

Cursus
Principes fondamentaux des agents IA
6 h
Alibaba vient de dévoiler son dernier grand modèle de langage, Qwen3.5. Cette sortie intervient dans la foulée de nouveaux lancements comme GPT-5.3 Codex et Claude Opus 4.6, qui nous ont tous deux impressionnés.
Selon Alibaba, Qwen 3.5 est « conçu pour l’ère de l’IA agentique ». Ce modèle de vision-langage serait moins coûteux et plus efficace que son prédécesseur, avec des performances de pointe très solides sur plusieurs benchmarks.
Alibaba lance également Qwen3.5‑Plus, une version premium dotée d’une fenêtre de contexte d’1 million de tokens, qui vise clairement Gemini 3.
Dans cet article, je vous présente les nouveautés clés de Qwen3.5 et Qwen3.5‑Plus, leur positionnement face aux concurrents, un aperçu des benchmarks, et comment accéder à ces nouveaux modèles.
Découvrez aussi nos guides sur les derniers modèles concurrents, comme Claude Sonnet 4.6 ou GPT-5.3 Instant.
Qwen3.5 est la dernière génération de la série de grands modèles de langage (LLM) d’Alibaba, Qwen3.5‑397B‑A17B. Contrairement à la famille Qwen3 précédente, Qwen3.5 fusionne des modèles spécialisés en un modèle vision‑langage natif unique. Comme les précédents Qwen, il est open source sous licence Apache 2.0.
Il se positionne comme un modèle de fondation polyvalent pour des cas d’usage grand public et entreprise, pensé pour des workflows multimodaux et agentiques natifs. Qwen3.5‑397B‑A17B propose deux modes :
Qwen3.5‑Plus est un service hébergé, accessible uniquement via API, correspondant à Qwen3.5‑397B‑A17B, et n’est pas un modèle open‑weight en tant que tel. La note de version peut prêter à confusion : la mention de Qwen3.5‑Plus pourrait laisser penser à un modèle distinct, mais il s’agit en réalité du service propriétaire d’Alibaba reposant sur le même modèle.
Bien que Qwen3.5‑Plus s’appuie sur le modèle Qwen3.5‑397B‑A17B, quelques différences sont à noter. L’accès se fait uniquement via l’Alibaba Cloud Model Studio à la consommation (pay‑per‑token), et via l’interface Qwen Chat avec un accès limité.
Qwen3.5‑Plus offre une fenêtre de contexte étendue à 1 million de tokens, contre 256 k pour le modèle Qwen3.5 standard. En plus des modes « Thinking » et « Fast », Qwen3.5‑Plus ajoute un mode « Auto » avec raisonnement adaptatif qui, en plus du raisonnement, peut utiliser des outils comme la recherche web et un interpréteur de code.
Passons en revue quelques nouveautés proposées par Qwen3.5 :
À l’instar d’OpenAI qui a fusionné ses modèles standard et Codex dans la récente version GPT‑5.3 Codex, Alibaba a combiné texte, vision et interaction avec l’interface utilisateur dans un seul modèle.
Qwen3.5 a été entraîné conjointement sur du texte, des images, des captures d’écrans d’IU et des contenus structurés. Il gère les questions‑réponses visuelles, la compréhension de documents, l’interprétation de graphiques/tableaux, et assure un ancrage au niveau du pixel pour identifier et interagir avec les éléments à l’écran.
C’est le deuxième axe majeur du nouveau modèle Qwen3.5. Grâce à un entraînement intensif sur des captures d’écrans d’interfaces, le modèle reconnaît et agit sur des interfaces mobiles et desktop. Il peut ainsi exécuter des workflows multi‑étapes comme :
Idéal pour l’automatisation de la productivité, Qwen3.5 permet, via des instructions en langage naturel, à l’agent visuel d’agir à travers plusieurs applications et d’achever des workflows complexes. Il peut même maintenir un état sur de longues séquences d’interactions, facilitant une orchestration robuste d’outils et d’apps.
Qwen3.5 est un modèle très massif, avec 397 milliards de paramètres au total, dont seulement 17 milliards sont activés par token grâce à l’architecture mixture‑of‑experts. En clair, il allie l’intelligence d’un très grand modèle à la vitesse et aux coûts d’un modèle bien plus compact.
