
Curso
Conceitos de MLOps
2 h
42.6K
Saiba como trabalhar com LLMs em Python diretamente em seu navegador

Com a introdução do GPT-4 e, posteriormente, do GPT-4o, começou a corrida para produzir grandes modelos de linguagem e realizar todo o potencial da IA moderna. Os LLMs exigem bancos de dados vetoriais e estruturas de integração para a criação de aplicativos inteligentes de IA.
O Qdrant é um mecanismo de pesquisa de similaridade vetorial de código aberto e um banco de dados vetorial que fornece um serviço pronto para produção com uma API conveniente, permitindo que você armazene, pesquise e gerencie embeddings vetoriais.
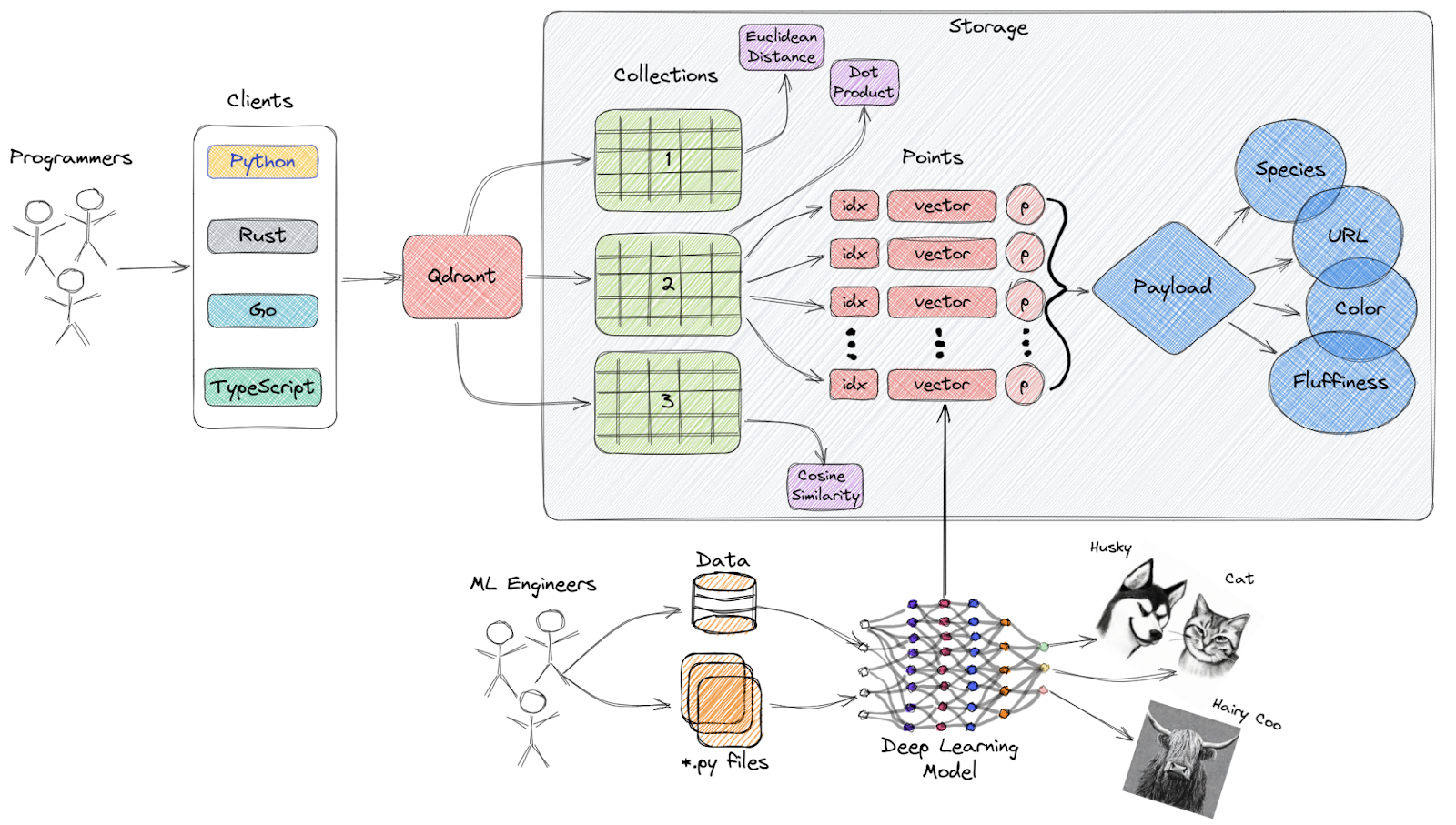
Visão geral de alto nível da arquitetura da Qdrant
Principais recursos:
Descubra os principais bancos de dados vetoriais lendo Os 5 melhores bancos de dados vetoriais: uma lista com exemplos.
O LangChain é uma estrutura versátil e avançada para o desenvolvimento de aplicativos alimentados por modelos de linguagem. Ele oferece vários componentes para permitir que os desenvolvedores criem, implantem e monitorem aplicativos com reconhecimento de contexto e baseados em raciocínio.
A estrutura consiste em quatro componentes principais:
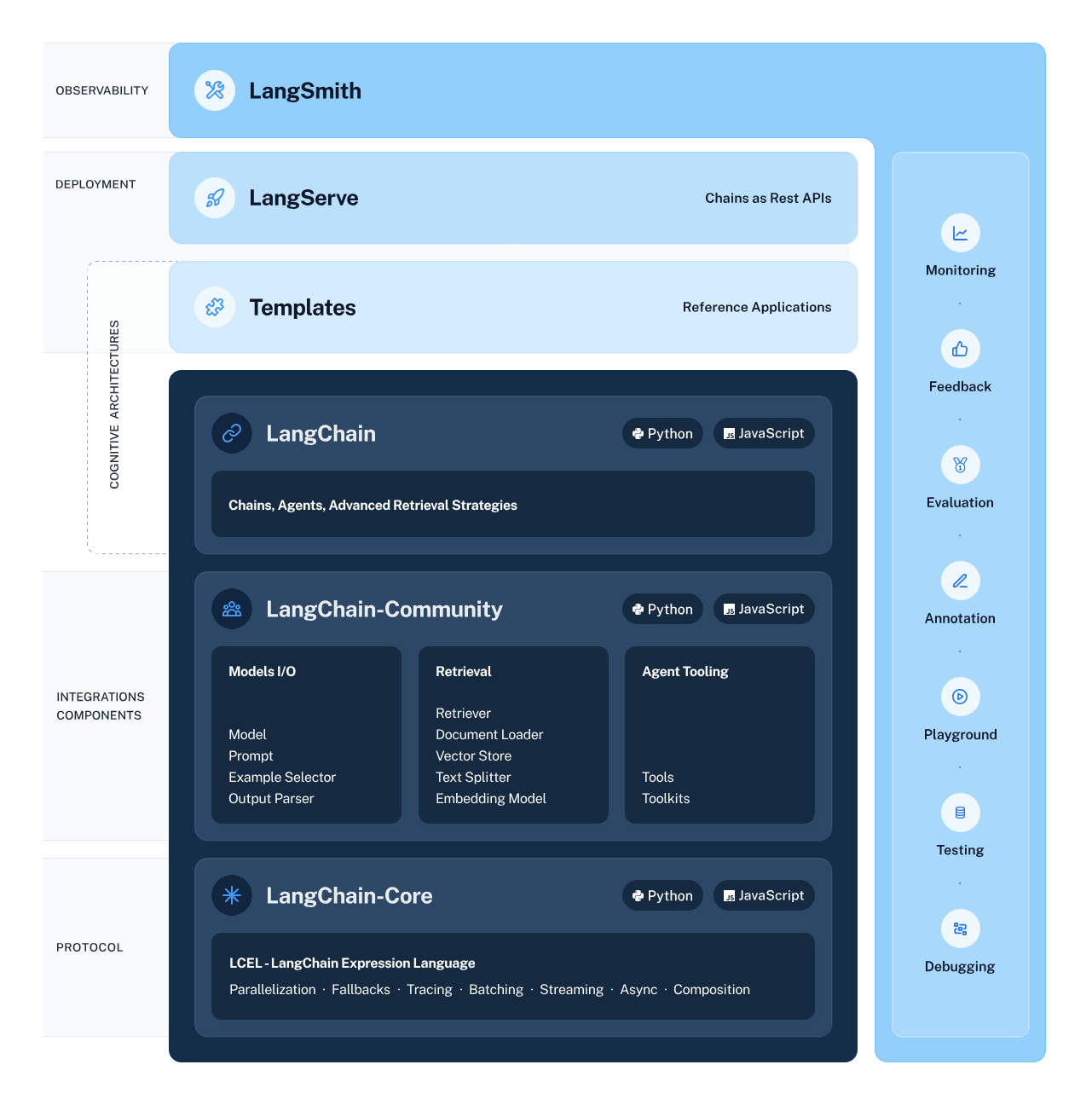
LangChain Ecosystem
Saiba como criar aplicativos LLM com o LangChain e explore o potencial inexplorado de modelos de linguagem grandes.
Essas ferramentas permitem que você gerencie os metadados do modelo e ajudam no rastreamento de experimentos:
O MLflow é uma ferramenta de código aberto que ajuda você a gerenciar as partes principais do ciclo de vida do aprendizado de máquina. Geralmente, ele é usado para rastreamento de experimentos, mas você também pode usá-lo para reprodutibilidade, implantação e registro de modelos. Você pode gerenciar os experimentos de aprendizado de máquina e os metadados do modelo usando CLI, Python, R, Java e API REST.
O MLflow tem quatro funções principais:
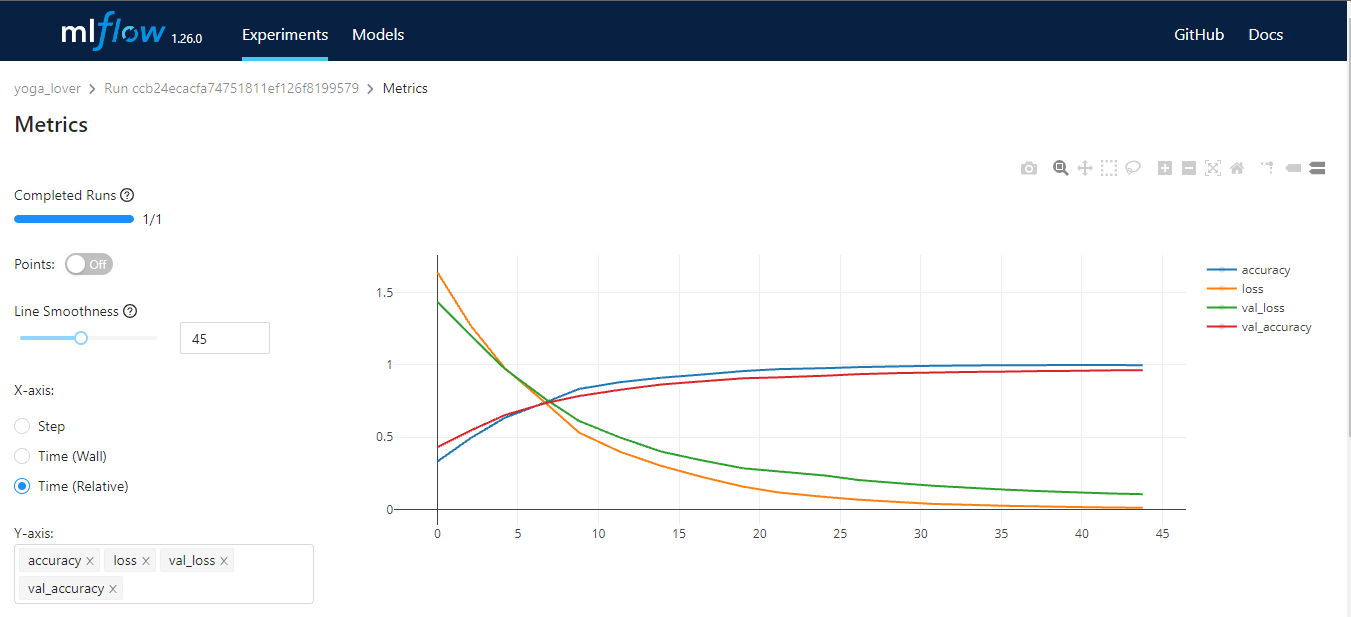
Imagem do autor
O Comet ML é uma plataforma para rastrear, comparar, explicar e otimizar modelos e experimentos de aprendizado de máquina. Você pode usá-lo com qualquer biblioteca de aprendizado de máquina, como Scikit-learn, Pytorch, TensorFlow e HuggingFace.
