumen berukuran besar, seperti dokumentasi.
Rilis ini juga menghadirkan Adaptive Thinking, yang berarti Claude kini dapat memutuskan kapan perlu melakukan pemikiran mendalam alih-alih menunggu Anda menyalakannya secara manual.
Claude Opus 4.6 bisa menentukan apakah sesuatu cukup diperbaiki cepat atau butuh waktu lebih untuk bernalar dan menyusun rencana perbaikan. Saya rasa ini akan sangat berguna untuk menyelesaikan masalah rekayasa yang kompleks. Tak mengherankan jika model ini berada di puncak papan peringkat text dan coding arena.
Pada benchmark coding, Claude Opus 4.6 meraih skor 81,42% di SWE-Bench Verified, yang menguji kemampuan model menyelesaikan isu GitHub nyata. Model ini juga meraih nilai terbaik di Humanity’s Last Exam.
Dengan Opus 4.6, Claude juga memperkenalkan Agent Teams sebagai fitur eksperimental di Claude Code. Saat diaktifkan, Anda dapat menjalankan banyak agen untuk mengerjakan tugas. Para agen bekerja bersama sebagai tim, dengan tugas bersama dan pesan antaragen.
Anda dapat mempelajari cara menggunakan Claude Code dari Anthropic untuk meningkatkan alur kerja pengembangan perangkat lunak melalui contoh praktis menggunakan pustaka Supabase Python dari tutorial Claude Code kami.
Claude Opus 4.6 adalah model agen yang sangat kuat. Bahkan, pembuat OpenClaw merekomendasikan menggunakannya di OpenClaw karena model ini sulit dipengaruhi oleh prompt injection. Ini membuat model lebih tangguh terhadap kode berbahaya.
Fitur Agents Teams, meski masih eksperimental, merupakan peningkatan besar dari subagent. Dengan fitur ini, Anda dapat membagi tugas ke beberapa agen Claude. Misalnya, satu menangani backend, lainnya frontend, dan satu lagi menjalankan pengujian. Setiap agen memiliki jendela konteksnya sendiri, sehingga mengurangi risiko kegagalan tugas akibat keterbatasan jendela konteks.
Cladue Opus 4.6 adalah model yang kuat, tetapi seperti pepatah, tidak ada makan siang gratis. Model ini tidak murah untuk dijalankan, terutama jika Anda pengguna berat.
GPT-5.4 adalah model terbaru dan termumpuni dari OpenAI. Model ini dibangun dengan menggabungkan kemampuan coding GPT-5.3-Codex dan menambahkan kemampuan penalaran untuk menciptakan satu model yang kuat. Artinya, Anda tidak lagi perlu beralih antara model codex untuk coding dan model OpenAI lain untuk tugas lainnya.
Fitur GPT-5.4 yang paling menarik bagi saya adalah kemampuan penggunaan komputer. Pada OSWorld, sebuah benchmark yang mengukur kemampuan model menggunakan komputer desktop, GPT-5.4 meraih skor 75,0% dengan performa manusia di 72,4%. Sebagai perbandingan, GPT-5.2 meraih 47,3% pada tes yang sama.
