

Programa
Fundamentos de agentes de IA
6 h
A Alibaba acaba de apresentar seu mais novo modelo de linguagem, o Qwen3.5. Ele chega na esteira de lançamentos como o GPT-5.3 Codex e o Claude Opus 4.6, que nos impressionaram.
Segundo a Alibaba, o Qwen 3.5 foi "feito para a era da IA agentiva". O modelo de visão e linguagem promete ser mais barato e eficiente que seu antecessor, entregando números de performance de ponta em vários benchmarks.
A Alibaba também está lançando o Qwen3.5-Plus, uma versão premium com janela de contexto de 1 milhão de tokens, mirando diretamente no Gemini 3.
Neste artigo, eu mostro os novos recursos do Qwen3.5 e do Qwen3.5-Plus, comparo com os concorrentes, trago os benchmarks e explico como acessar os novos modelos.
Aproveite para conferir também nossos guias sobre os modelos concorrentes mais recentes, como o Claude Sonnet 4.6 e o GPT-5.3 Instant.
O Qwen3.5 é a nova geração da série de modelos de linguagem (LLM) da Alibaba, Qwen3.5-397B-A17B. Diferente da família de modelos Qwen3 anterior, o Qwen3.5 unifica modelos especializados em um único modelo nativo de visão e linguagem. Assim como versões anteriores do Qwen, ele é open source sob a licença Apache 2.0.
Ele é posicionado como um foundation model de uso geral para casos de uso de consumo e corporativos, projetado para fluxos de trabalho multimodais e agentivos nativos. O Qwen3.5-397B-A17B oferece dois modos:
O Qwen3.5-Plus é um serviço hospedado, acessível apenas por API, correspondente ao Qwen3.5-397B-A17B e não é um modelo com pesos abertos. A nota de lançamento gerou um pouco de confusão: a menção ao Qwen3.5-Plus pode parecer um modelo separado, mas na prática é o serviço proprietário da Alibaba construído sobre o mesmo modelo.
Embora baseado no Qwen3.5-397B-A17B, há algumas diferenças. O acesso é apenas via Alibaba Cloud Model Studio, com cobrança por token, e pela interface Qwen Chat com acesso limitado.
O Qwen3.5-Plus usa uma janela de contexto estendida de 1 milhão de tokens, ante os 256 mil tokens do Qwen3.5 padrão. Além dos modos "Thinking" e "Fast", o Qwen3.5-Plus inclui ainda o modo "Auto", com raciocínio adaptativo, que além de pensar consegue usar ferramentas como busca e interpretador de código.
Veja alguns dos novos recursos do Qwen3.5:
Assim como a OpenAI unificou seus modelos padrão e Codex no recente GPT-5.3 Codex, a Alibaba combinou texto, visão e interação com UI em um único modelo.
O Qwen3.5 foi treinado conjuntamente com texto, imagens, capturas de tela de interfaces e conteúdo estruturado. Ele suporta perguntas e respostas visuais, entendimento de documentos e interpretação de gráficos/tabelas, além de fazer grounding em nível de pixel para identificar e interagir com elementos na tela.
Esse é outro foco central do novo Qwen3.5. Graças ao treinamento extenso com capturas de tela de interfaces, o modelo reconhece e age em interfaces móveis e de desktop. Isso permite executar fluxos de trabalho de múltiplas etapas, como:
Isso torna o Qwen3.5 ideal para automação de produtividade. Com instruções em linguagem natural, você pode permitir que o agente visual do Qwen atue em vários apps, concluindo fluxos de trabalho complexos. Ele ainda mantém estado ao longo de sequências longas de interação, possibilitando uma orquestração robusta de ferramentas e aplicativos.
O Qwen3.5 é um modelo bem grande, com 397 bilhões de parâmetros no total, embora apenas 17 bilhões sejam ativados por token graças à arquitetura de mixture-of-experts. Em essência, ele tem a inteligência de um modelo gigante, com a velocidade e o custo de um modelo bem menor.
