
Corso
Concetti di MLOps
2 h
43.7K
Con l’arrivo di GPT-4 e poi di GPT-4o, è iniziata la corsa alla produzione di large language model e alla realizzazione del pieno potenziale dell’AI moderna. Gli LLM richiedono database vettoriali e framework di integrazione per costruire applicazioni AI intelligenti.
Qdrant è un motore open-source per la ricerca di similarità vettoriale e un database vettoriale che offre un servizio pronto per la produzione con un’API intuitiva, permettendoti di archiviare, cercare e gestire embedding vettoriali.
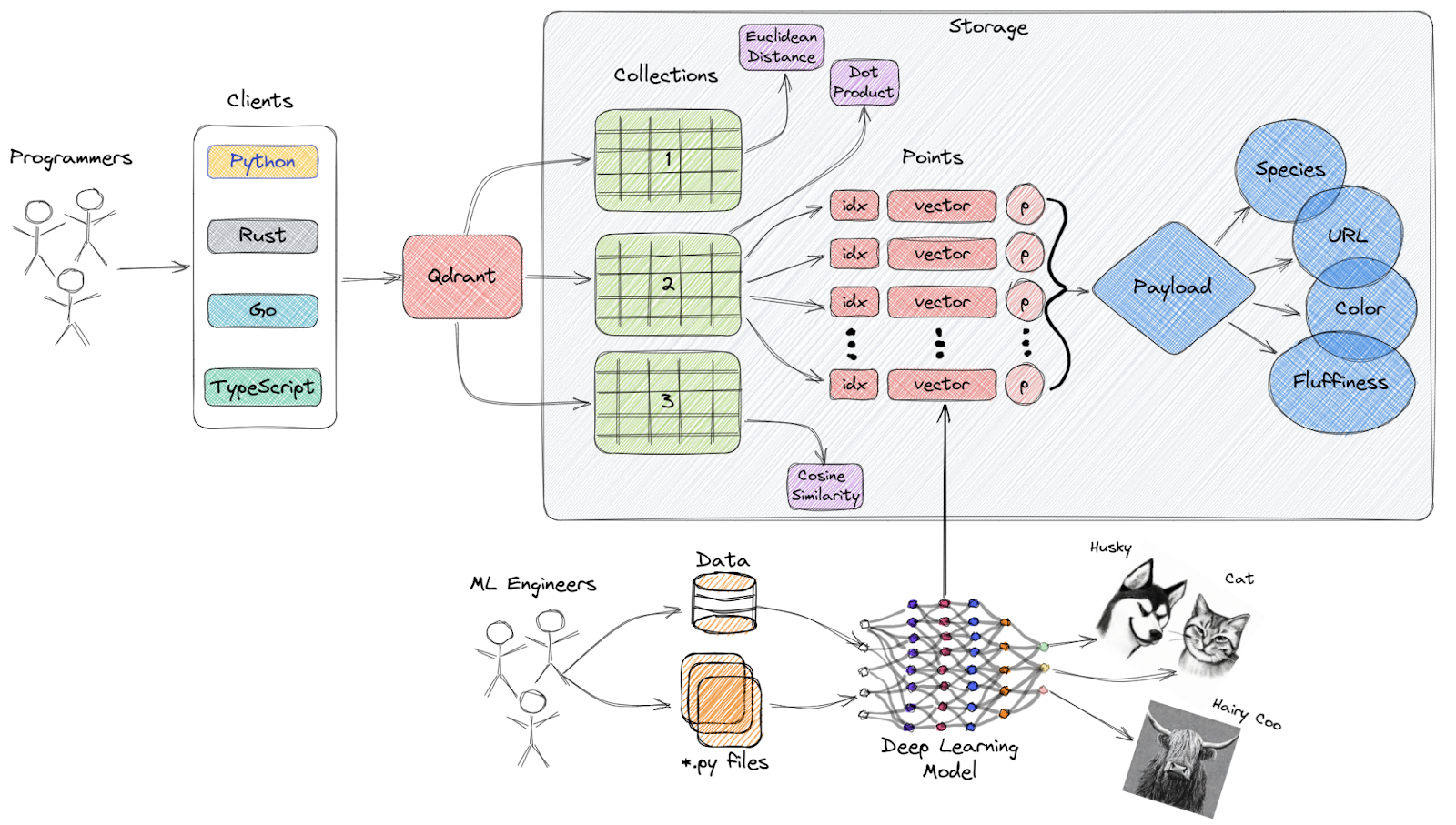
Panoramica ad alto livello dell’architettura di Qdrant
Caratteristiche principali:
Scopri i migliori database vettoriali leggendo I 5 migliori database vettoriali | Elenco con esempi.
LangChain è un framework potente e flessibile per sviluppare applicazioni basate su modelli linguistici. Offre diversi componenti che consentono agli sviluppatori di creare, distribuire e monitorare applicazioni sensibili al contesto e basate sul ragionamento.
Il framework è composto da 4 componenti principali:
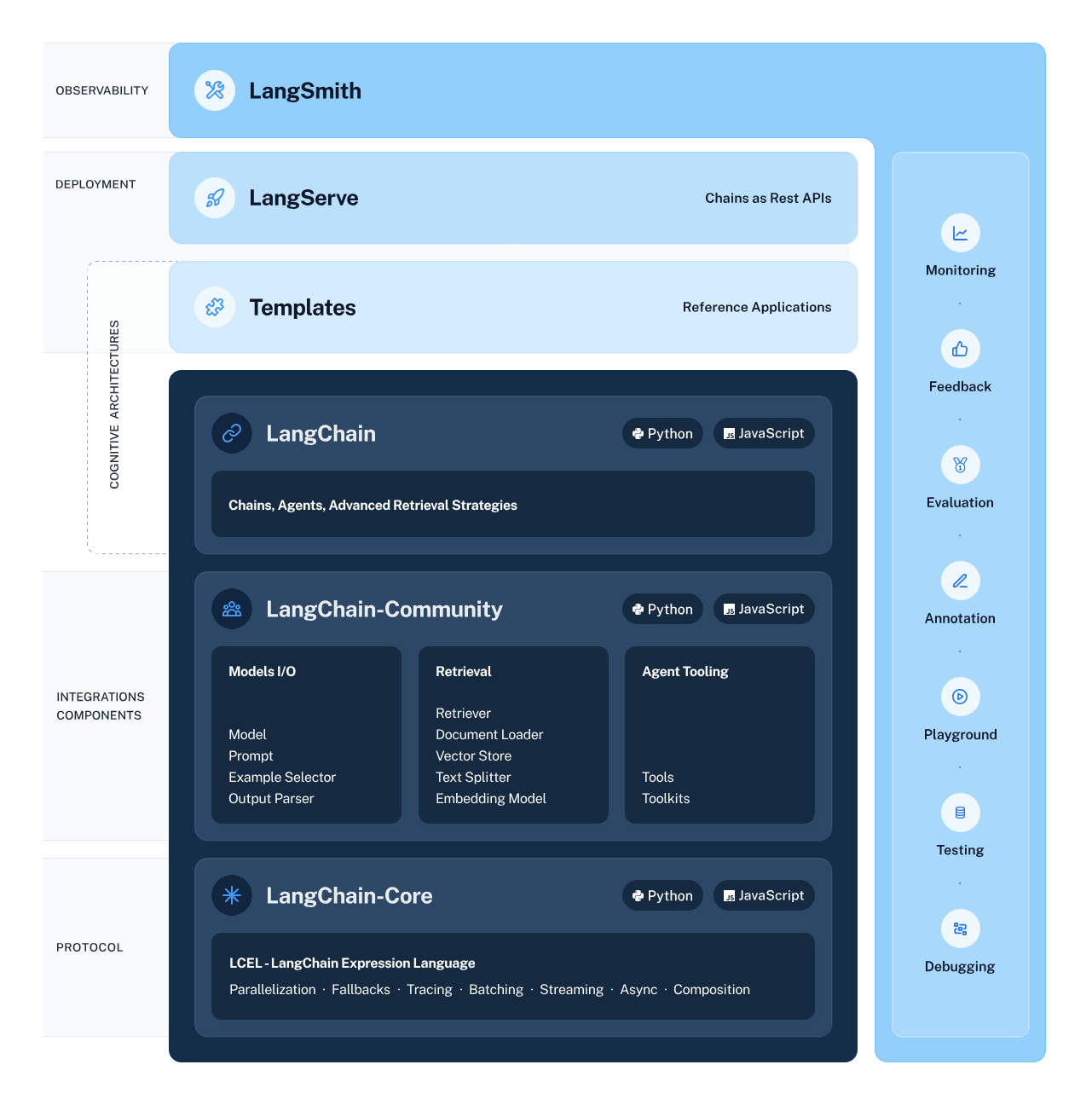
Ecosistema LangChain
Impara come creare applicazioni LLM con LangChain ed esplora il potenziale ancora inesplorato dei large language model.
Questi strumenti ti permettono di gestire i metadati dei modelli e aiutano nel tracciamento degli esperimenti:
MLflow è uno strumento open-source che ti aiuta a gestire le parti centrali del ciclo di vita del machine learning. È usato in genere per il tracciamento degli esperimenti, ma può essere utilizzato anche per riproducibilità, deployment e model registry. Puoi gestire esperimenti di machine learning e metadati dei modelli tramite CLI, Python, R, Java e REST API.
MLflow ha quattro funzioni principali:
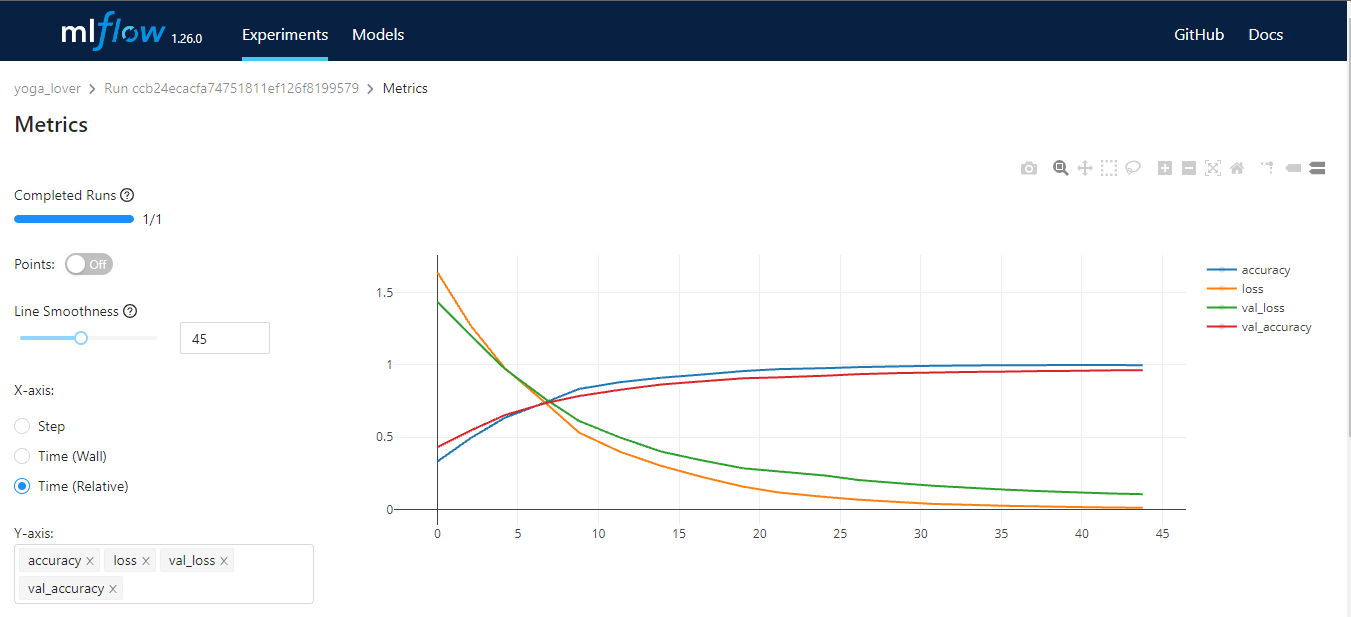
Immagine dell’autore
Comet ML è una piattaforma per tracciare, confrontare, spiegare e ottimizzare modelli ed esperimenti di machine learning. Puoi usarla con qualsiasi libreria di machine learning, come Scikit-learn, Pytorch, TensorFlow e HuggingFace.
Comet ML è pensata per individui, team, aziende e accademia. Consente a chiunque di visualizzare e confrontare facilmente gli esperimenti. Inoltre, permette di visualizzare campioni da immagini, audio, testo e dati tabellari.
