

Tracks
Cơ bản về Trợ lý Trí tuệ Nhân tạo
6 giờ
Alibaba vừa ra mắt mô hình ngôn ngữ lớn mới nhất, Qwen3.5. Mô hình này xuất hiện sau các bản phát hành mới như GPT-5.3 Codex và Claude Opus 4.6, cả hai đều đã gây ấn tượng mạnh với chúng tôi.
Theo Alibaba, Qwen 3.5 được “xây dựng cho kỷ nguyên AI tác tử”, và mô hình ngôn ngữ–thị giác này được cho là rẻ hơn và hiệu quả hơn thế hệ trước, đạt một số chỉ số hiệu năng ấn tượng ở nhiều bài kiểm tra chuẩn cấp độ tiên phong.
Alibaba cũng ra mắt Qwen3.5-Plus, phiên bản cao cấp của mô hình với cửa sổ ngữ cảnh 1 triệu token, hướng thẳng tới đối thủ Gemini 3.
Trong bài viết này, tôi sẽ giới thiệu các tính năng mới quan trọng của Qwen3.5 và Qwen3.5-Plus, đánh giá chúng so với đối thủ, xem xét các điểm chuẩn và cách bạn có thể truy cập các mô hình mới.
Bạn cũng nên xem các hướng dẫn về những mô hình cạnh tranh mới nhất, như Claude Sonnet 4.6 hoặc GPT-5.3 Instant.
Qwen3.5 là thế hệ mới nhất trong dòng mô hình ngôn ngữ lớn (LLM) của Alibaba, Qwen3.5-397B-A17B. Khác với họ mô hình Qwen3 trước đó, Qwen3.5 kết hợp các mô hình chuyên biệt thành một mô hình ngôn ngữ–thị giác bản địa duy nhất. Giống các phiên bản Qwen trước, nó là mã nguồn mở theo giấy phép Apache 2.0.
Mô hình được định vị là mô hình nền tảng đa dụng cho cả người dùng cá nhân và doanh nghiệp, được thiết kế cho quy trình làm việc đa phương thức và tác tử bản địa. Qwen3.5-397B-A17B cung cấp hai chế độ:
Qwen3.5-Plus là dịch vụ được lưu trữ, chỉ truy cập qua API, tương ứng với Qwen3.5-397B-A17B và bản thân không phải mô hình mở trọng số. Ghi chú phát hành có phần gây nhầm lẫn: việc nhắc tới Qwen3.5-Plus có thể được hiểu là một mô hình riêng, nhưng thực tế đây là dịch vụ độc quyền của Alibaba xây dựng trên cùng mô hình.
Dù Qwen3.5-Plus dựa trên mô hình Qwen3.5-397B-A17B, vẫn có một số khác biệt đáng chú ý. Nó chỉ có thể truy cập qua Alibaba Cloud Model Studio theo hình thức trả phí theo token, và qua giao diện Qwen Chat với quyền truy cập hạn chế.
Qwen3.5-Plus dùng cửa sổ ngữ cảnh mở rộng 1 triệu token, so với 256K token của Qwen3.5 tiêu chuẩn. Bên cạnh “Thinking” và “Fast”, Qwen3.5-Plus còn có chế độ “Auto” với tư duy thích ứng, ngoài tư duy còn có thể dùng công cụ như tìm kiếm và trình thông dịch mã.
Hãy xem một số tính năng mới của Qwen3.5:
Tương tự việc OpenAI hợp nhất mô hình tiêu chuẩn và Codex trong bản phát hành GPT-5.3 Codex gần đây, Alibaba kết hợp văn bản, thị giác và tương tác UI trong một mô hình duy nhất.
Qwen3.5 được huấn luyện chung trên văn bản, hình ảnh, ảnh chụp màn hình UI và nội dung có cấu trúc. Nó hỗ trợ hỏi đáp trực quan, hiểu tài liệu, diễn giải biểu đồ/bảng, và xử lý liên kết ở cấp độ điểm ảnh để nhận diện và tương tác với phần tử trên màn hình.
Đây là trọng tâm tiếp theo của Qwen3.5. Nhờ huấn luyện rộng rãi trên ảnh chụp UI, mô hình có thể nhận diện và thao tác trên giao diện di động và máy tính. Điều này cho phép mô hình thực thi các quy trình nhiều bước như:
Điều này khiến Qwen3.5 lý tưởng cho tự động hóa năng suất. Bằng hướng dẫn ngôn ngữ tự nhiên, bạn có thể cho tác tử trực quan của Qwen hành động trên nhiều ứng dụng, hoàn tất các quy trình phức tạp. Nó còn có thể duy trì trạng thái qua các chuỗi tương tác dài, cho phép điều phối công cụ và ứng dụng một cách vững chắc.
