
Course
MLOps Concepts
2 hr
42.6K
Learn how to work with LLMs in Python right in your browser

With the introduction of GPT-4 and later GPT-4o, the race has begun to produce large language models and realize the full potential of modern AI. LLMs require vector databases and integration frameworks for building intelligent AI applications.
Qdrant is an open-source vector similarity search engine and vector database that provides a production-ready service with a convenient API, allowing you to store, search, and manage vector embeddings.
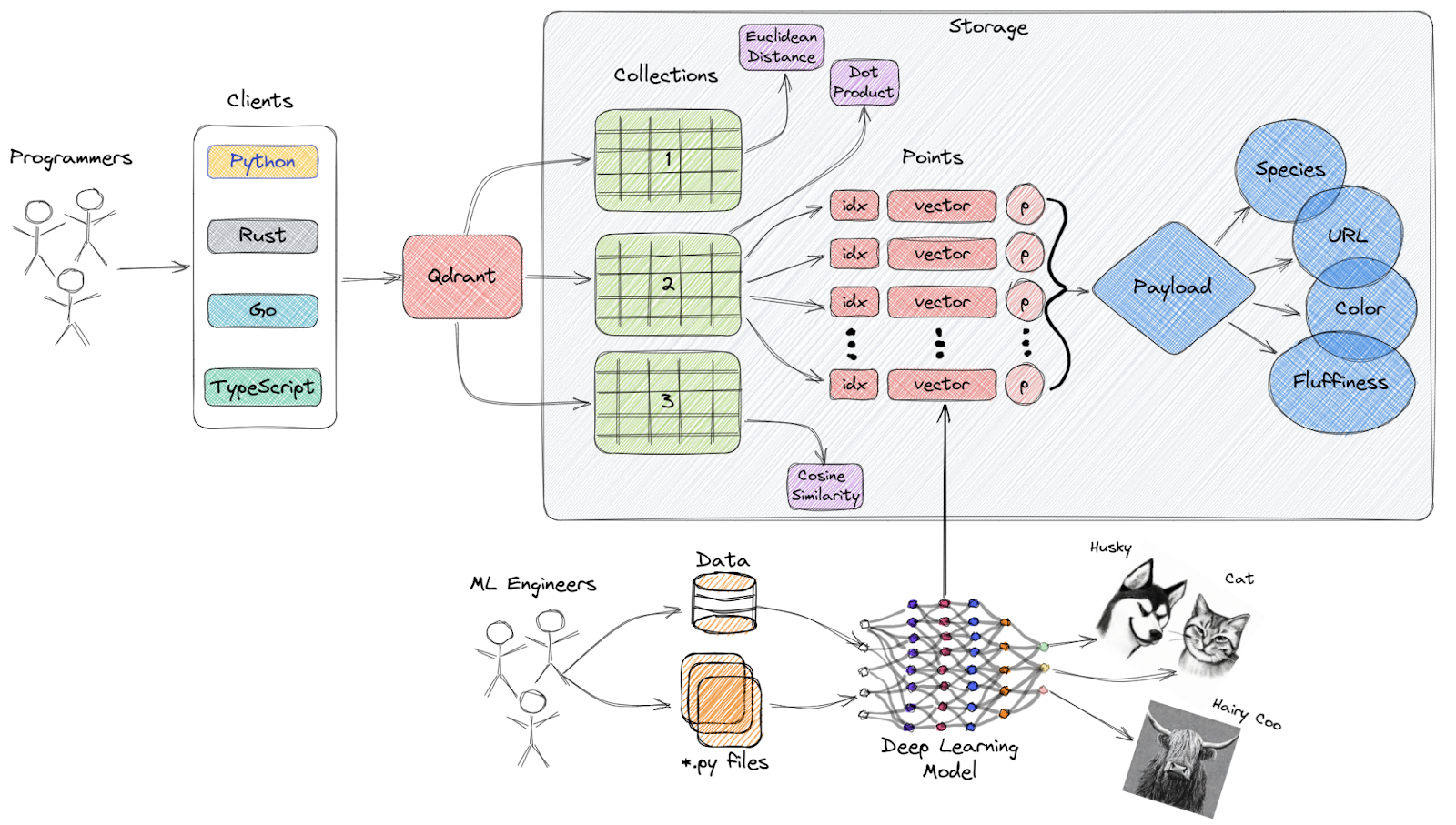
High-Level Overview of Qdrant’s Architecture
Key features:
Discover the top vector databases by reading The 5 Best Vector Databases | A List With Examples.
LangChain is a versatile and powerful framework for developing applications powered by language models. It offers several components to enable developers to build, deploy, and monitor context-aware and reasoning-based applications.
The framework consists of 4 main components:
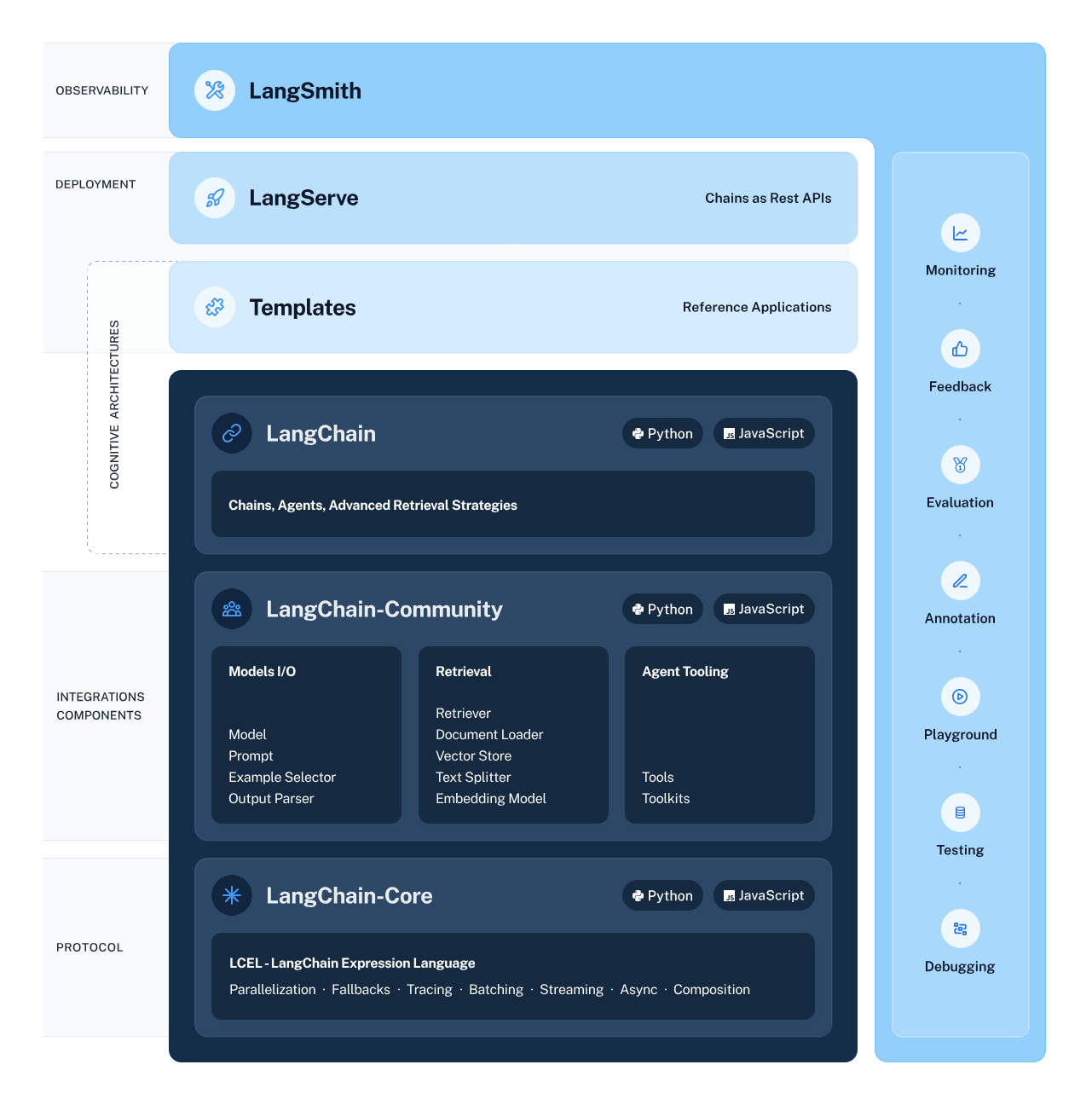
LangChain Ecosystem
Learn How to Build LLM Applications with LangChain and explore the untapped potential of large language models.
These tools allow you to manage model metadata and help with experiment tracking:
MLflow is an open-source tool that helps you manage core parts of the machine learning lifecycle. It is generally used for experiment tracking, but you can also use it for reproducibility, deployment, and model registry. You can manage the machine learning experiments and model metadata by using CLI, Python, R, Java, and REST API.
MLflow has four core functions:
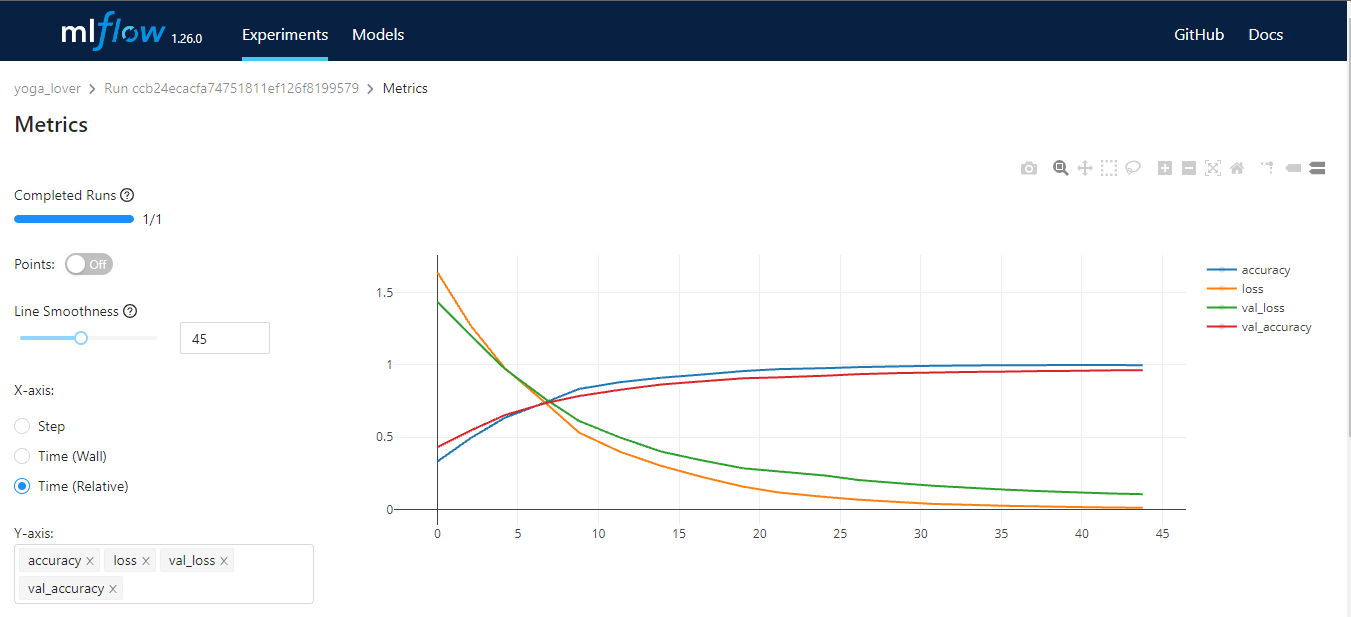
Image by Author
Comet ML is a platform for tracking, comparing, explaining, and optimizing machine learning models and experiments. You can use it with any machine learning library, such as Scikit-learn, Pytorch, TensorFlow, and HuggingFace.
Comet ML is for individuals, teams, enterprises, and academics. It allows anyone to easily visualize and compare the experiments. Furthermore, it enables you to visualize samples from images, audio, text, and tabular data.
Image from Comet ML
Weights & Biases is an ML platform for experiment tracking, data and model versioning, hyperparameter optimization, and model management. Furthermore, you can use it to log artifacts (datasets, models, dependencies, pipelines, and results) and visualize the datasets (audio, visual, text, and tabular).
