
Cursus
MLOps-concepten
2 Hr
43.7K
Met de introductie van GPT-4 en later GPT-4o is de race begonnen om large language models te bouwen en het volledige potentieel van moderne AI te benutten. LLM’s hebben vectordatabases en integratieframeworks nodig om slimme AI-toepassingen te bouwen.
Qdrant is een open-source vector similarity search engine en vectordatabase die een productieklare service biedt met een handige API, waarmee je vector-embeddings kunt opslaan, doorzoeken en beheren.
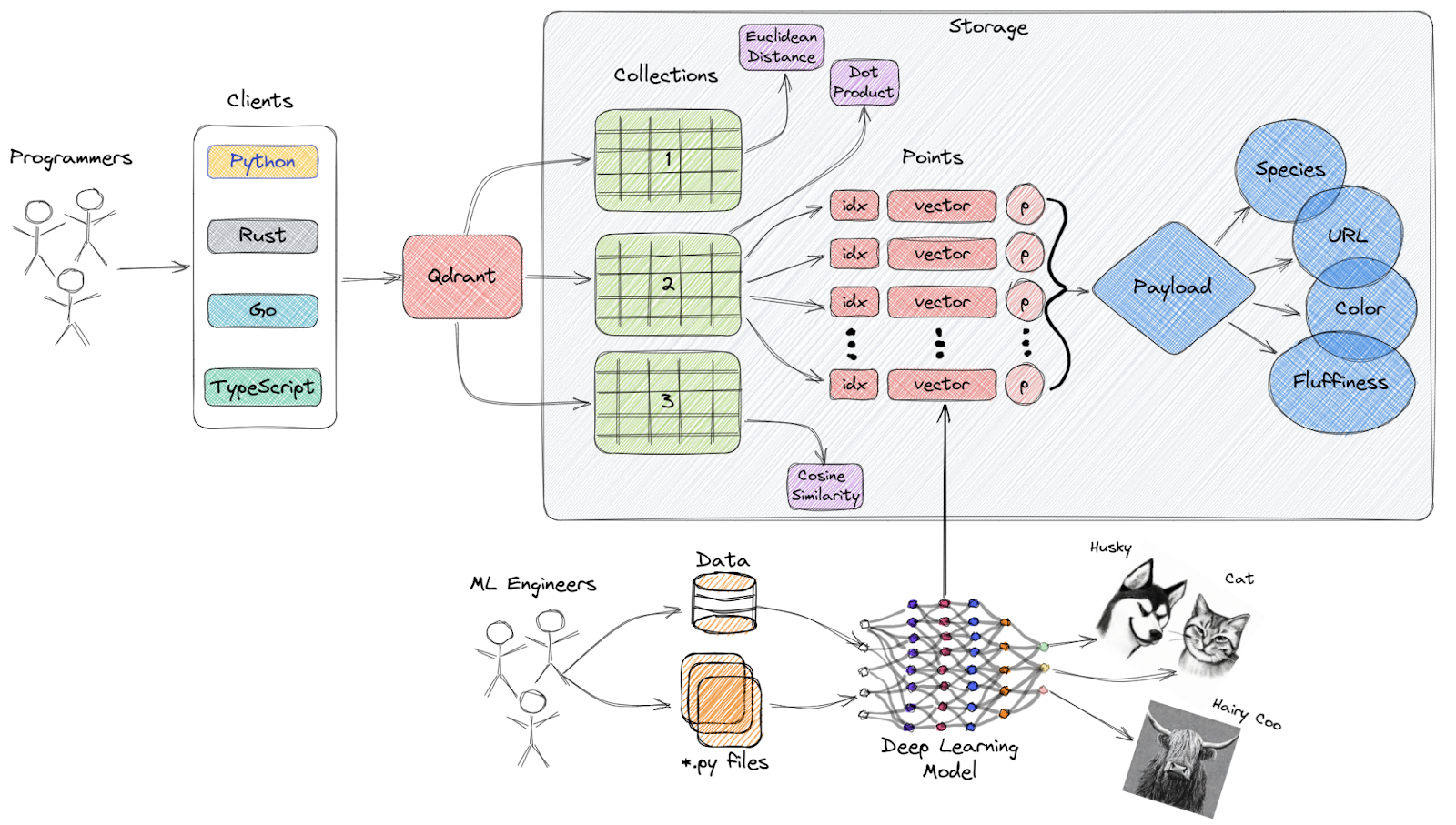
Overzicht op hoog niveau van de architectuur van Qdrant
Belangrijkste functies:
Ontdek de beste vectordatabases in De 5 beste vectordatabases | Een lijst met voorbeelden.
LangChain is een veelzijdig en krachtig framework voor het ontwikkelen van toepassingen die worden aangestuurd door taalmodellen. Het biedt diverse componenten waarmee ontwikkelaars contextbewuste en redeneergebaseerde applicaties kunnen bouwen, deployen en monitoren.
Het framework bestaat uit 4 hoofdonderdelen:
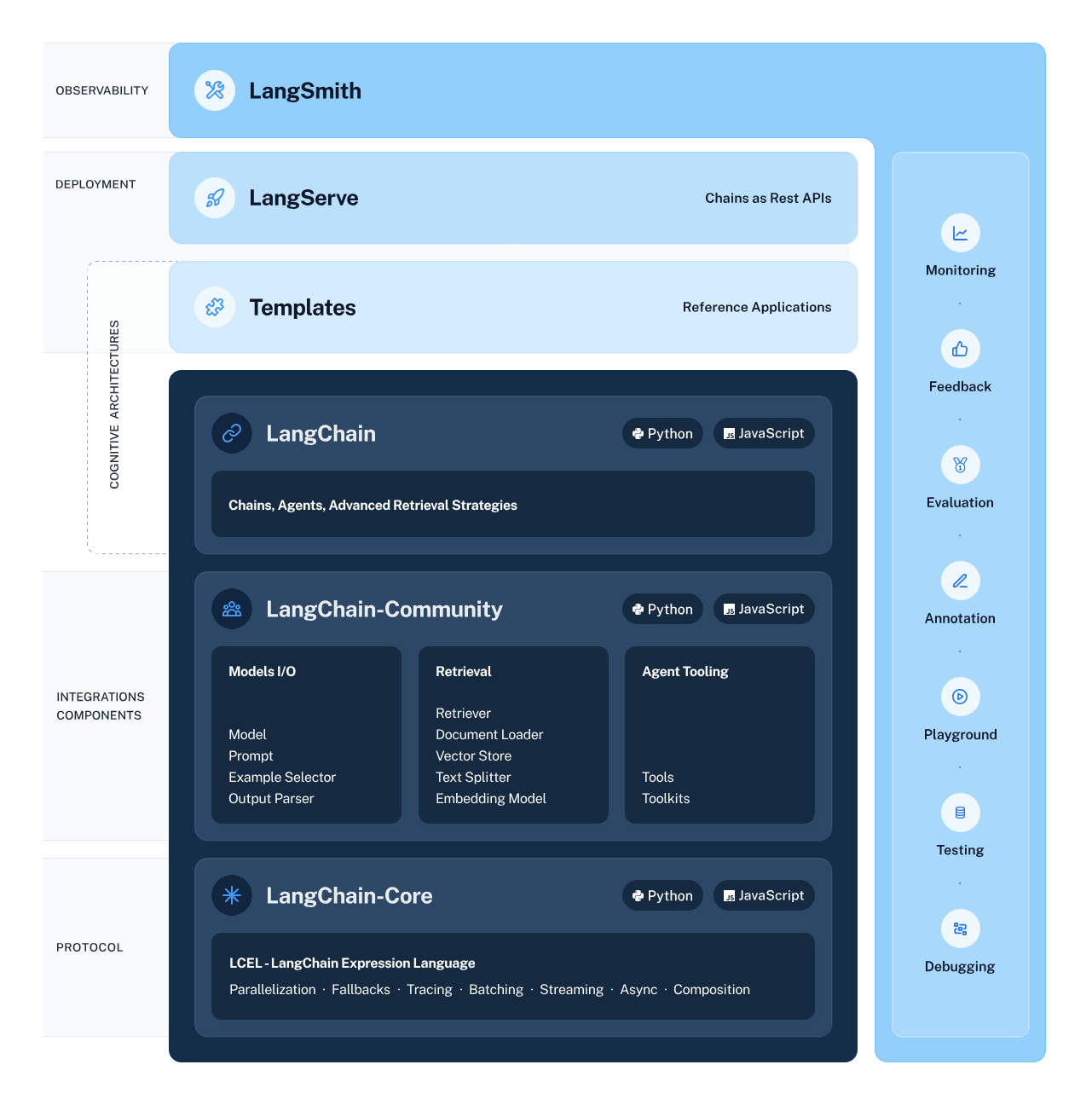
LangChain-ecosysteem
Leer Hoe je LLM-toepassingen bouwt met LangChain en ontdek het onbenutte potentieel van large language models.
Met deze tools beheer je modelmetadata en houd je experimenten bij:
MLflow is een open-sourcetool die helpt bij het beheren van de kernonderdelen van de machinelearning-levenscyclus. Het wordt vaak gebruikt voor het bijhouden van experimenten, maar je kunt het ook inzetten voor reproduceerbaarheid, uitrol en een modelregister. Je kunt machinelearningexperimenten en modelmetadata beheren via CLI, Python, R, Java en REST API.
MLflow heeft vier kernfuncties:
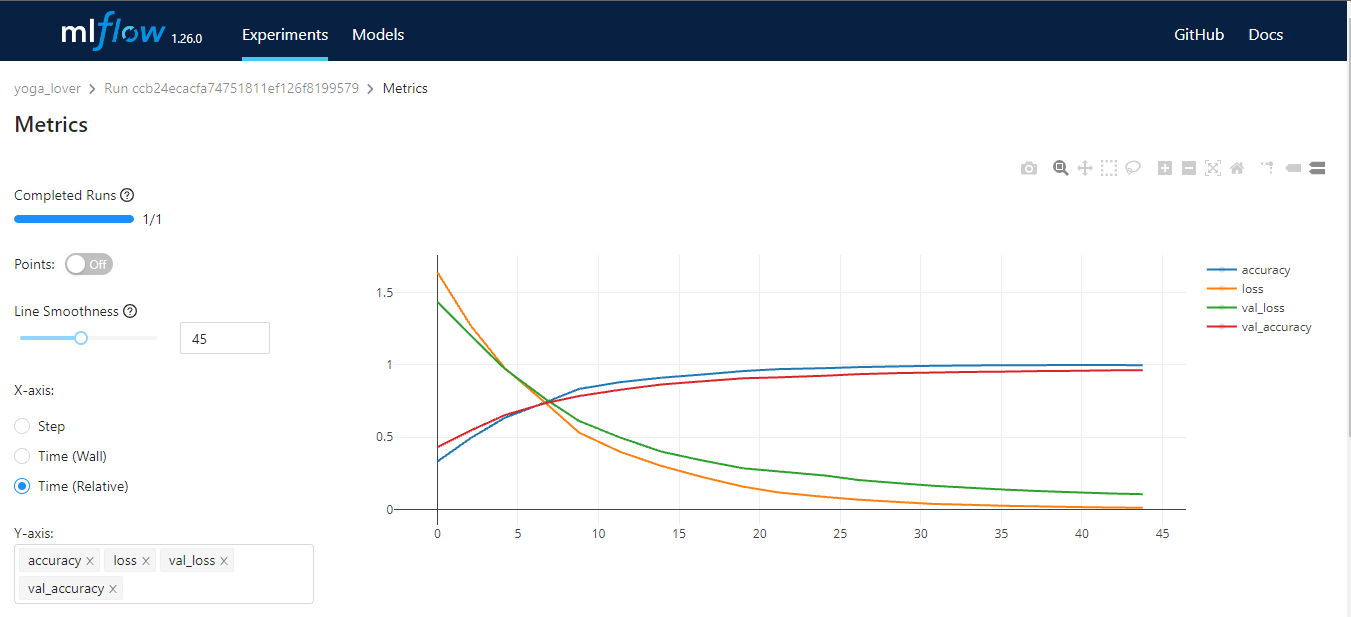
Afbeelding door de auteur
Comet ML is een platform voor het tracken, vergelijken, verklaren en optimaliseren van machinelearningmodellen en -experimenten. Je kunt het gebruiken met elke ML-bibliotheek, zoals Scikit-learn, PyTorch, TensorFlow en HuggingFace.
Comet ML is er voor individuen, teams, bedrijven en academici. Het stelt iedereen in staat om experimenten eenvoudig te visualiseren en te vergelijken. Daarnaast kun je voorbeelden visualiseren uit beeld-, audio-, tekst- en tabeldata.
