

Lernpfad
KI-Agent-Grundlagen
6 Std.
Alibaba hat soeben sein neuestes großes Sprachmodell vorgestellt: Qwen3.5. Das Modell erscheint als Antwort auf neue Releases wie GPT-5.3 Codex und Claude Opus 4.6, die beide überzeugt haben.
Laut Alibaba ist Qwen 3.5 „für das Zeitalter agentischer KI gebaut“. Das Vision-Language-Modell soll günstiger und effizienter sein als sein Vorgänger und zeigt in mehreren Benchmarks beeindruckende Werte auf Spitzenniveau.
Außerdem bringt Alibaba Qwen3.5-Plus heraus, eine Premium-Variante mit einem Kontextfenster von 1 Million Tokens – klar mit Gemini 3 im Visier.
In diesem Artikel führe ich dich durch die wichtigsten Neuerungen von Qwen3.5 und Qwen3.5-Plus, vergleiche sie mit Wettbewerbern, schaue auf die Benchmarks und erkläre, wie du die neuen Modelle nutzen kannst.
Schau dir dazu auch unsere Guides zu den neuesten Konkurrenzmodellen an, etwa Claude Sonnet 4.6 oder GPT-5.3 Instant.
Qwen3.5 ist die neueste Generation in Alibabas Reihe großer Sprachmodelle (LLM), Qwen3.5-397B-A17B. Im Gegensatz zur vorherigen Qwen3-Modellfamilie vereint Qwen3.5 spezialisierte Modelle in einem nativen Vision-Language-Modell. Wie frühere Qwen-Modelle ist es Open Source unter der Apache-2.0-Lizenz.
Es ist als vielseitiges Foundation Model für Consumer- wie Enterprise-Use-Cases positioniert und für native multimodale und agentische Workflows ausgelegt. Qwen3.5-397B-A17B bietet zwei Modi:
Qwen3.5-Plus ist ein gehosteter, nur per API nutzbarer Dienst, der dem Qwen3.5-397B-A17B entspricht, selbst aber kein Open-Weight-Modell ist. Die Release Note war diesbezüglich etwas missverständlich: Die Erwähnung von Qwen3.5-Plus könnte wie ein separates Modell klingen, tatsächlich ist es aber Alibabas proprietärer Dienst auf Basis desselben Modells.
Obwohl Qwen3.5-Plus auf dem Modell Qwen3.5-397B-A17B basiert, gibt es Unterschiede: Der Zugang erfolgt ausschließlich über das Alibaba Cloud Model Studio im Pay-per-Token-Modell sowie über die Qwen Chat UI mit eingeschränktem Zugriff.
Qwen3.5-Plus nutzt ein erweitertes Kontextfenster von 1 Million Tokens, gegenüber 256K bei der Standardversion von Qwen3.5. Zusätzlich zu „Thinking“ und „Fast“ gibt es bei Qwen3.5-Plus einen „Auto“-Modus mit adaptivem Denken, der neben Reasoning auch Tools wie Suche und einen Code-Interpreter einsetzen kann.
Werfen wir einen Blick auf die neuen Funktionen von Qwen3.5:
Ähnlich wie OpenAI in der jüngsten GPT-5.3-Codex-Version Text- und Codex-Modelle vereint hat, kombiniert Alibaba Text, Vision und UI-Interaktion in einem einzigen Modell.
Qwen3.5 wurde gemeinsam auf Text, Bildern, UI-Screenshots und strukturierten Inhalten trainiert. Es unterstützt visuelles Frage-Antworten, Dokumentenverständnis sowie die Interpretation von Diagrammen/Tabellen und beherrscht Pixel-Level-Grounding, um Elemente auf dem Bildschirm zu identifizieren und mit ihnen zu interagieren.