O Comet ML destina-se a indivíduos, equipes, empresas e acadêmicos. Ele permite que qualquer pessoa visualize e compare facilmente os experimentos. Além disso, ele permite que você visualize amostras de imagens, áudio, texto e dados tabulares.
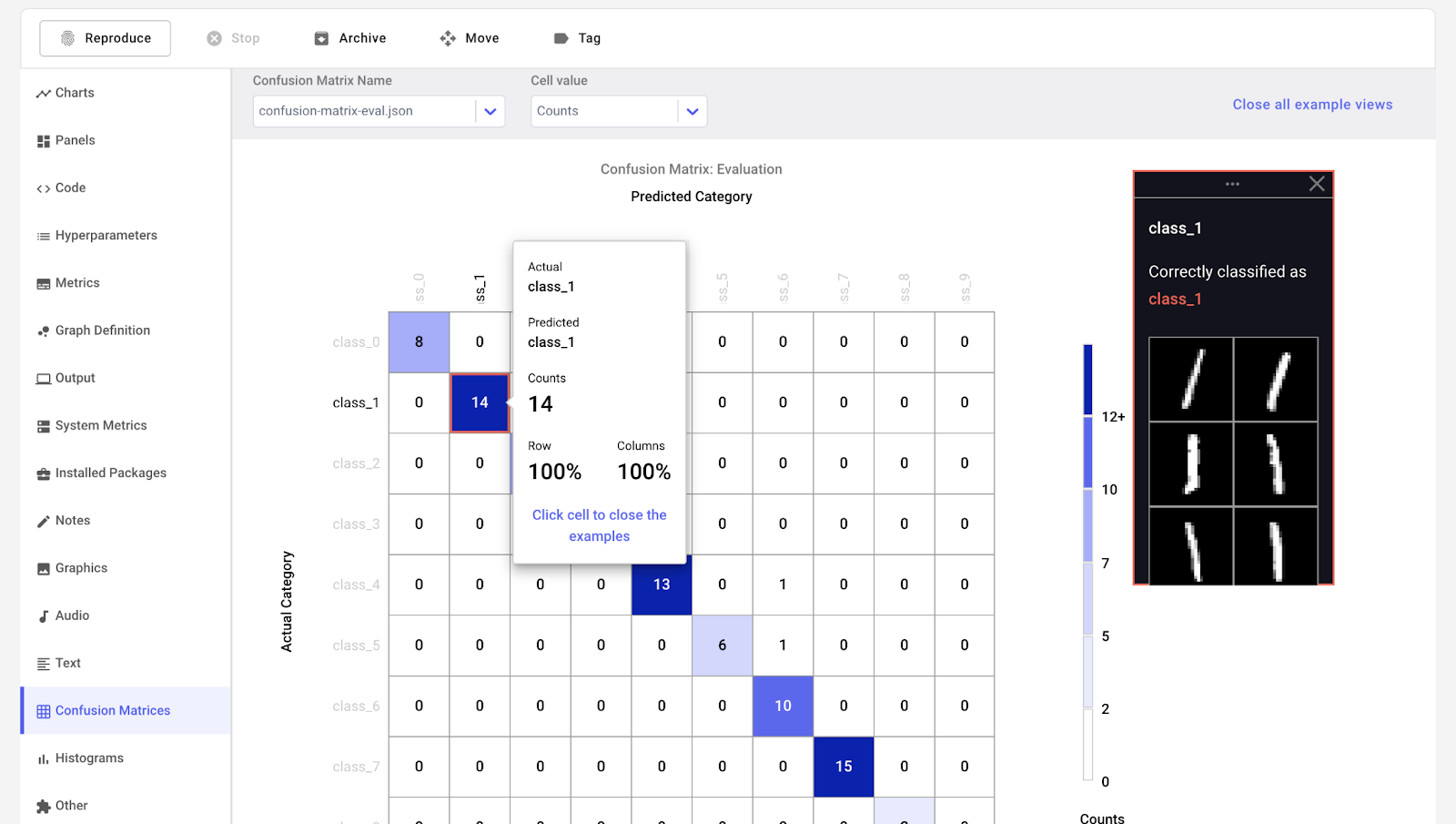
Imagem do Comet ML
O Weights & Biases é uma plataforma de ML para rastreamento de experimentos, versão de dados e modelos, otimização de hiperparâmetros e gerenciamento de modelos. Além disso, você pode usá-lo para registrar artefatos (conjuntos de dados, modelos, dependências, pipelines e resultados) e visualizar os conjuntos de dados (áudio, visual, texto e tabular).
O Weights & Biases tem um painel central de fácil utilização para experimentos de aprendizado de máquina. Assim como o Comet ML, você pode integrá-lo a outras bibliotecas de aprendizado de máquina, como Fastai, Keras, PyTorch, Hugging Face, Yolov5, Spacy e muitas outras. Você pode conferir nossa introdução a Weights & Bases em um artigo separado.