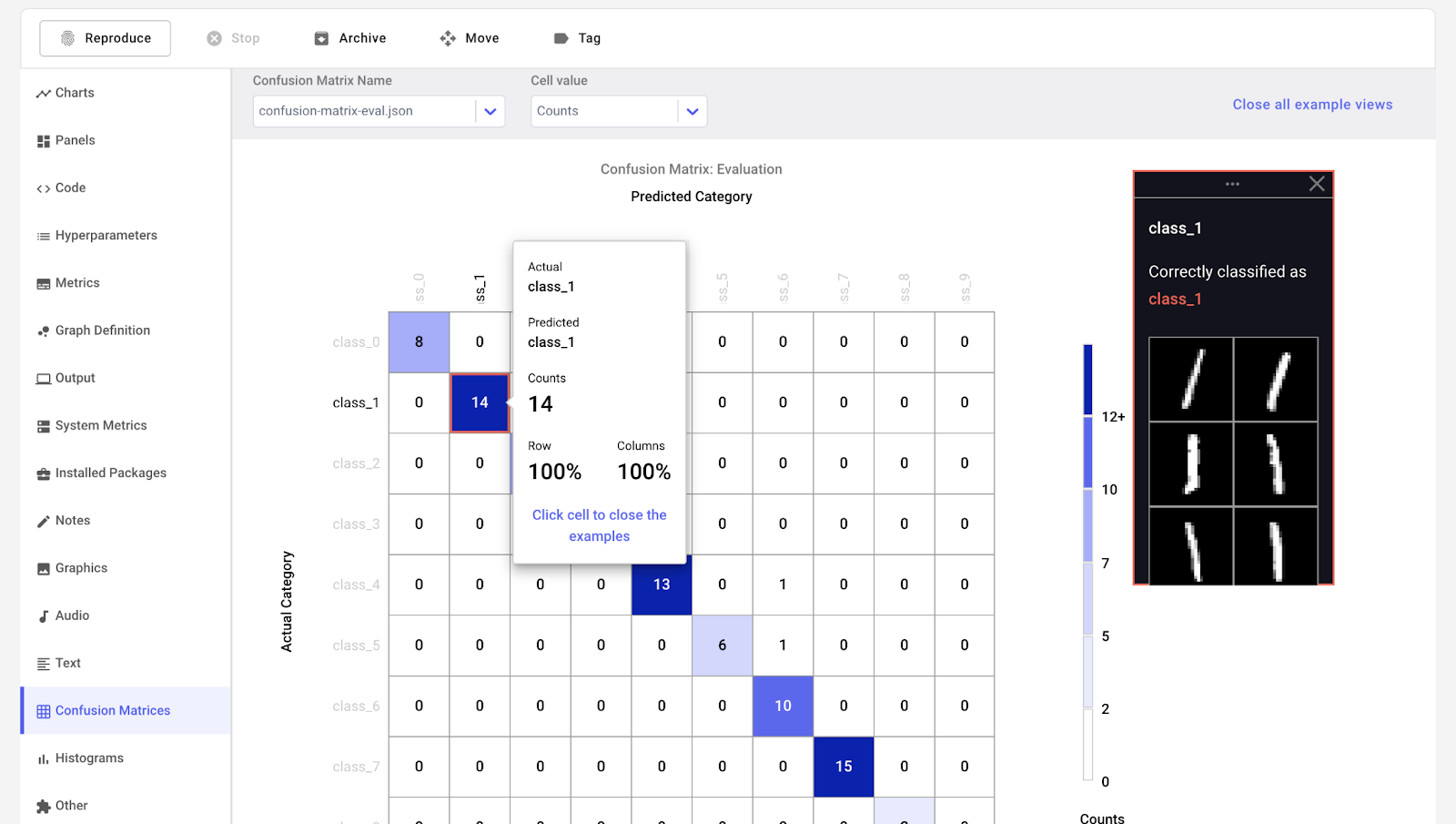
Afbeelding van Comet ML
Weights & Biases is een ML-platform voor het bijhouden van experimenten, versiebeheer van data en modellen, hyperparameteroptimalisatie en modelbeheer. Je kunt er bovendien artefacten (datasets, modellen, dependencies, pipelines en resultaten) mee loggen en datasets visualiseren (audio, visueel, tekst en tabulair).
Weights & Biases heeft een gebruiksvriendelijk centraal dashboard voor machinelearningexperimenten. Net als Comet ML kun je het integreren met andere ML-bibliotheken, zoals Fastai, Keras, PyTorch, Hugging Face, Yolov5, Spacy en nog veel meer. Bekijk onze introductie tot Weights & Biases in een apart artikel.
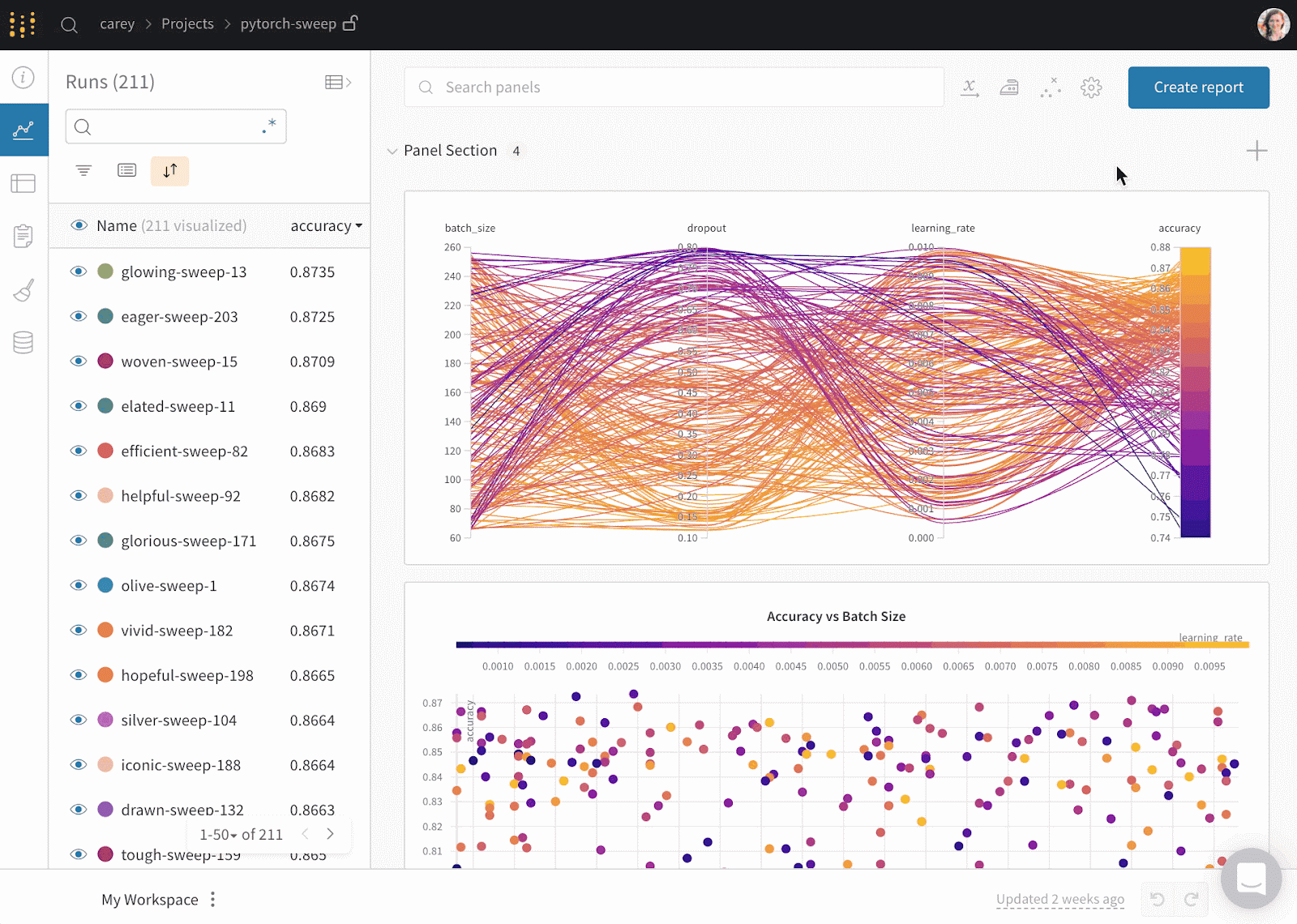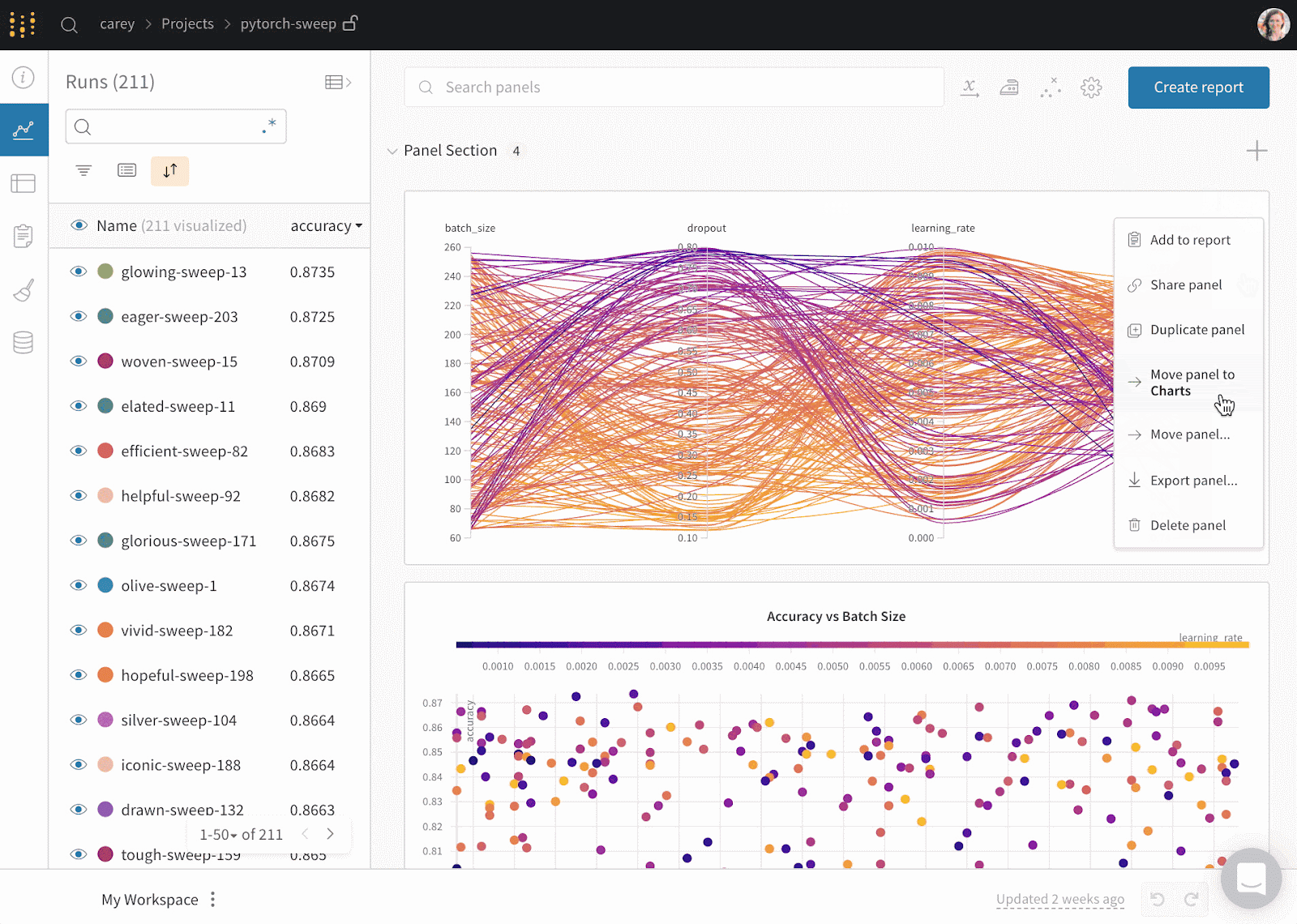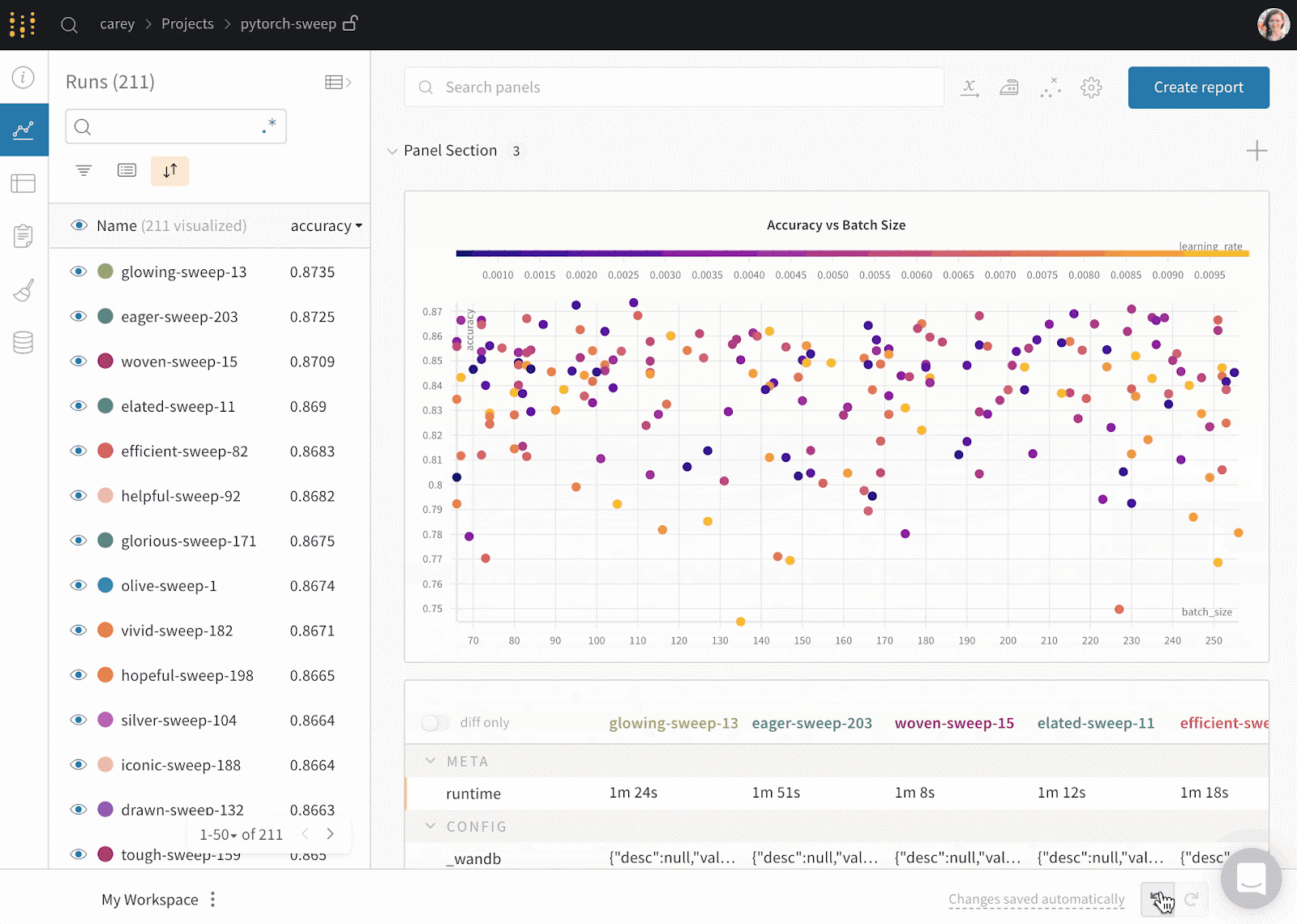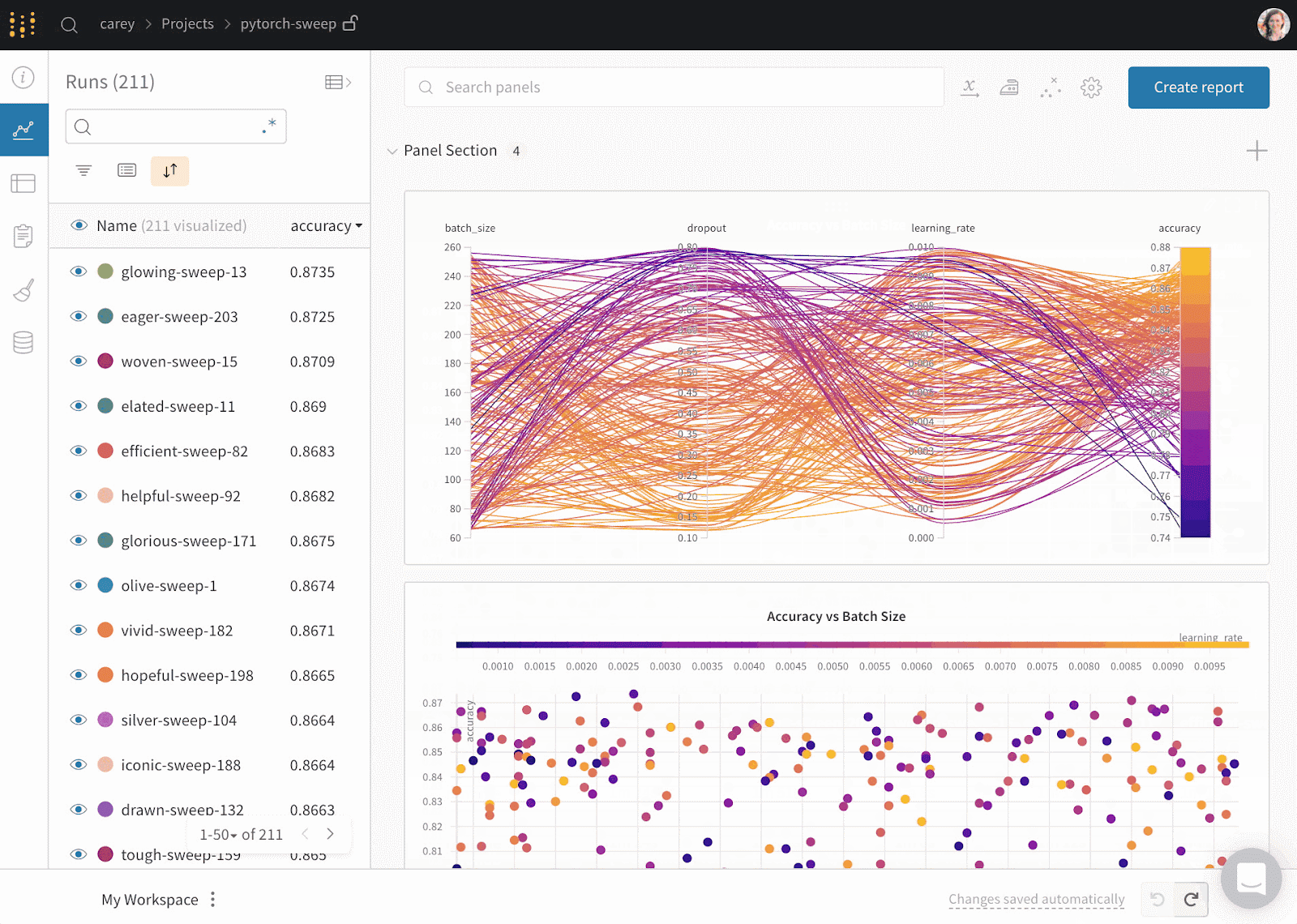
Gif van Weights & Biases
Let op: je kunt ook TensorBoard, Pachyderm, DagsHub en DVC Studio gebruiken voor experimenttracking en ML-metadata-beheer.
Met deze tools bouw je datasci-projecten en beheer je machinelearningworkflows:
Prefect is een moderne datastack voor het monitoren, coördineren en orkestreren van workflows tussen en over applicaties heen. Het is een open-source, lichtgewicht tool gebouwd voor end-to-end machinelearningpipelines.
Je kunt voor databases kiezen uit Prefect Orion UI of Prefect Cloud.
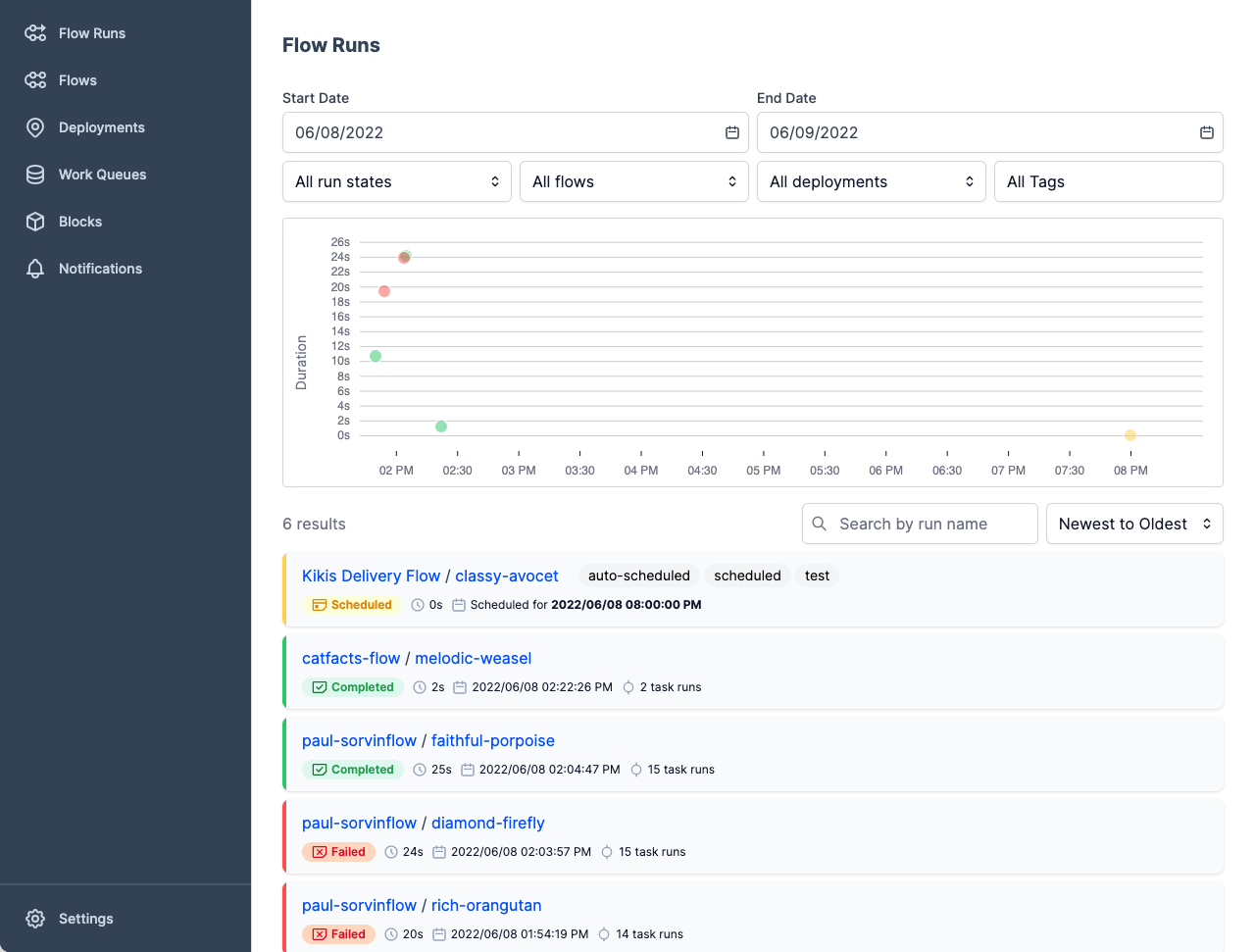
Afbeelding van Prefect
Metaflow is een krachtige, door de praktijk geharde workflowmanagementtool voor data science- en machinelearningprojecten. Het is gebouwd voor data scientists, zodat zij zich kunnen richten op het bouwen van modellen in plaats van op MLOps-engineering.
Met Metaflow kun je een workflow ontwerpen, op schaal draaien en het model in productie deployen. Het houdt ML-experimenten en data automatisch bij en versieert ze. Daarnaast kun je resultaten visualiseren in de notebook.
Metaflow werkt met meerdere clouds (waaronder AWS, GCP en Azure) en met diverse ML-Pythonpakketten (zoals Scikit-learn en TensorFlow), en de API is ook beschikbaar voor R.
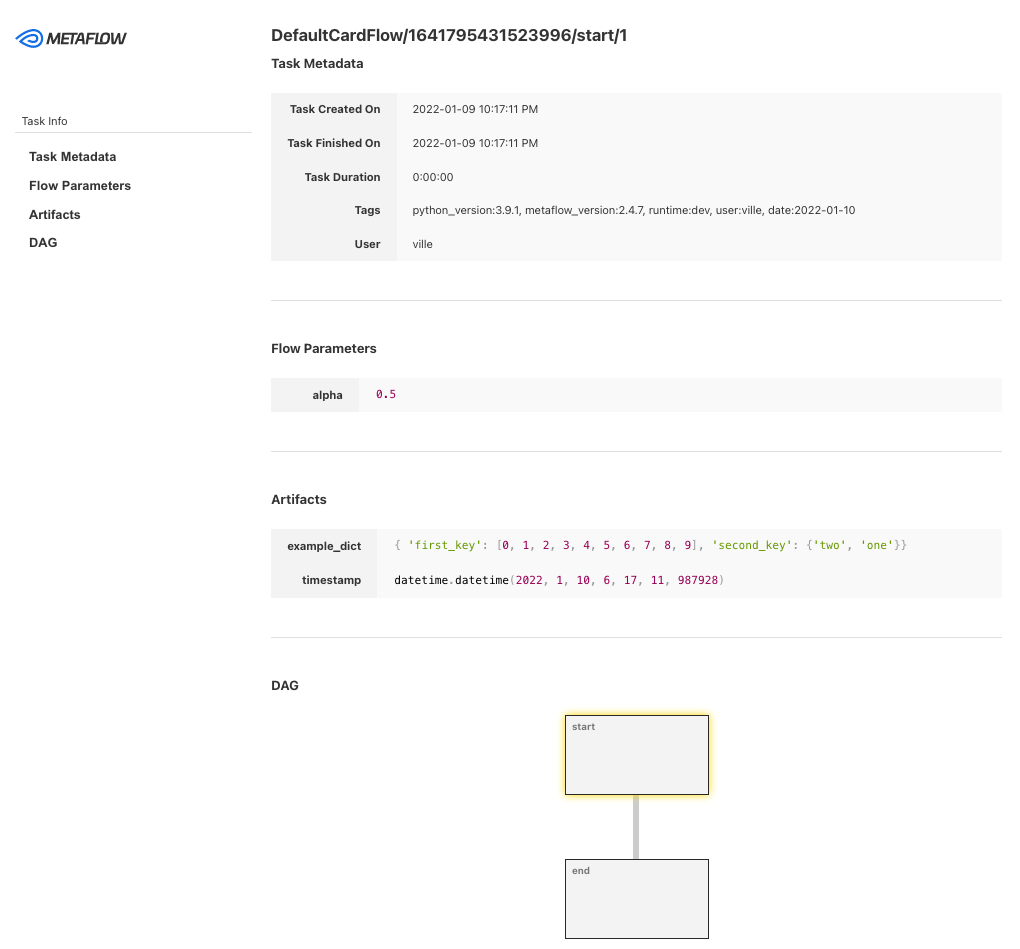
Afbeelding van Metaflow
Kedro is een op Python gebaseerde tool voor workflow-orkestratie. Je gebruikt het om reproduceerbare, onderhoudbare en modulaire datasci-projecten te maken. Het integreert softwareengineeringconcepten in machine learning, zoals modulariteit, separation of concerns en versiebeheer.
