

Programma
Nozioni di base sugli agenti AI
6 h
Alibaba ha appena presentato il suo ultimo large language model, Qwen3.5. Questo nuovo modello arriva in risposta a recenti rilasci come GPT-5.3 Codex e Claude Opus 4.6, che ci hanno entrambi colpito.
Secondo Alibaba, Qwen 3.5 è "costruito per l’era dell’AI agentica" e il modello vision-language sarebbe più economico ed efficiente del suo predecessore, con statistiche di performance di frontiera in diversi benchmark.
Alibaba rilascia anche Qwen3.5-Plus, una versione premium del modello con una finestra di contesto da 1 milione di token, che punta direttamente a Gemini 3.
In questo articolo ti guiderò tra le novità principali di Qwen3.5 e Qwen3.5-Plus, esaminando come se la cavano rispetto ai concorrenti, cosa dicono i benchmark e come puoi accedere ai nuovi modelli.
Dai un’occhiata anche alle nostre guide sui modelli concorrenti più recenti, come Claude Sonnet 4.6 o GPT-5.3 Instant.
Qwen3.5 è l’ultima generazione della serie di large language model (LLM) di Alibaba, Qwen3.5-397B-A17B. A differenza della precedente famiglia di modelli Qwen3, Qwen3.5 combina modelli specializzati in un unico modello nativo vision-language. Come i precedenti Qwen, è open source sotto licenza Apache 2.0.
È proposto come foundation model generico per casi d’uso consumer e enterprise ed è progettato per workflow nativamente multimodali e agentici. Qwen3.5-397B-A17B offre due modalità:
Qwen3.5-Plus è un servizio hosted, solo API, corrispondente a Qwen3.5-397B-A17B e non è di per sé un modello con pesi aperti. Le note di rilascio su questo punto erano un po’ ambigue: il riferimento a Qwen3.5-Plus potrebbe far pensare a un modello separato, ma in realtà è il servizio proprietario di Alibaba costruito sullo stesso modello.
Sebbene Qwen3.5-Plus si basi sul modello Qwen3.5-397B-A17B, ci sono alcune differenze da notare. È accessibile solo tramite Alibaba Cloud Model Studio con pagamento a token, e tramite la Qwen Chat UI con accesso limitato.
Qwen3.5-Plus utilizza una finestra di contesto estesa di 1 milione di token, rispetto alla finestra da 256K token del modello Qwen3.5 standard. Oltre a “Thinking” e “Fast”, Qwen3.5-Plus include anche una modalità “Auto” con thinking adattivo che, oltre al ragionamento, può usare strumenti come la ricerca e un interprete di codice.
Vediamo alcune delle nuove funzionalità disponibili con Qwen3.5:
Analogamente a OpenAI, che ha unito i suoi modelli standard e Codex nel recente rilascio di GPT-5.3 Codex, Alibaba ha combinato testo, visione e interazione con l’interfaccia in un unico modello.
Qwen3.5 è stato addestrato congiuntamente su testo, immagini, screenshot di interfacce e contenuti strutturati. Supporta il visual question answering, la comprensione di documenti e l’interpretazione di grafici/tabelle, e gestisce il grounding a livello di pixel per identificare e interagire con elementi a schermo.
Questo ci porta al prossimo punto focale del nuovo Qwen3.5. Grazie all’ampio addestramento su screenshot di UI, il modello può riconoscere e agire su interfacce mobile e desktop. Questo consente di eseguire workflow multi-step come:
Questo rende Qwen3.5 ideale per l’automazione della produttività. Usando istruzioni in linguaggio naturale, puoi consentire all’agente visivo Qwen di agire su più app, completando workflow complessi. Può persino mantenere uno stato su lunghe sequenze di interazione, abilitando un’orchestrazione solida di strumenti e app.
Qwen3.5 è un modello piuttosto grande, con 397 miliardi di parametri totali, anche se solo 17 miliardi sono attivati per token, grazie all’architettura mixture-of-experts. In sostanza, significa che ha l’intelligenza di un modello gigante, con la velocità e l’efficienza di costo di uno molto più piccolo.
In pratica, rispetto a Qwen3-Max, Qwen3.5 397B-A17B è 19 volte più veloce nel decodificare compiti a lungo contesto (256k token) e 8,6 volte più veloce per i workflow standard. Fondamentale, questa velocità non compromette l’intelligenza; eguaglia comunque il ragionamento e le prestazioni di coding di Qwen3-Max e supera Qwen3-VL, grazie alla fusione precoce di testo e video.
