
Kurs
MLOps-Konzepte
2 Std.
42.7K
Lerne, wie du mit LLMs in Python direkt in deinem Browser arbeiten kannst

Mit der Einführung von GPT-4 und später GPT-4o hat der Wettlauf begonnen, große Sprachmodelle zu erstellen und das volle Potenzial der modernen KI auszuschöpfen. LLMs benötigen Vektordatenbanken und Integrationsframeworks für den Aufbau intelligenter KI-Anwendungen.
Qdrant ist eine Open-Source-Suchmaschine für Vektorähnlichkeit und eine Vektordatenbank, die einen produktionsreifen Dienst mit einer praktischen API bietet, mit der du Vektoreinbettungen speichern, suchen und verwalten kannst.
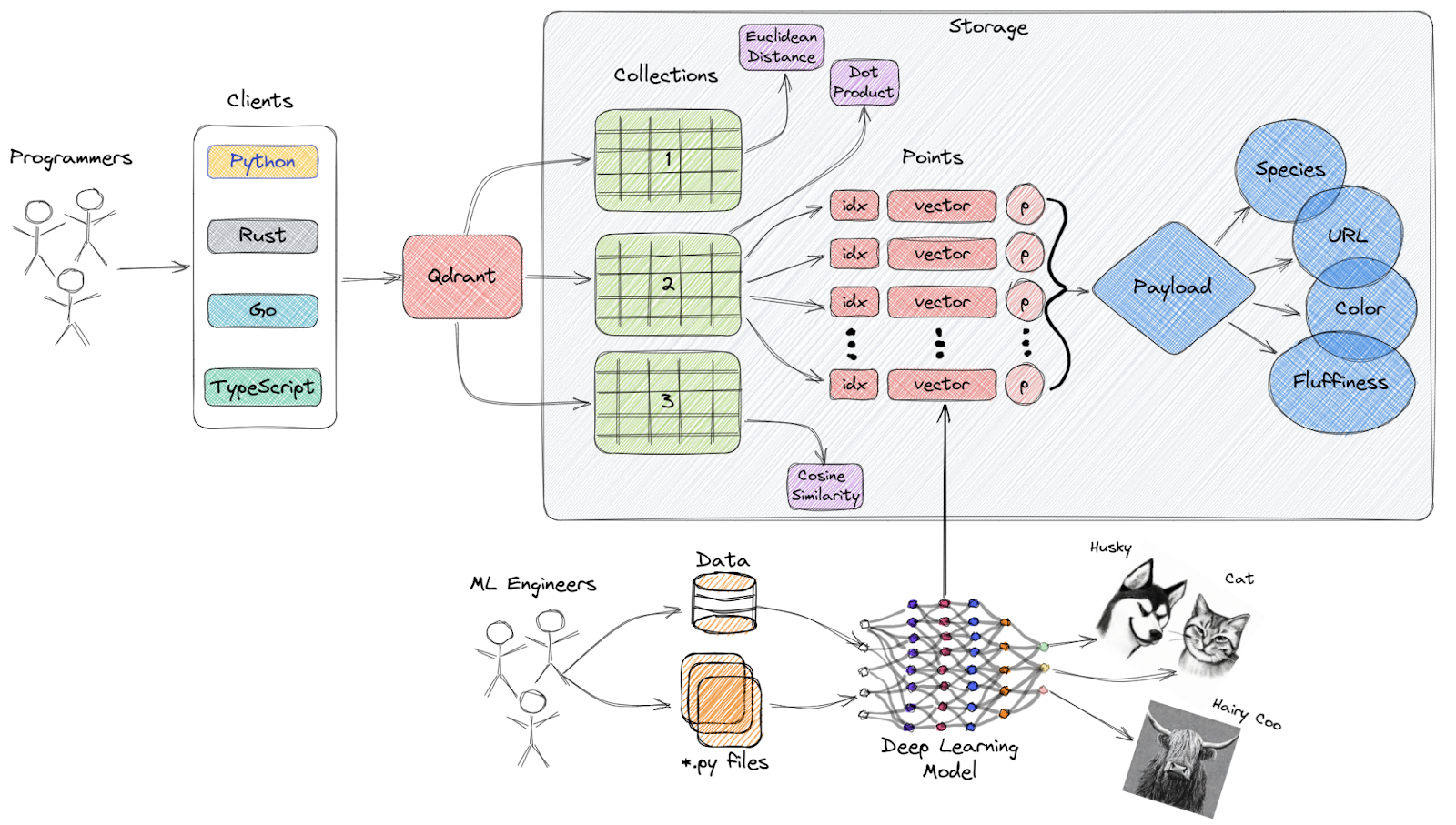
Überblick über die Architektur von Qdrant
Wichtige Merkmale:
Entdecke die besten Vektordatenbanken, indem du Die 5 besten Vektordatenbanken | Eine Liste mit Beispielen liest.
LangChain ist ein vielseitiges und leistungsstarkes Framework für die Entwicklung von Anwendungen, die auf Sprachmodellen basieren. Es bietet verschiedene Komponenten, mit denen Entwickler kontextbezogene und schlussfolgernde Anwendungen erstellen, einsetzen und überwachen können.
Der Rahmen besteht aus 4 Hauptkomponenten:
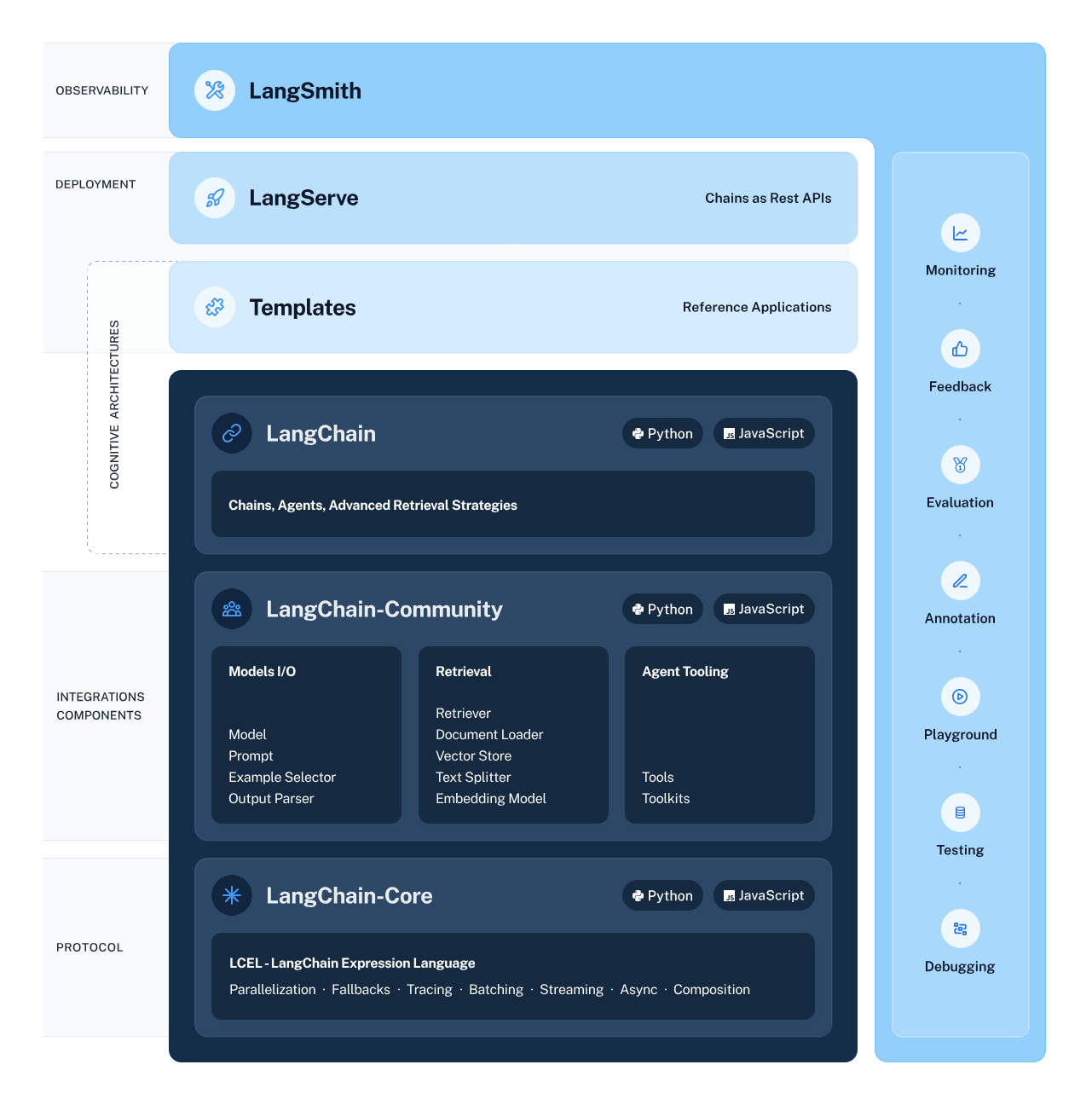
LangChain Ecosystem
Lerne , wie du LLM-Anwendungen mit LangChain erstellst und entdecke das ungenutzte Potenzial großer Sprachmodelle.
Mit diesen Tools kannst du die Metadaten der Modelle verwalten und die Experimente nachverfolgen:
MLflow ist ein Open-Source-Tool, das dir hilft, die wichtigsten Teile des Lebenszyklus des maschinellen Lernens zu verwalten. Er wird in der Regel für die Nachverfolgung von Experimenten verwendet, du kannst ihn aber auch für die Reproduzierbarkeit, den Einsatz und die Modellregistrierung nutzen. Du kannst die Machine-Learning-Experimente und Modell-Metadaten mit CLI, Python, R, Java und REST API verwalten.
MLflow hat vier Kernfunktionen:
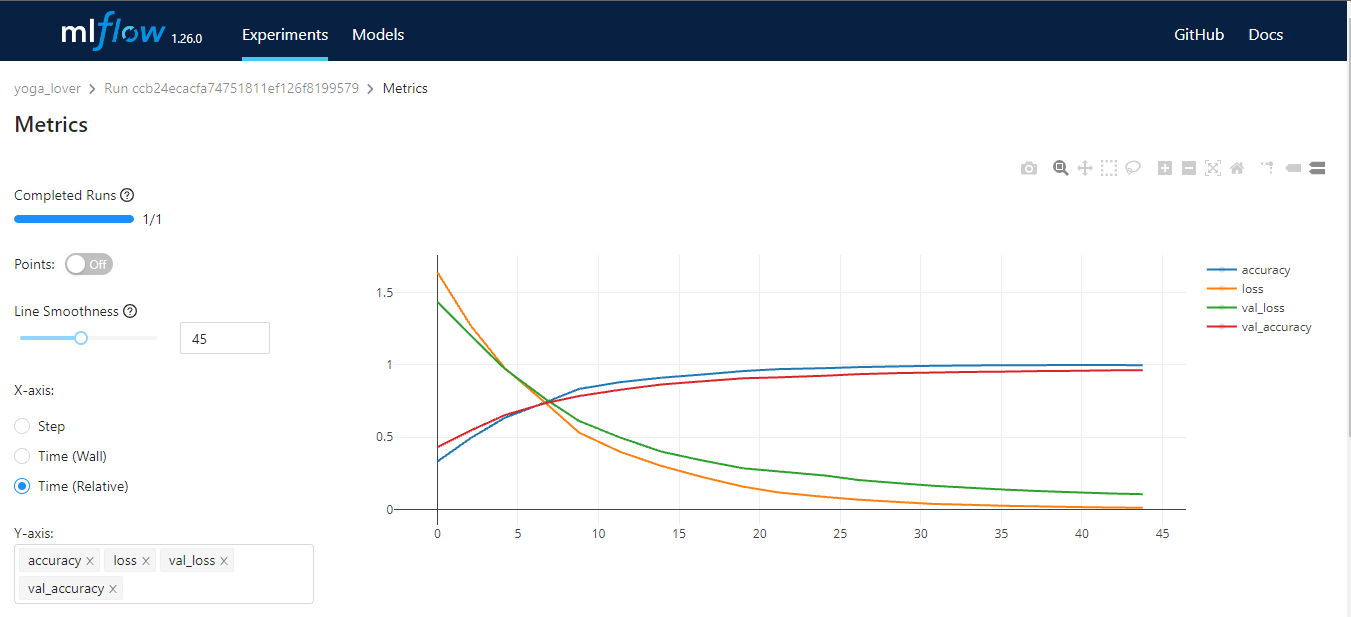
Bild vom Autor
Comet ML ist eine Plattform zum Verfolgen, Vergleichen, Erklären und Optimieren von Machine-Learning-Modellen und Experimenten. Du kannst es mit jeder Bibliothek für maschinelles Lernen verwenden, z. B. Scikit-learn, Pytorch, TensorFlow und HuggingFace.
Comet ML eignet sich für Einzelpersonen, Teams, Unternehmen und Hochschulen. So kann jeder die Experimente leicht visualisieren und vergleichen. Außerdem kannst du damit Muster aus Bildern, Audio-, Text- und Tabellendaten visualisieren.