Weights & Biases has a user-friendly central dashboard for machine learning experiments. Like Comet ML, you can integrate it with other machine learning libraries, such as Fastai, Keras, PyTorch, Hugging face, Yolov5, Spacy, and many more. You can check out our introduction to Weights & BIases in a separate article.
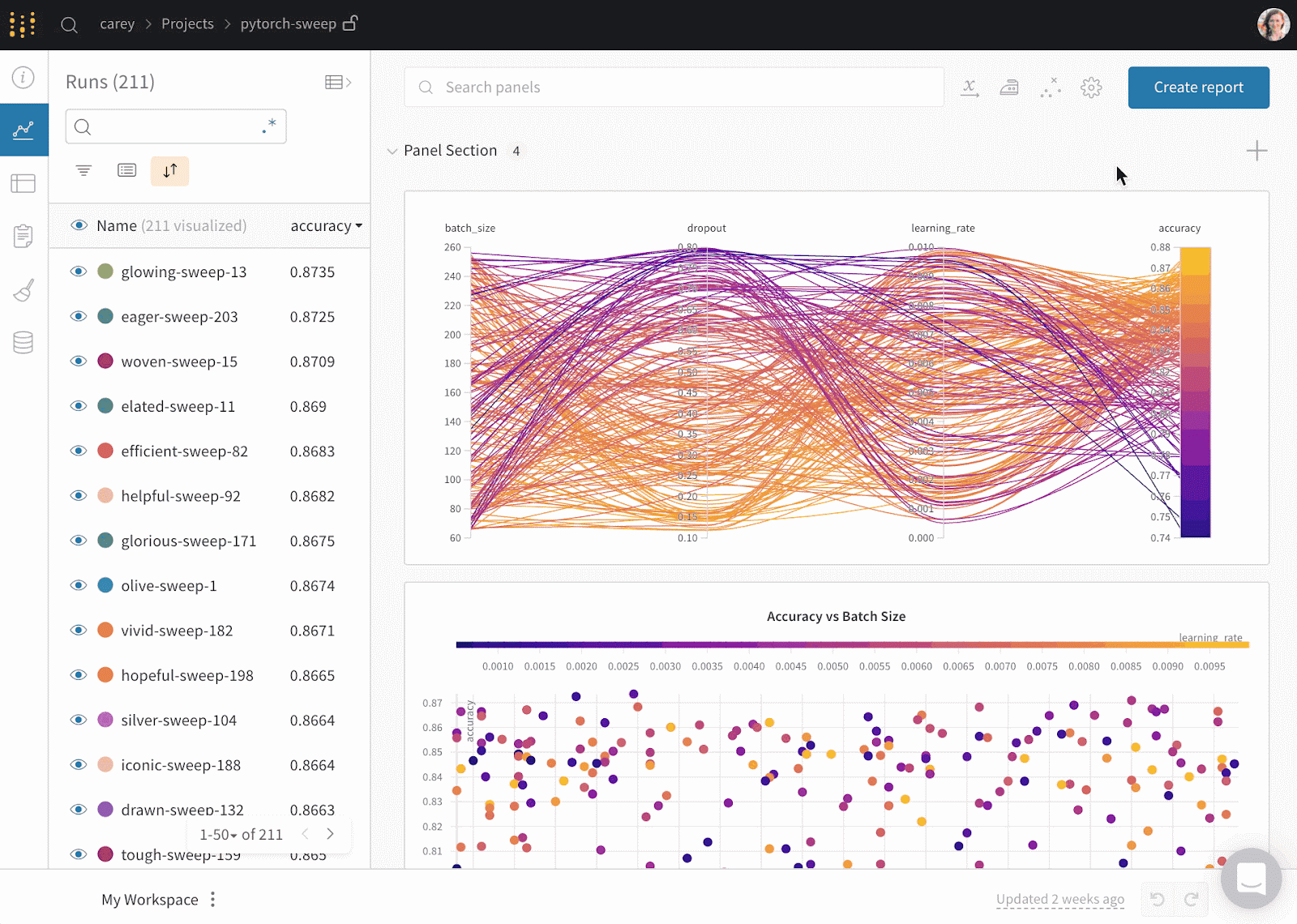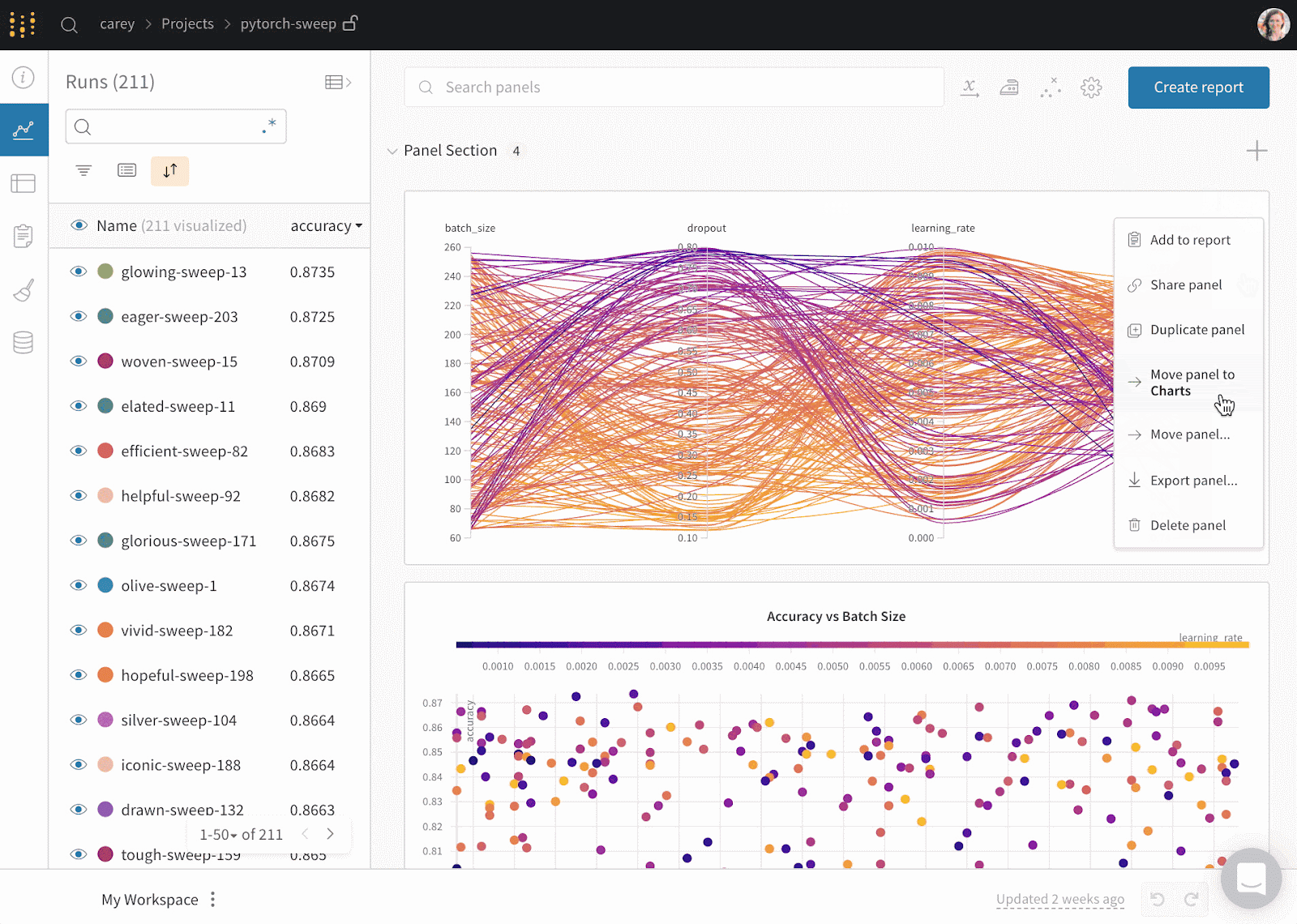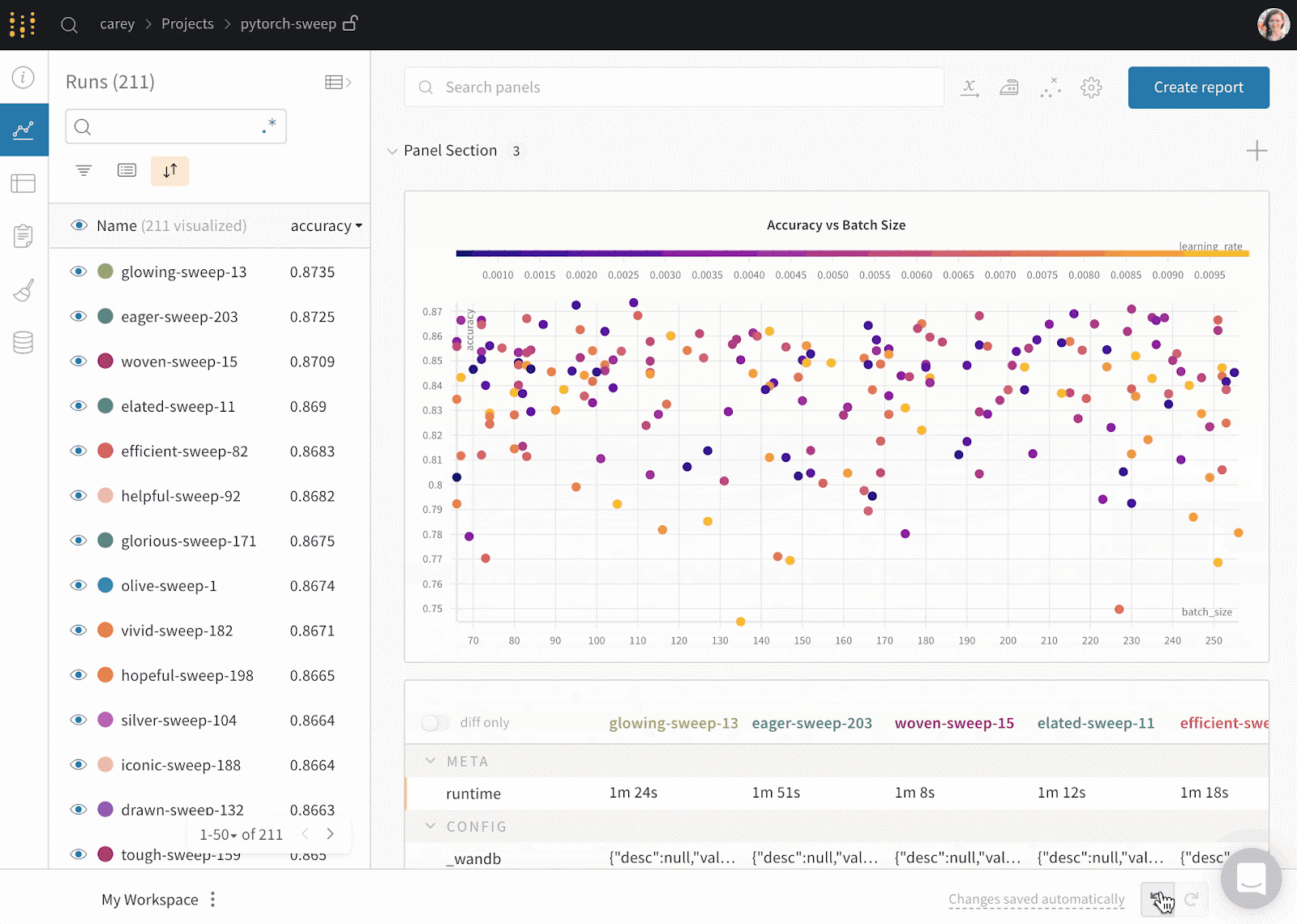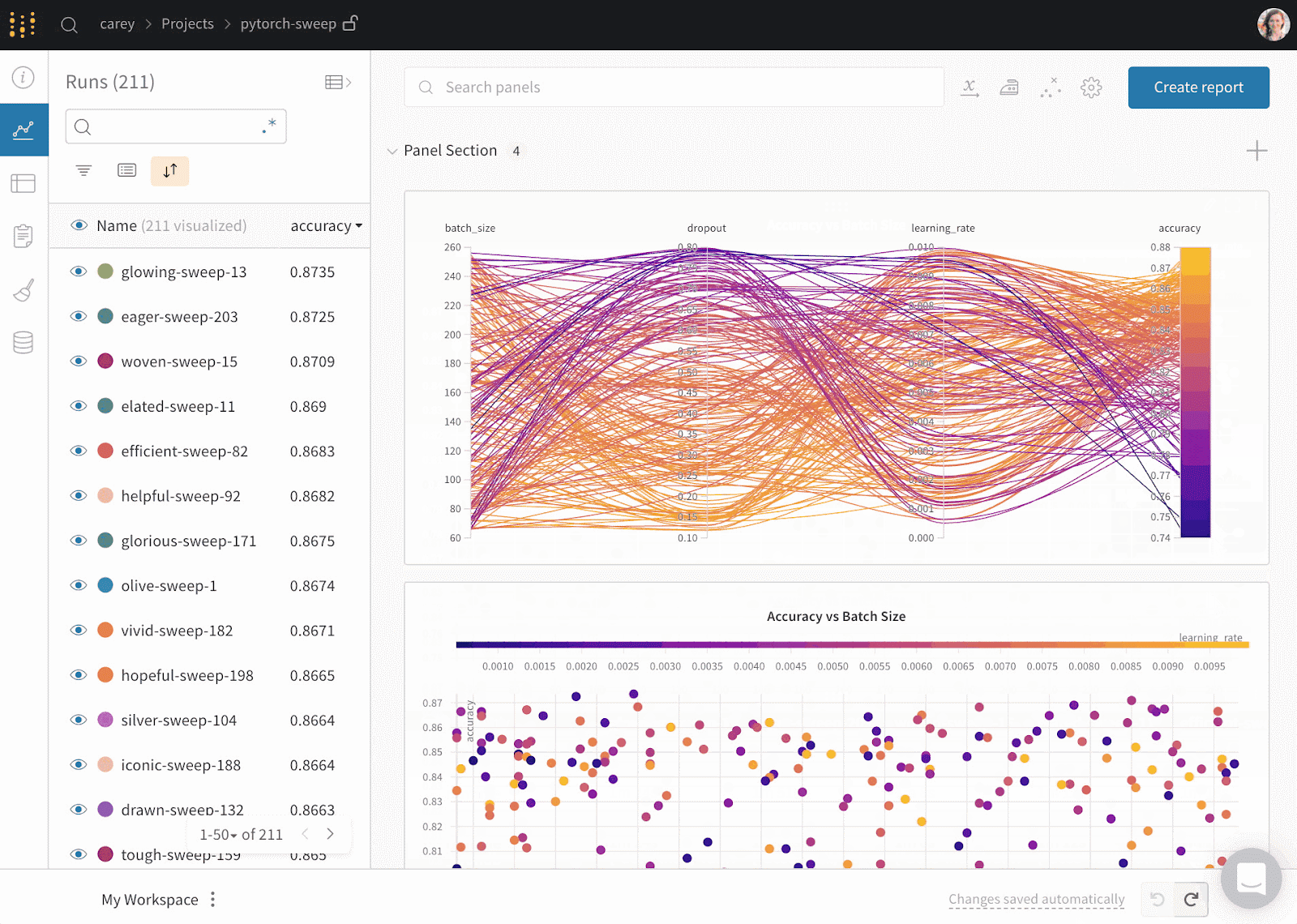
Gif from Weights & Biases
Note: You can also use TensorBoard, Pachyderm, DagsHub, and DVC Studio for experiment tracking and ML metadata management.