Met Kedro kun je:
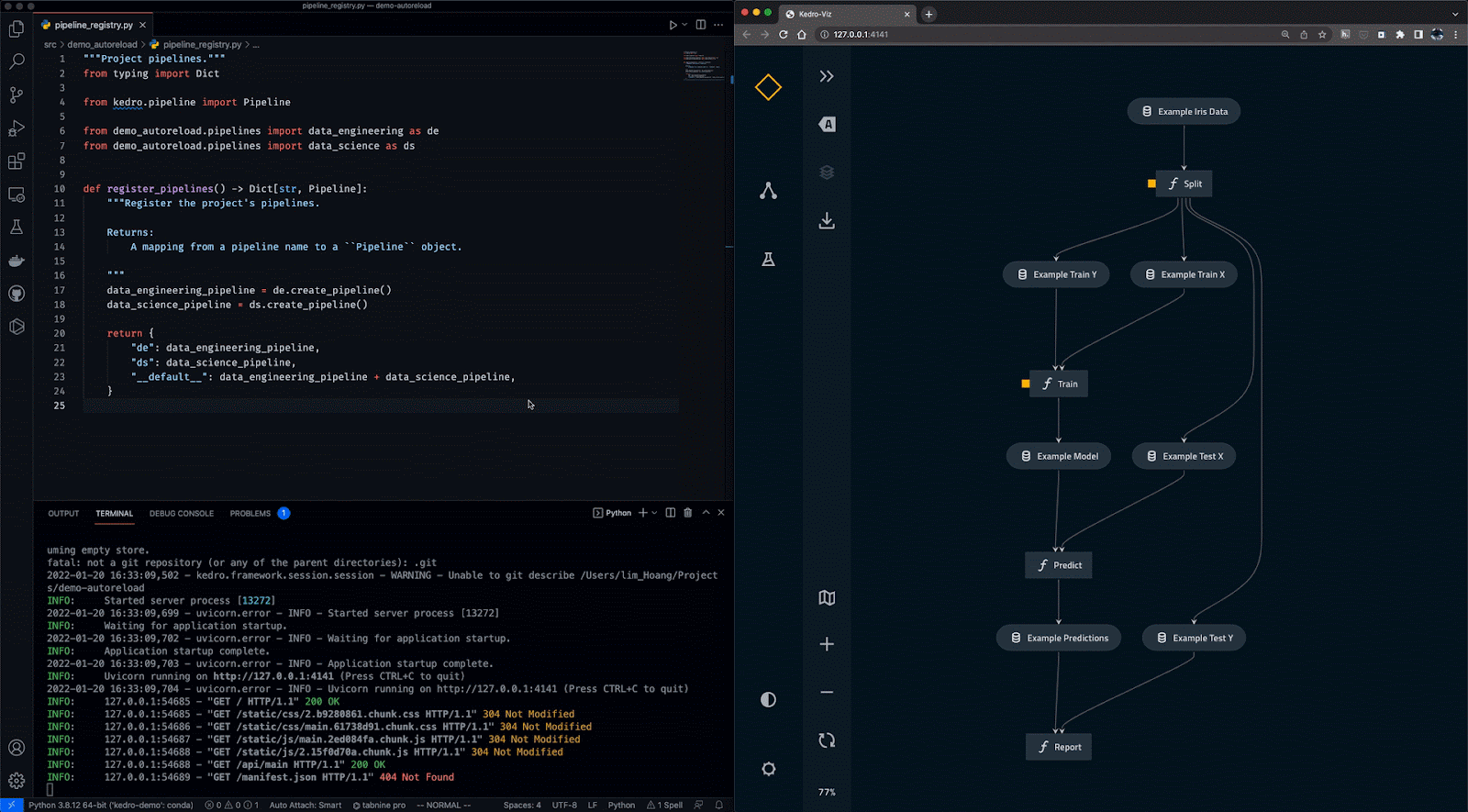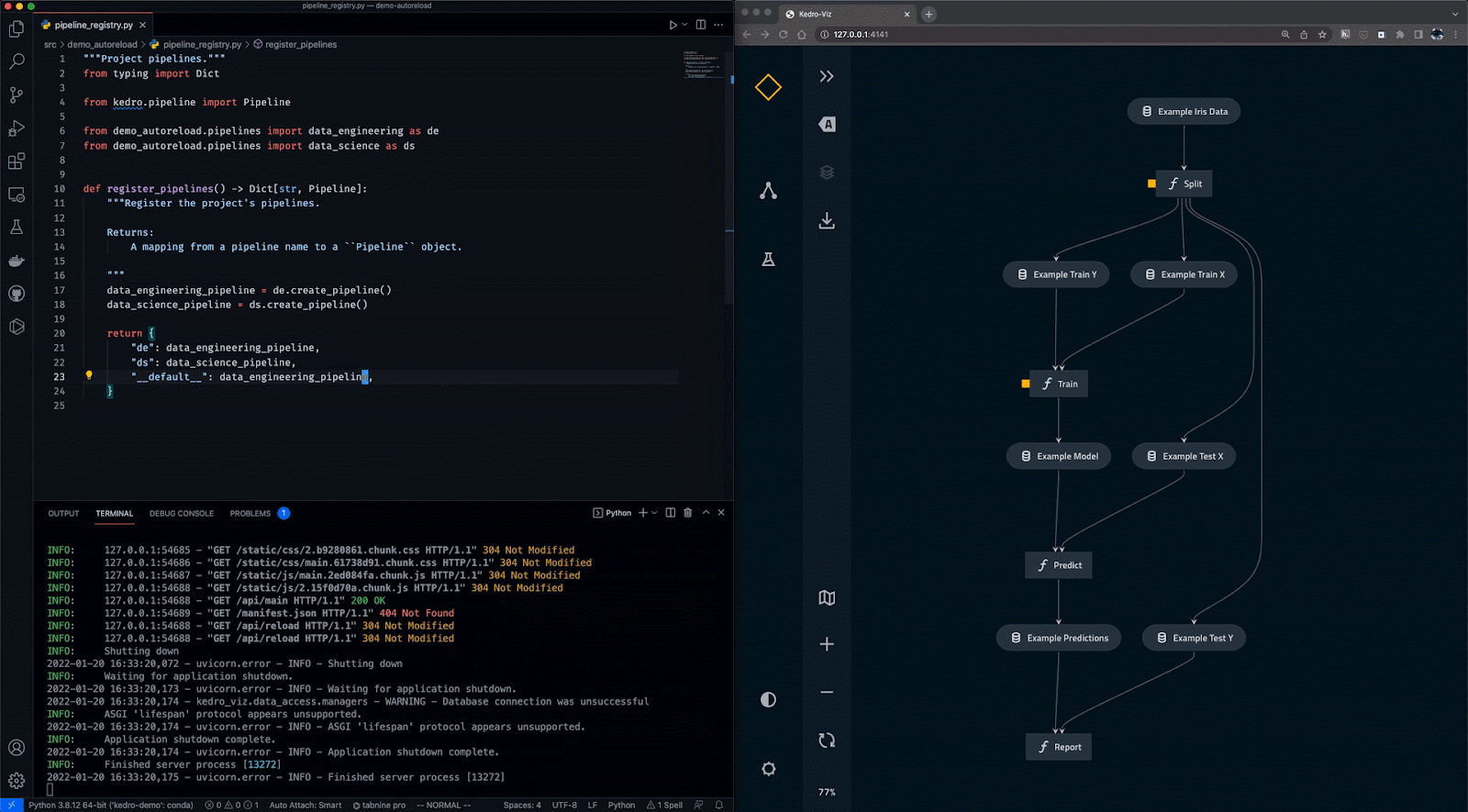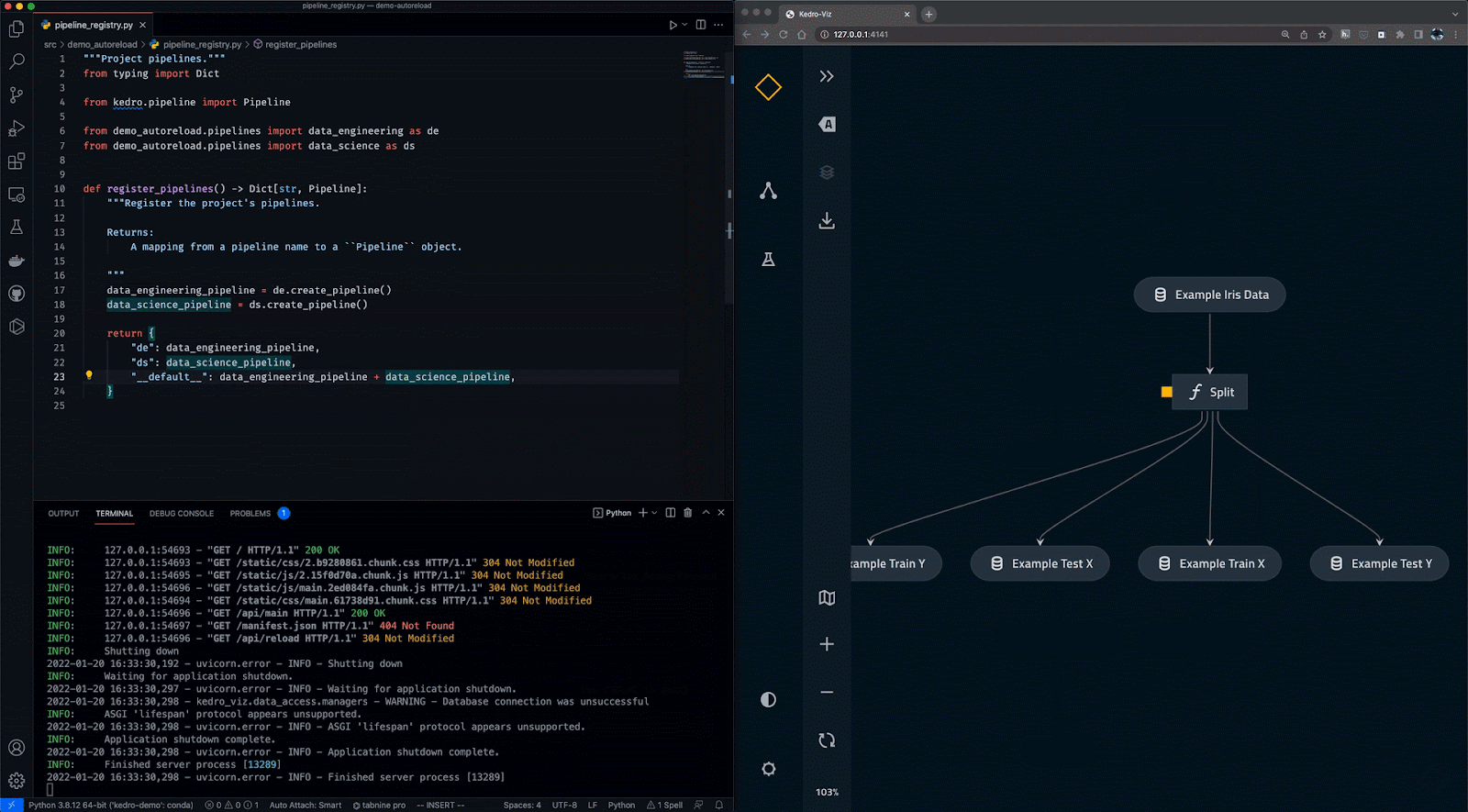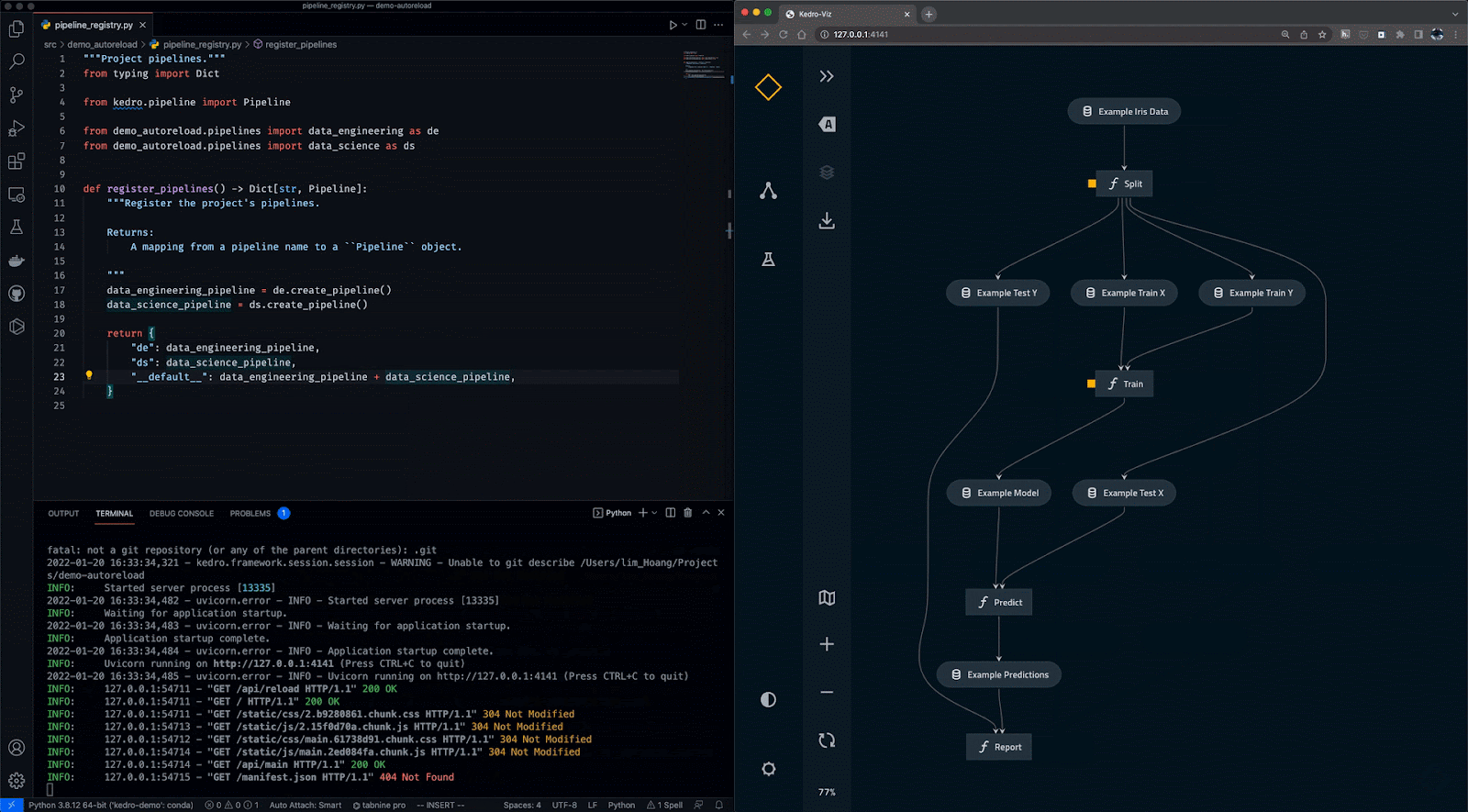
Gif van Kedro
Let op: je kunt ook Kubeflow en DVC gebruiken voor orkestratie en workflow-pipelines.