Bild von Comet ML
Weights & Biases ist eine ML-Plattform für die Nachverfolgung von Experimenten, die Versionierung von Daten und Modellen, die Optimierung von Hyperparametern und die Modellverwaltung. Außerdem kannst du damit Artefakte (Datensätze, Modelle, Abhängigkeiten, Pipelines und Ergebnisse) protokollieren und die Datensätze visualisieren (Audio, visuell, Text und tabellarisch).
Weights & Biases hat ein benutzerfreundliches zentrales Dashboard für Experimente zum maschinellen Lernen. Wie Comet ML kannst du es mit anderen Bibliotheken für maschinelles Lernen integrieren, z. B. Fastai, Keras, PyTorch, Hugging Face, Yolov5, Spacy und vielen anderen. Du kannst dir unsere Einführung in Gewichte & BIase in einem separaten Artikel ansehen.
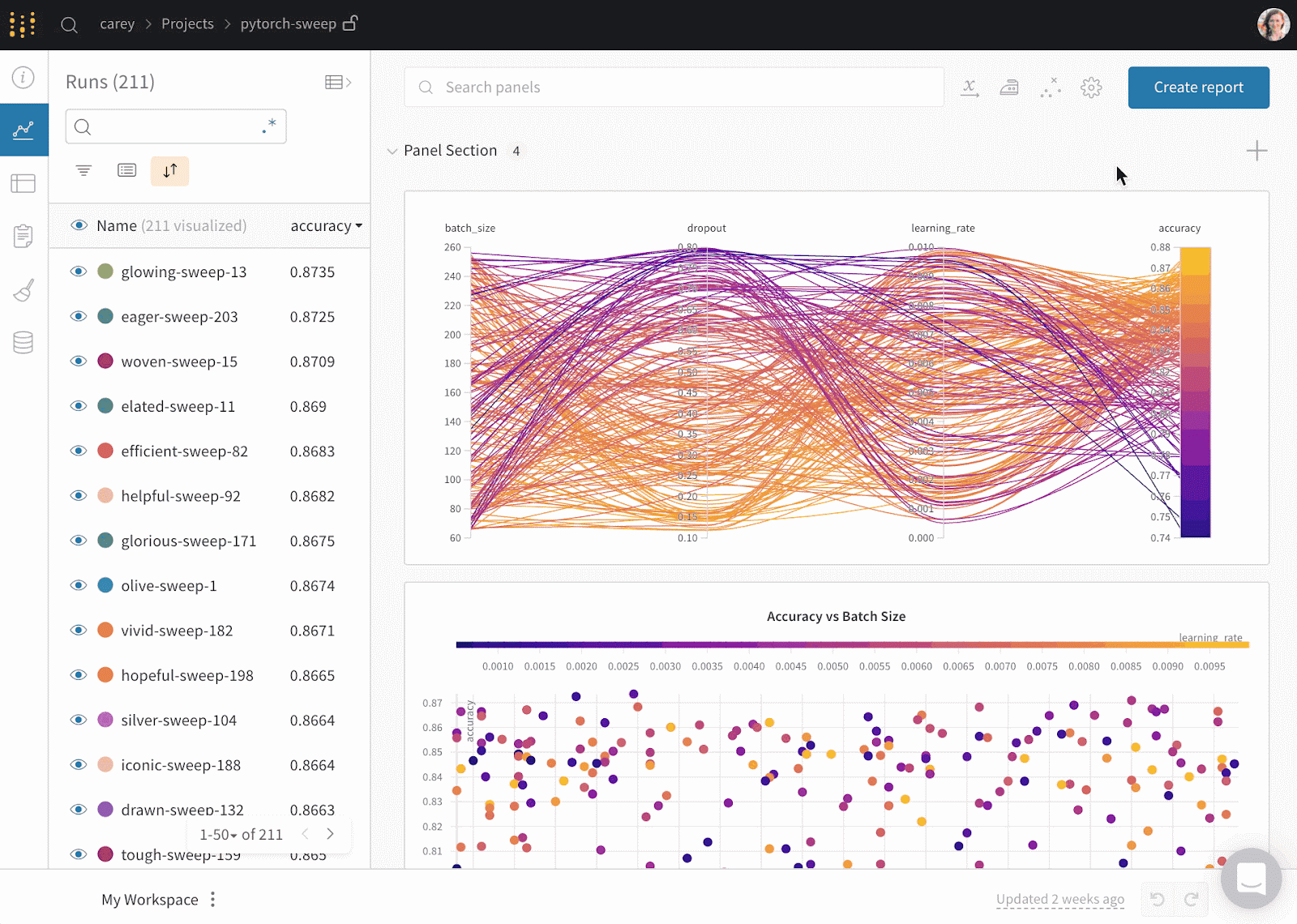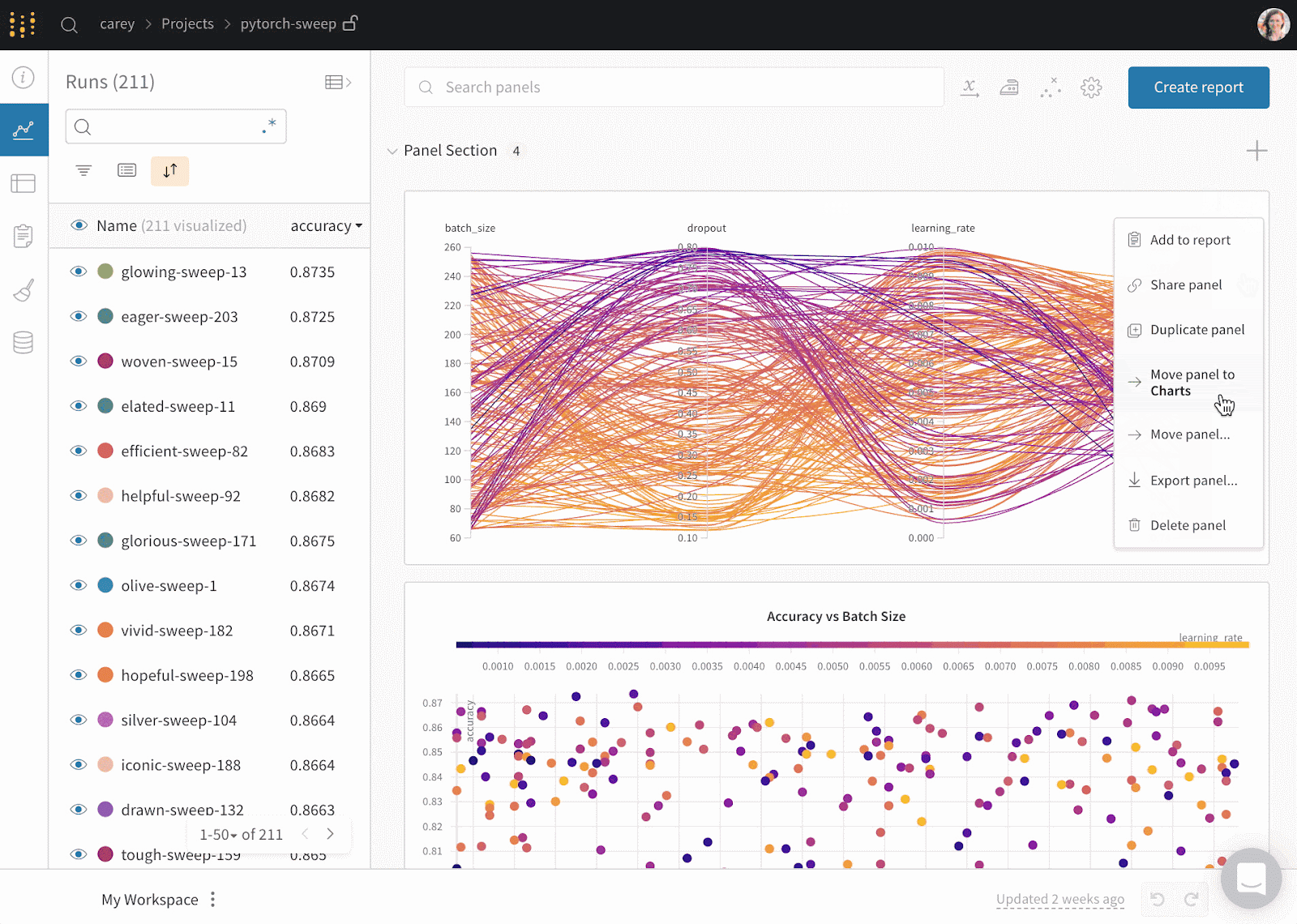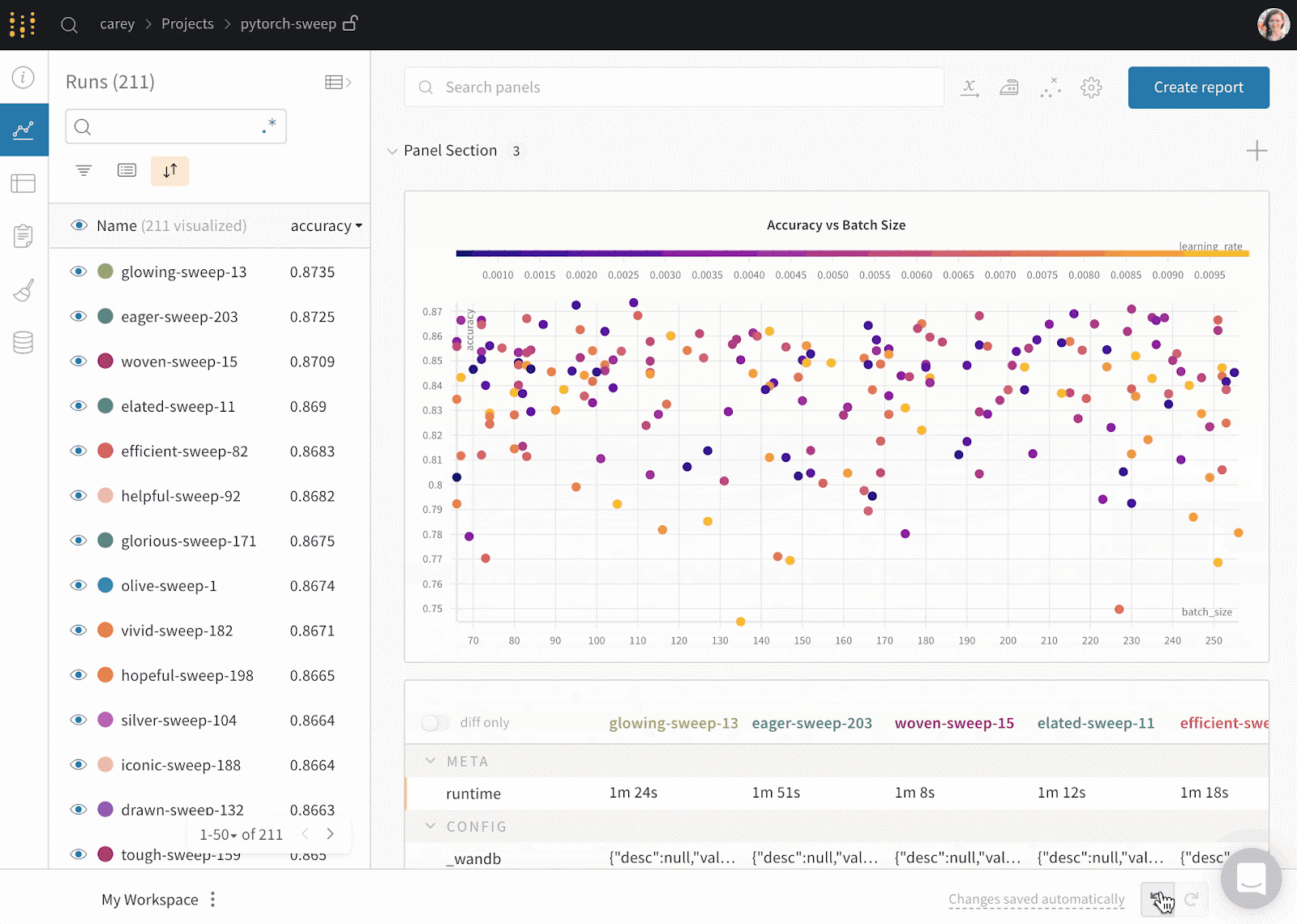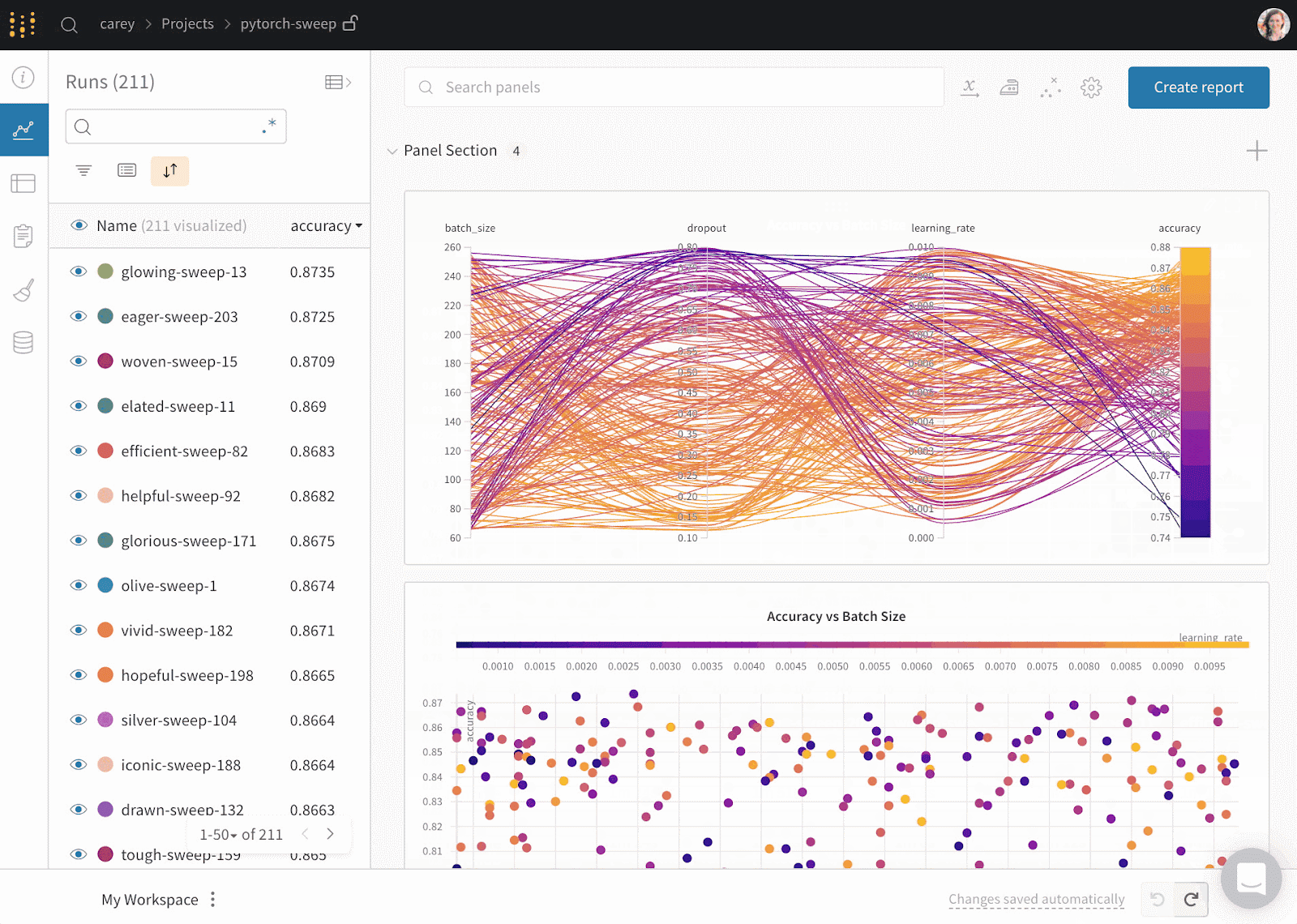
Gif von Weights & Biases
Hinweis: Du kannst auch TensorBoard, Pachyderm, DagsHub und DVC Studio für die Verfolgung von Experimenten und die Verwaltung von ML-Metadaten verwenden.