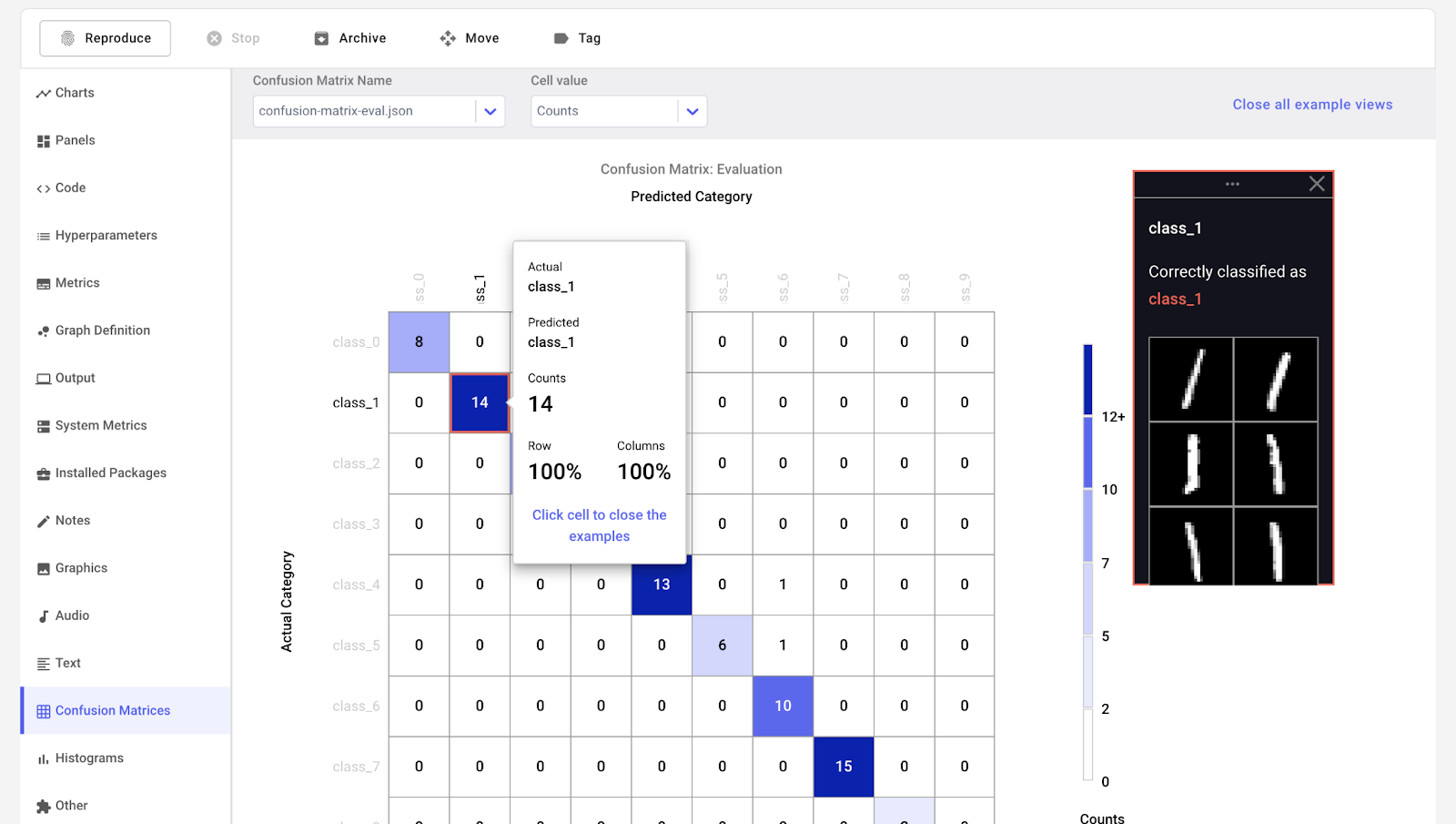
Immagine da Comet ML
Weights & Biases è una piattaforma ML per tracciamento degli esperimenti, versionamento di dati e modelli, ottimizzazione degli iperparametri e gestione dei modelli. Inoltre, puoi usarla per registrare artifact (dataset, modelli, dipendenze, pipeline e risultati) e visualizzare i dataset (audio, immagini, testo e tabellari).
Weights & Biases offre una dashboard centrale intuitiva per gli esperimenti di machine learning. Come Comet ML, si integra con altre librerie di machine learning, come Fastai, Keras, PyTorch, Hugging Face, Yolov5, Spacy e molte altre. Puoi consultare la nostra introduzione a Weights & BIases in un articolo dedicato.
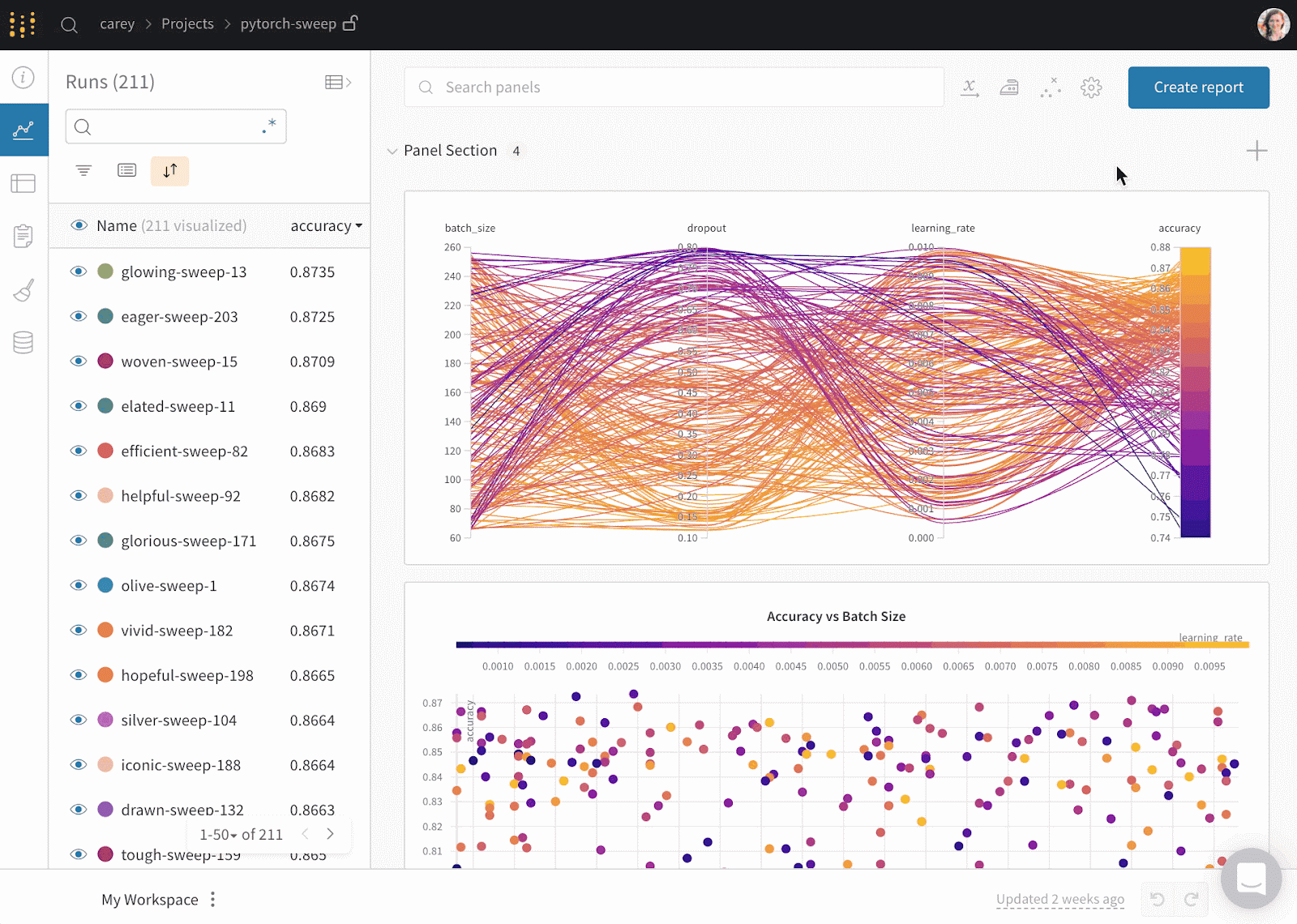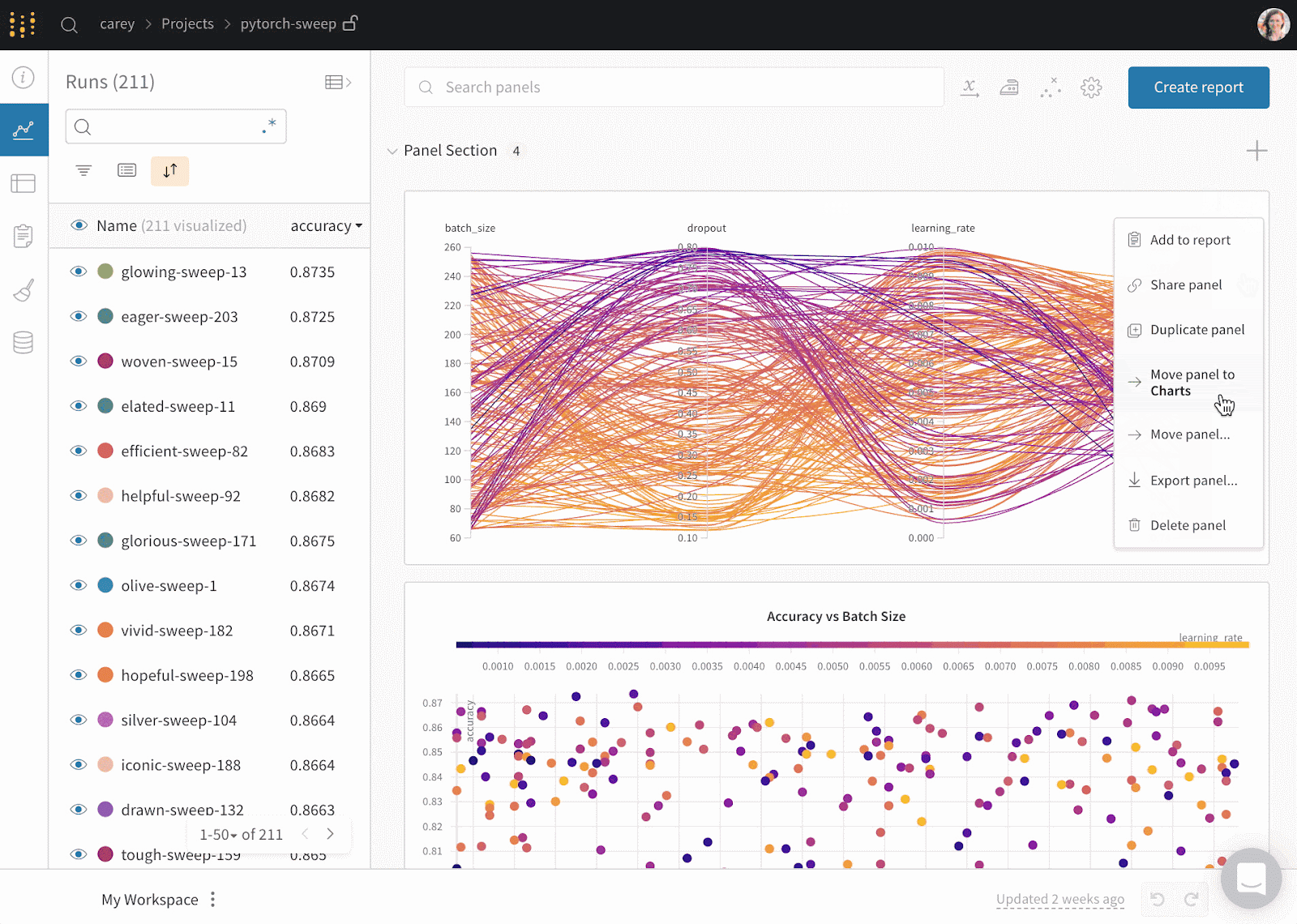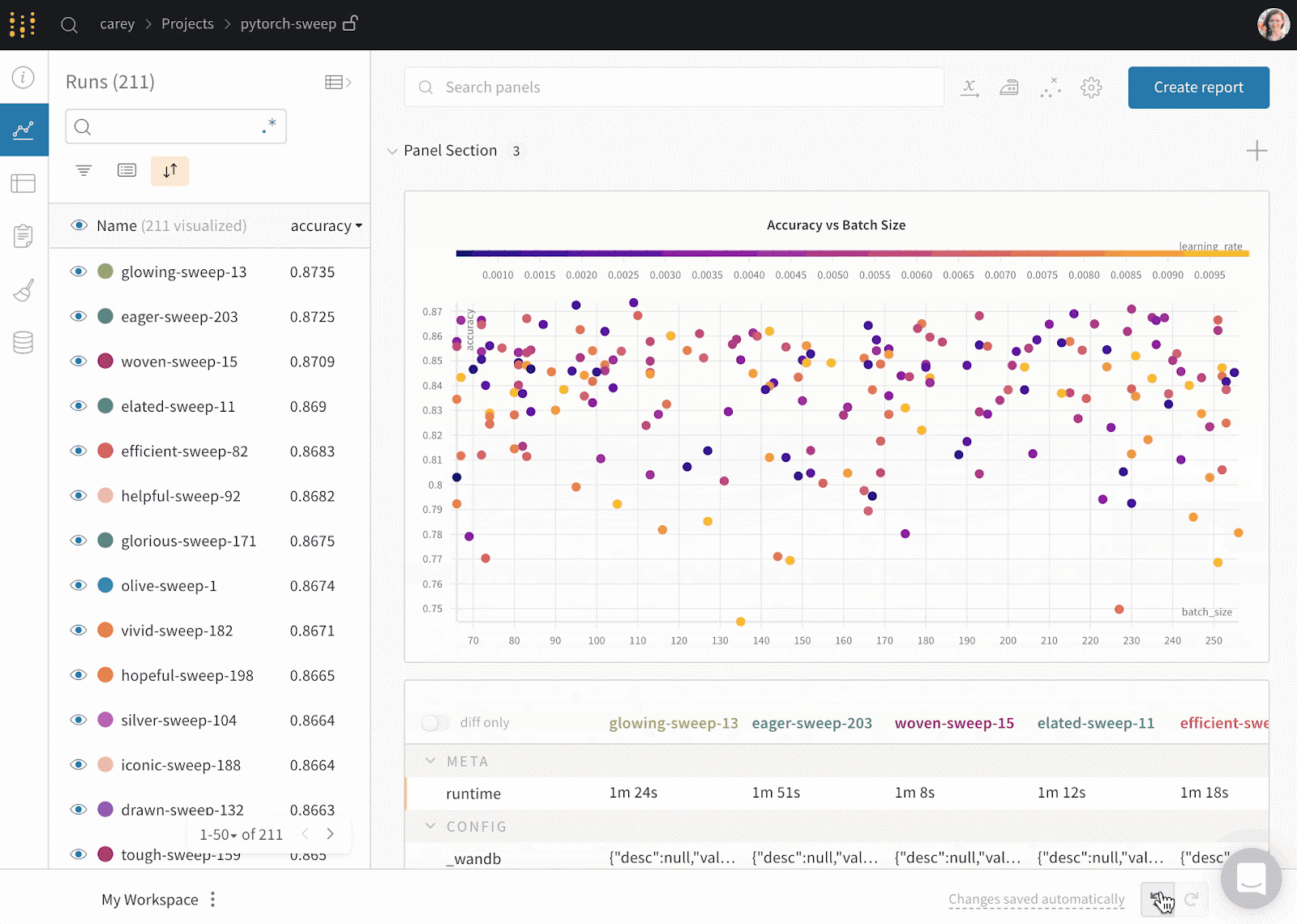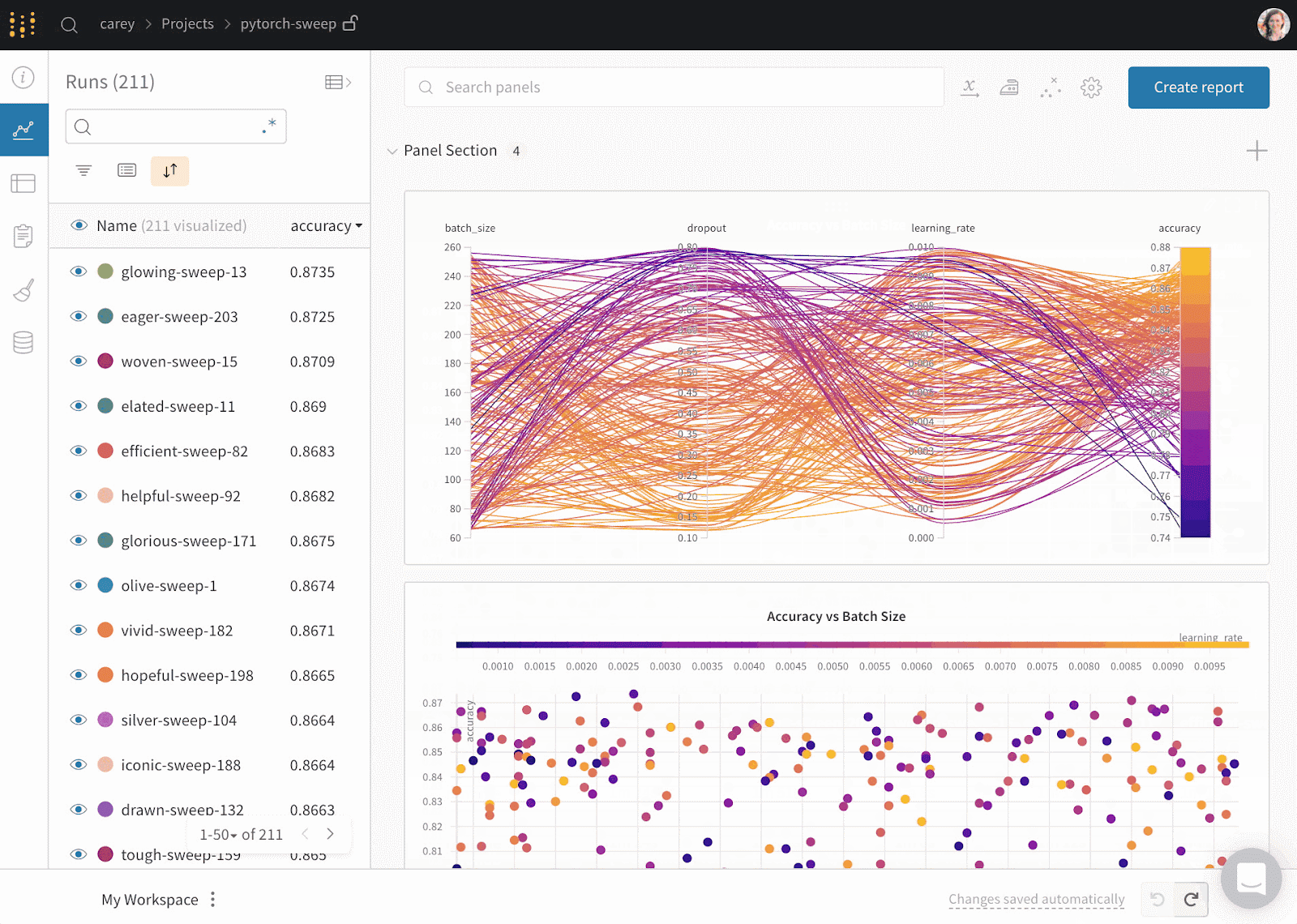
Gif da Weights & Biases
Nota: puoi usare anche TensorBoard, Pachyderm, DagsHub e DVC Studio per il tracciamento degli esperimenti e la gestione dei metadati ML.
Questi strumenti ti aiutano a creare progetti di data science e a gestire i workflow di machine learning:
Prefect è uno stack dati moderno per monitorare, coordinare e orchestrare workflow tra e all’interno delle applicazioni. È uno strumento open-source, leggero, pensato per pipeline di machine learning end-to-end.
Puoi usare Prefect Orion UI oppure Prefect Cloud per le basi dati.
Immagine da Prefect
Metaflow è un potente strumento, collaudato sul campo, per la gestione dei workflow in progetti di data science e machine learning. È stato creato per i data scientist, in modo che possano concentrarsi sulla costruzione dei modelli invece di preoccuparsi dell’ingegneria MLOps.
Con Metaflow puoi progettare il workflow, eseguirlo in scala e distribuire il modello in produzione. Traccia e versiona automaticamente esperimenti di machine learning e dati. Inoltre, puoi visualizzare i risultati nel notebook.
Metaflow funziona con più cloud (inclusi AWS, GCP e Azure) e varie librerie Python per il machine learning (come Scikit-learn e Tensorflow), e l’API è disponibile anche per il linguaggio R.
Immagine da Metaflow
Kedro è uno strumento di orchestrazione dei workflow basato su Python. Puoi usarlo per creare progetti di data science riproducibili, manutenibili e modulari. Integra concetti dell’ingegneria del software nel machine learning, come modularità, separazione delle responsabilità e versioning.
