

Program
Dasar-Dasar Agen Kecerdasan Buatan
6 Hr
Alibaba baru saja meluncurkan model bahasa besar terbarunya, Qwen3.5. Model terbaru ini hadir merespons rilis baru seperti GPT-5.3 Codex dan Claude Opus 4.6, yang keduanya mengesankan kami.
Menurut Alibaba, Qwen 3.5 "dibangun untuk era AI agen", dan model visi-bahasa ini dikabarkan lebih murah dan lebih efisien daripada pendahulunya, dengan menorehkan statistik kinerja kelas terdepan yang mengesankan di beberapa tolok ukur.
Alibaba juga merilis Qwen3.5-Plus, versi premium dari model ini dengan jendela konteks 1 juta token, yang menargetkan Gemini 3.
Dalam artikel ini, saya akan memandu Anda melalui fitur-fitur baru utama Qwen3.5 dan Qwen3.5-Plus, meninjau perbandingannya dengan pesaing, melihat hasil tolok ukurnya, dan menjelaskan cara mengakses model-model baru ini.
Jangan lupa lihat juga panduan kami untuk model pesaing terbaru, seperti Claude Sonnet 4.6 atau GPT-5.3 Instant.
Qwen3.5 adalah generasi terbaru dalam seri model bahasa besar (LLM) Alibaba, Qwen3.5-397B-A17B. Berbeda dengan keluarga model Qwen3 sebelumnya, Qwen3.5 menggabungkan model-model khusus ke dalam satu model visi-bahasa native. Seperti model Qwen sebelumnya, model ini bersifat open-source di bawah lisensi Apache 2.0.
Model ini diposisikan sebagai model fondasi serbaguna untuk kebutuhan konsumen dan perusahaan, serta dirancang untuk alur kerja multimodal dan agen secara native. Qwen3.5-397B-A17B menawarkan dua mode:
Qwen3.5-Plus adalah layanan hosted yang hanya tersedia melalui API dan sesuai dengan Qwen3.5-397B-A17B, serta bukan model dengan bobot terbuka. Catatan rilis sempat agak membingungkan dalam hal ini: penyebutan Qwen3.5-Plus bisa terbaca sebagai model terpisah, padahal sebenarnya ini adalah layanan proprieter Alibaba yang dibangun di atas model yang sama.
Walau Qwen3.5-Plus berbasis model Qwen3.5-397B-A17B, ada beberapa perbedaan yang perlu diperhatikan. Model ini hanya dapat diakses melalui Alibaba Cloud Model Studio dengan skema bayar per token, dan melalui UI Qwen Chat dengan akses terbatas.
Qwen3.5-Plus menggunakan jendela konteks yang diperluas hingga 1 juta token, dibandingkan jendela konteks 256K token pada model Qwen3.5 standar. Selain "Thinking" dan "Fast", Qwen3.5-Plus juga menyertakan mode "Auto" dengan penalaran adaptif, yang di samping berpikir, dapat menggunakan alat seperti penelusuran dan interpreter kode.
Mari kita lihat beberapa fitur baru yang tersedia di Qwen3.5:
Mirip dengan OpenAI yang menggabungkan model standar dan Codex dalam rilis GPT-5.3 Codex terbaru, Alibaba menggabungkan teks, visi, dan interaksi UI dalam satu model.
Qwen3.5 dilatih secara bersama pada teks, gambar, tangkapan layar UI, dan konten terstruktur. Model ini mendukung tanya jawab visual, pemahaman dokumen, serta interpretasi bagan/tabel, dan menangani grounding tingkat piksel untuk mengidentifikasi dan berinteraksi dengan elemen di layar.
Ini membawa kita ke fokus utama berikutnya dari model Qwen3.5. Berkat pelatihan intensif pada tangkapan layar UI, model ini dapat mengenali dan bertindak pada antarmuka seluler dan desktop. Ini memungkinkan model mengeksekusi alur kerja multi-langkah seperti:
Ini menjadikan Qwen3.5 ideal untuk otomasi produktivitas. Dengan instruksi bahasa alami, Anda dapat membuat agen visual Qwen bertindak di berbagai aplikasi, menyelesaikan alur kerja kompleks. Model ini bahkan dapat mempertahankan state selama rangkaian interaksi panjang, memungkinkan orkestrasi alat dan aplikasi yang andal.
Qwen3.5 adalah model yang cukup besar, dengan total 397 miliar parameter, meskipun hanya 17 miliar yang diaktifkan per token berkat arsitektur mixture-of-experts. Intinya, ini berarti model ini memiliki kecerdasan model raksasa, dengan kecepatan dan efisiensi biaya layaknya model yang jauh lebih kecil.