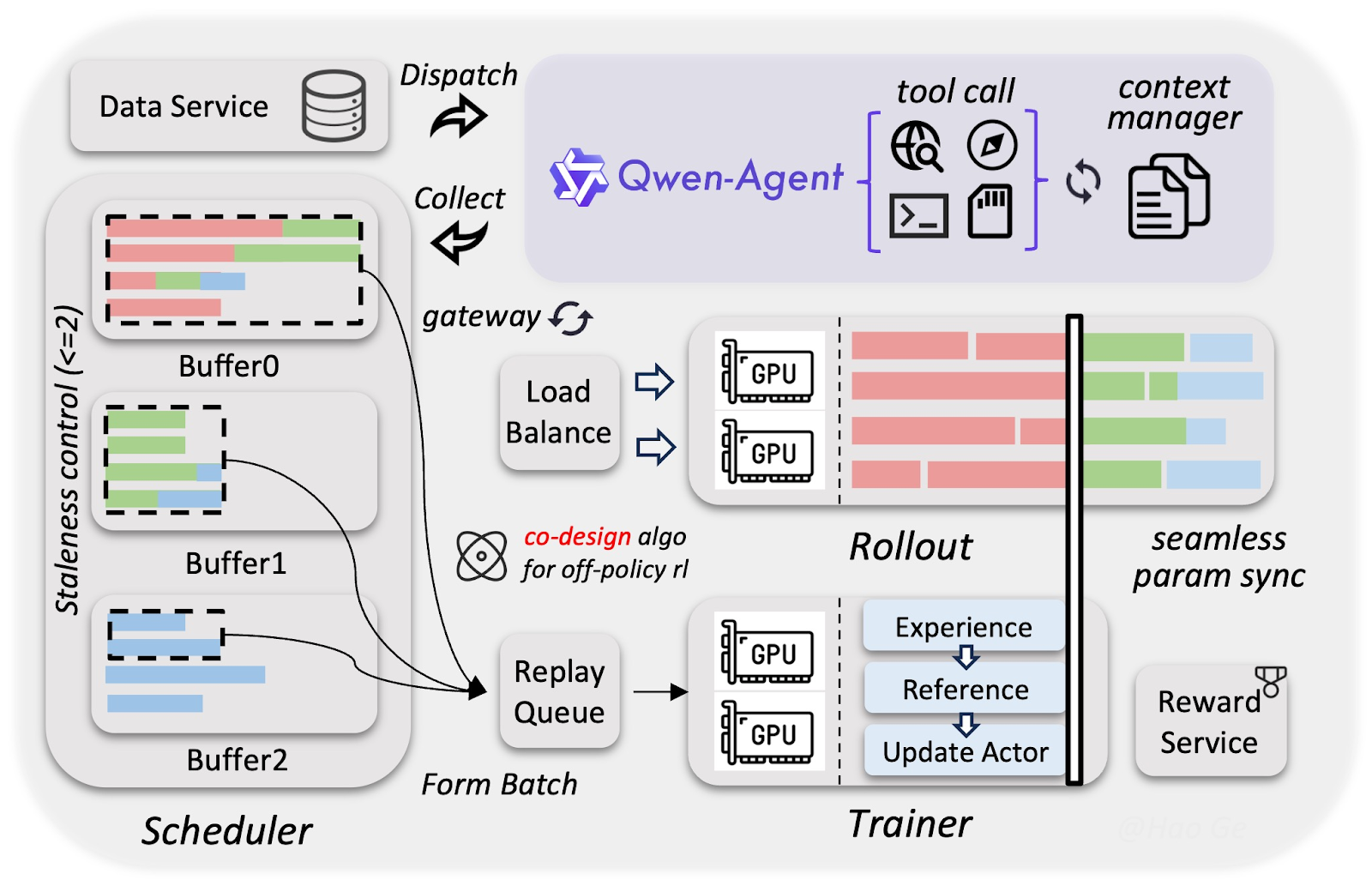
Damit kommen wir zum nächsten Schwerpunkt des neuen Qwen3.5. Durch das umfassende Training auf UI-Screenshots erkennt und bedient das Modell mobile wie Desktop-Oberflächen. So kann es mehrstufige Workflows ausführen, etwa:
Das macht Qwen3.5 ideal für Produktivitätsautomatisierung. Mit Anweisungen in natürlicher Sprache kann der visuelle Qwen-Agent über mehrere Apps hinweg handeln und komplexe Workflows abschließen. Er hält dabei sogar über lange Interaktionsfolgen hinweg den Zustand aufrecht und ermöglicht so eine robuste Orchestrierung von Tools und Apps.
Qwen3.5 ist ein sehr großes Modell mit insgesamt 397 Milliarden Parametern, von denen dank der Mixture-of-Experts-Architektur jedoch pro Token nur 17 Milliarden aktiviert werden. Kurz: die Intelligenz eines Riesenmodells mit der Geschwindigkeit und Kosteneffizienz eines deutlich kleineren.
Konkret heißt das: Im Vergleich zu Qwen3-Max ist Qwen3.5 397B-A17B beim Decoding von Long-Context-Aufgaben (256k Tokens) 19-mal schneller und bei Standardworkflows 8,6-mal schneller. Wichtig: Die Geschwindigkeit geht nicht zulasten der Intelligenz. Beim Reasoning und Coden hält es mit Qwen3-Max mit und übertrifft dank früher Fusion von Text und Video Qwen3-VL.