Concrètement, par rapport à Qwen3‑Max, Qwen3.5 397B‑A17B est 19 fois plus rapide au décodage sur des tâches à long contexte (256 k tokens) et 8,6 fois plus rapide sur des workflows standards. Et ce gain de vitesse ne se fait pas au détriment de l’intelligence : il égale les performances de raisonnement et de code de Qwen3‑Max et dépasse Qwen3‑VL, grâce à une fusion précoce du texte et de la vidéo.
Ces gains de performance s’accompagnent d’économies notables.
De plus, un pipeline natif en FP8 (traitement en précision 8 bits plutôt que 16 bits) réduit de 50 % la mémoire nécessaire à l’exécution. Les calculs s’effectuent donc plus vite, avec plus de 10 % de gain de vitesse à l’échelle du billion de tokens.
Qwen3.5 embarque aussi un vocabulaire conséquent de 250 k, lui permettant d’exprimer des concepts complexes avec moins de tokens. Associé aux prédictions multi‑tokens, le modèle peut « prédire » plusieurs mots futurs en une seule étape, réduisant les coûts de tokens de 10 à 60 % dans 201 langues.
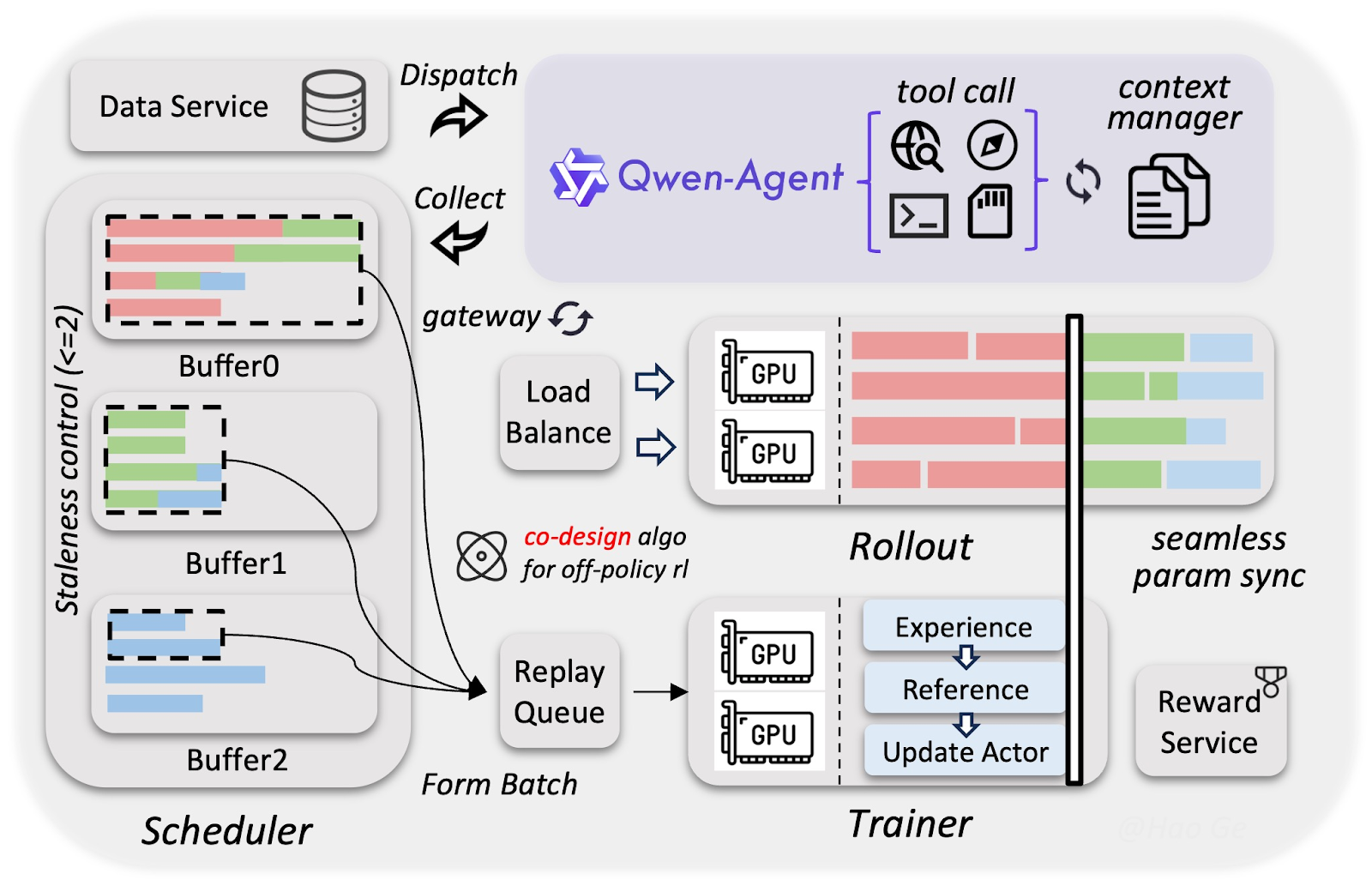
Le développement de Qwen3.5 s’appuie sur une infrastructure sur mesure qui rend l’entraînement de modèles multimodaux et agentiques (presque) aussi rapide et économique que celui de modèles texte purs. L’approche particulière retenue repose sur trois piliers :
L’équipe d’Alibaba a collecté bien plus de données visuo‑textuelles que pour la famille Qwen3, mais avec un filtrage très strict pour garantir une haute qualité. Ce jeu de données de grande qualité permet au modèle de 397 Md de paramètres d’égaler l’intelligence de modèles bien plus vastes à 1 T de paramètres, comme Qwen3‑Max.
