
Courses
Các khái niệm về MLOps
2 giờ
43.7K
Với sự ra đời của GPT-4 và sau đó là GPT-4o, cuộc đua tạo ra các mô hình ngôn ngữ lớn và khai thác toàn bộ tiềm năng của AI hiện đại đã bắt đầu. LLM cần các cơ sở dữ liệu vector và khung tích hợp để xây dựng các ứng dụng AI thông minh.
Qdrant là công cụ tìm kiếm tương đồng vector và cơ sở dữ liệu vector mã nguồn mở, cung cấp dịch vụ sẵn sàng cho sản xuất với API thuận tiện, cho phép bạn lưu trữ, tìm kiếm và quản lý vector embedding.
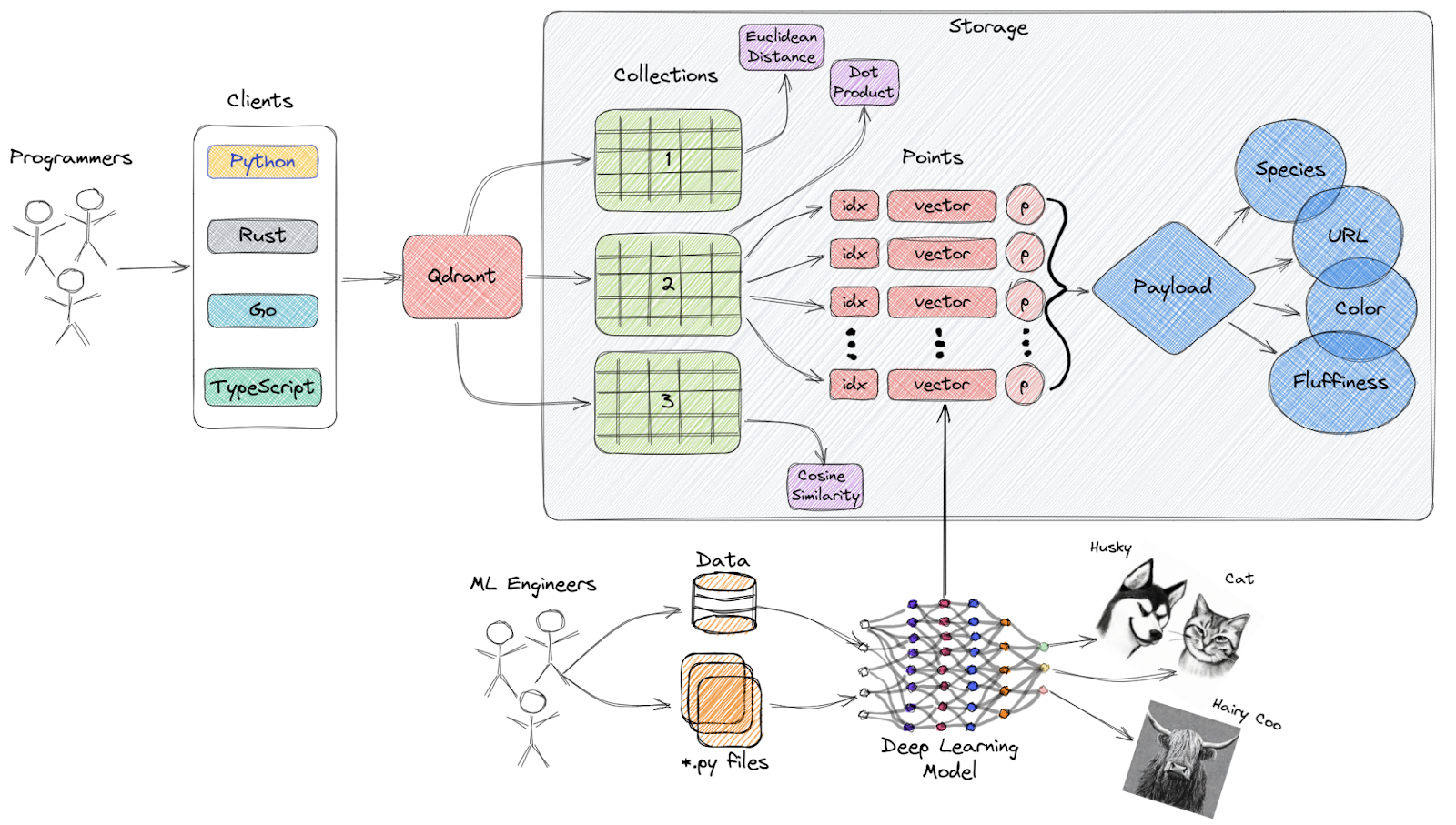
Tổng quan cấp cao về kiến trúc của Qdrant
Tính năng chính:
Khám phá các cơ sở dữ liệu vector hàng đầu qua bài viết 5 cơ sở dữ liệu vector tốt nhất | Danh sách kèm ví dụ.
LangChain là một framework linh hoạt và mạnh mẽ để phát triển các ứng dụng vận hành bởi mô hình ngôn ngữ. Nó cung cấp nhiều thành phần giúp nhà phát triển xây dựng, triển khai và giám sát các ứng dụng theo ngữ cảnh và dựa trên suy luận.
Framework gồm 4 thành phần chính:
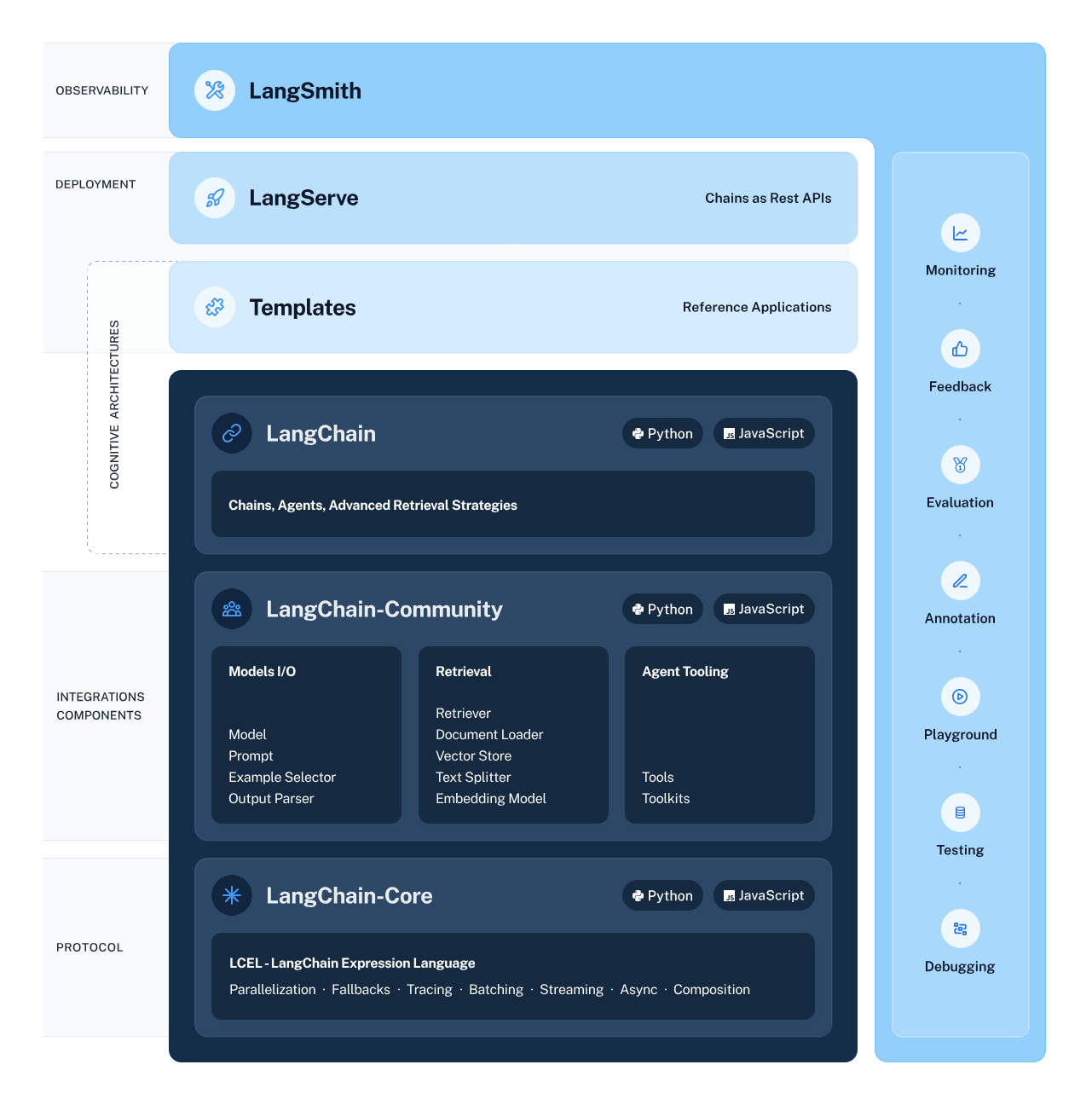
Hệ sinh thái LangChain
Tìm hiểu Cách xây dựng ứng dụng LLM với LangChain và khám phá tiềm năng còn bỏ ngỏ của các mô hình ngôn ngữ lớn.
Những công cụ này cho phép bạn quản lý siêu dữ liệu mô hình và hỗ trợ theo dõi thí nghiệm:
MLflow là công cụ mã nguồn mở giúp bạn quản lý các phần cốt lõi của vòng đời machine learning. Thường được dùng để theo dõi thí nghiệm, nhưng bạn cũng có thể dùng cho tái lập, triển khai và sổ đăng ký mô hình. Bạn có thể quản lý thí nghiệm machine learning và siêu dữ liệu mô hình bằng CLI, Python, R, Java và REST API.
MLflow có bốn chức năng cốt lõi:
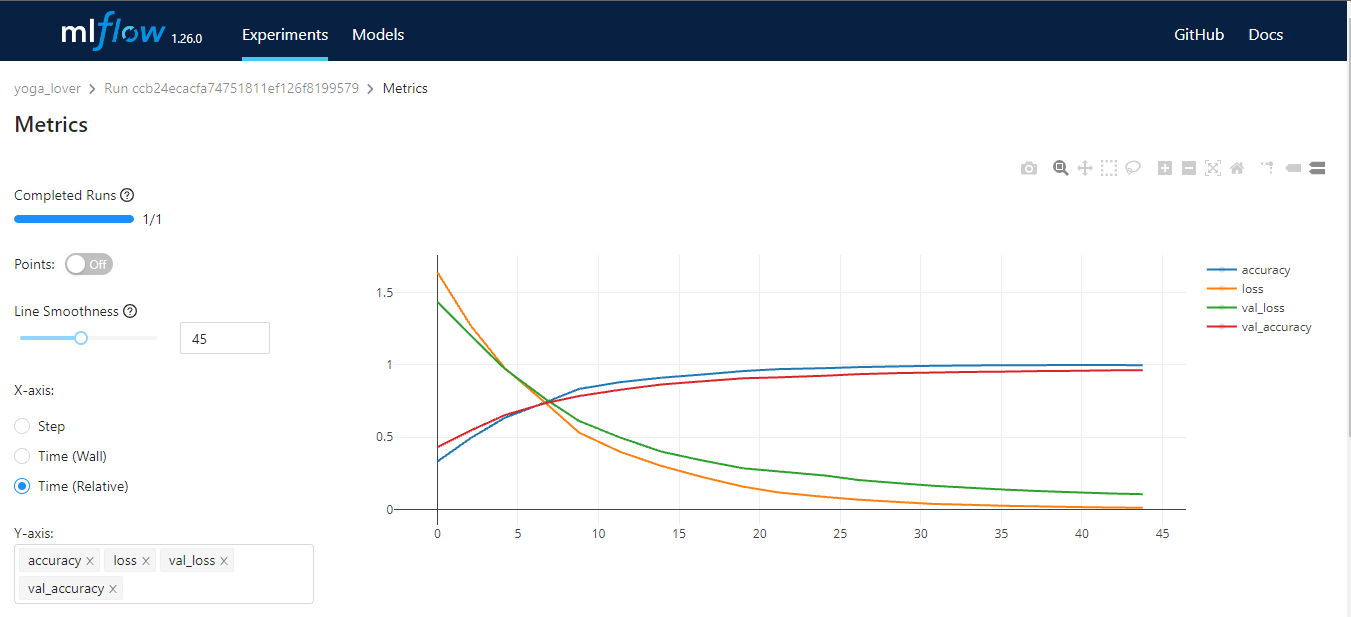
Hình do Tác giả cung cấp
Comet ML là nền tảng để theo dõi, so sánh, giải thích và tối ưu hóa mô hình và thí nghiệm machine learning. Bạn có thể dùng với bất kỳ thư viện machine learning nào như Scikit-learn, Pytorch, TensorFlow và HuggingFace.
Comet ML dành cho cá nhân, nhóm, doanh nghiệp và học thuật. Nó cho phép bất kỳ ai trực quan hóa và so sánh các thí nghiệm một cách dễ dàng. Hơn nữa, bạn có thể trực quan hóa mẫu từ dữ liệu ảnh, âm thanh, văn bản và dạng bảng.