Na prática, isso significa que, em comparação ao Qwen3-Max, o Qwen3.5 397B-A17B é 19x mais rápido para decodificar tarefas de longo contexto (256k tokens) e 8,6x mais rápido em fluxos padrão. O mais importante: essa velocidade não compromete a inteligência; ele mantém o desempenho de raciocínio e código do Qwen3-Max e supera o Qwen3-VL, graças à fusão precoce de texto e vídeo.
Com a performance melhor, também vêm ganhos de custo.
Da mesma forma, um pipeline nativo em FP8 (processando dados em 8 bits, em vez dos 16 bits padrão) reduz em 50% a memória necessária para rodar o modelo. Isso acelera os cálculos, aumentando a velocidade em mais de 10% na escala de trilhões de tokens.
O Qwen3.5 também traz um vocabulário robusto de 250k, permitindo expressar conceitos complexos com menos tokens. Com predições multi-token, o modelo consegue "prever" várias palavras futuras em um único passo, reduzindo o custo de tokens entre 10% e 60% em 201 idiomas.
O desenvolvimento do Qwen3.5 usou uma infraestrutura personalizada que torna o treino de modelos multimodais e agentivos quase tão rápido e barato quanto o de modelos apenas de texto. A abordagem especial no treinamento do Qwen3.5 se resume a três pilares:
A equipe da Alibaba coletou muito mais dados visuais e de texto do que para a família Qwen3, mas fez uma filtragem rígida para garantir alta qualidade. O conjunto resultante permite que o modelo de 397B parâmetros atinja a inteligência de modelos de 1T parâmetros, como o Qwen3-Max.