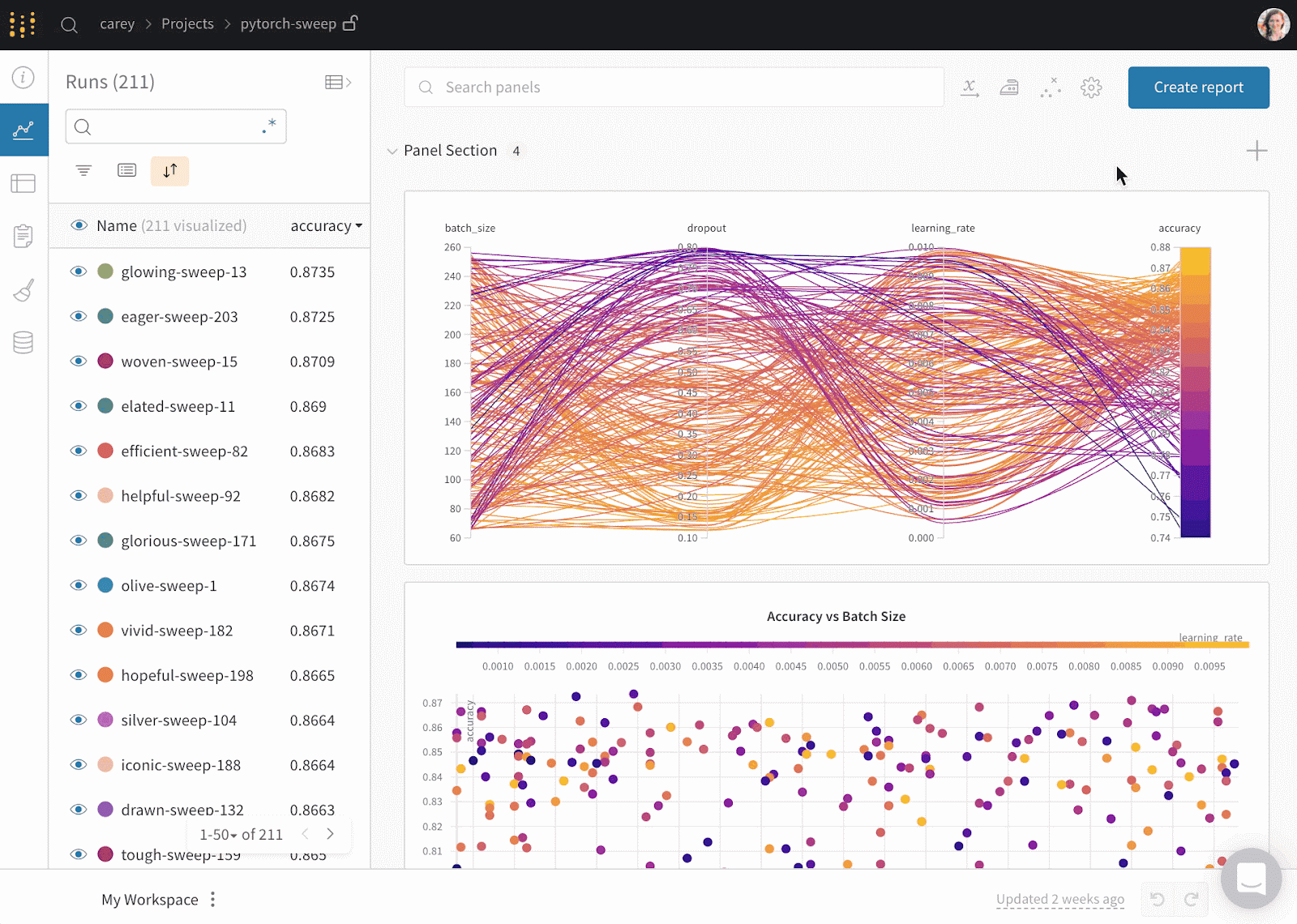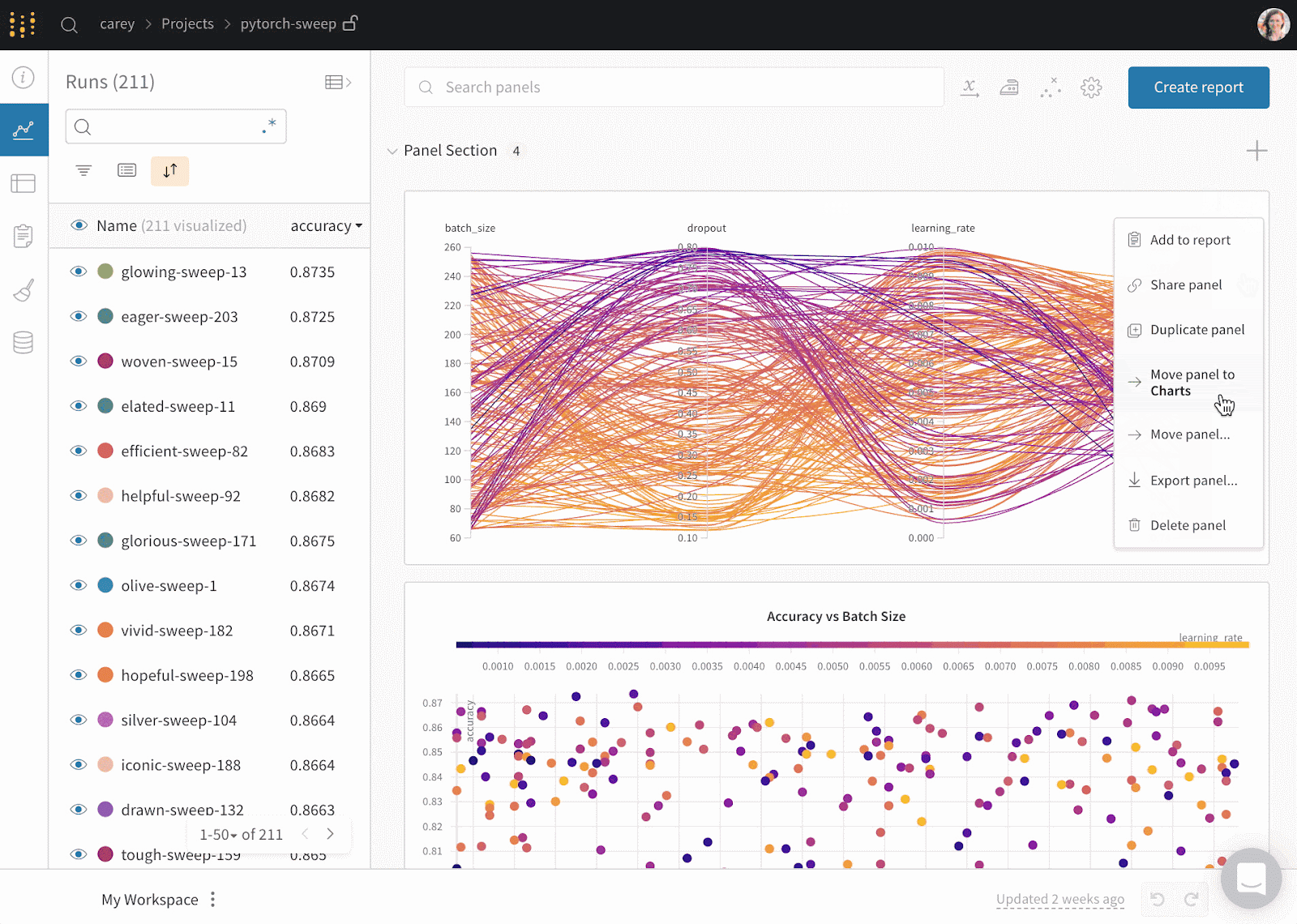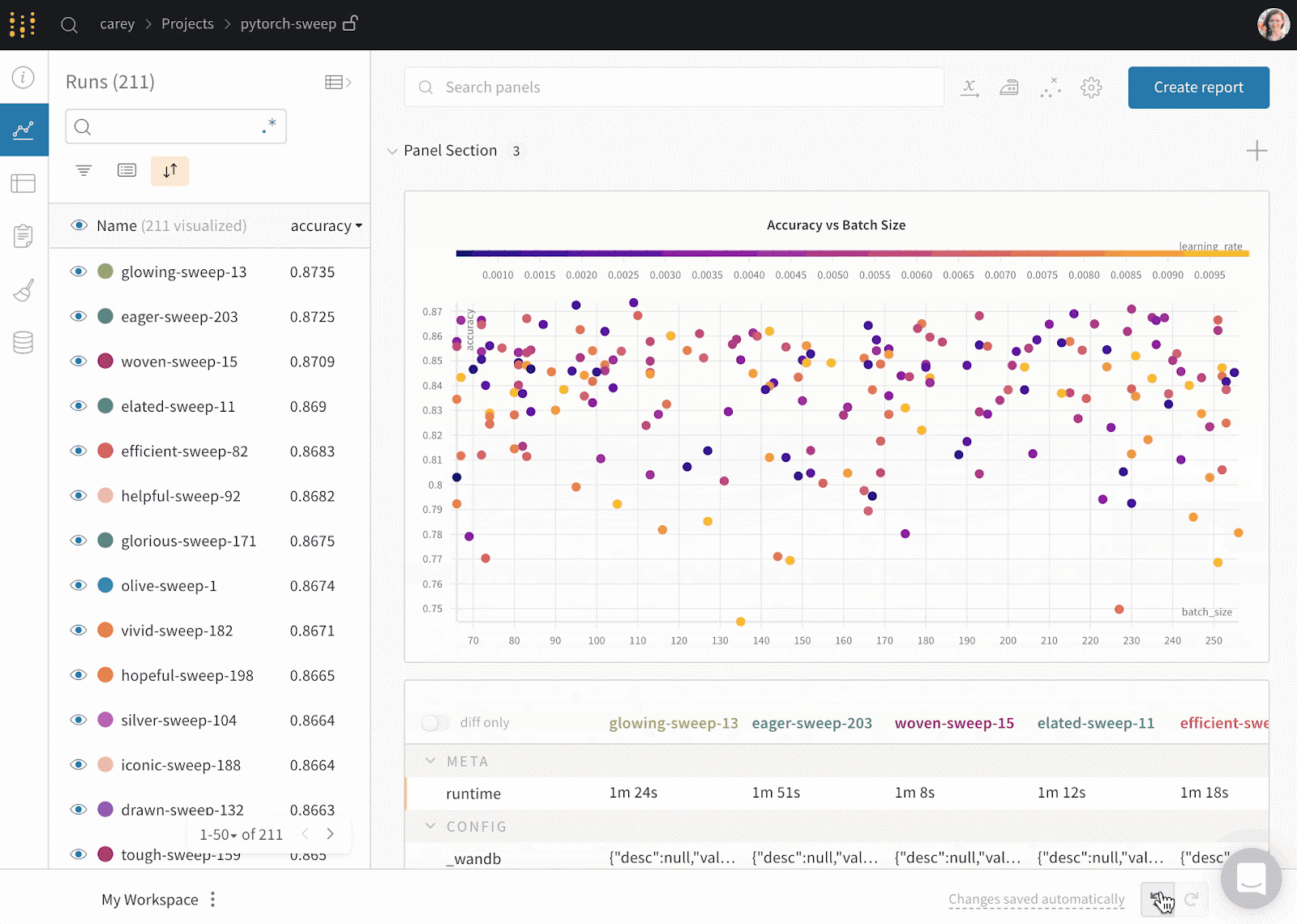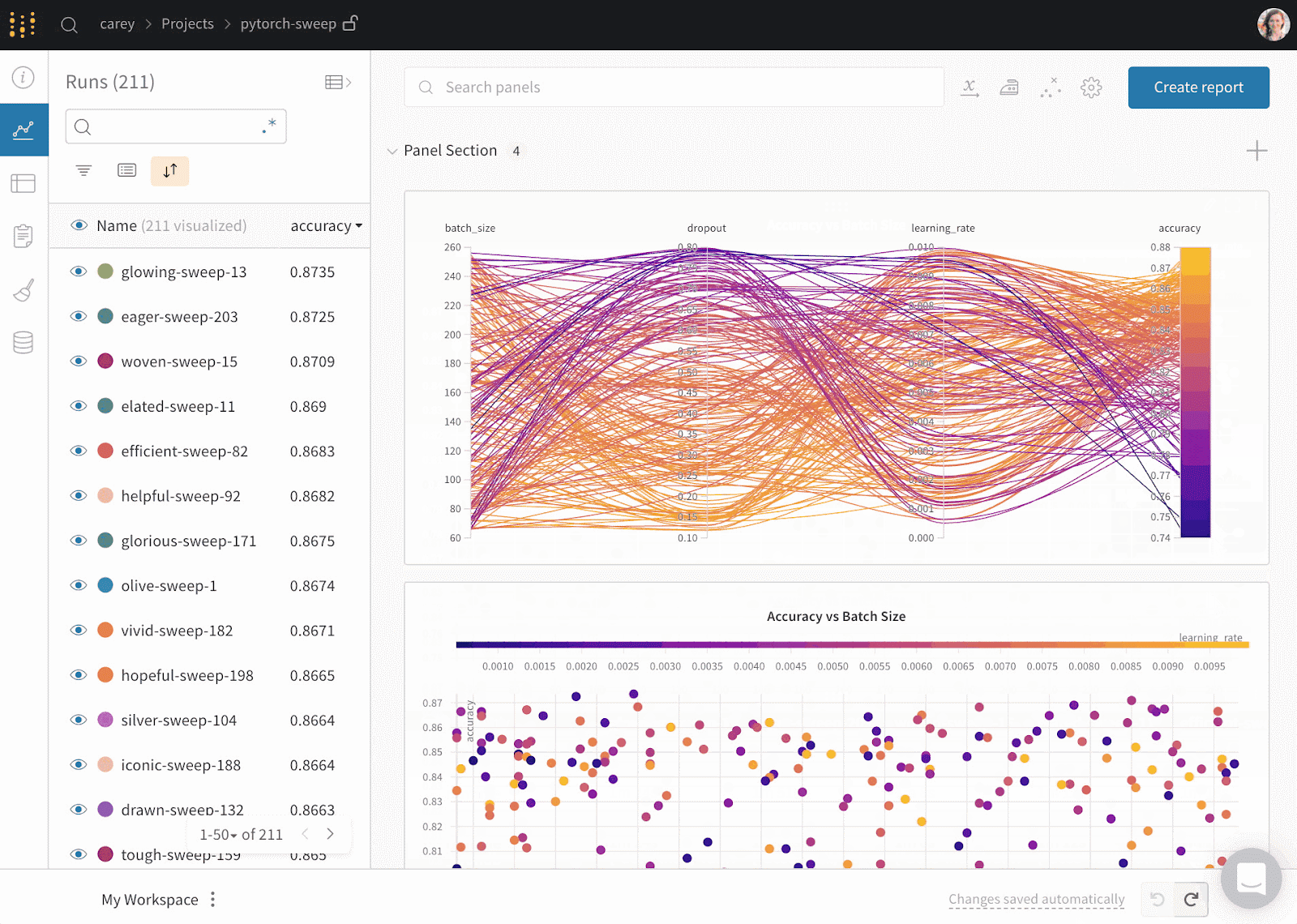
Gif de Weights & Biases
Observação: Você também pode usar o TensorBoard, o Pachyderm, o DagsHub e o DVC Studio para rastreamento de experimentos e gerenciamento de metadados de ML.
Essas ferramentas ajudam você a criar projetos de ciência de dados e gerenciar fluxos de trabalho de aprendizado de máquina:
O Prefect é uma pilha de dados moderna para monitorar, coordenar e orquestrar fluxos de trabalho entre aplicativos. É uma ferramenta leve e de código aberto criada para pipelines de aprendizado de máquina de ponta a ponta.
Você pode usar o Prefect Orion UI ou o Prefect Cloud para os bancos de dados.
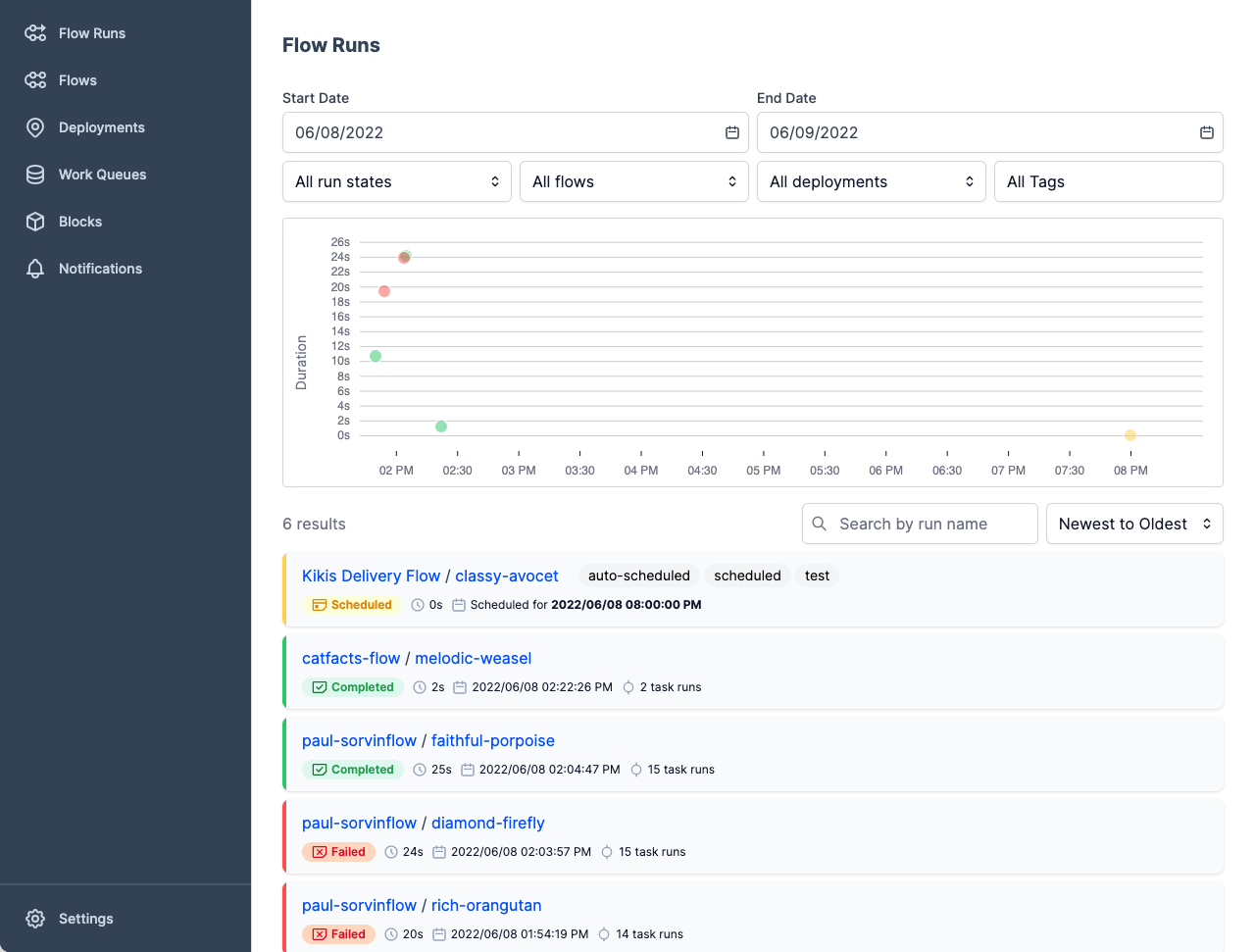
Imagem da Prefect
O Metaflow é uma ferramenta de gerenciamento de fluxo de trabalho avançada e resistente a batalhas para projetos de ciência de dados e aprendizado de máquina. Ele foi desenvolvido para cientistas de dados, para que eles possam se concentrar na criação de modelos em vez de se preocupar com a engenharia de MLOps.