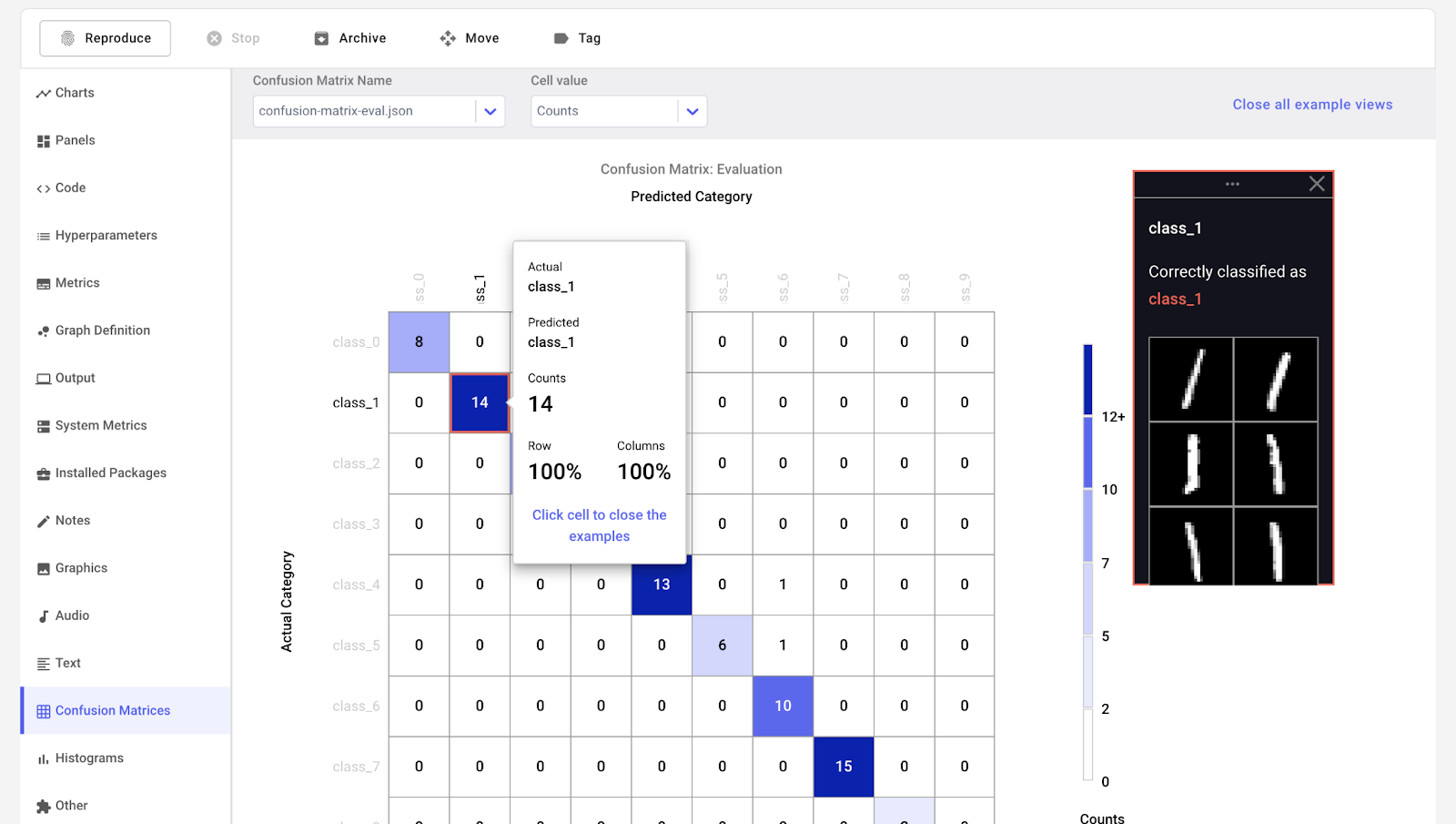
Hình từ Comet ML
Weights & Biases là nền tảng ML cho theo dõi thí nghiệm, quản lý phiên bản dữ liệu và mô hình, tối ưu siêu tham số và quản lý mô hình. Ngoài ra, bạn có thể dùng để ghi log artifact (tập dữ liệu, mô hình, phụ thuộc, pipeline và kết quả) và trực quan hóa tập dữ liệu (âm thanh, hình ảnh, văn bản và dạng bảng).
Weights & Biases có bảng điều khiển trung tâm thân thiện người dùng cho các thí nghiệm machine learning. Giống Comet ML, bạn có thể tích hợp với các thư viện machine learning khác như Fastai, Keras, PyTorch, Hugging face, Yolov5, Spacy và nhiều hơn nữa. Bạn có thể xem bài giới thiệu về Weights & BIases của chúng tôi ở một bài viết riêng.
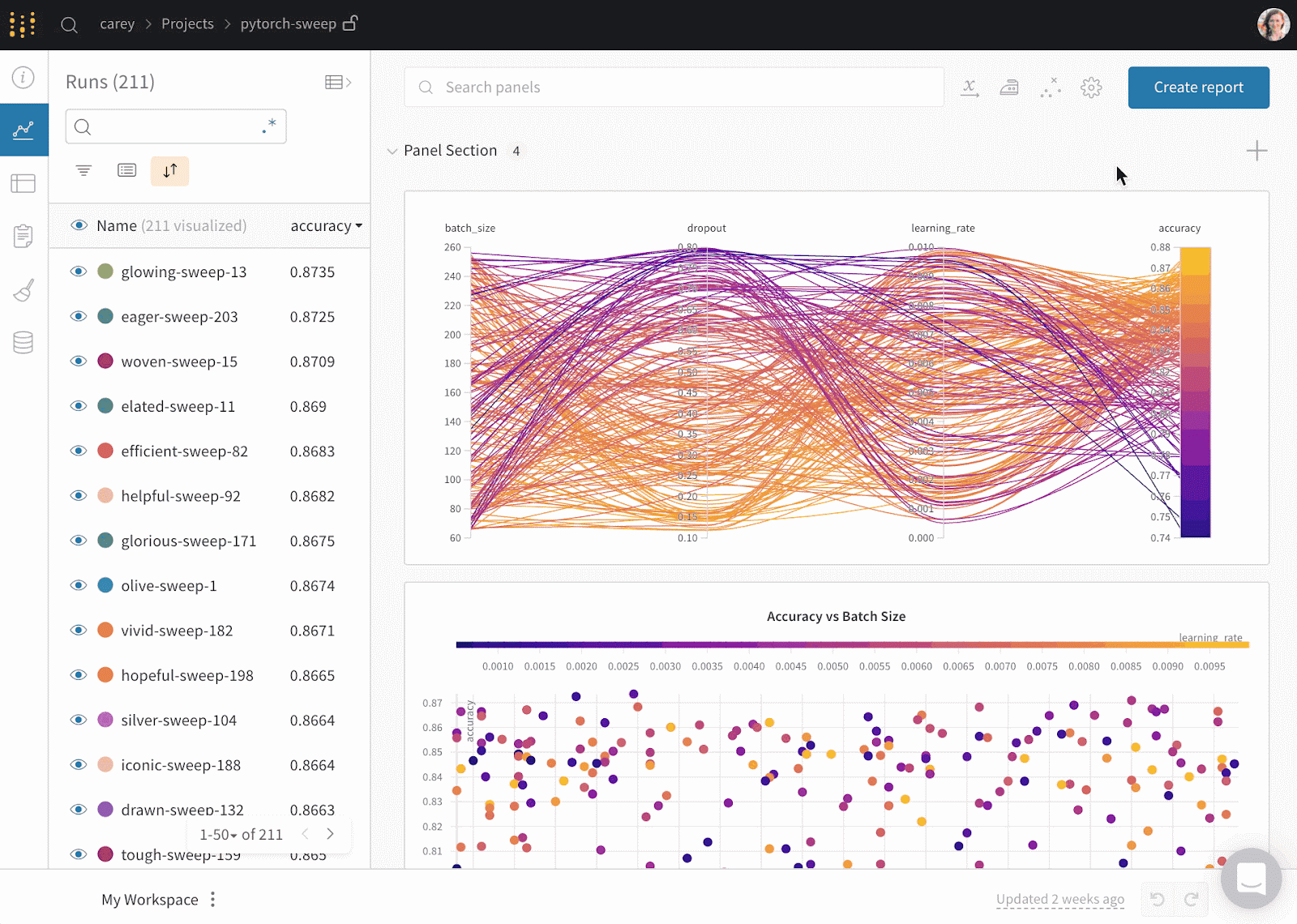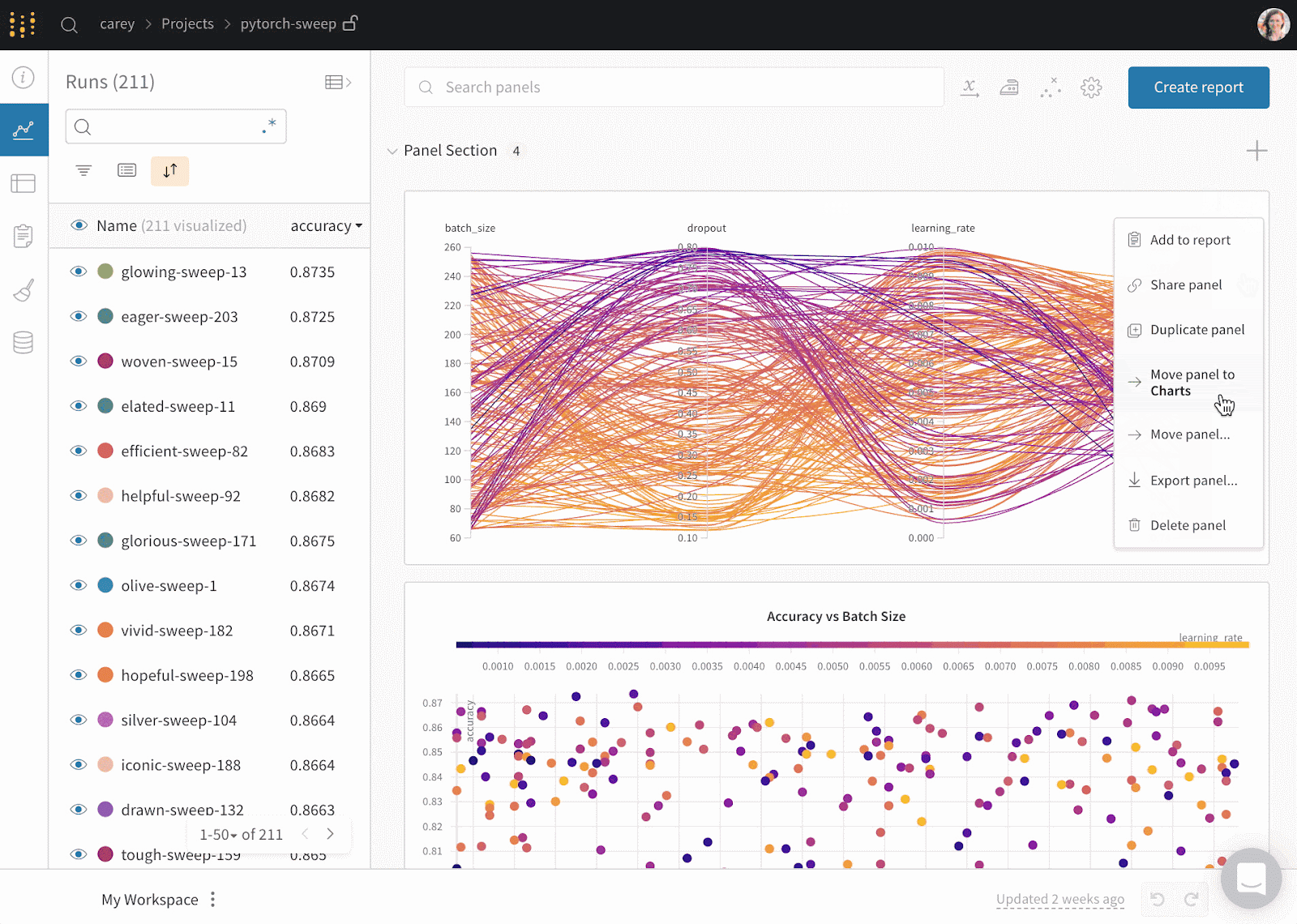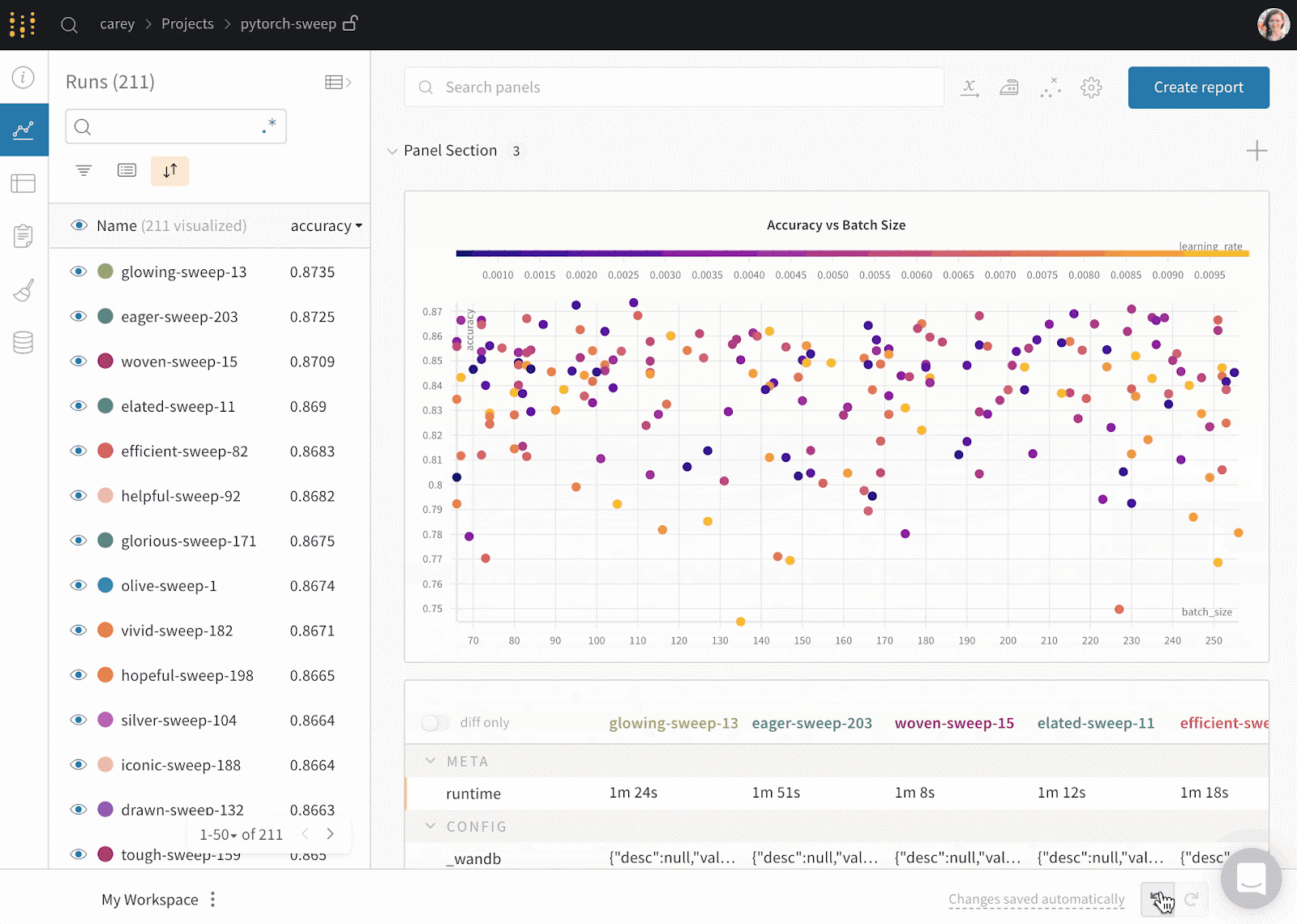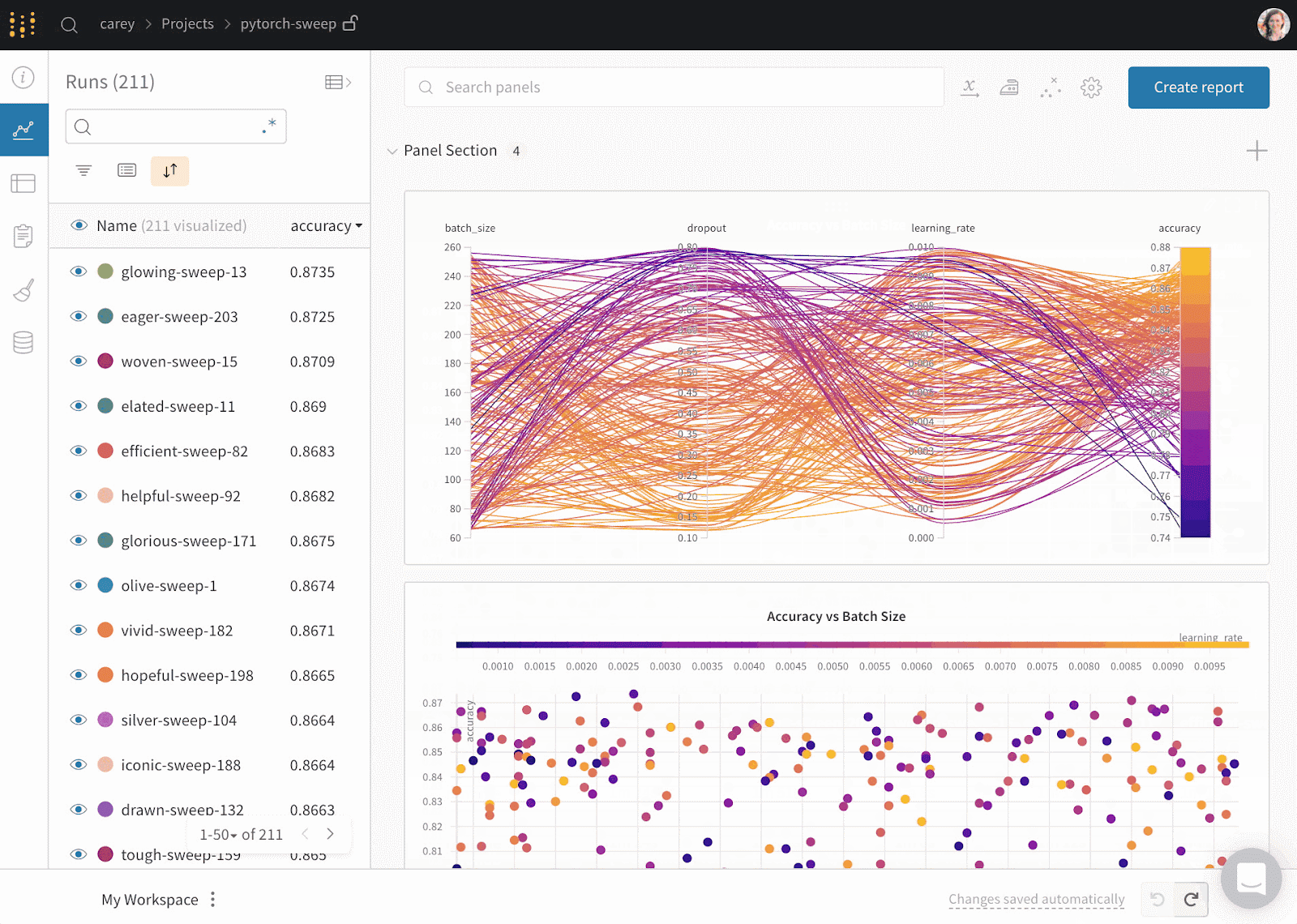
Gif từ Weights & Biases
Lưu ý: Bạn cũng có thể dùng TensorBoard, Pachyderm, DagsHub và DVC Studio để theo dõi thí nghiệm và quản lý siêu dữ liệu ML.