Secara praktis, dibandingkan Qwen3-Max, Qwen3.5 397B-A17B 19x lebih cepat dalam dekode tugas konteks panjang (256k token) dan 8,6x lebih cepat untuk alur kerja standar. Yang penting, kecepatan ini tidak mengorbankan kecerdasan; model ini tetap menyamai kinerja penalaran dan pengkodean Qwen3-Max dan melampaui Qwen3-VL, berkat penggabungan awal teks dan video.
Seiring peningkatan kinerja, kami juga melihat efisiensi biaya pada model ini.
Demikian pula, pipeline FP8 native (memproses data dalam presisi 8-bit, alih-alih standar 16-bit) membuat Qwen3.5 mengurangi kebutuhan memori hingga 50%. Ini berarti perhitungan dapat berlangsung lebih cepat, meningkatkan kecepatan lebih dari 10% pada skala triliunan token.
Qwen3.5 juga memiliki kosakata yang mengesankan sebesar 250 ribu, memungkinkannya mengekspresikan konsep kompleks dengan lebih sedikit token. Bersama dengan prediksi multi-token, model ini dapat "menebak" beberapa kata berikutnya dalam satu langkah, mengurangi biaya token sebesar 10–60% di 201 bahasa.
Proses pengembangan Qwen3.5 menggunakan infrastruktur khusus yang membuat pelatihan model multimodal dan agen (hampir) sama cepat dan murahnya dengan model teks murni. Pendekatan khusus dalam melatih Qwen3.5 bertumpu pada tiga komponen kunci:
Tim Alibaba mengumpulkan jauh lebih banyak data visual-teks dibandingkan untuk keluarga model Qwen3, namun menyaringnya dengan sangat ketat guna memastikan masukan berkualitas tinggi. Dataset berkualitas tinggi yang dihasilkan memungkinkan model 397B parameter menyamai kecerdasan model 1T parameter yang jauh lebih besar, seperti Qwen3-Max.
Bagian visi dan bahasa dilatih secara terpisah namun simultan. Karena keduanya tidak perlu saling menunggu saat yang lain menghitung, tumpang tindih yang dihasilkan memberikan throughput pelatihan hampir 100% dibandingkan model teks murni.
Dengan menggunakan kompresi FP8 (pada dasarnya menyimpan angka dengan separuh jumlah bit) dan decoding spekulatif (menebak ke depan), agen menjalankan ribuan tugas secara simultan sementara pelatihan berlangsung di latar belakang tanpa menunggu. Ini mempercepat pelatihan tanpa kehilangan kualitas signifikan, sehingga Qwen3.5 mempelajari keterampilan agen yang kompleks, seperti mengeklik UI atau tugas multi-langkah, 3–5x lebih cepat.
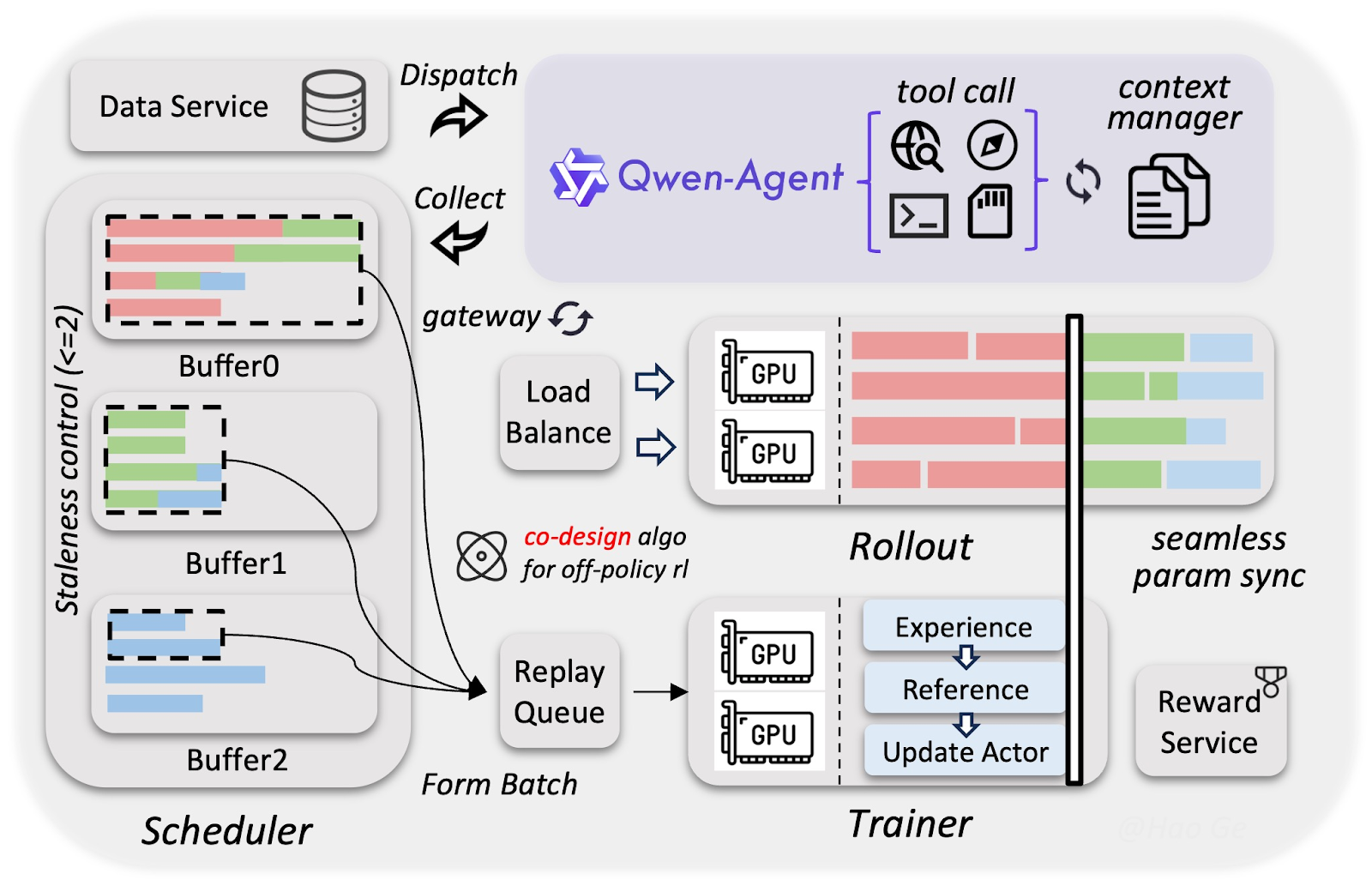