These tools help you create data science projects and manage machine learning workflows:
The Prefect is a modern data stack for monitoring, coordinating, and orchestrating workflows between and across applications. It is an open-source, lightweight tool built for end-to-end machine-learning pipelines.
You can either use Prefect Orion UI or Prefect Cloud for the databases.
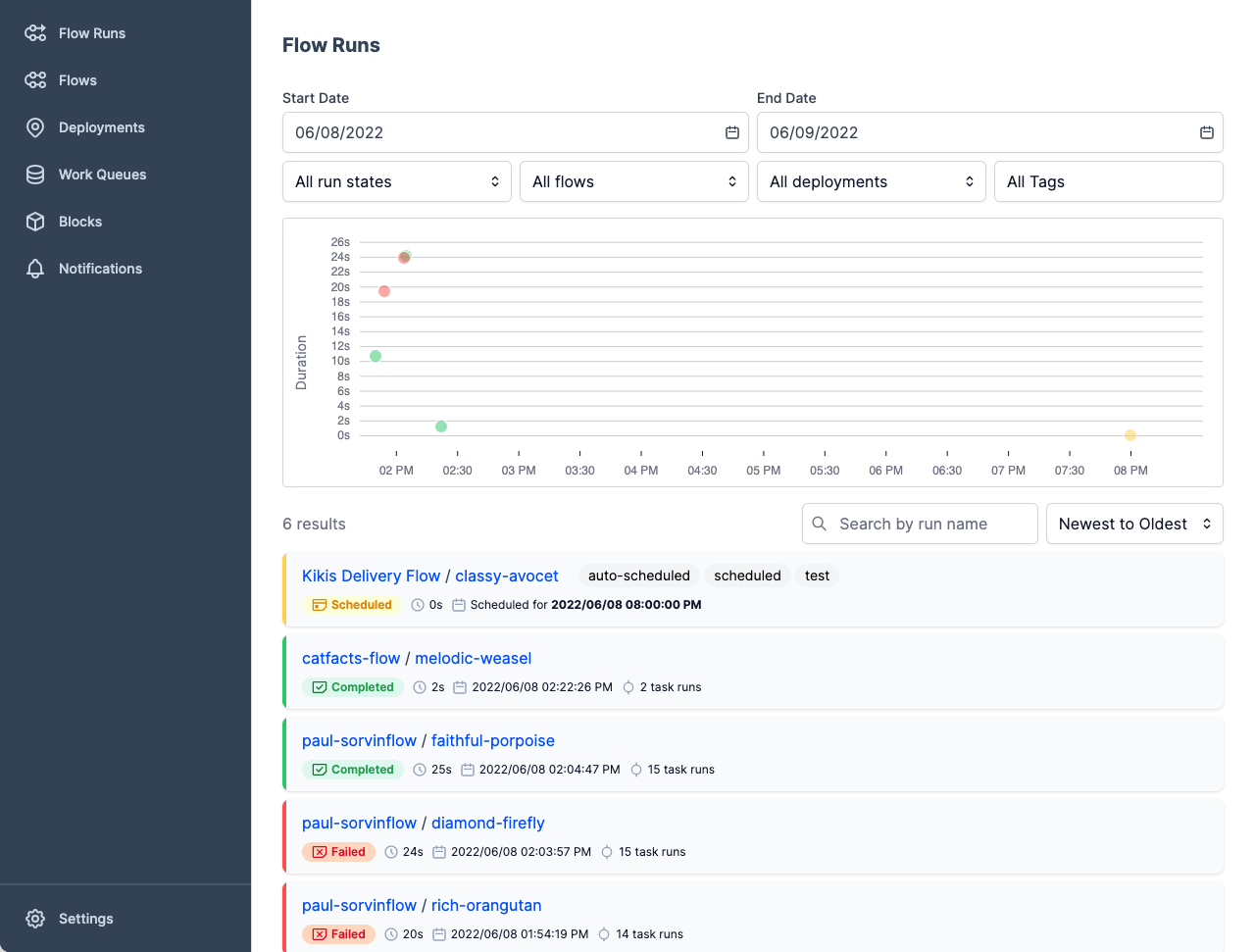
Image from Prefect
Metaflow is a powerful, battle-hardened workflow management tool for data science and machine learning projects. It was built for data scientists so they can focus on building models instead of worrying about MLOps engineering.
With Metaflow, you can design workflow, run it on the scale, and deploy the model in production. It tracks and version machine learning experiments and data automatically. Furthermore, you can visualize the results in the notebook.
Metaflow works with multiple clouds (including AWS, GCP, and Azure) and various machine-learning Python packages (like Scikit-learn and Tensorflow), and the API is available for R language too.
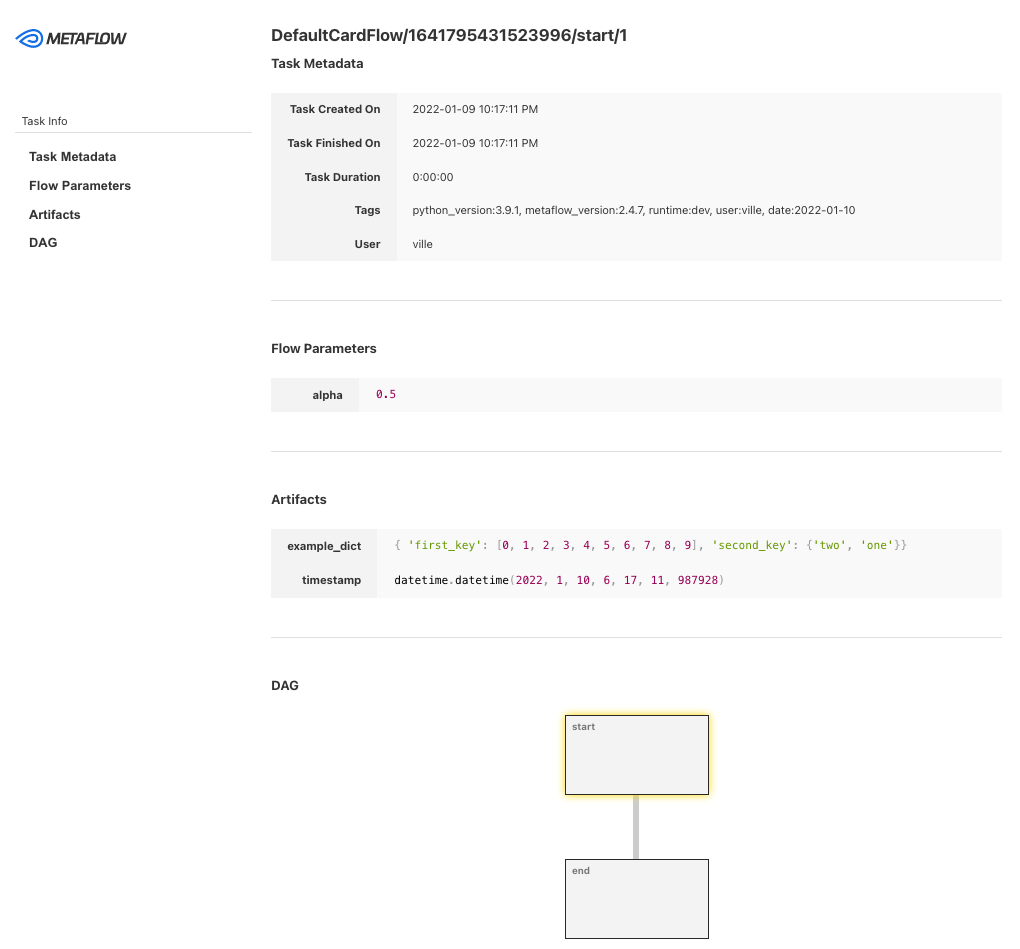
Image from Metaflow
Kedro is a workflow orchestration tool based on Python. You can use it for creating reproducible, maintainable, and modular data science projects. It integrates the concepts from software engineering into machine learning, such as modularity, separation of concerns, and versioning.