Diese Tools helfen dir, Data-Science-Projekte zu erstellen und Workflows für maschinelles Lernen zu verwalten:
Prefect ist ein moderner Datenstack für die Überwachung, Koordination und Orchestrierung von Arbeitsabläufen zwischen und über Anwendungen hinweg. Es ist ein leichtgewichtiges Open-Source-Tool, das für End-to-End-Pipelines für maschinelles Lernen entwickelt wurde.
Du kannst entweder Prefect Orion UI oder Prefect Cloud für die Datenbanken verwenden.
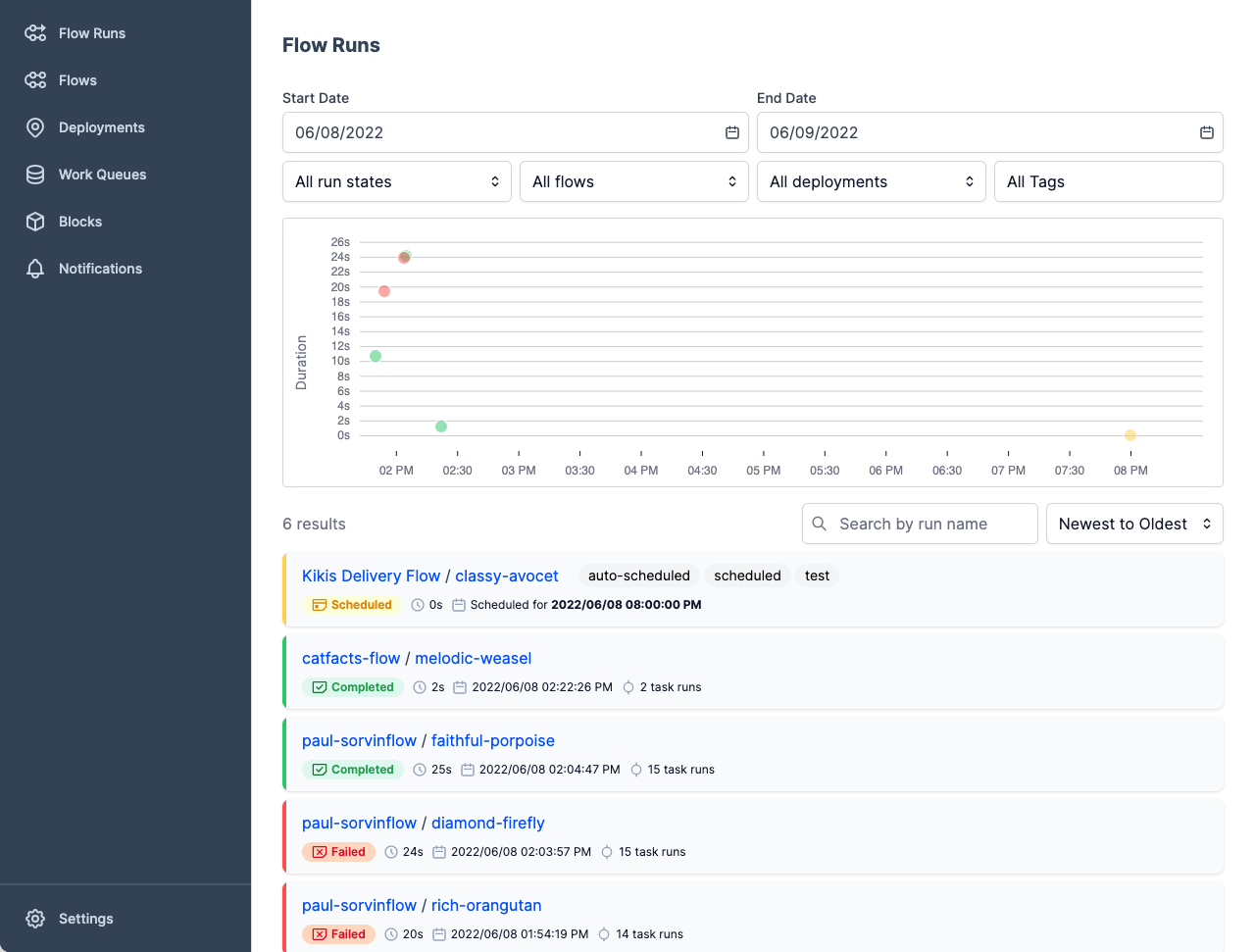
Bild von Prefect
Metaflow ist ein leistungsstarkes, kampferprobtes Workflow-Management-Tool für Data Science- und Machine Learning-Projekte. Es wurde für Datenwissenschaftler entwickelt, damit sie sich auf die Erstellung von Modellen konzentrieren können, anstatt sich um die MLOps-Technik zu kümmern.
Mit Metaflow kannst du Arbeitsabläufe entwerfen, sie im Maßstab ausführen und das Modell in der Produktion einsetzen. Es verfolgt und versioniert Experimente und Daten zum maschinellen Lernen automatisch. Außerdem kannst du die Ergebnisse im Notizbuch visualisieren.
Metaflow arbeitet mit mehreren Clouds (einschließlich AWS, GCP und Azure) und verschiedenen Python-Paketen für maschinelles Lernen (wie Scikit-learn und Tensorflow) zusammen, und die API ist auch für die Sprache R verfügbar.
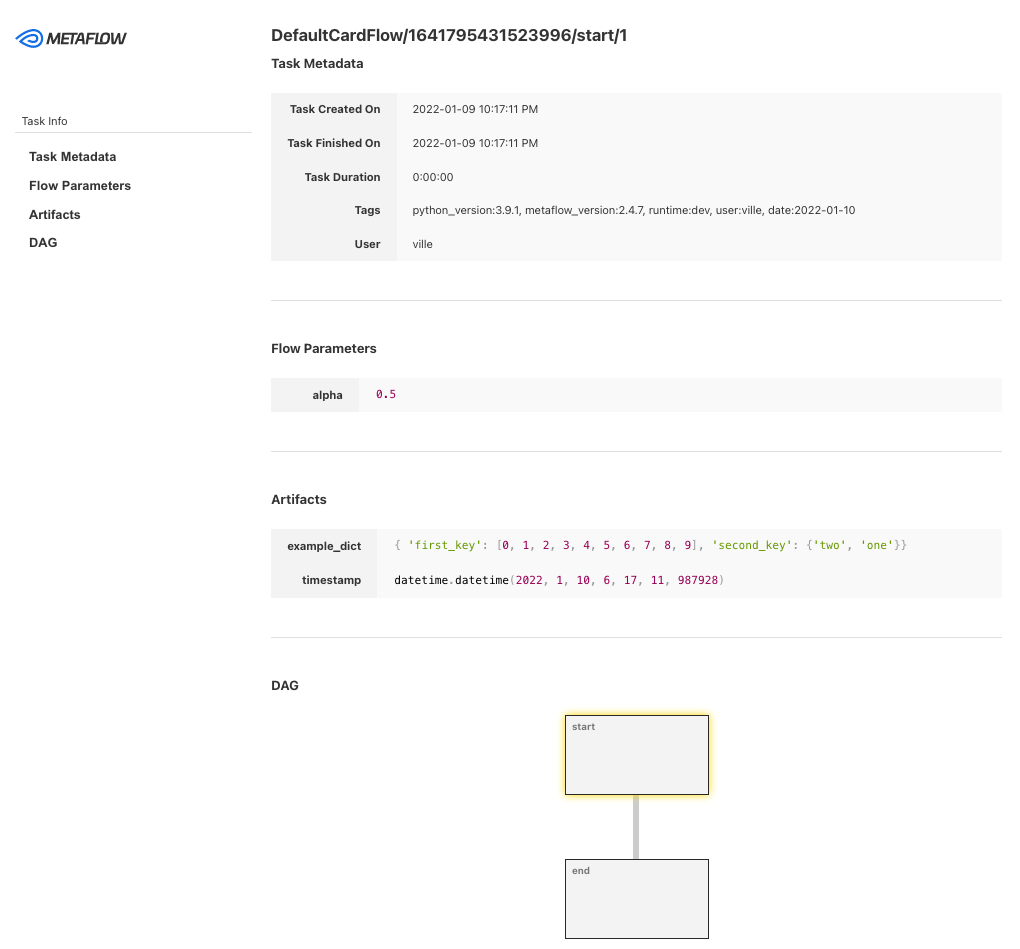
Bild von Metaflow
Kedro ist ein auf Python basierendes Tool zur Workflow-Orchestrierung. Du kannst damit reproduzierbare, wartbare und modulare Data-Science-Projekte erstellen. Es integriert Konzepte aus dem Software-Engineering in das maschinelle Lernen, wie z.B. Modularität, Trennung von Belangen und Versionierung.