Con Kedro puoi:
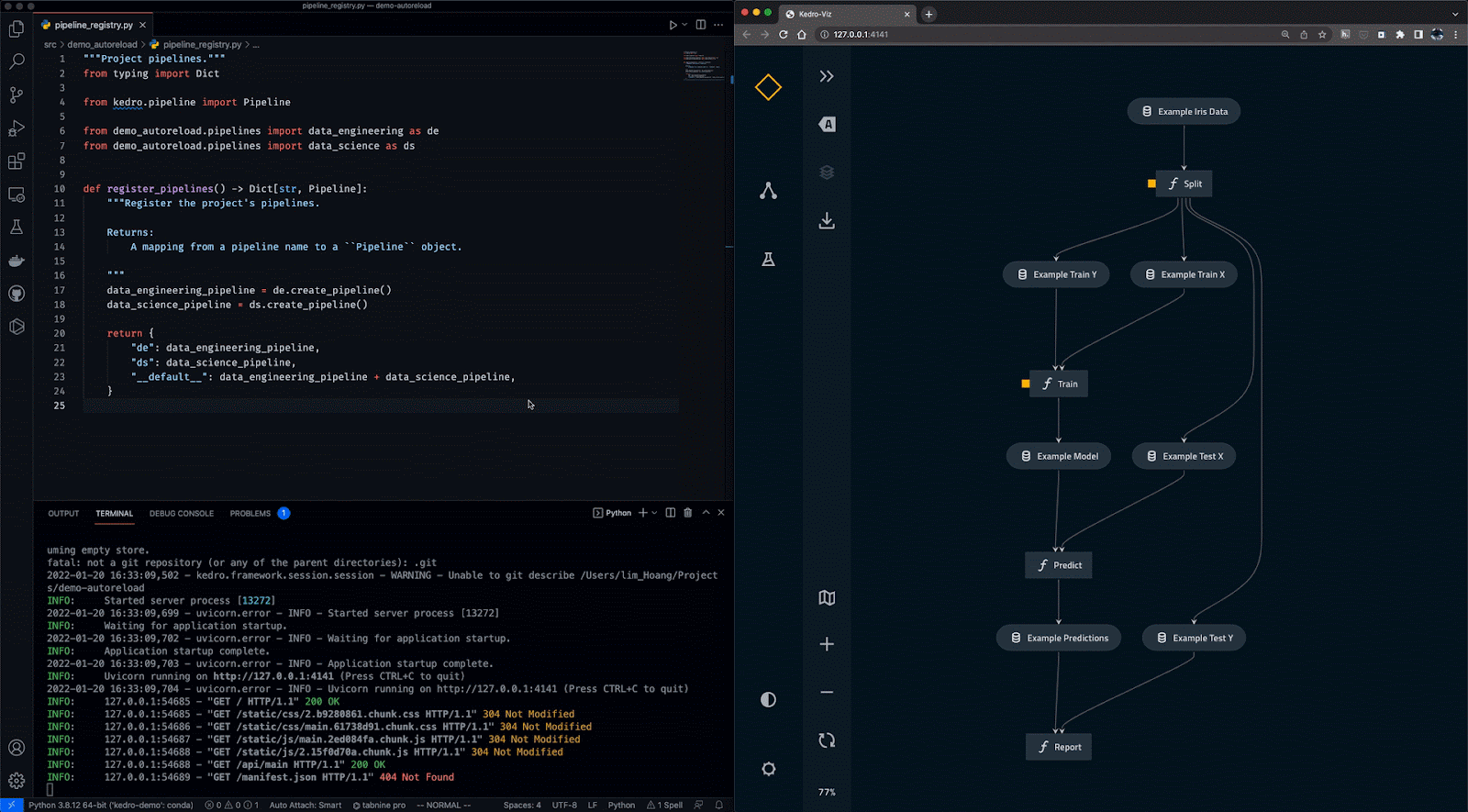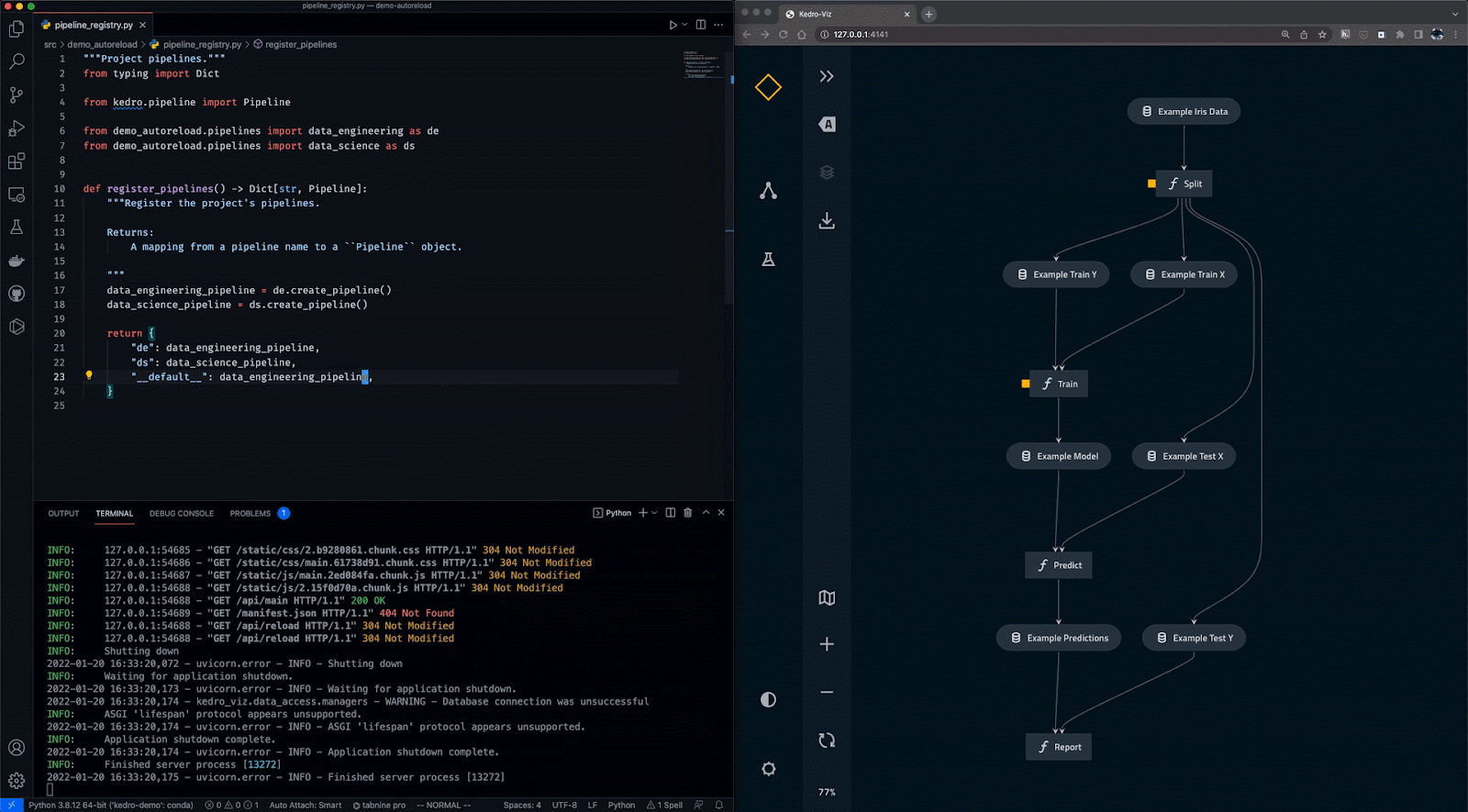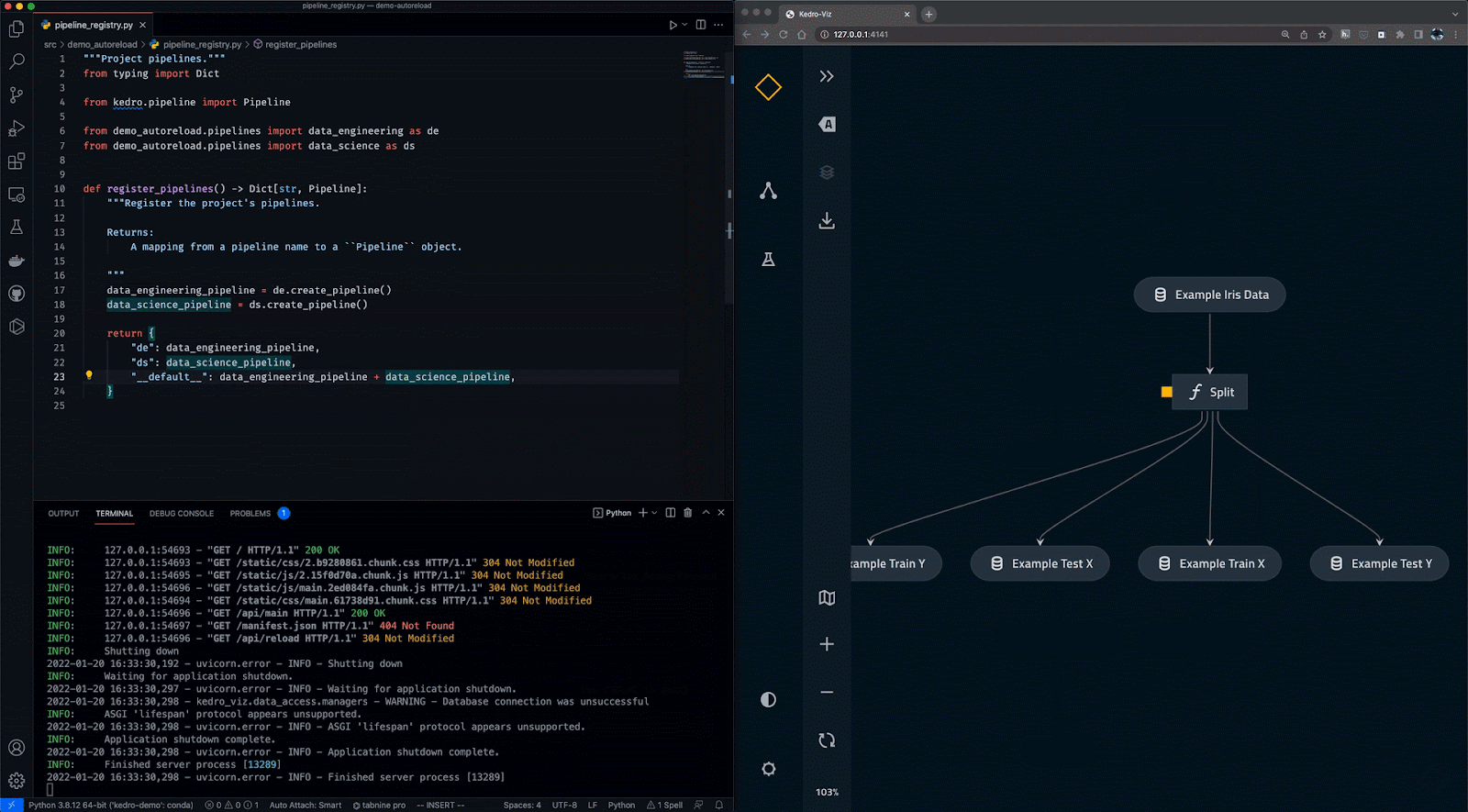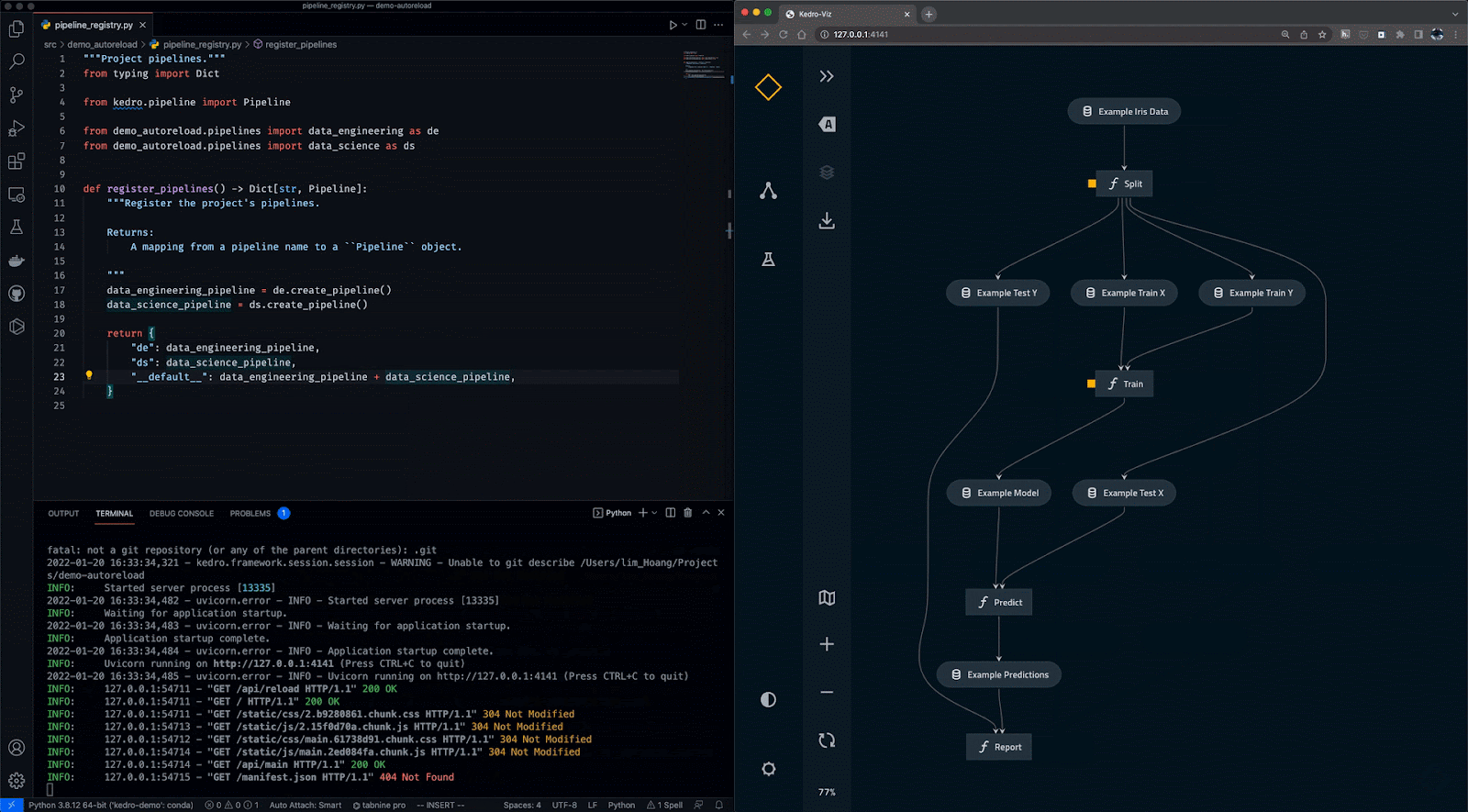
Gif da Kedro
Nota: puoi usare anche Kubeflow e DVC per orchestrazione e workflow pipeline.
Con questi strumenti MLOps puoi gestire le attività legate al versionamento di dati e pipeline:
Pachyderm automatizza la trasformazione dei dati con versionamento, lineage e pipeline end-to-end su Kubernetes. Puoi integrare qualsiasi dato (immagini, log, video, CSV), qualsiasi linguaggio (Python, R, SQL, C/C++) e a qualsiasi scala (petabyte di dati, migliaia di job).
La community edition è open-source e adatta a team piccoli. Organizzazioni e team che desiderano funzionalità avanzate possono optare per l’edizione Enterprise.
Proprio come Git, puoi versionare i tuoi dati usando una sintassi simile. In Pachyderm, l’oggetto di livello più alto è il Repository e puoi usare Commit, Branches, File, History e Provenance per tracciare e versionare il dataset.