Pada GDPval, benchmark yang menguji kerja pengetahuan profesional di 44 profesi, GPT-5.4 meraih skor 83%. Ini berarti model dapat melakukan tugas agen di pekerjaan papan atas AS pada level profesional.
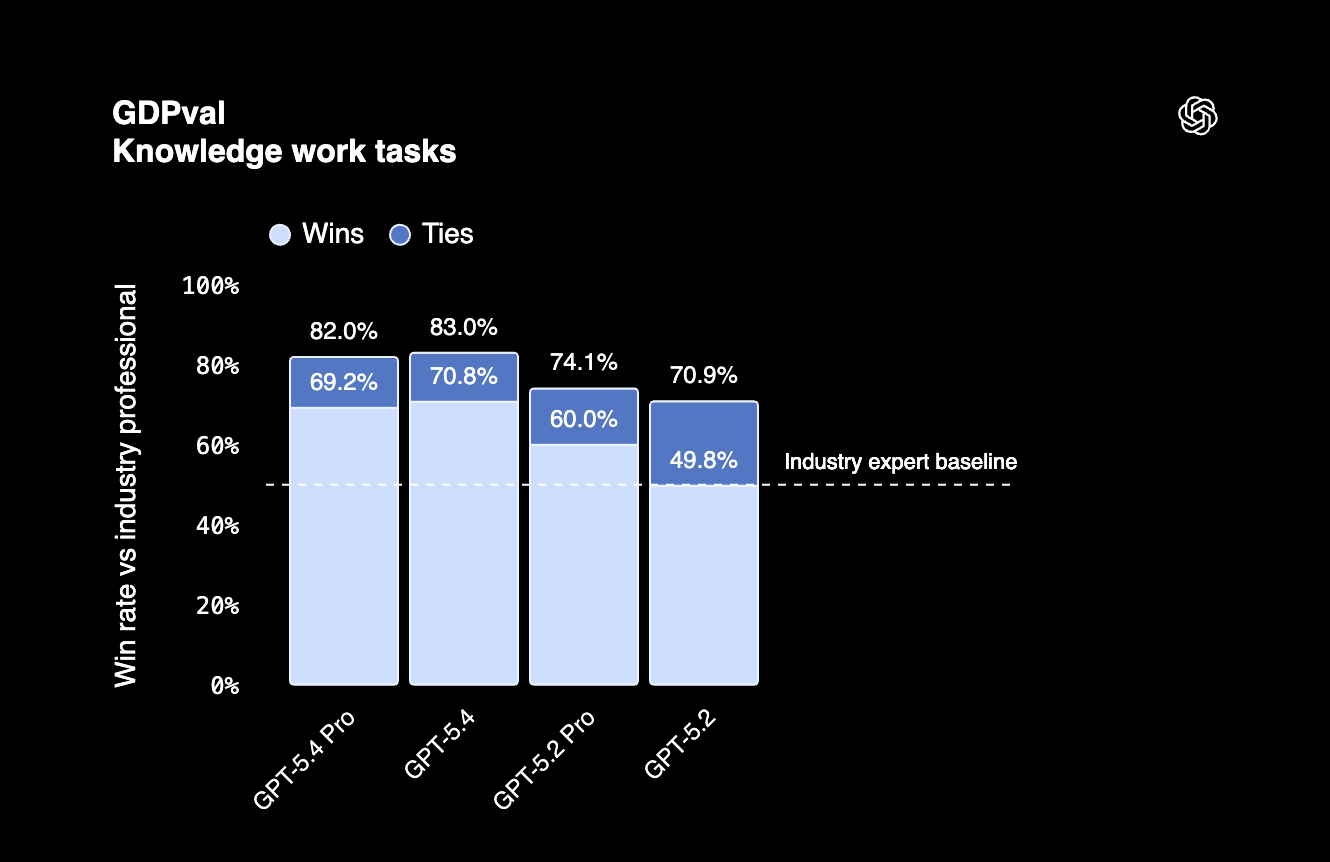
GPT-5.4 juga menonjol dalam efisiensi token, artinya menggunakan lebih sedikit token dibanding model sebelumnya untuk banyak tugas. Ini penting dicatat jika Anda menjalankan banyak permintaan per hari.
GPT-5.4 juga memperkenalkan sistem Tool Search, yang membuat model bekerja efisien saat diberi banyak alat. Alih-alih memasukkan definisi alat dalam prompt—yang menambah token—model kini diberi daftar alat dan kemampuan pencarian alat. Saat model membutuhkan alat, ia akan mencarinya dan menambahkannya ke percakapan tersebut. Ini meningkatkan efisiensi token.
Fitur yang paling mengesankan bagi saya adalah kemampuan GPT-5.4 mengungguli manusia dalam penggunaan komputer otonom. Model ini mengalahkan Claude Opus 4.6 di area ini, meraih 75% pada benchmark OSWorld, dibanding 72,7% milik Opus 4.6.
Riset independen dari Artificial Analysis menunjukkan GPT 5.4 (xhigh) meraih skor 30% pada benchmark CritPt, yang menguji penalaran fisika setingkat riset untuk LLM, mencakup 71 tantangan riset komposit.
GPT-5.4 lebih baik dan lebih akurat dalam pemanggilan alat (tool calling). Dalam laporan rilis, OpenAI mencatat model ini meraih hasil lebih baik dengan lebih sedikit langkah pada Toolathlon, benchmark untuk menguji bagaimana agen menggunakan alat dan API dunia nyata untuk menyelesaikan tugas multi-langkah.
Sama seperti Claude Opus 4.6, GPT-5.4 juga bukan model yang murah. Untungnya, OpenAI menawarkan harga yang lebih hemat melalui batch inference API.
Sekarang setelah Anda melihat kelebihan dan kekurangan GPT-5.4 dan Opus 4.6, mari bandingkan keduanya untuk menentukan mana yang terbaik bagi kasus penggunaan Anda.
Secara keseluruhan, GPT-5.4 adalah model terbaik menurut Artificial Analysis Intelligence Index, yang mengukur performa model di berbagai benchmark. Satu-satunya yang mengunggulinya adalah Gemini 3.1 Pro.
Claude Opus 4.6 unggul dalam orkestrasi multi-agen. Dengan fitur Agent Teams, Anda dapat menjalankan beberapa alur kerja dengan agen paralel yang mengerjakan tugas berbeda.
GPT-5.4 unggul tipis dalam penggunaan komputer. Jika agen Anda perlu mengoperasikan desktop, menavigasi browser, atau berinteraksi dengan perangkat lunak berbasis GUI, GPT-5.4 saat ini adalah pilihan yang lebih baik
Claude Opus 4.6 adalah pemrogram yang lebih baik dengan skor 80,84% pada SWE-Bench Verified dan 81,4% saat menggunakan prompt yang dimodifikasi.