Mit Kedro kannst du:
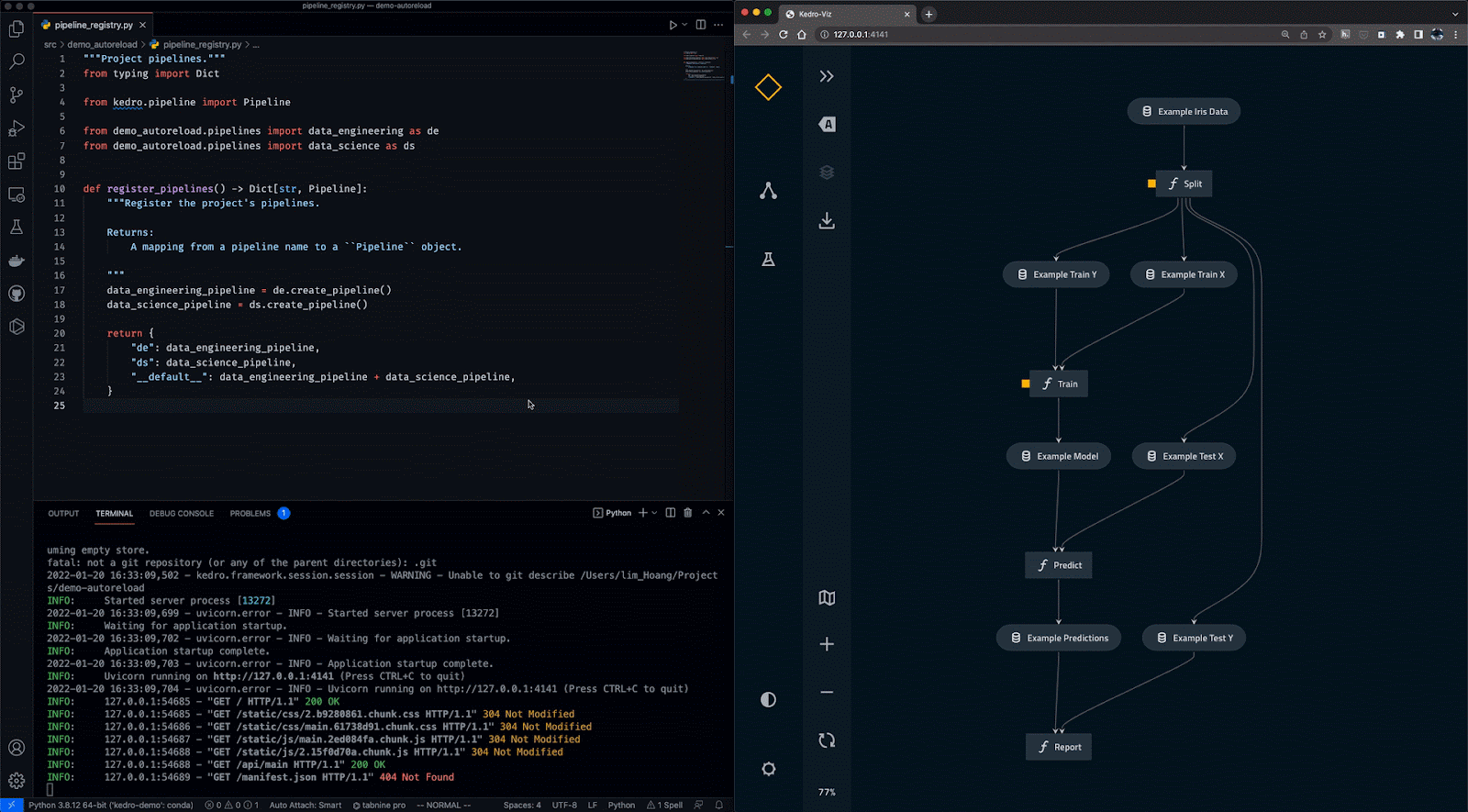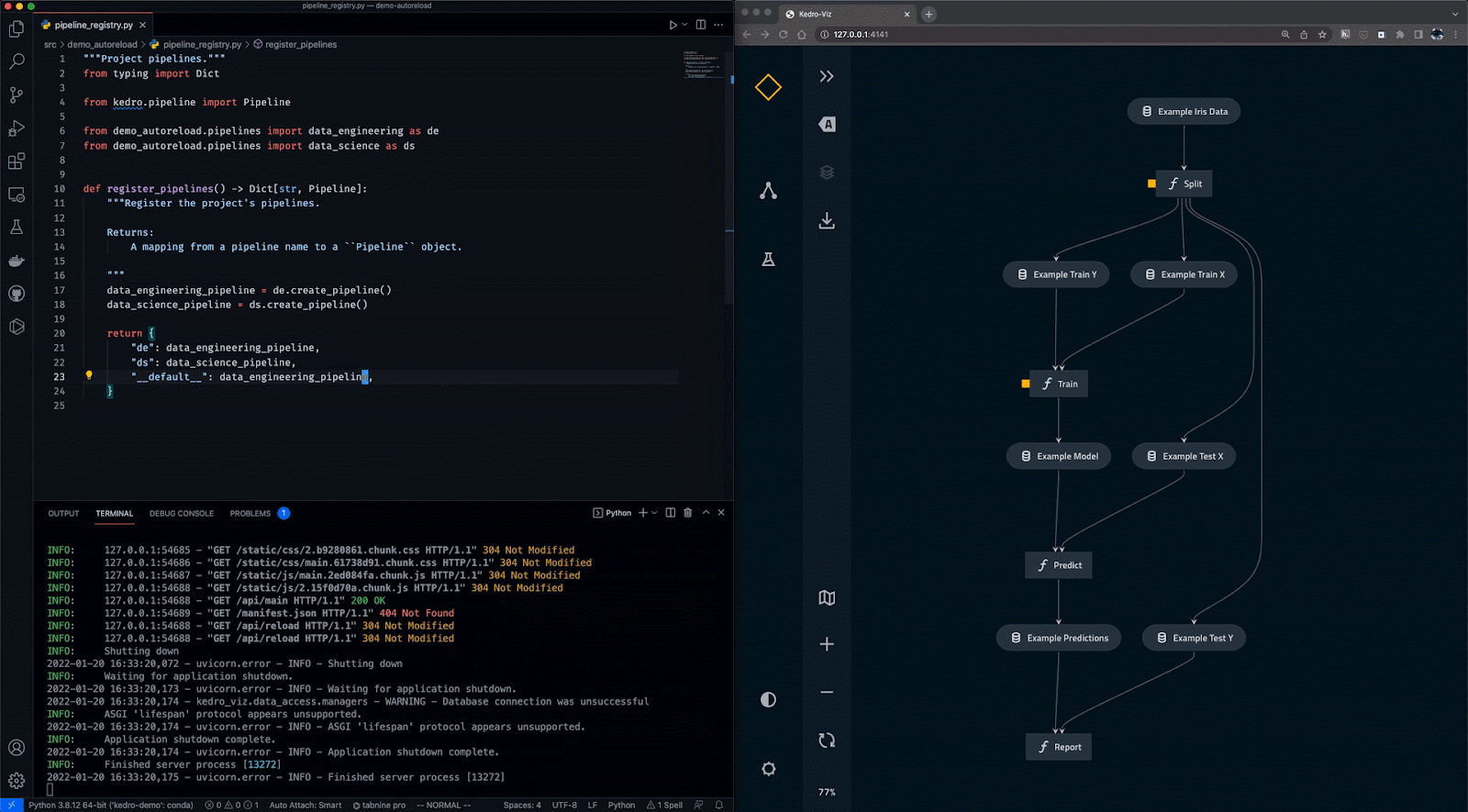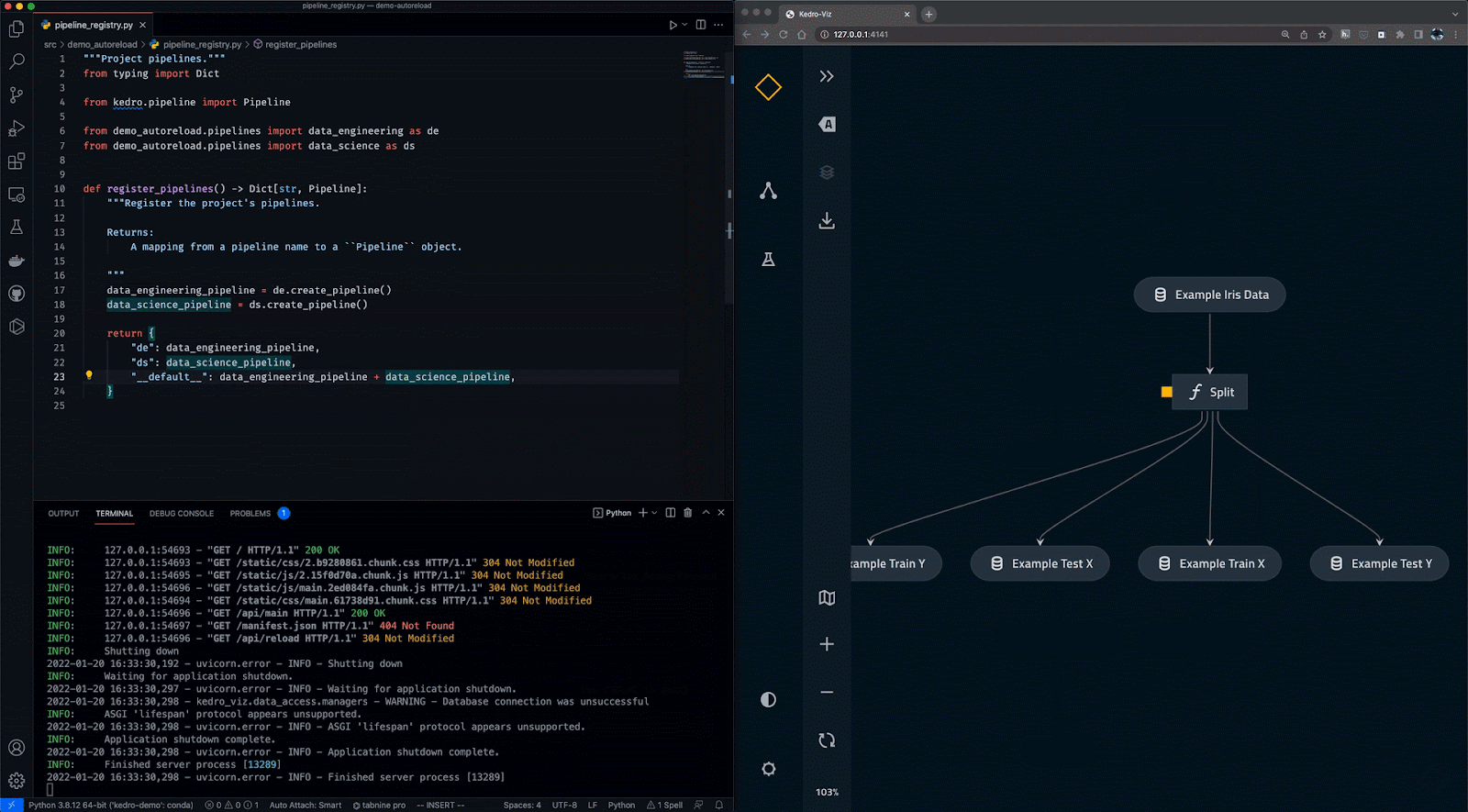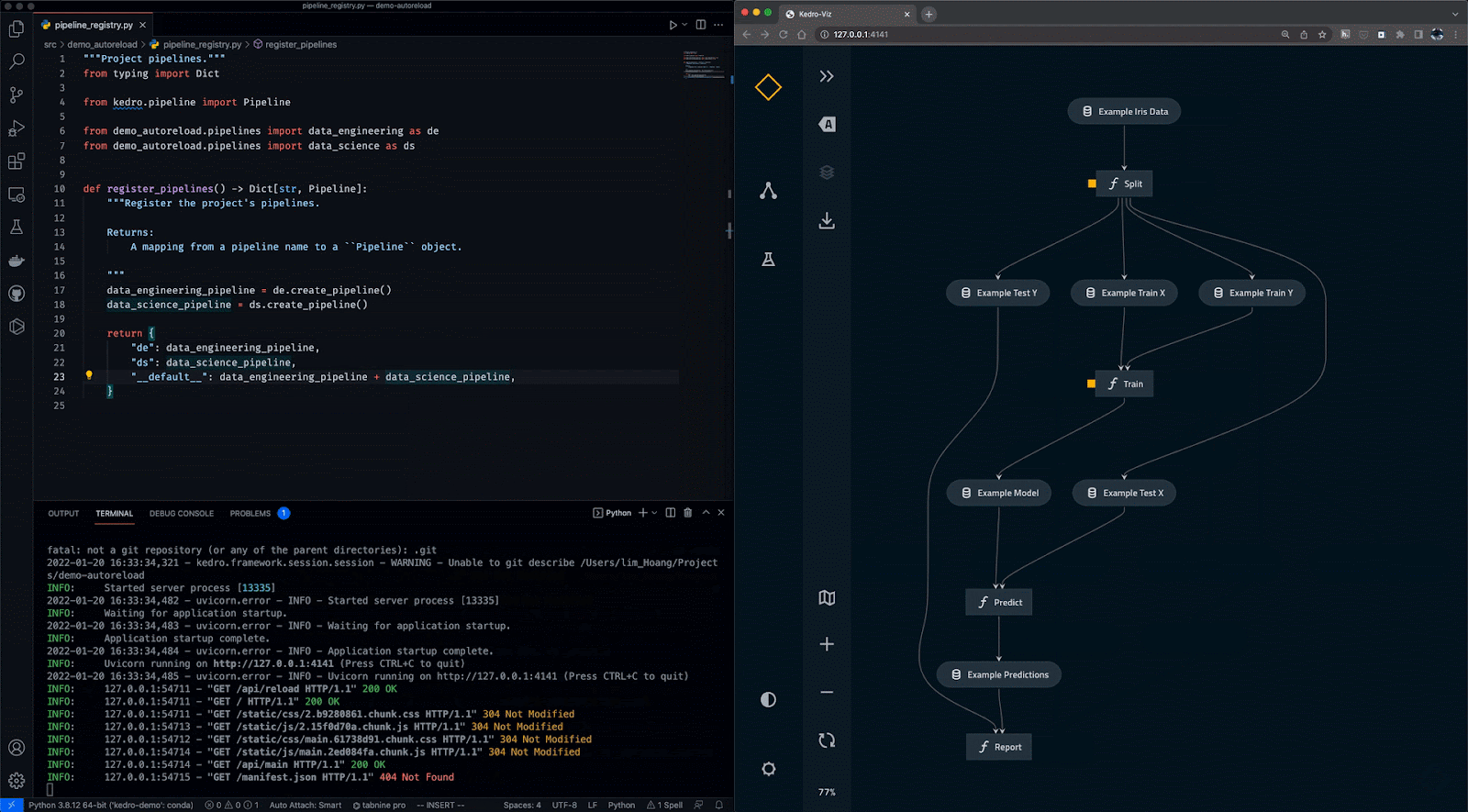
Gif von Kedro
Hinweis: Du kannst auch Kubeflow und DVC für Orchestrierung und Workflow-Pipelines verwenden.