Com o Metaflow, você pode projetar o fluxo de trabalho, executá-lo em escala e implantar o modelo na produção. Ele rastreia e versiona automaticamente os dados e os experimentos de aprendizado de máquina. Além disso, você pode visualizar os resultados no notebook.
O Metaflow funciona com várias nuvens (incluindo AWS, GCP e Azure) e vários pacotes Python de aprendizado de máquina (como Scikit-learn e Tensorflow), e a API também está disponível para a linguagem R.
Imagem da Metaflow
O Kedro é uma ferramenta de orquestração de fluxo de trabalho baseada em Python. Você pode usá-lo para criar projetos de ciência de dados reproduzíveis, passíveis de manutenção e modulares. Ele integra os conceitos da engenharia de software ao aprendizado de máquina, como modularidade, separação de preocupações e controle de versão.
Com o Kedro, você pode:
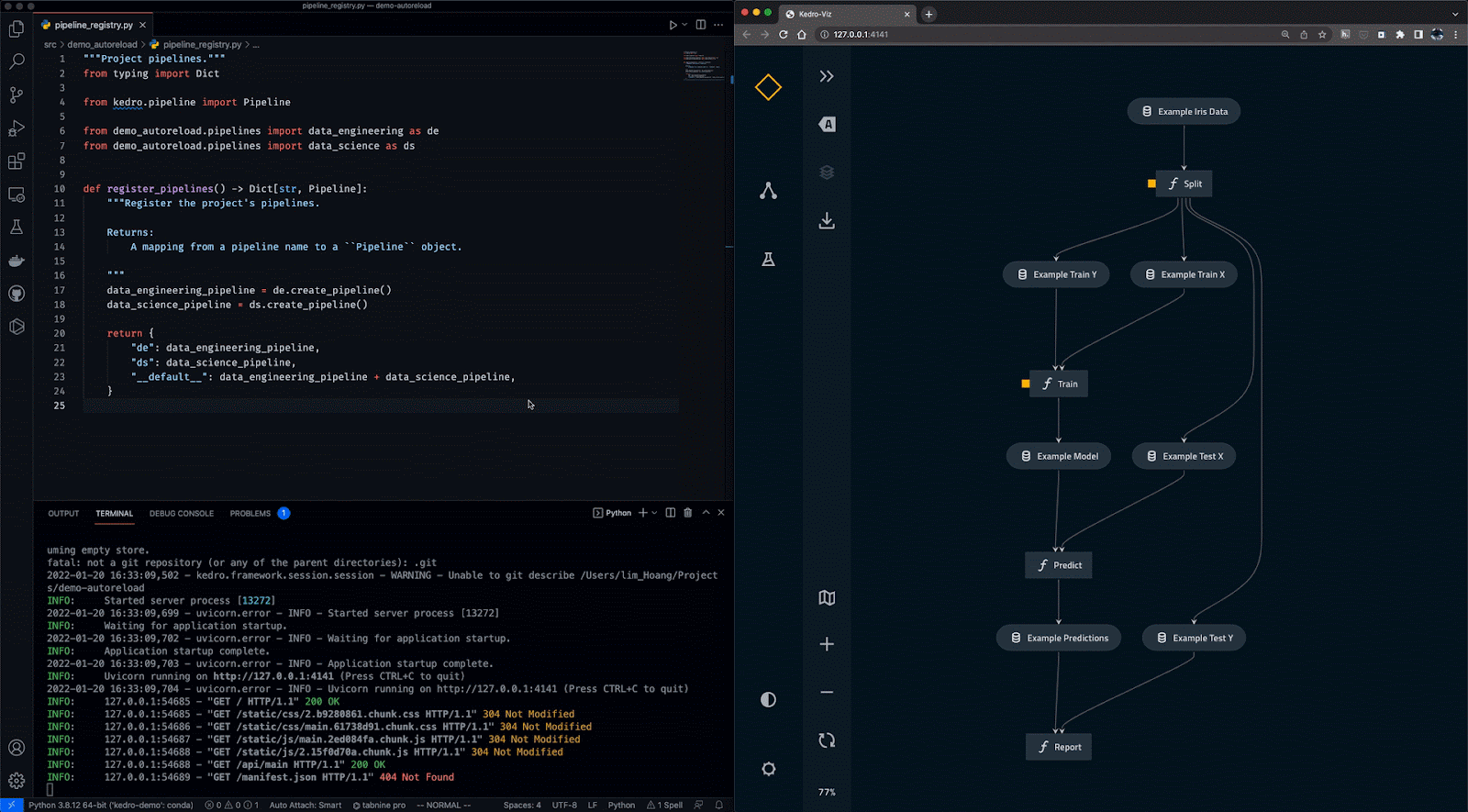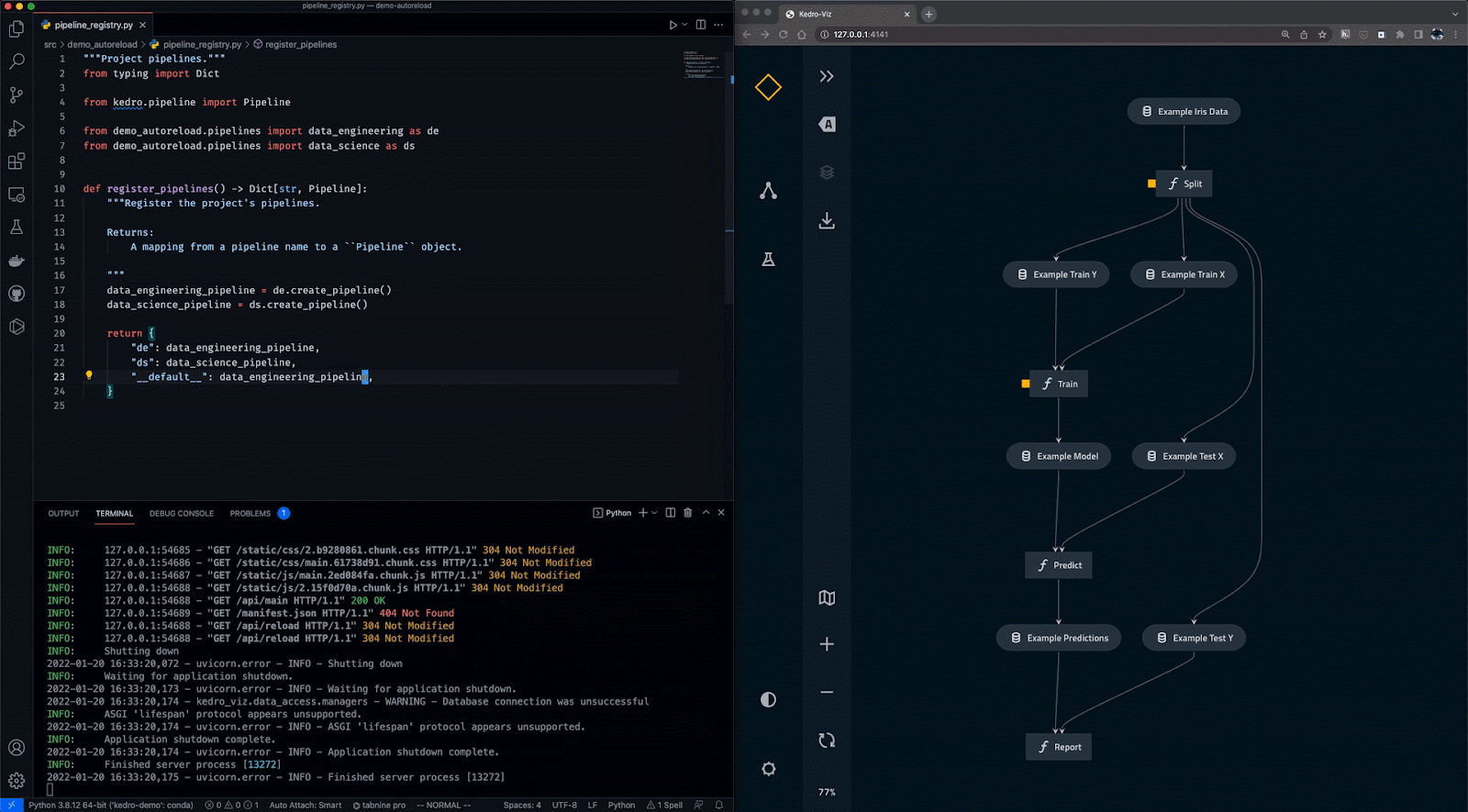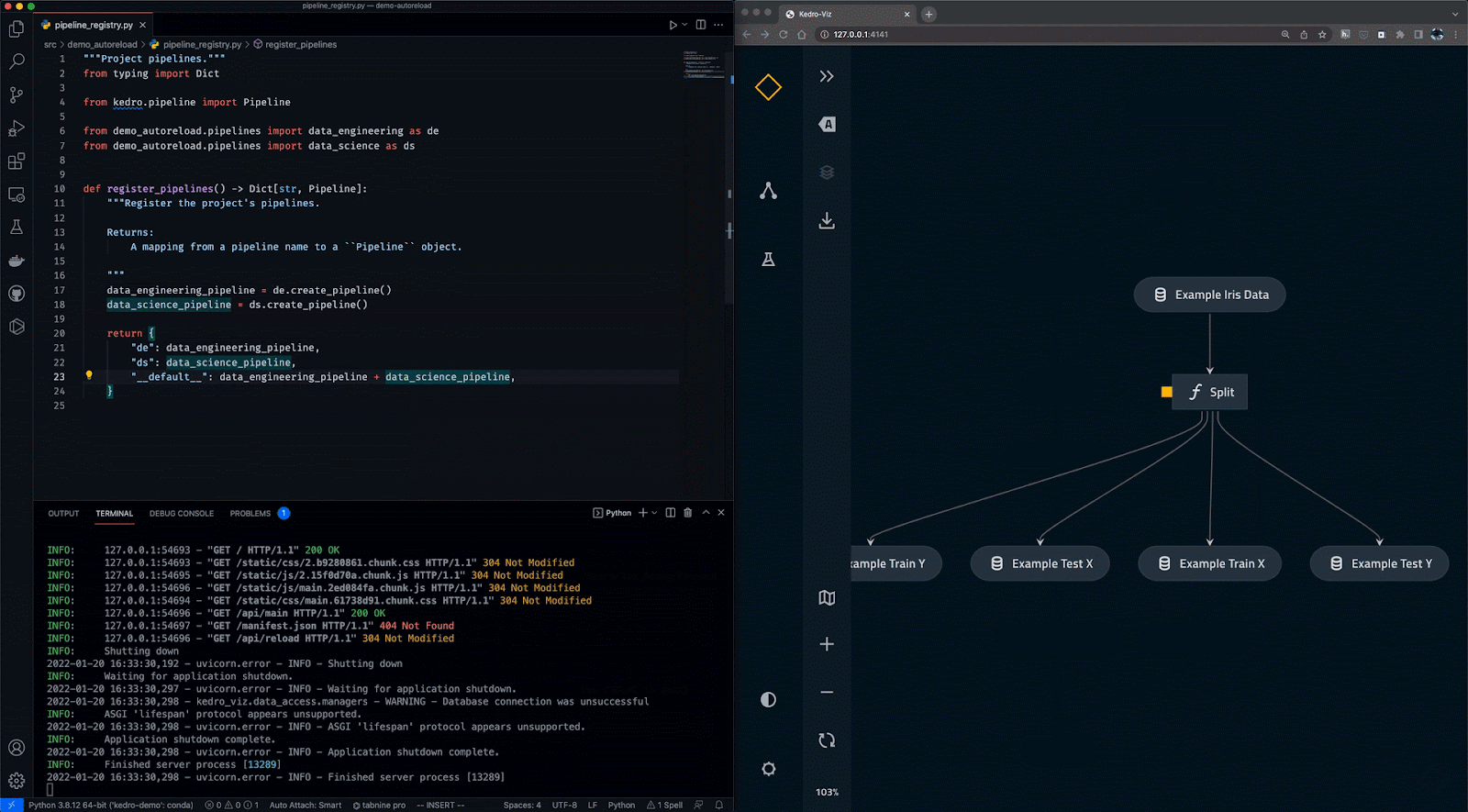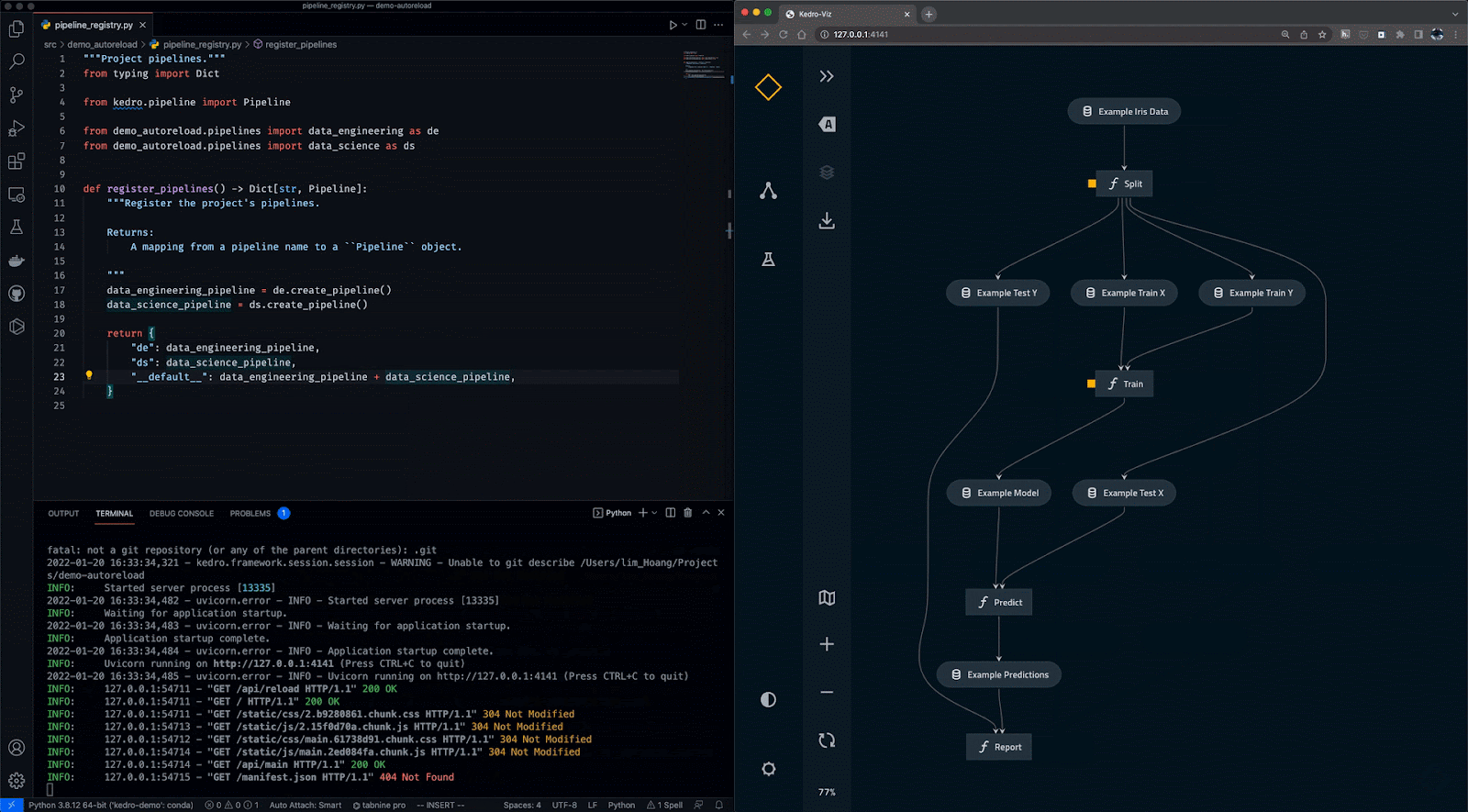
Gif de Kedro
Observação: você também pode usar o Kubeflow e o DVC para orquestração e pipelines de fluxo de trabalho.
Com essas ferramentas de MLOps, você pode gerenciar tarefas relacionadas a dados e controle de versão de pipeline:
O Pachyderm automatiza a transformação de dados com controle de versão de dados, linhagem e pipelines de ponta a ponta no Kubernetes. Você pode fazer a integração com qualquer dado (imagens, logs, vídeo, CSVs), qualquer linguagem (Python, R, SQL, C/C++) e em qualquer escala (Petabytes de dados, milhares de trabalhos).