As partes de visão e linguagem foram treinadas separadamente, porém em paralelo. Como uma não precisa esperar a outra, o overlap resultante entrega quase 100% da taxa de treinamento de modelos puramente textuais.
Usando compressão FP8 (armazenando números com metade dos bits) e decodificação especulativa (prevendo adiante), agentes executam milhares de tarefas simultaneamente enquanto o treino ocorre em background, sem espera. Isso acelerou o treinamento sem perda significativa de qualidade, fazendo o Qwen3.5 aprender habilidades agentivas complexas, como cliques em UI e tarefas de múltiplas etapas, de 3 a 5 vezes mais rápido.
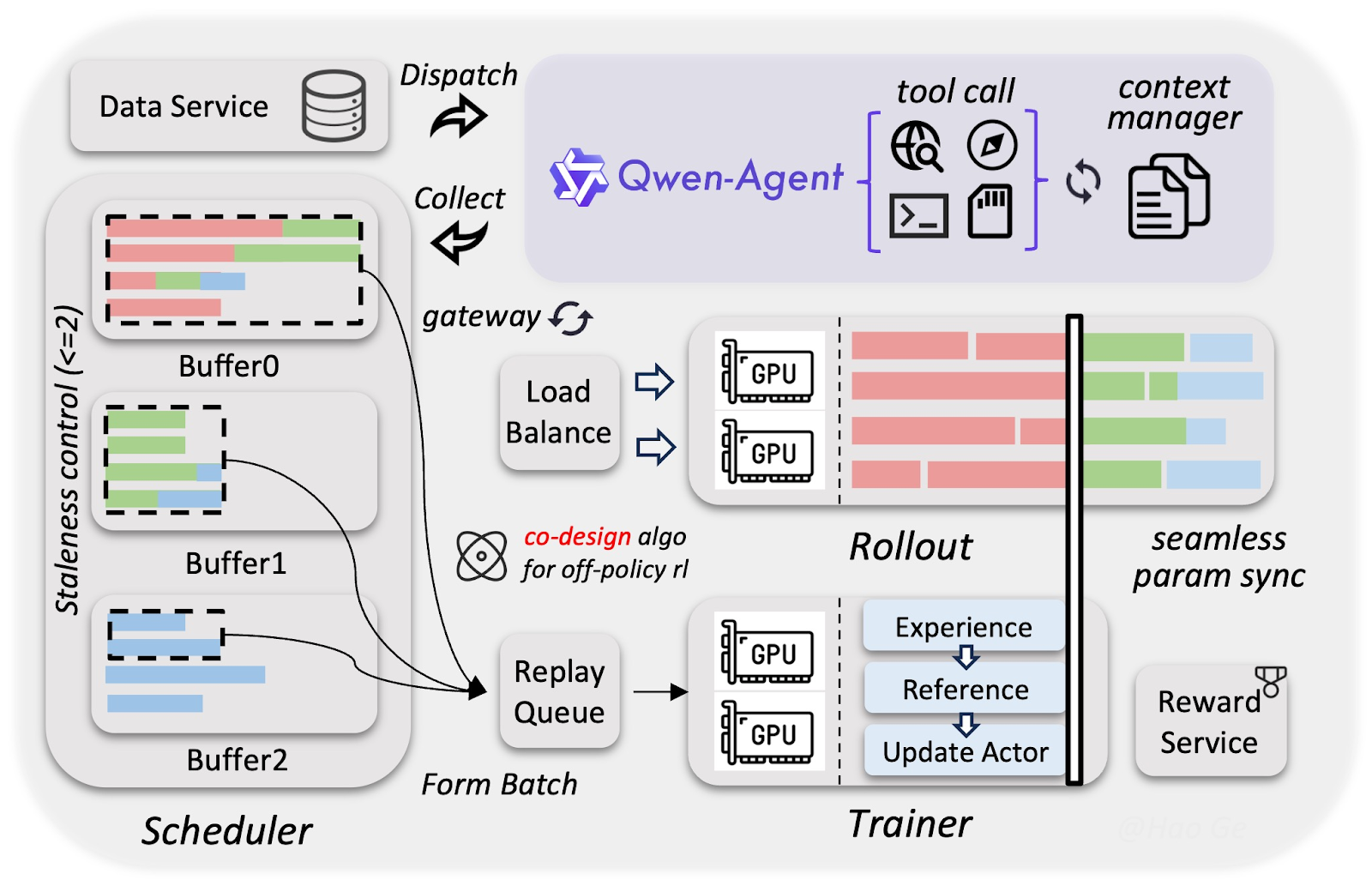
O desempenho do novo modelo da Alibaba já foi validado em muitas tarefas. Vamos focar nos resultados para fluxos agentivos e multimodais e em habilidades gerais de raciocínio.
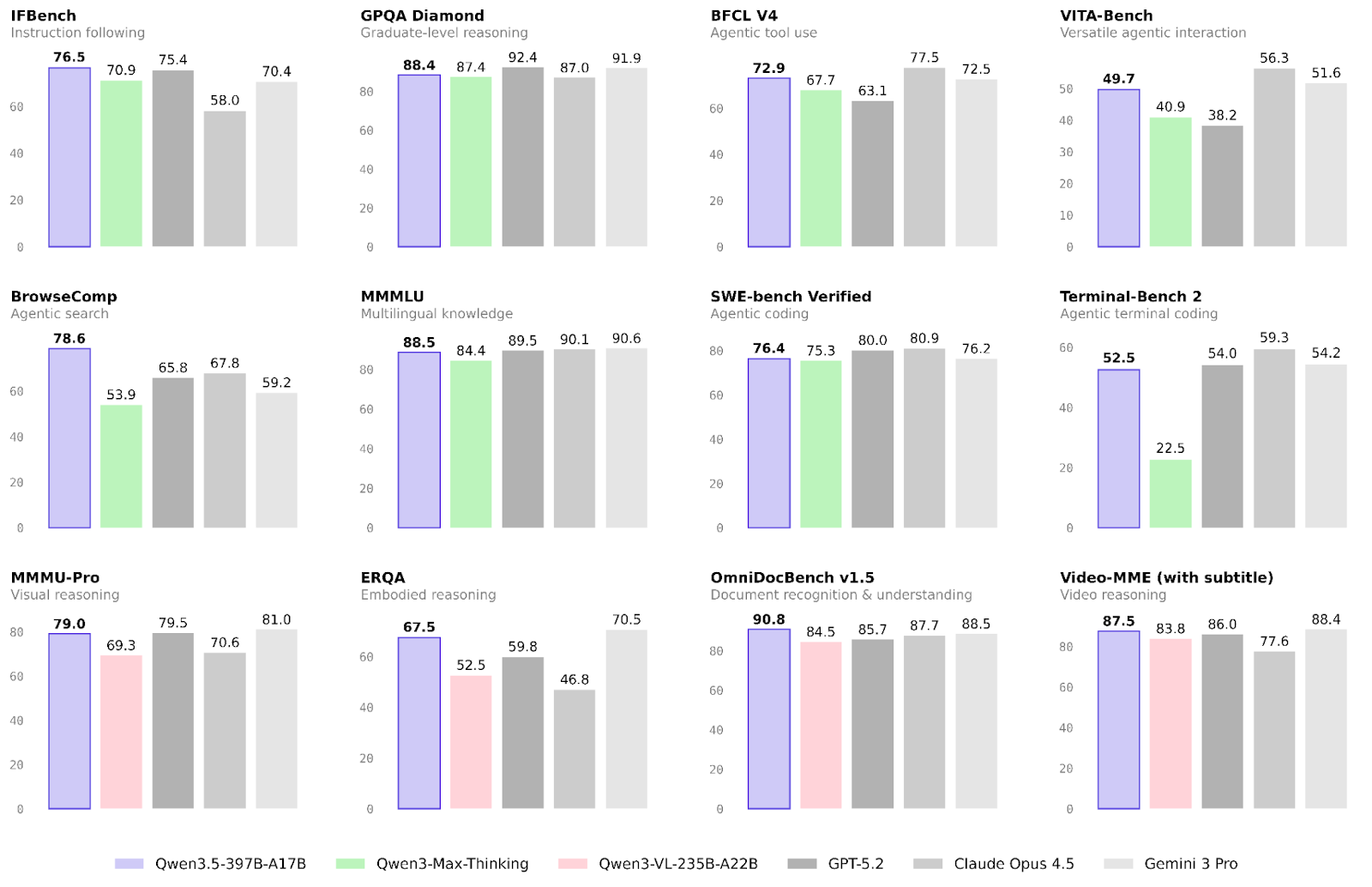
A maior evolução do Qwen3.5 em relação à família Qwen3 está nos fluxos agentivos.
A multimodalidade também apresentou avanços significativos em relação à família anterior, especialmente em raciocínio incorporado e reconhecimento de documentos:
Raciocínio e conhecimento claramente não foram o foco principal deste release. Ainda assim, há leves melhorias, especialmente em confiabilidade.
Como nos modelos anteriores, os Qwen3.5 são open source e podem ser usados de várias formas: direto no app de chat, via API, baixando para uso local ou integrando em setups personalizados.