Những công cụ này giúp bạn tạo dự án khoa học dữ liệu và quản lý quy trình làm việc machine learning:
Prefect là một stack dữ liệu hiện đại để giám sát, phối hợp và điều phối các quy trình làm việc giữa và xuyên qua các ứng dụng. Đây là công cụ mã nguồn mở, nhẹ, được xây dựng cho các pipeline machine learning đầu-cuối.
Bạn có thể dùng Prefect Orion UI hoặc Prefect Cloud cho cơ sở dữ liệu.
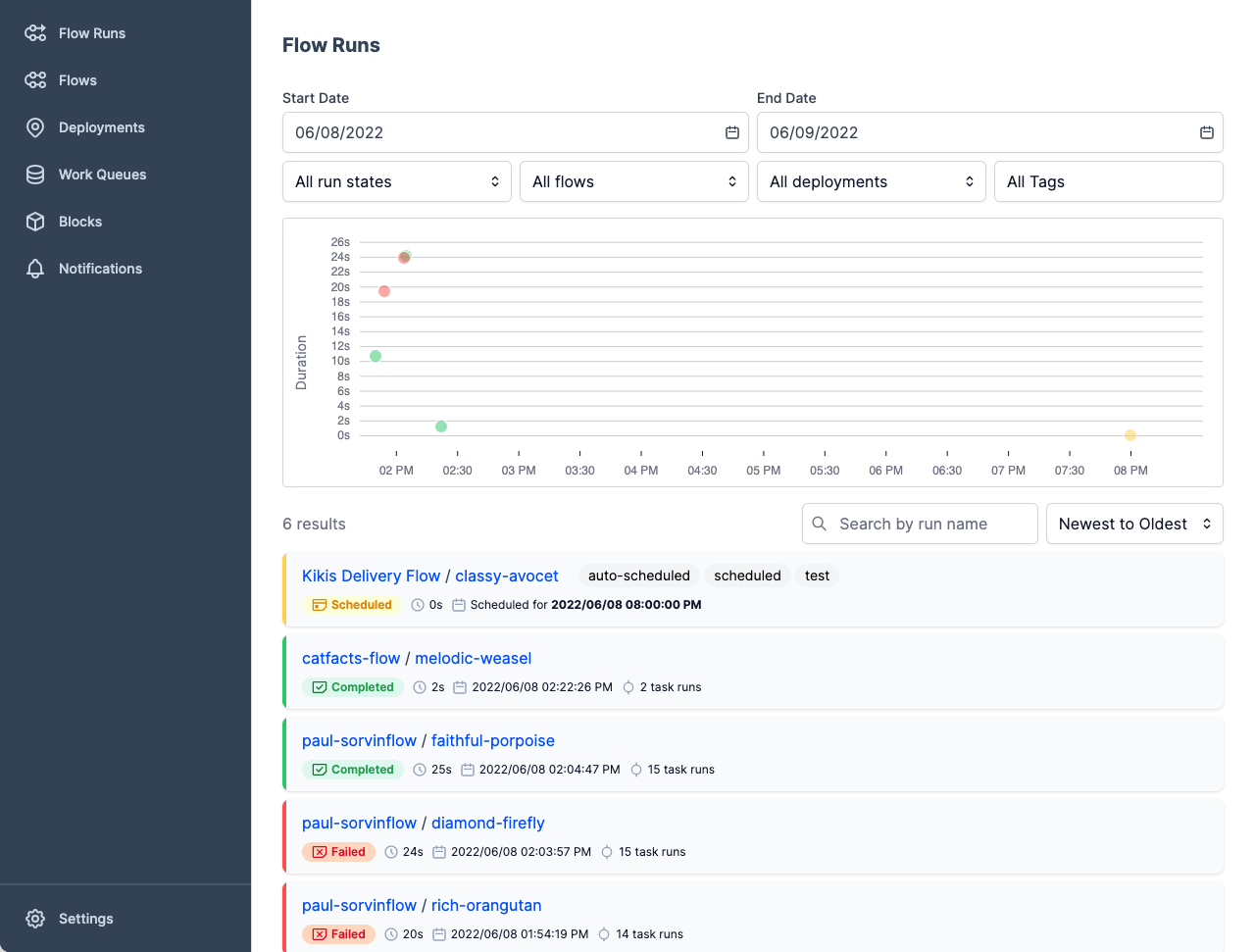
Hình từ Prefect
Metaflow là công cụ quản lý quy trình làm việc mạnh mẽ, dày dạn thực chiến cho các dự án khoa học dữ liệu và machine learning. Nó được xây dựng cho nhà khoa học dữ liệu để họ tập trung xây dựng mô hình thay vì bận tâm về kỹ thuật MLOps.
Với Metaflow, bạn có thể thiết kế quy trình làm việc, chạy ở quy mô lớn và triển khai mô hình vào sản xuất. Nó tự động theo dõi và quản lý phiên bản các thí nghiệm và dữ liệu machine learning. Bên cạnh đó, bạn có thể trực quan hóa kết quả trong notebook.
Metaflow làm việc với nhiều đám mây (bao gồm AWS, GCP và Azure) và nhiều gói Python cho machine learning (như Scikit-learn và Tensorflow), và API cũng có cho ngôn ngữ R.
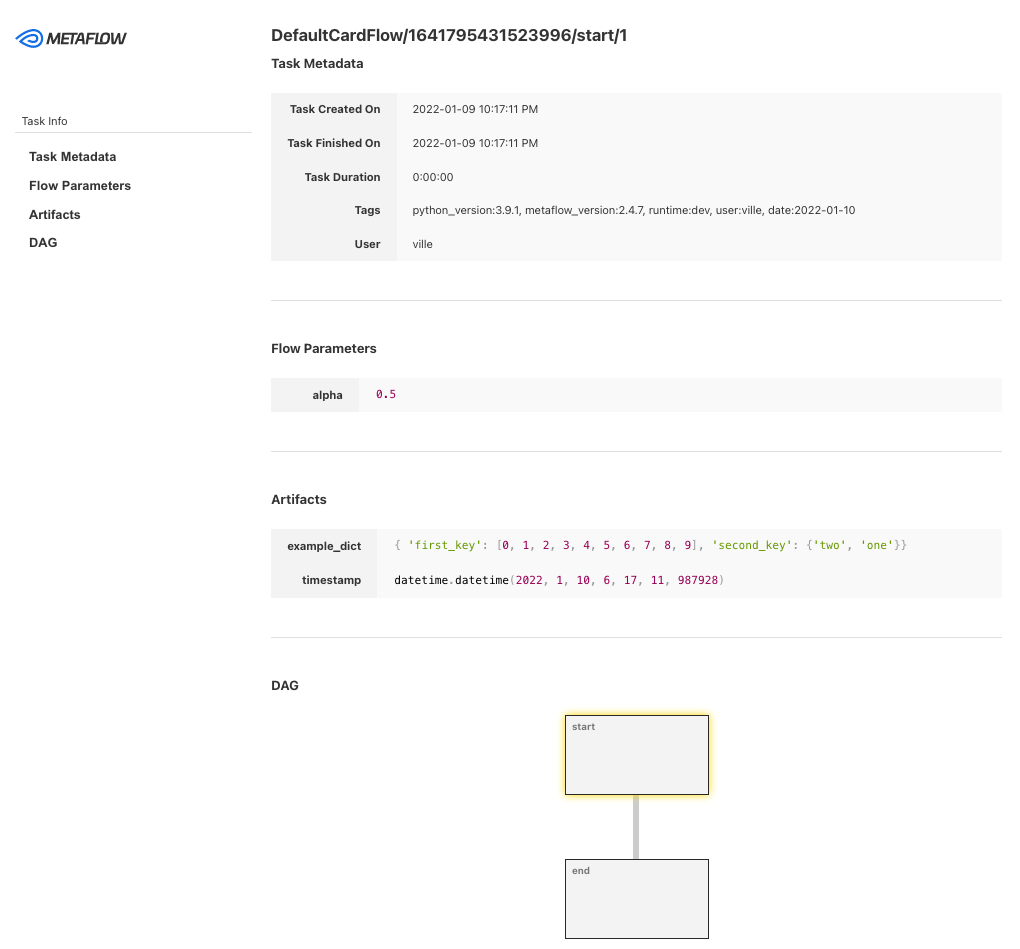
Hình từ Metaflow
Kedro là công cụ điều phối quy trình làm việc dựa trên Python. Bạn có thể dùng để tạo các dự án khoa học dữ liệu có thể tái lập, dễ bảo trì và có tính mô-đun. Nó tích hợp các khái niệm từ kỹ thuật phần mềm vào machine learning như tính mô-đun, tách biệt mối quan tâm và quản lý phiên bản.
