

programa
Fundamentos de agentes de IA
6 h
Alibaba acaba de presentar su último modelo de lenguaje grande, Qwen3.5. Este lanzamiento llega como respuesta a novedades recientes como GPT-5.3 Codex y Claude Opus 4.6, que nos dejaron muy buenas sensaciones.
Según Alibaba, Qwen 3.5 está "pensado para la era de la IA agente", y el modelo visión-lenguaje promete ser más barato y eficiente que su predecesor, con métricas de rendimiento muy sólidas en varios benchmarks de primer nivel.
Alibaba también lanza Qwen3.5-Plus, una versión premium con una ventana de contexto de 1 millón de tokens que apunta directamente a Gemini 3.
En este artículo te cuento las novedades clave de Qwen3.5 y Qwen3.5-Plus, cómo se comparan con sus competidores, qué dicen los benchmarks y cómo puedes acceder a estos nuevos modelos.
No te pierdas también nuestras guías de los últimos modelos de la competencia, como Claude Sonnet 4.6 o GPT-5.3 Instant.
Qwen3.5 es la última generación de la serie de modelos de lenguaje grande (LLM) de Alibaba, Qwen3.5-397B-A17B. A diferencia de la familia Qwen3 anterior, Qwen3.5 combina modelos especializados en un único modelo nativo de visión y lenguaje. Como los modelos Qwen anteriores, es de código abierto bajo la licencia Apache 2.0.
Se posiciona como un modelo fundacional de propósito general para casos de uso tanto de consumo como empresariales, y está diseñado para flujos de trabajo multimodales y agentes nativos. Qwen3.5-397B-A17B ofrece dos modos:
Qwen3.5-Plus es un servicio alojado y solo accesible por API que corresponde a Qwen3.5-397B-A17B y no es un modelo de pesos abiertos en sí mismo. La nota de lanzamiento puede resultar algo confusa en este punto: al mencionar Qwen3.5-Plus puede parecer un modelo aparte, pero en realidad es el servicio propietario de Alibaba basado en el mismo modelo.
Aunque Qwen3.5-Plus se basa en el modelo Qwen3.5-397B-A17B, hay diferencias a tener en cuenta. Solo se puede acceder a través de Alibaba Cloud Model Studio con pago por token, y mediante la interfaz Qwen Chat con acceso limitado.
Qwen3.5-Plus utiliza una ventana de contexto ampliada de 1 millón de tokens, frente a los 256K tokens de la versión estándar Qwen3.5. Además de los modos "Thinking" y "Fast", Qwen3.5-Plus incluye un modo "Auto" con razonamiento adaptativo que, además de pensar, puede usar herramientas como búsqueda e intérprete de código.
Veamos algunas de las novedades que trae Qwen3.5:
De forma similar a cómo OpenAI combinó sus modelos estándar y Codex en el reciente GPT-5.3 Codex, Alibaba ha unido texto, visión e interacción con interfaces en un único modelo.
Qwen3.5 se ha entrenado conjuntamente con texto, imágenes, capturas de pantalla de interfaces y contenido estructurado. Soporta preguntas y respuestas visuales, comprensión de documentos e interpretación de gráficos/tablas, y maneja el anclaje a nivel de píxel para identificar e interactuar con elementos en pantalla.
Esto nos lleva al siguiente foco clave del nuevo Qwen3.5. Gracias al amplio entrenamiento con capturas de interfaz, el modelo puede reconocer y actuar sobre interfaces móviles y de escritorio. Esto le permite ejecutar flujos de trabajo multietapa como:
Esto hace que Qwen3.5 sea ideal para automatizar productividad. Con instrucciones en lenguaje natural, puedes permitir que el agente visual de Qwen actúe en varias aplicaciones y complete flujos de trabajo complejos. Incluso puede mantener el estado a lo largo de secuencias largas de interacción, lo que facilita una orquestación sólida de herramientas y apps.
Qwen3.5 es un modelo enorme, con 397 mil millones de parámetros totales, aunque solo activa 17 mil millones por token gracias a la arquitectura mixture-of-experts. En esencia, tiene la inteligencia de un modelo gigante, con la velocidad y eficiencia de coste de uno mucho más pequeño.
En la práctica, esto significa que, frente a Qwen3-Max, Qwen3.5 397B-A17B es 19 veces más rápido decodificando tareas de contexto largo (256k tokens) y 8,6 veces más rápido en flujos estándar. Lo importante: esta velocidad no sacrifica inteligencia; iguala el rendimiento en razonamiento y programación de Qwen3-Max y supera a Qwen3-VL gracias a la fusión temprana de texto y vídeo.
A la par de la mejora de rendimiento, también vemos eficiencias de coste con este modelo.
Del mismo modo, una canalización nativa en FP8 (procesando en 8 bits en lugar de los 16 estándar) reduce un 50% la memoria necesaria para ejecutar Qwen3.5. Así, los cálculos se realizan más rápido, mejorando la velocidad en más de un 10% a escala del billón de tokens.
Qwen3.5 también incorpora un vocabulario impresionante de 250k, que le permite expresar conceptos complejos con menos tokens. Junto con predicciones multi-token, el modelo puede "adivinar" varias palabras futuras en un solo paso, reduciendo el coste de tokens entre un 10% y un 60% en 201 idiomas.
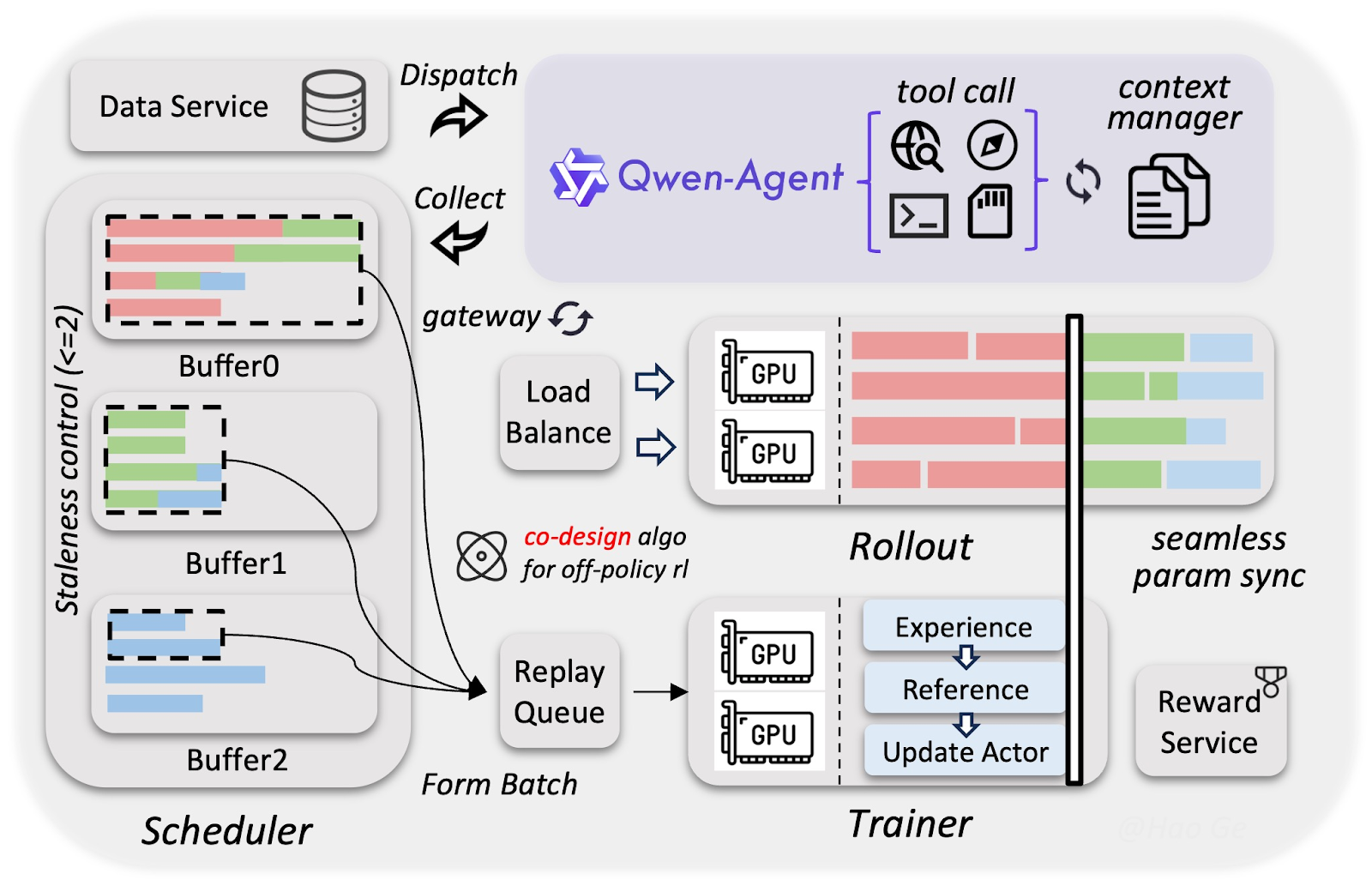
El desarrollo de Qwen3.5 utilizó una infraestructura a medida que hace que entrenar modelos multimodales y con capacidades de agente sea (casi) tan rápido y barato como los modelos puramente de texto. El enfoque especial se apoya en tres componentes clave:
El equipo de Alibaba recopiló muchos más datos texto-visuales que para la familia Qwen3, pero los filtró con gran rigor para asegurar entradas de alta calidad. El resultado permite que el modelo de 397B parámetros iguale la inteligencia de modelos mucho mayores de 1T parámetros, como Qwen3-Max.
Las partes de visión y lenguaje se entrenaron por separado, pero en paralelo. Como ninguna tiene que esperar a la otra, esta superposición logra casi el 100% de rendimiento de entrenamiento frente a modelos solo de texto.
Usando compresión FP8 (almacenando números con la mitad de bits) y decodificación especulativa (anticipación), los agentes ejecutan miles de tareas en paralelo mientras el entrenamiento continúa en segundo plano sin esperas. Esto aceleró el entrenamiento sin pérdidas de calidad significativas, de modo que Qwen3.5 aprendió habilidades de agente complejas, como clics en UI o tareas multietapa, entre 3 y 5 veces más rápido.
El rendimiento del nuevo modelo de Alibaba ya se ha validado en muchas tareas. Vamos a centrarnos en los resultados de flujos de trabajo con agentes y multimodales, además de habilidades generales de razonamiento.
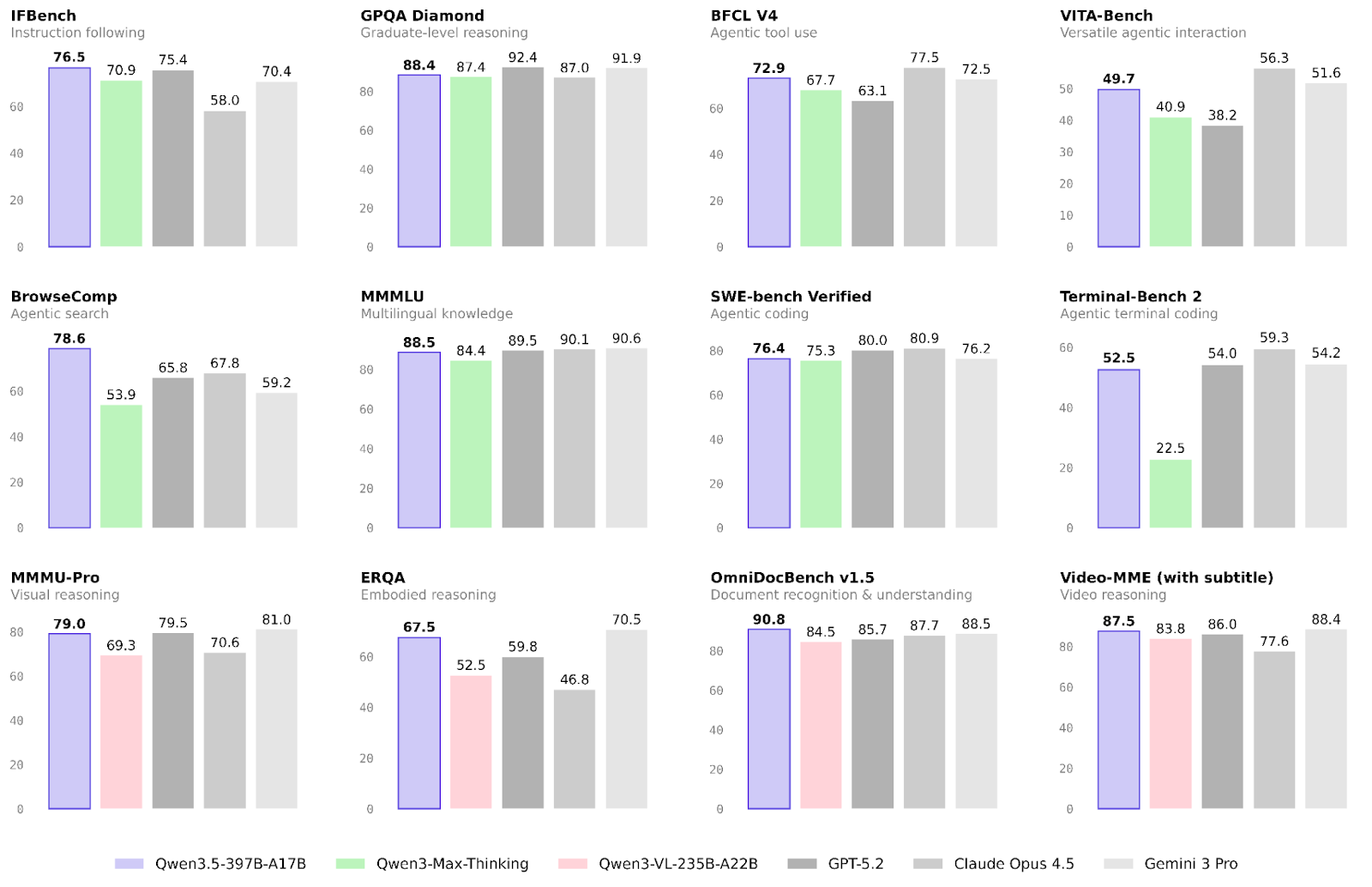
El área donde Qwen3.5 más mejora respecto a la familia Qwen3 es en flujos de trabajo con agentes.
La multimodalidad también ha mejorado notablemente respecto a la familia anterior, especialmente en razonamiento encarnado y reconocimiento de documentos:
El razonamiento y el conocimiento no parecen ser el foco principal de esta versión. Aun así, hay mejoras ligeras, especialmente en fiabilidad.
Como en versiones previas, los modelos Qwen3.5 son de código abierto y pueden usarse de varias formas: directamente en la app de chat, vía API, descargándolos para despliegue local o integrándolos en configuraciones personalizadas.