Você pode acessar o Qwen3.5 diretamente em chat.qwen.ai, na interface de chat já conhecida.
No seletor de modelos, você encontra o Qwen3.5-397B-A17B e o Qwen3.5-Plus, além de alguns modelos anteriores da família Qwen3 e o Qwen2.5-Max.
O acesso à API do Qwen 3.5 funciona como no Qwen3: endpoints compatíveis com OpenAI via ModelScope (camada gratuita, cotas diárias) ou DashScope/Model Studio (pago, inclui Qwen3.5-Plus). Atualize o ID do modelo para qwen3.5-397b-a17b ou qwen3.5-plus e pronto.
Como mencionado, os pesos do Qwen3.5-397B-A17B foram lançados sob a licença Apache 2.0. Você pode rodar o Qwen3.5 localmente com ferramentas como Ollama, LM Studio ou vLLM.
Os pesos podem ser baixados em:
Com novos agentes visuais, mais performance e otimização de custos, o lançamento do Qwen3.5 impressiona e pressiona não só outros modelos chineses, como também rivais da OpenAI e da Anthropic.
Assim como em outros lançamentos deste ano, como GPT-5.3-Codex e Claude Opus 4.6, o foco está migrando para a IA agentiva. O sucesso rápido do OpenClaw mostrou que as pessoas querem usos práticos de IA, e modelos como Qwen3.5, Seedance 2.0 e o rumor do próximo lançamento da DeepSeek indicam que a China caminha para a liderança no mercado de modelos de IA.
Principais cursos de IA
Programa
Curso
Curso
blog
Adel Nehme
15 min
blog
Josep Ferrer
8 min
blog
Javier Canales Luna
9 min
blog
Abid Ali Awan
9 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita




