
Cours
Concepts MLOps
2 h
42.6K
Apprenez à travailler avec des LLM en Python directement dans votre navigateur

Avec l'introduction de GPT-4 et, plus tard, de GPT-4o, la course a commencé pour produire de grands modèles linguistiques et réaliser le plein potentiel de l'IA moderne. Les LLM ont besoin de bases de données vectorielles et de cadres d'intégration pour créer des applications d'IA intelligentes.
Qdrant est un moteur de recherche de similarités vectorielles et une base de données vectorielles open-source qui fournit un service prêt à la production avec une API pratique, vous permettant de stocker, de rechercher et de gérer des embeddings vectoriels.
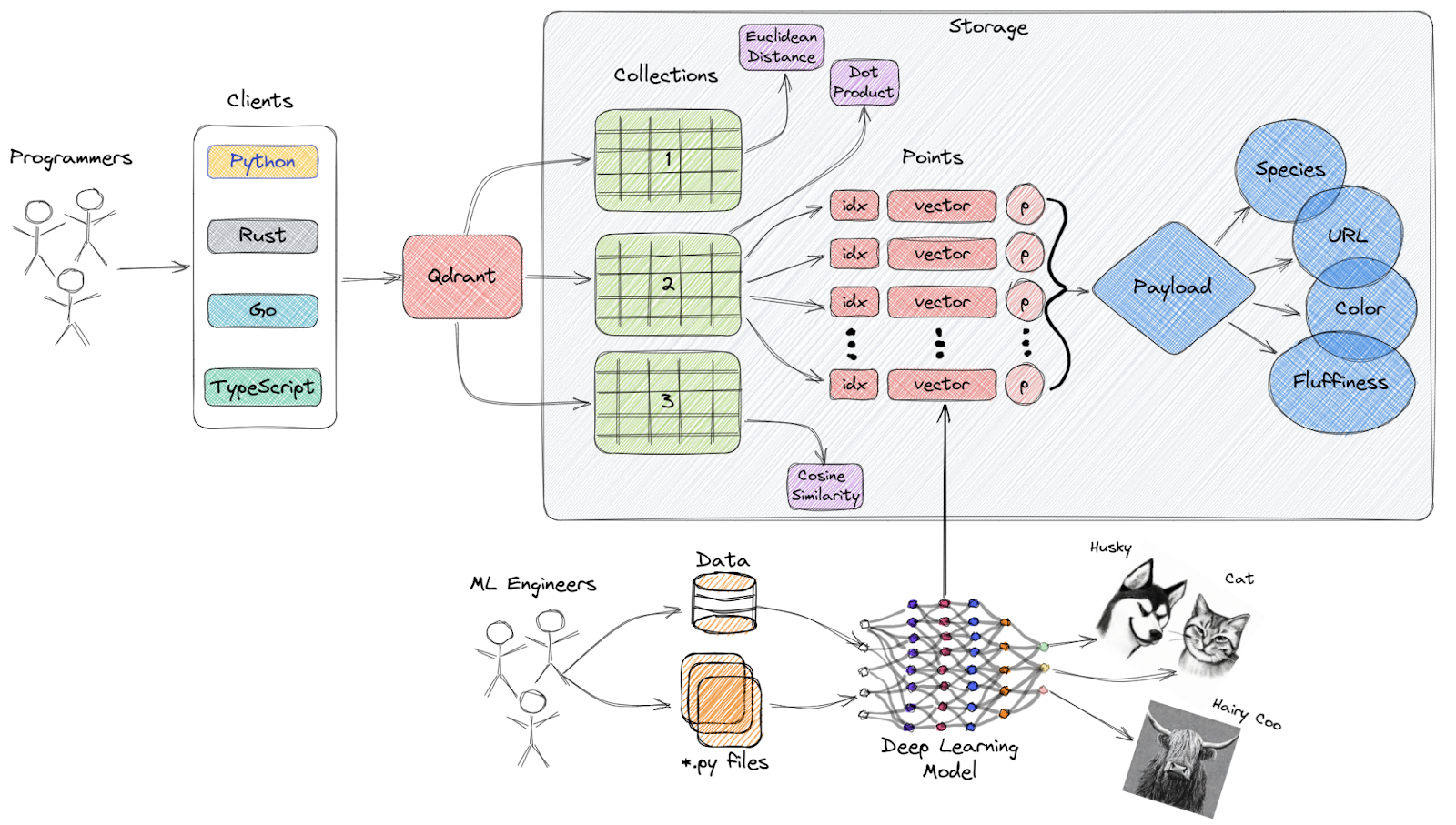
Vue d'ensemble de l'architecture de Qdrant
Caractéristiques principales :
Découvrez les meilleures bases de données vectorielles en lisant Les 5 meilleures bases de données vectorielles - Une liste avec des exemples.
LangChain est un cadre polyvalent et puissant pour le développement d'applications basées sur des modèles de langage. Il offre plusieurs composants permettant aux développeurs de créer, de déployer et de contrôler des applications contextuelles et basées sur le raisonnement.
Le cadre se compose de quatre éléments principaux :
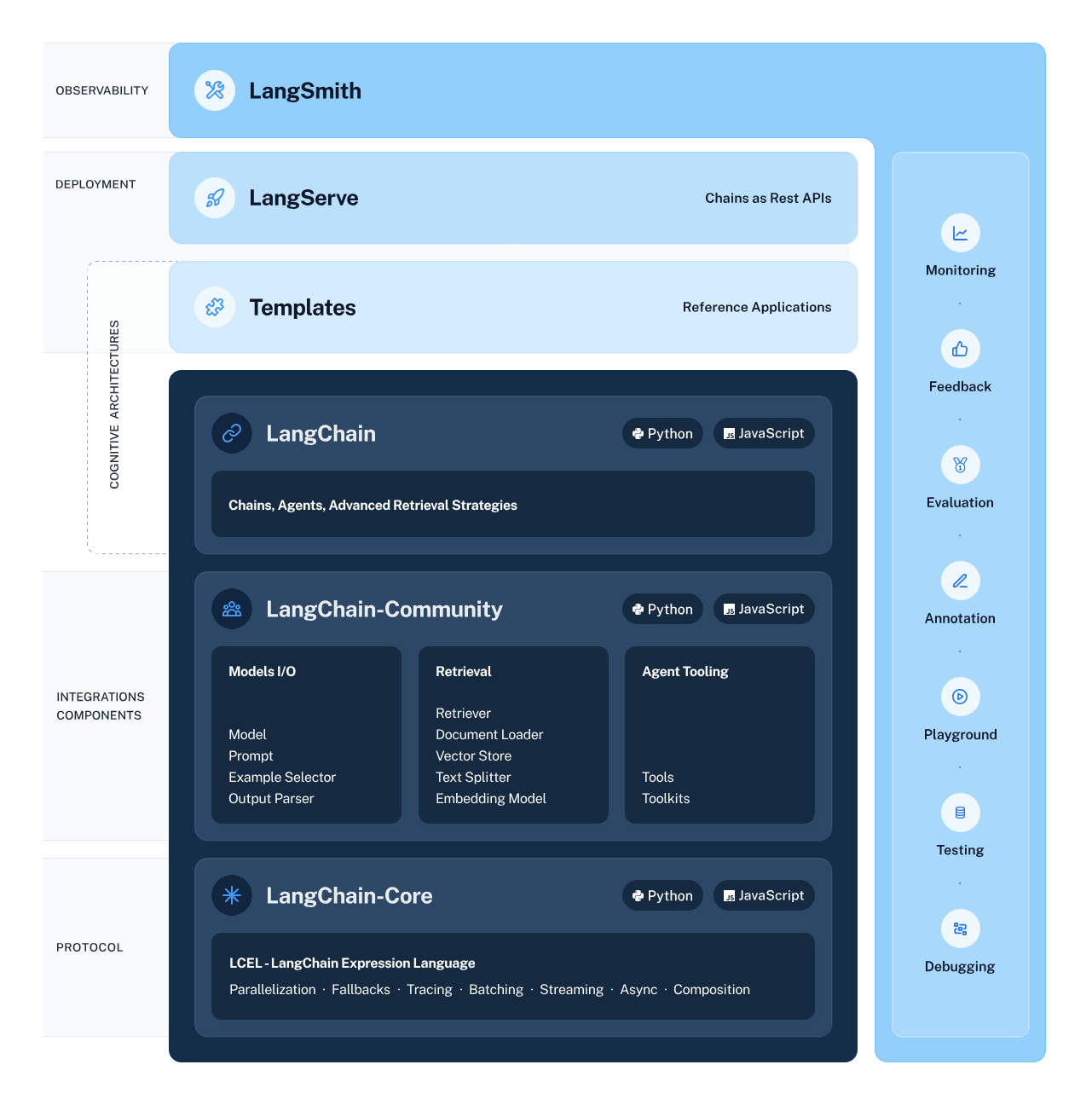
Écosystème LangChain
Apprenez à créer des applications LLM avec LangChain et exploitez le potentiel inexploité des grands modèles de langage.
Ces outils vous permettent de gérer les métadonnées des modèles et facilitent le cursus des expériences :
MLflow est un outil open-source qui vous aide à gérer les principales parties du cycle de vie de l'apprentissage automatique. Il est généralement utilisé pour le cursus des expériences, mais vous pouvez également l'utiliser pour la reproductibilité, le déploiement et le registre des modèles. Vous pouvez gérer les expériences d'apprentissage automatique et les métadonnées des modèles à l'aide de la CLI, de Python, de R, de Java et de l'API REST.
MLflow a quatre fonctions principales :
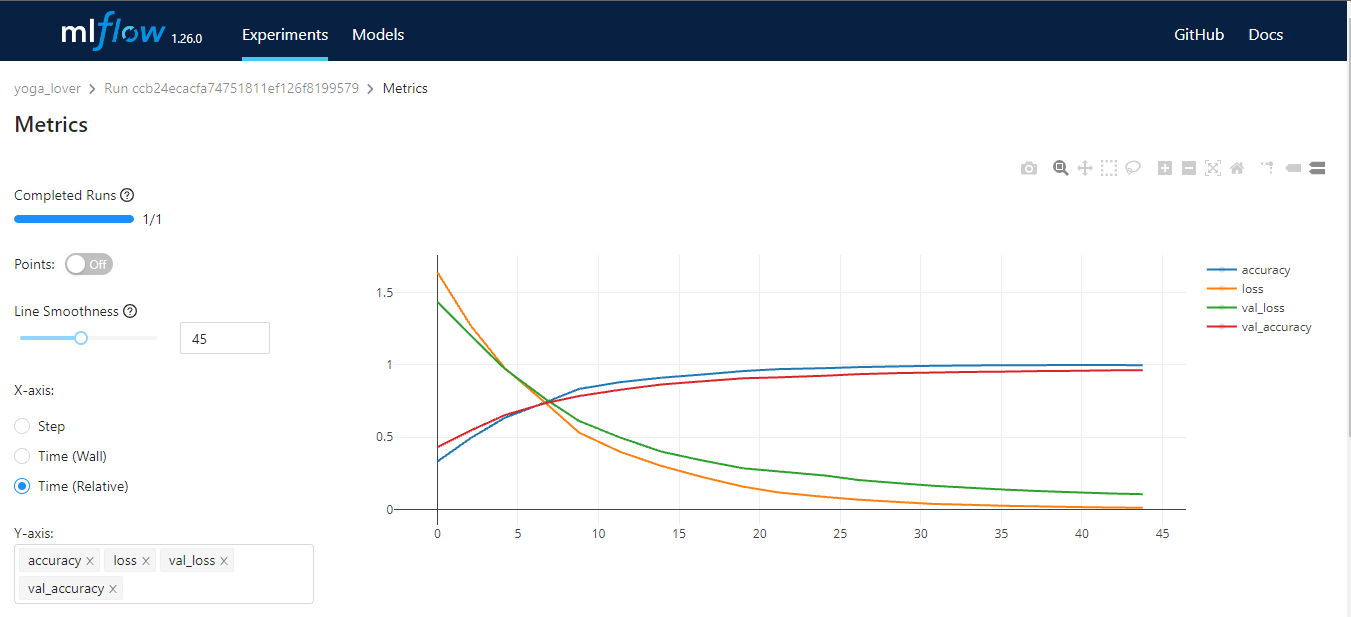
Image par l'auteur
Comet ML est une plateforme de cursus, de comparaison, d'explication et d'optimisation des modèles et expériences d'apprentissage automatique. Vous pouvez l'utiliser avec n'importe quelle bibliothèque d'apprentissage automatique, comme Scikit-learn, Pytorch, TensorFlow et HuggingFace.