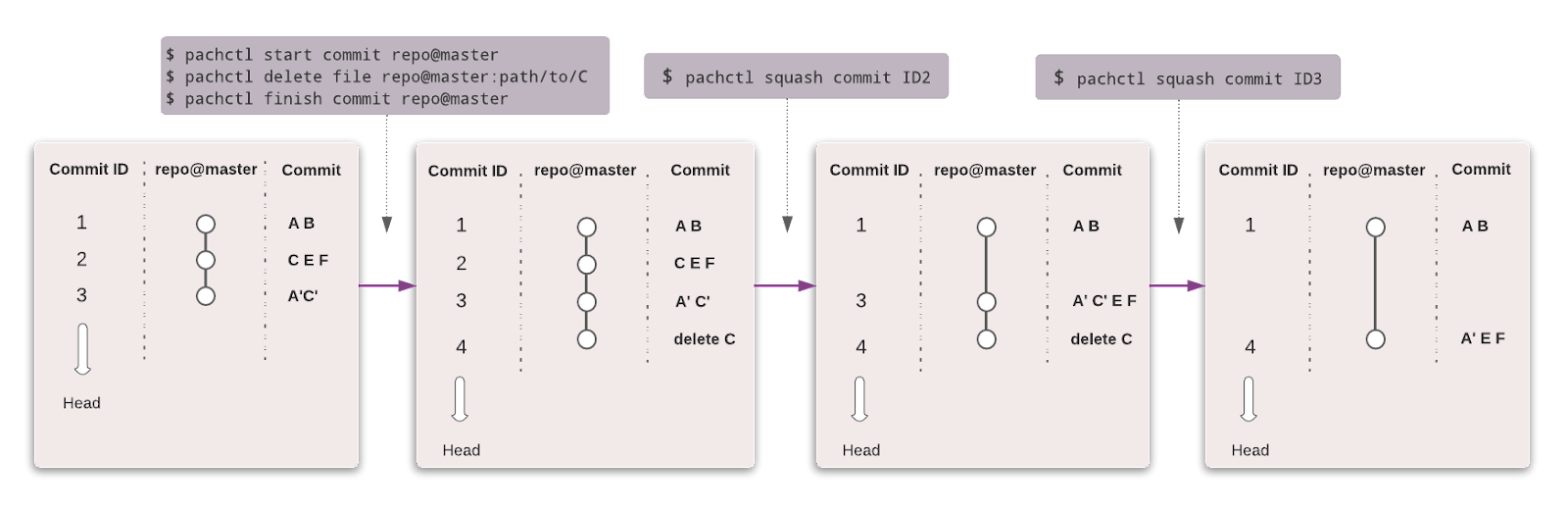
Immagine da Pachyderm
Data Version Control è uno strumento open-source e molto diffuso per progetti di machine learning. Funziona perfettamente con Git per offrirti versionamento di codice, dati, modelli, metadati e pipeline.
DVC è molto più di un semplice strumento di tracciamento e versionamento dei dati.
Puoi usarlo per:
Immagine da DVC
Nota: anche DagsHub può essere usato per il versionamento di dati e pipeline.
LakeFS è uno strumento open-source e scalabile di data version control che fornisce un’interfaccia di controllo versione in stile Git per gli object storage, consentendo di gestire i data lake come si fa con il codice. Con LakeFS è possibile eseguire il controllo versione dei dati a scala exabyte, risultando una soluzione altamente scalabile per la gestione di grandi data lake.
Capacità aggiuntive:
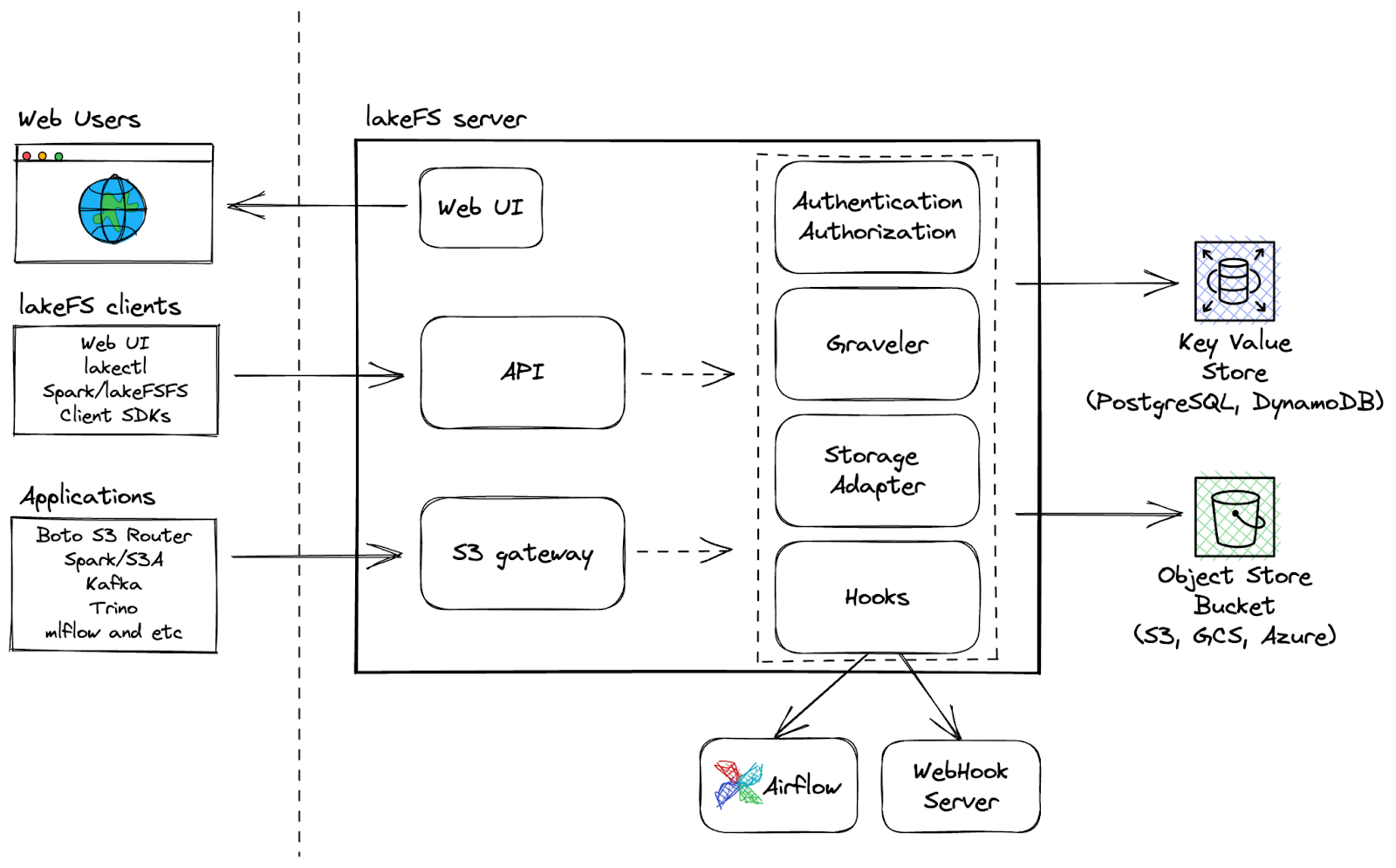
Architettura di LakeFS
I feature store sono repository centralizzati per archiviare, versionare, gestire e servire le feature (attributi di dati elaborati usati per addestrare i modelli di machine learning) sia per l’uso in produzione che per l’addestramento.
Feast è un feature store open-source che aiuta i team di machine learning a portare in produzione modelli real-time e a costruire una piattaforma di feature che favorisca la collaborazione tra ingegneri e data scientist.
Caratteristiche principali:
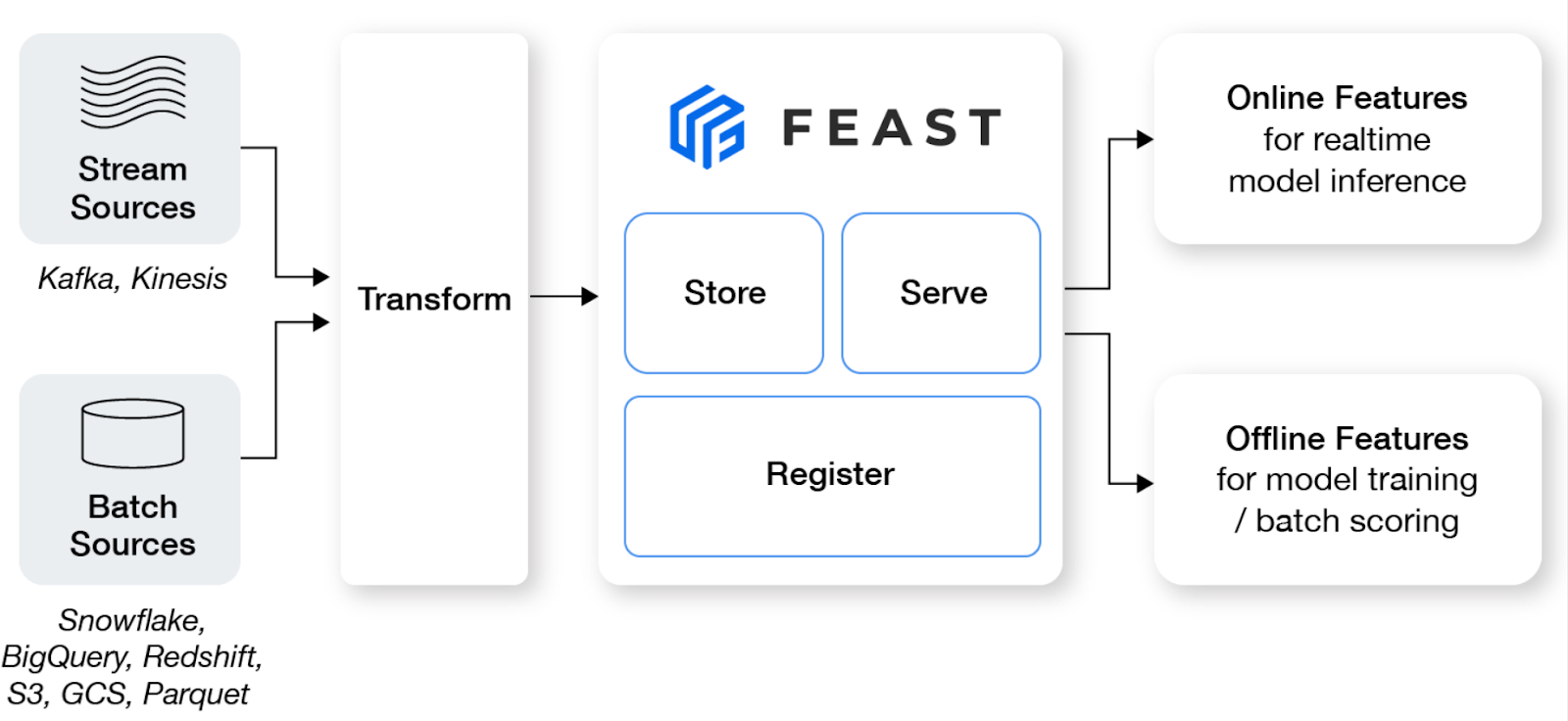
Immagine da Feast
Featureform è un feature store virtuale che consente ai data scientist di definire, gestire e servire le feature dei propri modelli ML. Può aiutare i team di data science a migliorare la collaborazione, organizzare la sperimentazione, facilitare il deployment, aumentare l’affidabilità e garantire la conformità.
Caratteristiche principali:
Immagine da Featureform
Con questi strumenti MLOps puoi testare la qualità dei modelli e garantirne affidabilità, robustezza e accuratezza:
Deepchecks è una soluzione open-source che copre tutte le esigenze di validazione ML, garantendo che dati e modelli siano testati a fondo dalla ricerca alla produzione. Offre un approccio olistico per validare dati e modelli attraverso i suoi vari componenti.
Immagine da Deepchecks
Deepchecks è composto da tre componenti:
TruEra è una piattaforma avanzata progettata per migliorare qualità e performance dei modelli tramite test automatizzati, spiegabilità e analisi delle cause radice. Offre varie funzionalità per ottimizzare e fare debug dei modelli, ottenere spiegabilità di livello superiore e integrarsi facilmente nel tuo stack ML.