Mit der höheren Leistung kommen auch Kostenvorteile.
Eine native FP8-Pipeline (Verarbeitung in 8-Bit statt üblichen 16-Bit) halbiert den Speicherbedarf für den Betrieb. Dadurch lassen sich Berechnungen schneller durchführen, was im Billionen-Token-Maßstab über 10% mehr Geschwindigkeit bringt.
Qwen3.5 verfügt außerdem über einen beeindruckenden Wortschatz von 250.000 Tokens und kann komplexe Inhalte mit weniger Tokens ausdrücken. Zusammen mit Multi-Token-Vorhersagen kann das Modell mehrere kommende Wörter in einem Schritt „erraten“ und so die Tokenkosten in 201 Sprachen um 10–60% senken.
Für Qwen3.5 kam eine maßgeschneiderte Infrastruktur zum Einsatz, die das Training multimodaler und agentischer Modelle (fast) so schnell und günstig macht wie bei reinen Textmodellen. Der besondere Trainingsansatz beruht auf drei Kernelementen:
Das Alibaba-Team hat deutlich mehr visuell-textuelle Daten als für die Qwen3-Familie gesammelt, diese aber sehr streng gefiltert, um hohe Qualität sicherzustellen. Das resultierende High-Quality-Dataset ermöglicht es dem 397B-Parameter-Modell, die Intelligenz deutlich größerer 1T-Parameter-Modelle wie Qwen3-Max zu erreichen.
Vision- und Sprachkomponenten wurden getrennt, aber gleichzeitig trainiert. Da keine der beiden warten muss, während die andere rechnet, ergibt sich nahezu 100% Trainingsdurchsatz im Vergleich zu reinen Textmodellen.
Mit FP8-Kompression (Zahlen werden mit halb so vielen Bits gespeichert) und spekulativem Decoding (vorausschauendes „Raten“) führen Agenten tausende Aufgaben gleichzeitig aus, während das Training im Hintergrund weiterläuft. So ließ sich das Training ohne nennenswerte Qualitätsverluste beschleunigen – Qwen3.5 erlernte komplexe Agentenfähigkeiten wie UI-Klicks oder mehrstufige Aufgaben 3–5-mal schneller.
Die Leistung von Alibabas neuem Modell wurde bereits in vielen Aufgabenbereichen validiert. Wir konzentrieren uns auf Ergebnisse in den Schwerpunkten agentische und multimodale Workflows sowie allgemeine Reasoning-Fähigkeiten.
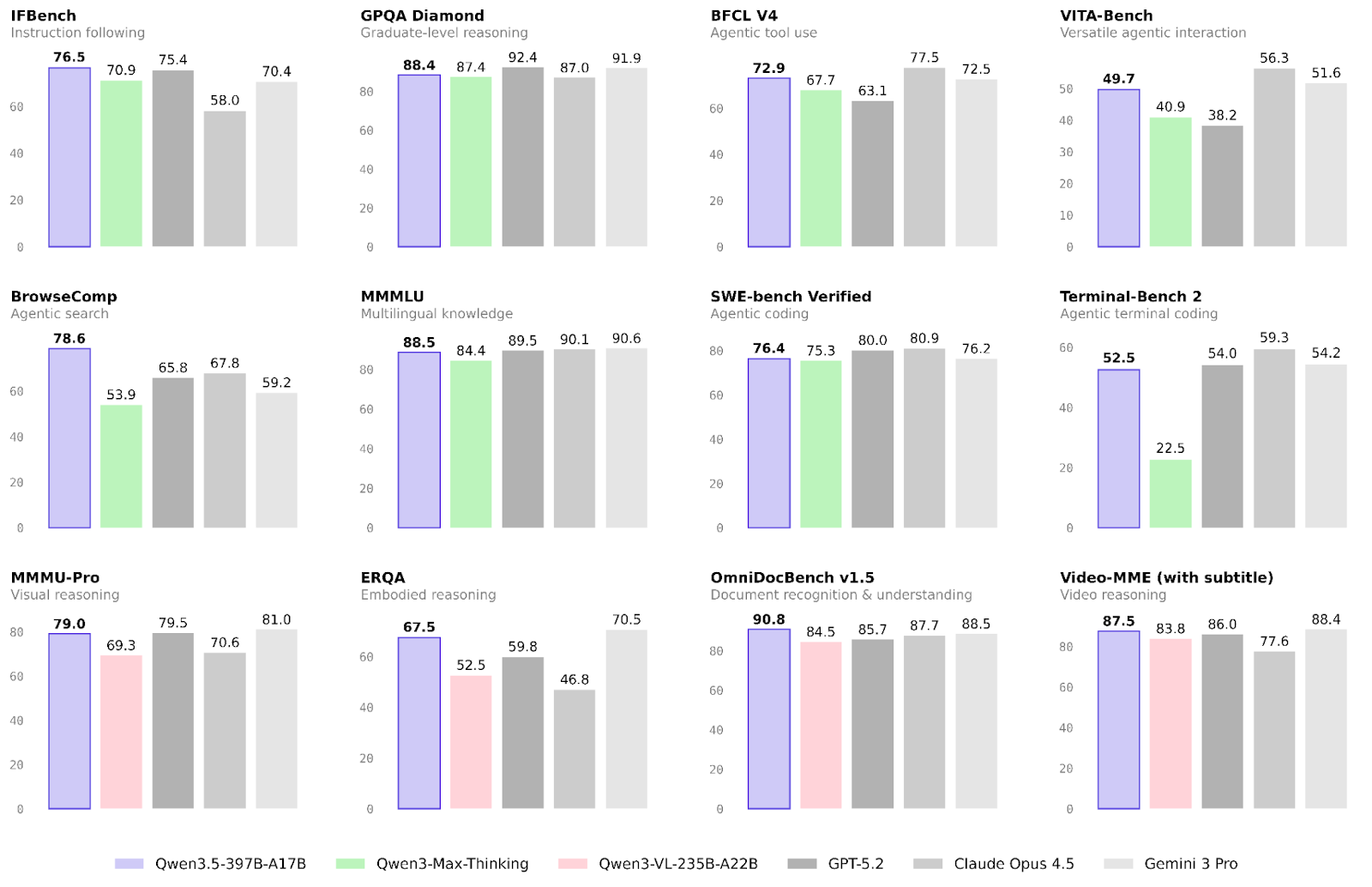
Hier hat sich Qwen3.5 gegenüber der Qwen3-Familie am deutlichsten verbessert.