With Kedro, you can:
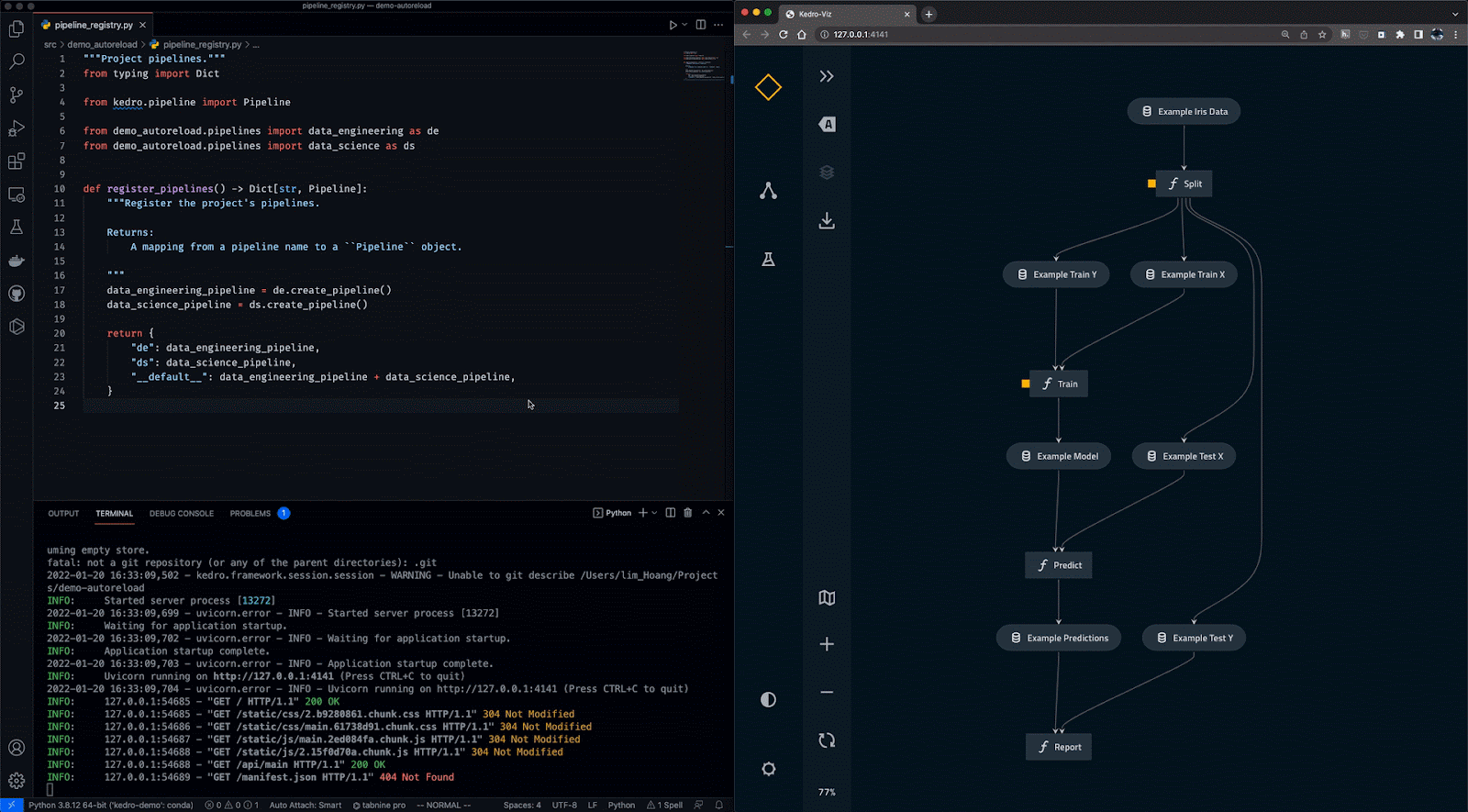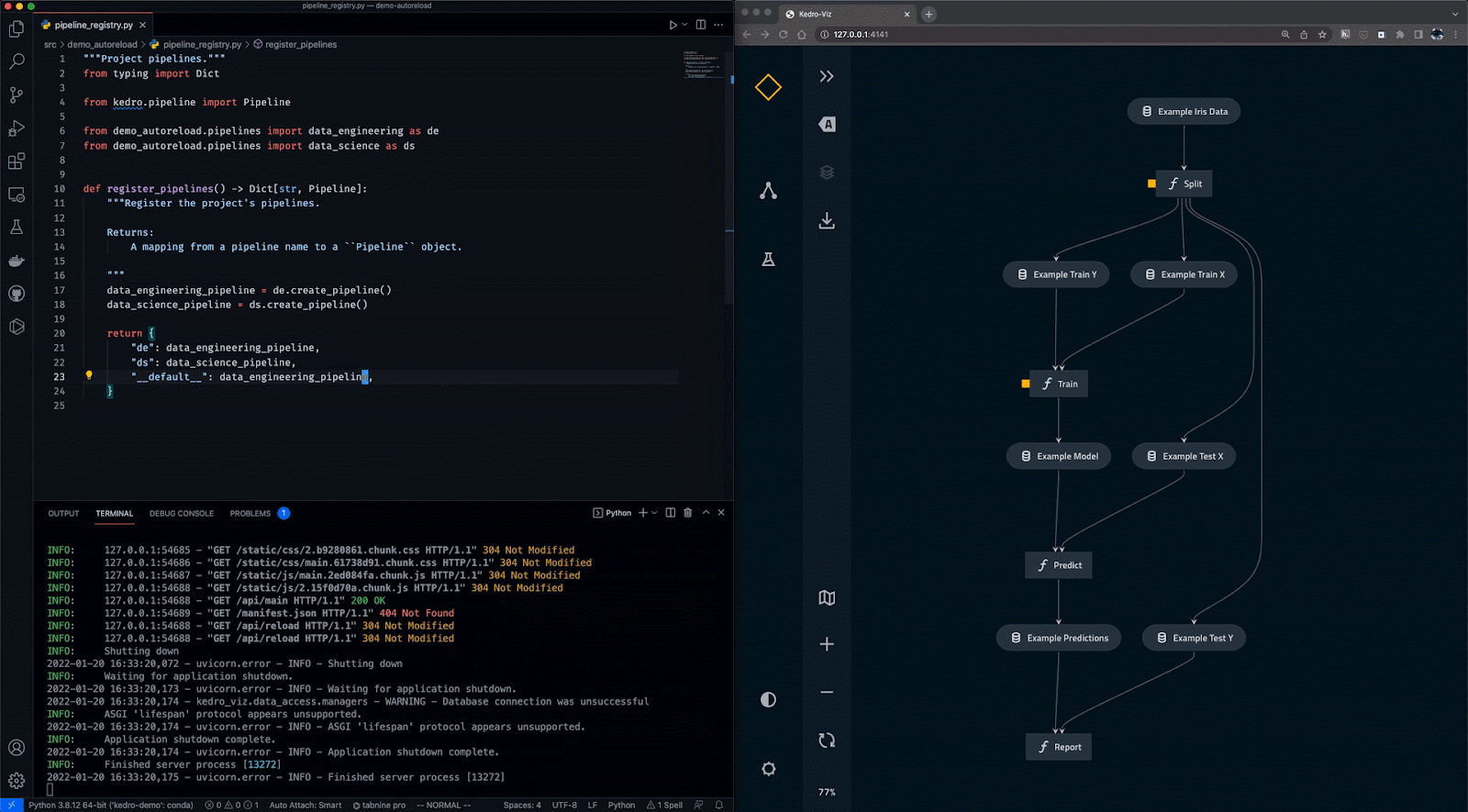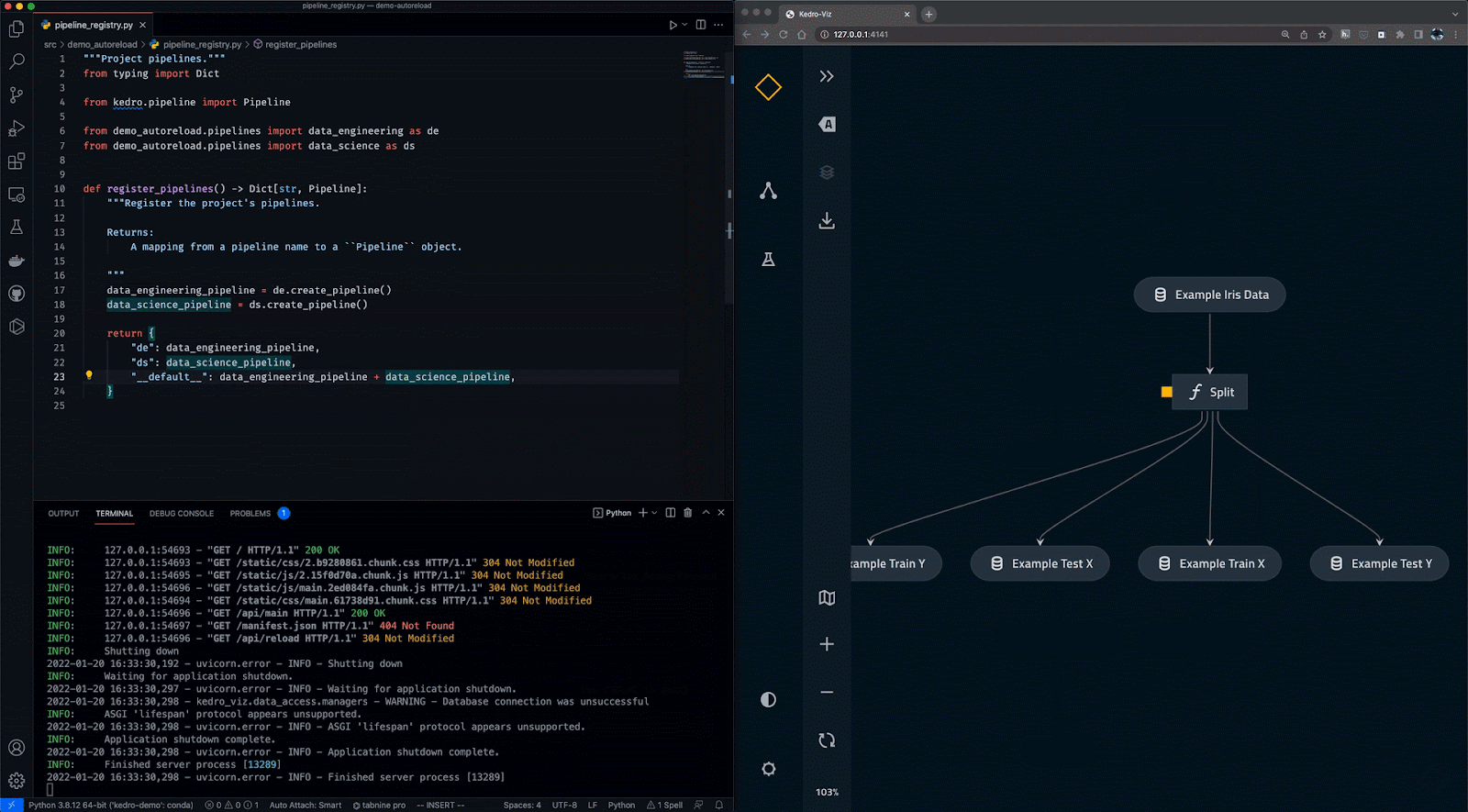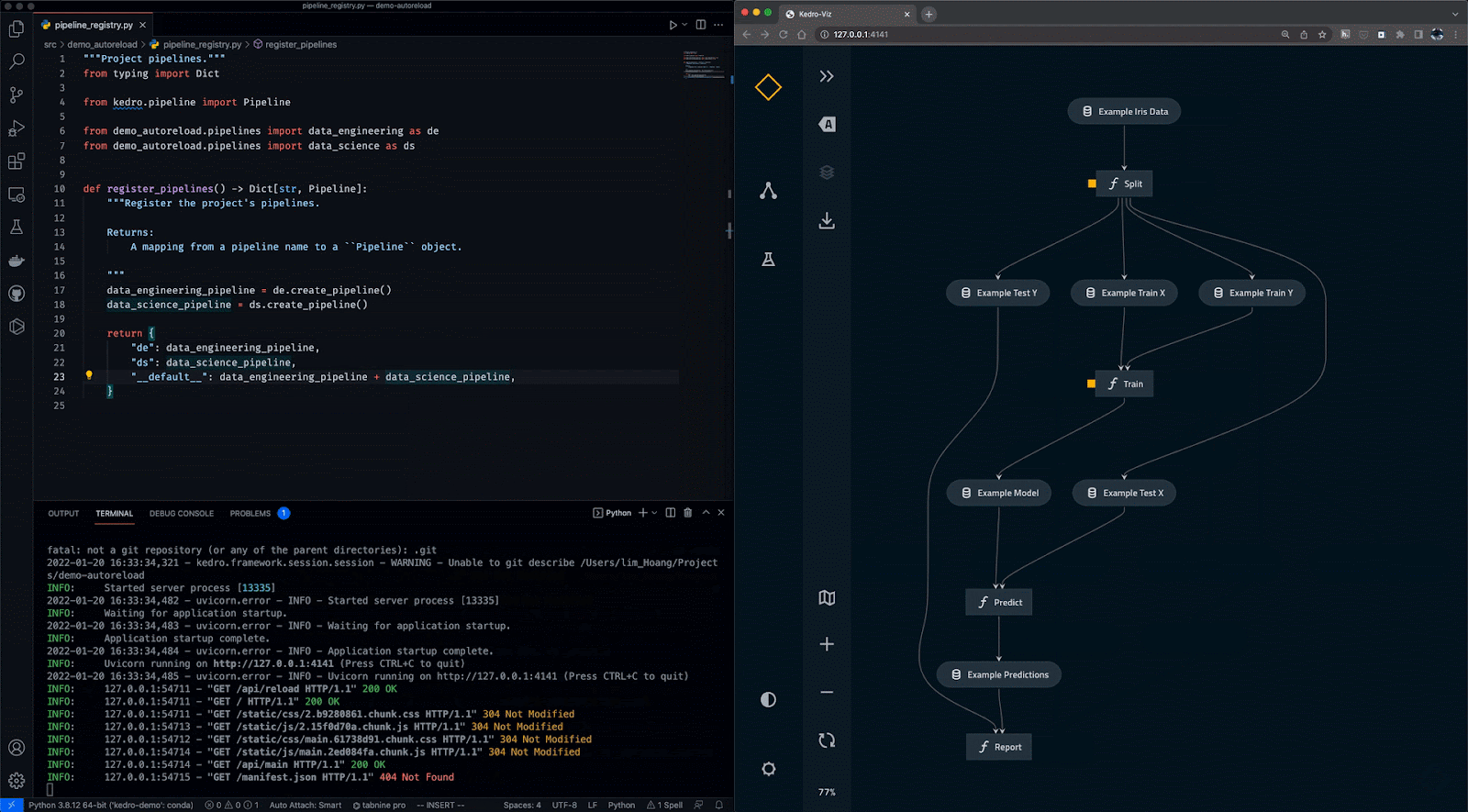
Gif from Kedro
Note: you can also use Kubeflow and DVC for orchestration and Workflow pipelines.