Met deze MLOps-tools beheer je taken rond versiebeheer van data en pipelines:
Pachyderm automatiseert datatransformatie met dataversiebeheer, herkomst (lineage) en end-to-end pipelines op Kubernetes. Je kunt integreren met elke vorm van data (afbeeldingen, logs, video, CSV’s), elke taal (Python, R, SQL, C/C++) en op elke schaal (petabytes aan data, duizenden jobs).
De community-editie is open source en geschikt voor een klein team. Organisaties en teams die geavanceerde functies willen, kunnen kiezen voor de Enterprise-editie.
Net als met Git kun je je data versiebeheren met een vergelijkbare syntax. In Pachyderm is het hoogste objectniveau Repository, en je gebruikt Commit, Branches, File, History en Provenance om de dataset te volgen en te versiebeheren.
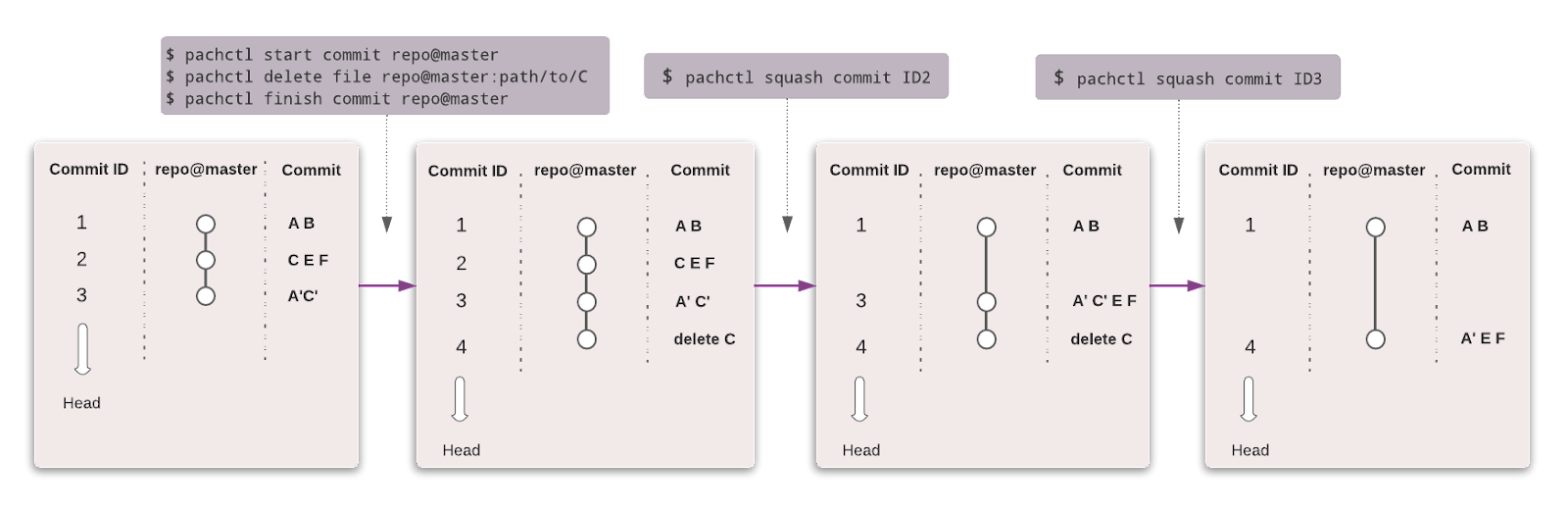
Afbeelding van Pachyderm
Data Version Control is een open-source en populaire tool voor machinelearningprojecten. Het werkt naadloos met Git en voorziet in versiebeheer van code, data, model, metadata en pipelines.
DVC is meer dan alleen een tool voor datatracking en -versiebeheer.
Je kunt het gebruiken voor:
Afbeelding van DVC
Let op: DagsHub kan ook worden gebruikt voor versiebeheer van data en pipelines.
LakeFS is een open-source, schaalbare tool voor dataversiebeheer die een Git-achtige interface biedt voor objectopslag, zodat gebruikers hun datalakes kunnen beheren zoals hun code. Met LakeFS kun je data op exabyteschaal versiebeheren, wat het tot een zeer schaalbare oplossing maakt voor grote datalakes.
Aanvullende mogelijkheden:
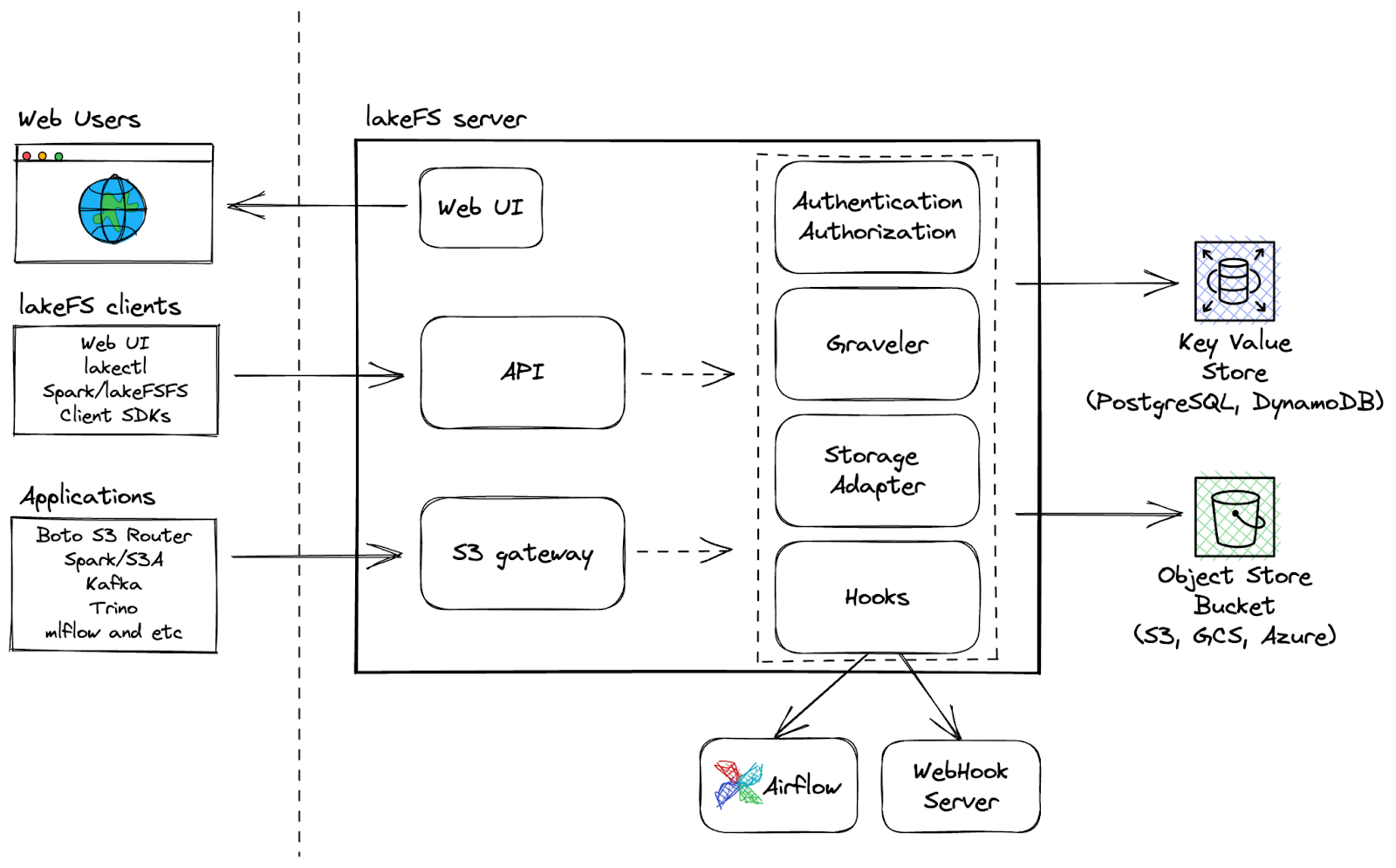
LakeFS-architectuur
Feature stores zijn centrale repositories voor het opslaan, versiebeheren, beheren en serveren van features (verwerkte data-attributen die gebruikt worden voor het trainen van ML-modellen) voor modellen in productie én voor training.
Feast is een open-source feature store die ML-teams helpt realtimemodellen te productiseren en een featureplatform te bouwen dat samenwerking tussen engineers en data scientists stimuleert.
Belangrijkste functies:
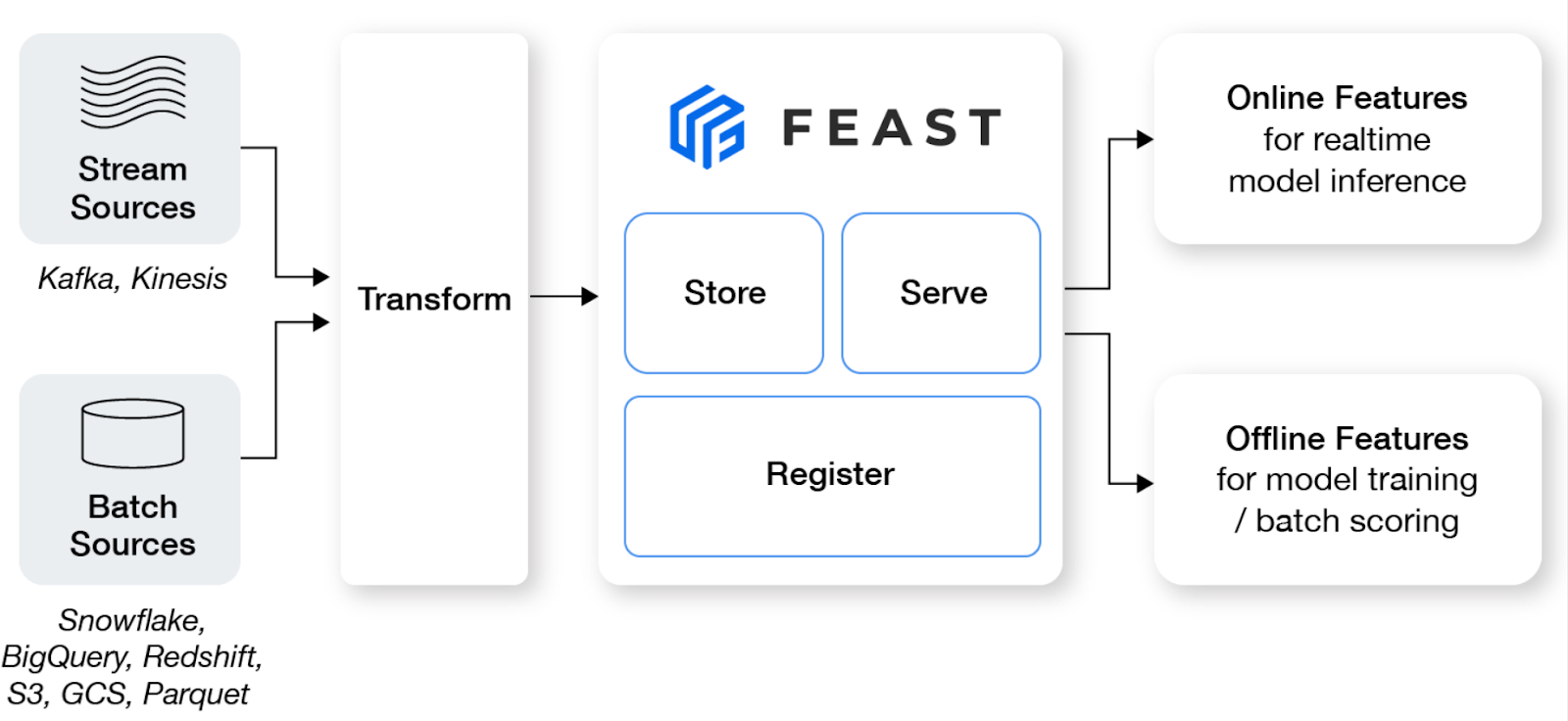
Afbeelding van Feast
Featureform is een virtuele feature store waarmee data scientists de features van hun ML-modellen kunnen definiëren, beheren en serveren. Het helpt datasci-teams om beter samen te werken, experimenten te organiseren, deployment te faciliteren, betrouwbaarheid te vergroten en compliance te borgen.
