

Leerpad
Basisprincipes van AI-agenten
6 Hr
Alibaba heeft zojuist zijn nieuwste large language model onthuld: Qwen3.5. Dit nieuwe model volgt op recente releases zoals GPT-5.3 Codex en Claude Opus 4.6, die ons allebei wisten te imponeren.
Volgens Alibaba is Qwen 3.5 “gebouwd voor het agentic AI-tijdperk”, en het vision-languagemodel zou goedkoper en efficiënter zijn dan zijn voorganger, met indrukwekkende prestaties op frontier-niveau in diverse benchmarks.
Alibaba brengt ook Qwen3.5-Plus uit, een premiumversie met een contextvenster van 1 miljoen tokens, waarmee het de concurrentie met Gemini 3 nadrukkelijk aangaat.
In dit artikel neem ik je mee langs de belangrijkste nieuwe features van Qwen3.5 en Qwen3.5-Plus, bekijken we hoe ze zich verhouden tot concurrenten, wat de benchmarks laten zien en hoe je toegang krijgt tot de nieuwe modellen.
Bekijk ook zeker onze gidsen over de nieuwste concurrerende modellen, zoals Claude Sonnet 4.6 of GPT-5.3 Instant.
Qwen3.5 is de nieuwste generatie in Alibaba’s serie large language models (LLM), Qwen3.5-397B-A17B. In tegenstelling tot de Qwen3-modelfamilie ervoor, combineert Qwen3.5 gespecialiseerde modellen in één native vision-language model. Net als eerdere Qwen-modellen is het open source onder de Apache 2.0-licentie.
Het is gepositioneerd als een algemeen fundamentmodel voor zowel consumenten- als bedrijfsgebruik en is ontworpen voor native multimodale en agentic workflows. Qwen3.5-397B-A17B biedt twee modi:
Qwen3.5-Plus is een gehoste, alleen-API-service die overeenkomt met Qwen3.5-397B-A17B en is zelf geen open‑weight model. De releasenote was hier enigszins verwarrend over: de vermelding van Qwen3.5-Plus kan worden gelezen als een apart model, maar in werkelijkheid is het Alibaba’s propriëtaire dienst op basis van hetzelfde model.
Hoewel Qwen3.5-Plus op het Qwen3.5-397B-A17B-model is gebaseerd, zijn er enkele verschillen. Het is uitsluitend toegankelijk via de Alibaba Cloud Model Studio op basis van betalen per token, en via de Qwen Chat-UI met beperkte toegang.
Qwen3.5-Plus gebruikt een uitgebreid contextvenster van 1 miljoen tokens, vergeleken met het contextvenster van 256K tokens van het standaard Qwen3.5-model. Naast “Thinking” en “Fast” bevat Qwen3.5-Plus bovendien een “Auto”-modus met adaptief denken, die naast reasoning ook tools kan gebruiken zoals zoeken en een code interpreter.
Laten we de nieuwe functies van Qwen3.5 eens bekijken:
Net als OpenAI, dat zijn standaard- en Codex-modellen combineerde in de recente GPT-5.3 Codex-release, combineerde Alibaba tekst, visie en UI-interactie in één model.
Qwen3.5 is gezamenlijk getraind op tekst, afbeeldingen, UI-schermafbeeldingen en gestructureerde content. Het ondersteunt visuele vraagbeantwoording, documentbegrip en interpretatie van grafieken/tabellen, en kan pixel-niveau grounding uitvoeren om elementen op het scherm te identificeren en ermee te interacteren.
Dit brengt ons bij de volgende hoofdfocus van het nieuwe Qwen3.5-model. Door uitgebreide training op UI-schermafbeeldingen kan het model mobiele en desktopinterfaces herkennen en erop acteren. Dit stelt het model in staat om meerstapsworkflows uit te voeren zoals:
Dit maakt Qwen3.5 ideaal voor productiviteitsautomatisering. Met natuurlijke taalopdrachten kun je de visuele agent van Qwen laten handelen over meerdere apps heen en complexe workflows afronden. Het model kan zelfs een toestand behouden over lange interactiereeksen, wat robuuste orkestratie van tools en apps mogelijk maakt.
Qwen3.5 is een behoorlijk groot model met in totaal 397 miljard parameters, hoewel slechts 17 miljard per token worden geactiveerd dankzij de mixture-of-experts-architectuur. Kort gezegd: het heeft de intelligentie van een reuzenmodel, met de snelheid en kostenefficiëntie van een veel kleiner model.