Comet ML s'adresse aux individus, aux équipes, aux entreprises et aux universités. Il permet à chacun de visualiser et de comparer facilement les expériences. En outre, il vous permet de visualiser des échantillons d'images, d'audio, de texte et de données tabulaires.
Image de Comet ML
Weights & Biases est une plateforme ML pour le cursus des expériences, le versionnage des données et des modèles, l'optimisation des hyperparamètres et la gestion des modèles. En outre, vous pouvez l'utiliser pour enregistrer des artefacts (ensembles de données, modèles, dépendances, pipelines et résultats) et visualiser les ensembles de données (audio, visuel, texte et tableau).
Weights & Biases dispose d'un tableau de bord central convivial pour les expériences d'apprentissage automatique. Comme Comet ML, vous pouvez l'intégrer à d'autres bibliothèques d'apprentissage automatique, telles que Fastai, Keras, PyTorch, Hugging face, Yolov5, Spacy, et bien d'autres encore. Vous pouvez consulter notre introduction aux poids et aux bases dans un autre article.
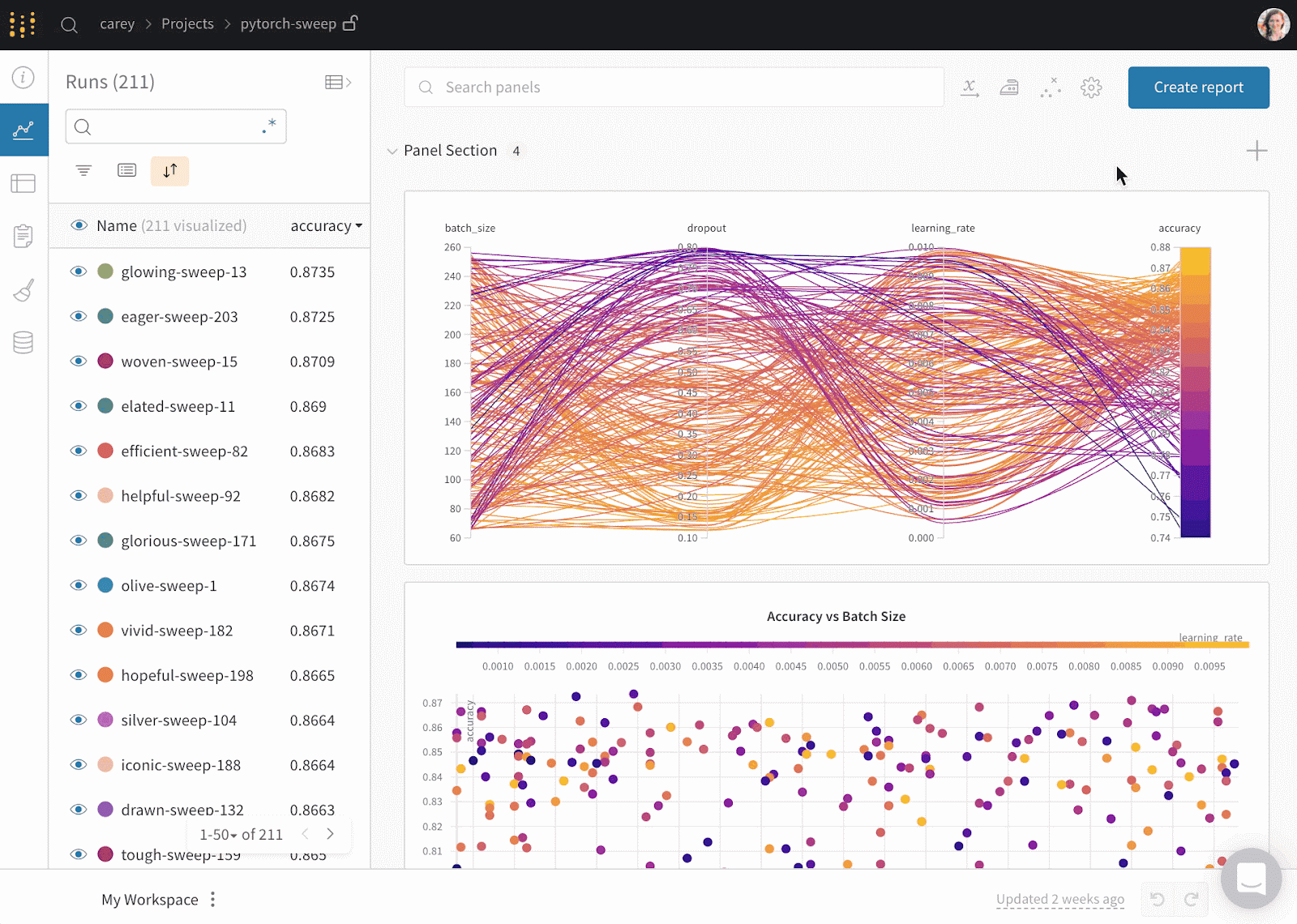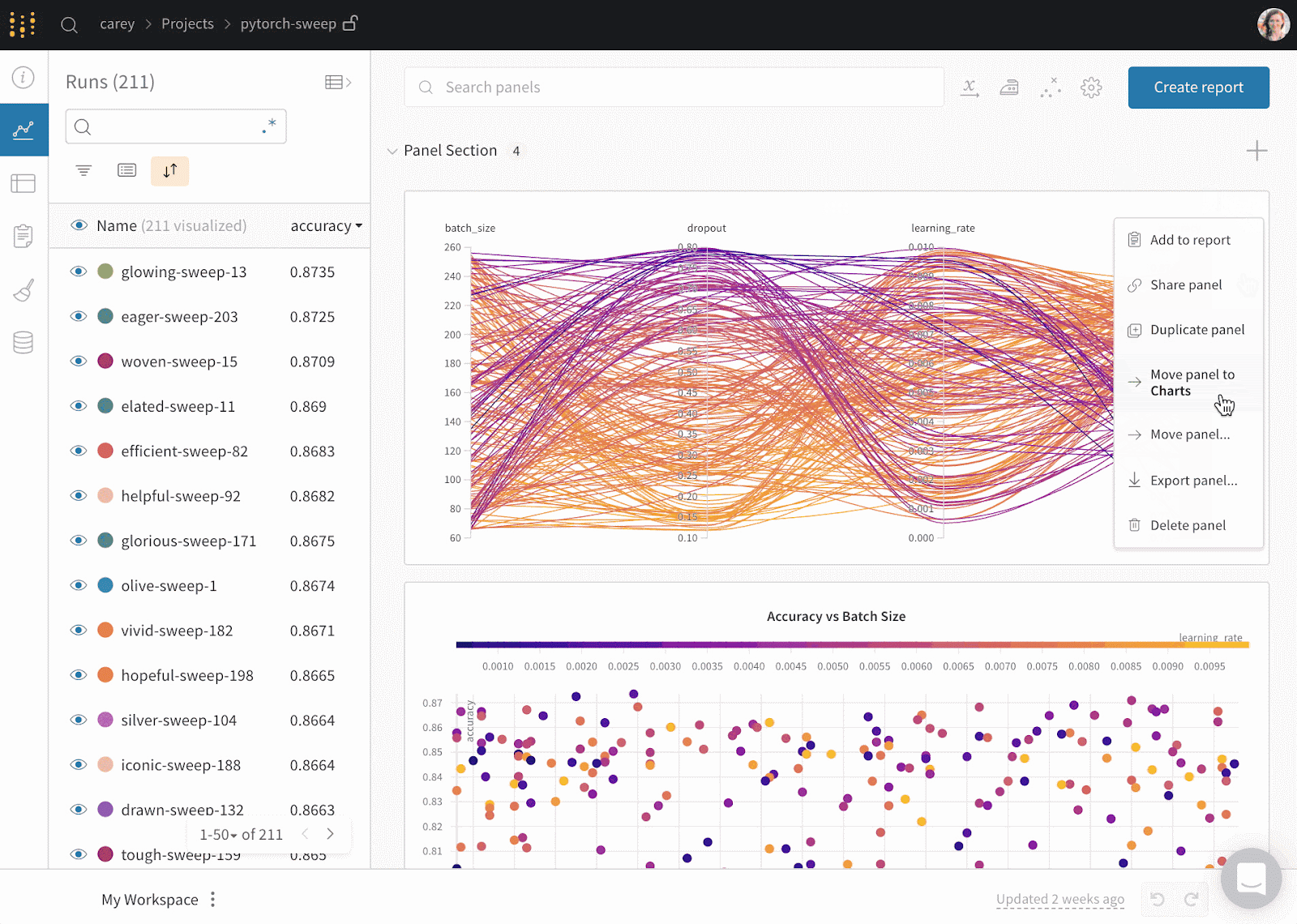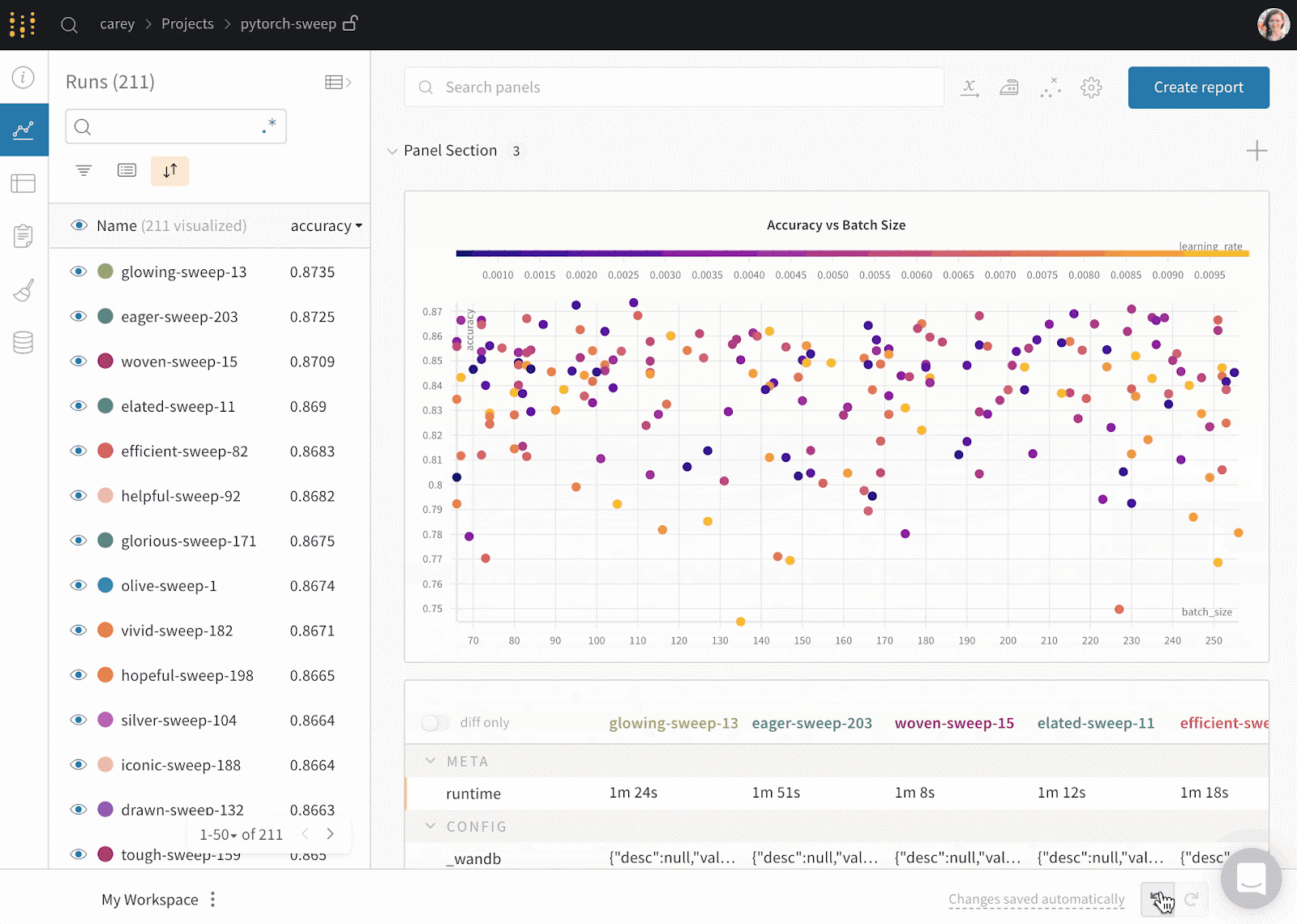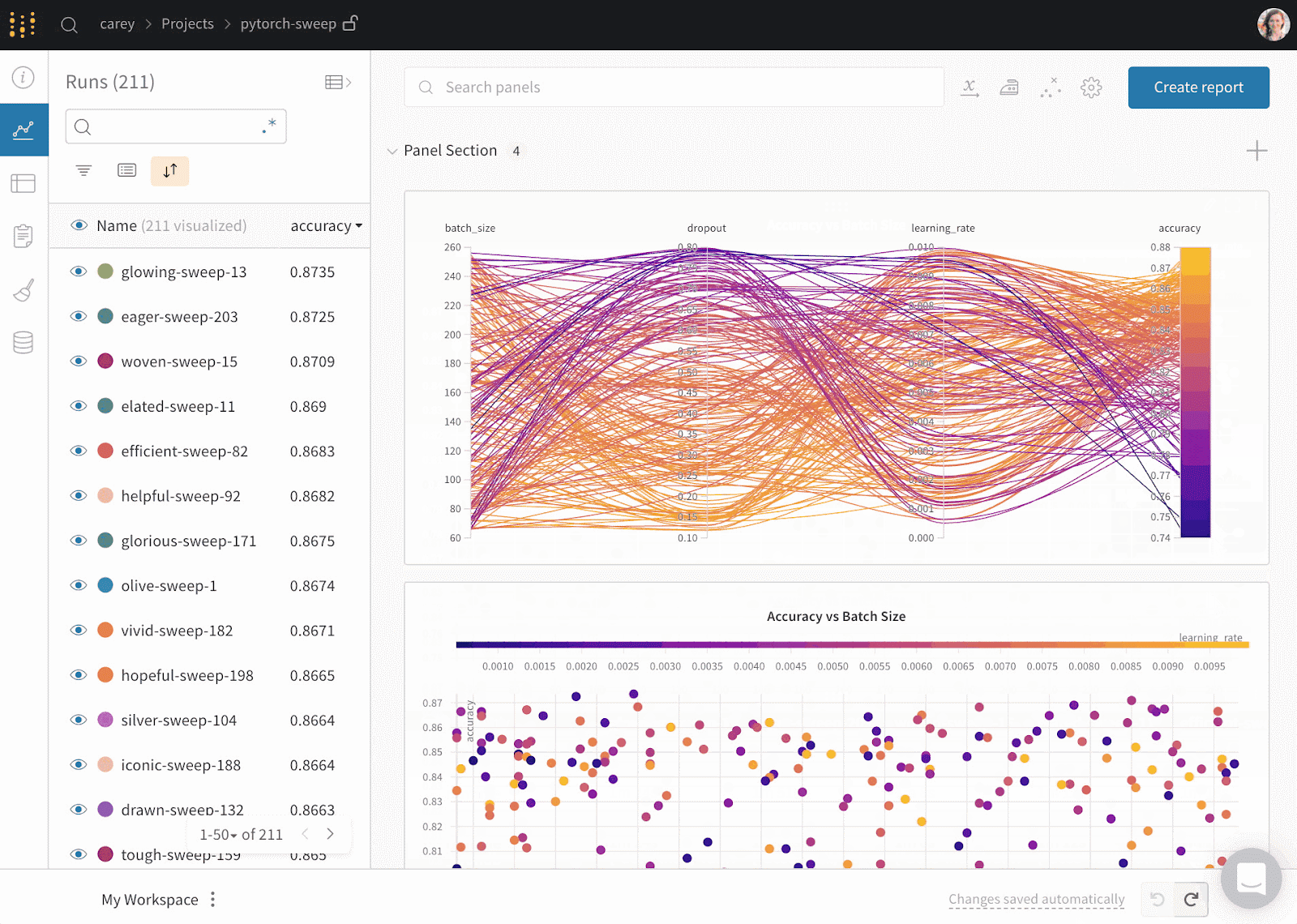
Gif de Weights & Biases
Note: Vous pouvez également utiliser TensorBoard, Pachyderm, DagsHub et DVC Studio pour le suivi des expériences et la gestion des métadonnées ML.
Ces outils vous aident à créer des projets de science des données et à gérer des flux de travail d'apprentissage automatique :
The Prefect est une pile de données moderne permettant de surveiller, de coordonner et d'orchestrer les flux de travail entre et à travers les applications. Il s'agit d'un outil léger et open-source conçu pour les pipelines d'apprentissage automatique de bout en bout.
Vous pouvez utiliser soit l'interface utilisateur de Prefect Orion, soit Prefect Cloud pour les bases de données.
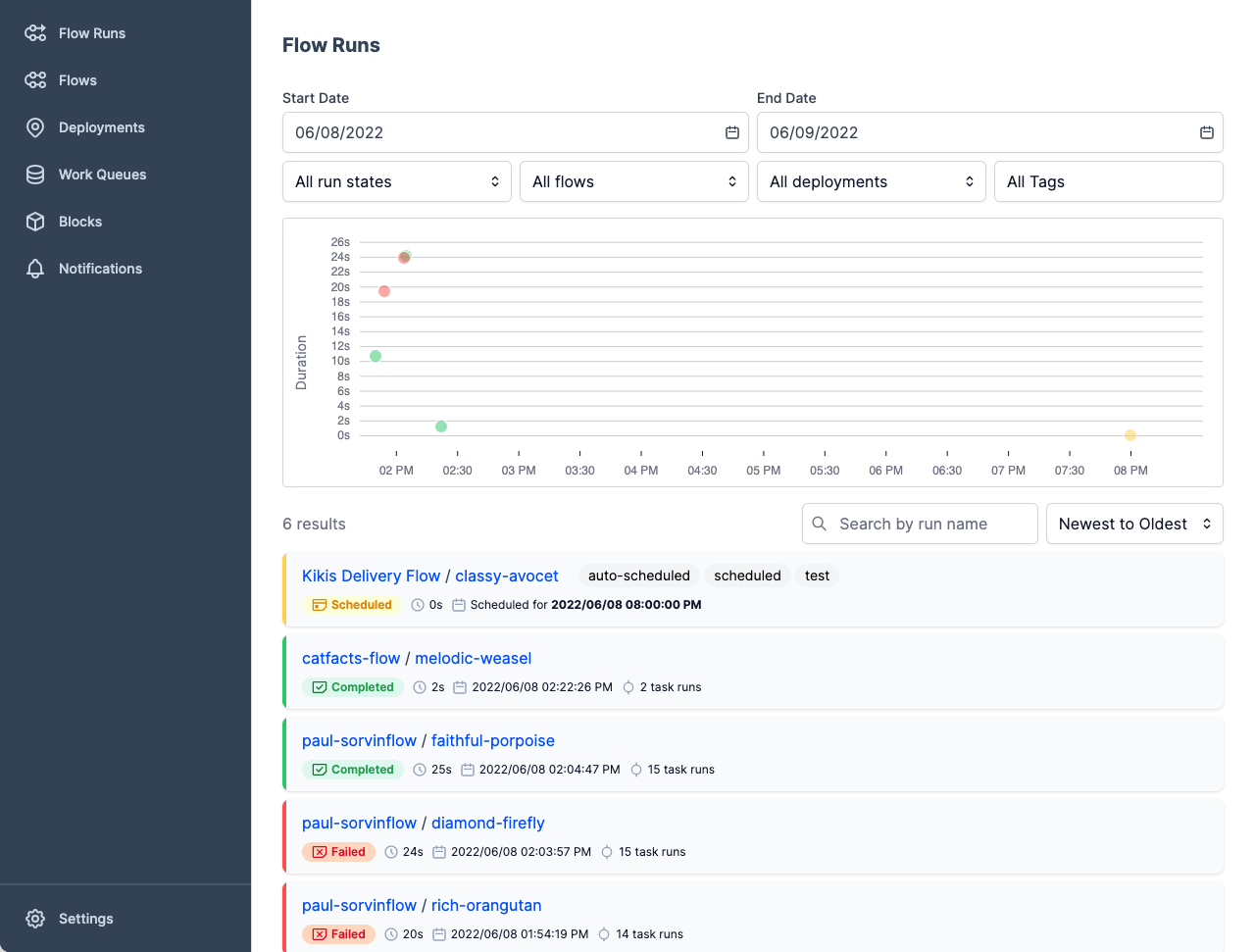
Image de Prefect
Metaflow est un outil de gestion de flux de travail puissant et robuste pour les projets de science des données et d'apprentissage automatique. Il a été conçu pour les scientifiques des données afin qu'ils puissent se concentrer sur la construction de modèles au lieu de se préoccuper de l'ingénierie MLOps.
Avec Metaflow, vous pouvez concevoir un flux de travail, l'exécuter à l'échelle et déployer le modèle en production. Il cursus et version des expériences et des données d'apprentissage automatique automatiquement. En outre, vous pouvez visualiser les résultats dans le carnet de notes.
Metaflow fonctionne avec plusieurs clouds (notamment AWS, GCP et Azure) et divers packages Python d'apprentissage automatique (comme Scikit-learn et Tensorflow), et l'API est également disponible pour le langage R.
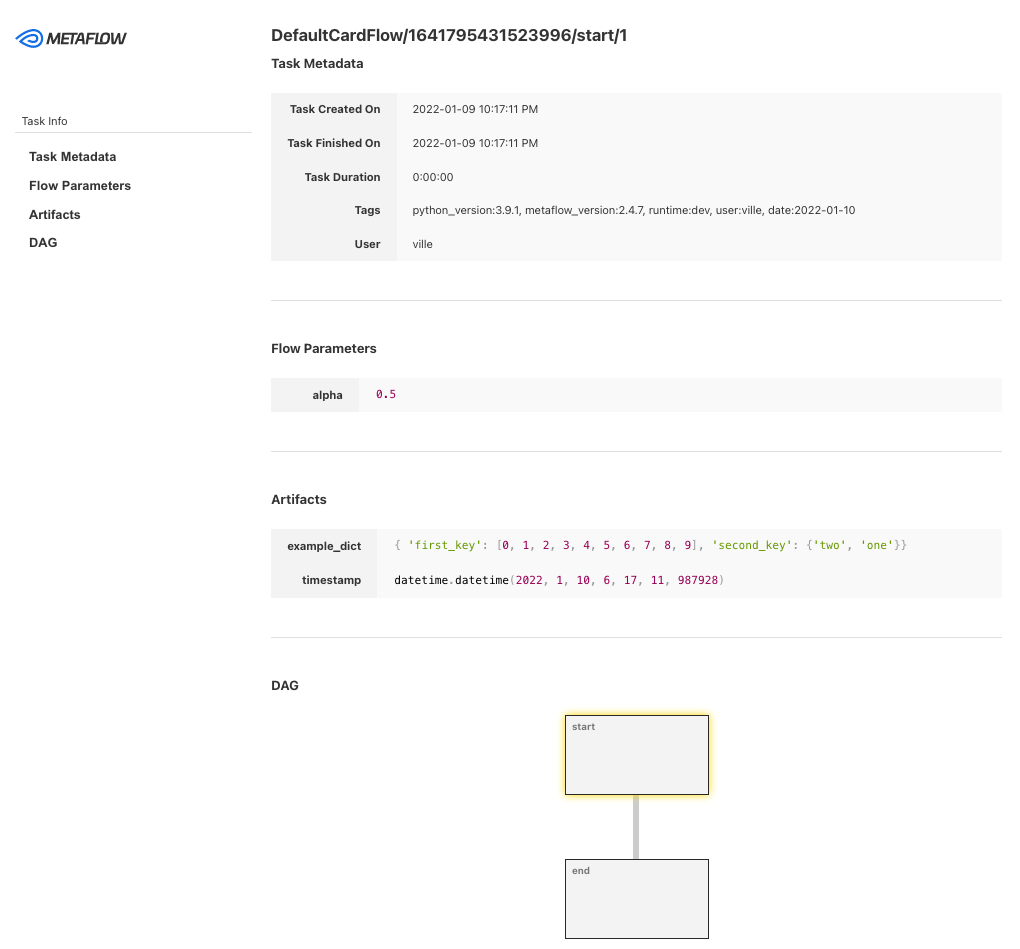
Image de Metaflow
Kedro est un outil d'orchestration de flux de travail basé sur Python. Vous pouvez l'utiliser pour créer des projets de science des données reproductibles, maintenables et modulaires. Il intègre les concepts de l'ingénierie logicielle dans l'apprentissage automatique, tels que la modularité, la séparation des préoccupations et le versionnage.
Avec Kedro, vous pouvez :
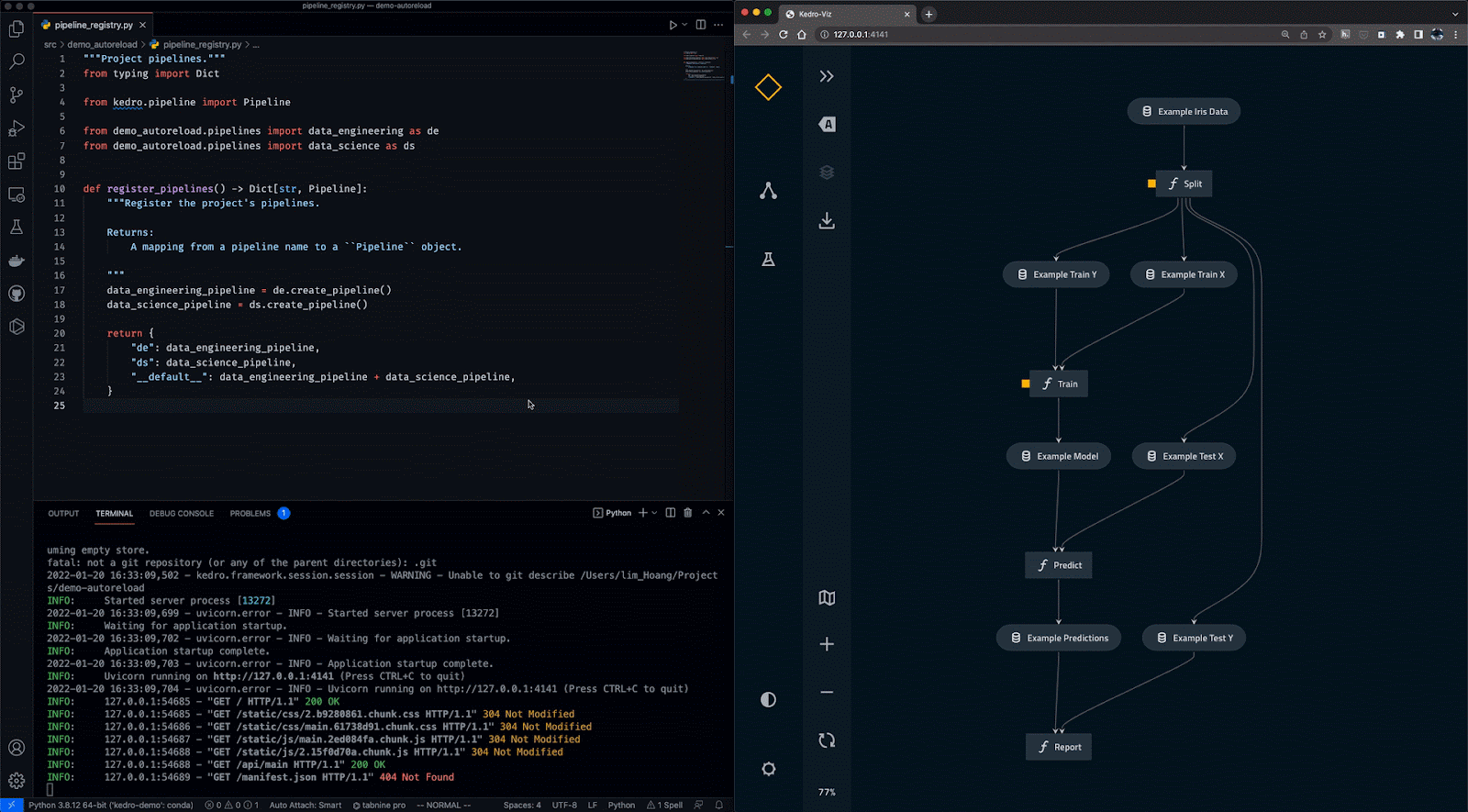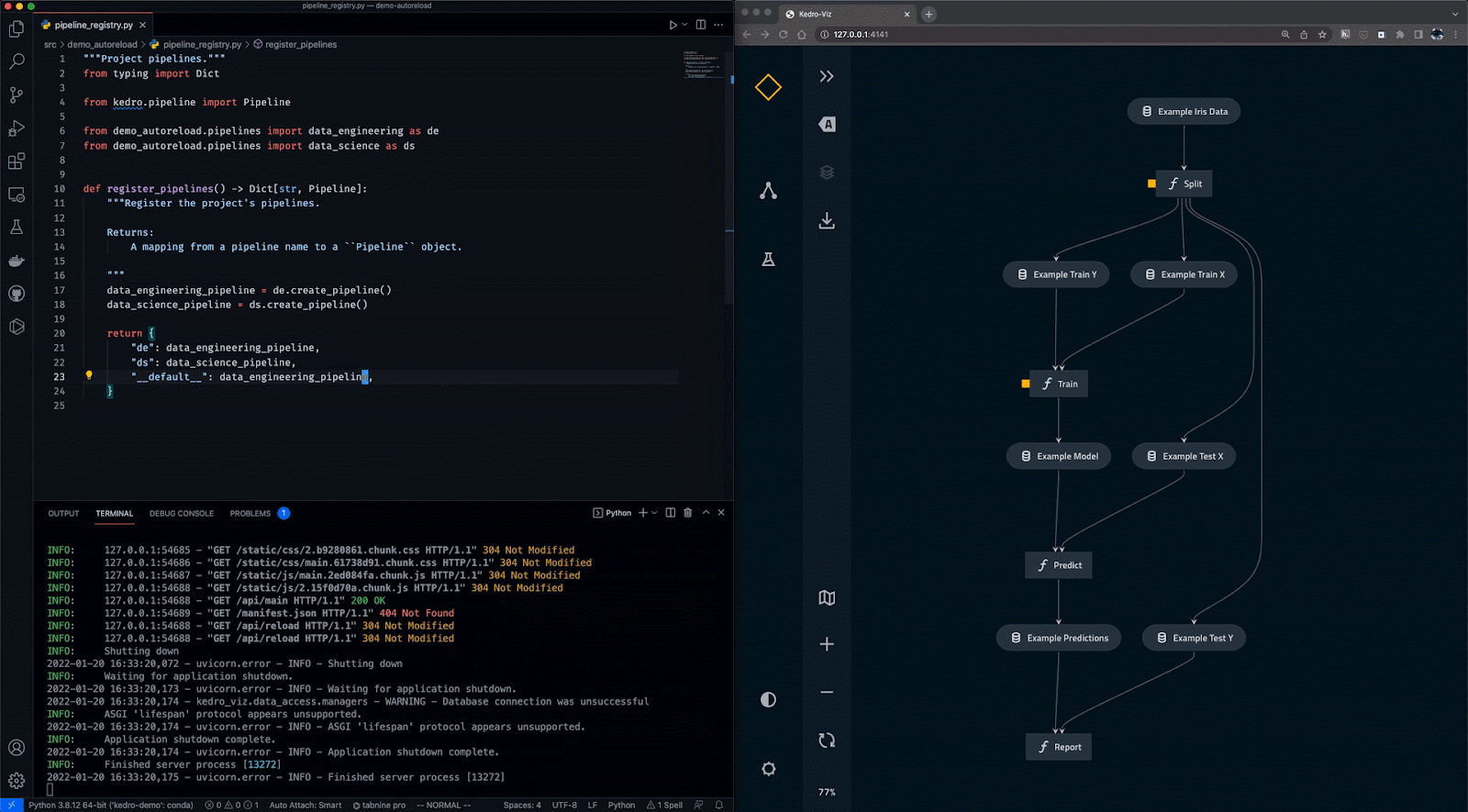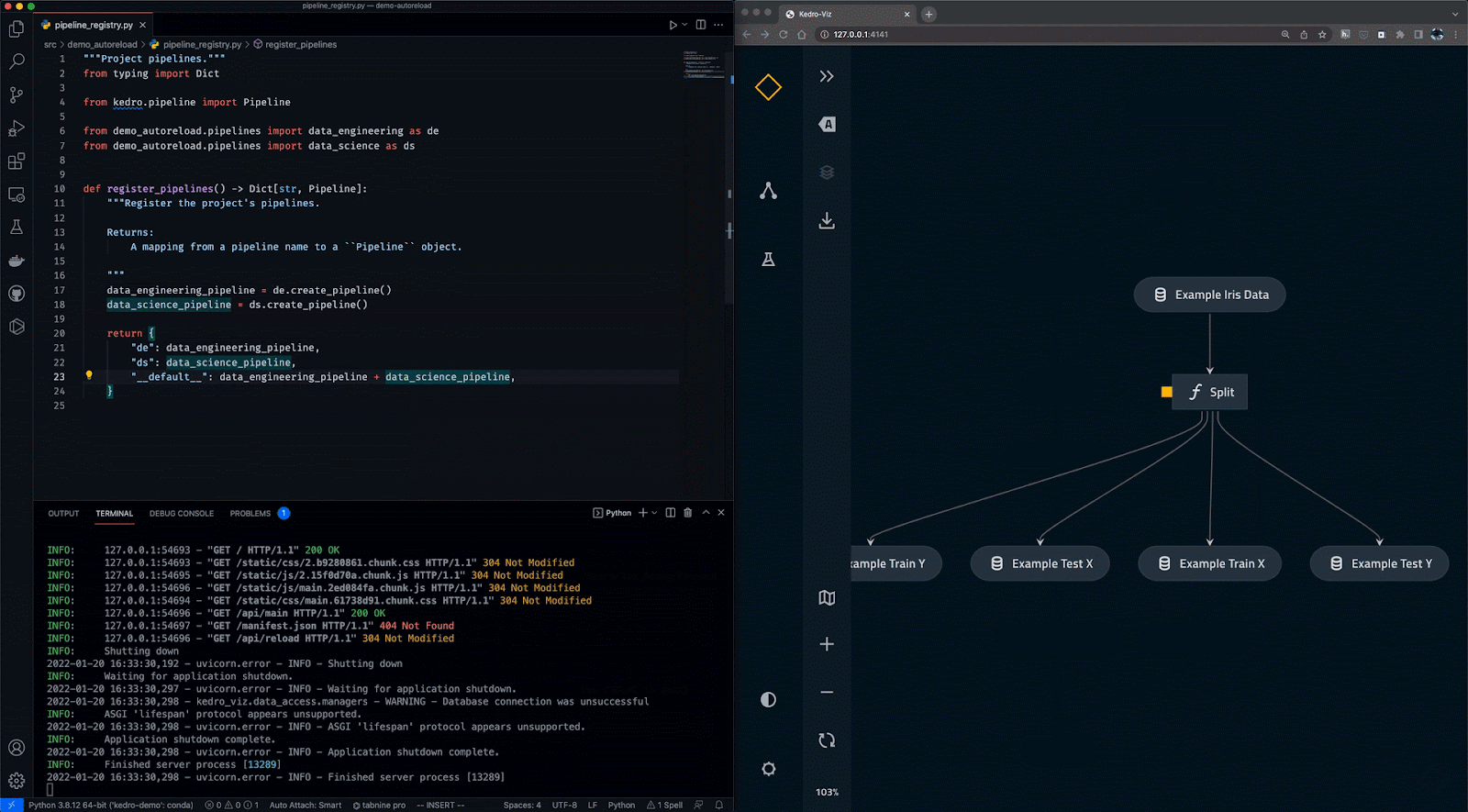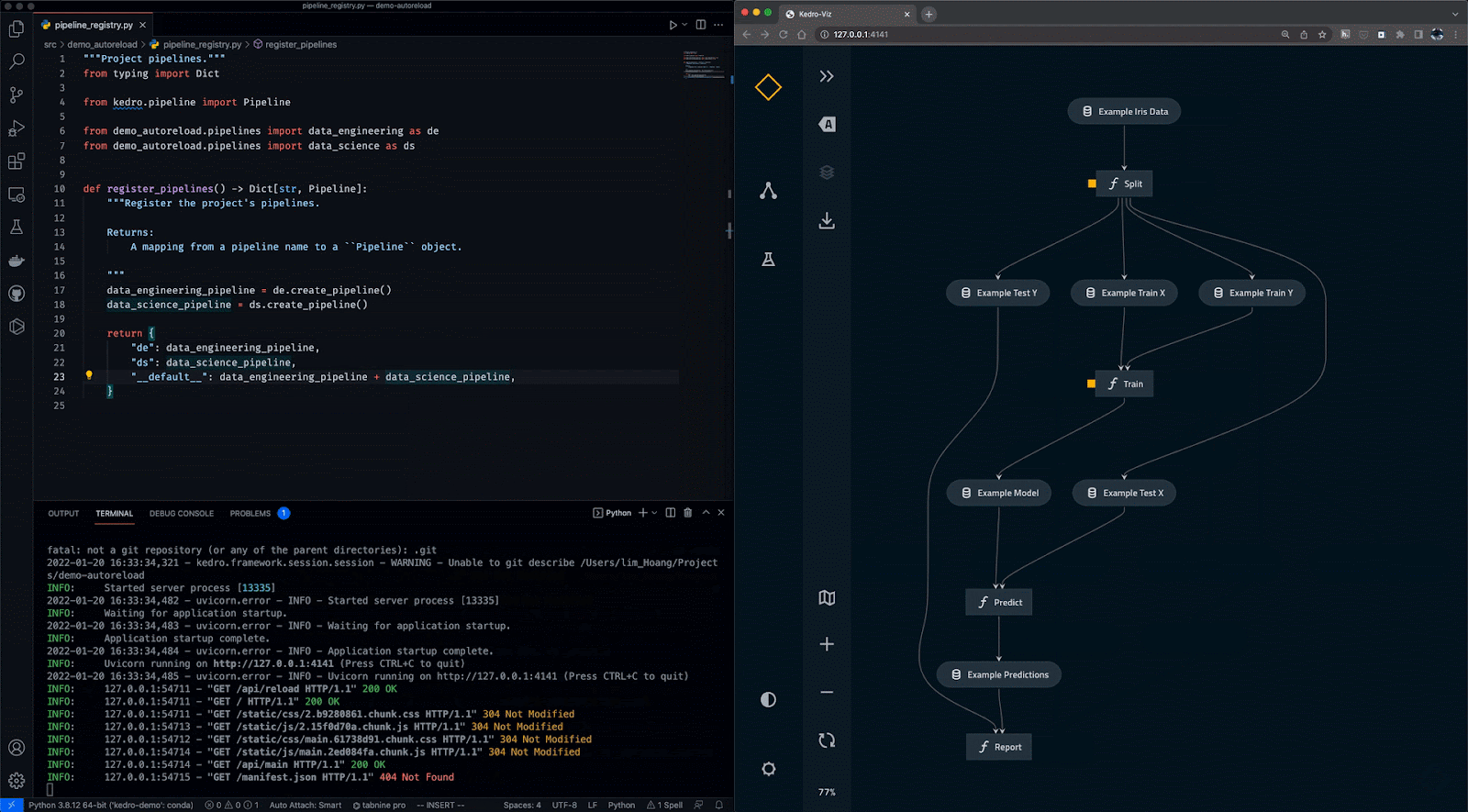
Gif de Kedro
Remarque: vous pouvez également utiliser Kubeflow et DVC pour l'orchestration et les pipelines de flux de travail.