Belangrijkste functies:
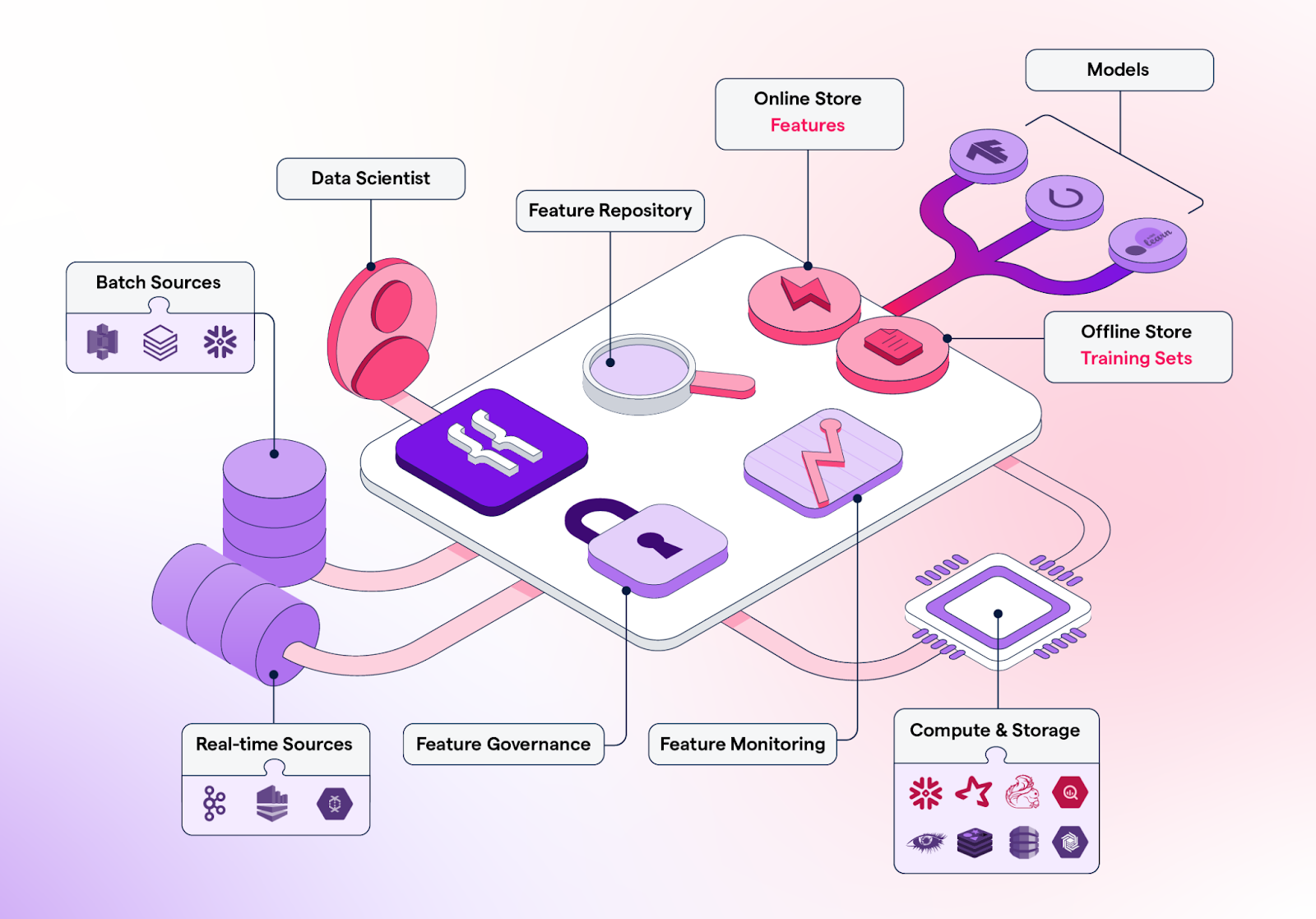
Afbeelding van Featureform
Met deze MLOps-tools test je modelkwaliteit en borg je de betrouwbaarheid, robuustheid en nauwkeurigheid van machinelearningmodellen:
Deepchecks is een open-sourceoplossing voor al je ML-validatiebehoeften, zodat je data en modellen grondig getest worden van research tot productie. Het biedt een holistische aanpak om je data en modellen te valideren via verschillende componenten.
Afbeelding van Deepchecks
Deepchecks bestaat uit drie componenten:
TruEra is een geavanceerd platform dat modelkwaliteit en -prestaties aanjaagt via geautomatiseerd testen, verklaarbaarheid en root-causeanalyse. Het biedt verschillende functies om modellen te optimaliseren en te debuggen, best-in-class verklaarbaarheid te bereiken en eenvoudig te integreren in je ML-techstack.
Belangrijkste functies:
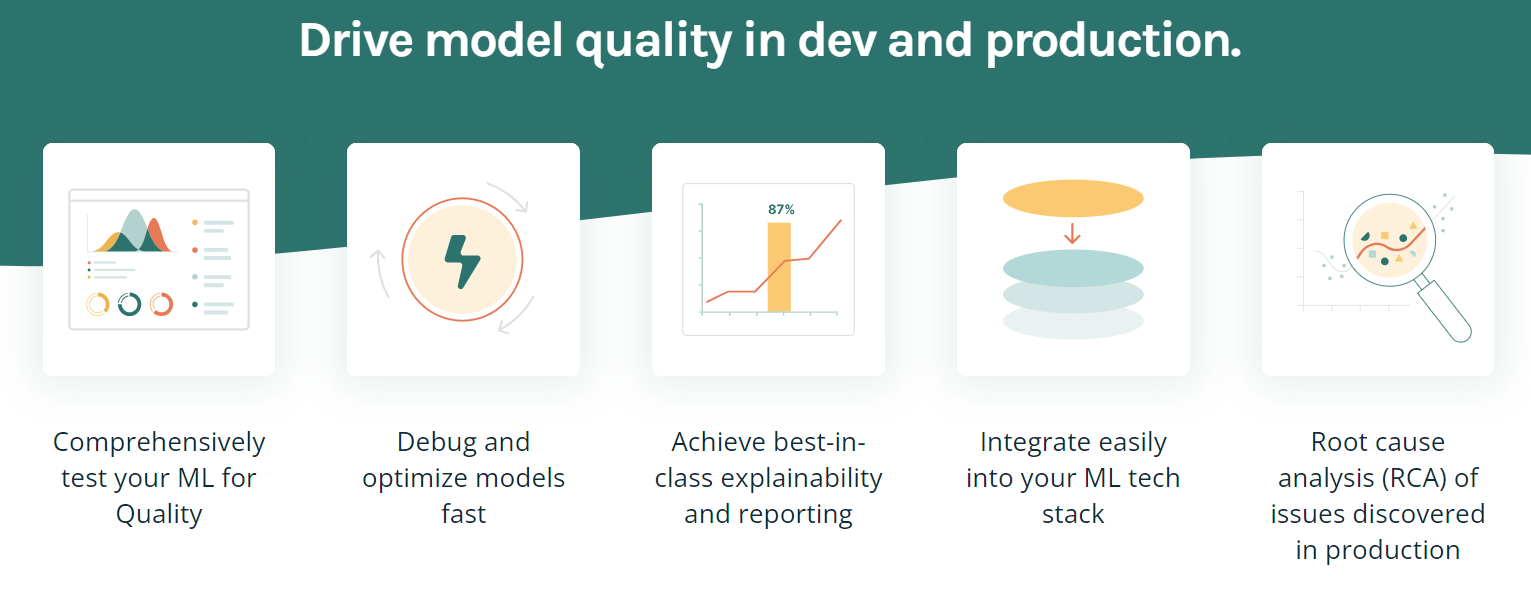
Afbeelding door TruEra
Voor het deployen van modellen kunnen deze MLOps-tools enorm helpen:
Kubeflow maakt het deployen van ML-modellen op Kubernetes eenvoudig, draagbaar en schaalbaar. Je kunt het gebruiken voor datapreparatie, modeltraining, modeloptimalisatie, prediction serving en het monitoren van modelprestaties in productie. Je kunt ML-workflows lokaal, on-premises of in de cloud deployen. Kortom, het maakt Kubernetes toegankelijk voor datascienceteams.
Belangrijkste functies:
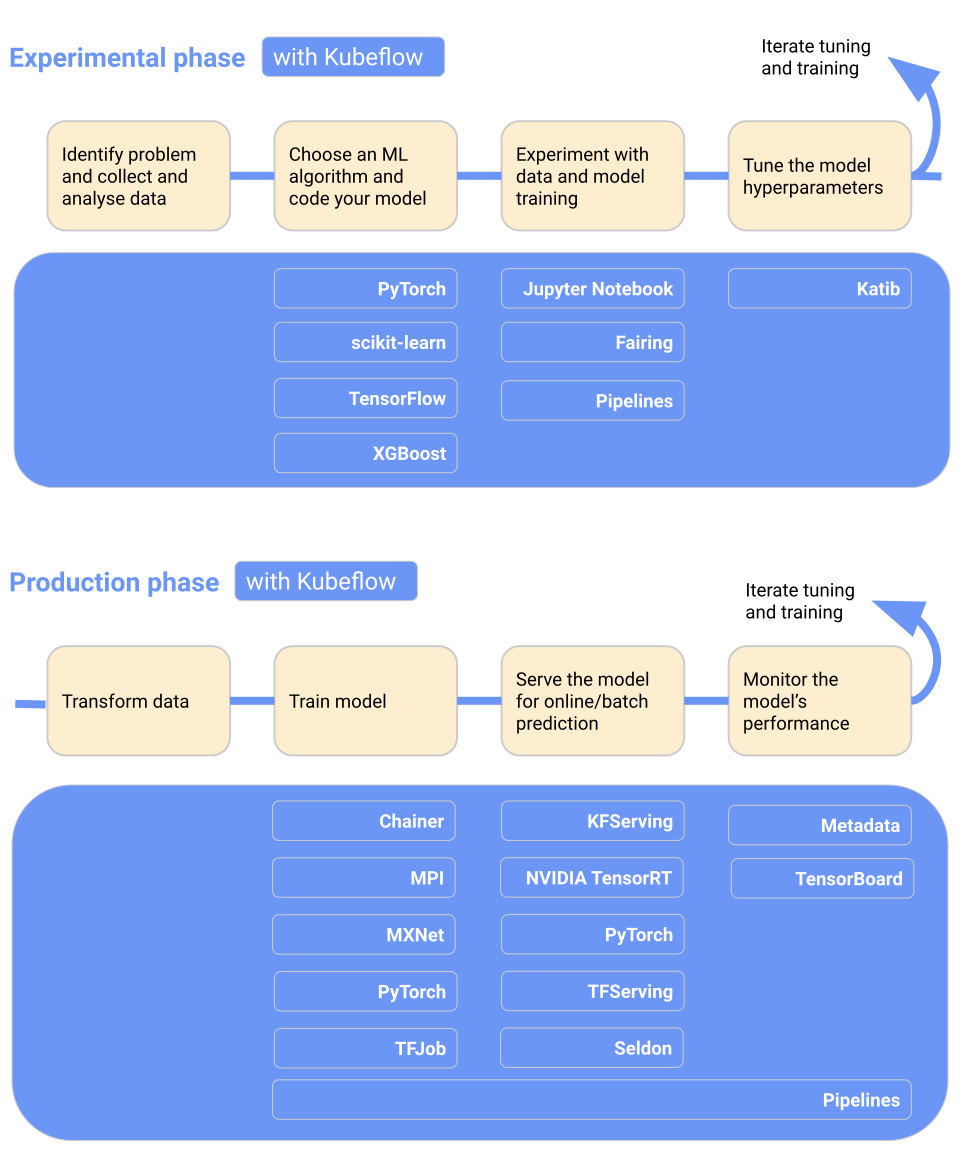
Afbeelding van Kubeflow
BentoML maakt het makkelijker en sneller om machinelearningapplicaties te leveren. Het is een Python-first tool voor het deployen en onderhouden van API’s in productie. Het schaalt met krachtige optimalisaties door parallelle inferentie en adaptieve batching te draaien en biedt hardwareversnelling.