Concreet betekent dit dat Qwen3.5 397B-A17B, vergeleken met Qwen3-Max, 19x sneller decodeert bij long-contexttaken (256k tokens) en 8,6x sneller is bij standaardworkflows. Cruciaal is dat deze snelheid niet ten koste gaat van de intelligentie; het model evenaart nog steeds de redeneer- en codeerprestaties van Qwen3-Max en presteert beter dan Qwen3-VL, dankzij de vroege fusie van tekst en video.
Met de verbeterde prestaties zien we ook kostenvoordelen bij dit model.
Ook betekent een native FP8-pijplijn (gegevens verwerken met 8-bit precisie in plaats van de standaard 16-bit) dat Qwen3.5 het benodigde geheugen halveert. Hierdoor kunnen berekeningen sneller plaatsvinden, wat de snelheid met meer dan 10% verbetert op de schaal van biljoenen tokens.
Qwen3.5 heeft bovendien een indrukwekkende vocabulaire van 250k, waardoor het complexe concepten met minder tokens kan uitdrukken. Samen met multi-tokenvoorspellingen kan het model meerdere toekomstige woorden in één stap ‘raden’, wat de tokenkosten met 10–60% verlaagt in 201 talen.
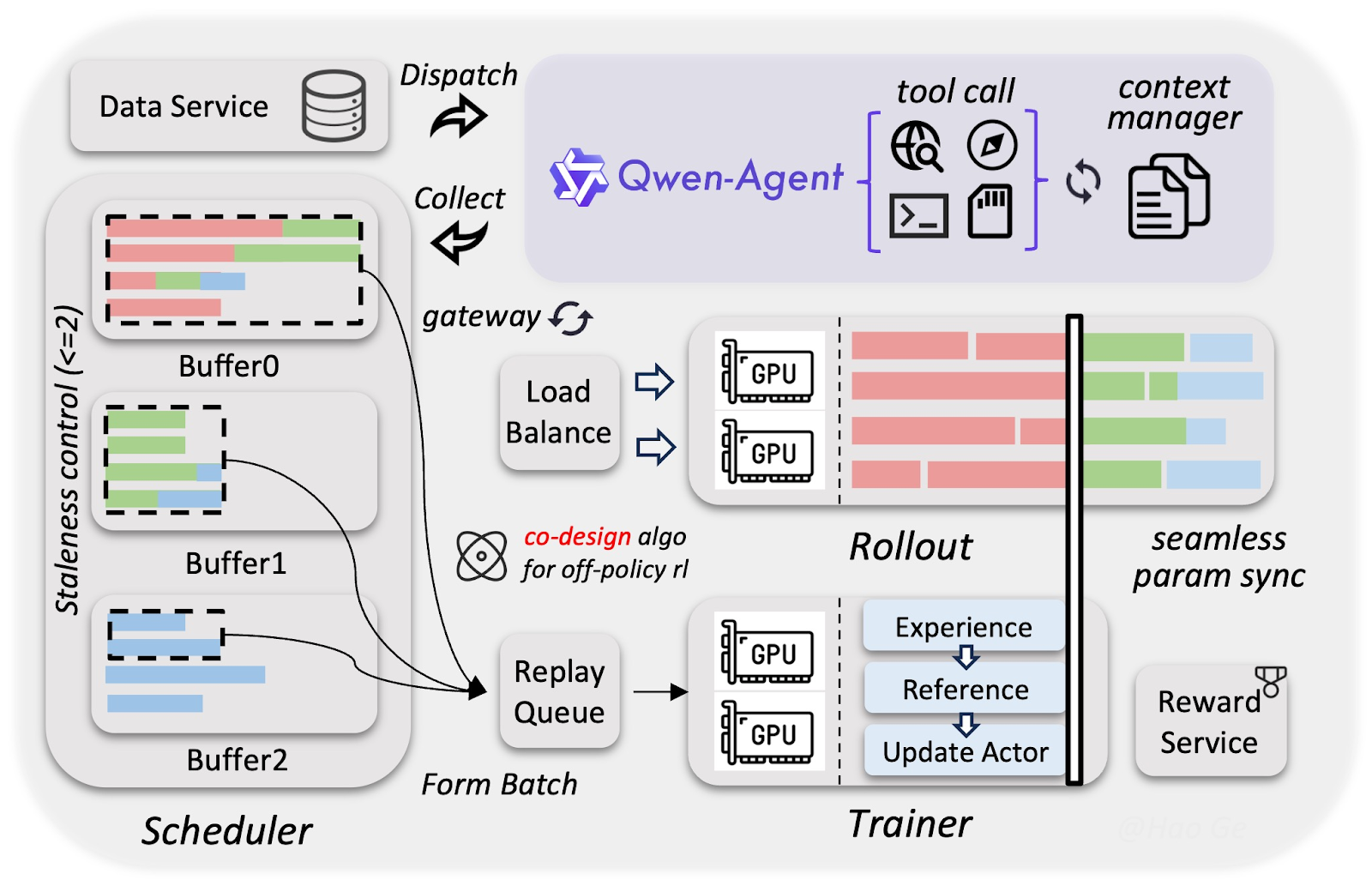
Voor de ontwikkeling van Qwen3.5 is een aangepaste infrastructuur gebruikt die het trainen van multimodale en agentic modellen (bijna) net zo snel en goedkoop maakt als pure tekstmodellen. De speciale aanpak bij het trainen van Qwen3.5 komt neer op drie kerncomponenten:
Het team van Alibaba verzamelde veel meer visueel-tekstdata dan voor de Qwen3-modelfamilie, maar filterde deze zeer streng om invoer van hoge kwaliteit te garanderen. Dankzij de resulterende hoogwaardige dataset kan het model met 397B parameters zich meten met veel grotere modellen met 1T parameters, zoals Qwen3-Max.