With these MLOps tools, you can manage tasks around data and pipeline versioning:
Pachyderm automates data transformation with data versioning, lineage, and end-to-end pipelines on Kubernetes. You can integrate with any data (Images, logs, video, CSVs), any language (Python, R, SQL, C/C++), and at any scale (Petabytes of data, thousands of jobs).
The community edition is open-source and for a small team. Organizations and teams who want advanced features can opt for the Enterprise edition.
Just like Git, you can version your data using a similar syntax. In Pachyderm, the highest level of the object is Repository, and you can use Commit, Branches, File, History, and Provenance to track and version the dataset.
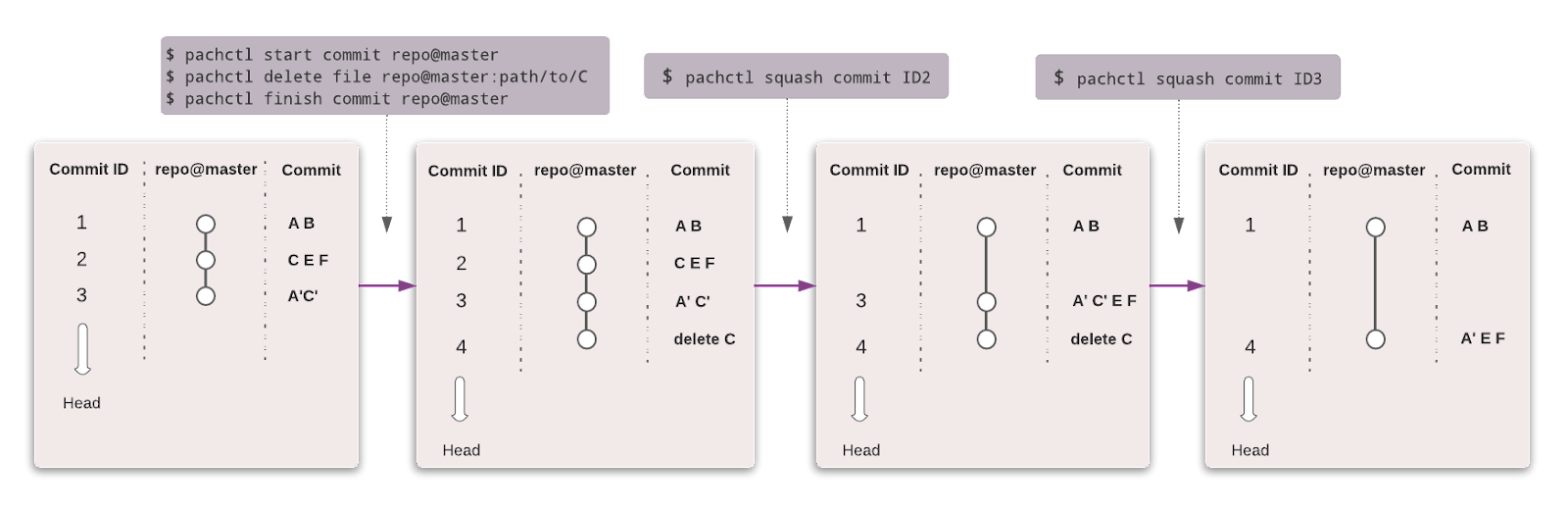
Image from Pachyderm
Data Version Control is an open-source and popular tool for machine learning projects. It works seamlessly with Git to provide you with code, data, model, metadata, and pipeline versioning.
DVC is more than just a data tracking and versioning tool.
You can use it for:
Image from DVC
Note: DagsHub can also be used for data and pipeline versioning.
LakeFS is an open-source scalable data version control tool that provides a Git-like version control interface for object storage, enabling users to manage their data lakes as they would their code. With LakeFS, users can version control data at exabyte scale, making it a highly scalable solution for managing large data lakes.
Additional capabilities:
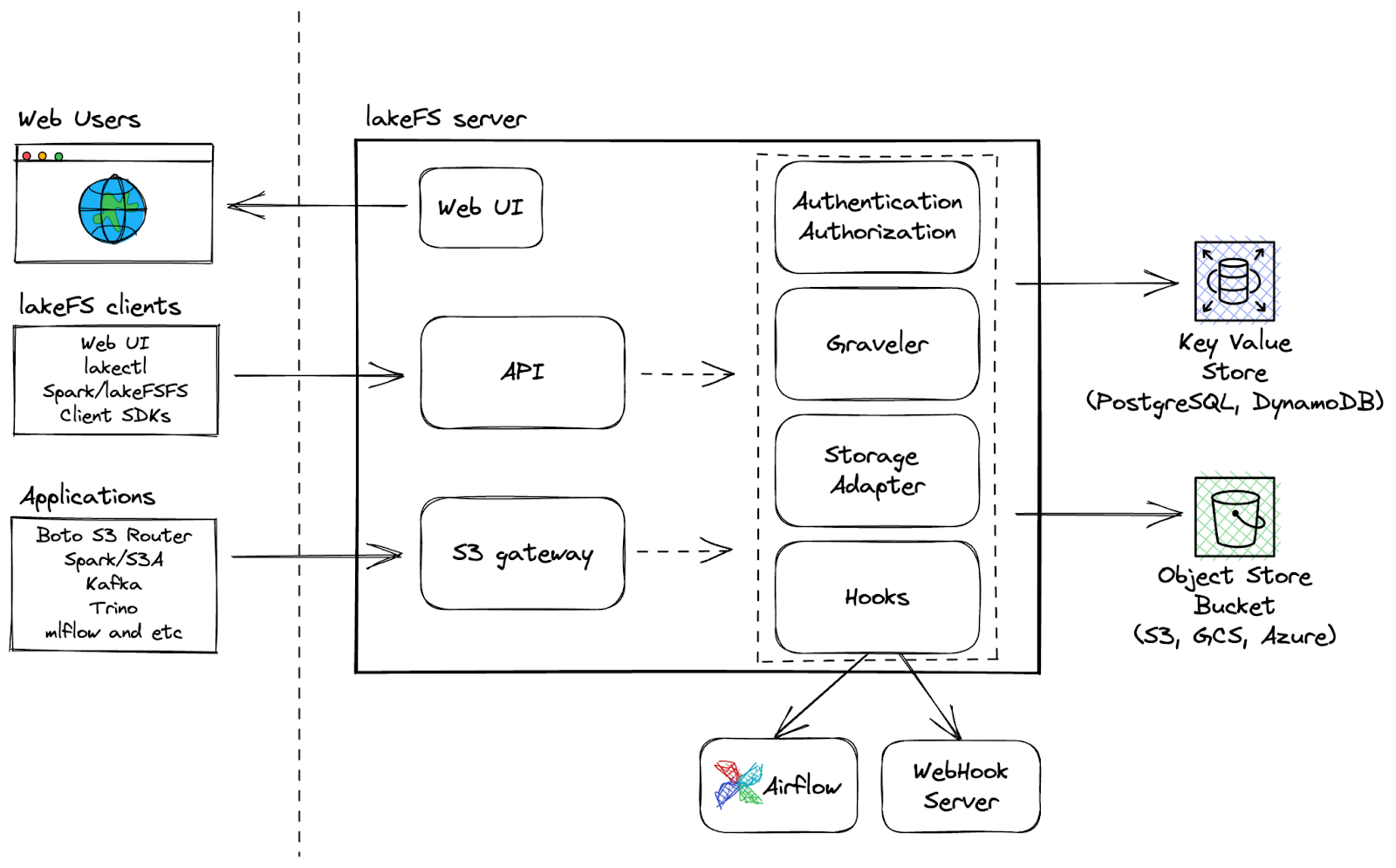
LakeFS Architecture
Feature stores are centralized repositories for storing, versioning, managing, and serving features (processed data attributes used for training machine learning models) for machine learning models in production as well as for training purposes.
Feast is an open-source feature store that helps machine learning teams productionize real-time models and build a feature platform that promotes collaboration between engineers and data scientists.
Key features:
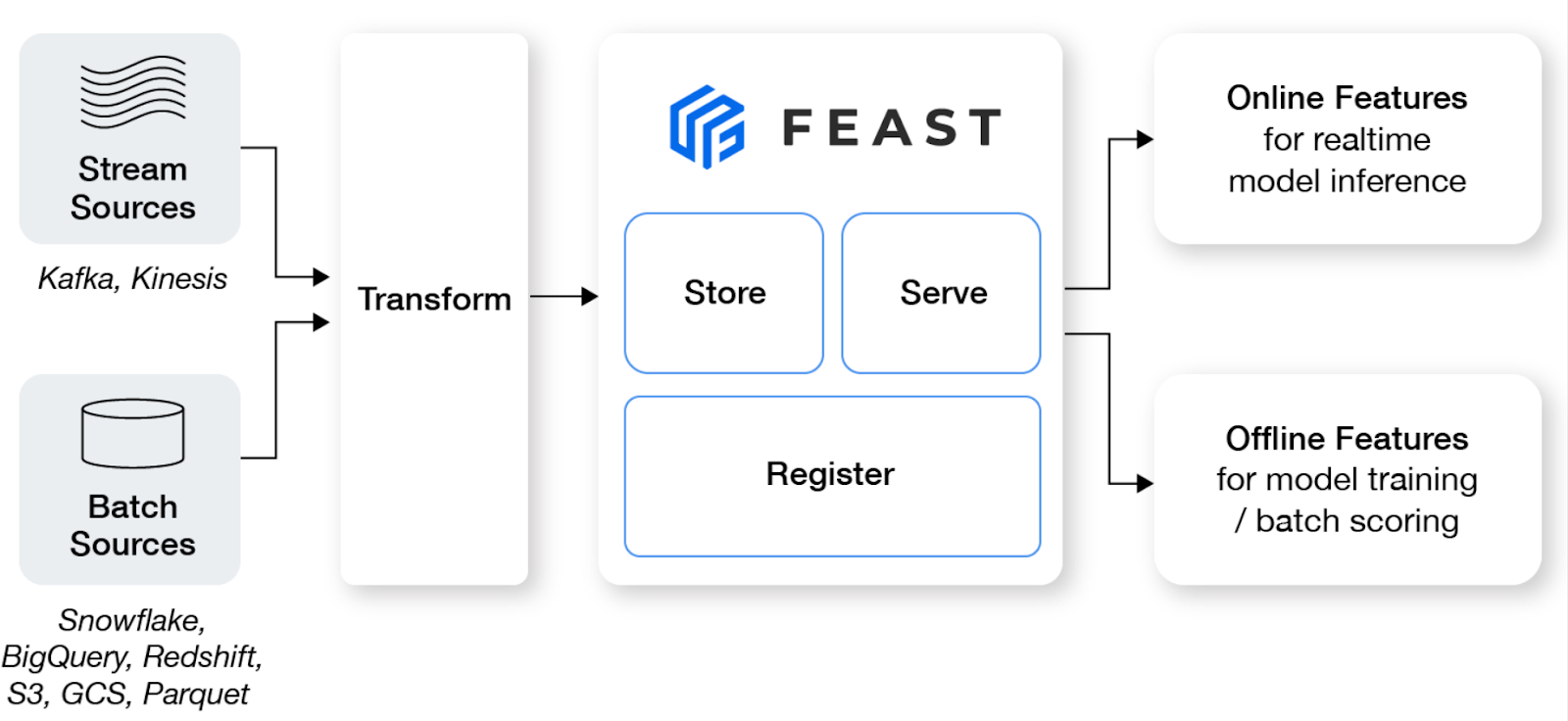
Image from Feast
Featureform is a virtual feature store that enables data scientists to define, manage, and serve their ML model's features. It can help data science teams to enhance collaboration, organize experimentation, facilitate deployment, increase reliability, and preserve compliance.