Caratteristiche principali:
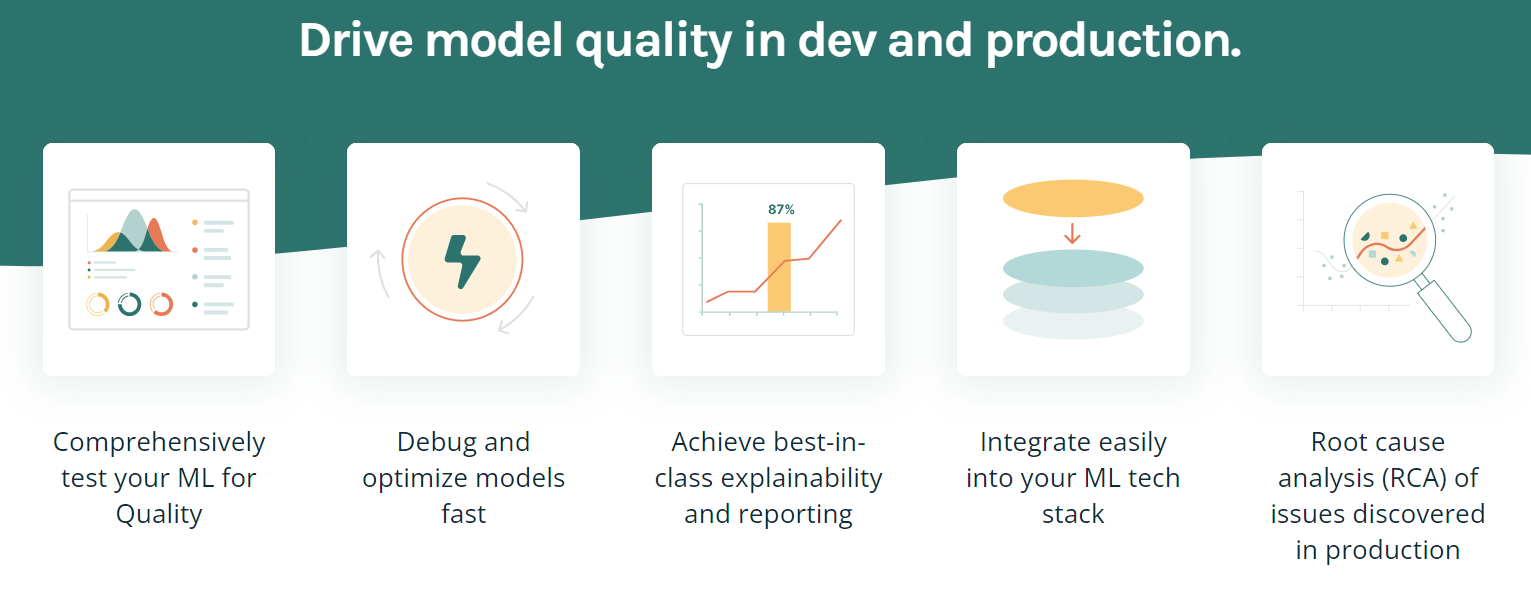
Immagine di TruEra
Quando si tratta di distribuire i modelli, questi strumenti MLOps possono essere di grande aiuto:
Kubeflow rende semplice, portabile e scalabile il deployment di modelli di machine learning su Kubernetes. Puoi usarlo per preparazione dei dati, training dei modelli, ottimizzazione, serving delle predizioni e monitoraggio delle performance del modello in produzione. Puoi distribuire workflow di machine learning in locale, on-premises o nel cloud. In breve, rende Kubernetes accessibile ai team di data science.
Caratteristiche principali:
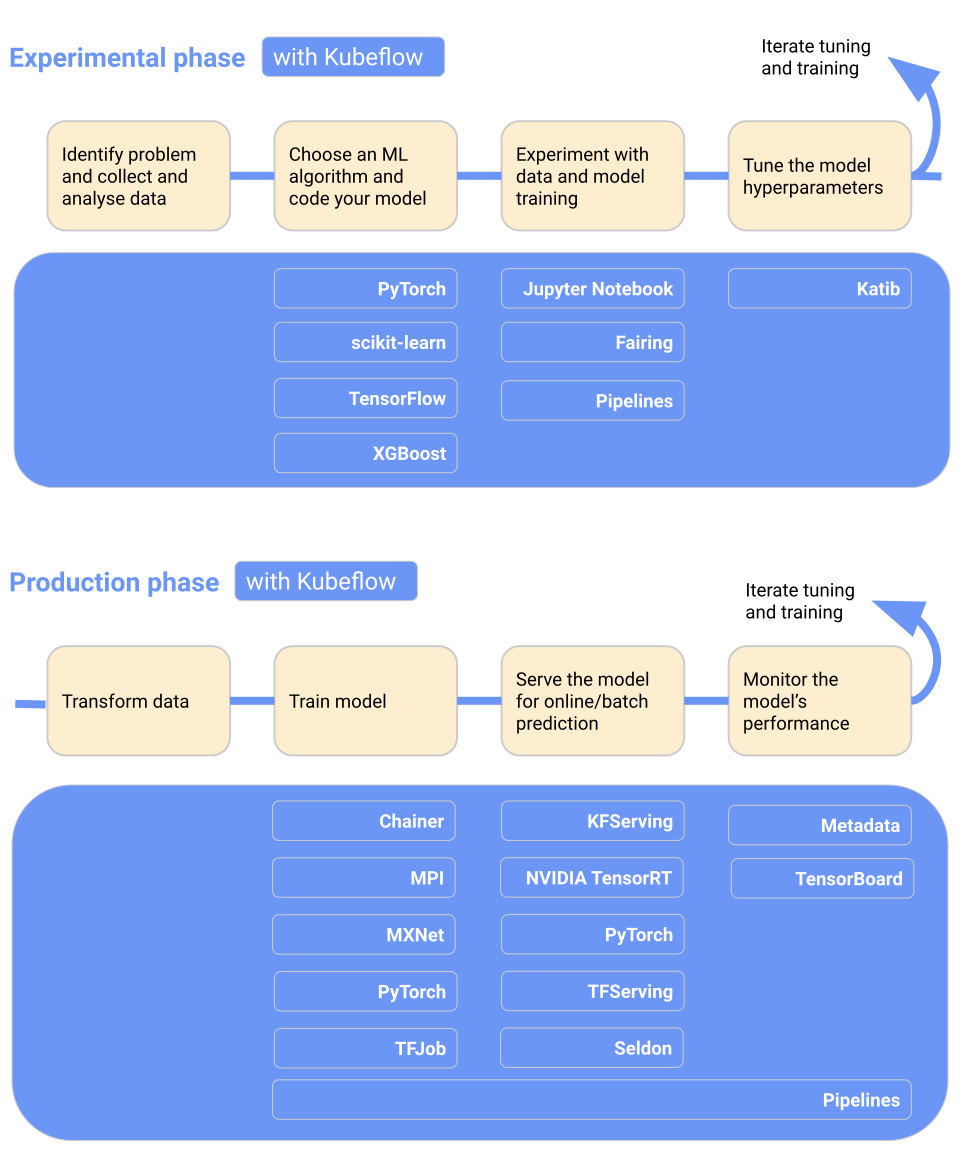
Immagine da Kubeflow
BentoML rende più semplice e veloce la messa in produzione di applicazioni di machine learning. È uno strumento orientato a Python per distribuire e mantenere API in produzione. Scala con potenti ottimizzazioni eseguendo inferenza in parallelo e batching adattivo e offre accelerazione hardware.
La dashboard centrale interattiva di BentoML semplifica l’organizzazione e il monitoraggio durante il deployment dei modelli di machine learning. La cosa migliore è che funziona con ogni tipo di framework di machine learning, come Keras, ONNX, LightGBM, Pytorch e Scikit-learn. In breve, BentoML fornisce una soluzione completa per deployment, serving e monitoraggio dei modelli.
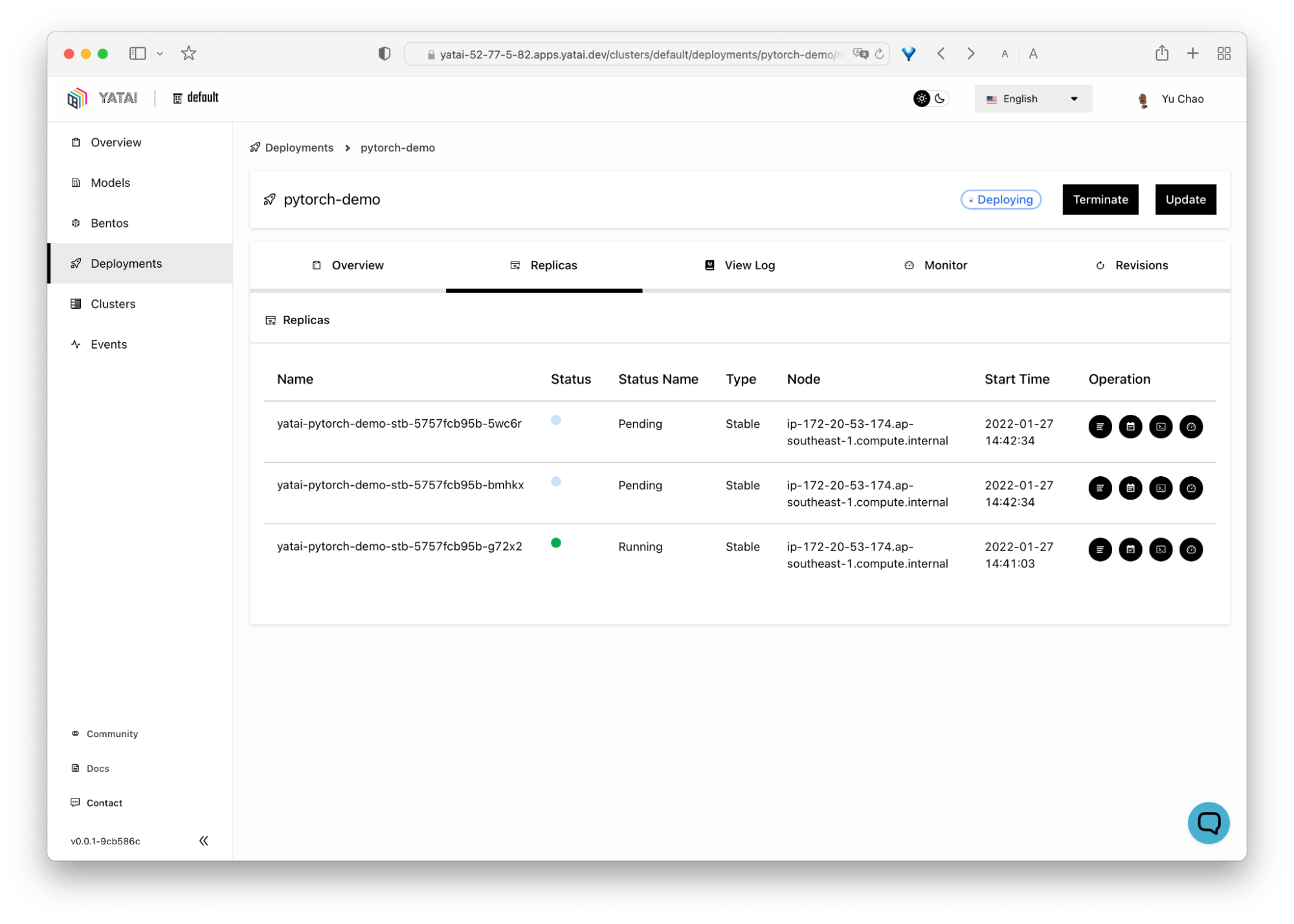
Immagine da BentoML
Hugging Face Inference Endpoints è un servizio cloud offerto da Hugging Face, una piattaforma ML all-in-one che consente di addestrare, ospitare e condividere modelli, dataset e demo. Questi endpoint sono pensati per aiutarti a distribuire i modelli di machine learning addestrati per l’inferenza senza dover configurare e gestire l’infrastruttura necessaria.
Caratteristiche principali:
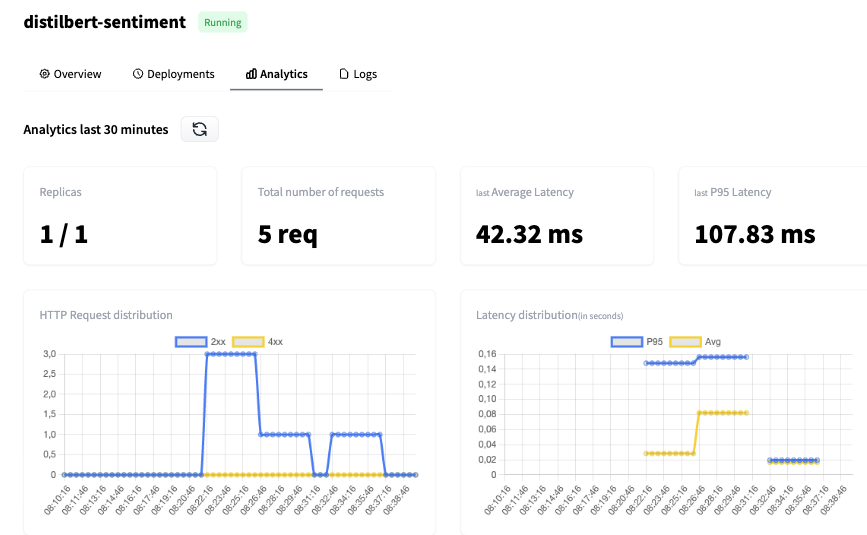
Immagine da Hugging Face
Nota: puoi usare anche MLflow e AWS sagemaker per deployment e serving dei modelli.