De visuele en taaldelen zijn afzonderlijk, maar gelijktijdig getraind. Doordat geen van beide hoeft te wachten tot de ander klaar is met rekenen, zorgt de overlap voor bijna 100% trainingsthroughput vergeleken met pure tekstmodellen.
Met FP8-compressie (cijfers opslaan met de helft van het aantal bits) en speculatieve decodering (vooruit gokken) voeren agents duizenden taken gelijktijdig uit terwijl de training op de achtergrond doorgaat zonder te wachten. Dit versnelde de training zonder noemenswaardig kwaliteitsverlies, waardoor Qwen3.5 complexe agentvaardigheden, zoals UI-klikken of meerstapstaken, 3–5x sneller leerde.
De prestaties van Alibaba’s nieuwe model zijn al gevalideerd op veel taken. We focussen op de resultaten in de speerpunten agentic en multimodale workflows, en op meer algemene redeneervaardigheden.
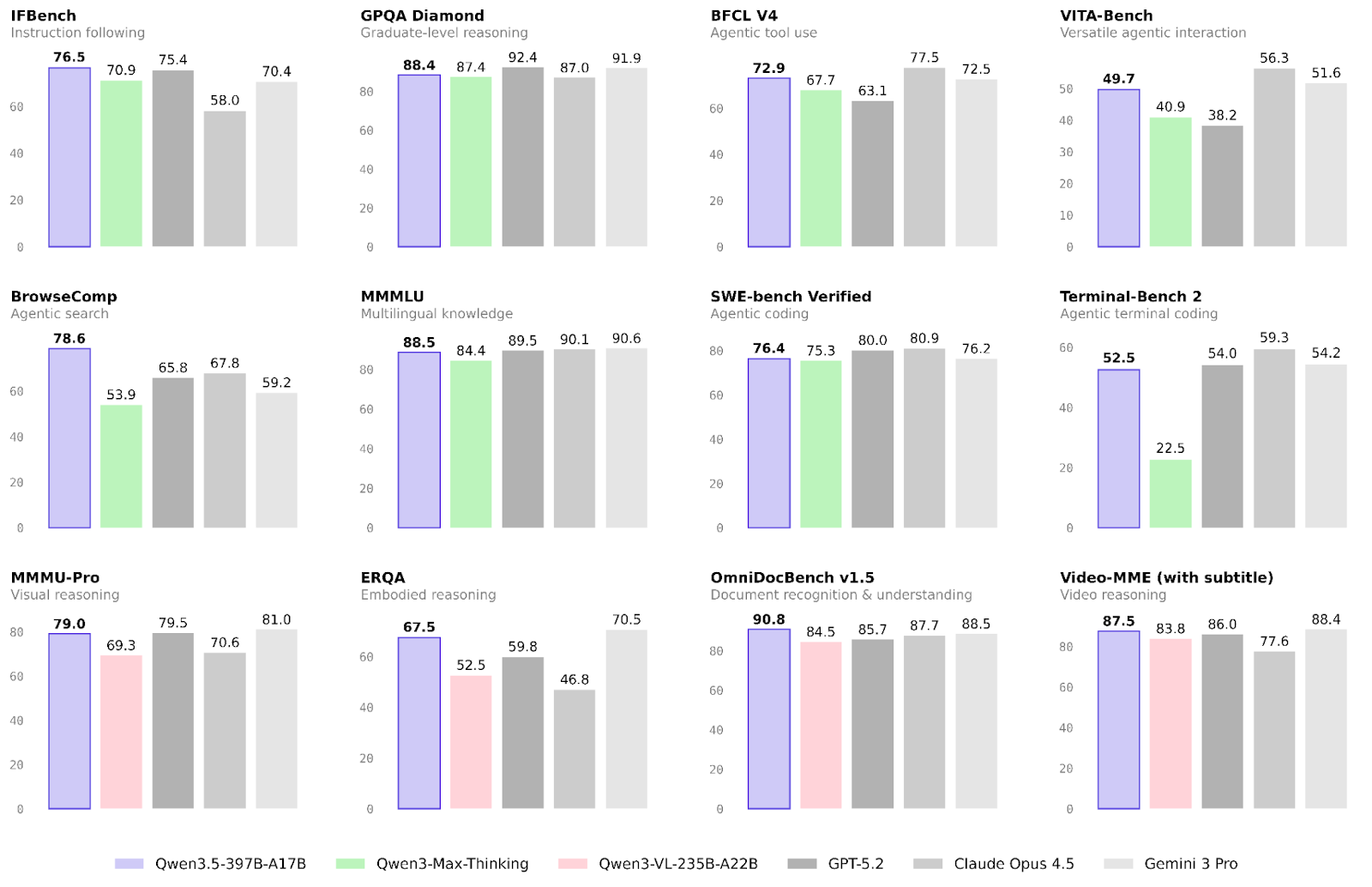
Het gebied waarin Qwen3.5 de grootste vooruitgang boekt ten opzichte van de Qwen3-familie is agentic workflows.
Multimodaliteit is nog een gebied dat aanzienlijke verbeteringen laat zien ten opzichte van de vorige modelfamilie. Dit geldt vooral voor embodied reasoning en documentherkenning:
Redeneren en kennis waren duidelijk niet de hoofdprioriteiten van deze release. Toch zijn er lichte verbeteringen, vooral op het gebied van betrouwbaarheid.