Het interactieve centrale dashboard van BentoML maakt het eenvoudig om te organiseren en te monitoren bij het deployen van ML-modellen. Het mooiste is dat het werkt met allerlei ML-frameworks, zoals Keras, ONNX, LightGBM, PyTorch en Scikit-learn. Kortom, BentoML biedt een complete oplossing voor modeluitrol, -serving en -monitoring.
Afbeelding van BentoML
Hugging Face Inference Endpoints is een clouddienst van Hugging Face, een alles-in-één ML-platform waar gebruikers modellen, datasets en demo’s kunnen trainen, hosten en delen. Deze endpoints zijn bedoeld om getrainde ML-modellen voor inferentie te deployen zonder zelf de benodigde infrastructuur op te zetten en te beheren.
Belangrijkste functies:
Afbeelding van Hugging Face
Let op: je kunt ook MLflow en AWS SageMaker gebruiken voor modeluitrol en -serving.
Of je ML-model nu in ontwikkeling, validatie of productie zit, deze tools helpen je verschillende factoren te monitoren:
Evidently AI is een open-source Python-bibliotheek voor het monitoren van ML-modellen tijdens ontwikkeling, validatie en in productie. Het controleert data- en modelkwaliteit, datadrift, target drift en prestaties van regressie en classificatie.
Evidently heeft drie hoofcomponenten:
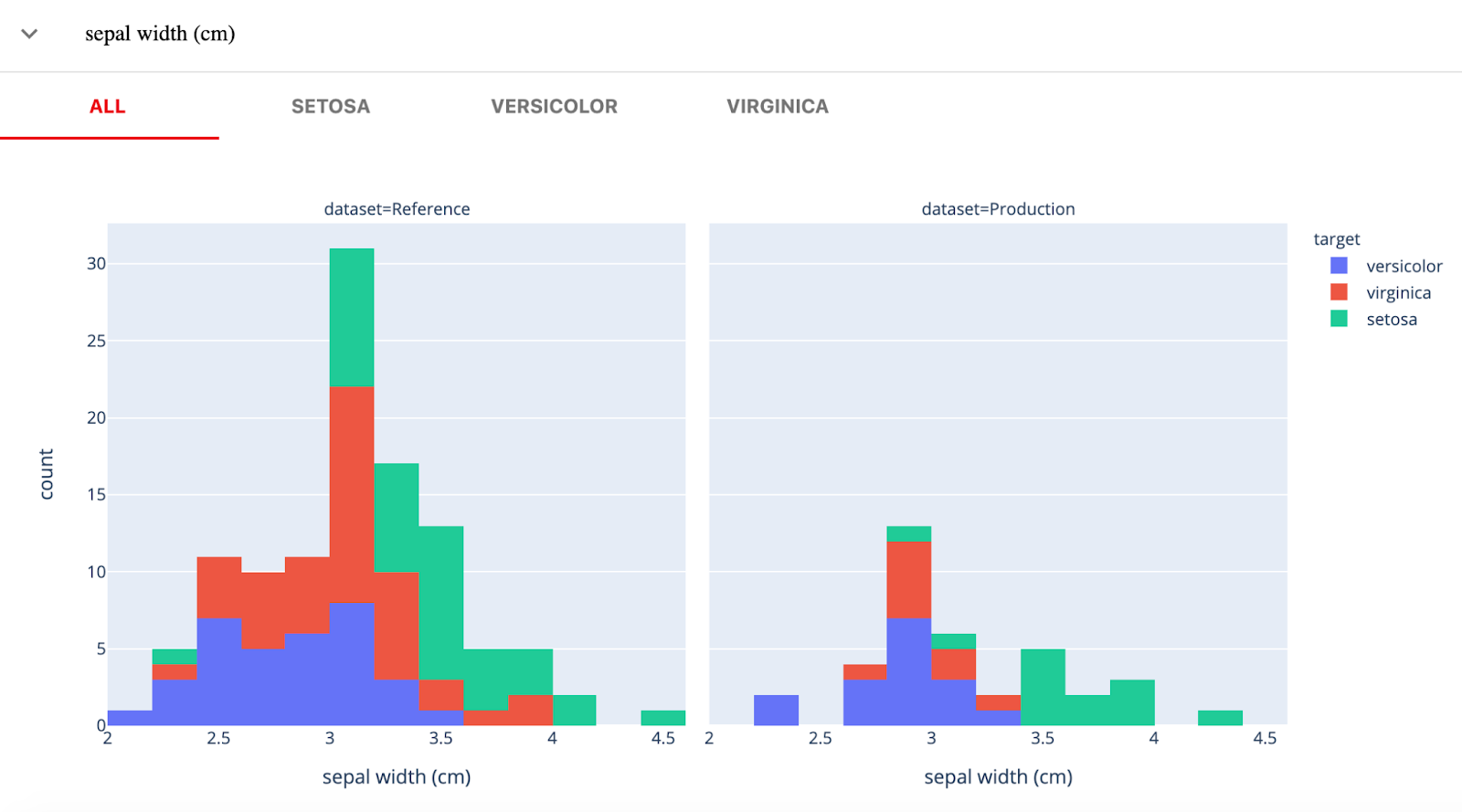
Afbeelding van Evidently
Fiddler AI is een ML-modelmonitoringtool met een duidelijke, gebruiksvriendelijke UI. Je kunt er voorspellingen mee verklaren en debuggen, modelgedrag analyseren voor de hele dataset, ML-modellen op schaal deployen en modelprestaties monitoren.
Dit zijn de belangrijkste Fiddler AI-functies voor ML-monitoring:
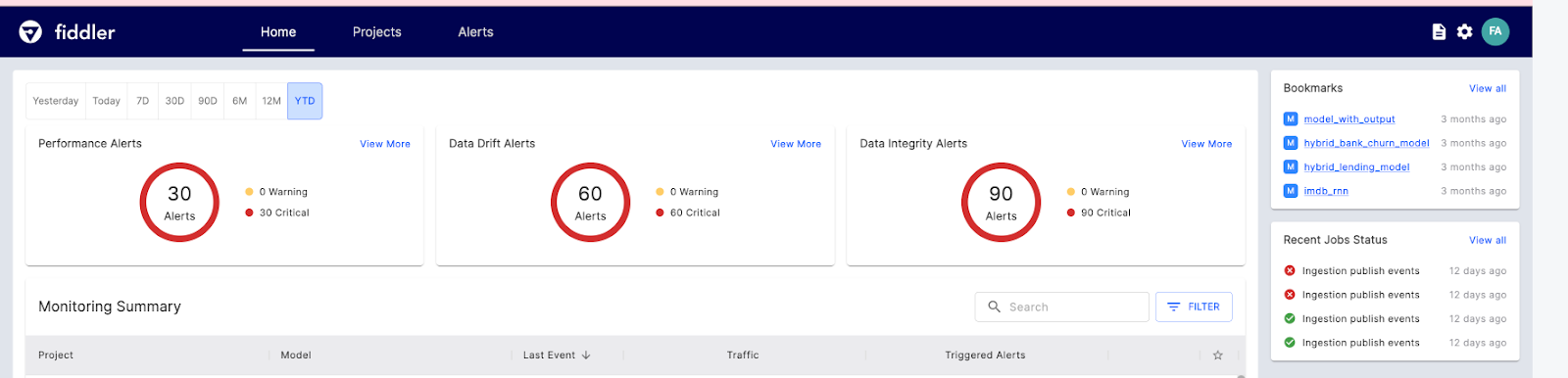
Afbeelding van Fiddler
De runtime-engine is verantwoordelijk voor het laden van het model, het pre-processen van invoerdata, het uitvoeren van inferentie en het terugsturen van de resultaten naar de clientapplicatie.
Ray is een veelzijdig framework om AI- en Python-applicaties op te schalen, waardoor ontwikkelaars hun ML-projecten makkelijker kunnen beheren en optimaliseren.
Het platform bestaat uit twee hoofdonderdelen: een core distributed runtime en een set AI-bibliotheken die ML-compute vereenvoudigen.
Ray Core biedt een beperkte set fundamentele bouwstenen waarmee je gedistribueerde applicaties kunt opbouwen en uitbreiden.
Ray levert ook AI-bibliotheken voor schaalbare datasets voor ML, gedistribueerde training, hyperparameter-tuning, reinforcement learning en schaalbare, programmeerbare serving.
Het volgende voorbeeld laat zien hoe je een Gradient Boosting Classifier-model traint en serveert.
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")Nuclio is een krachtig framework dat zich richt op data-, I/O- en compute-intensieve workloads. Het is ontworpen om serverless te zijn, zodat je je niet met serverbeheer hoeft bezig te houden. Nuclio is goed geïntegreerd met populaire datasciencetools zoals Jupyter en Kubeflow. Het ondersteunt ook een breed scala aan data- en streamingbronnen en kan draaien op CPU’s en GPU’s.
Belangrijkste functies:
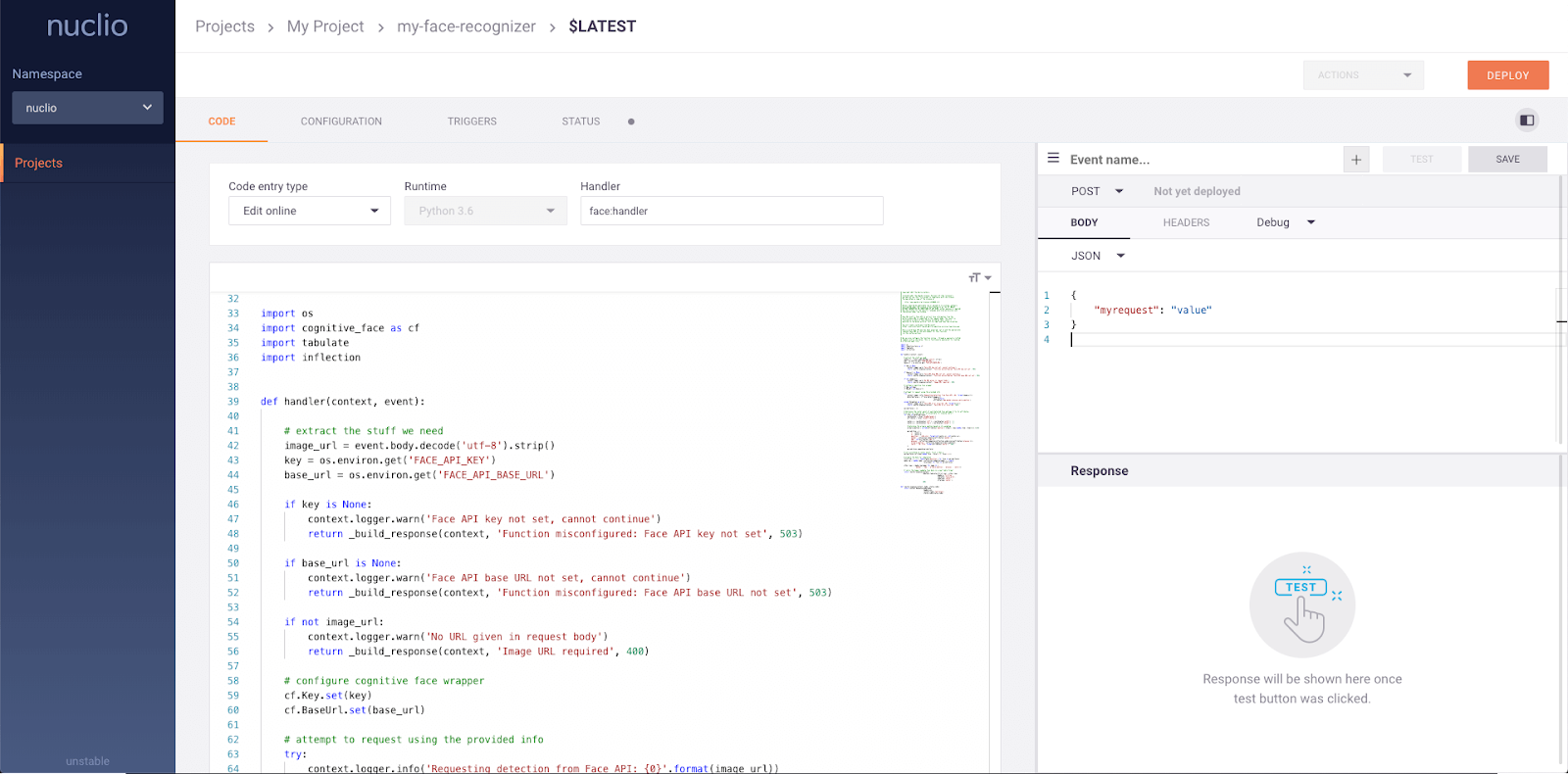
Afbeelding van Nuclio
Zoek je een allesomvattende MLOps-tool die tijdens het hele proces helpt? Dit zijn enkele van de beste opties:
Amazon Web Services SageMaker is een one-stopoplossing voor MLOps. Je kunt modelontwikkeling trainen en versnellen, experimenten tracken en versiebeheren, ML-artefacten catalogiseren, CI/CD-ML-pipelines integreren en modellen naadloos deployen, serven en monitoren in productie.