A edição comunitária é de código aberto e para uma equipe pequena. As organizações e equipes que desejam recursos avançados podem optar pela edição Enterprise.
Assim como o Git, você pode versionar seus dados usando uma sintaxe semelhante. No Pachyderm, o nível mais alto do objeto é o Repositório, e você pode usar Commit, Branches, File, History e Provenance para rastrear e versionar o conjunto de dados.
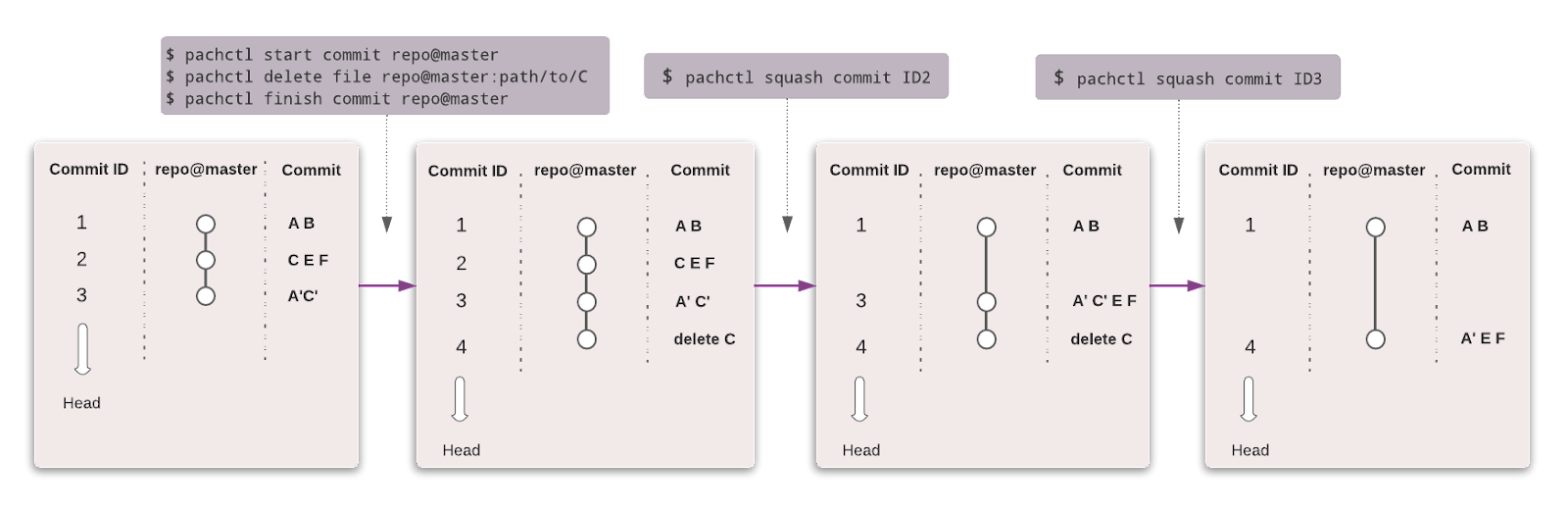
Imagem de Pachyderm
O Data Version Control é uma ferramenta popular e de código aberto para projetos de aprendizado de máquina. Ele funciona perfeitamente com o Git para fornecer a você versões de código, dados, modelos, metadados e pipeline.
O DVC é mais do que apenas uma ferramenta de controle de dados e controle de versão.
Você pode usá-lo para:
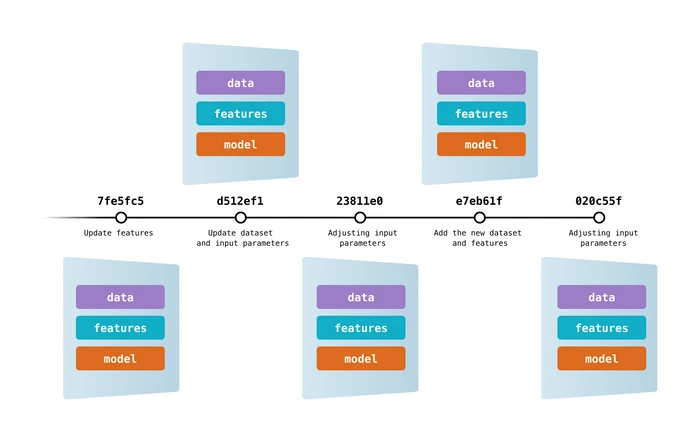
Imagem do DVC
Observação: O DagsHub também pode ser usado para controle de versão de dados e pipeline.
O LakeFS é uma ferramenta de controle de versão de dados dimensionável e de código aberto que fornece uma interface de controle de versão semelhante à do Git para armazenamento de objetos, permitindo que os usuários gerenciem seus lagos de dados como fariam com seu código. Com o LakeFS, os usuários podem controlar a versão dos dados em escala de exabytes, o que o torna uma solução altamente dimensionável para o gerenciamento de grandes lagos de dados.