Với Kedro, bạn có thể:
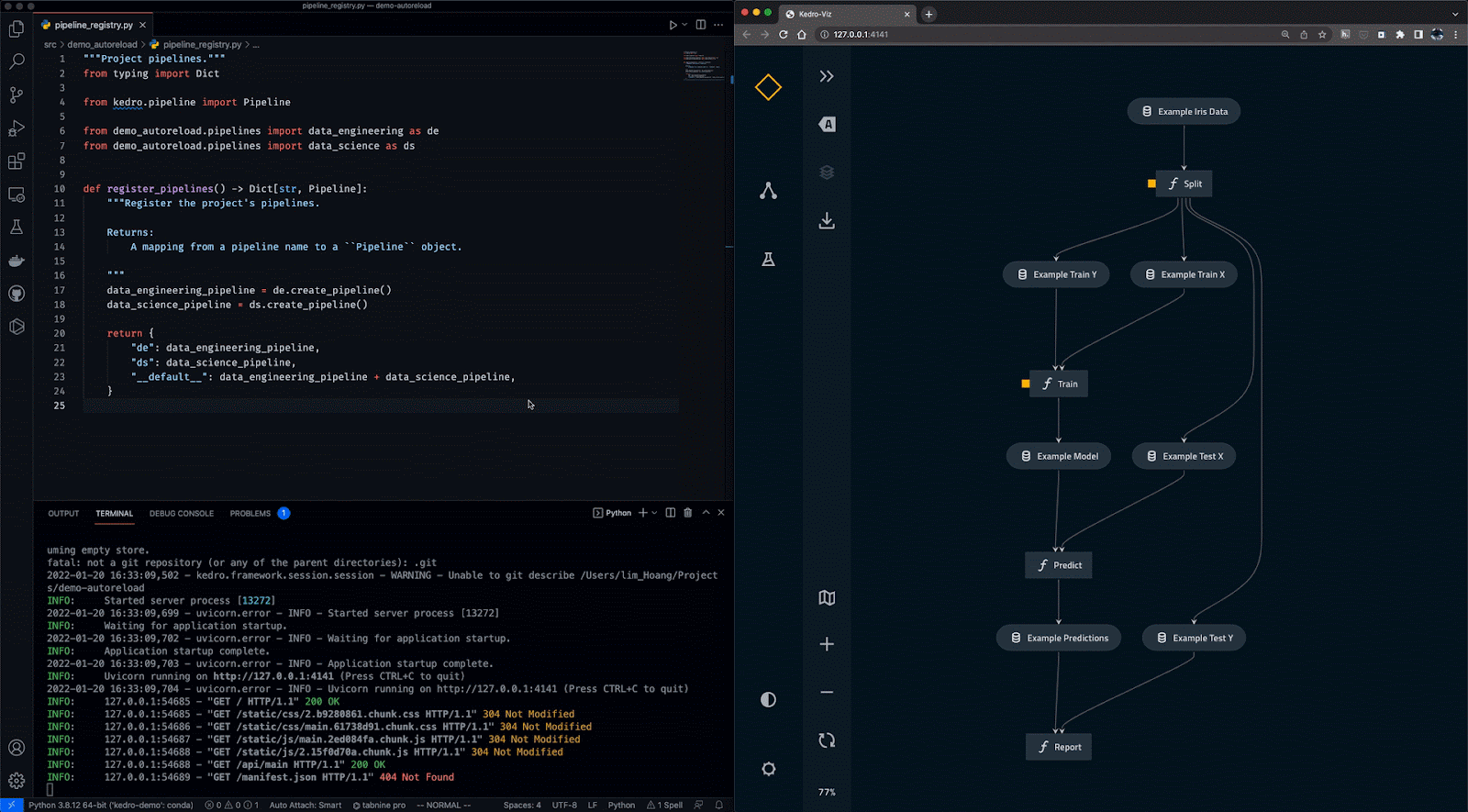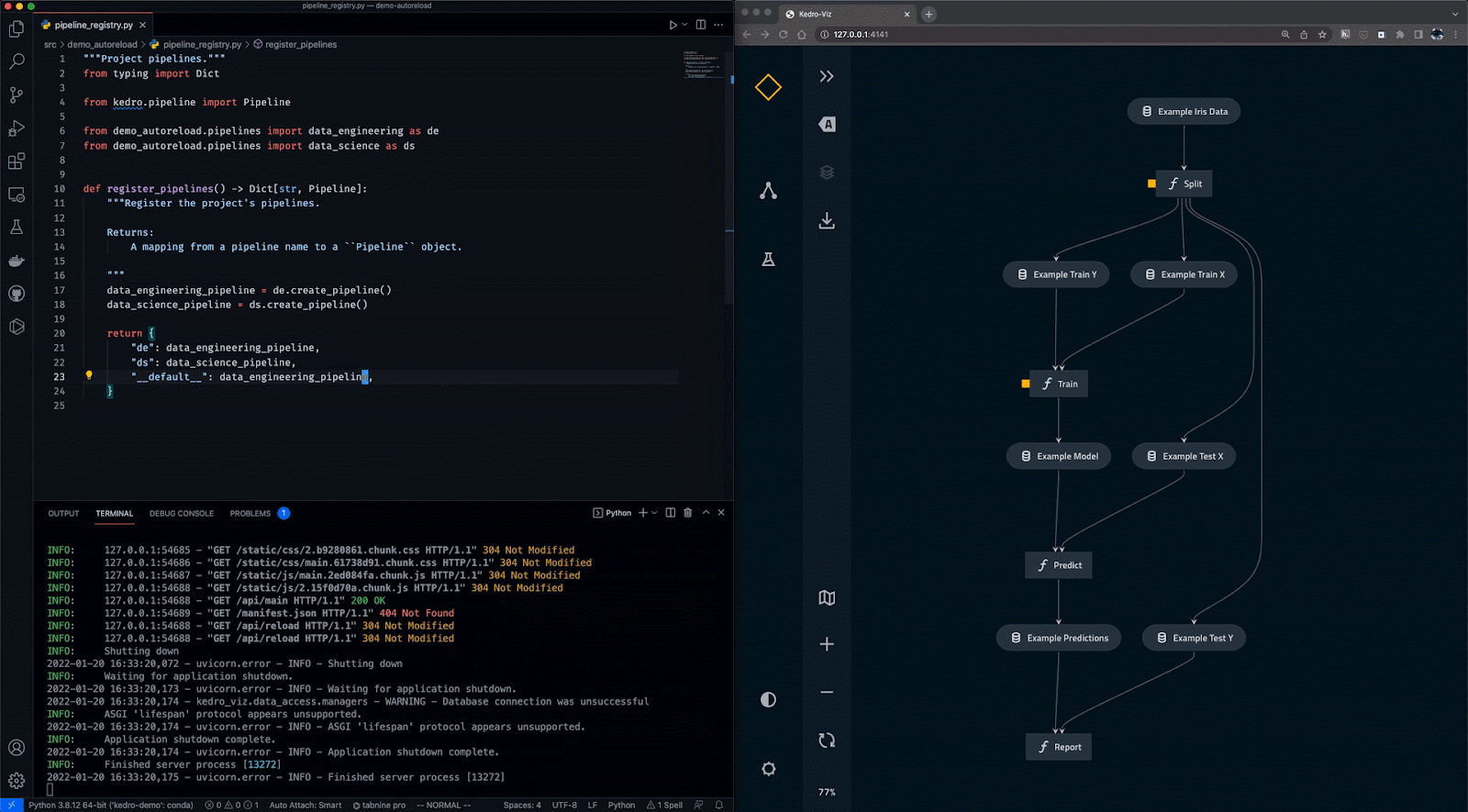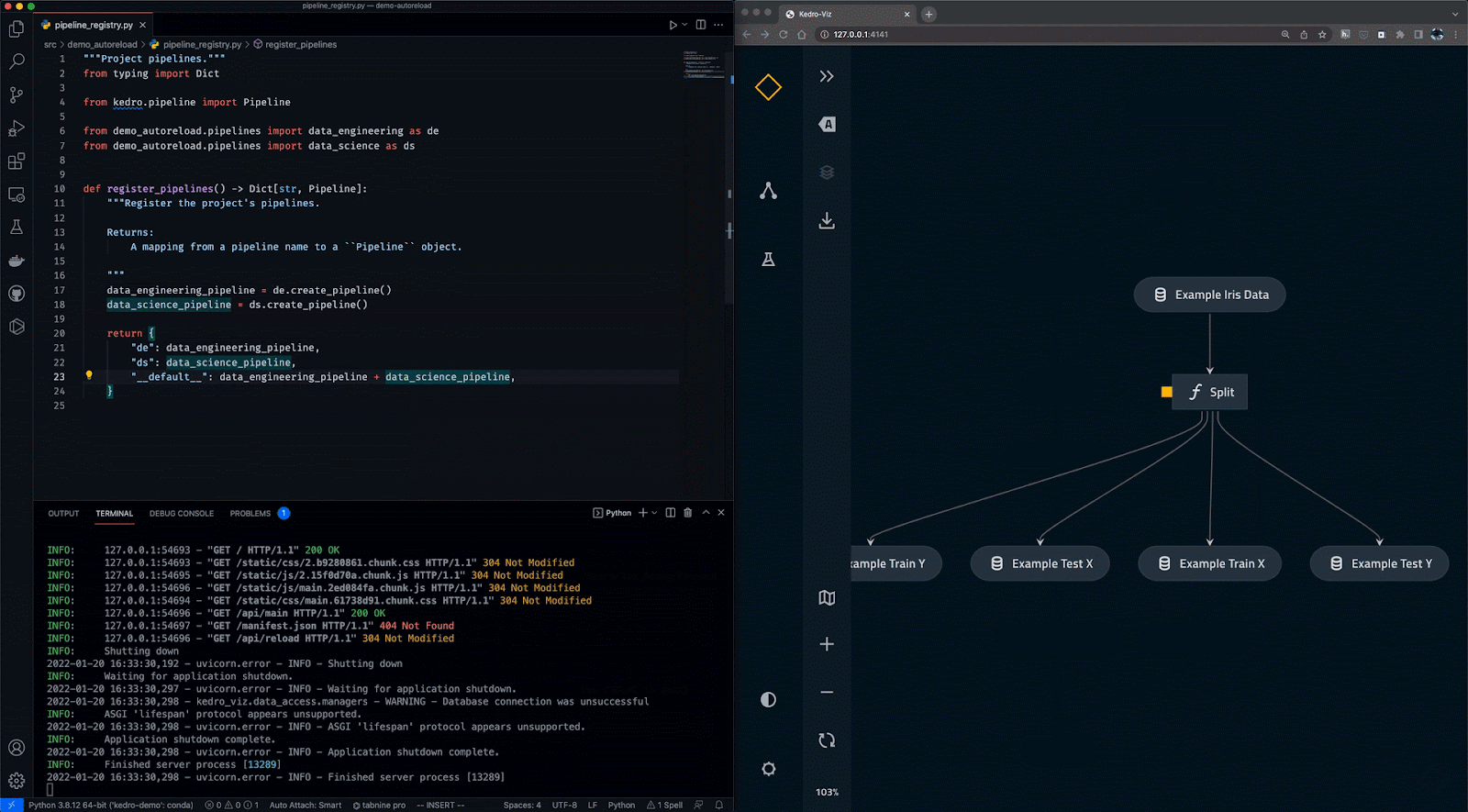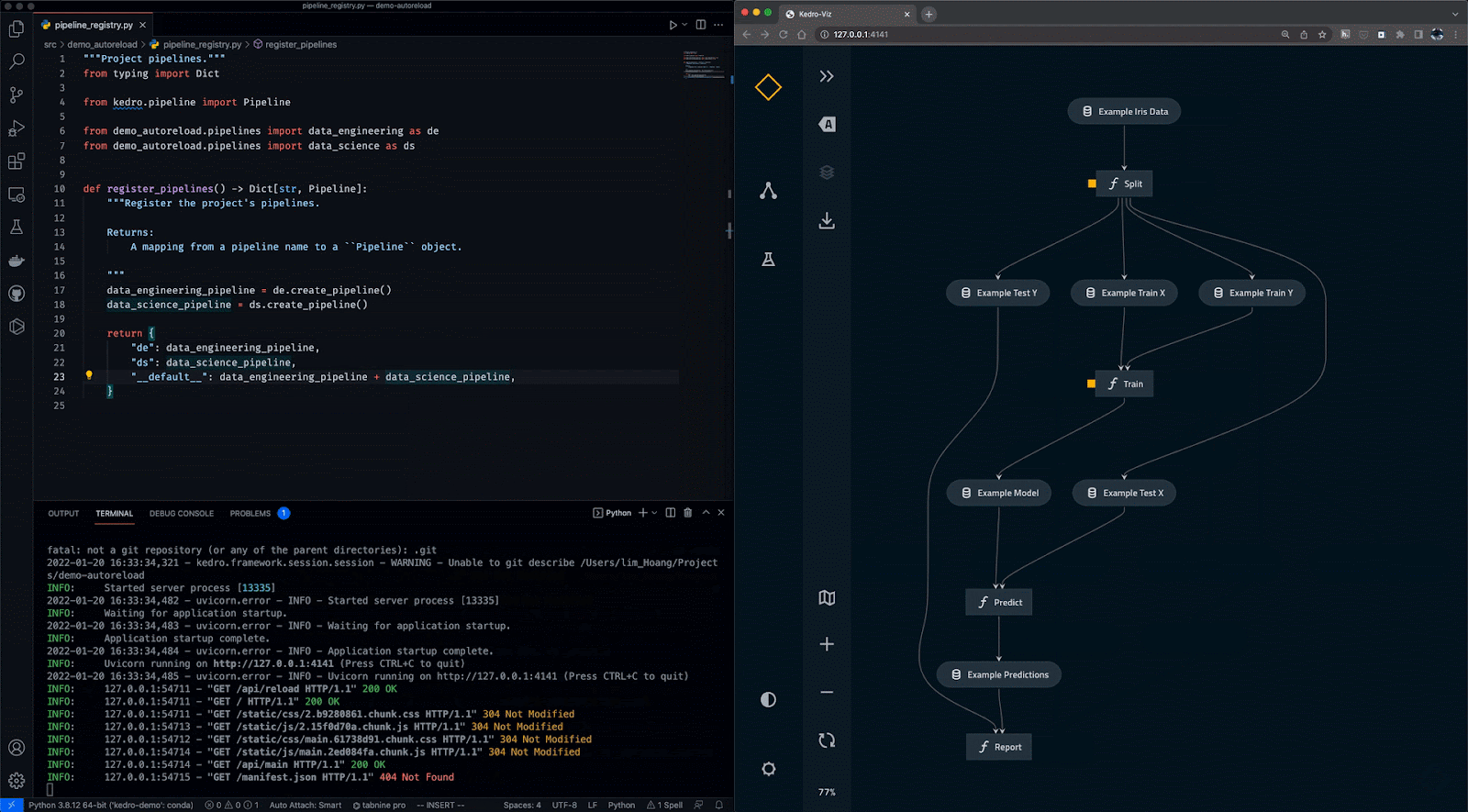
Gif từ Kedro
Lưu ý: bạn cũng có thể dùng Kubeflow và DVC cho điều phối và pipeline quy trình làm việc.
Với các công cụ MLOps này, bạn có thể quản lý các tác vụ liên quan đến quản lý phiên bản dữ liệu và pipeline:
Pachyderm tự động hóa biến đổi dữ liệu với quản lý phiên bản dữ liệu, nguồn gốc dữ liệu và pipeline đầu-cuối trên Kubernetes. Bạn có thể tích hợp với mọi dữ liệu (ảnh, log, video, CSV), mọi ngôn ngữ (Python, R, SQL, C/C++), và mọi quy mô (petabyte dữ liệu, hàng nghìn job).
Bản cộng đồng là mã nguồn mở và cho đội nhỏ. Tổ chức và nhóm muốn tính năng nâng cao có thể chọn bản Enterprise.
Tương tự Git, bạn có thể quản lý phiên bản dữ liệu bằng cú pháp tương tự. Trong Pachyderm, cấp đối tượng cao nhất là Repository, và bạn có thể dùng Commit, Branches, File, History và Provenance để theo dõi và quản lý phiên bản tập dữ liệu.