Auch hier gibt es deutliche Fortschritte gegenüber der vorherigen Modellfamilie – besonders beim Embodied Reasoning und der Dokumentenerkennung:
Reasoning und Wissen standen bei diesem Release offenkundig nicht im Mittelpunkt. Dennoch gibt es leichte Verbesserungen – insbesondere bei der Verlässlichkeit.
Wie bei früheren Modellen sind die Qwen3.5-Modelle Open Source und lassen sich auf verschiedene Arten nutzen: direkt in der Chat-App, über die API, als Download für den lokalen Betrieb oder integriert in eigene Setups.
Du kannst Qwen3.5 direkt unter chat.qwen.ai in der gewohnten Chat-Oberfläche nutzen.
Im Modellauswahl-Menü findest du sowohl Qwen3.5-397B-A17B als auch Qwen3.5-Plus sowie einige Vorgängermodelle aus der Qwen3-Familie und Qwen2.5-Max.
Der API-Zugang für Qwen 3.5 funktioniert wie bei Qwen3: OpenAI-kompatible Endpunkte über ModelScope (Free-Tier mit Tageskontingenten) oder DashScope/Model Studio (kostenpflichtig, inkl. Qwen3.5-Plus). Aktualisiere einfach deine Model-ID auf qwen3.5-397b-a17b oder qwen3.5-plus – und los geht's.
Wie erwähnt, wurden die Gewichte von Qwen3.5-397B-A17B unter der Apache-2.0-Lizenz veröffentlicht. Du kannst Qwen3.5 lokal mit Tools wie Ollama, LM Studio oder vLLM ausführen.
Die Gewichte kannst du hier herunterladen:
Mit neuen visuellen Agenten, mehr Leistung und optimierten Kosten ist Qwen3.5 ein starkes Release, das nicht nur andere chinesische Modelle unter Druck setzt, sondern auch die Konkurrenz von OpenAI und Anthropic herausfordert.
Wie bei anderen Neuerscheinungen in diesem Jahr – etwa GPT-5.3-Codex und Claude Opus 4.6 – verlagert sich der Fokus klar auf agentische KI. Der rasche Erfolg von OpenClaw zeigt, wie groß der Bedarf an praktischen KI-Anwendungen ist, und Modelle wie Qwen3.5, Seedance 2.0 und das gemunkelte nächste Release von DeepSeek belegen, dass China bei KI-Modellen schnell zur führenden Kraft aufsteigt.
Top-Kurse zu KI
Lernpfad
Kurs
Kurs
Blog
Blog
Hesam Sheikh Hassani
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Blog
Matt Crabtree
14 Min.
Tutorial
Matt Crabtree