GPT-5.4 mewarisi kemampuan coding GPT-5.3-Codex. Menurut OpenAI, GPT-5.4 meraih skor 57,7% pada SWE-Bench Pro (Publik) dengan latensi lebih rendah di tugas penalaran.
Dalam laporannya, OpenAI mengklaim GPT-5.4 menunjukkan pengurangan penggunaan token hingga 47% pada tugas tertentu. Meski lebih mahal daripada Opus 4.6, GPT-5.4 bisa jadi lebih murah untuk dioperasikan pada skala besar berkat pengurangan token ini.
Namun, Opus 4.6 masih bisa menjadi model yang lebih baik untuk menjalankan tugas agen yang lebih sedikit tetapi kompleks.
Sebagai konteks, model GPT-5.4 terkuat (panjang konteks>272K) berbiaya $60 untuk 1M token input dan $270 untuk 1M token output, sedangkan Claude Opus 4.6 berbiaya $5 untuk 1M token input dan $25 untuk 1M token output.
Baik GPT-5.4 maupun Claude Opus 4.6 mendukung hingga 1M token konteks, meski milik Claude masih beta. Ini membuat keduanya menjadi pesaing kuat untuk bekerja pada codebase besar.
|
Kategori |
Claude Opus 4.6 |
GPT-5.4 |
|
Tugas agen |
Kuat (Agent Teams, orkestrasi paralel) |
Kuat (penggunaan komputer, OSWorld 75%) |
|
Benchmark coding |
SWE-Bench 80,2% dengan Thinking |
57,7% pada SWE-Bench Pro (Publik) |
|
Penggunaan komputer |
72,7% pada OSWorld |
OSWorld 75% (mengungguli pakar manusia) |
|
Jendela konteks |
1M token (beta), output maks 128K |
1M token |
|
Kerja pengetahuan |
Pemimpin Humanity's Last Exam |
GDPval 83% |
|
Harga (input/output) |
$5 Base Input Tokens $25 Output Tokens per juta token |
gpt-5.4 (<272K panjang konteks) berbiaya $2,50 untuk 1M token input dan $15,00 untuk 1M token output. Model dengan jendela konteks lebih besar lebih mahal. |
|
Efisiensi token |
Standar |
47% lebih sedikit token pada beberapa tugas |
|
Terbaik untuk |
Agen berdurasi panjang, codebase kompleks |
Penggunaan komputer, alur kerja dokumen, enterprise |
Sebagai penutup, mari jawab pertanyaan terpenting: dari keduanya, mana yang harus Anda pilih?
Model Anthropic telah lama menjadi andalan untuk coding, namun juga cemerlang di area tak terduga seperti penulisan kreatif. Faktanya, banyak yang berpendapat mereka adalah yang terbaik di bidang ini.
Namun Anthropic tidak pernah menyatakan secara publik bahwa model mereka terspesialisasi pada tugas tertentu, sebagaimana OpenAI menyatakan bahwa model Codex khusus untuk pemrograman.
Saya merasa sangat menarik bahwa OpenAI kini bergerak ke arah Anthropic. Dengan rilis terbaru, mereka mendorong ke satu model terpadu yang menangani beragam besar tugas profesional. Ini kemenangan besar bagi pengguna; tak seorang pun ingin terus-menerus berganti model spesialis untuk menyelesaikan pekerjaan.
Di sisi lain, menyenangkan melihat Anthropic mengadopsi jendela konteks 1M, yang telah lama dimiliki model lain (seperti Gemini 3). Saya pikir di masa depan fitur model-model ini akan sangat mirip, sehingga faktor penentunya bagi pengguna akan sangat sedikit. Meski begitu, performa model pada tugas berbeda akan menjadi pembeda utama, karena pengguna akan memilih model yang unggul pada alur kerja spesifik mereka.
Pada 2026, Anthropic dan OpenAI sama-sama memiliki model kuat untuk pekerjaan agen. Yang mungkin membingungkan Anda adalah mereka melaporkan benchmark yang berbeda—barangkali memilih area yang paling menonjol bagi model mereka.
Kini terserah Anda merujuk analisis independen untuk benchmark lain dan mengujinya pada kasus penggunaan Anda sendiri. Yang jelas, model-modelnya semakin baik. Dan Anda pun sebaiknya makin mahir menggunakannya.
Salah satu cara agar Anda tidak tertinggal oleh pergerakan agen ini adalah menguasai cara menggunakan model-model ini secara efektif untuk rekayasa perangkat lunak. Saya sarankan memulai dengan mendaftar kursus Software Development with Cursor kami secara gratis. Anda juga bisa mengikuti kursus Introduction to Claude Models dan OpenAI Fundamentals skill track.
Kursus Teratas di DataCamp
Program
Kursus
Kursus
blogs
Javier Canales Luna
14 mnt
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