Grâce à ces outils MLOps, vous pouvez gérer les tâches liées à la version des données et du pipeline :
Pachyderm automatise la transformation des données avec le versionnage des données, le lignage et les pipelines de bout en bout sur Kubernetes. Vous pouvez intégrer n'importe quelles données (images, journaux, vidéos, CSV), n'importe quel langage (Python, R, SQL, C/C++) et à n'importe quelle échelle (Pétaoctets de données, milliers de tâches).
L'édition communautaire est open-source et destinée à une petite équipe. Les organisations et les équipes qui souhaitent bénéficier de fonctionnalités avancées peuvent opter pour l'édition Enterprise.
Tout comme Git, vous pouvez versionner vos données en utilisant une syntaxe similaire. Dans Pachyderm, le niveau le plus élevé de l'objet est Repository, et vous pouvez utiliser Commit, Branches, File, History et Provenance pour suivre et versionner le jeu de données.
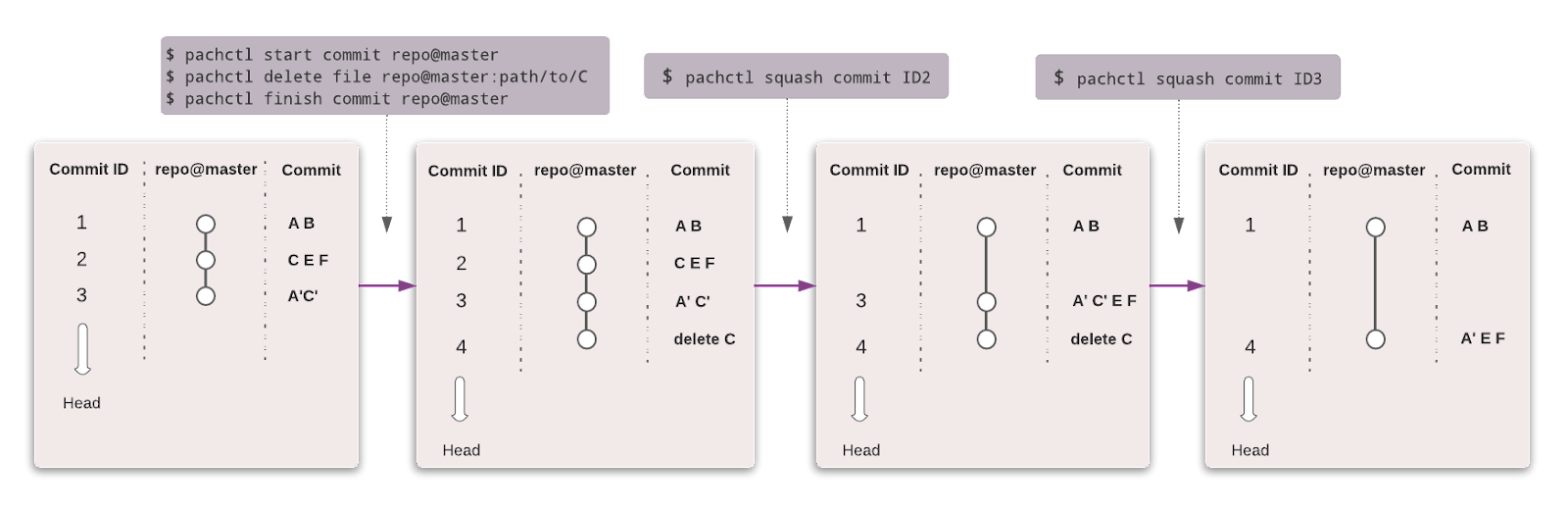
Image de Pachyderm
Data Version Control est un outil libre et populaire pour les projets d'apprentissage automatique. Il fonctionne de manière transparente avec Git pour vous fournir du code, des données, des modèles, des métadonnées et des versions de pipeline.
DVC est plus qu'un simple outil de suivi des données et de gestion des versions.
Vous pouvez l'utiliser pour :
Image de DVC
Note: DagsHub peut également être utilisé pour le versionnage des données et du pipeline.
LakeFS est un outil open-source de contrôle de version de données évolutif qui fournit une interface de contrôle de version de type Git pour le stockage d'objets, permettant aux utilisateurs de gérer leurs lacs de données comme ils le feraient pour leur code. Avec LakeFS, les utilisateurs peuvent contrôler les versions des données à l'échelle d'un exaoctet, ce qui en fait une solution hautement évolutive pour la gestion de grands lacs de données.
Capacités supplémentaires:
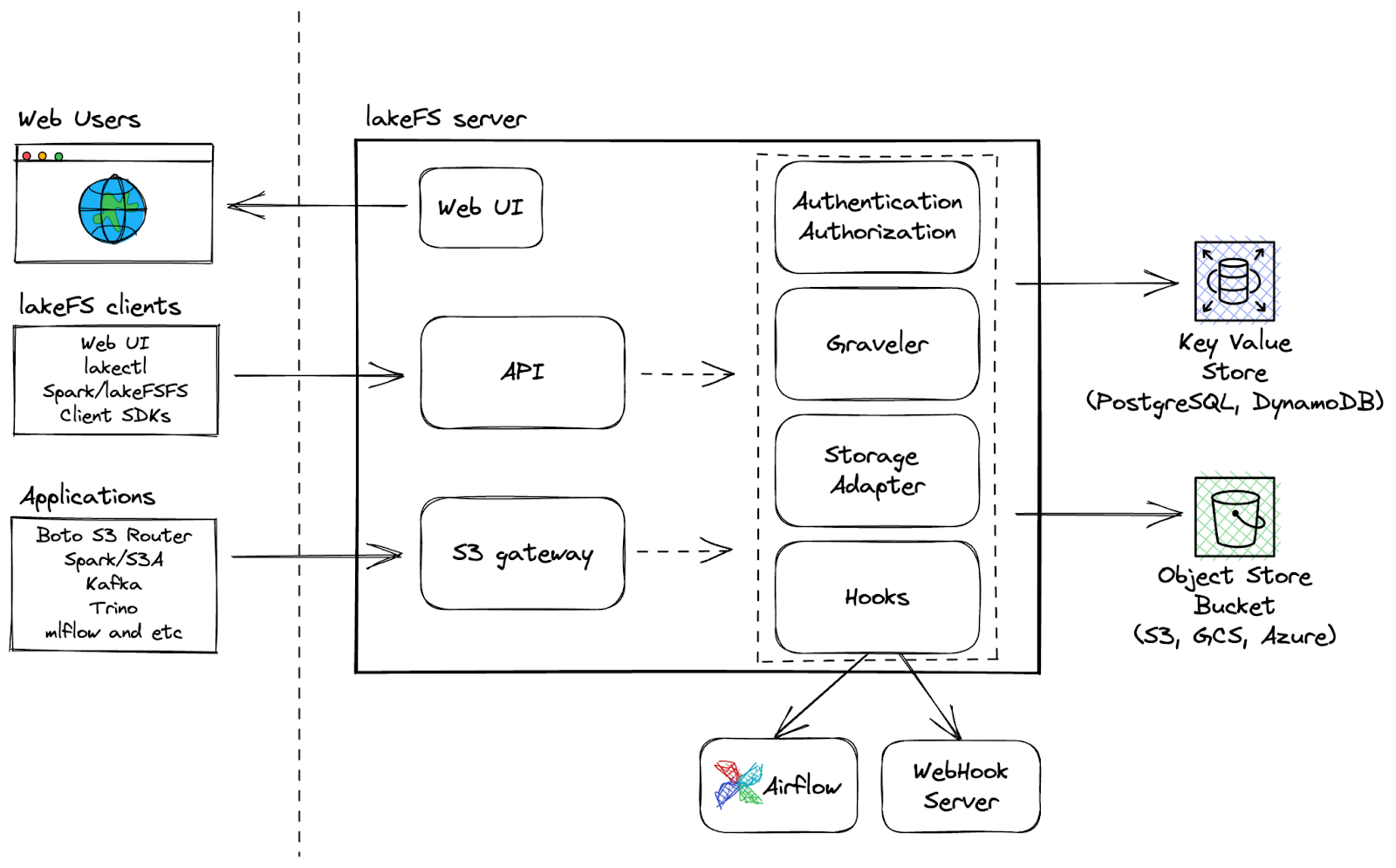
LakeFS Architecture
Les magasins d'entités sont des référentiels centralisés pour le stockage, la gestion des versions et la fourniture d'entités (attributs de données traitées utilisés pour l'apprentissage des modèles d'apprentissage automatique) pour les modèles d'apprentissage automatique en production ainsi qu'à des fins de formation.
Feast est un magasin de fonctionnalités open-source qui aide les équipes d'apprentissage automatique à produire des modèles en temps réel et à construire une plateforme de fonctionnalités qui favorise la collaboration entre les ingénieurs et les scientifiques des données.