Recursos adicionais:
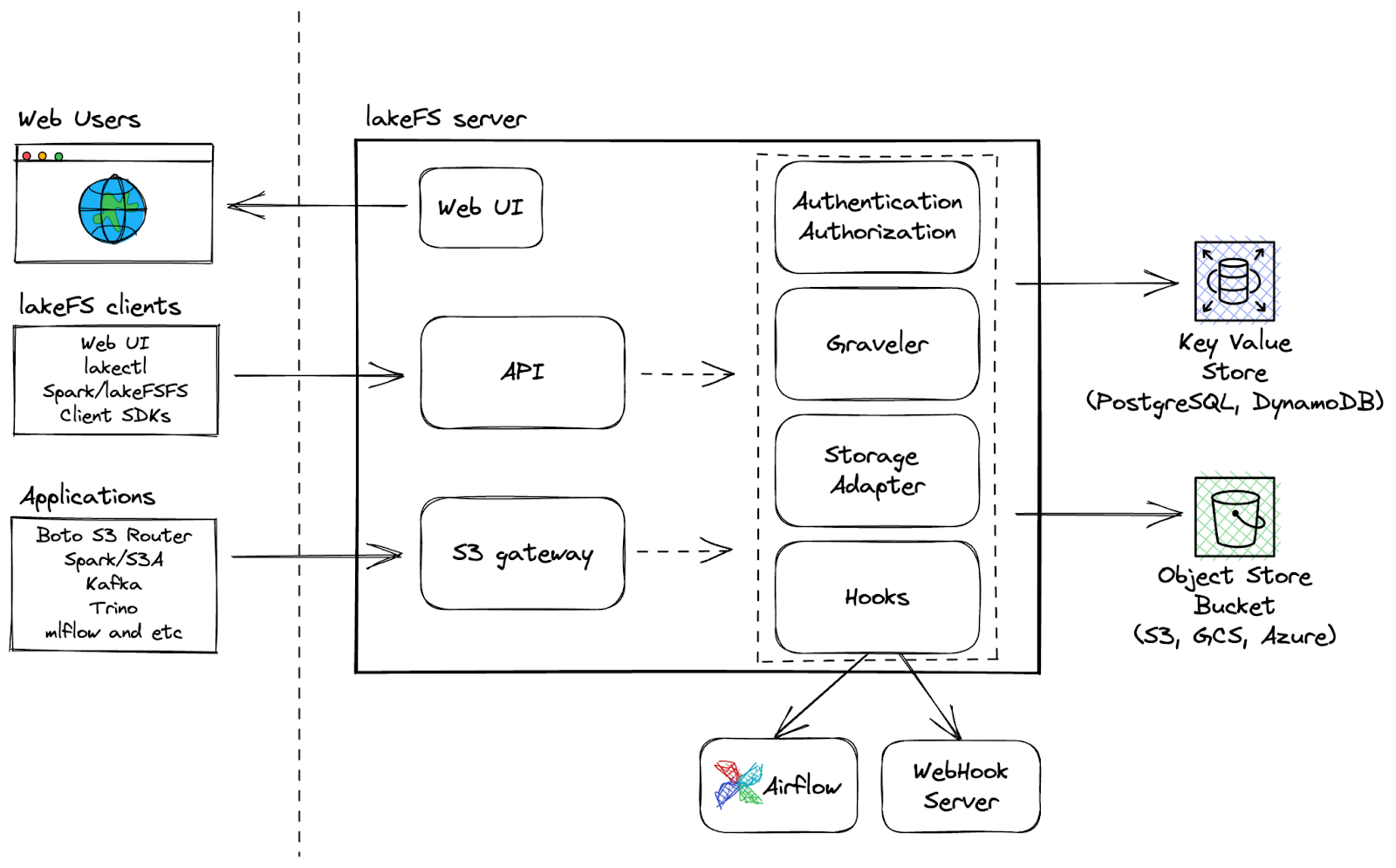
LakeFS Architecture
Os repositórios de recursos são repositórios centralizados para armazenamento, controle de versão, gerenciamento e fornecimento de recursos (atributos de dados processados usados para treinar modelos de aprendizado de máquina) para modelos de aprendizado de máquina em produção e também para fins de treinamento.
O Feast é um armazenamento de recursos de código aberto que ajuda as equipes de aprendizado de máquina a produzir modelos em tempo real e a criar uma plataforma de recursos que promove a colaboração entre engenheiros e cientistas de dados.
Principais recursos:
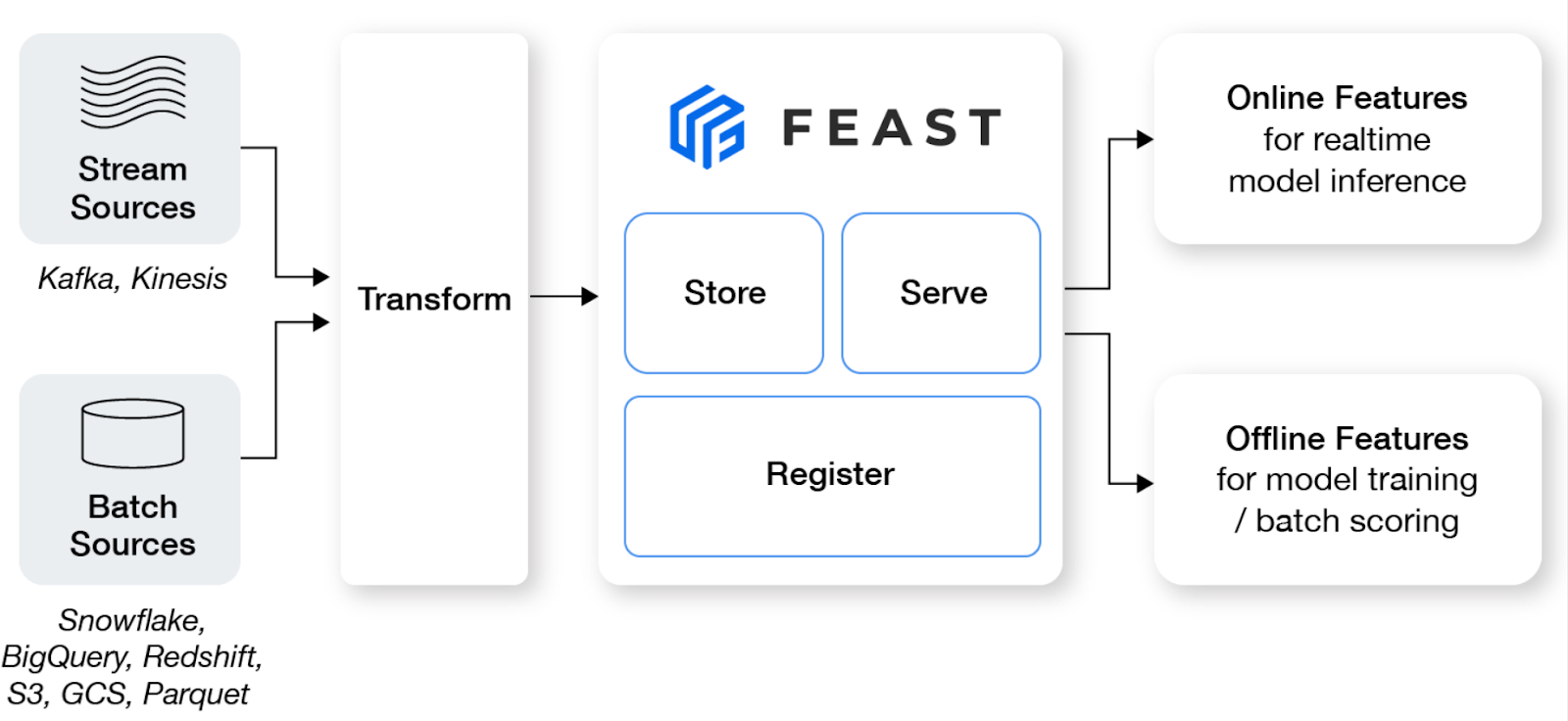
Imagem de Feast
O Featureform é um armazenamento virtual de recursos que permite que os cientistas de dados definam, gerenciem e atendam aos recursos de seus modelos de ML. Ele pode ajudar as equipes de ciência de dados a aprimorar a colaboração, organizar a experimentação, facilitar a implantação, aumentar a confiabilidade e preservar a conformidade.
Principais recursos:
Imagem do Featureform
Com essas ferramentas de MLOps, você pode testar a qualidade do modelo e garantir a confiabilidade, a robustez e a precisão dos modelos de aprendizado de máquina:
O Deepchecks é uma solução de código aberto que atende a todas as suas necessidades de validação de ML, garantindo que seus dados e modelos sejam totalmente testados, desde a pesquisa até a produção. Ele oferece uma abordagem holística para validar seus dados e modelos por meio de seus vários componentes.
Imagem de Deepchecks
O Deepchecks consiste em três componentes:
O TruEra é uma plataforma avançada projetada para impulsionar a qualidade e o desempenho do modelo por meio de testes automatizados, explicabilidade e análise de causa raiz. Ele oferece vários recursos para ajudar a otimizar e depurar modelos, obter a melhor explicabilidade da categoria e integrar-se facilmente à sua pilha de tecnologia de ML.
Principais recursos:
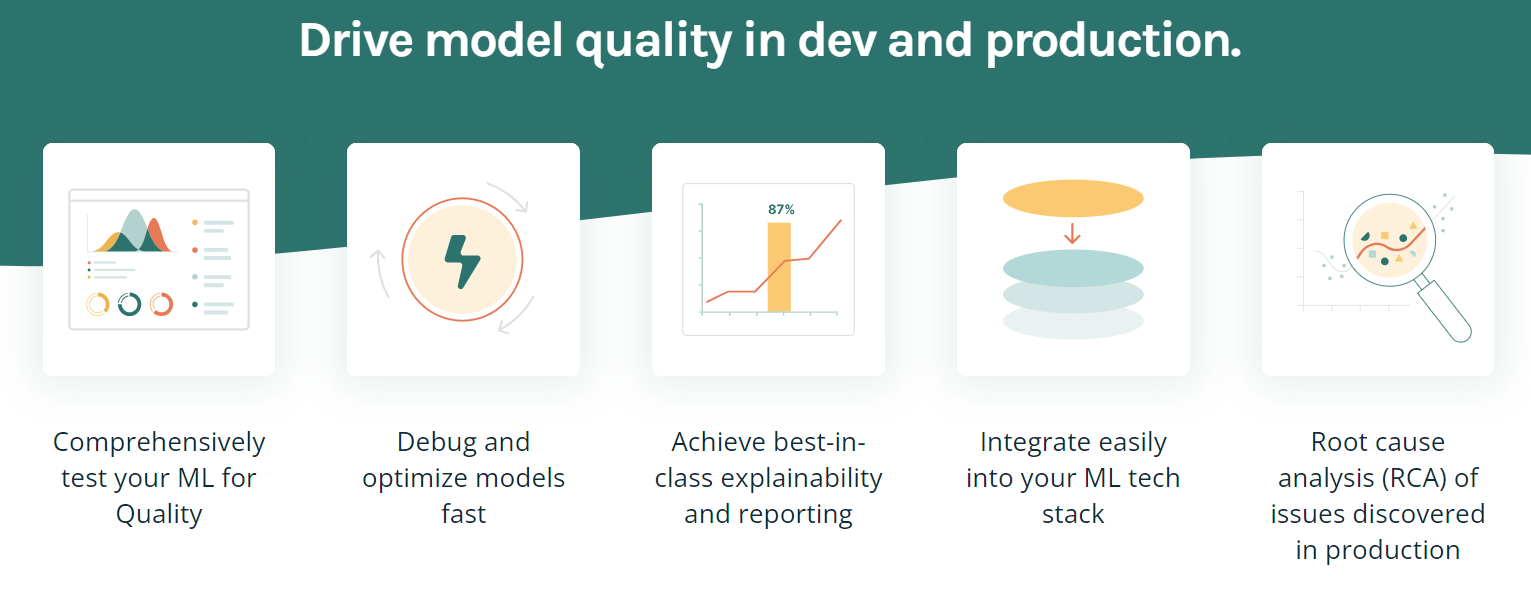
Imagem por TruEra
Quando se trata de implementar modelos, essas ferramentas de MLOps podem ser extremamente úteis:
O Kubeflow torna a implantação do modelo de aprendizado de máquina no Kubernetes simples, portátil e dimensionável. Você pode usá-lo para a preparação de dados, treinamento de modelos, otimização de modelos, serviço de previsão e motorização do desempenho do modelo na produção. Você pode implementar o fluxo de trabalho de aprendizado de máquina localmente, no local ou na nuvem. Em resumo, ele torna o Kubernetes fácil para as equipes de ciência de dados.