Mit diesen MLOps-Tools kannst du Aufgaben rund um die Versionierung von Daten und Pipelines verwalten:
Pachyderm automatisiert die Datenumwandlung mit Datenversionierung, Lineage und End-to-End-Pipelines auf Kubernetes. Du kannst jede Art von Daten (Bilder, Protokolle, Videos, CSVs), jede Sprache (Python, R, SQL, C/C++) und jede Größenordnung (Petabytes an Daten, Tausende von Jobs) integrieren.
Die Community Edition ist Open-Source und für ein kleines Team. Organisationen und Teams, die erweiterte Funktionen wünschen, können sich für die Enterprise Edition entscheiden.
Genau wie bei Git kannst du deine Daten mit einer ähnlichen Syntax versionieren. In Pachyderm ist die höchste Ebene des Objekts Repository, und du kannst Commit, Branches, File, History und Provenance verwenden, um den Lernpfad und die Version des Datensatzes zu verfolgen.
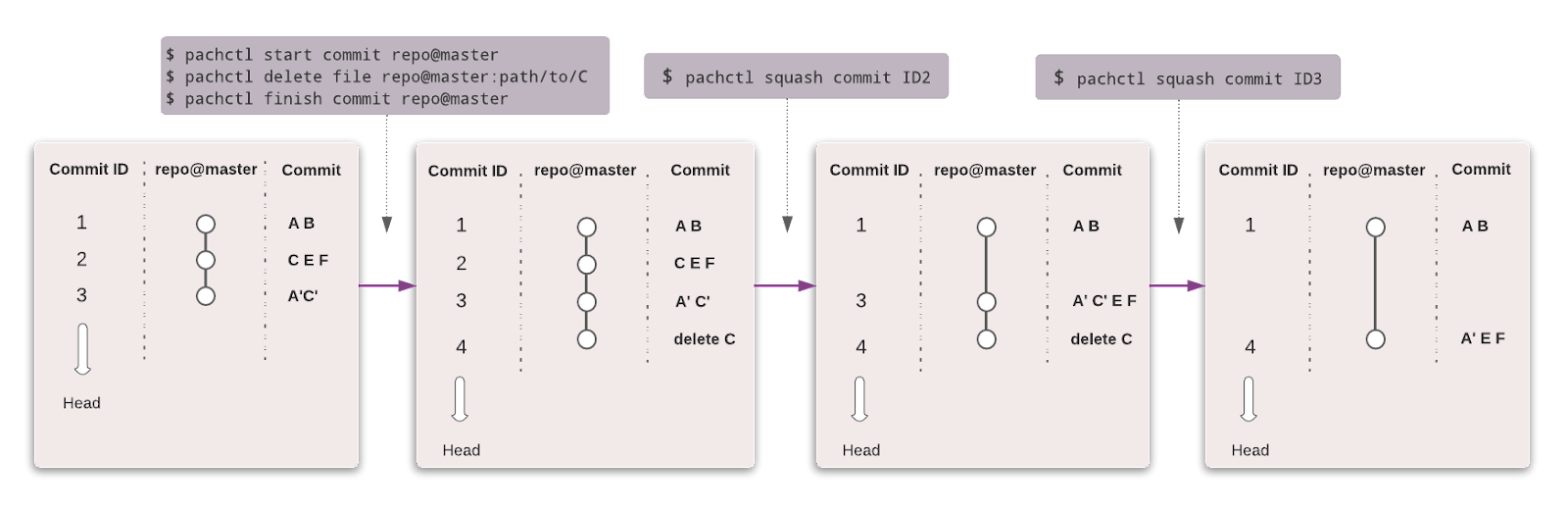
Bild von Pachyderm
Data Version Control ist ein beliebtes Open-Source-Tool für Machine-Learning-Projekte. Es arbeitet nahtlos mit Git zusammen und ermöglicht dir die Versionierung von Code, Daten, Modellen, Metadaten und Pipelines.
DVC ist mehr als nur ein Lernpfad und ein Tool zur Versionskontrolle.
Du kannst es verwenden für:
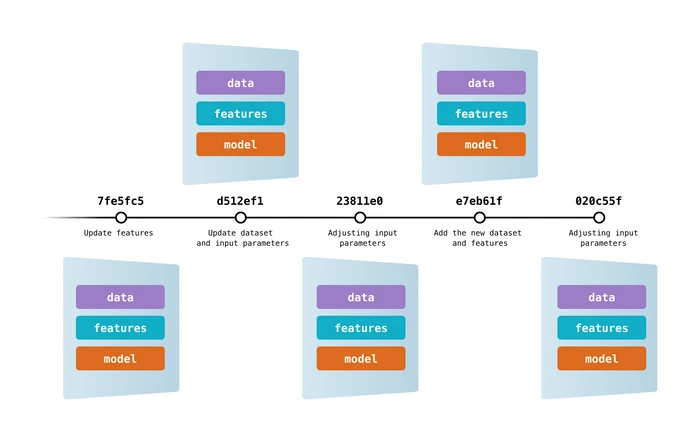
Bild von DVC
Hinweis: DagsHub kann auch für die Versionierung von Daten und Pipelines verwendet werden.
LakeFS ist ein Open-Source-Tool für die skalierbare Versionskontrolle von Daten, das eine Git-ähnliche Versionskontrollschnittstelle für Objektspeicher bietet und es den Nutzern ermöglicht, ihre Data Lakes wie ihren Code zu verwalten. LakeFS ermöglicht die Versionskontrolle von Daten im Exabyte-Bereich und ist damit eine hochskalierbare Lösung für die Verwaltung großer Data Lakes.
Zusätzliche Fähigkeiten:
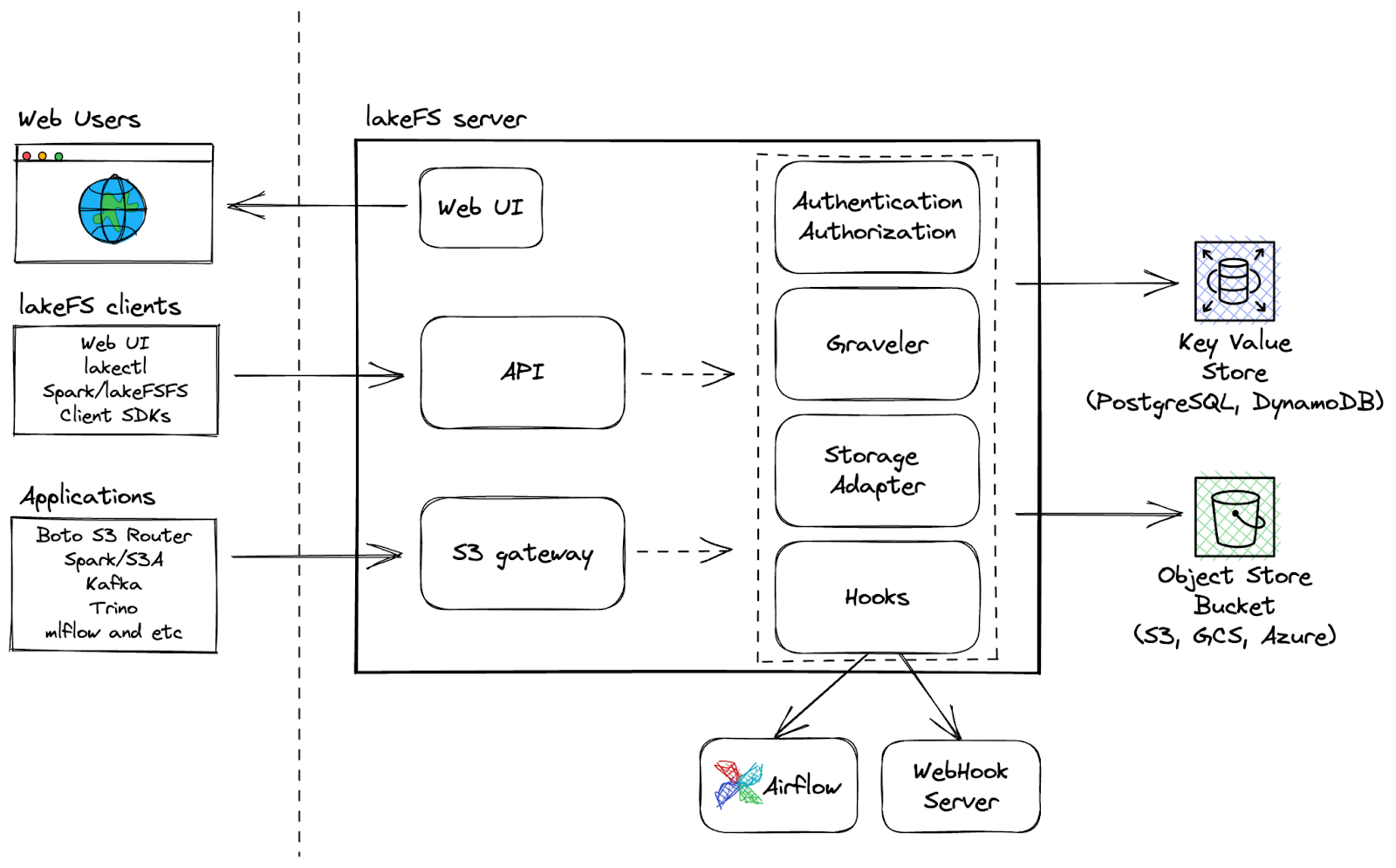
LakeFS Architektur
Feature-Stores sind zentrale Repositories zum Speichern, Versionieren, Verwalten und Bereitstellen von Features (verarbeitete Datenattribute, die für das Training von Machine-Learning-Modellen verwendet werden) für Machine-Learning-Modelle in der Produktion und für Trainingszwecke.
Feast ist ein Open-Source-Feature-Store, der Teams für maschinelles Lernen dabei hilft, Echtzeitmodelle zu produzieren und eine Feature-Plattform aufzubauen, die die Zusammenarbeit zwischen Ingenieuren und Datenwissenschaftlern fördert.