Key features:
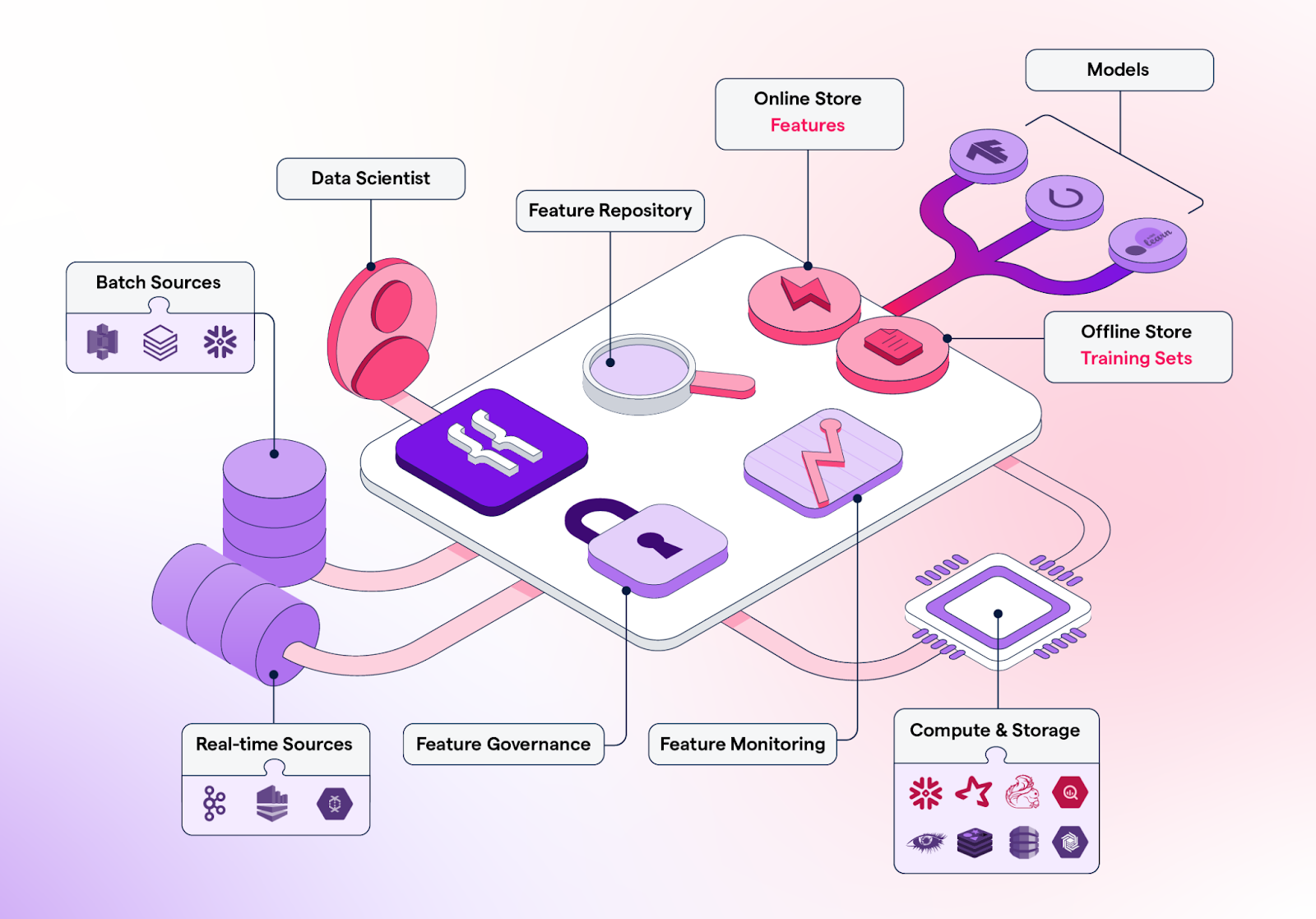
Image from Featureform
With these MLOps tools, you can test model quality and ensure machine learning models' reliability, robustness, and accuracy:
Deepchecks is an open-source solution that caters to all your ML validation needs, ensuring that your data and models are thoroughly tested from research to production. It offers a holistic approach to validate your data and models through its various components.
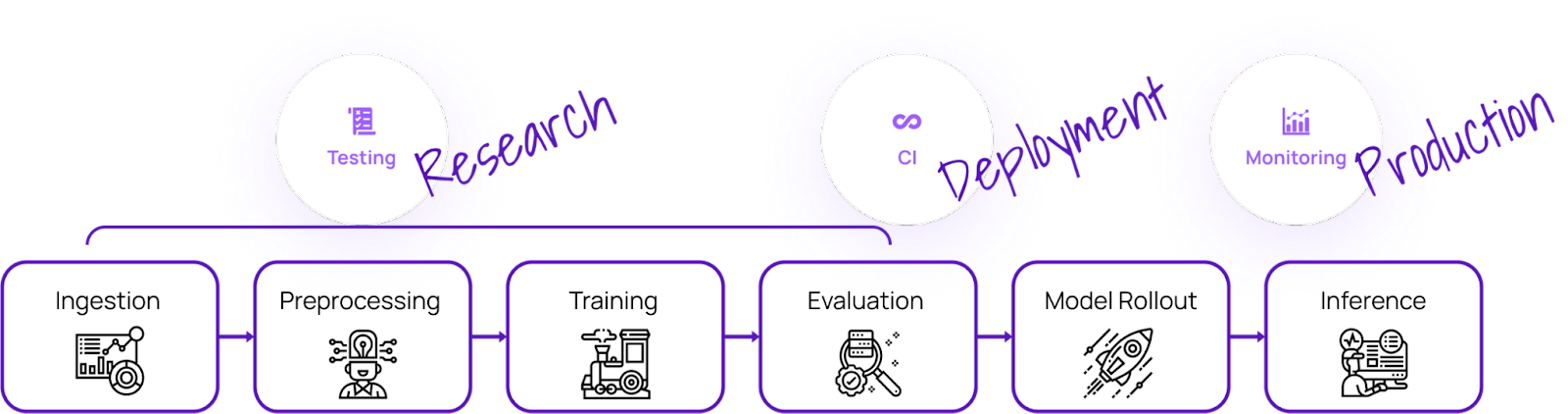
Image from Deepchecks
Deepchecks consists of three components:
TruEra is an advanced platform designed to drive model quality and performance through automated testing, explainability, and root cause analysis. It offers various features to help optimize and debug models, achieve best-in-class explainability, and integrate easily into your ML tech stack.
Key features:
Image by TruEra
When it comes to deploying models, these MLOps tools can be hugely helpful:
Kubeflow makes machine learning model deployment on Kubernetes simple, portable, and scalable. You can use it for data preparation, model training, model optimization, prediction serving, and motor the model performance in production. You can deploy machine learning workflow locally, on-premises, or to the cloud. In short, it makes Kubernetes easy for data science teams.
Key features:
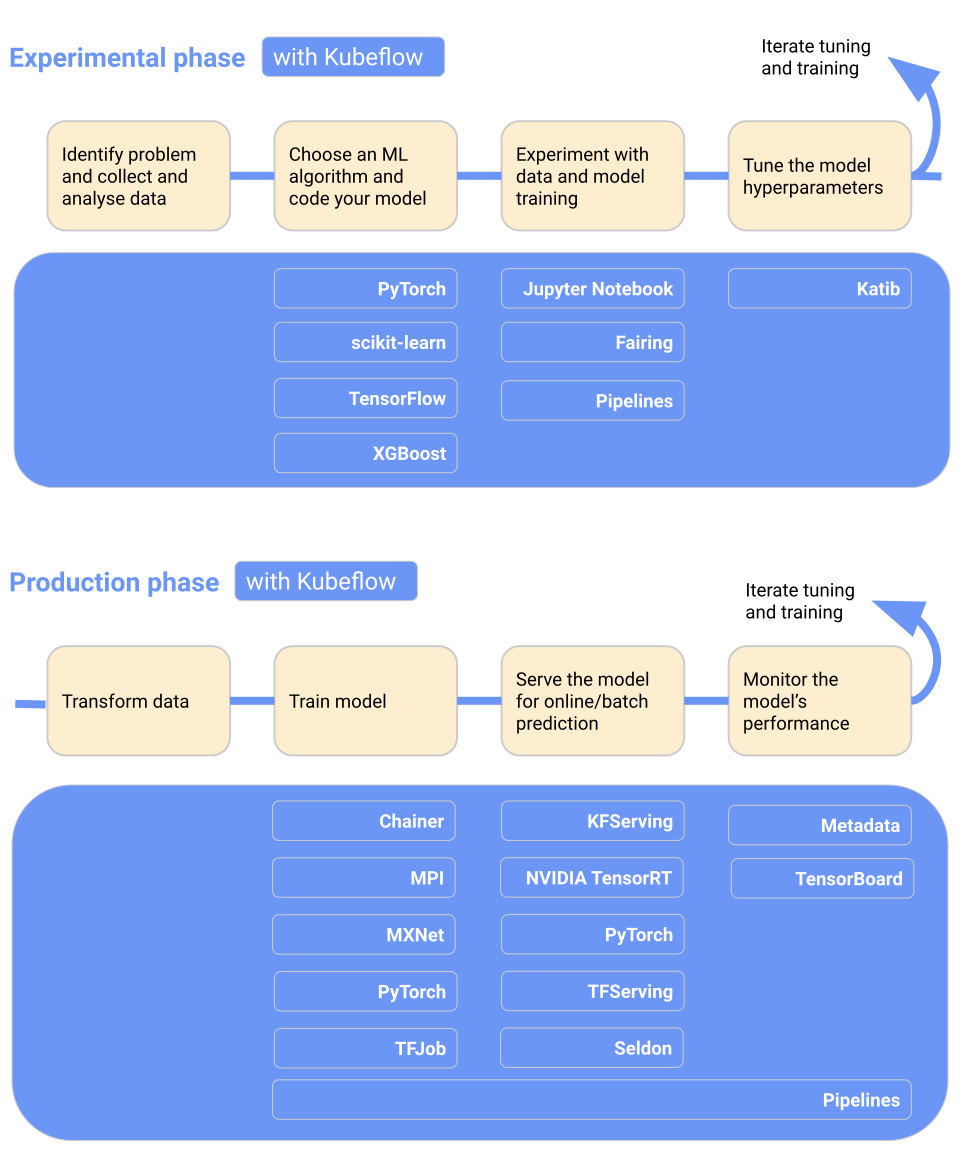
Image from Kubeflow
BentoML makes it easy and faster to ship machine learning applications. It is a Python-first tool for deploying and maintaining APIs in production. It scales with powerful optimizations by running parallel inference and adaptive batching and provides hardware acceleration.
BentoML’s interactive centralized dashboard makes it easy to organize and monitor when deploying machine learning models. The best part is that it works with all kinds of machine learning frameworks, such as Keras, ONNX, LightGBM, Pytorch, and Scikit-learn. In short, BentoML provides a complete solution for model deployment, serving, and monitoring.