Qwen3.5 là mô hình khá lớn, với tổng 397 tỷ tham số, dù chỉ 17 tỷ tham số được kích hoạt trên mỗi token nhờ kiến trúc mixture-of-experts. Về bản chất, điều này có nghĩa là nó có trí tuệ của mô hình khổng lồ, nhưng tốc độ và chi phí như mô hình nhỏ hơn nhiều.
Thực tế, so với Qwen3-Max, Qwen3.5 397B-A17B nhanh hơn 19 lần khi giải mã tác vụ ngữ cảnh dài (256k token) và nhanh hơn 8,6 lần cho quy trình tiêu chuẩn. Quan trọng là tốc độ này không làm giảm trí tuệ; nó vẫn ngang bằng về suy luận và lập trình so với Qwen3-Max và vượt Qwen3-VL nhờ kết hợp sớm văn bản và video.
Cùng với hiệu năng cải thiện, mô hình này cũng mang lại hiệu quả chi phí.
Tương tự, pipeline FP8 bản địa (xử lý dữ liệu ở độ chính xác 8-bit thay vì chuẩn 16-bit) giúp Qwen3.5 cắt giảm 50% bộ nhớ cần thiết để chạy. Điều này cho phép tính toán nhanh hơn, cải thiện tốc độ hơn 10% ở quy mô nghìn tỷ token.
Qwen3.5 còn có bộ từ vựng 250 nghìn ấn tượng, cho phép diễn đạt khái niệm phức tạp với ít token hơn. Cùng với dự đoán đa token, mô hình có thể “đoán” nhiều từ tiếp theo trong một bước, giảm chi phí token từ 10–60% trên 201 ngôn ngữ.
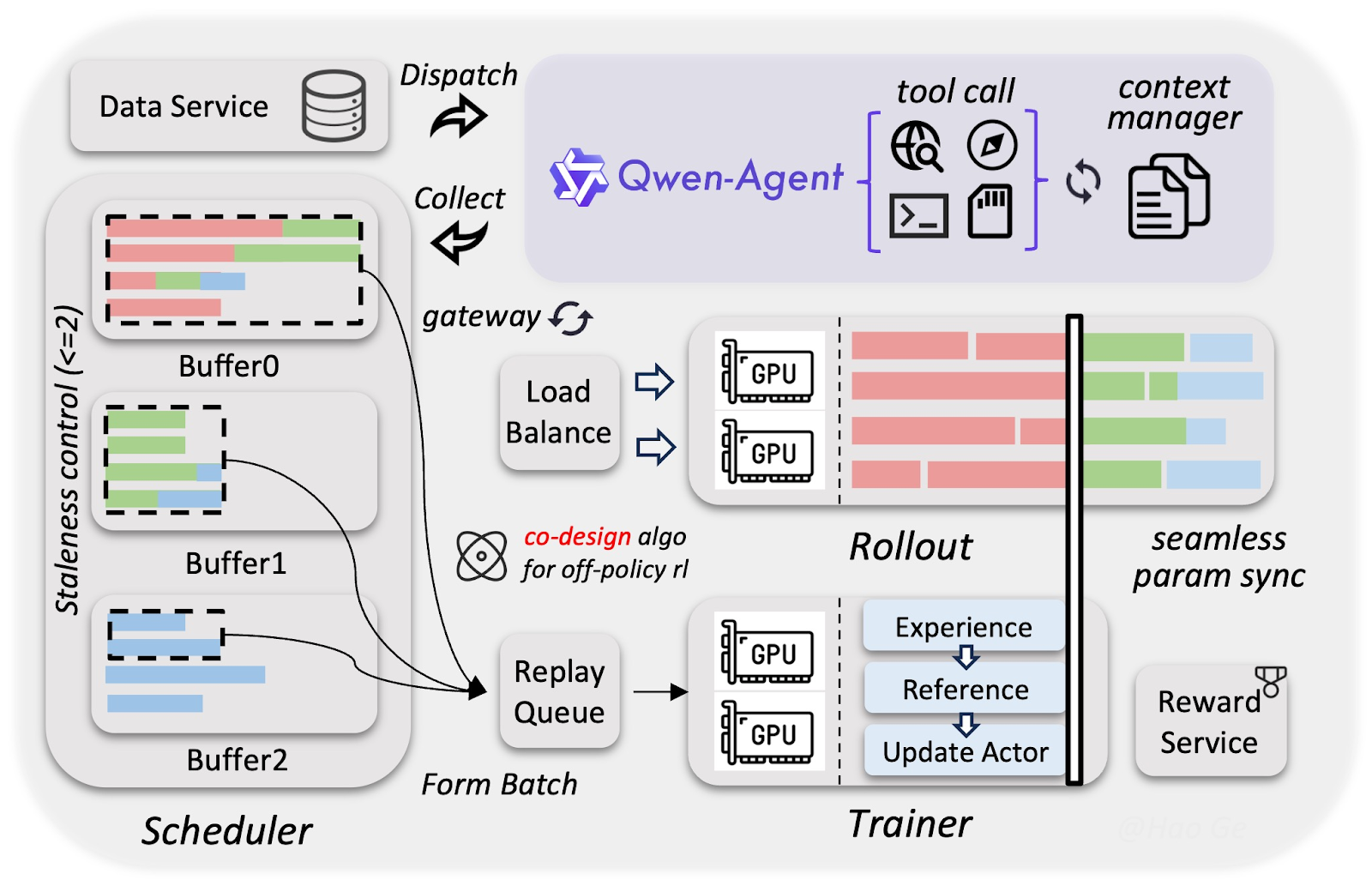
Quy trình phát triển Qwen3.5 sử dụng hạ tầng tùy chỉnh giúp huấn luyện mô hình đa phương thức và tác tử nhanh và rẻ (gần) như mô hình thuần văn bản. Cách tiếp cận đặc biệt trong huấn luyện Qwen3.5 nằm ở ba thành phần chính:
Đội ngũ Alibaba thu thập dữ liệu văn bản–hình ảnh nhiều hơn đáng kể so với họ mô hình Qwen3, nhưng lọc rất nghiêm ngặt để đảm bảo đầu vào chất lượng cao. Bộ dữ liệu chất lượng này giúp mô hình 397B tham số đạt mức thông minh tương đương những mô hình 1T tham số lớn hơn, như Qwen3-Max.
Phần thị giác và ngôn ngữ được huấn luyện tách biệt nhưng đồng thời. Vì không phần nào phải chờ phần kia tính toán, sự chồng lấp này đem lại thông lượng huấn luyện gần như 100% so với mô hình thuần văn bản.
Sử dụng nén FP8 (về cơ bản là lưu trữ số với một nửa số bit) và giải mã suy đoán (đoán trước), các tác tử chạy hàng nghìn tác vụ đồng thời trong khi huấn luyện diễn ra nền mà không cần chờ. Điều này tăng tốc huấn luyện mà không suy giảm chất lượng đáng kể, nên Qwen3.5 học các kỹ năng tác tử phức tạp, như bấm UI hoặc tác vụ nhiều bước, nhanh hơn 3–5 lần.
Hiệu năng của mô hình mới từ Alibaba đã được kiểm chứng trên nhiều tác vụ. Chúng tôi sẽ tập trung vào kết quả trong các lĩnh vực quy trình tác tử và đa phương thức, cũng như kỹ năng suy luận tổng quát.
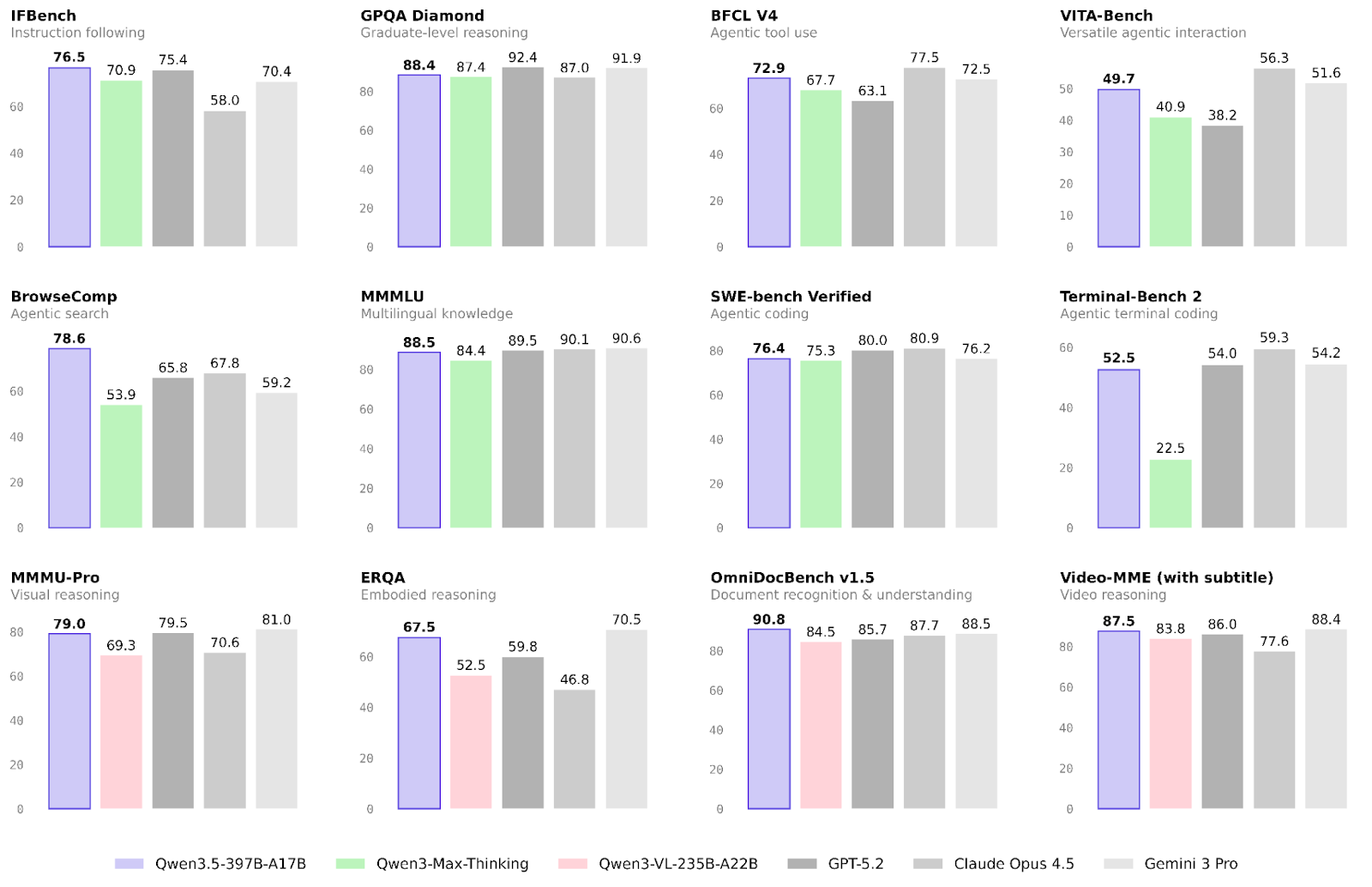
Lĩnh vực Qwen3.5 cải thiện nhiều nhất so với họ Qwen3 là các quy trình tác tử.
Đa phương thức cũng được cải thiện đáng kể so với họ mô hình trước. Điều này đặc biệt đúng với suy luận nhập vai và nhận dạng tài liệu:
Suy luận và kiến thức rõ ràng không phải trọng tâm chính của bản phát hành này. Dù vậy, vẫn có những cải tiến nhỏ, đặc biệt về độ tin cậy.
Tương tự các mô hình trước, Qwen3.5 là mã nguồn mở và có thể dùng theo nhiều cách: trực tiếp trong ứng dụng chat, qua API, tải về để triển khai cục bộ, hoặc tích hợp vào thiết lập tùy chỉnh.
Bạn có thể truy cập Qwen3.5 trực tiếp tại chat.qwen.ai với giao diện quen thuộc.
Danh sách chọn mô hình gồm cả Qwen3.5-397B-A17B và Qwen3.5-Plus, cùng một vài mô hình trước thuộc họ Qwen3 và Qwen2.5-Max.
Truy cập API Qwen 3.5 hoạt động giống Qwen3: endpoint tương thích OpenAI qua ModelScope (miễn phí, hạn ngạch hằng ngày) hoặc DashScope/Model Studio (trả phí, bao gồm Qwen3.5-Plus). Cập nhật ID mô hình thành qwen3.5-397b-a17b hoặc qwen3.5-plus là bạn có thể bắt đầu.
Như đã đề cập, trọng số mô hình Qwen3.5-397B-A17B được phát hành theo giấy phép Apache 2.0. Bạn có thể chạy Qwen3.5 cục bộ bằng các công cụ như Ollama, LM Studio, hoặc vLLM.
Bạn có thể tải trọng số từ:
Với các tác tử trực quan mới, hiệu năng cao hơn và tối ưu chi phí, Qwen3.5 là một bản phát hành ấn tượng, tạo áp lực không chỉ lên các mô hình Trung Quốc khác mà còn thách thức cả mô hình từ OpenAI và Anthropic.
Giống nhiều bản phát hành năm nay như GPT-5.3-Codex và Claude Opus 4.6, trọng tâm đang chuyển dịch rõ rệt sang AI tác tử. Thành công nhanh chóng của OpenClaw cho thấy mọi người đang khao khát các ứng dụng AI thực tiễn, và những mô hình như Qwen3.5, Seedance 2.0, cùng tin đồn về bản phát hành sắp tới từ DeepSeek cho thấy Trung Quốc đang nhanh chóng trở thành thị trường dẫn đầu về mô hình AI.
Các khóa học AI hàng đầu
Tracks
Courses
Courses
blogs
Matt Crabtree
10 phút