Wichtige Merkmale:
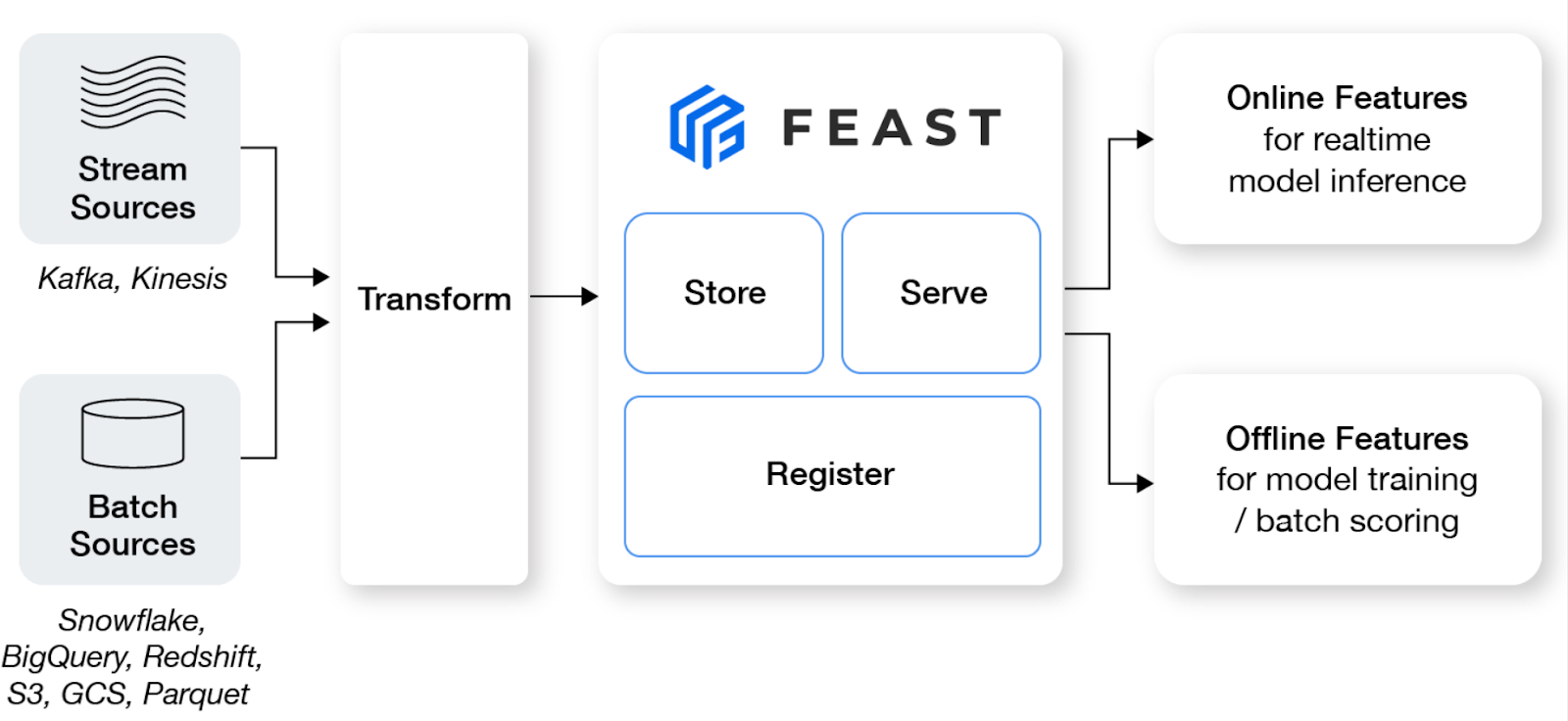
Bild von Feast
Featureform ist ein virtueller Funktionsspeicher, mit dem Datenwissenschaftler die Funktionen ihrer ML-Modelle definieren, verwalten und bereitstellen können. Sie kann Data-Science-Teams dabei helfen, die Zusammenarbeit zu verbessern, Experimente zu organisieren, die Bereitstellung zu erleichtern, die Zuverlässigkeit zu erhöhen und die Compliance zu wahren.
Wichtige Merkmale:
Bild von Featureform
Mit diesen MLOps-Tools kannst du die Modellqualität testen und die Zuverlässigkeit, Robustheit und Genauigkeit von Machine Learning-Modellen sicherstellen:
Deepchecks ist eine Open-Source-Lösung, die alle deine ML-Validierungsanforderungen erfüllt und sicherstellt, dass deine Daten und Modelle von der Forschung bis zur Produktion gründlich getestet werden. Es bietet einen ganzheitlichen Ansatz zur Validierung deiner Daten und Modelle durch seine verschiedenen Komponenten.
Bild von Deepchecks
Deepchecks bestehen aus drei Komponenten:
TruEra ist eine fortschrittliche Plattform, die die Modellqualität und -leistung durch automatisierte Tests, Erklärbarkeit und Ursachenanalyse verbessert. Es bietet verschiedene Funktionen, um Modelle zu optimieren und zu debuggen, eine erstklassige Erklärbarkeit zu erreichen und sich einfach in deinen ML-Tech-Stack zu integrieren.
Wichtige Merkmale:
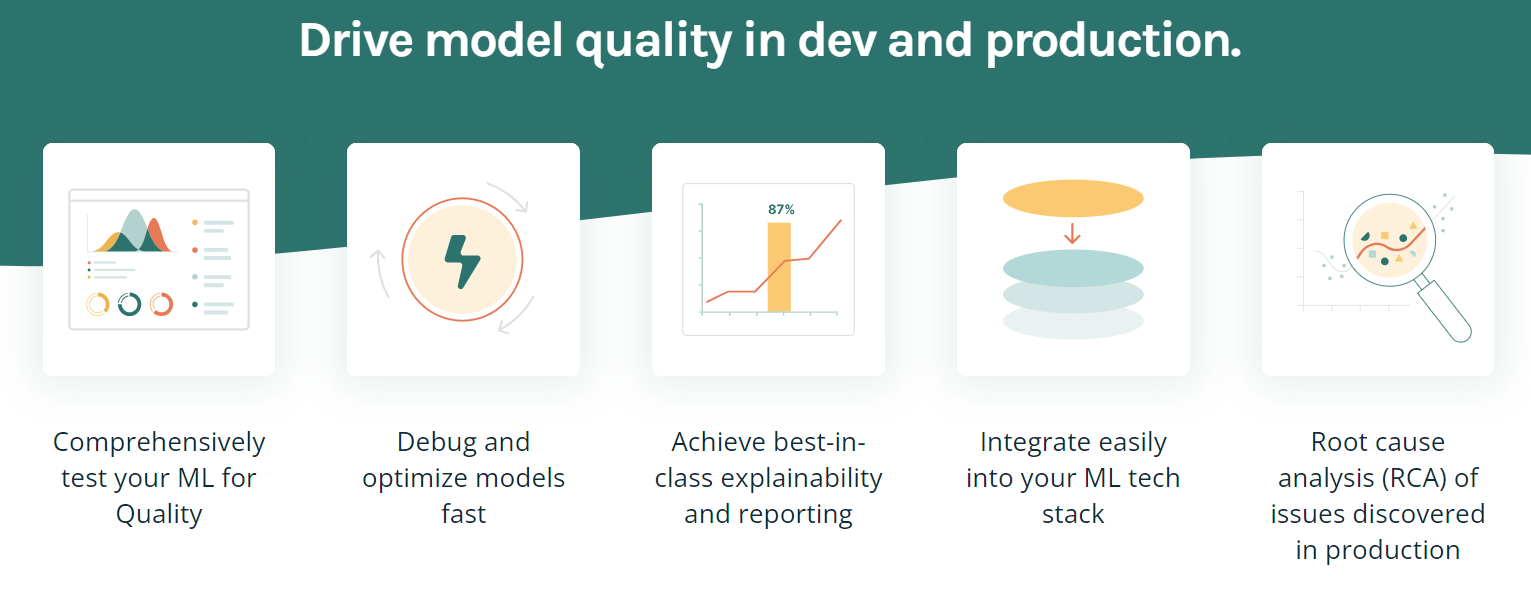
Bild von TruEra
Wenn es um den Einsatz von Modellen geht, können diese MLOps-Tools eine große Hilfe sein:
Kubeflow macht die Bereitstellung von Machine Learning-Modellen auf Kubernetes einfach, portabel und skalierbar. Du kannst es für die Datenaufbereitung, das Modelltraining, die Modelloptimierung, das Prediction Serving und den Motor der Modellleistung in der Produktion verwenden. Du kannst Machine Learning Workflows lokal, vor Ort oder in der Cloud einsetzen. Kurz gesagt, es macht Kubernetes für Data Science Teams einfach.
Wichtige Merkmale:
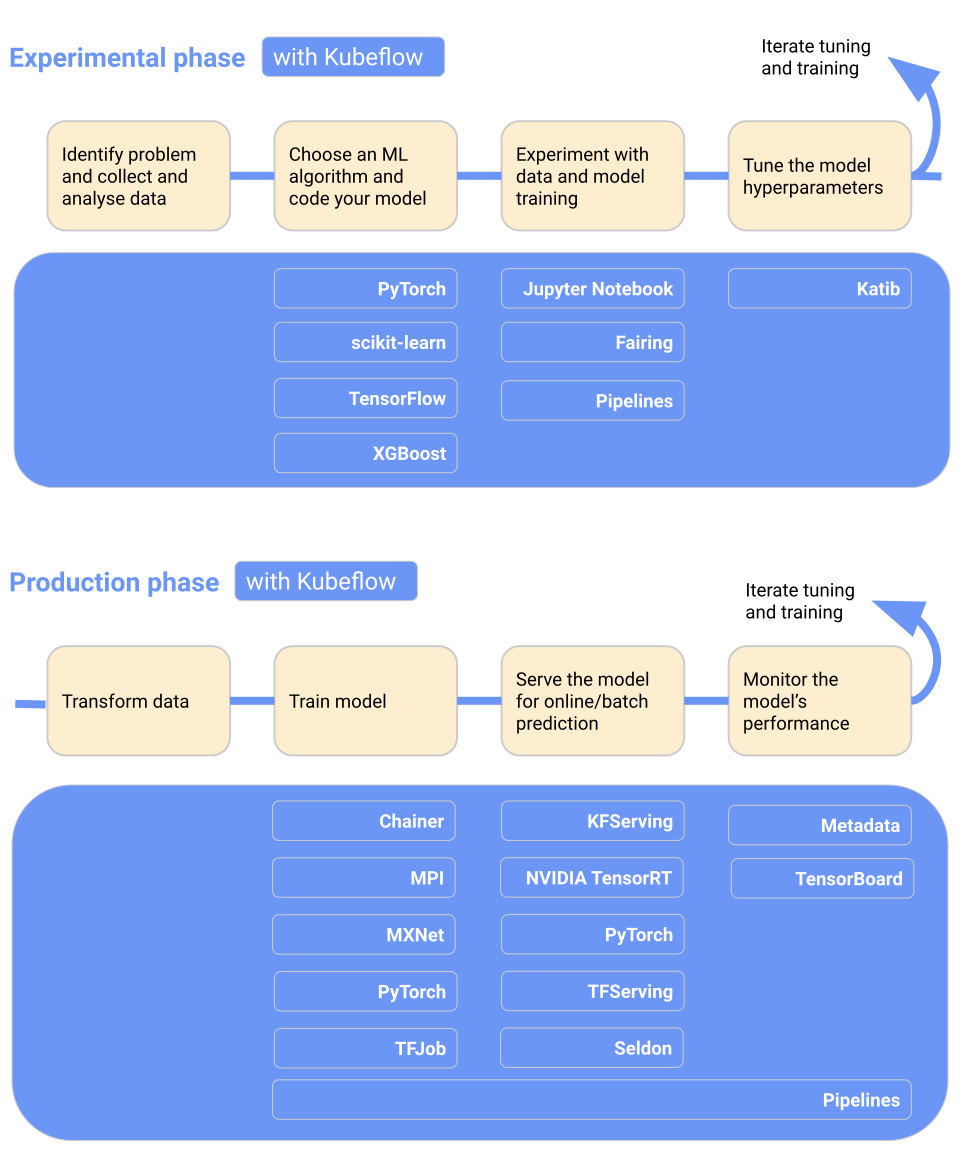
Bild von Kubeflow
BentoML macht es einfach und schneller, Anwendungen für maschinelles Lernen bereitzustellen. Es ist ein Python-basiertes Werkzeug für die Bereitstellung und Pflege von APIs in der Produktion. Sie skaliert mit leistungsstarken Optimierungen durch parallele Inferenz und adaptives Batching und bietet Hardware-Beschleunigung.
Das interaktive, zentrale Dashboard von BentoML erleichtert die Organisation und Überwachung des Einsatzes von Machine Learning-Modellen. Das Beste daran ist, dass es mit allen Arten von Frameworks für maschinelles Lernen funktioniert, wie Keras, ONNX, LightGBM, Pytorch und Scikit-learn. Kurz gesagt: BentoML bietet eine Komplettlösung für die Bereitstellung, das Servicing und die Überwachung von Modellen.
Bild von BentoML
Hugging Face Inference Endpoints ist ein Cloud-basierter Service von Hugging Face, einer All-in-One ML-Plattform, die es Nutzern ermöglicht, Modelle, Datensätze und Demos zu trainieren, zu hosten und zu teilen. Diese Endpunkte sollen den Nutzern helfen, ihre trainierten Machine-Learning-Modelle für Inferenzen einzusetzen, ohne dass sie die erforderliche Infrastruktur einrichten und verwalten müssen.
Wichtige Merkmale:
Bild von Hugging Face
Hinweis: Du kannst auch MLflow und AWS Sagemaker für die Modellbereitstellung und das Serving verwenden.
Egal, ob sich dein ML-Modell in der Entwicklung, in der Validierung oder in der Produktion befindet, mit diesen Tools kannst du eine Reihe von Faktoren überwachen:
Evidently AI ist eine quelloffene Python-Bibliothek zur Überwachung von ML-Modellen während der Entwicklung, Validierung und in der Produktion. Sie prüft die Daten- und Modellqualität, die Datendrift, die Zieldrift sowie die Regressions- und Klassifizierungsleistung.