Principais recursos:
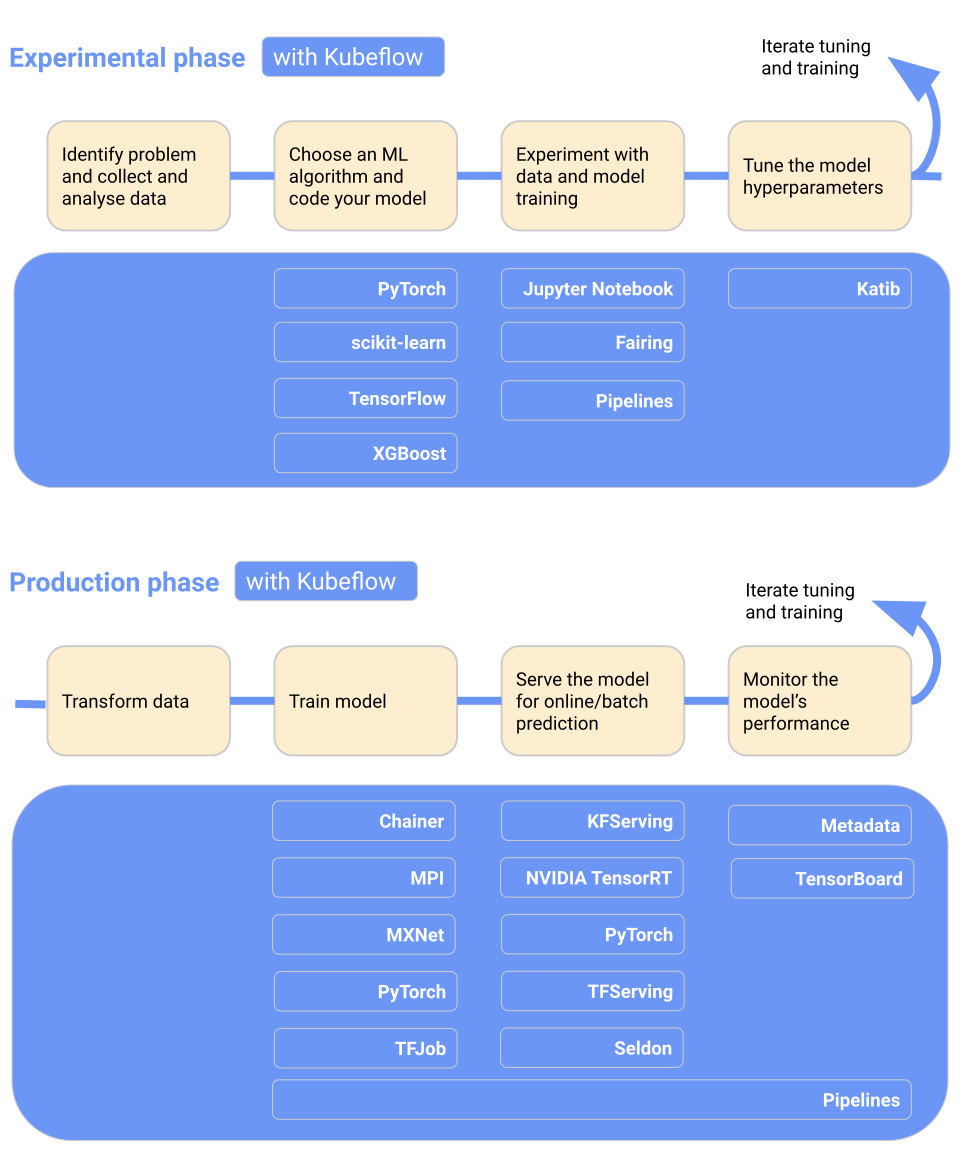
Imagem do Kubeflow
O BentoML facilita e agiliza o envio de aplicativos de aprendizado de máquina. É uma ferramenta baseada em Python para implantação e manutenção de APIs na produção. Ele é dimensionado com otimizações avançadas, executando inferência paralela e agrupamento adaptável, e oferece aceleração de hardware.
O painel centralizado e interativo do BentoML facilita a organização e o monitoramento da implementação de modelos de aprendizado de máquina. A melhor parte é que ele funciona com todos os tipos de estruturas de aprendizado de máquina, como Keras, ONNX, LightGBM, Pytorch e Scikit-learn. Em suma, o BentoML oferece uma solução completa para implementação, serviço e monitoramento de modelos.
Imagem de BentoML
O Hugging Face Inference Endpoints é um serviço baseado em nuvem oferecido pela Hugging Face, uma plataforma de ML tudo-em-um que permite aos usuários treinar, hospedar e compartilhar modelos, conjuntos de dados e demonstrações. Esses endpoints são projetados para ajudar os usuários a implementar seus modelos de aprendizado de máquina treinados para inferência sem a necessidade de configurar e gerenciar a infraestrutura necessária.
Principais recursos:
Imagem de Hugging Face
Observação: Você também pode usar o MLflow e o AWS sagemaker para implantação e fornecimento de modelos.
Independentemente de seu modelo de ML estar em desenvolvimento, validação ou implantado na produção, essas ferramentas podem ajudar você a monitorar uma série de fatores:
Evidently AI é uma biblioteca Python de código aberto para monitorar modelos de ML durante o desenvolvimento, a validação e a produção. Ele verifica a qualidade dos dados e do modelo, o desvio dos dados, o desvio do alvo e o desempenho da regressão e da classificação.
Evidentemente, tem três componentes principais:
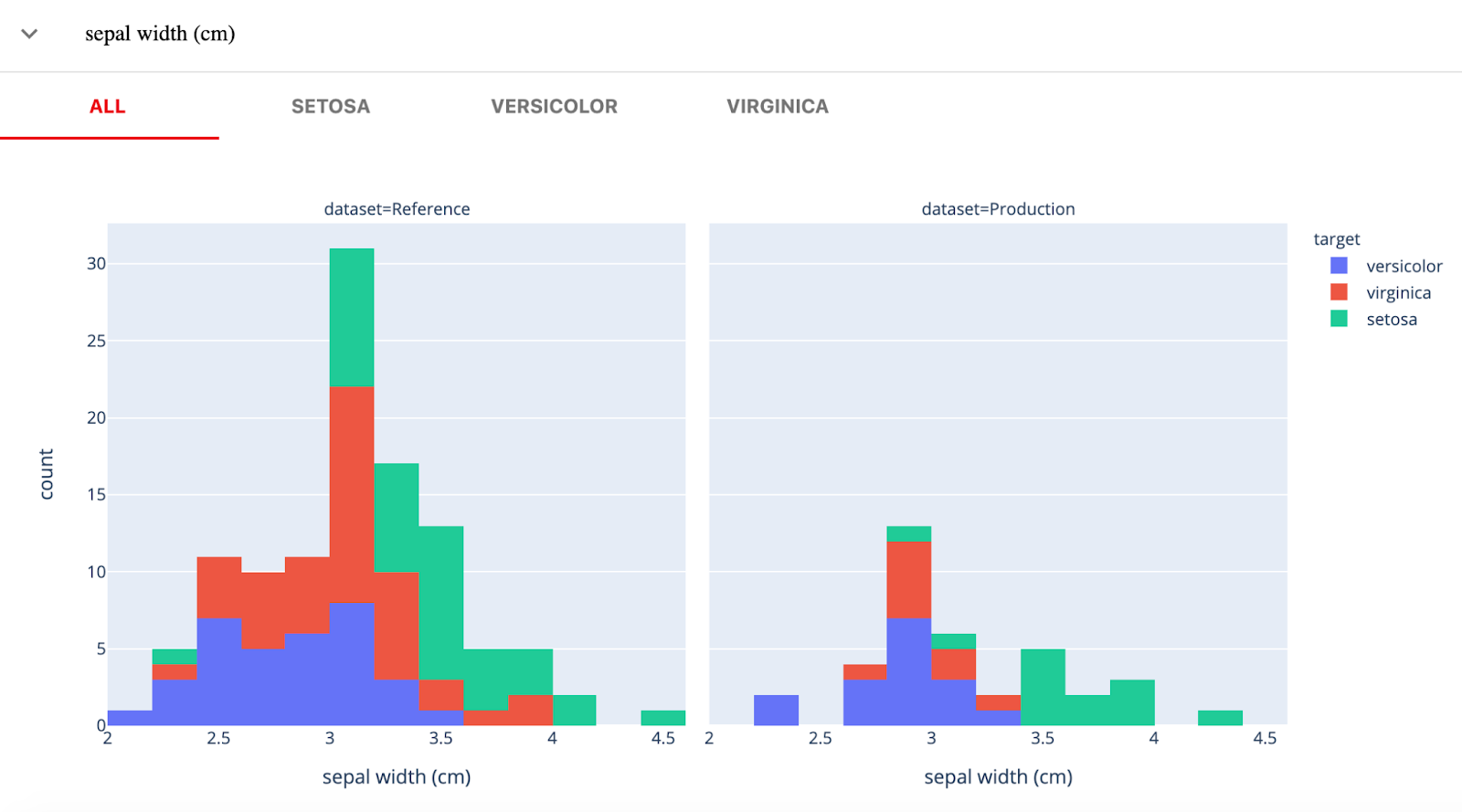
Imagem de Evidently
O Fiddler AI é uma ferramenta de monitoramento de modelos de ML com uma interface de usuário clara e fácil de usar. Ele permite que você explique e depure previsões, analise o comportamento do modo para todo o conjunto de dados, implemente modelos de aprendizado de máquina em escala e monitore o desempenho do modelo.
Vamos dar uma olhada nos principais recursos de IA do Fiddler para monitoramento de ML:
Imagem de Fiddler
O mecanismo de tempo de execução é responsável por carregar o modelo, pré-processar os dados de entrada, executar a inferência e retornar os resultados para o aplicativo cliente.
O Ray é uma estrutura versátil projetada para dimensionar aplicativos de IA e Python, facilitando aos desenvolvedores o gerenciamento e a otimização de seus projetos de aprendizado de máquina.
A plataforma consiste em dois componentes principais: um núcleo de tempo de execução distribuído e um conjunto de bibliotecas de IA adaptadas para simplificar a computação de ML.
O Ray Core oferece um conjunto limitado de elementos fundamentais que podem ser usados para criar e expandir aplicativos distribuídos.
A Ray também fornece bibliotecas de IA para conjuntos de dados dimensionáveis para ML, treinamento distribuído, ajuste de hiperparâmetros, aprendizado por reforço e serviço dimensionável e programável.
O exemplo a seguir demonstra o treinamento e a veiculação de um modelo de classificador de Gradient Boosting.
import requests
from starlette.requests import Request
from typing import Dict
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from ray import serve
# Train model.
iris_dataset = load_iris()
model = GradientBoostingClassifier()
model.fit(iris_dataset["data"], iris_dataset["target"])
@serve.deployment
class BoostingModel:
def __init__(self, model):
self.model = model
self.label_list = iris_dataset["target_names"].tolist()
async def __call__(self, request: Request) -> Dict:
payload = (await request.json())["vector"]
print(f"Received http request with data {payload}")
prediction = self.model.predict([payload])[0]
human_name = self.label_list[prediction]
return {"result": human_name}
# Deploy model.
serve.run(BoostingModel.bind(model), route_prefix="/iris")O Nuclio é uma estrutura avançada que se concentra em cargas de trabalho com uso intenso de dados, E/S e computação. Ele foi projetado para ser sem servidor, o que significa que você não precisa se preocupar com o gerenciamento de servidores. O Nuclio é bem integrado a ferramentas populares de ciência de dados, como Jupyter e Kubeflow. Ele também oferece suporte a uma ampla variedade de fontes de dados e streaming e pode ser executado em CPUs e GPUs.