Caractéristiques principales:
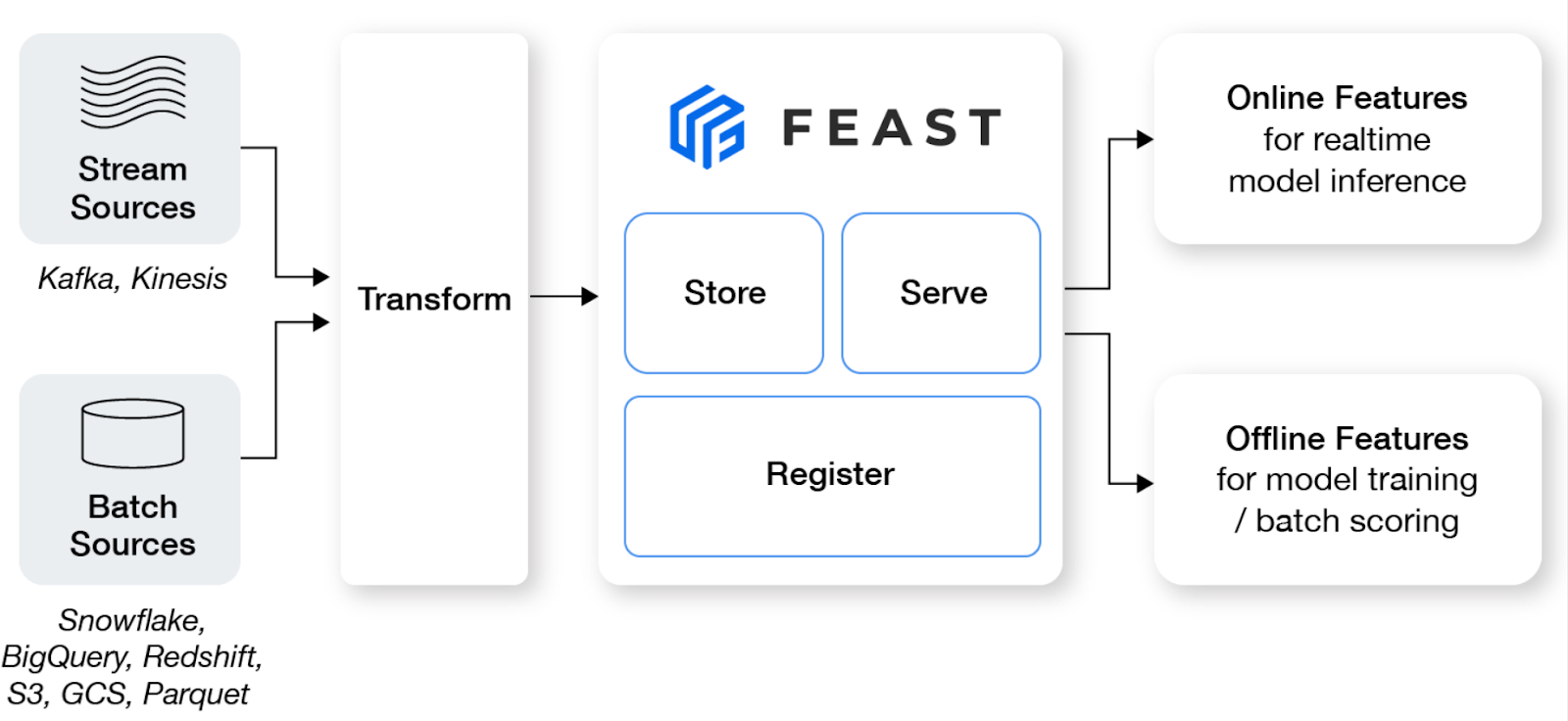
Image de Feast
Featureform est un magasin virtuel de fonctionnalités qui permet aux scientifiques des données de définir, de gérer et de servir les fonctionnalités de leur modèle ML. Il peut aider les équipes de science des données à améliorer la collaboration, à organiser l'expérimentation, à faciliter le déploiement, à accroître la fiabilité et à préserver la conformité.
Caractéristiques principales:
Image de Featureform
Grâce à ces outils MLOps, vous pouvez tester la qualité des modèles et garantir la fiabilité, la robustesse et la précision des modèles d'apprentissage automatique :
Deepchecks est une solution open-source qui répond à tous vos besoins en matière de validation ML, garantissant que vos données et vos modèles sont testés de manière approfondie, de la recherche à la production. Il offre une approche holistique pour valider vos données et vos modèles grâce à ses différents composants.
Image de Deepchecks
Les vérifications approfondies se composent de trois éléments :
TruEra est une plateforme avancée conçue pour améliorer la qualité et la performance des modèles grâce à des tests automatisés, à l'explicabilité et à l'analyse des causes profondes. Il offre diverses fonctionnalités permettant d'optimiser et de déboguer les modèles, d'obtenir la meilleure explicabilité possible et de s'intégrer facilement dans votre pile technologique de ML.
Caractéristiques principales:
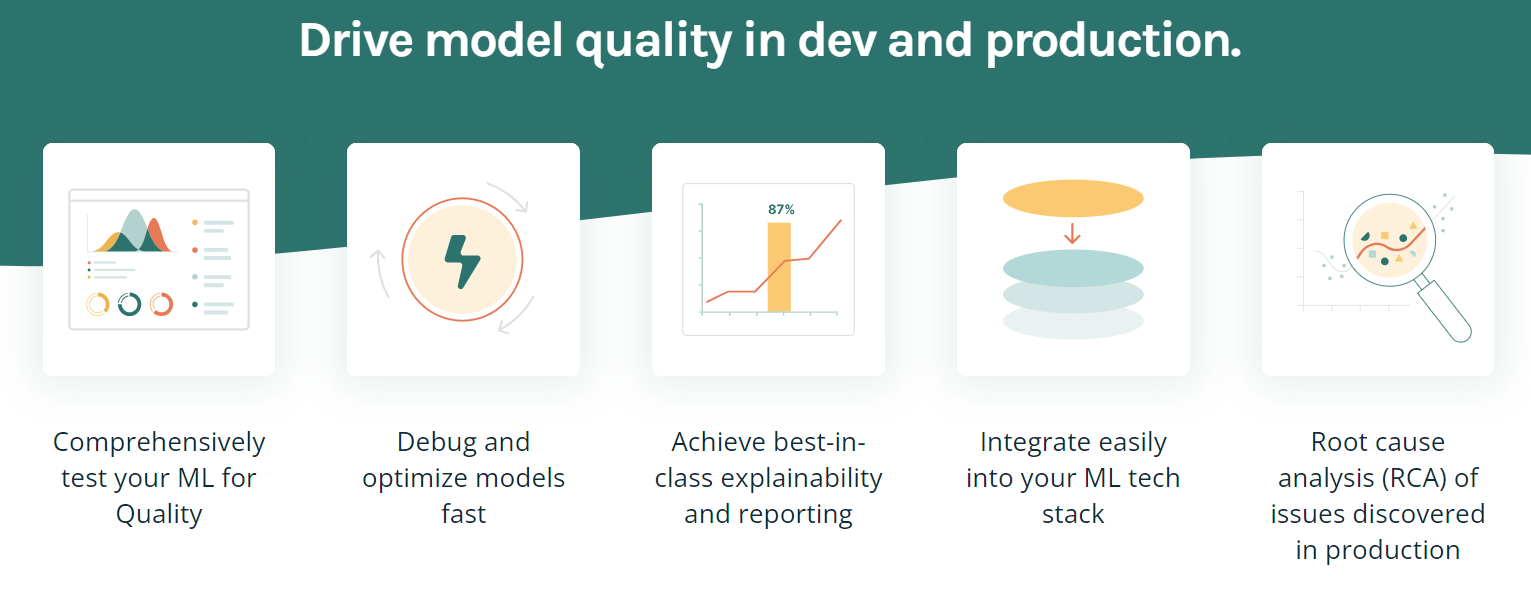
Image par TruEra
Lorsqu'il s'agit de déployer des modèles, ces outils MLOps peuvent s'avérer extrêmement utiles :
Kubeflow rend le déploiement de modèles d'apprentissage automatique sur Kubernetes simple, portable et évolutif. Vous pouvez l'utiliser pour la préparation des données, l'entraînement des modèles, l'optimisation des modèles, la prédiction au service et la motorisation de la performance des modèles en production. Vous pouvez déployer le flux de travail d'apprentissage automatique localement, sur site, ou dans le cloud. En bref, il facilite l'utilisation de Kubernetes pour les équipes de science des données.
Caractéristiques principales:
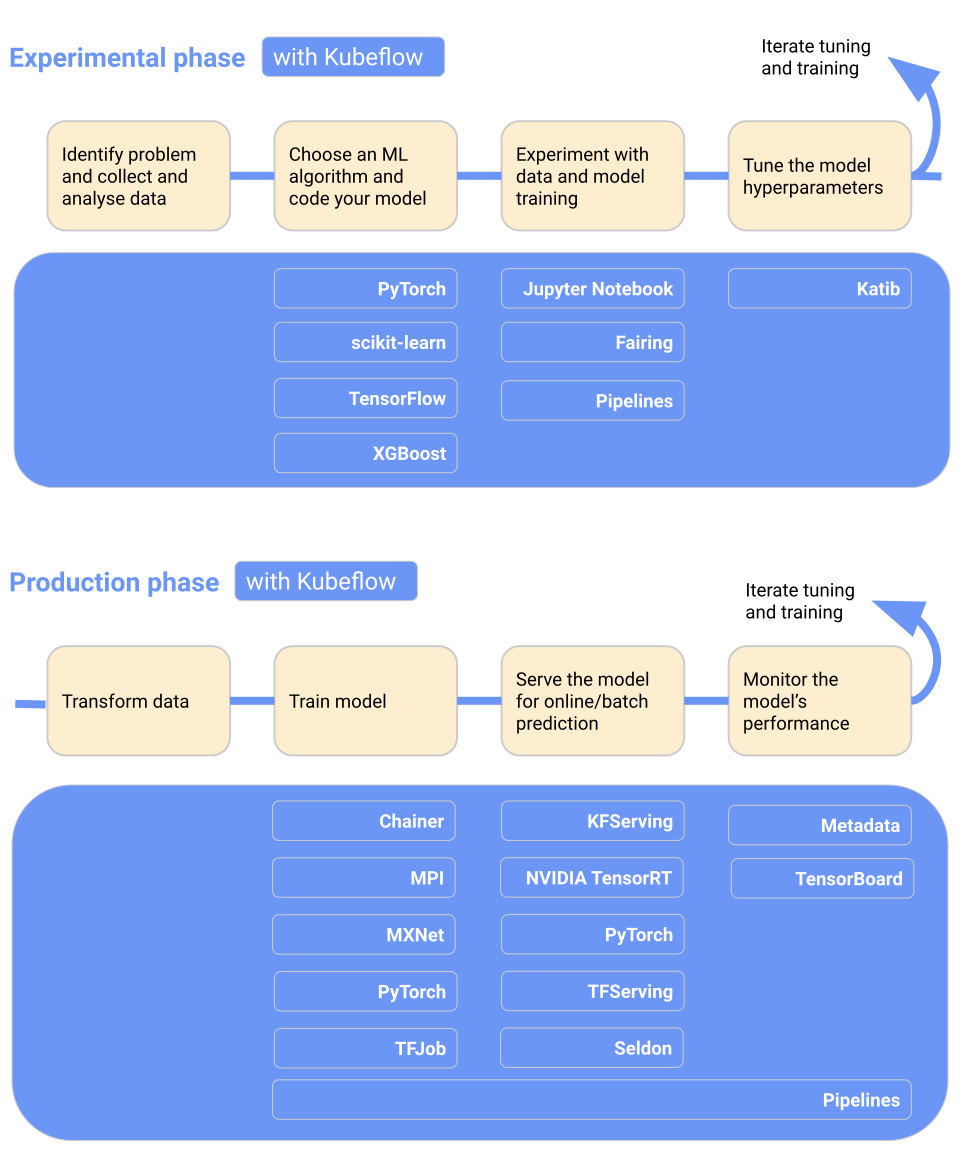
Image de Kubeflow
BentoML facilite et accélère la mise en place d'applications d'apprentissage automatique. Il s'agit d'un outil Python-first pour le déploiement et la maintenance des API en production. Il s'adapte avec de puissantes optimisations en exécutant l'inférence parallèle et la mise en lots adaptative et fournit une accélération matérielle.
Le tableau de bord centralisé et interactif de BentoML facilite l'organisation et le suivi du déploiement des modèles d'apprentissage automatique. Le plus intéressant est qu'il fonctionne avec toutes sortes de cadres d'apprentissage automatique, tels que Keras, ONNX, LightGBM, Pytorch et Scikit-learn. En bref, BentoML fournit une solution complète pour le déploiement, le service et la surveillance des modèles.
Image de BentoML
Hugging Face Inference Endpoints est un service basé sur le cloud offert par Hugging Face, une plateforme ML tout-en-un qui permet aux utilisateurs d'entraîner, d'héberger et de partager des modèles, des ensembles de données et des démonstrations. Ces points finaux sont conçus pour aider les utilisateurs à déployer leurs modèles d'apprentissage automatique formés pour l'inférence sans avoir à mettre en place et à gérer l'infrastructure requise.
Caractéristiques principales:
Image tirée de Hugging Face
Note : Vous pouvez également utiliser MLflow et AWS Sagemaker pour le déploiement et la distribution des modèles.
Que votre modèle de ML soit en cours de développement, de validation ou déployé en production, ces outils peuvent vous aider à contrôler une série de facteurs :
Evidently AI est une bibliothèque Python open-source pour la surveillance des modèles ML pendant le développement, la validation et en production. Il vérifie la qualité des données et des modèles, la dérive des données, la dérive des cibles et les performances de régression et de classification.