Offensichtlich gibt es drei Hauptkomponenten:
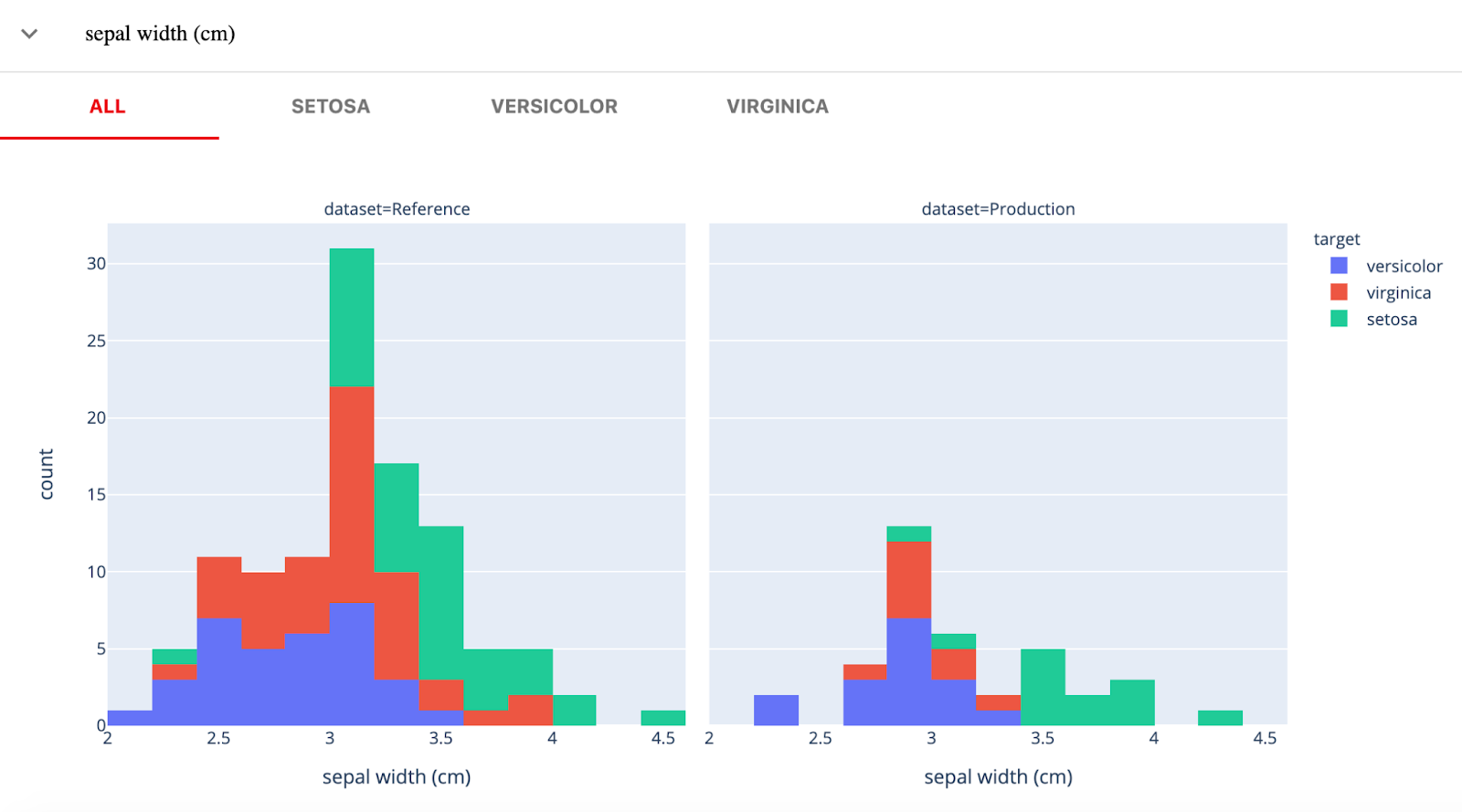
Bild von Evidently
Fiddler AI ist ein ML-Modell-Überwachungstool mit einer einfach zu bedienenden, übersichtlichen Benutzeroberfläche. Damit kannst du Vorhersagen erklären und debuggen, das Verhalten der Modi für den gesamten Datensatz analysieren, Modelle für maschinelles Lernen in großem Umfang einsetzen und die Modellleistung überwachen.
Sehen wir uns die wichtigsten KI-Funktionen von Fiddler für die ML-Überwachung an:
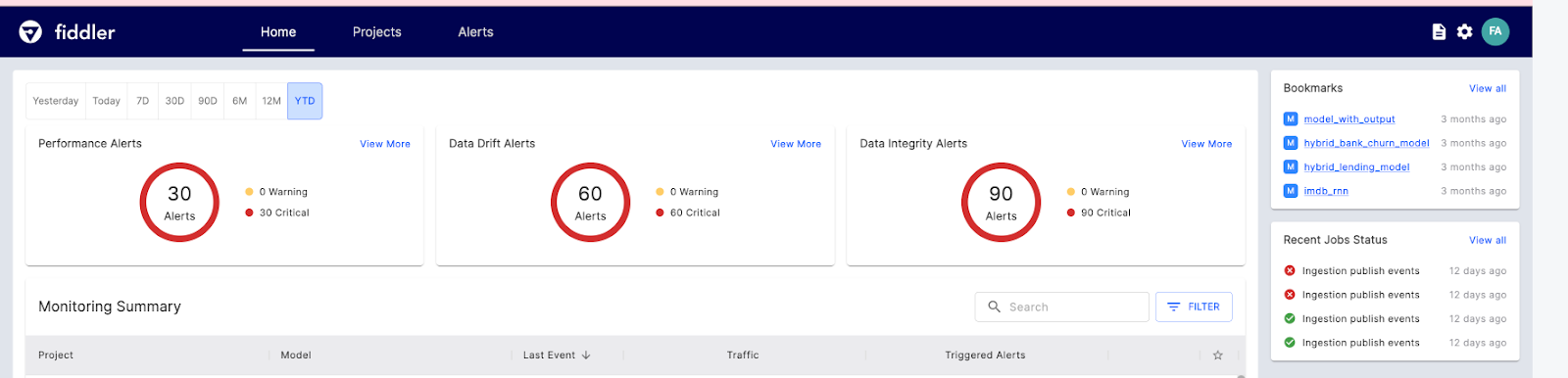
Bild aus Fiddler
Die Runtime Engine ist für das Laden des Modells, die Vorverarbeitung der Eingabedaten, die Durchführung der Inferenz und die Rückgabe der Ergebnisse an die Client-Anwendung verantwortlich.
Ray ist ein vielseitiges Framework zur Skalierung von KI- und Python-Anwendungen, das es Entwicklern erleichtert, ihre Machine-Learning-Projekte zu verwalten und zu optimieren.
Die Plattform besteht aus zwei Hauptkomponenten: einer verteilten Kernlaufzeit und einer Reihe von KI-Bibliotheken, die auf die Vereinfachung von ML-Berechnungen zugeschnitten sind.
Ray Core bietet eine begrenzte Anzahl grundlegender Elemente, die für den Aufbau und die Erweiterung verteilter Anwendungen genutzt werden können.
Ray bietet außerdem KI-Bibliotheken für skalierbare Datensätze für ML, verteiltes Training, Hyperparameter-Tuning, Reinforcement Learning und skalierbares und programmierbares Serving.
Das folgende Beispiel zeigt das Training und den Einsatz eines Gradient Boosting Classifier-Modells.
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")Nuclio ist ein leistungsstarkes Framework, das sich auf daten-, I/O- und rechenintensive Workloads konzentriert. Sie ist so konzipiert, dass sie serverlos ist, d.h. du musst dich nicht um die Verwaltung von Servern kümmern. Nuclio ist gut in beliebte Data-Science-Tools wie Jupyter und Kubeflow integriert. Es unterstützt außerdem eine Vielzahl von Daten- und Streaming-Quellen und kann über CPUs und GPUs ausgeführt werden.
Wichtige Merkmale:
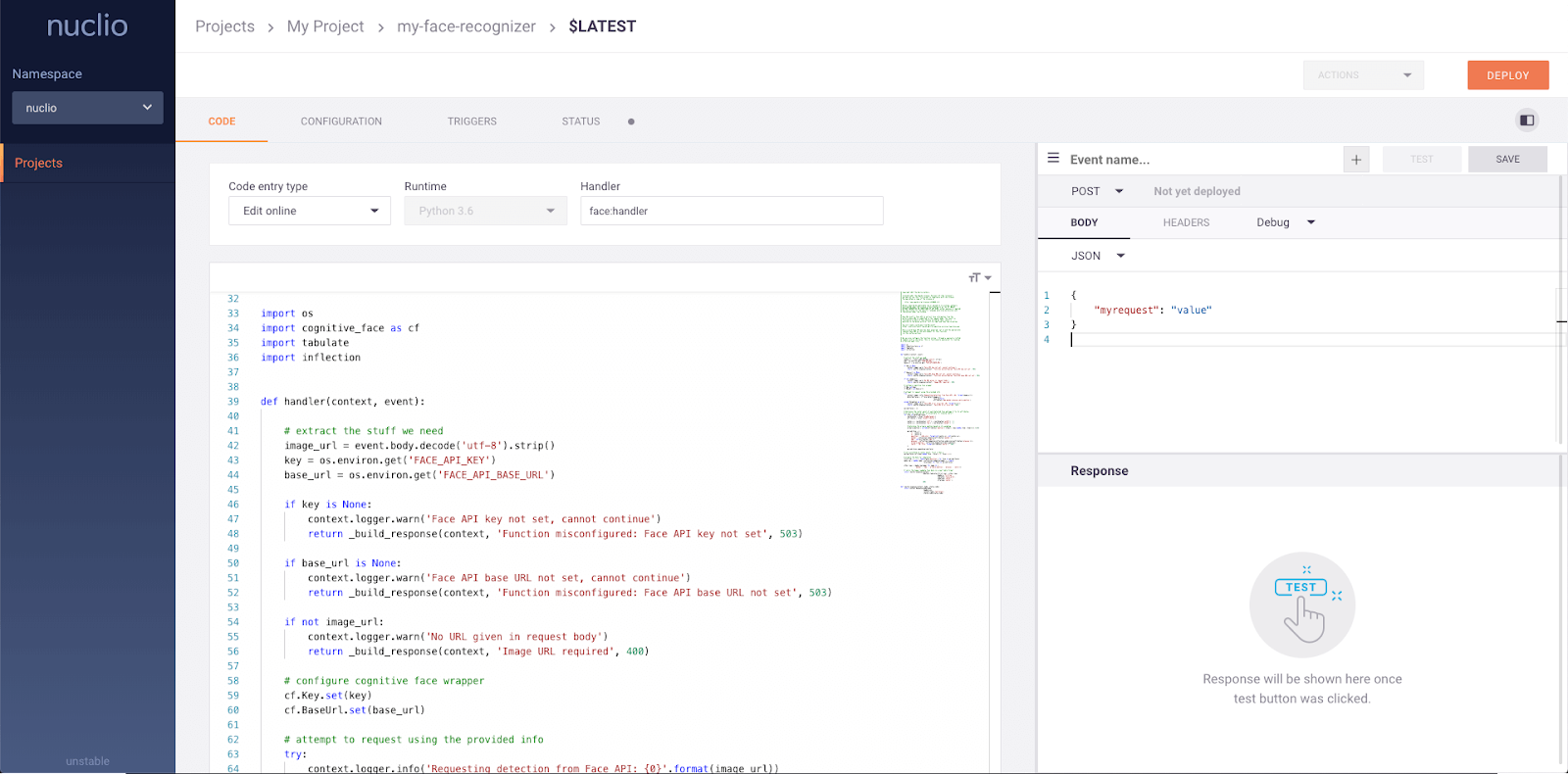
Bild von Nuclio
Wenn du auf der Suche nach einem umfassenden MLOps-Tool bist, das dich während des gesamten Prozesses unterstützt, findest du hier einige der besten:
Amazon Web Services SageMaker ist eine One-Stop-Lösung für MLOps. Du kannst die Modellentwicklung trainieren und beschleunigen, Experimente nachverfolgen und versionieren, ML-Artefakte katalogisieren, CI/CD-ML-Pipelines integrieren und Modelle nahtlos in der Produktion einsetzen, bedienen und überwachen.
Wichtige Merkmale:
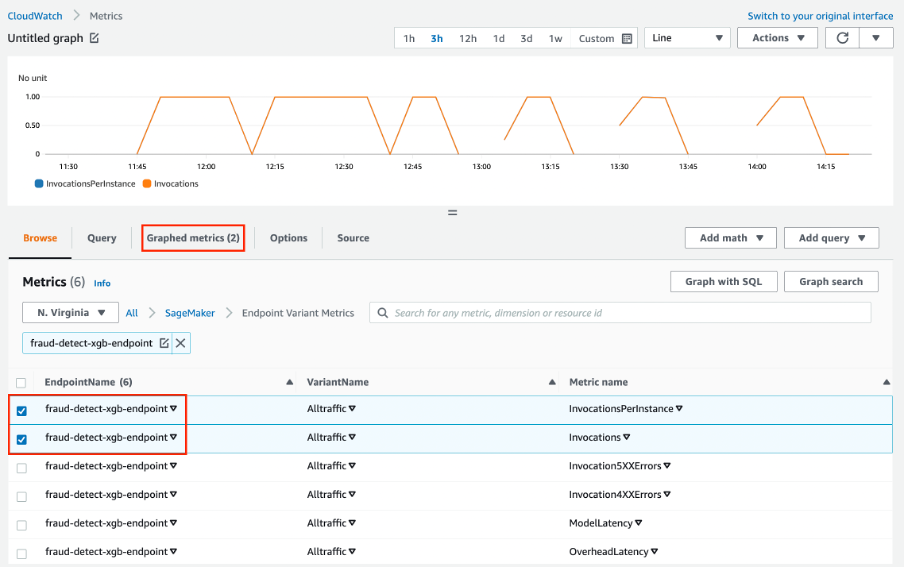
Bild von Amazon SageMaker
DagsHub ist eine Plattform für die Machine-Learning-Community, um Daten, Modelle, Experimente, ML-Pipelines und Code zu verfolgen und zu versionieren. Es ermöglicht deinem Team, Machine-Learning-Projekte zu erstellen, zu überprüfen und zu teilen.