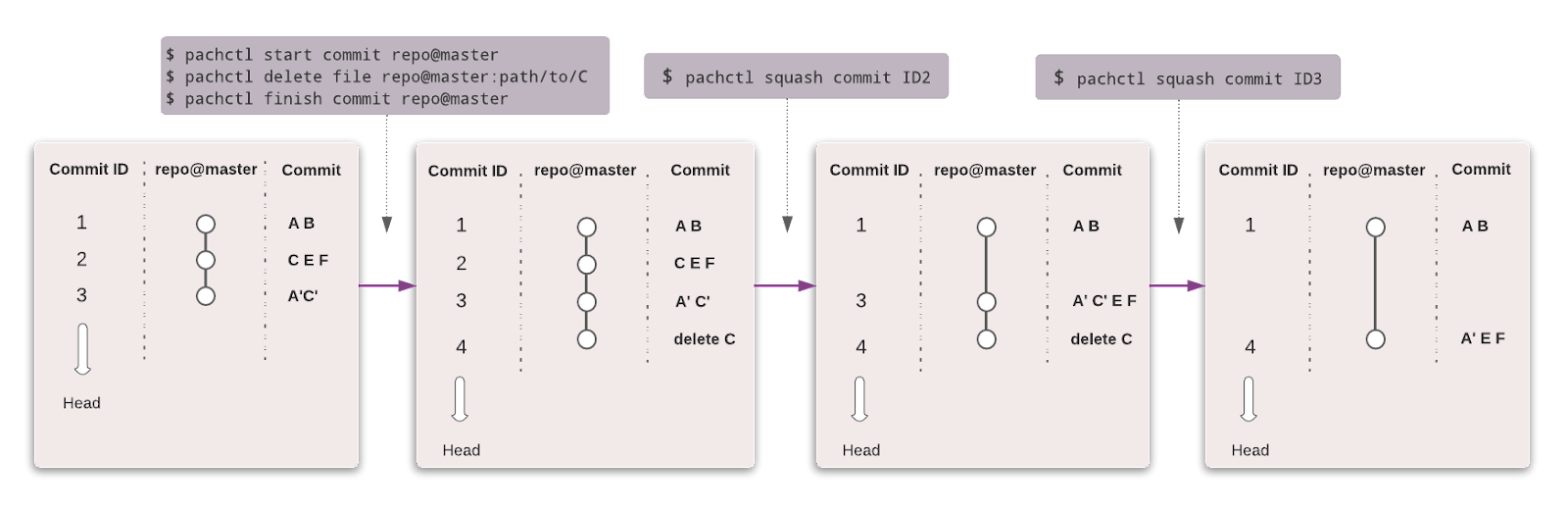
Hình từ Pachyderm
Data Version Control là công cụ mã nguồn mở và phổ biến cho các dự án machine learning. Nó hoạt động liền mạch với Git để cung cấp quản lý phiên bản cho mã, dữ liệu, mô hình, siêu dữ liệu và pipeline.
DVC không chỉ là công cụ theo dõi và quản lý phiên bản dữ liệu.
Bạn có thể dùng để:
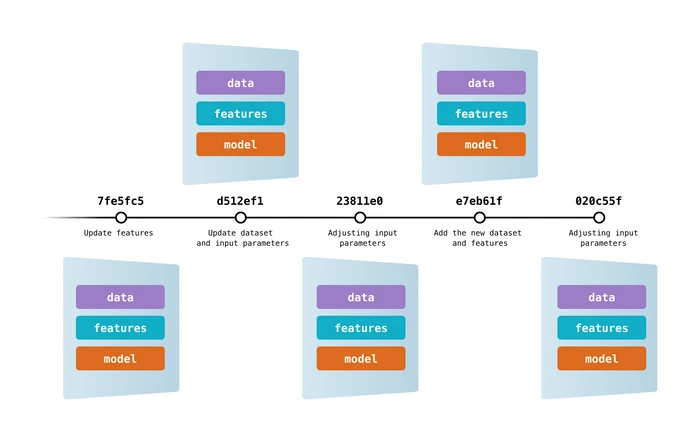
Hình từ DVC
Lưu ý: DagsHub cũng có thể dùng để quản lý phiên bản dữ liệu và pipeline.
LakeFS là công cụ mã nguồn mở, có thể mở rộng để quản lý phiên bản dữ liệu, cung cấp giao diện quản lý phiên bản giống Git cho object storage, cho phép người dùng quản lý data lake như quản lý mã. Với LakeFS, người dùng có thể quản lý phiên bản dữ liệu ở quy mô exabyte, khiến nó trở thành giải pháp có khả năng mở rộng cao cho quản lý các data lake lớn.
Khả năng bổ sung:
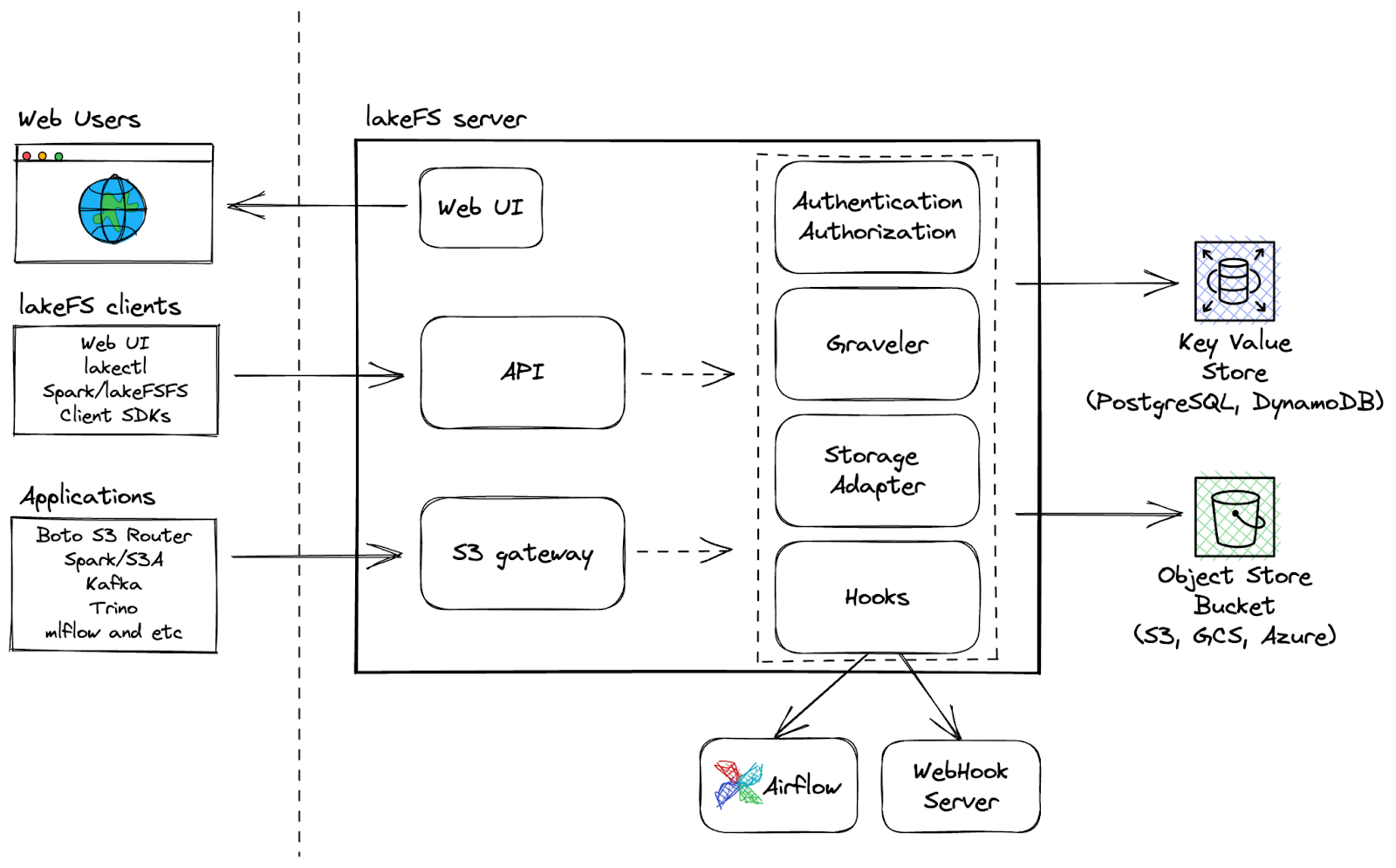
Kiến trúc LakeFS
Feature store là kho lưu trữ tập trung để lưu, quản lý phiên bản, quản trị và phục vụ feature (các thuộc tính dữ liệu đã xử lý dùng để huấn luyện mô hình machine learning) cho mô hình trong sản xuất cũng như cho mục đích huấn luyện.
Feast là feature store mã nguồn mở giúp các nhóm machine learning đưa mô hình thời gian thực vào sản xuất và xây dựng nền tảng feature thúc đẩy hợp tác giữa kỹ sư và nhà khoa học dữ liệu.
Tính năng chính:
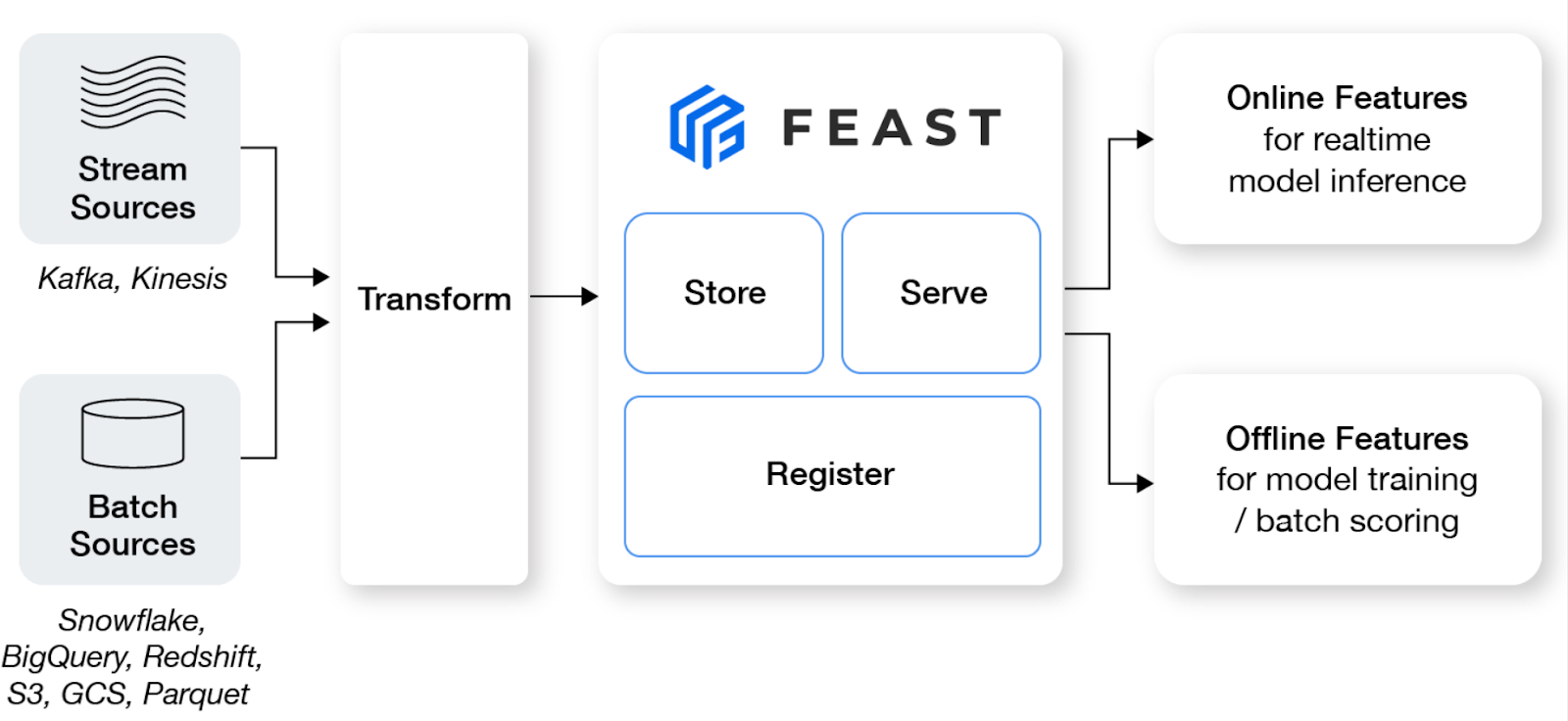
Hình từ Feast
Featureform là feature store ảo cho phép nhà khoa học dữ liệu định nghĩa, quản lý và phục vụ feature cho mô hình ML của họ. Nó có thể giúp các nhóm khoa học dữ liệu tăng cường cộng tác, tổ chức thí nghiệm, hỗ trợ triển khai, tăng độ tin cậy và đảm bảo tuân thủ.