Con le migliori prestazioni, vediamo anche efficienze sui costi con questo modello.
Allo stesso modo, una pipeline nativa FP8 (elaborazione dei dati a 8 bit di precisione, piuttosto che i canonici 16 bit) fa sì che Qwen3.5 dimezzi la memoria necessaria all’esecuzione. Questo consente calcoli più rapidi, migliorando le velocità di oltre il 10% alla scala del trilione di token.
Qwen3.5 ha anche un lessico notevole da 250k, che gli permette di esprimere concetti complessi con meno token. Insieme alle predizioni multi-token, il modello può “indovinare” diverse parole future in un singolo step, riducendo i costi in token dal 10% al 60% in 201 lingue.
Lo sviluppo di Qwen3.5 ha utilizzato un’infrastruttura personalizzata che rende l’addestramento di modelli multimodali e agentici (quasi) veloce ed economico quanto quello dei modelli puramente testuali. L’approccio speciale all’addestramento di Qwen3.5 si basa su tre componenti chiave:
Il team di Alibaba ha raccolto molti più dati visivo-testuali rispetto alla famiglia Qwen3, ma li ha filtrati in modo molto rigoroso per garantire input di alta qualità. Il dataset risultante consente al modello da 397B parametri di eguagliare le capacità di modelli molto più grandi da 1T parametri, come Qwen3-Max.
Le parti di visione e linguaggio sono state addestrate separatamente ma in parallelo. Poiché nessuna delle due deve attendere i calcoli dell’altra, la sovrapposizione risultante offre una velocità di addestramento quasi al 100% rispetto ai modelli puramente testuali.
Usando la compressione FP8 (in sostanza memorizzando i numeri con metà dei bit) e la decodifica speculativa (anticipando le previsioni), gli agenti eseguono migliaia di task simultaneamente mentre l’addestramento procede in background senza attese. Questo ha accelerato l’addestramento senza perdite significative di qualità, così Qwen3.5 ha imparato abilità agentiche complesse, come il clic su UI o i task multi-step, 3-5 volte più velocemente.
Le prestazioni del nuovo modello di Alibaba sono già state validate su molti compiti. Ci concentreremo sui risultati nelle aree chiave di workflow agentici e multimodali, oltre che sulle capacità generali di ragionamento.