Einfach ausgedrückt ist es ein GitHub für maschinelles Lernen, und du bekommst verschiedene Tools, um den gesamten maschinellen Lernprozess zu optimieren.
Wichtige Merkmale:
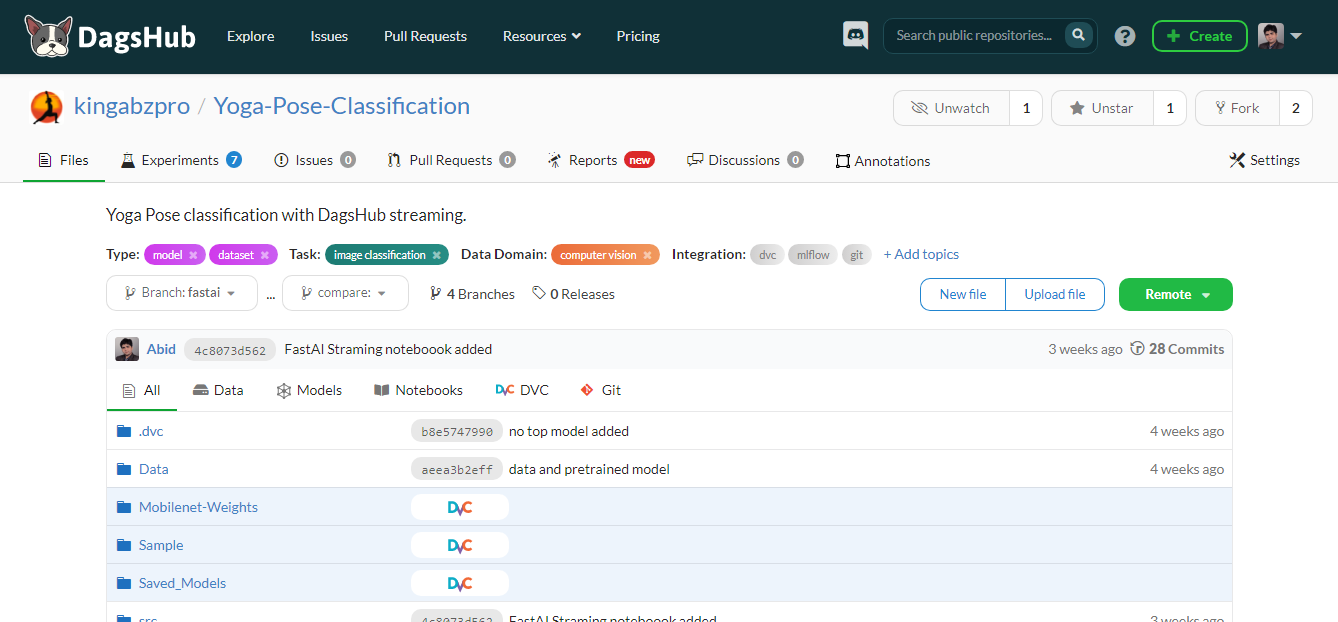
Bild vom Autor
Die Iguazio MLOps-Plattform ist eine End-to-End-MLOps-Plattform, die es Unternehmen ermöglicht, die maschinelle Lernpipeline von der Datenerfassung und -aufbereitung bis hin zum Training, Einsatz und der Überwachung in der Produktion zu automatisieren. Es bietet eine offene(MLRun) und verwaltete Plattform.
Ein wesentliches Unterscheidungsmerkmal der Iguazio MLOps-Plattform ist ihre Flexibilität bei den Einsatzoptionen. Nutzer können KI-Anwendungen überall einsetzen, auch in Cloud-, Hybrid- oder On-Premises-Umgebungen. Dies ist besonders wichtig für Branchen wie das Gesundheits- und Finanzwesen, in denen Datenschutzbedenken eine Bereitstellung vor Ort erforderlich machen können.
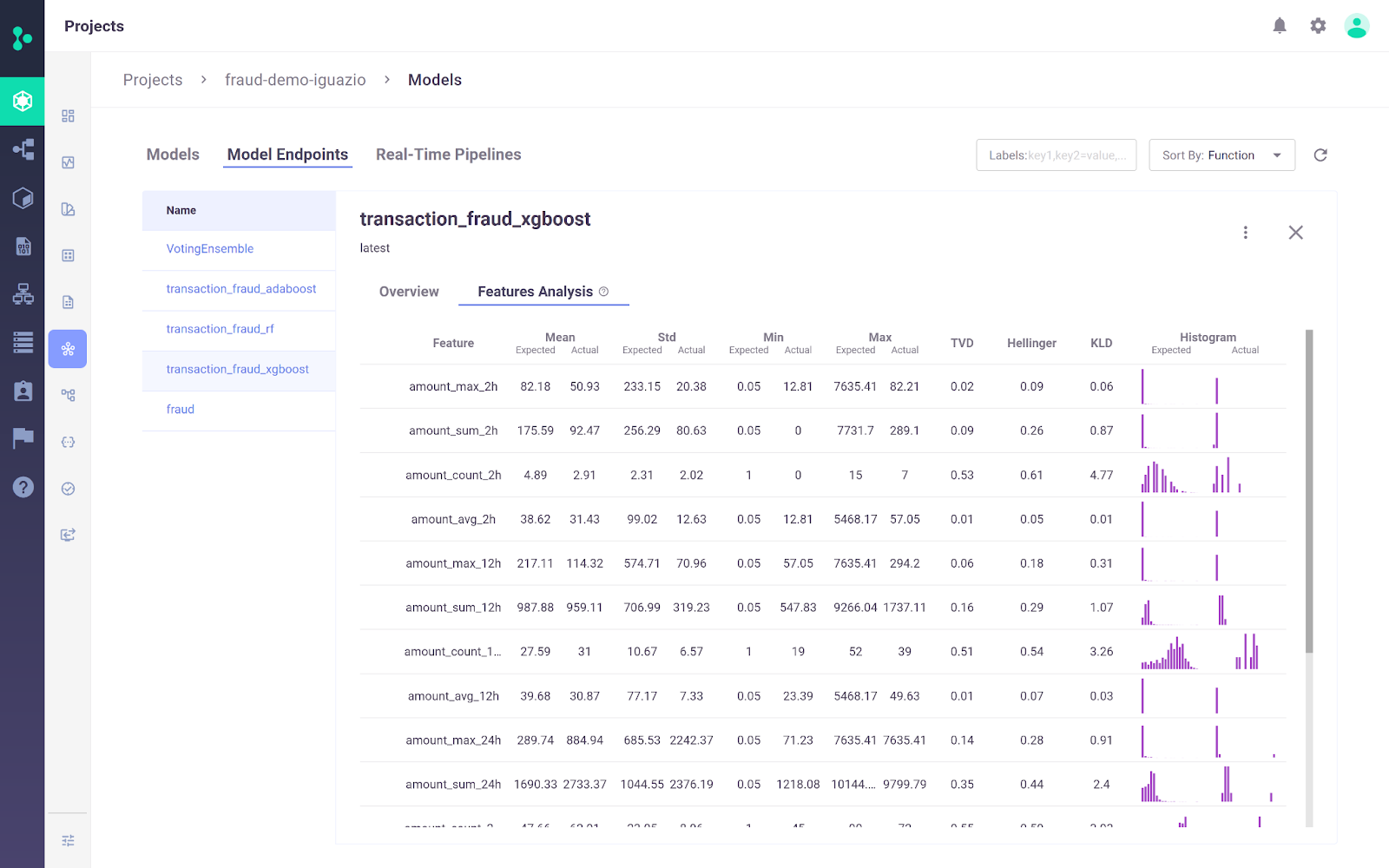
Bild von der Iguazio MLOps Plattform
Wichtige Merkmale:
Hier ist eine Vergleichstabelle, mit der du diese Tools Seite an Seite bewerten und dich für die besten für deine Projekte entscheiden kannst:
| Tool | Hauptfunktionalität | Unterstützte Frameworks | Optionen für den Einsatz |
|---|---|---|---|
| Qdrant | Vektorielle Ähnlichkeitssuche und Datenbankmanagement | Python, mehrere Sprachen | Cloud-nativ, horizontal skalierbar |
| LangChain | Anwendungen mit Sprachmodellen entwickeln | Python, JavaScript | REST API, Vorlagen |
| MLFlow | Lernpfad, Modellregistrierung, Einsatz | Python, R, Java, REST API | Lokal, Wolke |
| Comet ML | Lernpfad und Optimierung von Experimenten | Scikit-learn, PyTorch, TensorFlow, HuggingFace | Lokal, Wolke |
| Gewichte & Verzerrungen | Lernpfad, Daten- und Modellversionierung | Fastai, Keras, PyTorch, HuggingFace, Yolov5, Spacy | Lokal, Wolke |
| Präfekt | Workflow-Orchestrierung und -Überwachung | Python | Lokal (Orion UI), Cloud |
| Metaflow | Workflow Management für Data Science | Scikit-learn, TensorFlow, Python, R | AWS, GCP, Azure, lokal |
| Kedro | Workflow-Organisation, Reproduzierbarkeit | Python | Lokal, verteilt |
| Dickhäuter | Datenumwandlung, Versionierung und Abstammung | Jede Sprache | Kubernetes |
| DVC | Versionierung von Daten und Pipelines | Git, Python | Lokal, Wolke |
| LakeFS | Git-ähnliche Versionskontrolle für Data Lakes | Jeder Speicherdienst | Lokal, Wolke |
| Fest | Zentraler Merkmalspeicher für ML-Modelle | Python | Lokal, Wolke |
| Featureform | Virtueller Merkmalspeicher für ML-Modelle | Python | Lokal, Wolke |
| Deepchecks | ML-Modellprüfung und -Validierung | Python | Lokal, Wolke |
| TruEra | Modellqualität und Leistungstests | Python | Lokal, Wolke |
| Kubeflow | ML-Modellbereitstellung und -Orchestrierung | TensorFlow, PyTorch, PaddlePaddle, MXNet, XGboost | Kubernetes, cloud |
| BentoML | Modellbereitstellung und API-Verwaltung | Keras, ONNX, LightGBM, PyTorch, Scikit-learn | Lokal, Wolke |
| Hugging Face | Inferenz und Modellentwicklung | Jedes Modell | Cloud |
| Offensichtlich | Überwachung von ML-Modellen auf Daten- und Zielabweichungen | Python | Lokal, Wolke |
| Fiddler | ML-Modellüberwachung und Fehlerbehebung | Python | Lokal, Wolke |
| Ray | KI- und Python-Anwendungen skalieren | Python | Lokal, Wolke |
| Nuclio | Serverloses Framework für daten- und rechenintensive Workloads | Jupyter, Kubeflow | Cloud, vor Ort |
| AWS SageMaker | End-to-End-Management des ML-Lebenszyklus | Python, R, Java, TensorFlow, PyTorch | AWS-Wolke |
| DagsHub | Versionierung und Zusammenarbeit für ML-Projekte | Git, DVC, MLflow | Lokal, Wolke |
| Iguazio | End-to-End-Automatisierung von ML-Pipelines | Python, MLRun | Cloud, Hybrid, Vor-Ort |
Wir befinden uns in einer Zeit, in der die MLOps-Branche einen Boom erlebt. Jede Woche gibt es neue Entwicklungen, neue Startups und neue Tools, die das grundlegende Problem der Umwandlung von Notebooks in produktionsreife Anwendungen lösen sollen. Selbst bestehende Tools erweitern ihren Horizont und integrieren neue Funktionen, um zu Super-MLOps-Tools zu werden.
In diesem Blog haben wir die besten MLOps-Tools für verschiedene Schritte des MLOps-Prozesses kennengelernt. Diese Tools helfen dir bei der Erprobung, Entwicklung, Einführung und Überwachung.
Wenn du neu auf dem Gebiet des maschinellen Lernens bist und dir die wichtigsten Fähigkeiten aneignen willst, um einen Job als Machine Learning Scientist zu bekommen, solltest du unseren Lernpfad zum Machine Learning Scientist mit Python besuchen.
Wenn du ein Profi bist und mehr über die Standard-MLOps-Praktiken erfahren möchtest, lies unseren Artikel über die MLOps Best Practices und ihre Anwendung und schau dir unseren Lernpfad zu den MLOps-Grundlagen an.
In diesen Kursen erfährst du mehr über MLOps!
Kurs
Kurs
Kurs
Blog
Blog
Nisha Arya Ahmed
15 Min.
Blog
Hesam Sheikh Hassani
15 Min.
Tutorial
Matt Crabtree