Les composantes vision et langage ont été entraînées séparément, mais en parallèle. Comme aucune ne doit attendre l’autre, ce recouvrement aboutit à un débit d’entraînement presque équivalent à 100 % de celui des modèles texte purs.
Grâce à la compression FP8 (stockage des nombres avec deux fois moins de bits) et au décodage spéculatif (anticipation), des agents exécutent des milliers de tâches simultanément tandis que l’entraînement se poursuit en arrière‑plan sans attente. La formation s’en trouve accélérée sans perte de qualité notable : Qwen3.5 a appris des compétences agentiques complexes, comme le clic dans l’IU ou les tâches multi‑étapes, 3 à 5 fois plus vite.
Les performances du nouveau modèle d’Alibaba ont déjà été validées sur de nombreuses tâches. Nous mettons l’accent sur les résultats liés aux workflows agentiques et multimodaux, ainsi que sur les capacités de raisonnement plus générales.
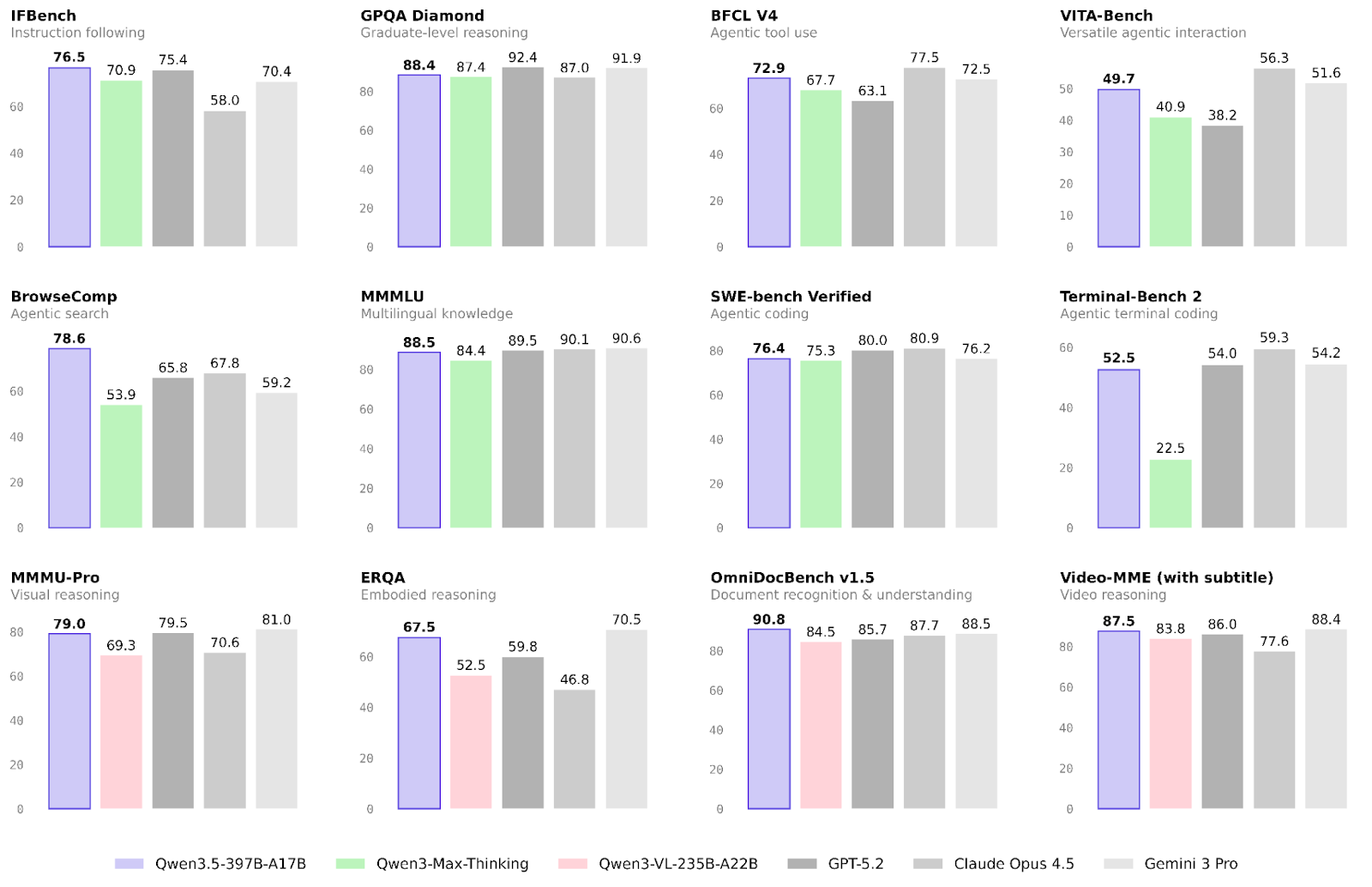
Là où Qwen3.5 progresse le plus face à la famille Qwen3, c’est sur les workflows agentiques.
La multimodalité progresse aussi nettement par rapport à la génération précédente, notamment en raisonnement incarné et en reconnaissance de documents :
Le raisonnement et les connaissances n’étaient clairement pas le cœur de cette mise à jour. On observe toutefois de légères améliorations, notamment sur la fiabilité.