Che il tuo modello ML sia in sviluppo, in validazione o in produzione, questi strumenti possono aiutarti a monitorare una serie di fattori:
Evidently AI è una libreria Python open-source per monitorare i modelli ML durante lo sviluppo, la validazione e in produzione. Controlla qualità di dati e modelli, data drift, target drift e performance di regressione e classificazione.
Evidently ha tre componenti principali:
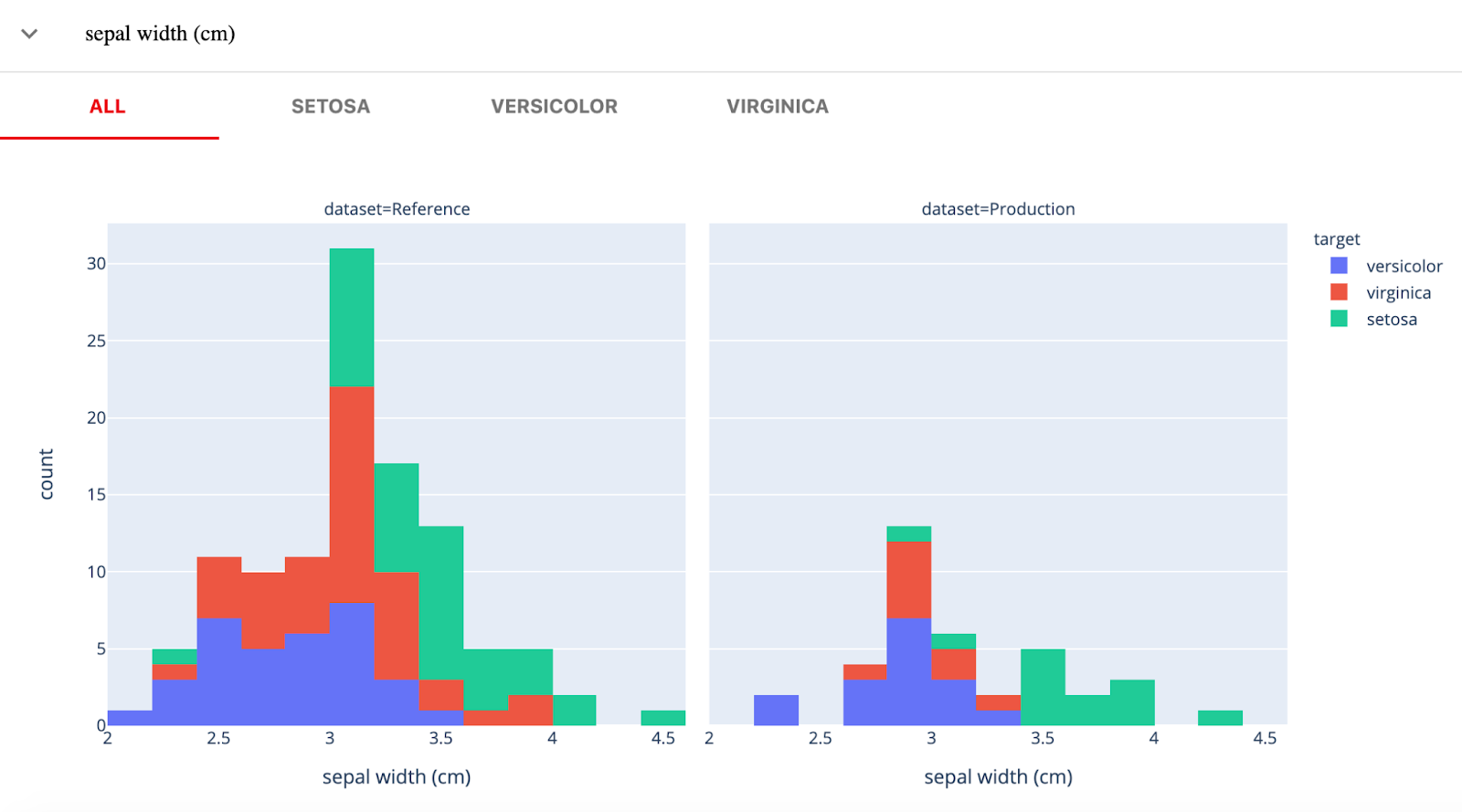
Immagine da Evidently
Fiddler AI è uno strumento di monitoraggio dei modelli ML con un’interfaccia semplice e chiara. Ti permette di spiegare e fare debug delle predizioni, analizzare il comportamento del modello sull’intero dataset, distribuire modelli di machine learning in scala e monitorarne le performance.
Vediamo le principali funzionalità di Fiddler AI per il monitoraggio ML:
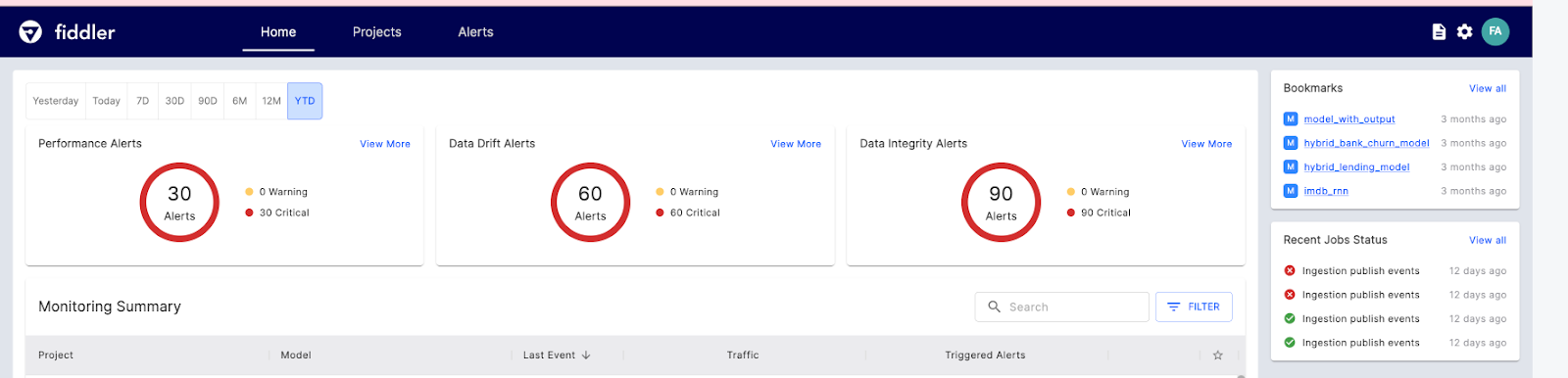
Immagine da Fiddler
Il motore di runtime è responsabile del caricamento del modello, della pre-elaborazione dei dati in input, dell’esecuzione dell’inferenza e della restituzione dei risultati all’applicazione client.
Ray è un framework versatile progettato per scalare applicazioni di AI e Python, semplificando per gli sviluppatori la gestione e l’ottimizzazione dei progetti di machine learning.
La piattaforma è composta da due componenti principali: un runtime distribuito core e un insieme di librerie AI pensate per semplificare il calcolo ML.
Ray Core offre un set limitato di elementi fondamentali che possono essere usati per costruire ed espandere applicazioni distribuite.
Ray fornisce anche librerie AI per dataset scalabili per l’ML, training distribuito, tuning di iperparametri, reinforcement learning e serving scalabile e programmabile.
L’esempio seguente mostra il training e il serving di un modello Gradient Boosting Classifier.
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")Nuclio è un framework potente focalizzato su carichi di lavoro intensivi in dati, I/O e computazione. È progettato per essere serverless, quindi non devi preoccuparti di gestire i server. Nuclio è ben integrato con strumenti di data science popolari, come Jupyter e Kubeflow. Supporta inoltre un’ampia varietà di fonti dati e di streaming e può essere eseguito su CPU e GPU.
Caratteristiche principali:
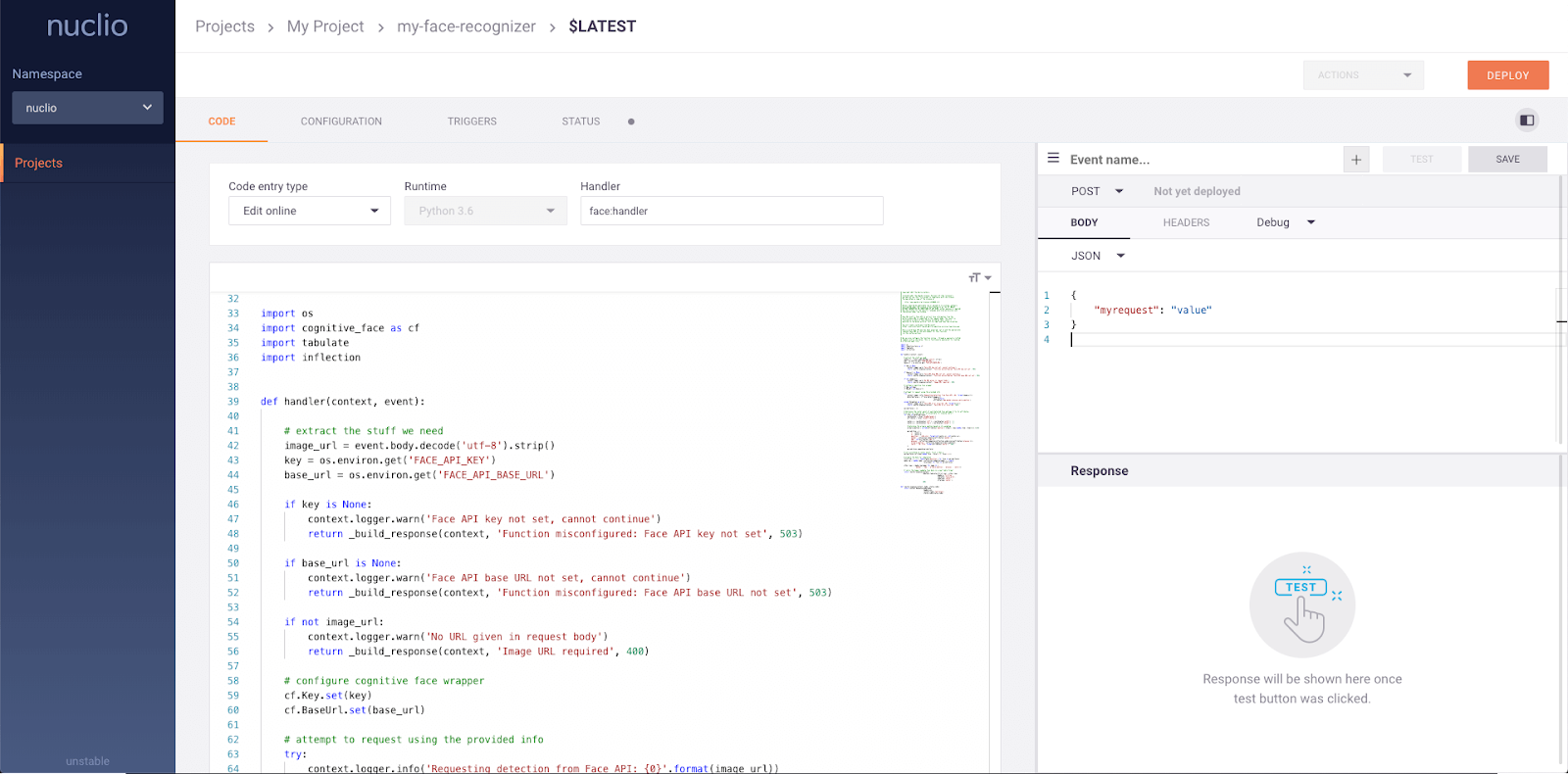
Immagine da Nuclio
Se cerchi uno strumento MLOps completo che ti supporti durante l’intero processo, ecco alcuni dei migliori:
Amazon Web Services SageMaker è una soluzione unica per MLOps. Puoi addestrare e accelerare lo sviluppo dei modelli, tracciare e versionare esperimenti, catalogare artifact ML, integrare pipeline ML CI/CD e distribuire, servire e monitorare i modelli in produzione senza interruzioni.