Image from BentoML
Hugging Face Inference Endpoints is a cloud-based service offered by Hugging Face, an all-in-one ML platform that enables users to train, host, and share models, datasets, and demos. These endpoints are designed to help users deploy their trained machine learning models for inference without the need to set up and manage the required infrastructure.
Key features:
Image from Hugging Face
Note: You can also use MLflow and AWS sagemaker for model deployment and serving.
Whether your ML model is in development, validation, or deployed to production, these tools can help you monitor a range of factors:
Evidently AI is an open-source Python library for monitoring ML models during development, validation, and in production. It checks data and model quality, data drift, target drift, and regression and classification performance.
Evidently has three main components:
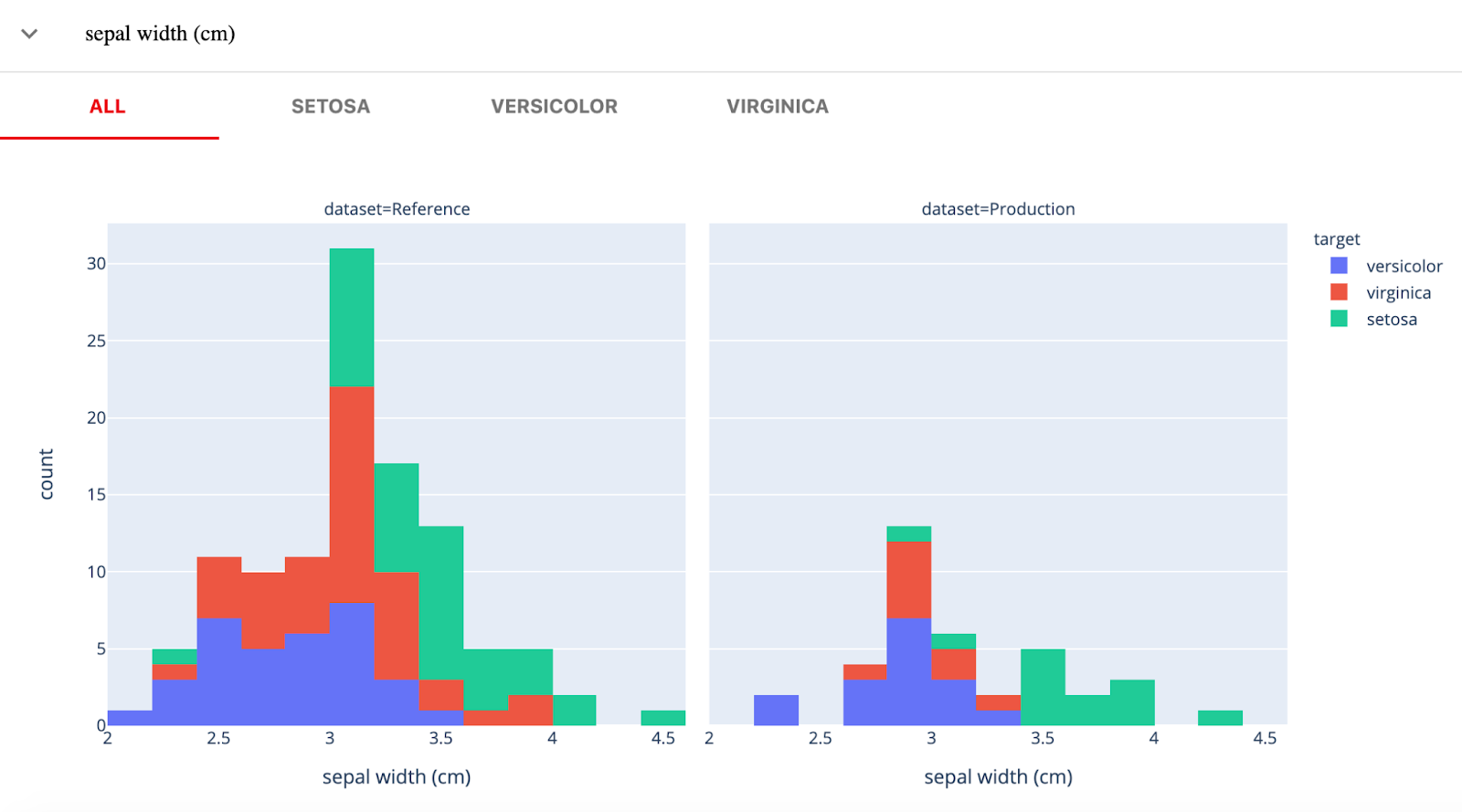
Image from Evidently
Fiddler AI is an ML model monitoring tool with an easy-to-use, clear UI. It lets you explain and debug predictions, analyze mode behavior for the entire dataset, deploy machine learning models at scale, and monitor model performance.
Let’s look at the main Fiddler AI features for ML monitoring:
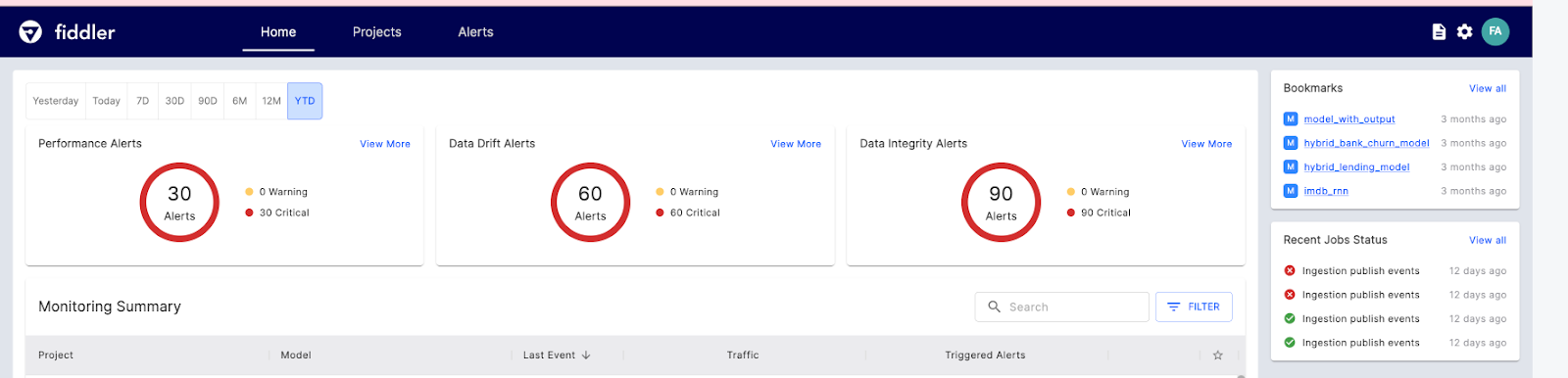
Image from Fiddler
The runtime engine is responsible for loading the model, preprocessing input data, running inference, and returning the results to the client application.
Ray is a versatile framework designed to scale AI and Python applications, making it easier for developers to manage and optimize their machine learning projects.
The platform consists of two main components: a core distributed runtime and a set of AI libraries tailored for simplifying ML compute.
Ray Core offers a limited set of fundamental elements that can be used to construct and expand distributed applications.
Ray also provides AI libraries for scalable datasets for ML, distributed training, hyperparameter tuning, reinforcement learning, and scalable and programmable serving.
The following example demonstrates the training and serving of a Gradient Boosting Classifier model.
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")Nuclio is a powerful framework that is focused on data, I/O, and compute-intensive workloads. It is designed to be serverless, meaning that you don't need to worry about managing servers. Nuclio is well-integrated with popular data science tools, such as Jupyter and Kubeflow. It also supports a wide variety of data and streaming sources and can be executed over CPUs and GPUs.
Key features:
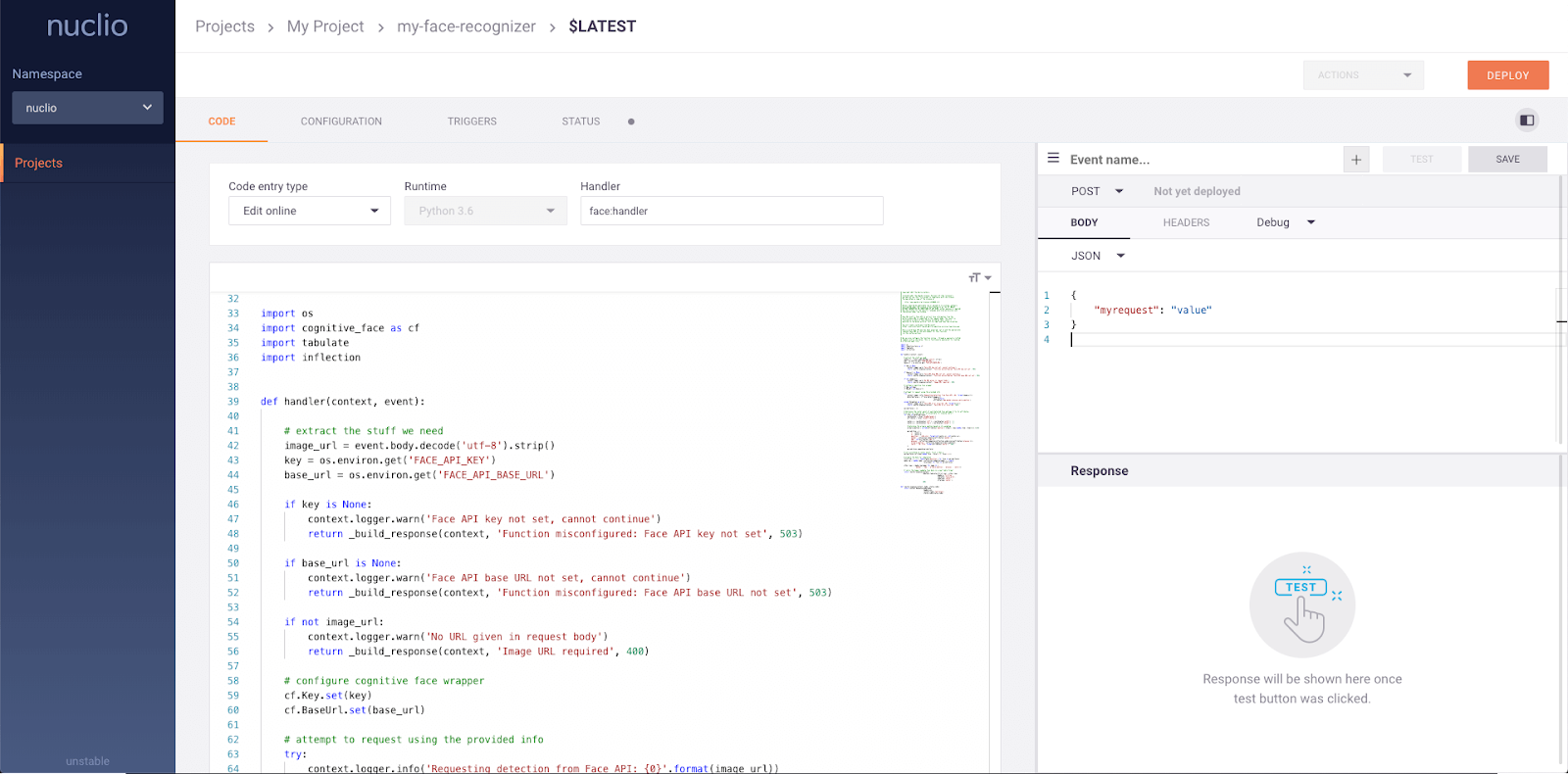
Image from Nuclio
If you’re looking for a comprehensive MLOps tool that can help during the entire process, here are some of the best:
Amazon Web Services SageMaker is a one-stop solution for MLOps. You can train and accelerate model development, track and version experiments, catalog ML artifacts, integrate CI/CD ML pipelines, and deploy, serve, and monitor models in production seamlessly.