Comme les modèles précédents, les modèles Qwen3.5 sont open source et accessibles de plusieurs façons : directement via l’application de chat, par API, en téléchargement pour un déploiement local, ou intégrés à des configurations sur mesure.
Vous pouvez accéder à Qwen3.5 directement sur chat.qwen.ai via une interface familière.
Le menu de sélection du modèle propose Qwen3.5‑397B‑A17B et Qwen3.5‑Plus, ainsi que quelques modèles antérieurs de la famille Qwen3 et Qwen2.5‑Max.
L’accès API à Qwen 3.5 fonctionne comme pour Qwen3 : endpoints compatibles OpenAI via ModelScope (palier gratuit, quotas quotidiens) ou DashScope/Model Studio (payant, inclut Qwen3.5‑Plus). Mettez à jour l’ID du modèle en qwen3.5-397b-a17b ou qwen3.5-plus et vous êtes prêt.
Comme indiqué, les poids du modèle Qwen3.5‑397B‑A17B sont publiés sous licence Apache 2.0. Vous pouvez exécuter Qwen3.5 en local avec des outils comme Ollama, LM Studio ou vLLM.
Les poids sont disponibles au téléchargement sur :
Avec ses nouveaux agents visuels, ses performances en hausse et son optimisation des coûts, Qwen3.5 marque les esprits, en mettant la pression non seulement sur les modèles chinois, mais aussi sur ceux d’OpenAI et d’Anthropic.
Comme pour d’autres lancements cette année, tels que GPT‑5.3‑Codex et Claude Opus 4.6, la tendance se déplace clairement vers l’IA agentique. Le succès rapide d’OpenClaw montre l’appétence pour des usages concrets de l’IA, et des modèles comme Qwen3.5, Seedance 2.0, ou la rumeur d’une prochaine sortie de DeepSeek, indiquent que la Chine s’impose rapidement comme leader du marché des modèles d’IA.
Meilleures formations en IA
Cursus
Cours
Cours