Caratteristiche principali:
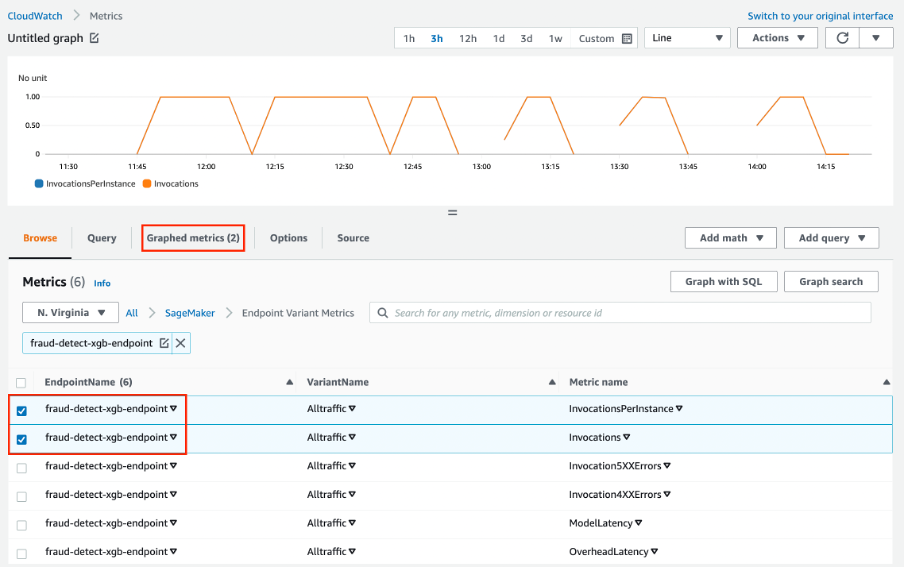
Immagine da Amazon SageMaker
DagsHub è una piattaforma pensata per la community del machine learning per tracciare e versionare dati, modelli, esperimenti, pipeline ML e codice. Permette al tuo team di creare, revisionare e condividere progetti di machine learning.
In poche parole, è un GitHub per il machine learning, e offre vari strumenti per ottimizzare il processo end-to-end di machine learning.
Caratteristiche principali:
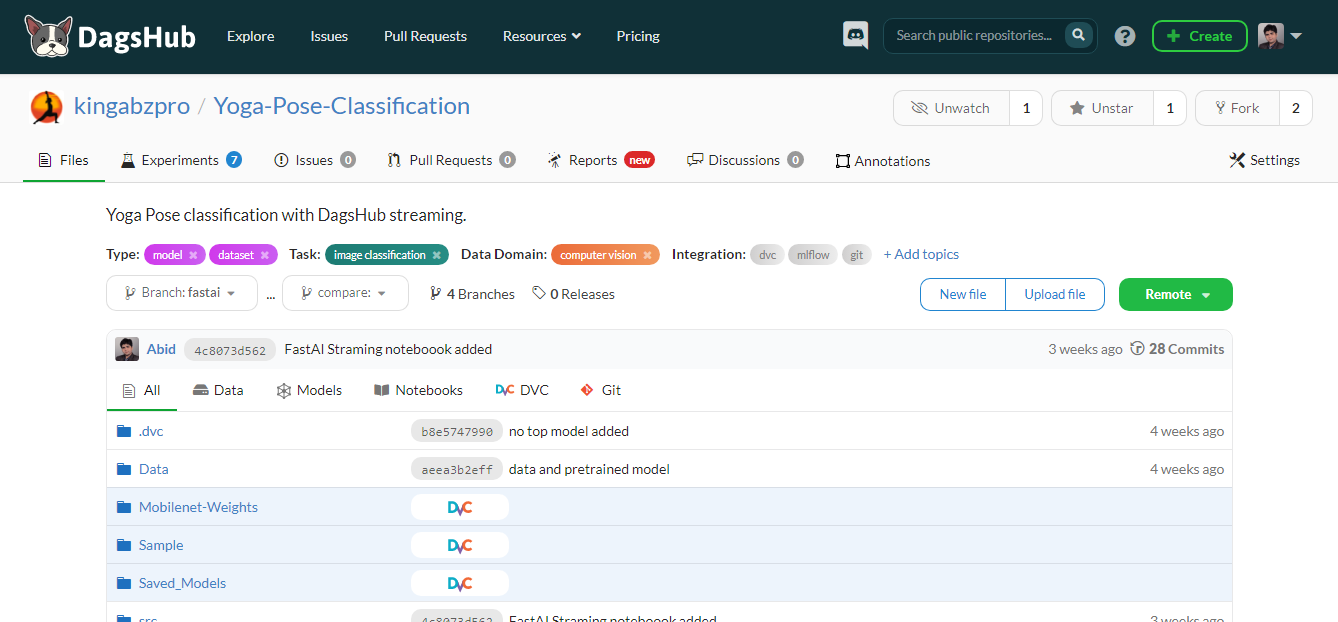
Immagine dell’autore
La Iguazio MLOps Platform è una piattaforma MLOps end-to-end che consente alle organizzazioni di automatizzare la pipeline di machine learning, dalla raccolta e preparazione dei dati al training, al deployment e al monitoraggio in produzione. Fornisce una piattaforma open (MLRun) e gestita.
Un elemento distintivo della Iguazio MLOps Platform è la flessibilità nelle opzioni di deployment. È possibile distribuire applicazioni AI ovunque, inclusi cloud, ambienti ibridi o on-premises. Questo è particolarmente importante per settori come sanità e finanza, dove le esigenze di privacy dei dati possono richiedere il deployment on-premises.
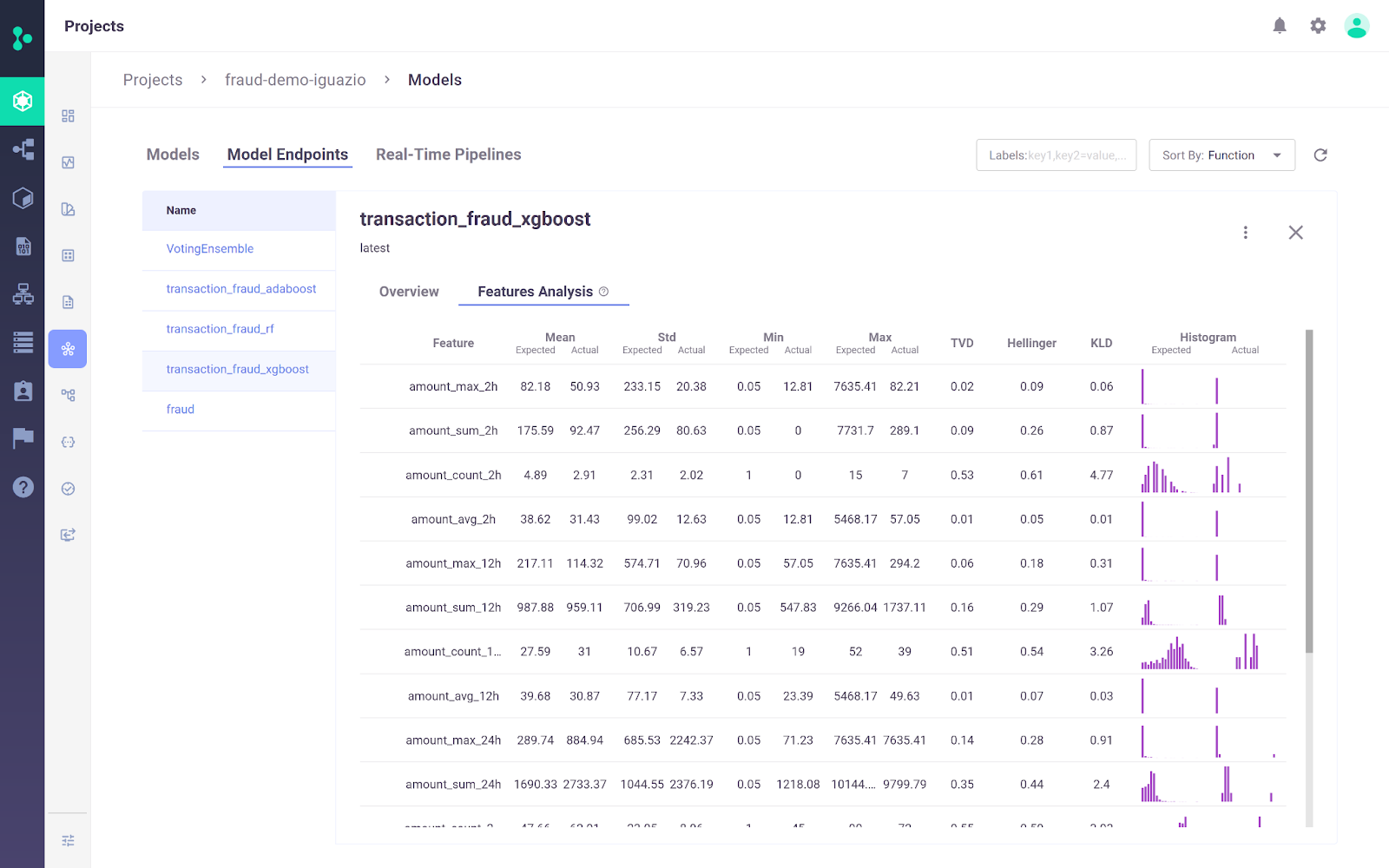
Immagine dalla piattaforma Iguazio MLOps
Caratteristiche principali:
Ecco una tabella comparativa per valutare questi strumenti fianco a fianco e scegliere i migliori per i tuoi progetti:
| Strumento | Funzionalità principale | Framework supportati | Opzioni di deployment |
|---|---|---|---|
| Qdrant | Ricerca di similarità vettoriale e gestione database | Python, più linguaggi | Cloud-native, scalabile orizzontalmente |
| LangChain | Sviluppare applicazioni con modelli linguistici | Python, JavaScript | REST API, template |
| MLFlow | Tracciamento esperimenti, model registry, deployment | Python, R, Java, REST API | Locale, cloud |
| Comet ML | Tracciamento e ottimizzazione degli esperimenti | Scikit-learn, PyTorch, TensorFlow, HuggingFace | Locale, cloud |
| Weights & Biases | Tracciamento esperimenti, versionamento di dati e modelli | Fastai, Keras, PyTorch, HuggingFace, Yolov5, Spacy | Locale, cloud |
| Prefect | Orchestrazione e monitoraggio dei workflow | Python | Locale (Orion UI), Cloud |
| Metaflow | Gestione workflow per data science | Scikit-learn, TensorFlow, Python, R | AWS, GCP, Azure, locale |
| Kedro | Orchestrazione workflow, riproducibilità | Python | Locale, distribuito |
| Pachyderm | Trasformazione, versionamento e lineage dei dati | Qualsiasi linguaggio | Kubernetes |
| DVC | Versionamento di dati e pipeline | Git, Python | Locale, cloud |
| LakeFS | Controllo versione in stile Git per data lake | Qualsiasi servizio di storage | Locale, cloud |
| Feast | Feature store centralizzato per modelli ML | Python | Locale, cloud |
| Featureform | Feature store virtuale per modelli ML | Python | Locale, cloud |
| Deepchecks | Test e validazione di modelli ML | Python | Locale, cloud |
| TruEra | Test di qualità e performance dei modelli | Python | Locale, cloud |
| Kubeflow | Deployment e orchestrazione di modelli ML | TensorFlow, PyTorch, PaddlePaddle, MXNet, XGboost | Kubernetes, cloud |
| BentoML | Deployment dei modelli e gestione API | Keras, ONNX, LightGBM, PyTorch, Scikit-learn | Locale, cloud |
| Hugging Face | Inference e deployment dei modelli | Qualsiasi modello | Cloud |
| Evidently | Monitoraggio modelli ML per data e target drift | Python | Locale, cloud |
| Fiddler | Monitoraggio e debugging dei modelli ML | Python | Locale, cloud |
| Ray | Scalare applicazioni di AI e Python | Python | Locale, cloud |
| Nuclio | Framework serverless per carichi intensivi di dati e compute | Jupyter, Kubeflow | Cloud, on-premises |
| AWS SageMaker | Gestione end-to-end del ciclo di vita ML | Python, R, Java, TensorFlow, PyTorch | Cloud AWS |
| DagsHub | Versionamento e collaborazione per progetti ML | Git, DVC, MLflow | Locale, cloud |
| Iguazio | Automazione end-to-end delle pipeline ML | Python, MLRun | Cloud, ibrido, on-premises |
Viviamo un momento di boom dell’industria MLOps. Ogni settimana emergono nuovi sviluppi, startup e strumenti che puntano a risolvere il problema di base: trasformare i notebook in applicazioni pronte per la produzione. Anche gli strumenti esistenti stanno ampliando gli orizzonti e integrando nuove funzionalità per diventare super strumenti MLOps.
In questo blog abbiamo visto i migliori strumenti MLOps per le varie fasi del processo MLOps. Questi strumenti ti aiuteranno nelle fasi di sperimentazione, sviluppo, deployment e monitoraggio.
Se sei nuovo al machine learning e vuoi padroneggiare le competenze essenziali per trovare lavoro come machine learning scientist, prova la nostra career track Machine Learning Scientist with Python.
Se sei un professionista e vuoi approfondire le pratiche standard di MLOps, leggi il nostro articolo sulle Best practice MLOps e come applicarle e consulta la nostra skill track MLOps Fundamentals.
Approfondisci MLOps con questi corsi!
Corso
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min