Kinerja model baru Alibaba ini telah divalidasi di banyak tugas. Kami akan berfokus pada hasil di area alur kerja agen dan multimodal, serta kemampuan penalaran yang lebih umum.
Area di mana Qwen3.5 paling meningkat dibanding keluarga Qwen3 adalah alur kerja agen.
Multimodalitas adalah bidang lain yang mengalami peningkatan signifikan dibanding keluarga model sebelumnya. Hal ini terutama berlaku untuk penalaran embodied dan pengenalan dokumen:
Penalaran dan pengetahuan jelas bukan fokus utama rilis ini. Meski begitu, ada peningkatan kecil di area ini, terutama dalam hal keandalan.
Seperti model sebelumnya, model Qwen3.5 bersifat open source dan dapat digunakan dalam berbagai cara: langsung di aplikasi chat, melalui API, diunduh untuk penerapan lokal, atau diintegrasikan ke dalam pengaturan kustom.
Anda dapat mengakses Qwen3.5 langsung di chat.qwen.ai dalam antarmuka chat yang familiar.
Menu dropdown pemilihan model menawarkan model Qwen3.5-397B-A17B dan Qwen3.5-Plus, serta beberapa model sebelumnya dari keluarga model Qwen3 dan Qwen2.5-Max.
Akses API Qwen 3.5 bekerja sama seperti Qwen3: endpoint yang kompatibel dengan OpenAI melalui ModelScope (tingkat gratis, kuota harian) atau DashScope/Model Studio (berbayar, termasuk Qwen3.5-Plus). Perbarui ID model Anda ke qwen3.5-397b-a17b atau qwen3.5-plus dan Anda siap menggunakannya.
Seperti disebutkan sebelumnya, bobot model Qwen3.5-397B-A17B dirilis di bawah lisensi Apache 2.0. Anda dapat menjalankan Qwen3.5 secara lokal menggunakan alat seperti Ollama, LM Studio, atau vLLM.
Bobot dapat diunduh dari:
Dengan agen visual baru, peningkatan kinerja, dan optimasi biaya, rilis Qwen3.5 terbilang mengesankan, menekan bukan hanya model-model China lainnya tetapi juga menantang model dari OpenAI dan Anthropic.
Seperti rilis baru lainnya tahun ini, seperti GPT-5.3-Codex dan Claude Opus 4.6, fokus jelas bergeser ke AI agen. Keberhasilan cepat OpenClaw membuktikan bahwa orang menginginkan penggunaan AI yang praktis, dan model seperti Qwen3.5, Seedance 2.0, serta kabar rilis mendatang dari DeepSeek menunjukkan bahwa China dengan cepat menjadi pemimpin pasar dalam model AI.
Kursus AI Teratas
Program
Kursus
Kursus
blogs
Dario Radečić
15 mnt
blogs
David Woods
13 mnt
blogs
Javier Canales Luna
14 mnt
blogs
Hugo Bowne-Anderson
13 mnt