Evidently a trois composantes principales :
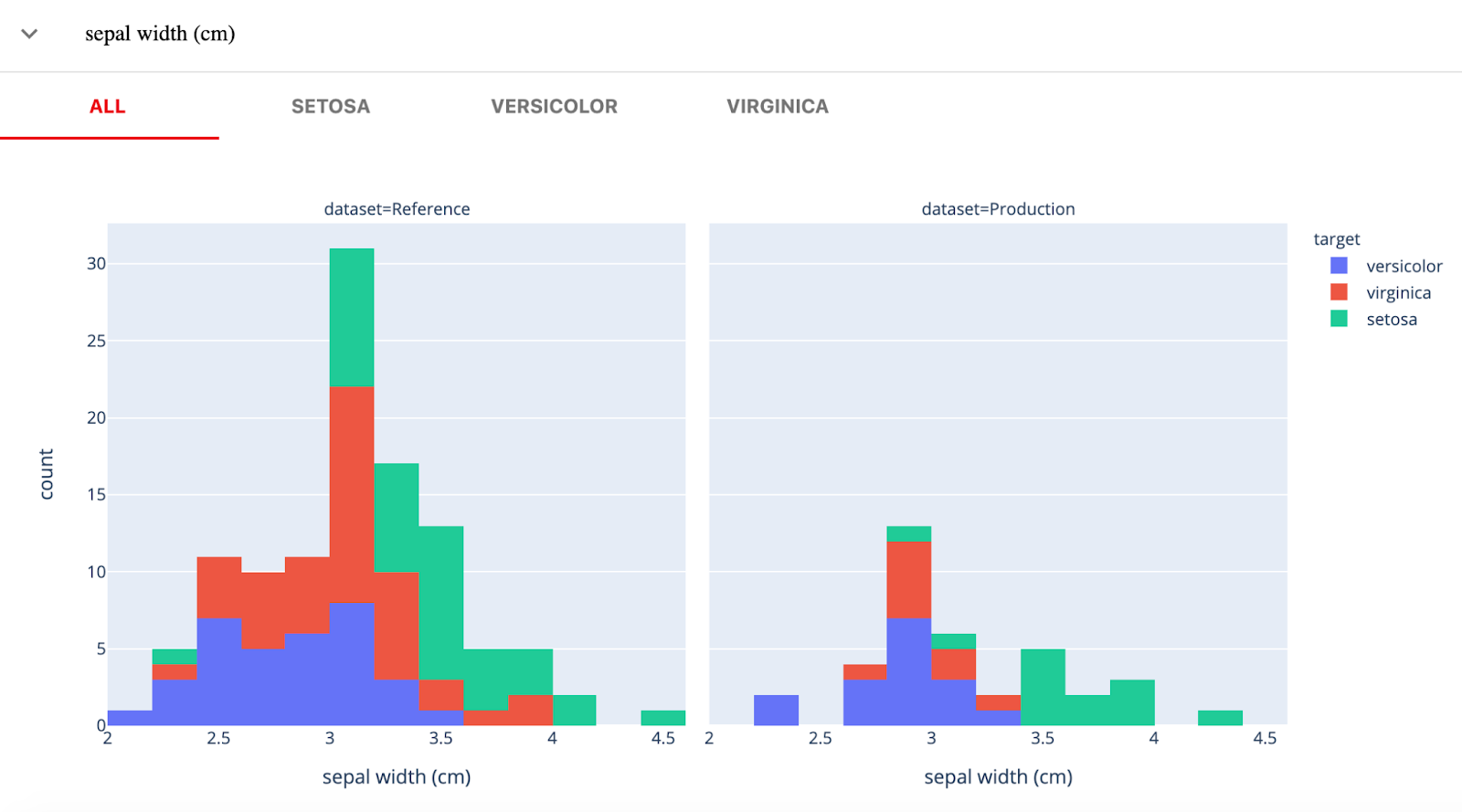
Image de Evidently
Fiddler AI est un outil de surveillance des modèles ML doté d'une interface utilisateur claire et facile à utiliser. Il vous permet d'expliquer et de déboguer les prédictions, d'analyser le comportement des modes pour l'ensemble des données, de déployer des modèles d'apprentissage automatique à grande échelle et de surveiller les performances des modèles.
Examinons les principales fonctionnalités de Fiddler AI pour la surveillance du ML :
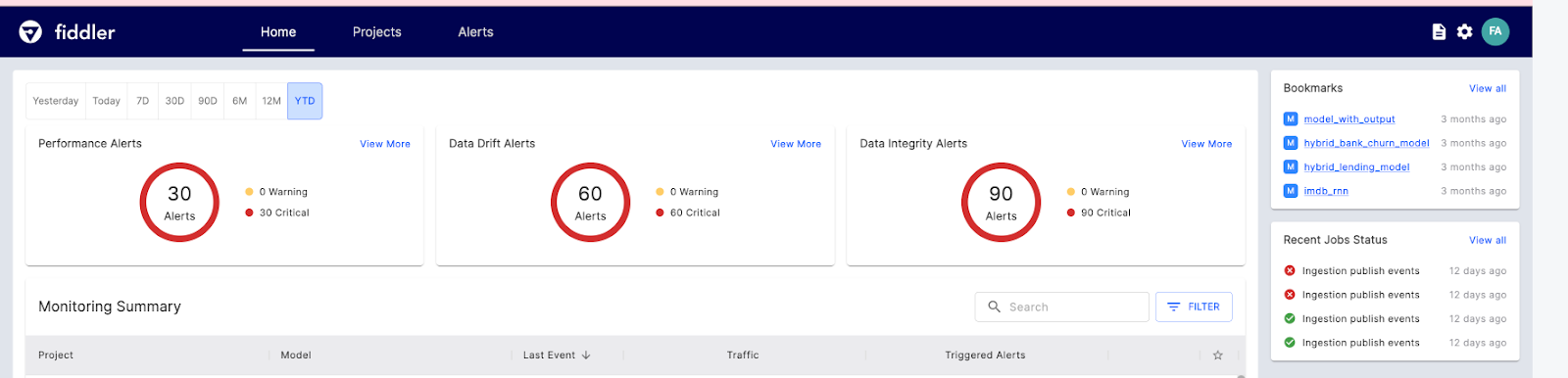
Image de Fiddler
Le moteur d'exécution est responsable du chargement du modèle, du prétraitement des données d'entrée, de l'exécution de l'inférence et du renvoi des résultats à l'application cliente.
Ray est un framework polyvalent conçu pour mettre à l'échelle les applications d'IA et de Python, facilitant ainsi la gestion et l'optimisation des projets d'apprentissage automatique par les développeurs.
La plateforme se compose de deux éléments principaux : un moteur d'exécution distribué et un ensemble de bibliothèques d'intelligence artificielle conçues pour simplifier le calcul ML.
Ray Core offre un ensemble limité d'éléments fondamentaux qui peuvent être utilisés pour construire et développer des applications distribuées.
Ray fournit également des bibliothèques d'IA pour les ensembles de données évolutifs pour la ML, l'entraînement distribué, l'ajustement des hyperparamètres, l'apprentissage par renforcement et les services évolutifs et programmables.
L'exemple suivant illustre la formation et l'utilisation d'un modèle de classification par renforcement du gradient.
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")Nuclio est un cadre puissant qui se concentre sur les charges de travail à forte intensité de données, d'E/S et de calcul. Il est conçu pour être sans serveur, ce qui signifie que vous n'avez pas à vous soucier de la gestion des serveurs. Nuclio est bien intégré aux outils de science des données les plus populaires, tels que Jupyter et Kubeflow. Il prend également en charge une grande variété de sources de données et de flux et peut être exécuté sur des CPU et des GPU.
Caractéristiques principales:
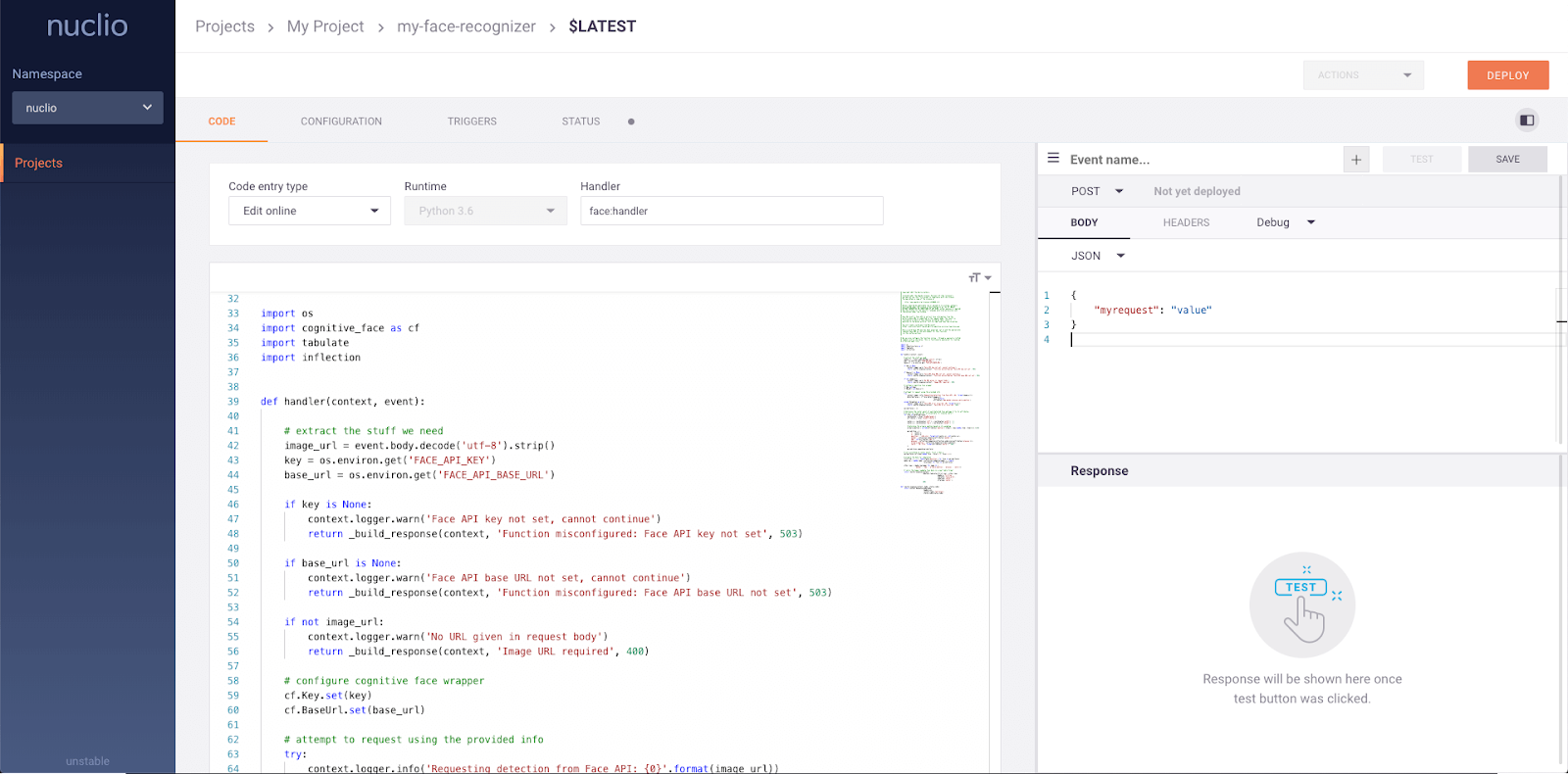
Image de Nuclio
Si vous êtes à la recherche d'un outil MLOps complet qui peut vous aider tout au long du processus, voici quelques-uns des meilleurs :
Amazon Web Services SageMaker est une solution complète pour les MLOps. Vous pouvez former et accélérer le développement de modèles, suivre et versionner des expériences, cataloguer des artefacts ML, intégrer des pipelines ML CI/CD, et déployer, servir et surveiller des modèles en production de manière transparente.
Caractéristiques principales:
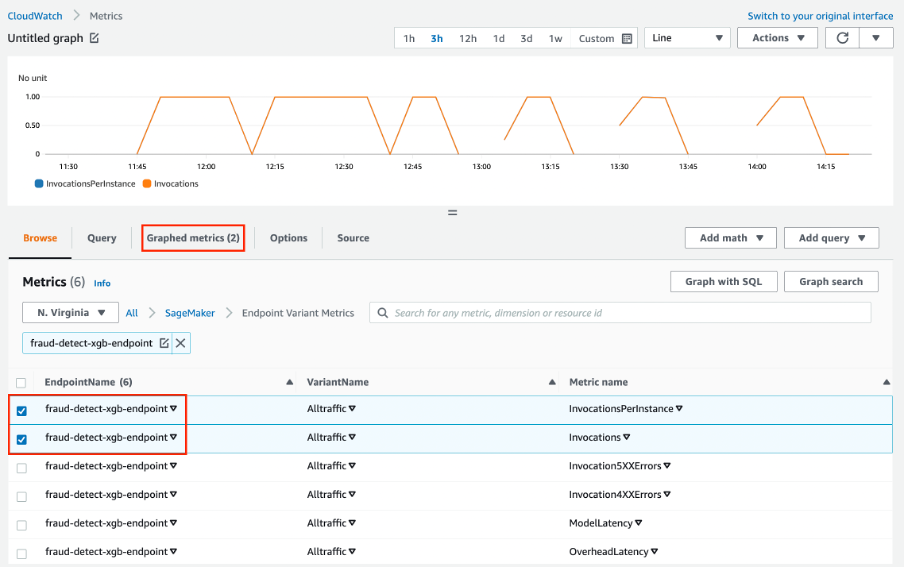
Image de Amazon SageMaker
DagsHub est une plateforme faite pour la communauté de l'apprentissage automatique pour suivre et versionner les données, les modèles, les expériences, les pipelines ML, et le code. Il permet à votre équipe d'élaborer, de réviser et de partager des projets d'apprentissage automatique.