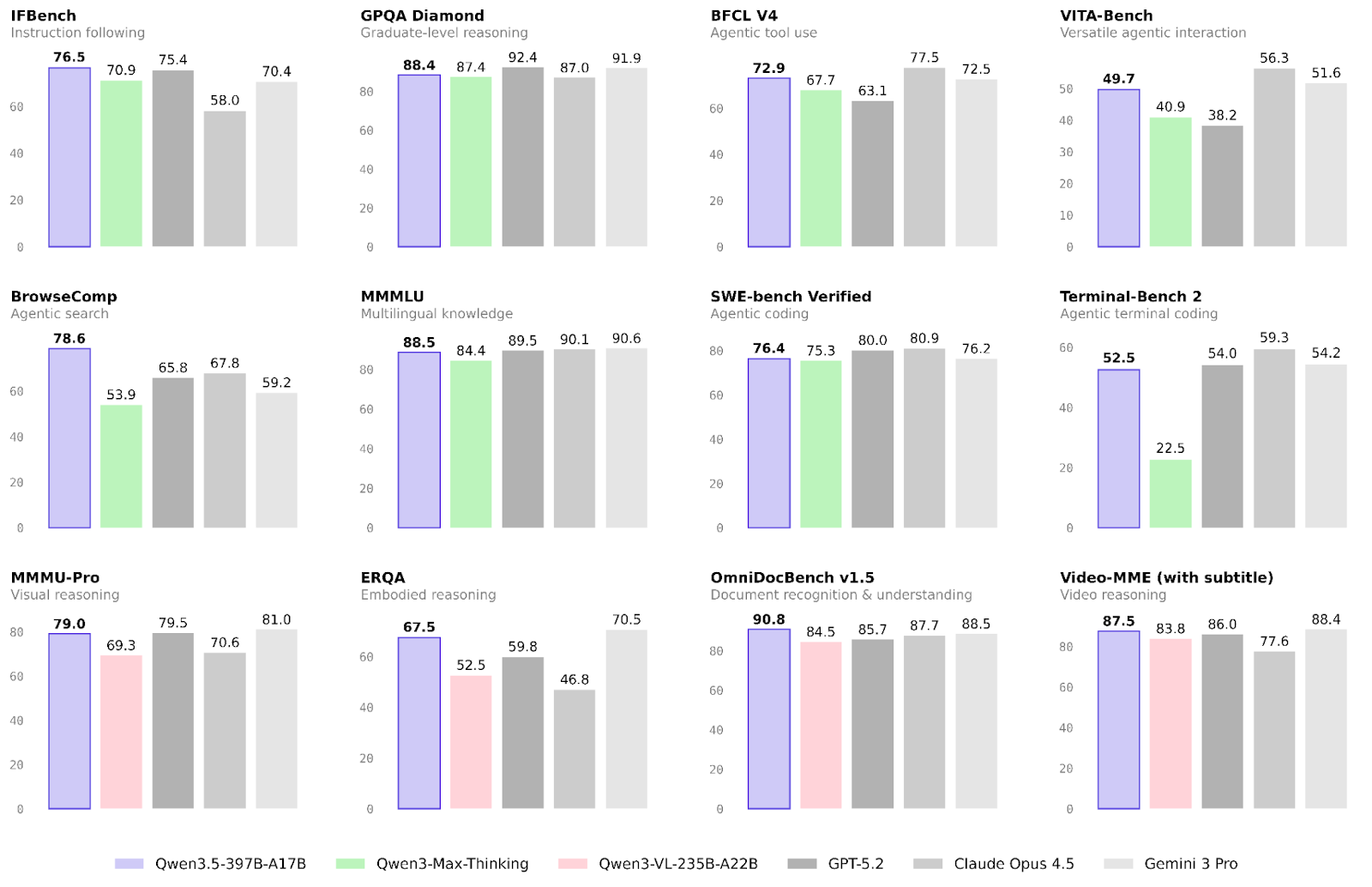
L’area in cui Qwen3.5 è migliorato di più rispetto alla famiglia Qwen3 sono i workflow agentici.
La multimodalità è un altro ambito che ha visto miglioramenti significativi rispetto alla famiglia precedente. Ciò è particolarmente vero per l’embodied reasoning e il riconoscimento di documenti:
Ragionamento e conoscenza non sono chiaramente le aree principali di questo rilascio. Ciononostante, ci sono lievi miglioramenti, soprattutto in termini di affidabilità.
Come per i modelli precedenti, i modelli Qwen3.5 sono open source e possono essere utilizzati in vari modi: direttamente nell’app di chat, via API, scaricati per il deploy locale o integrati in setup personalizzati.
Puoi accedere a Qwen3.5 direttamente su chat.qwen.ai nella consueta interfaccia di chat.
Il menu a tendina per la selezione del modello offre sia Qwen3.5-397B-A17B che Qwen3.5-Plus, oltre ad alcuni modelli precedenti della famiglia Qwen3 e Qwen2.5-Max.
L’accesso API a Qwen 3.5 funziona come per Qwen3: endpoint compatibili con OpenAI tramite ModelScope (free tier, quote giornaliere) o DashScope/Model Studio (a pagamento, include Qwen3.5-Plus). Aggiorna l’ID modello a qwen3.5-397b-a17b o qwen3.5-plus e sei pronto.
Come detto, i pesi del modello Qwen3.5-397B-A17B sono stati rilasciati sotto licenza Apache 2.0. Puoi eseguire Qwen3.5 in locale con strumenti come Ollama, LM Studio o vLLM.
I pesi possono essere scaricati da:
Con nuovi agenti visivi, prestazioni migliorate e ottimizzazione dei costi, il rilascio di Qwen3.5 è notevole e mette pressione non solo sugli altri modelli cinesi ma anche su quelli di OpenAI e Anthropic.
Come per altri rilasci di quest’anno, come GPT-5.3-Codex e Claude Opus 4.6, l’attenzione si sta chiaramente spostando verso l’AI agentica. Il rapido successo di OpenClaw ha dimostrato che le persone desiderano usi pratici dell’AI, e modelli come Qwen3.5, Seedance 2.0 e il presunto prossimo rilascio di DeepSeek mostrano che la Cina sta rapidamente diventando il leader di mercato nei modelli di AI.
I migliori corsi di AI
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