Puedes acceder a Qwen3.5 directamente en chat.qwen.ai con la interfaz de chat de siempre.
El selector de modelo ofrece tanto Qwen3.5-397B-A17B como Qwen3.5-Plus, además de algunos modelos previos de la familia Qwen3 y Qwen2.5-Max.
El acceso a la API de Qwen 3.5 funciona igual que en Qwen3: endpoints compatibles con OpenAI vía ModelScope (nivel gratuito, cupos diarios) o DashScope/Model Studio (de pago, incluye Qwen3.5-Plus). Actualiza tu ID de modelo a qwen3.5-397b-a17b o qwen3.5-plus y listo.
Como ya se mencionó, los pesos del modelo Qwen3.5-397B-A17B se publicaron bajo la licencia Apache 2.0. Puedes ejecutar Qwen3.5 en local con herramientas como Ollama, LM Studio o vLLM.
Puedes descargar los pesos desde:
Con sus nuevos agentes visuales, el aumento de rendimiento y la optimización de costes, Qwen3.5 llega con fuerza, presionando no solo a otros modelos chinos, sino también a los de OpenAI y Anthropic.
Como en otros lanzamientos de este año, como GPT-5.3 Codex y Claude Opus 4.6, el foco se desplaza claramente hacia la IA con agentes. El éxito fulgurante de OpenClaw ha demostrado que la gente quiere usos prácticos de la IA, y modelos como Qwen3.5, Seedance 2.0 y el rumoreado próximo lanzamiento de DeepSeek muestran que China está posicionándose rápidamente como líder del mercado en modelos de IA.
Los mejores cursos de IA
programa
Curso
Curso
blog
Abid Ali Awan
10 min
blog
Josep Ferrer
8 min
Tutorial
Moez Ali
Tutorial
Zoumana Keita
Tutorial
Zoumana Keita