Key features:
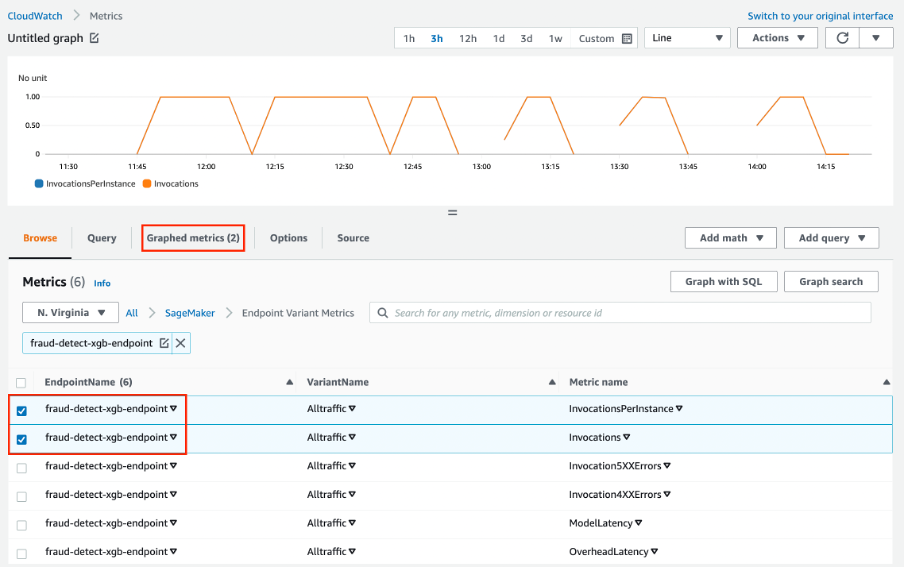
Image from Amazon SageMaker
DagsHub is a platform made for the machine learning community to track and version the data, models, experiments, ML pipelines, and code. It allows your team to build, review, and share machine-learning projects.
Simply put, it is a GitHub for machine learning, and you get various tools to optimize the end-to-end machine learning process.
Key features:
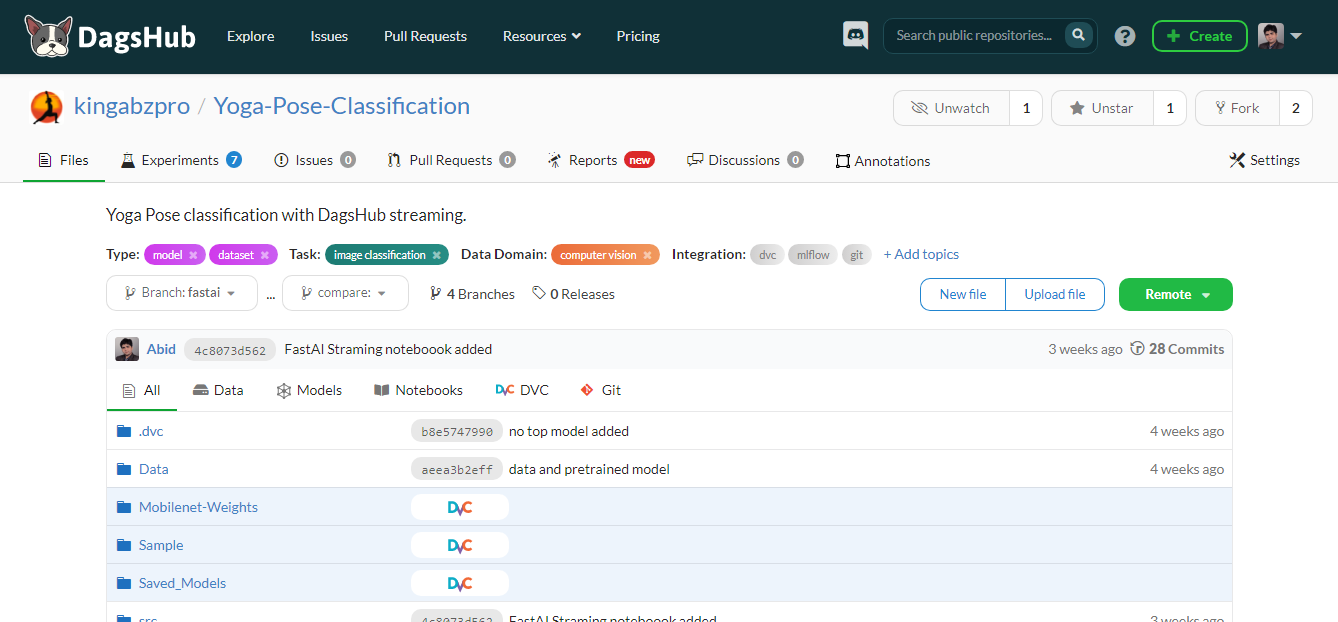
Image by Author
The Iguazio MLOps Platform is an end-to-end MLOps platform that enables organizations to automate the machine learning pipeline from data collection and preparation to training, deployment, and monitoring in production. It provides an open (MLRun) and managed platform.
One key differentiator of the Iguazio MLOps Platform is its flexibility in deployment options. Users can deploy AI applications anywhere, including any cloud, hybrid, or on-premises environments. This is particularly important for industries like healthcare and finance, where data privacy concerns may make on-premises deployment a requirement.
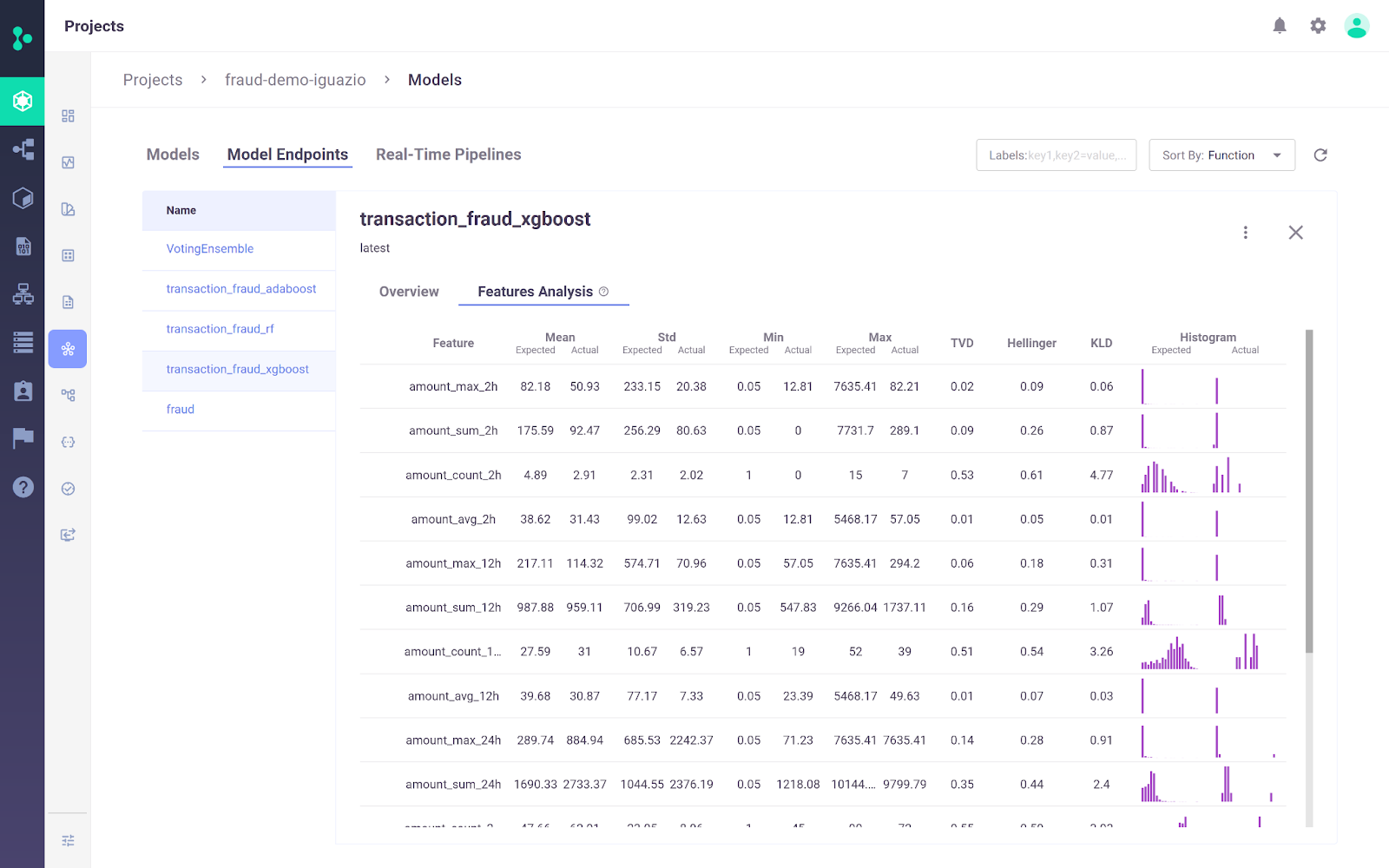
Image from Iguazio MLOps Platform
Key features:
Here's a comparison table so you can evaluate these tools side-by-side and decide on the best ones for your projects:
| Tool | Main functionality | Supported frameworks | Deployment options |
|---|---|---|---|
| Qdrant | Vector similarity search and database management | Python, multiple languages | Cloud-native, scalable horizontally |
| LangChain | Develop applications with language models | Python, JavaScript | REST API, templates |
| MLFlow | Experiment tracking, model registry, deployment | Python, R, Java, REST API | Local, cloud |
| Comet ML | Experiment tracking and optimization | Scikit-learn, PyTorch, TensorFlow, HuggingFace | Local, cloud |
| Weights & Biases | Experiment tracking, data and model versioning | Fastai, Keras, PyTorch, HuggingFace, Yolov5, Spacy | Local, cloud |
| Prefect | Workflow orchestration and monitoring | Python | Local (Orion UI), Cloud |
| Metaflow | Workflow management for data science | Scikit-learn, TensorFlow, Python, R | AWS, GCP, Azure, local |
| Kedro | Workflow orchestration, reproducibility | Python | Local, distributed |
| Pachyderm | Data transformation, versioning, and lineage | Any language | Kubernetes |
| DVC | Data and pipeline versioning | Git, Python | Local, cloud |
| LakeFS | Git-like version control for data lakes | Any storage service | Local, cloud |
| Feast | Centralized feature store for ML models | Python | Local, cloud |
| Featureform | Virtual feature store for ML models | Python | Local, cloud |
| Deepchecks | ML model testing and validation | Python | Local, cloud |
| TruEra | Model quality and performance testing | Python | Local, cloud |
| Kubeflow | ML model deployment and orchestration | TensorFlow, PyTorch, PaddlePaddle, MXNet, XGboost | Kubernetes, cloud |
| BentoML | Model deployment and API management | Keras, ONNX, LightGBM, PyTorch, Scikit-learn | Local, cloud |
| Hugging Face | Inference and model deployment | Any model | Cloud |
| Evidently | Monitoring ML models for data and target drift | Python | Local, cloud |
| Fiddler | ML model monitoring and debugging | Python | Local, cloud |
| Ray | Scale AI and Python applications | Python | Local, cloud |
| Nuclio | Serverless framework for data and compute-intensive workloads | Jupyter, Kubeflow | Cloud, on-premises |
| AWS SageMaker | End-to-end ML lifecycle management | Python, R, Java, TensorFlow, PyTorch | AWS cloud |
| DagsHub | Versioning and collaboration for ML projects | Git, DVC, MLflow | Local, cloud |
| Iguazio | End-to-end automation of ML pipelines | Python, MLRun | Cloud, hybrid, on-premises |
We’re at a time when there is a boom in the MLOps industry. Every week you see new developments, new startups, and new tools launching to solve the basic problem of converting notebooks into production-ready applications. Even existing tools are expanding the horizon and integrating new features to become super MLOps tools.
In this blog, we have learned about the best MLOps tools for various steps of the MLOps process. These tools will help you during the experimentation, development, deployment, and monitoring stages.
If you are new to machine learning and want to master the essential skills to land a job as a machine learning scientist, try taking our Machine Learning Scientist with Python career track.
If you are a professional and want to learn more about standard MLOps Practices, read our article on the MLOps Best Practices and How to Apply Them and check out our MLOps Fundamentals skill track.
Learn more about MLOps with these courses!
Course
Course
Course
blog
Abid Ali Awan
14 min
blog
Ani Madurkar
7 min
blog
Adel Nehme
12 min
blog
Adel Nehme
12 min
blog
Patrick Brus
11 min
blog
Hajar Khizou
14 min