Tính năng chính:
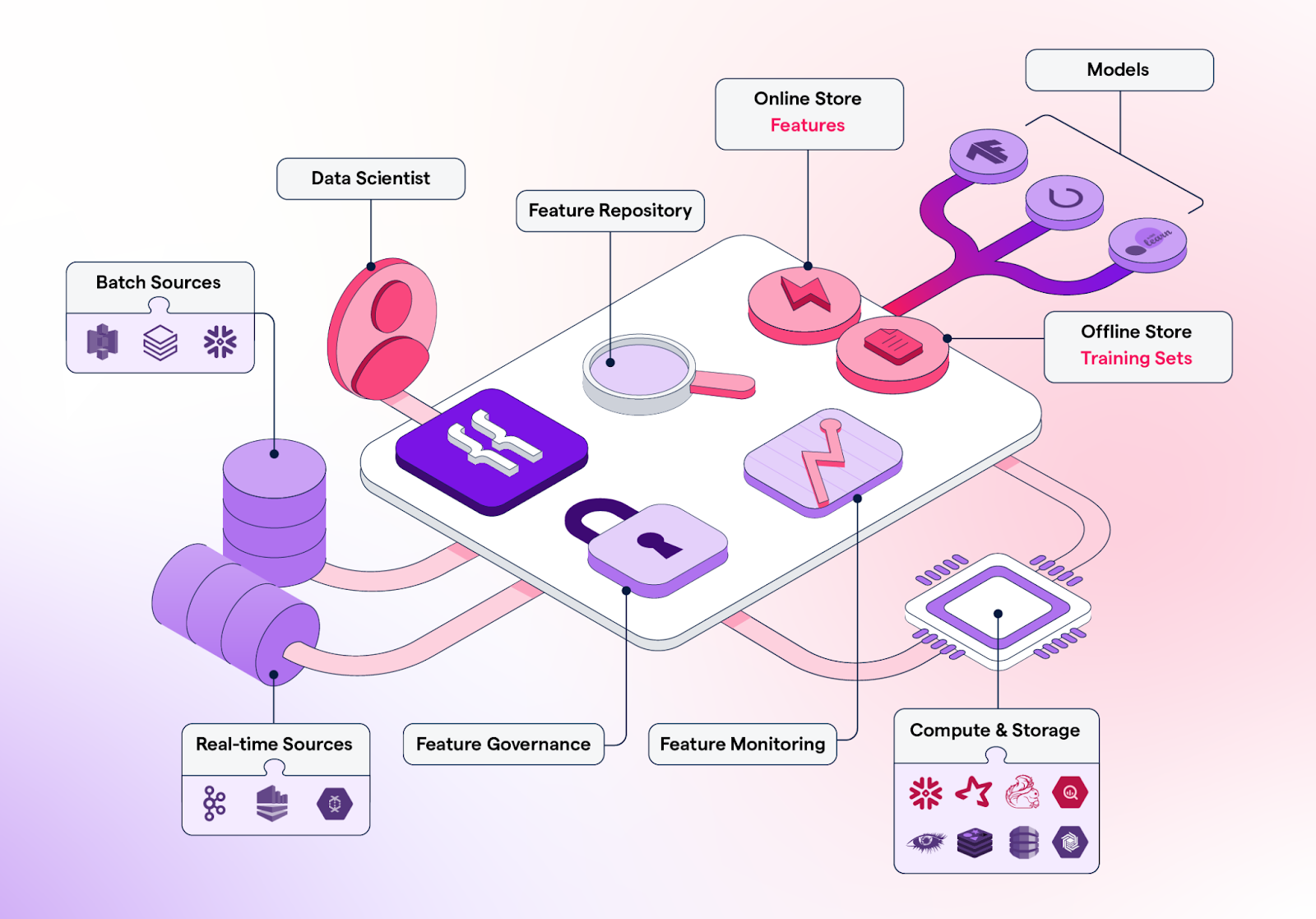
Hình từ Featureform
Với các công cụ MLOps này, bạn có thể kiểm thử chất lượng mô hình và đảm bảo độ tin cậy, độ vững và độ chính xác của mô hình machine learning:
Deepchecks là giải pháp mã nguồn mở đáp ứng mọi nhu cầu xác thực ML của bạn, đảm bảo dữ liệu và mô hình được kiểm thử kỹ lưỡng từ nghiên cứu đến sản xuất. Nó cung cấp cách tiếp cận toàn diện để xác thực dữ liệu và mô hình thông qua các thành phần khác nhau.
Hình từ Deepchecks
Deepchecks gồm ba thành phần:
TruEra là nền tảng tiên tiến nhằm thúc đẩy chất lượng và hiệu suất mô hình thông qua kiểm thử tự động, khả năng giải thích và phân tích nguyên nhân gốc rễ. Nó cung cấp nhiều tính năng để giúp tối ưu và debug mô hình, đạt khả năng giải thích đẳng cấp, và tích hợp dễ dàng vào stack ML của bạn.
Tính năng chính:
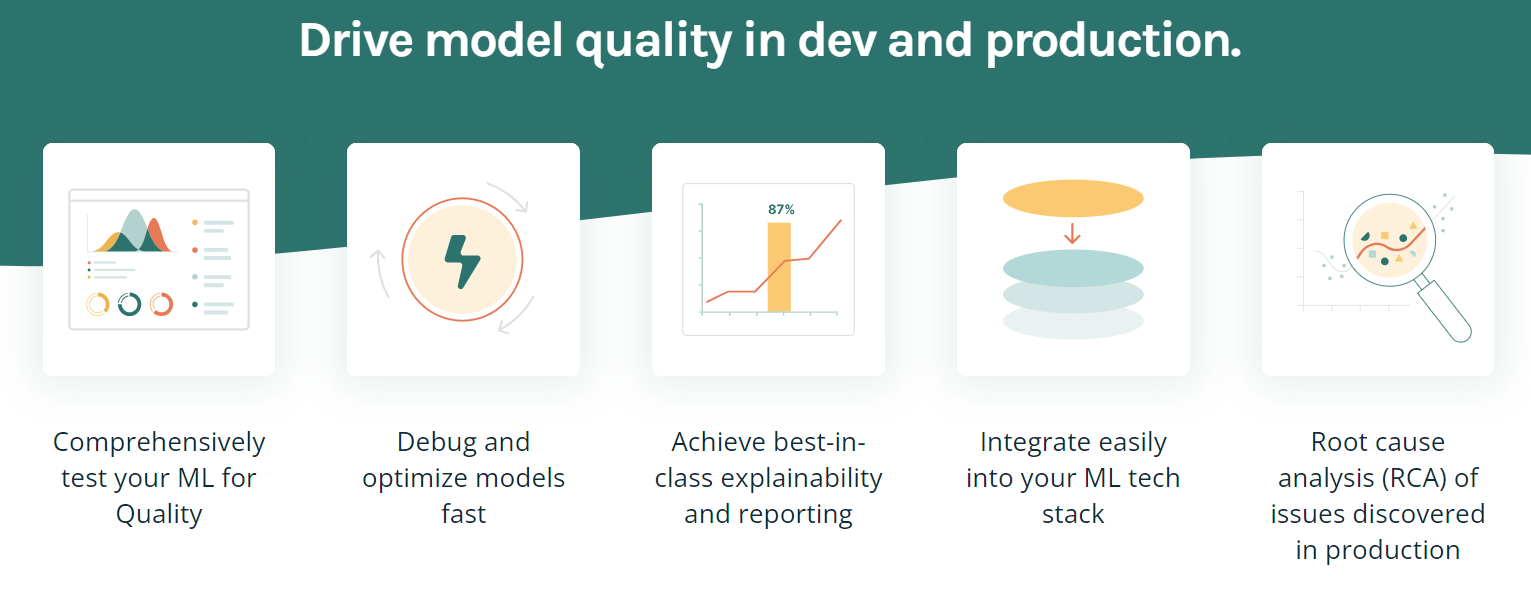
Hình bởi TruEra
Khi triển khai mô hình, các công cụ MLOps này có thể hỗ trợ rất nhiều:
Kubeflow giúp triển khai mô hình machine learning trên Kubernetes trở nên đơn giản, linh động và có thể mở rộng. Bạn có thể dùng cho chuẩn bị dữ liệu, huấn luyện mô hình, tối ưu mô hình, phục vụ dự đoán và theo dõi hiệu suất mô hình trong sản xuất. Bạn có thể triển khai quy trình làm việc ML tại chỗ, on-premises hoặc lên đám mây. Nói ngắn gọn, nó làm cho Kubernetes trở nên dễ dàng với các nhóm khoa học dữ liệu.
Tính năng chính:
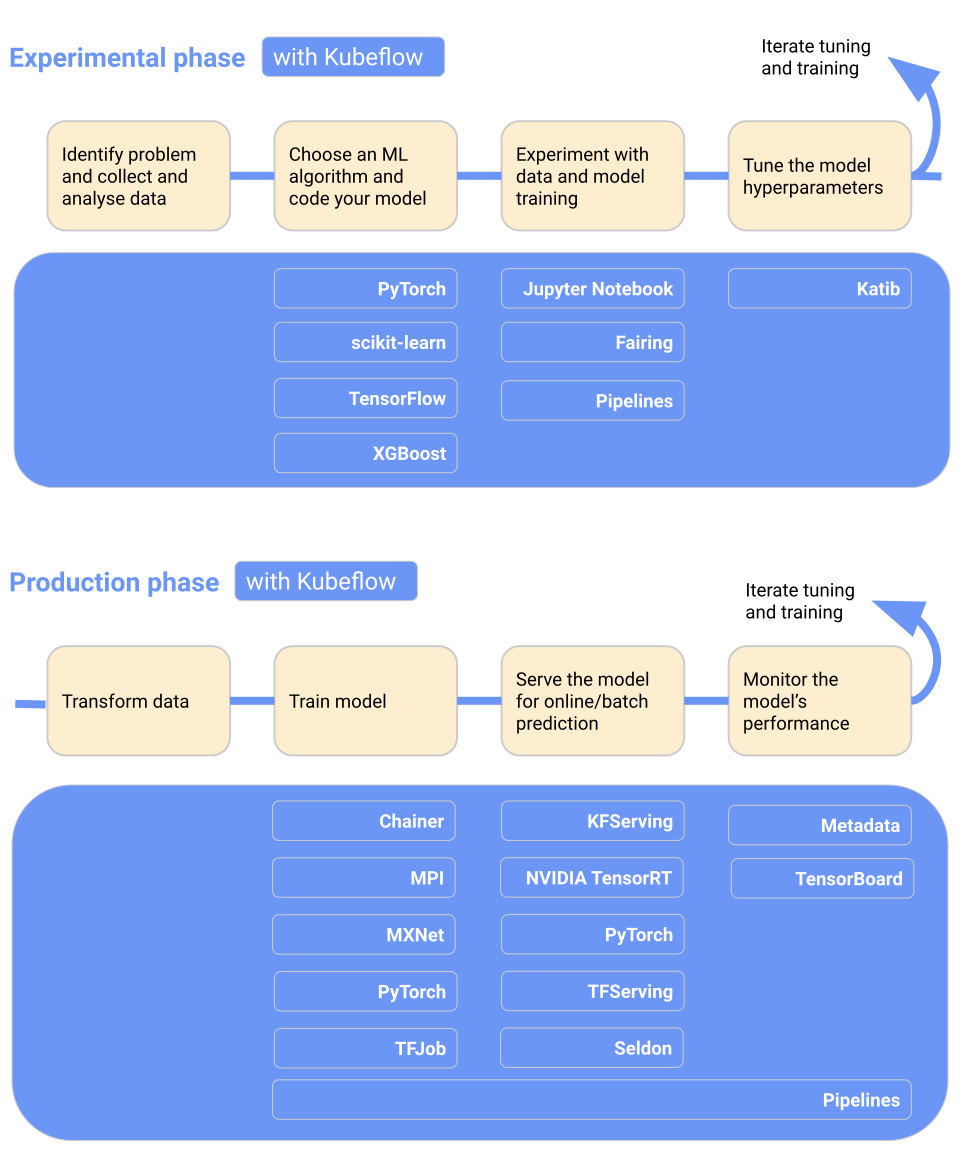
Hình từ Kubeflow
BentoML giúp việc đưa các ứng dụng machine learning vào sử dụng trở nên dễ dàng và nhanh hơn. Đây là công cụ ưu tiên Python để triển khai và duy trì API trong sản xuất. Nó mở rộng quy mô với các tối ưu hóa mạnh mẽ bằng cách chạy suy luận song song và batching thích ứng, đồng thời cung cấp tăng tốc phần cứng.
Bảng điều khiển trung tâm tương tác của BentoML giúp tổ chức và giám sát khi triển khai mô hình machine learning trở nên dễ dàng. Điểm hay là nó hoạt động với mọi loại framework machine learning như Keras, ONNX, LightGBM, Pytorch và Scikit-learn. Tóm lại, BentoML cung cấp giải pháp hoàn chỉnh cho triển khai, phục vụ và giám sát mô hình.
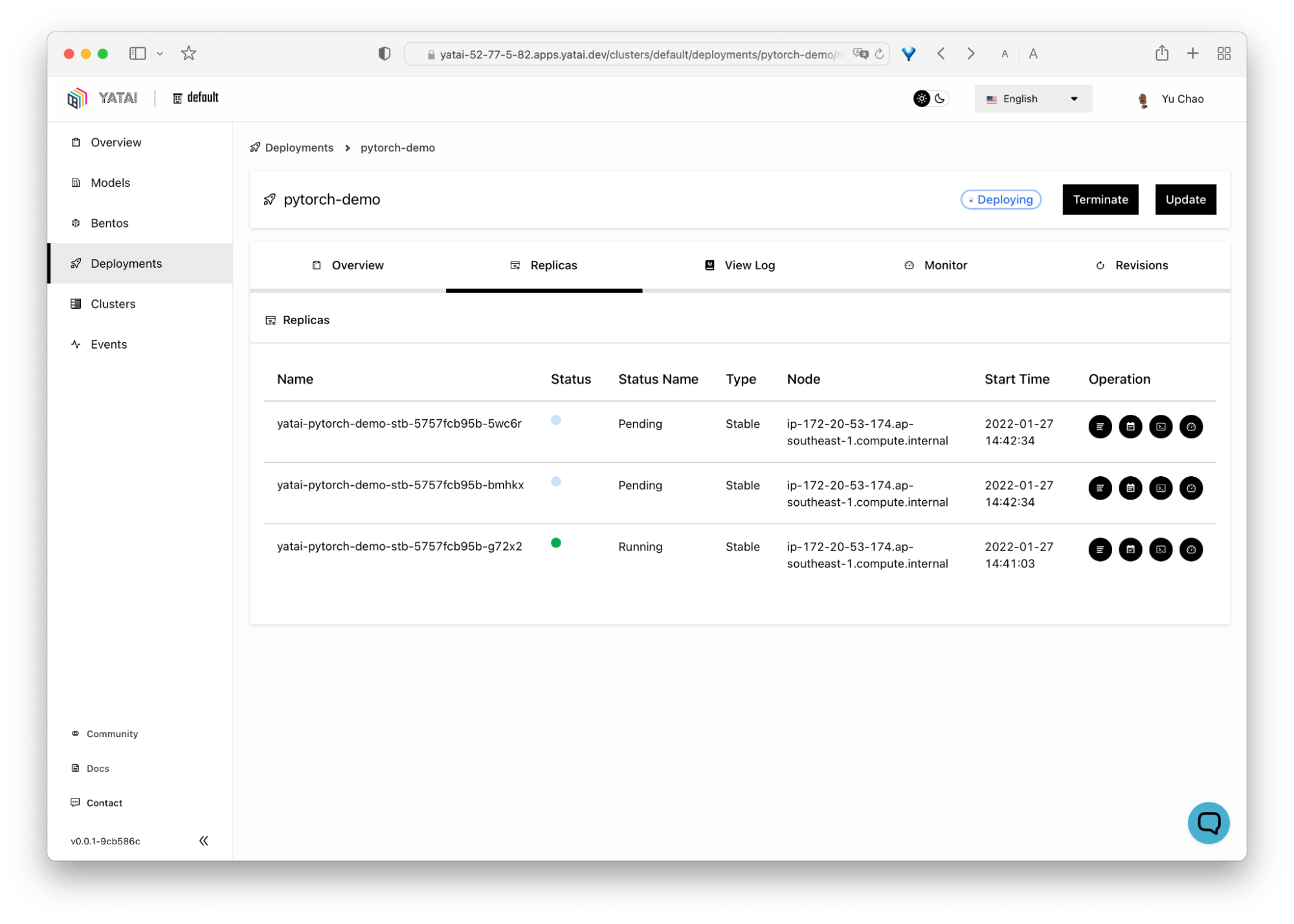
Hình từ BentoML
Hugging Face Inference Endpoints là dịch vụ dựa trên đám mây do Hugging Face cung cấp, một nền tảng ML tất-cả-trong-một cho phép người dùng huấn luyện, lưu trữ và chia sẻ mô hình, tập dữ liệu và bản demo. Các endpoint này được thiết kế để giúp người dùng triển khai các mô hình machine learning đã huấn luyện cho suy luận mà không cần thiết lập và quản lý hạ tầng cần thiết.