Net als eerdere modellen is Qwen3.5 open source en op meerdere manieren te gebruiken: direct in de chatapp, via de API, gedownload voor lokale deployment of geïntegreerd in maatwerkopstellingen.
Je hebt direct toegang tot Qwen3.5 op chat.qwen.ai in de vertrouwde chatinterface.
De keuzelijst voor modelselectie biedt zowel Qwen3.5-397B-A17B als Qwen3.5-Plus, plus enkele eerdere modellen uit de Qwen3-familie en Qwen2.5-Max.
API-toegang voor Qwen 3.5 werkt hetzelfde als voor Qwen3: OpenAI-compatibele endpoints via ModelScope (gratis tier, dagelijkse quota) of DashScope/Model Studio (betaald, inclusief Qwen3.5-Plus). Werk je model-ID bij naar qwen3.5-397b-a17b of qwen3.5-plus en je bent klaar om te gaan.
Zoals eerder vermeld zijn de modelgewichten van Qwen3.5-397B-A17B vrijgegeven onder de Apache 2.0-licentie. Je kunt Qwen3.5 lokaal draaien met tools zoals Ollama, LM Studio of vLLM.
De gewichten zijn te downloaden van:
Met nieuwe visuele agents, verbeterde prestaties en kostenoptimalisatie is de release van Qwen3.5 indrukwekkend. Het zet niet alleen druk op andere Chinese modellen, maar daagt ook modellen van OpenAI en Anthropic uit.
Zoals bij andere releases dit jaar, zoals GPT-5.3-Codex en Claude Opus 4.6, verschuift de focus duidelijk richting agentic AI. Het snelle succes van OpenClaw heeft laten zien dat mensen snakken naar praktische AI-toepassingen, en modellen als Qwen3.5, Seedance 2.0 en de geruchten over een aanstaande release van DeepSeek tonen aan dat China snel uitgroeit tot marktleider in AI-modellen.
Topcursussen over AI
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