En d'autres termes, il s'agit d'un GitHub pour l'apprentissage automatique, et vous disposez de divers outils pour optimiser le processus d'apprentissage automatique de bout en bout.
Caractéristiques principales:
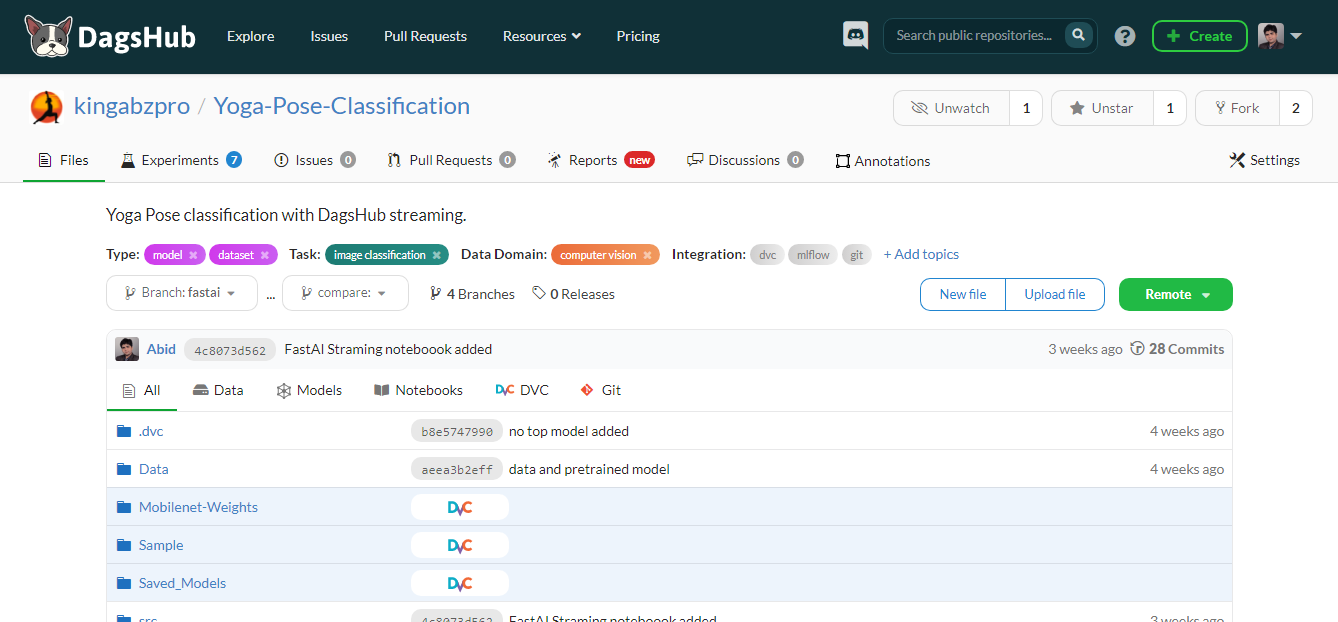
Image par l'auteur
La plateforme MLOps d 'Iguazio est une plateforme MLOps de bout en bout qui permet aux organisations d'automatiser le pipeline d'apprentissage automatique, de la collecte et de la préparation des données à l'entraînement, au déploiement et à la surveillance en production. Il s'agit d'une plateforme ouverte(MLRun) et gérée.
La plateforme MLOps d'Iguazio se distingue notamment par sa flexibilité en matière d'options de déploiement. Les utilisateurs peuvent déployer des applications d'IA n'importe où, y compris dans n'importe quel environnement cloud, hybride ou sur site. Ceci est particulièrement important pour des secteurs tels que la santé et la finance, où les préoccupations en matière de confidentialité des données peuvent imposer un déploiement sur site.
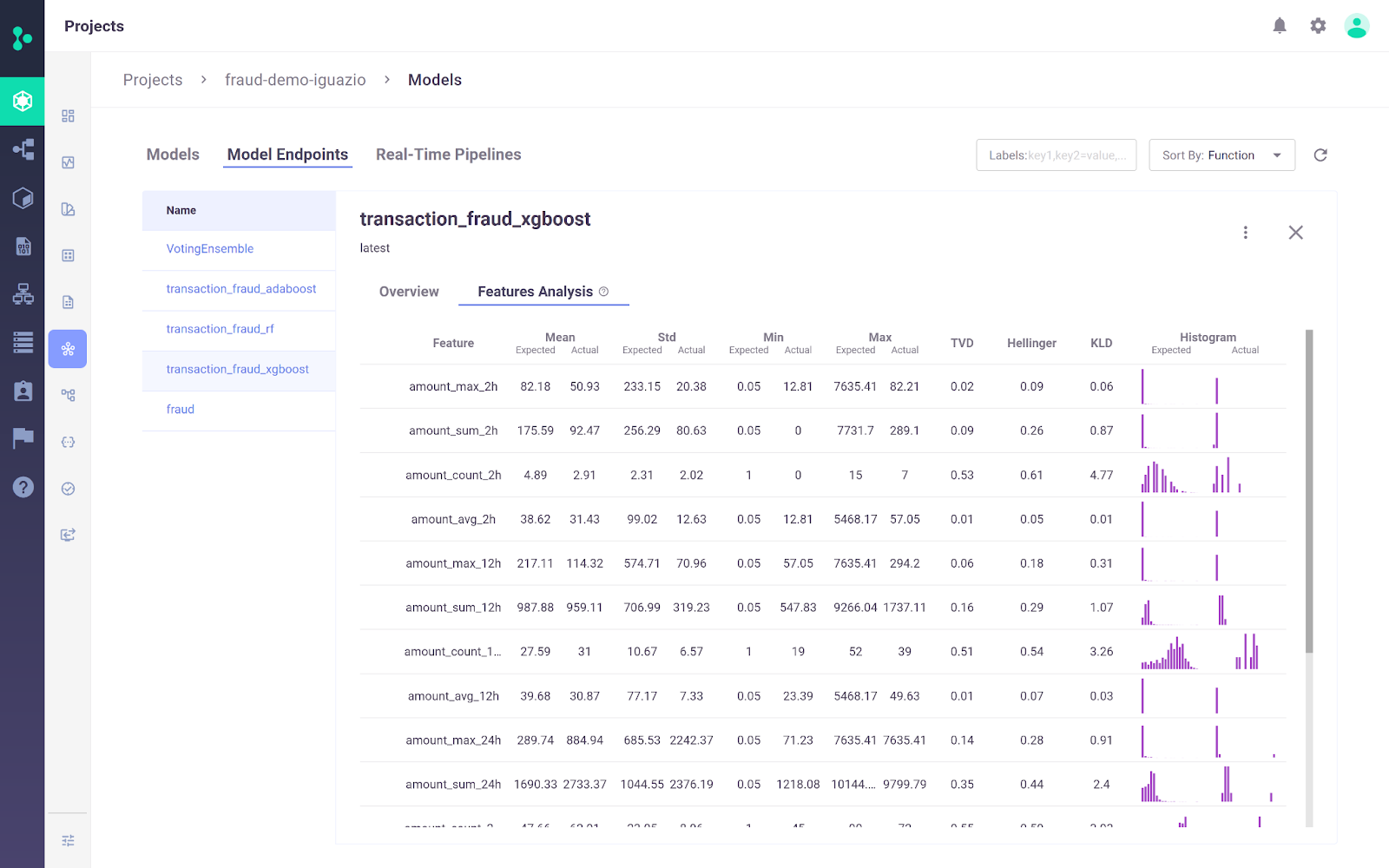
Image de la plateforme MLOps d'Iguazio
Caractéristiques principales:
Voici un tableau comparatif qui vous permettra d'évaluer ces outils côte à côte et de choisir ceux qui conviennent le mieux à vos projets :
| Outil | Fonctionnalité principale | Cadres pris en charge | Options de déploiement |
|---|---|---|---|
| Qdrant | Recherche de similarités vectorielles et gestion de bases de données | Python, plusieurs langues | Cloud-native, extensible horizontalement |
| LangChain | Développer des applications avec des modèles linguistiques | Python, JavaScript | API REST, modèles |
| MLFlow | Suivi des expériences, registre des modèles, déploiement | Python, R, Java, API REST | Local, cloud |
| Comète ML | Suivi et optimisation des expériences | Scikit-learn, PyTorch, TensorFlow, HuggingFace | Local, cloud |
| Poids et biais | Suivi des expériences, versionnement des données et des modèles | Fastai, Keras, PyTorch, HuggingFace, Yolov5, Spacy | Local, cloud |
| Préfet | Orchestration et surveillance du flux de travail | Python | Local (Orion UI), Cloud |
| Metaflow | Gestion du flux de travail pour la science des données | Scikit-learn, TensorFlow, Python, R | AWS, GCP, Azure, local |
| Kedro | Orchestration du flux de travail, reproductibilité | Python | Local, distribué |
| Pachyderme | Transformation, versionnement et lignage des données | Toutes les langues | Kubernetes |
| DVC | Versionnement des données et du pipeline | Git, Python | Local, cloud |
| LakeFS | Contrôle de version de type Git pour les lacs de données | Tout service de stockage | Local, cloud |
| Festin | Stockage centralisé des caractéristiques pour les modèles de ML | Python | Local, cloud |
| Formulaire d'information | Magasin virtuel de caractéristiques pour les modèles ML | Python | Local, cloud |
| Vérifications approfondies | Test et validation du modèle ML | Python | Local, cloud |
| TruEra | Qualité du modèle et tests de performance | Python | Local, cloud |
| Kubeflow | Déploiement et orchestration de modèles ML | TensorFlow, PyTorch, PaddlePaddle, MXNet, XGboost | Kubernetes, cloud |
| BentoML | Déploiement de modèles et gestion des API | Keras, ONNX, LightGBM, PyTorch, Scikit-learn | Local, cloud |
| Hugging Face | Inférence et déploiement de modèles | Tous les modèles | Cloud |
| De toute évidence | Contrôle de la dérive des données et des cibles des modèles ML | Python | Local, cloud |
| Violoniste | Surveillance et débogage du modèle ML | Python | Local, cloud |
| Ray | Mettre à l'échelle les applications d'IA et de Python. | Python | Local, cloud |
| Nuclio | Cadre sans serveur pour les charges de travail à forte intensité de données et de calcul. | Jupyter, Kubeflow | Cloud, sur site |
| AWS SageMaker | Gestion de bout en bout du cycle de vie des ML | Python, R, Java, TensorFlow, PyTorch | Cloud AWS |
| DagsHub | Version et collaboration pour les projets de ML | Git, DVC, MLflow | Local, cloud |
| Iguazio | Automatisation de bout en bout des pipelines de ML | Python, MLRun | Cloud, hybride, sur site |
Nous sommes à une époque où le secteur des MLOps est en plein essor. Chaque semaine, vous voyez de nouveaux développements, de nouvelles startups et de nouveaux outils lancés pour résoudre le problème fondamental de la conversion des ordinateurs portables en applications prêtes à la production. Même les outils existants élargissent leur horizon et intègrent de nouvelles fonctionnalités pour devenir de super outils MLOps.
Dans ce blog, nous avons découvert les meilleurs outils MLOps pour les différentes étapes du processus MLOps. Ces outils vous aideront pendant les phases d'expérimentation, de développement, de déploiement et de contrôle.
Si vous débutez dans l'apprentissage automatique et que vous souhaitez maîtriser les compétences essentielles pour décrocher un emploi de scientifique en apprentissage automatique, essayez de suivre notre cursus de carrière Scientifique en apprentissage automatique avec Python.
Si vous êtes un professionnel et que vous souhaitez en savoir plus sur les pratiques standard de MLOps, lisez notre article sur les meilleures pratiques de MLOps et la manière de les appliquer et consultez notre cursus de compétences MLOps Fundamentals .
Apprenez-en plus sur les MLOps grâce à ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Nisha Arya Ahmed
15 min
blog
Nathaniel Taylor-Leach
8 min
blog
Lynn Heidmann
Tutoriel