Belangrijkste functies:
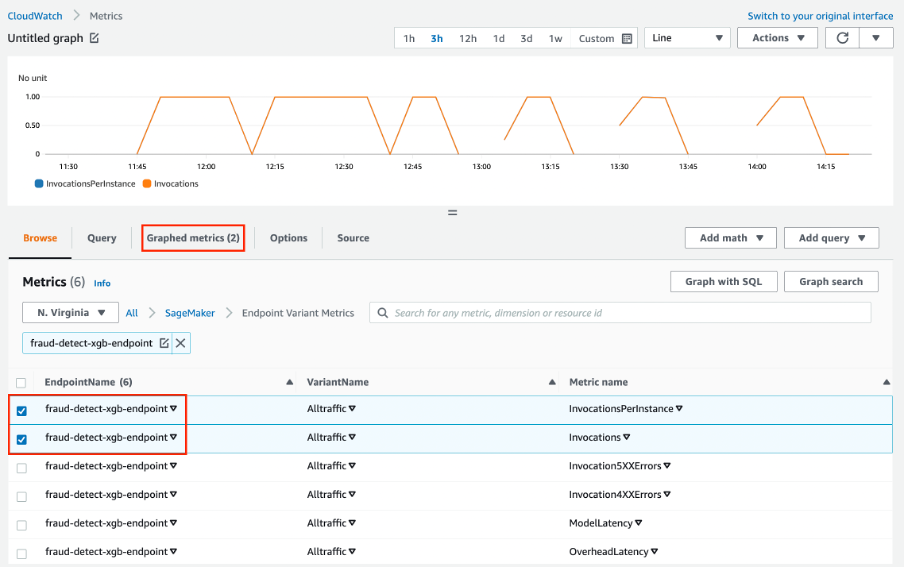
Afbeelding van Amazon SageMaker
DagsHub is een platform voor de ML-community om data, modellen, experimenten, ML-pipelines en code te tracken en te versiebeheren. Het stelt je team in staat om ML-projecten te bouwen, te reviewen en te delen.
Eenvoudig gezegd: het is een GitHub voor machine learning, met diverse tools om het end-to-end ML-proces te optimaliseren.
Belangrijkste functies:
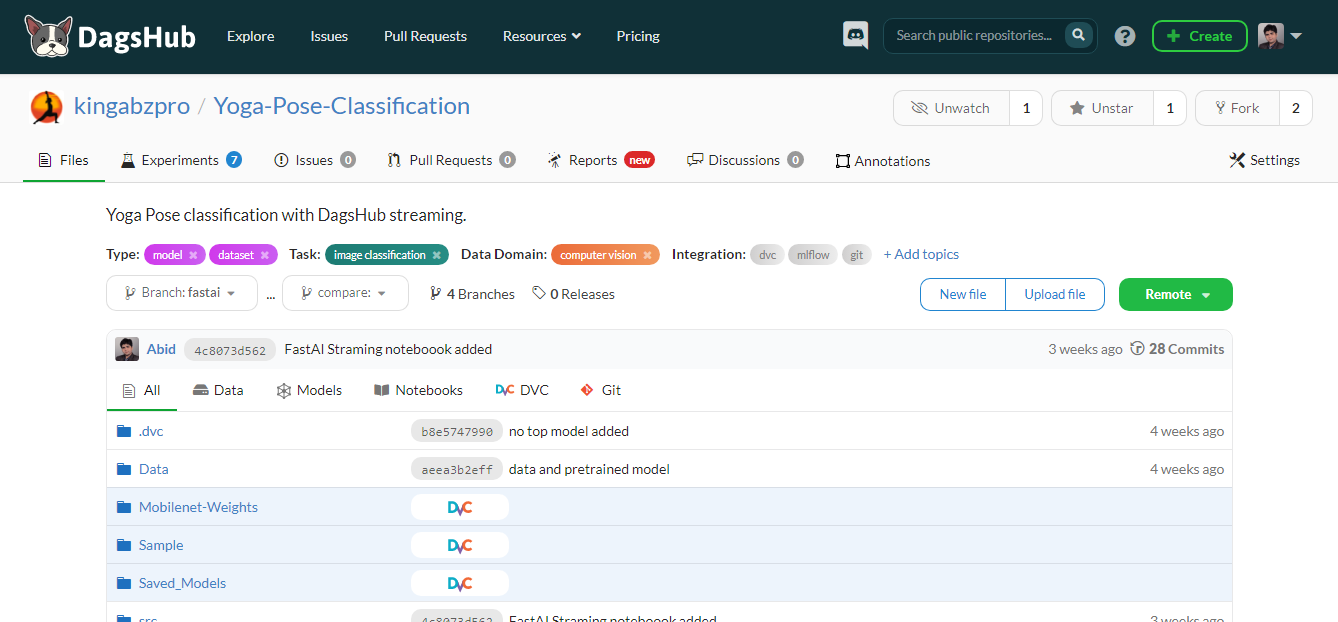
Afbeelding door de auteur
Het Iguazio MLOps Platform is een end-to-end MLOps-platform waarmee organisaties de ML-pipeline kunnen automatiseren, van dataverzameling en -voorbereiding tot training, deployment en monitoring in productie. Het biedt een open (MLRun) en beheerd platform.
Een belangrijk onderscheidend kenmerk van het Iguazio MLOps Platform is de flexibiliteit in deploymentopties. Gebruikers kunnen AI-toepassingen overal deployen: in elke cloud, hybride of on-premises. Dit is vooral belangrijk in sectoren als zorg en financiën, waar on-premises deployment soms vereist is vanwege dataprivacy.
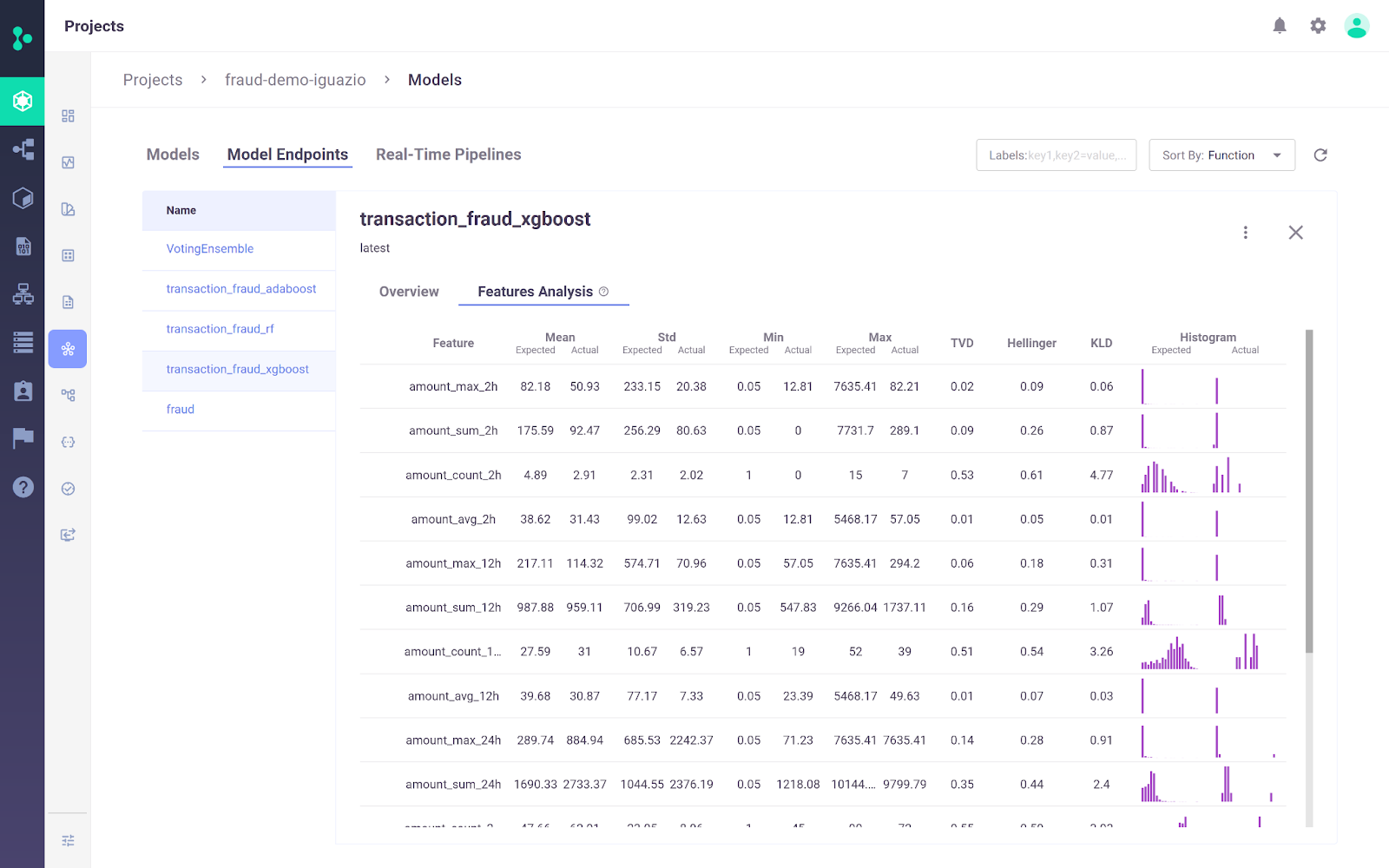
Afbeelding van Iguazio MLOps Platform
Belangrijkste functies:
Hier is een vergelijkingstabel om deze tools naast elkaar te beoordelen en de beste keuzes voor jouw projecten te maken:
| Tool | Belangrijkste functionaliteit | Ondersteunde frameworks | Deployopties |
|---|---|---|---|
| Qdrant | Vector similarity search en databasemanagement | Python, meerdere talen | Cloud-native, horizontaal schaalbaar |
| LangChain | Toepassingen ontwikkelen met taalmodellen | Python, JavaScript | REST API, templates |
| MLFlow | Experimenttracking, modelregister, deployment | Python, R, Java, REST API | Lokaal, cloud |
| Comet ML | Experimenttracking en optimalisatie | Scikit-learn, PyTorch, TensorFlow, HuggingFace | Lokaal, cloud |
| Weights & Biases | Experimenttracking, versiebeheer van data en modellen | Fastai, Keras, PyTorch, HuggingFace, Yolov5, Spacy | Lokaal, cloud |
| Prefect | Workflow-orkestratie en monitoring | Python | Lokaal (Orion UI), Cloud |
| Metaflow | Workflowmanagement voor data science | Scikit-learn, TensorFlow, Python, R | AWS, GCP, Azure, lokaal |
| Kedro | Workflow-orkestratie, reproduceerbaarheid | Python | Lokaal, gedistribueerd |
| Pachyderm | Datatransformatie, versiebeheer en lineage | Elke taal | Kubernetes |
| DVC | Versiebeheer van data en pipelines | Git, Python | Lokaal, cloud |
| LakeFS | Git-achtig versiebeheer voor datalakes | Elke opslagservice | Lokaal, cloud |
| Feast | Gecentraliseerde feature store voor ML-modellen | Python | Lokaal, cloud |
| Featureform | Virtuele feature store voor ML-modellen | Python | Lokaal, cloud |
| Deepchecks | Testen en valideren van ML-modellen | Python | Lokaal, cloud |
| TruEra | Testen van modelkwaliteit en prestaties | Python | Lokaal, cloud |
| Kubeflow | ML-modeluitrol en orkestratie | TensorFlow, PyTorch, PaddlePaddle, MXNet, XGboost | Kubernetes, cloud |
| BentoML | Modeluitrol en API-beheer | Keras, ONNX, LightGBM, PyTorch, Scikit-learn | Lokaal, cloud |
| Hugging Face | Inferentie en modeluitrol | Elk model | Cloud |
| Evidently | Monitoring van ML-modellen voor data- en targetdrift | Python | Lokaal, cloud |
| Fiddler | Monitoring en debugging van ML-modellen | Python | Lokaal, cloud |
| Ray | AI- en Python-applicaties opschalen | Python | Lokaal, cloud |
| Nuclio | Serverless framework voor data- en compute-intensieve workloads | Jupyter, Kubeflow | Cloud, on-premises |
| AWS SageMaker | End-to-end beheer van de ML-levenscyclus | Python, R, Java, TensorFlow, PyTorch | AWS-cloud |
| DagsHub | Versiebeheer en samenwerking voor ML-projecten | Git, DVC, MLflow | Lokaal, cloud |
| Iguazio | End-to-end automatisering van ML-pipelines | Python, MLRun | Cloud, hybride, on-premises |
We zitten in een periode waarin de MLOps-sector een sterke groei doormaakt. Elke week zie je nieuwe ontwikkelingen, startups en tools die worden gelanceerd om het basale probleem op te lossen: notitieboeken omzetten naar productieklare applicaties. Zelfs bestaande tools verbreden hun horizon en integreren nieuwe functies om super-MLOps-tools te worden.
In deze blog hebben we de beste MLOps-tools voor verschillende stappen in het MLOps-proces bekeken. Deze tools helpen je tijdens de fases van experimenteren, ontwikkelen, deployen en monitoren.
Ben je nieuw met machine learning en wil je de essentiële vaardigheden beheersen om een baan te krijgen als machine learning scientist? Probeer dan onze Machine Learning Scientist with Python-carrièretrack.
Ben je professional en wil je meer leren over standaard MLOps-praktijken? Lees dan ons artikel MLOps Best Practices en hoe je ze toepast en bekijk onze MLOps Fundamentals-skill track.
Leer meer over MLOps met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