Tính năng chính:
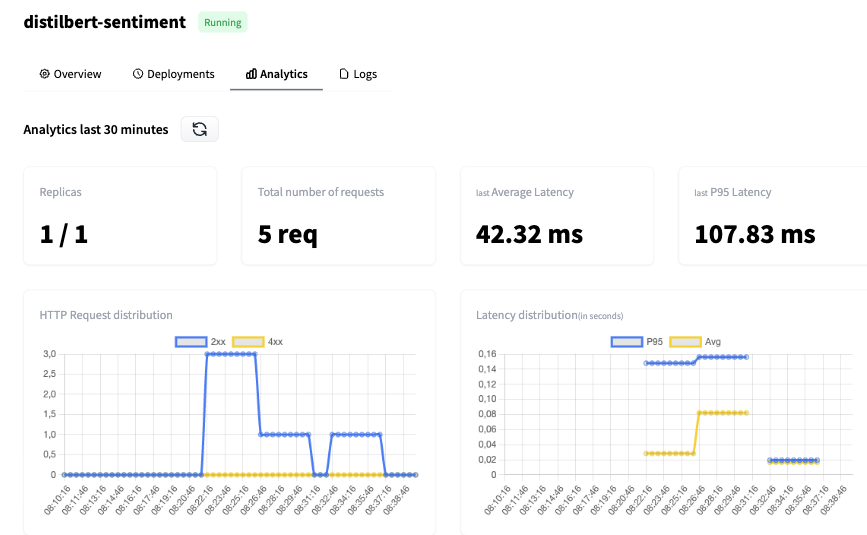
Hình từ Hugging Face
Lưu ý: Bạn cũng có thể dùng MLflow và AWS sagemaker để triển khai và phục vụ mô hình.
Dù mô hình ML của bạn đang ở giai đoạn phát triển, thẩm định hay đã triển khai vào sản xuất, những công cụ này có thể giúp bạn giám sát nhiều yếu tố:
Evidently AI là thư viện Python mã nguồn mở để giám sát mô hình ML trong giai đoạn phát triển, thẩm định và sản xuất. Nó kiểm tra chất lượng dữ liệu và mô hình, trôi dữ liệu, trôi mục tiêu, và hiệu suất hồi quy/lớp hóa.
Evidently có ba thành phần chính:
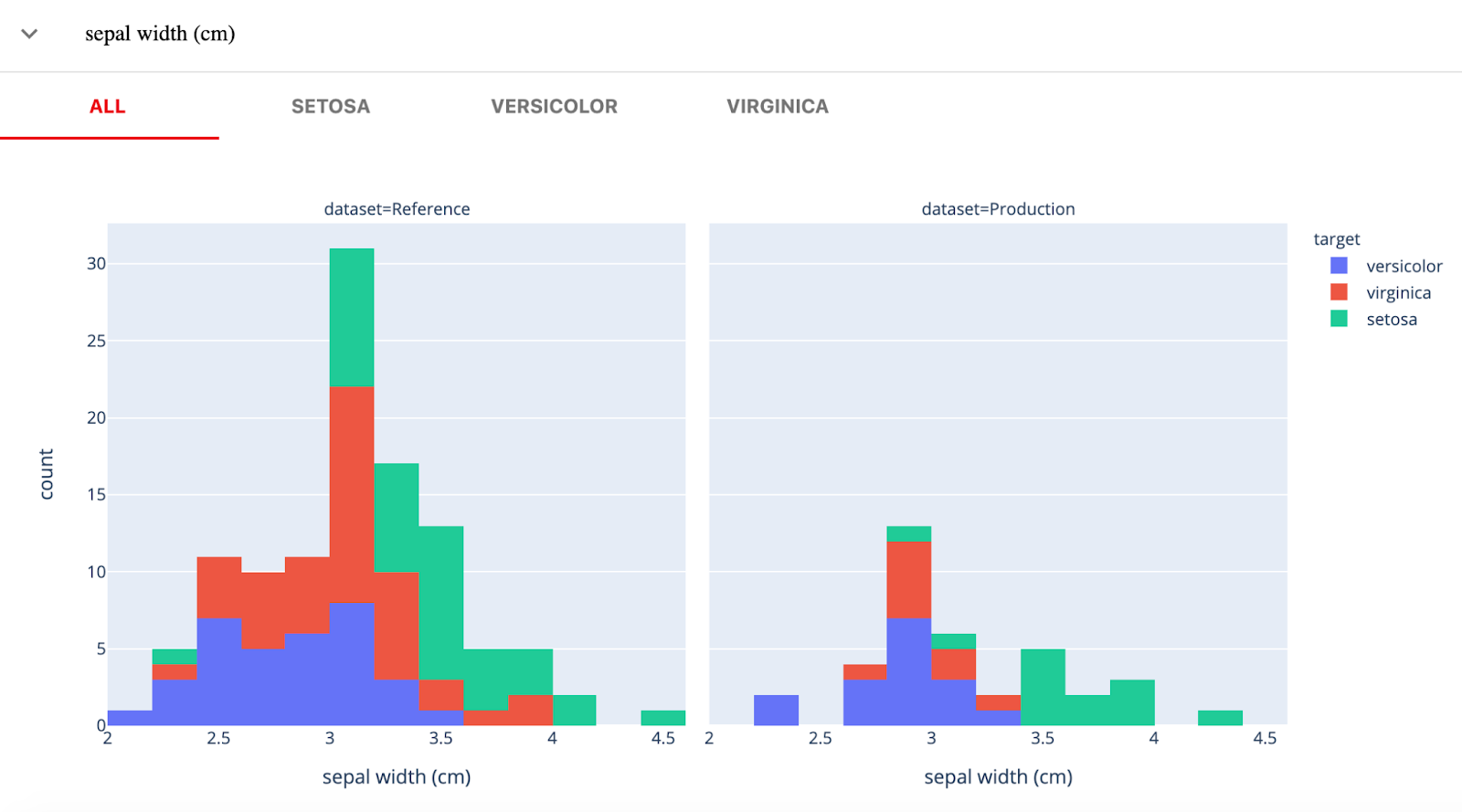
Hình từ Evidently
Fiddler AI là công cụ giám sát mô hình ML với giao diện rõ ràng, dễ dùng. Nó cho phép bạn giải thích và debug dự đoán, phân tích hành vi mô hình trên toàn bộ tập dữ liệu, triển khai mô hình ở quy mô lớn và giám sát hiệu suất mô hình.
Hãy xem các tính năng chính của Fiddler AI cho giám sát ML:
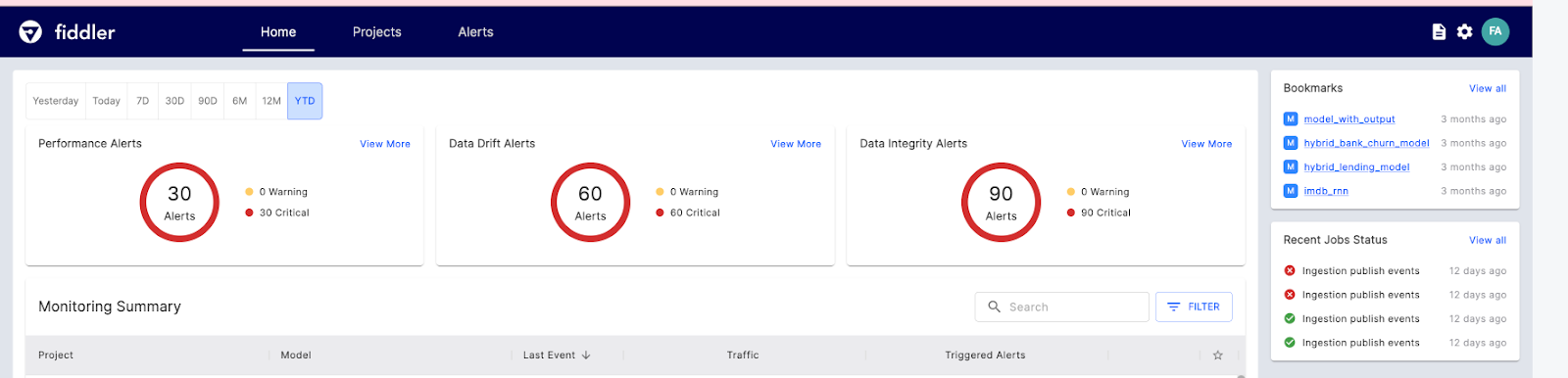
Hình từ Fiddler
Runtime engine chịu trách nhiệm tải mô hình, tiền xử lý dữ liệu đầu vào, chạy suy luận và trả kết quả về cho ứng dụng khách.
Ray là framework đa năng được thiết kế để mở rộng ứng dụng AI và Python, giúp nhà phát triển dễ dàng quản lý và tối ưu các dự án machine learning.
Nền tảng gồm hai thành phần chính: runtime phân tán cốt lõi và một bộ thư viện AI dành cho đơn giản hóa tính toán ML.
Ray Core cung cấp một tập nhỏ các phần tử cơ bản có thể dùng để xây dựng và mở rộng ứng dụng phân tán.
Ray cũng cung cấp các thư viện AI cho tập dữ liệu có thể mở rộng cho ML, huấn luyện phân tán, điều chỉnh siêu tham số, học tăng cường, và phục vụ có thể lập trình và mở rộng.
Ví dụ sau minh họa việc huấn luyện và phục vụ mô hình Gradient Boosting Classifier.
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")Nuclio là framework mạnh mẽ tập trung vào các khối lượng công việc nặng về dữ liệu, I/O và tính toán. Nó được thiết kế theo kiểu serverless, nghĩa là bạn không cần lo quản lý máy chủ. Nuclio được tích hợp tốt với các công cụ khoa học dữ liệu phổ biến như Jupyter và Kubeflow. Nó cũng hỗ trợ nhiều nguồn dữ liệu và streaming, và có thể chạy trên CPU và GPU.
Tính năng chính:
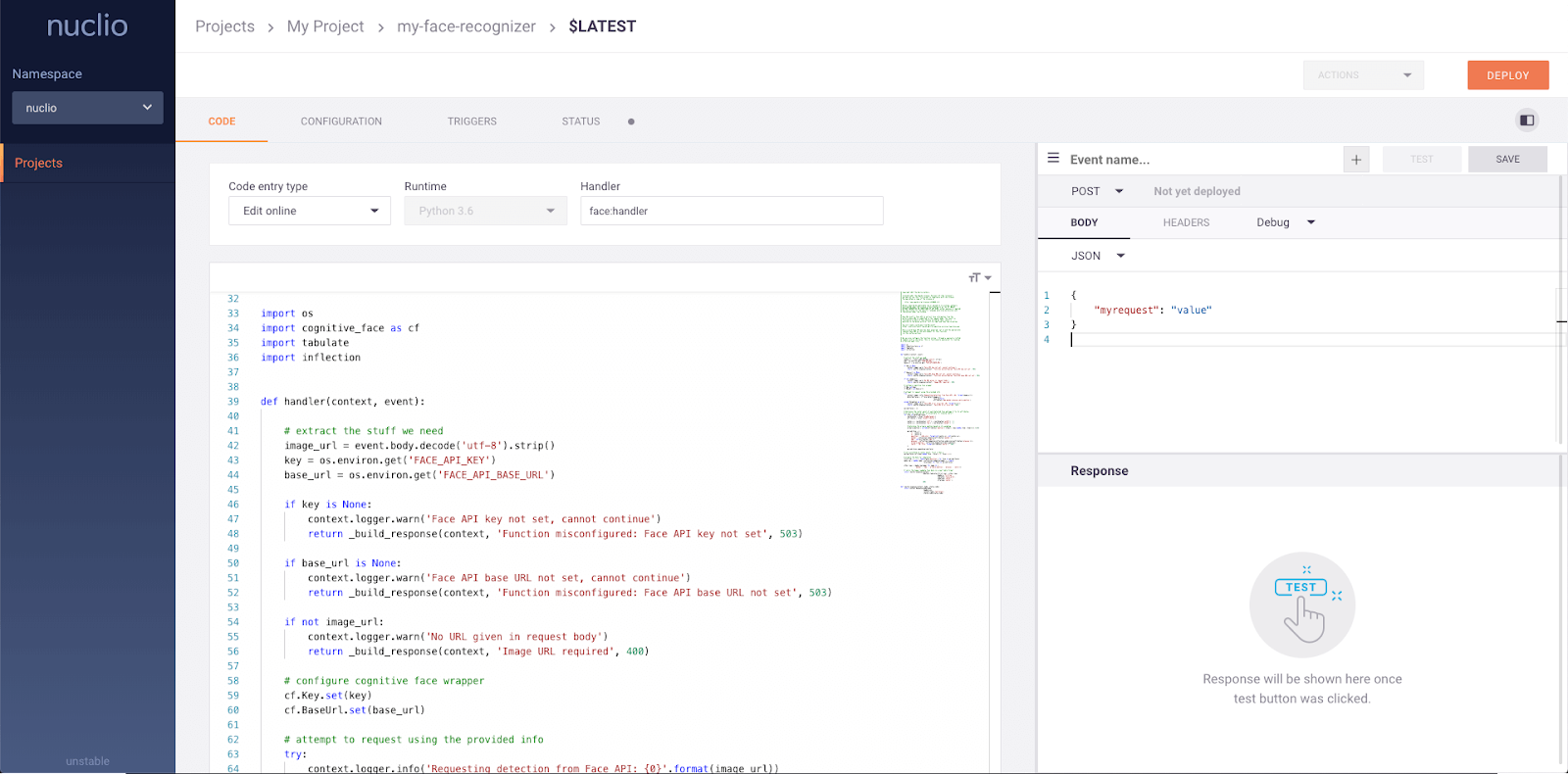
Hình từ Nuclio
Nếu bạn đang tìm một công cụ MLOps toàn diện hỗ trợ trong suốt quy trình, dưới đây là một vài lựa chọn tốt:
Amazon Web Services SageMaker là giải pháp một-cửa cho MLOps. Bạn có thể huấn luyện và tăng tốc phát triển mô hình, theo dõi và quản lý phiên bản thí nghiệm, lập danh mục artifact ML, tích hợp pipeline ML CI/CD, đồng thời triển khai, phục vụ và giám sát mô hình trong sản xuất một cách liền mạch.
Tính năng chính:
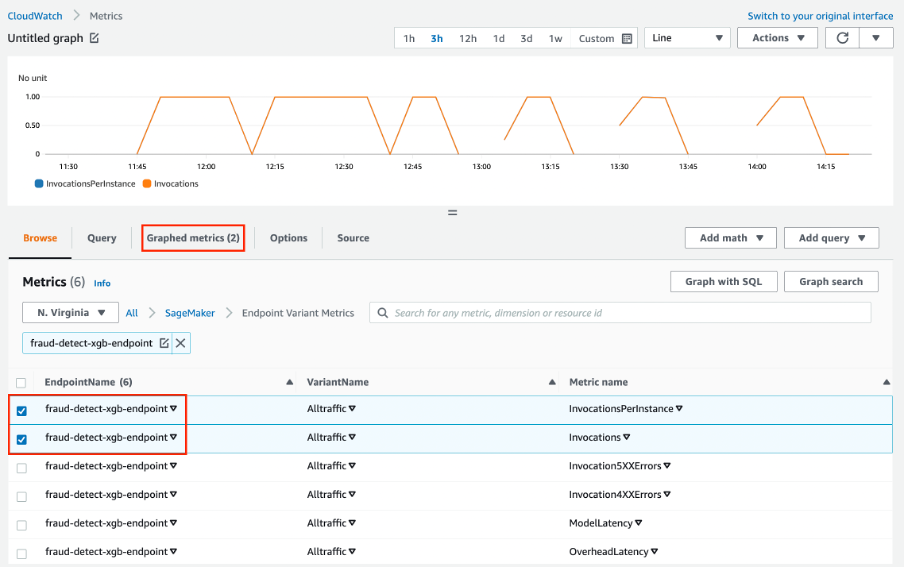
Hình từ Amazon SageMaker
DagsHub là nền tảng dành cho cộng đồng machine learning để theo dõi và quản lý phiên bản dữ liệu, mô hình, thí nghiệm, pipeline ML và mã. Nó cho phép nhóm của bạn xây dựng, rà soát và chia sẻ các dự án machine learning.
Nói đơn giản, đây là GitHub cho machine learning, và bạn có các công cụ khác nhau để tối ưu quy trình machine learning đầu-cuối.
Tính năng chính:
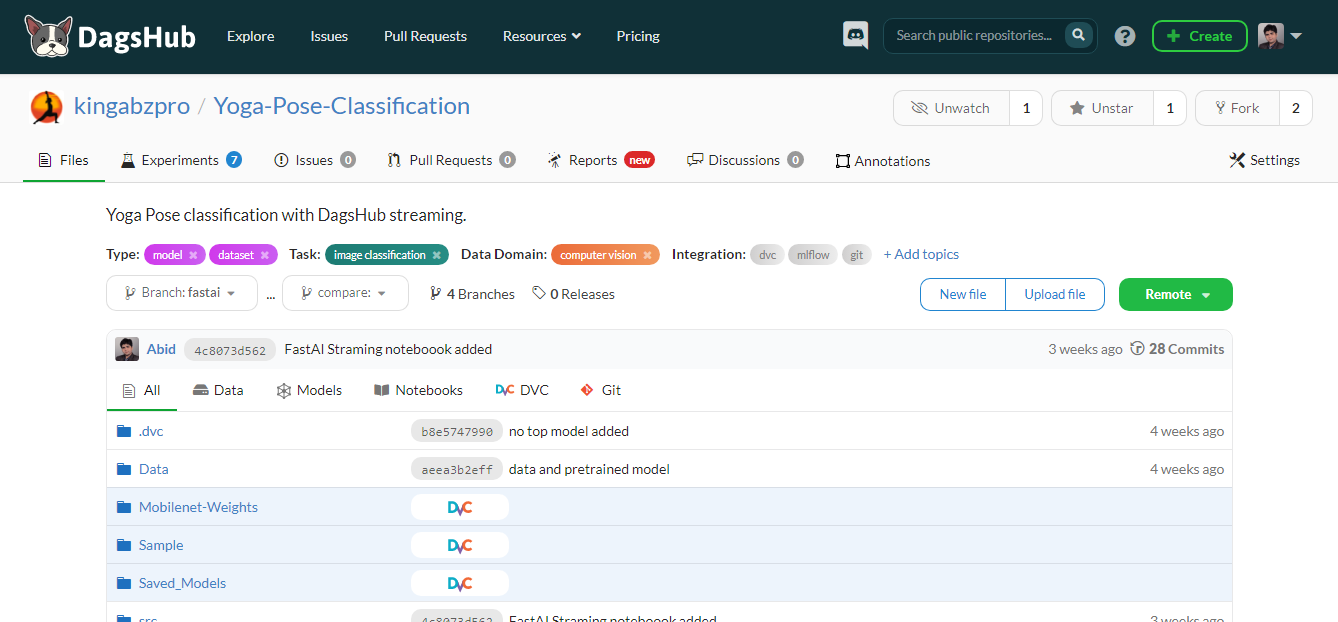
Hình bởi Tác giả
Nền tảng Iguazio MLOps là nền tảng MLOps đầu-cuối cho phép tổ chức tự động hóa pipeline machine learning từ thu thập và chuẩn bị dữ liệu đến huấn luyện, triển khai và giám sát trong sản xuất. Nó cung cấp nền tảng mở (MLRun) và được quản lý.
Một điểm khác biệt quan trọng của Nền tảng Iguazio MLOps là tính linh hoạt trong tùy chọn triển khai. Người dùng có thể triển khai ứng dụng AI ở bất cứ đâu, bao gồm mọi đám mây, môi trường hybrid hoặc on-premises. Điều này đặc biệt quan trọng với các ngành như y tế và tài chính, nơi yêu cầu về quyền riêng tư dữ liệu có thể đòi hỏi triển khai on-premises.
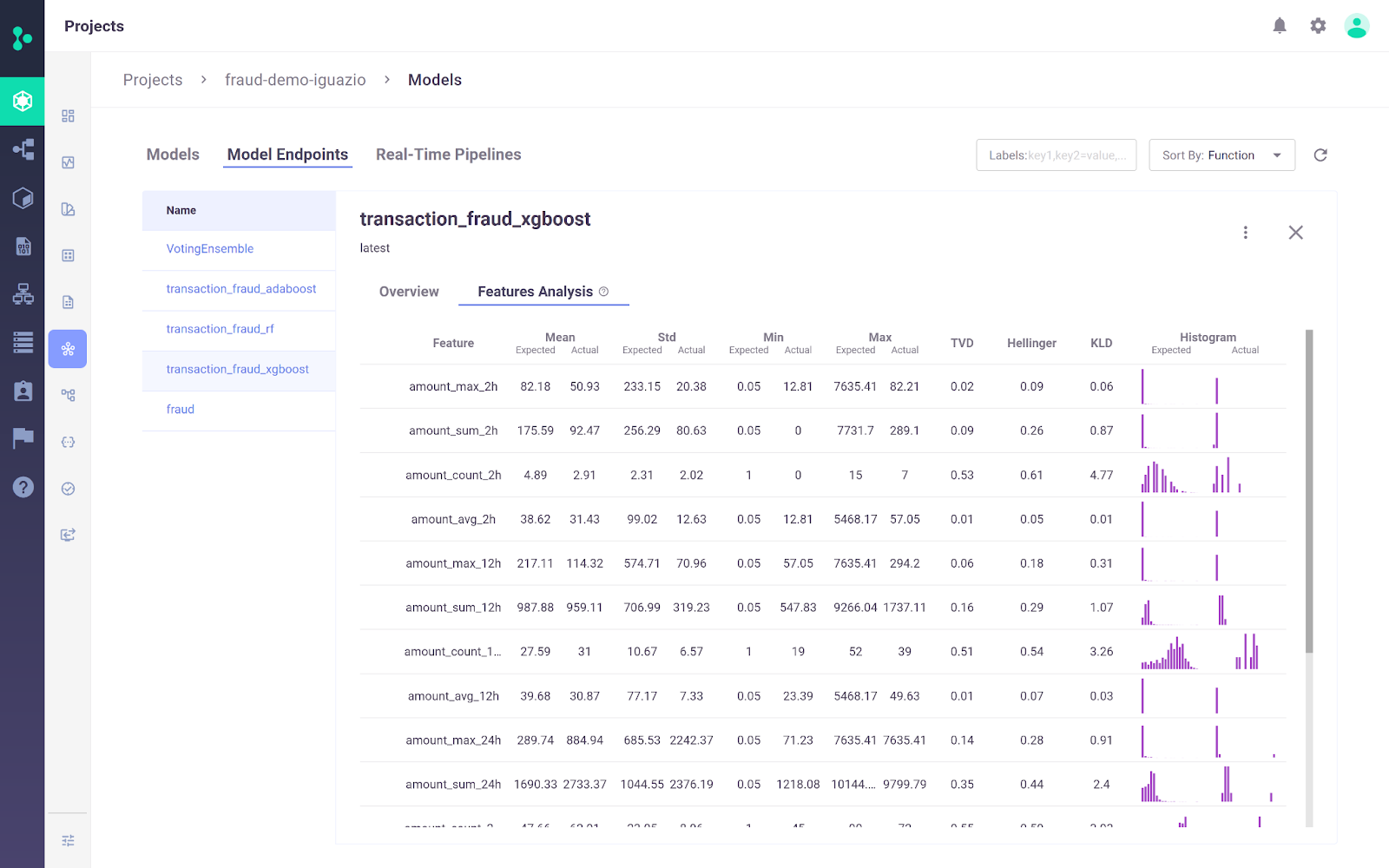
Hình từ Nền tảng Iguazio MLOps
Tính năng chính:
Đây là bảng so sánh để bạn có thể đánh giá các công cụ cạnh nhau và quyết định công cụ tốt nhất cho dự án của mình:
| Công cụ | Chức năng chính | Framework được hỗ trợ | Tùy chọn triển khai |
|---|---|---|---|
| Qdrant | Tìm kiếm tương đồng vector và quản lý cơ sở dữ liệu | Python, nhiều ngôn ngữ | Cloud-native, mở rộng ngang |
| LangChain | Phát triển ứng dụng với mô hình ngôn ngữ | Python, JavaScript | REST API, template |
| MLFlow | Theo dõi thí nghiệm, sổ đăng ký mô hình, triển khai | Python, R, Java, REST API | Cục bộ, đám mây |
| Comet ML | Theo dõi và tối ưu hóa thí nghiệm | Scikit-learn, PyTorch, TensorFlow, HuggingFace | Cục bộ, đám mây |
| Weights & Biases | Theo dõi thí nghiệm, quản lý phiên bản dữ liệu và mô hình | Fastai, Keras, PyTorch, HuggingFace, Yolov5, Spacy | Cục bộ, đám mây |
| Prefect | Điều phối và giám sát quy trình làm việc | Python | Cục bộ (Orion UI), Đám mây |
| Metaflow | Quản lý quy trình làm việc cho khoa học dữ liệu | Scikit-learn, TensorFlow, Python, R | AWS, GCP, Azure, cục bộ |
| Kedro | Điều phối quy trình làm việc, tái lập | Python | Cục bộ, phân tán |
| Pachyderm | Biến đổi dữ liệu, quản lý phiên bản và nguồn gốc | Bất kỳ ngôn ngữ nào | Kubernetes |
| DVC | Quản lý phiên bản dữ liệu và pipeline | Git, Python | Cục bộ, đám mây |
| LakeFS | Quản lý phiên bản kiểu Git cho data lake | Bất kỳ dịch vụ lưu trữ nào | Cục bộ, đám mây |
| Feast | Feature store tập trung cho mô hình ML | Python | Cục bộ, đám mây |
| Featureform | Feature store ảo cho mô hình ML | Python | Cục bộ, đám mây |
| Deepchecks | Kiểm thử và xác thực mô hình ML | Python | Cục bộ, đám mây |
| TruEra | Kiểm thử chất lượng và hiệu suất mô hình | Python | Cục bộ, đám mây |
| Kubeflow | Triển khai và điều phối mô hình ML | TensorFlow, PyTorch, PaddlePaddle, MXNet, XGboost | Kubernetes, đám mây |
| BentoML | Triển khai mô hình và quản lý API | Keras, ONNX, LightGBM, PyTorch, Scikit-learn | Cục bộ, đám mây |
| Hugging Face | Suy luận và triển khai mô hình | Bất kỳ mô hình nào | Đám mây |
| Evidently | Giám sát mô hình ML về trôi dữ liệu và trôi mục tiêu | Python | Cục bộ, đám mây |
| Fiddler | Giám sát và debug mô hình ML | Python | Cục bộ, đám mây |
| Ray | Mở rộng ứng dụng AI và Python | Python | Cục bộ, đám mây |
| Nuclio | Framework serverless cho khối lượng công việc nặng dữ liệu và tính toán | Jupyter, Kubeflow | Đám mây, on-premises |
| AWS SageMaker | Quản lý vòng đời ML đầu-cuối | Python, R, Java, TensorFlow, PyTorch | Đám mây AWS |
| DagsHub | Quản lý phiên bản và cộng tác cho dự án ML | Git, DVC, MLflow | Cục bộ, đám mây |
| Iguazio | Tự động hóa đầu-cuối các pipeline ML | Python, MLRun | Đám mây, hybrid, on-premises |
Chúng ta đang ở thời điểm ngành MLOps bùng nổ. Mỗi tuần lại có những phát triển mới, startup mới và công cụ mới ra mắt để giải quyết bài toán cơ bản: chuyển notebook thành ứng dụng sẵn sàng sản xuất. Ngay cả các công cụ hiện có cũng đang mở rộng tầm với và tích hợp tính năng mới để trở thành những siêu công cụ MLOps.
Trong blog này, chúng ta đã tìm hiểu các công cụ MLOps tốt nhất cho từng bước trong quy trình MLOps. Những công cụ này sẽ giúp bạn trong giai đoạn thí nghiệm, phát triển, triển khai và giám sát.
Nếu bạn mới làm quen với machine learning và muốn thành thạo các kỹ năng thiết yếu để giành được vị trí nhà khoa học machine learning, hãy thử lộ trình nghề nghiệp Machine Learning Scientist with Python của chúng tôi.
Nếu bạn là chuyên gia và muốn tìm hiểu thêm về các thực hành MLOps tiêu chuẩn, hãy đọc bài viết Các thực hành MLOps tốt nhất và cách áp dụng và xem Skill Track MLOps Fundamentals.
Tìm hiểu thêm về MLOps với các khóa học này!
Courses
Courses
Courses
blogs
Matt Crabtree
10 phút