Principais recursos:
Imagem de Nuclio
Se você estiver procurando uma ferramenta abrangente de MLOps que possa ajudar durante todo o processo, aqui estão algumas das melhores:
O Amazon Web Services SageMaker é uma solução completa para MLOps. Você pode treinar e acelerar o desenvolvimento de modelos, rastrear e versionar experimentos, catalogar artefatos de ML, integrar pipelines de ML de CI/CD e implantar, servir e monitorar modelos na produção sem problemas.
Principais recursos:
Imagem do Amazon SageMaker
O DagsHub é uma plataforma criada para que a comunidade de aprendizado de máquina rastreie e controle a versão de dados, modelos, experimentos, pipelines de ML e código. Ele permite que sua equipe crie, revise e compartilhe projetos de aprendizado de máquina.
Simplificando, ele é um GitHub para aprendizado de máquina, e você obtém várias ferramentas para otimizar o processo de aprendizado de máquina de ponta a ponta.
Principais recursos:
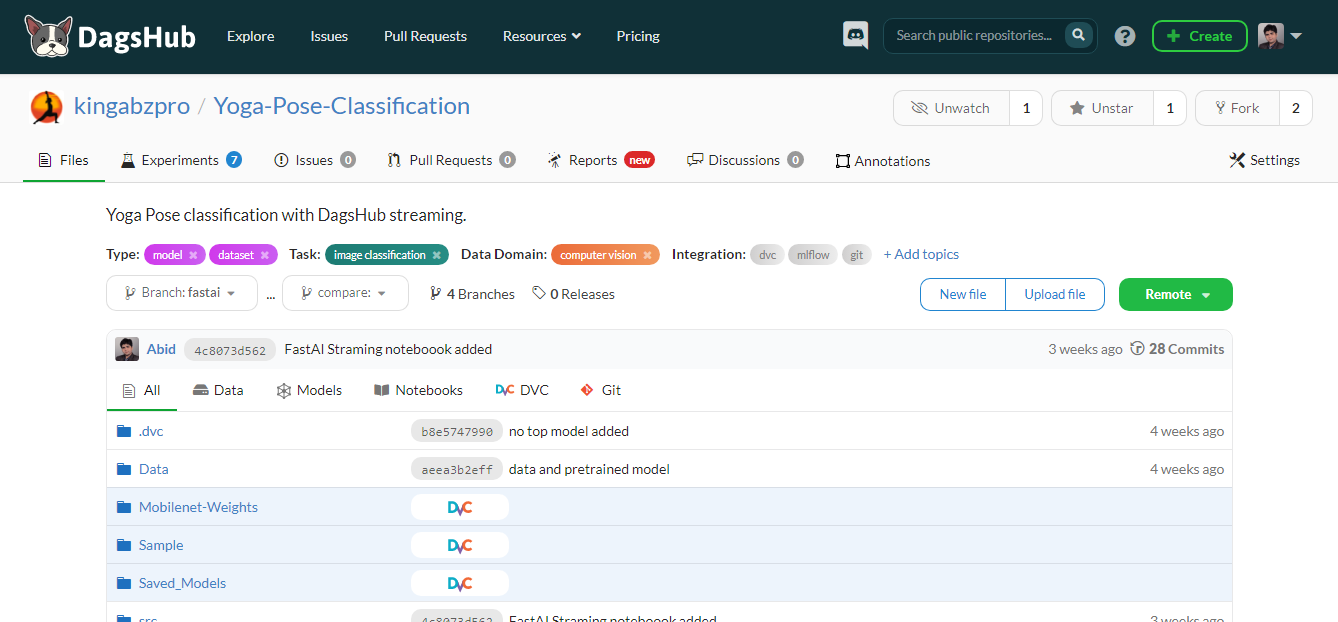
Imagem do autor
A Iguazio MLOps Platform é uma plataforma de MLOps de ponta a ponta que permite que as organizações automatizem o pipeline de aprendizado de máquina, desde a coleta e a preparação de dados até o treinamento, a implementação e o monitoramento na produção. Ele oferece uma plataforma aberta(MLRun) e gerenciada.
Um diferencial importante da plataforma MLOps da Iguazio é a flexibilidade nas opções de implementação. Os usuários podem implementar aplicativos de IA em qualquer lugar, inclusive em ambientes de nuvem, híbridos ou locais. Isso é particularmente importante para setores como saúde e finanças, em que as preocupações com a privacidade dos dados podem tornar a implantação no local um requisito.
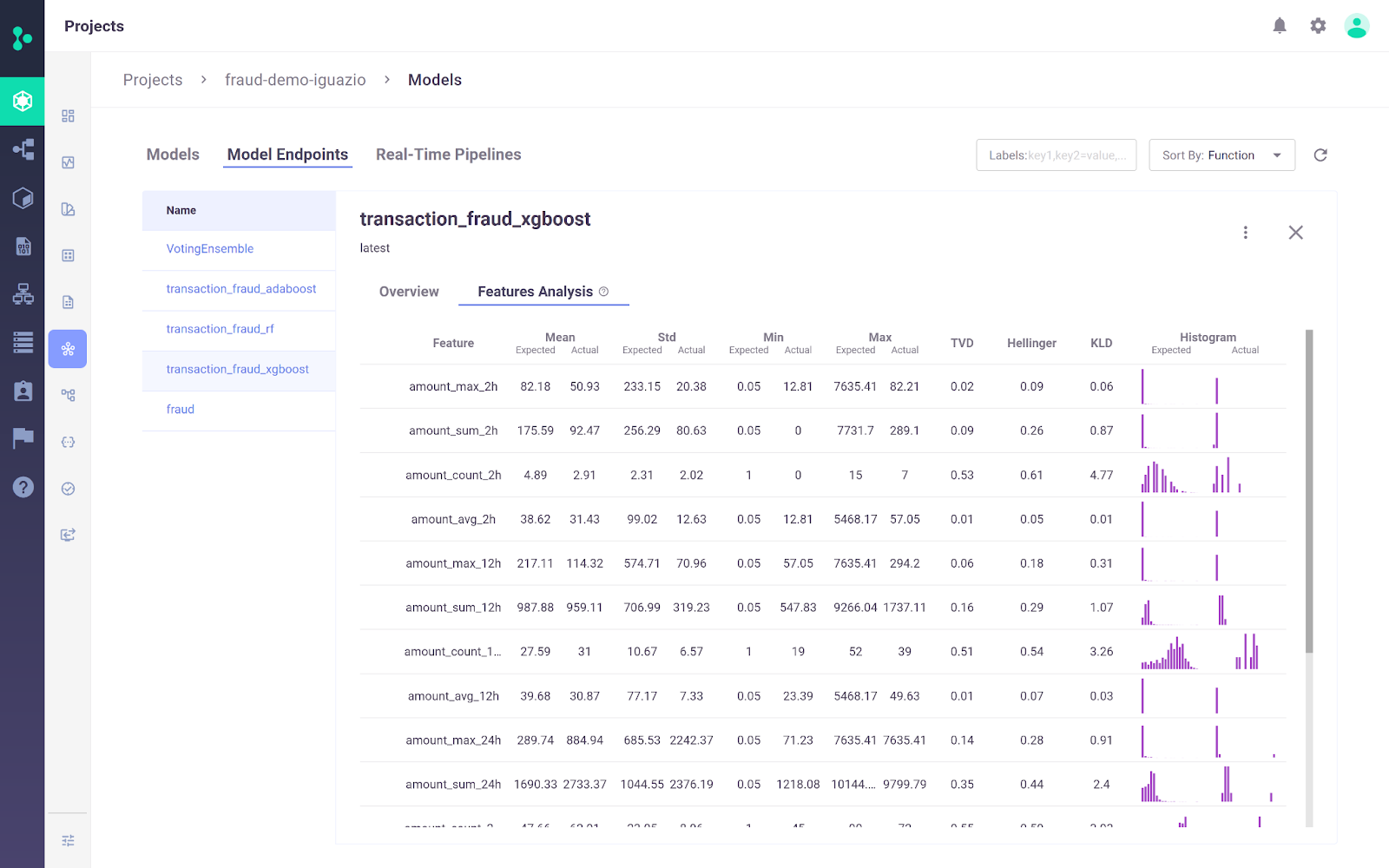
Imagem da plataforma MLOps da Iguazio
Principais recursos:
Aqui está uma tabela de comparação para que você possa avaliar essas ferramentas lado a lado e decidir quais são as melhores para seus projetos:
| Ferramenta | Funcionalidade principal | Estruturas compatíveis | Opções de implementação |
|---|---|---|---|
| Qdrant | Pesquisa de similaridade vetorial e gerenciamento de banco de dados | Python, vários idiomas | Nativo na nuvem, escalável horizontalmente |
| LangChain | Desenvolver aplicativos com modelos de linguagem | Python, JavaScript | API REST, modelos |
| MLFlow | Rastreamento de experimentos, registro de modelos, implantação | Python, R, Java, REST API | Local, na nuvem |
| Cometa ML | Rastreamento e otimização de experimentos | Scikit-learn, PyTorch, TensorFlow, HuggingFace | Local, na nuvem |
| Pesos e vieses | Acompanhamento de experimentos, controle de versão de dados e modelos | Fastai, Keras, PyTorch, HuggingFace, Yolov5, Spacy | Local, na nuvem |
| Prefeito | Orquestração e monitoramento do fluxo de trabalho | Python | Local (UI do Orion), nuvem |
| Metaflow | Gerenciamento de fluxo de trabalho para ciência de dados | Scikit-learn, TensorFlow, Python, R | AWS, GCP, Azure, local |
| Kedro | Orquestração de fluxo de trabalho, reprodutibilidade | Python | Local, distribuído |
| Paquiderme | Transformação de dados, controle de versão e linhagem | Qualquer idioma | Kubernetes |
| DVC | Controle de versão de dados e pipeline | Git, Python | Local, na nuvem |
| LakeFS | Controle de versão semelhante ao Git para lagos de dados | Qualquer serviço de armazenamento | Local, na nuvem |
| Festa | Armazenamento centralizado de recursos para modelos de ML | Python | Local, na nuvem |
| Forma de recurso | Armazenamento virtual de recursos para modelos de ML | Python | Local, na nuvem |
| Verificações profundas | Teste e validação do modelo de ML | Python | Local, na nuvem |
| TruEra | Teste de qualidade e desempenho do modelo | Python | Local, na nuvem |
| Kubeflow | Implantação e orquestração de modelos de ML | TensorFlow, PyTorch, PaddlePaddle, MXNet, XGboost | Kubernetes, nuvem |
| BentoML | Implementação de modelos e gerenciamento de API | Keras, ONNX, LightGBM, PyTorch, Scikit-learn | Local, na nuvem |
| Cara de abraço | Inferência e implementação de modelos | Qualquer modelo | Nuvem |
| Evidentemente | Monitoramento de modelos de ML para desvio de dados e alvos | Python | Local, na nuvem |
| Violinista | Monitoramento e depuração de modelos de ML | Python | Local, na nuvem |
| Raio | Dimensione aplicativos de IA e Python | Python | Local, na nuvem |
| Nuclio | Estrutura sem servidor para cargas de trabalho com uso intensivo de dados e computação | Jupyter, Kubeflow | Nuvem, no local |
| AWS SageMaker | Gerenciamento de ciclo de vida de ML de ponta a ponta | Python, R, Java, TensorFlow, PyTorch | Nuvem AWS |
| DagsHub | Controle de versão e colaboração para projetos de ML | Git, DVC, MLflow | Local, na nuvem |
| Iguazio | Automação de ponta a ponta de pipelines de ML | Python, MLRun | Nuvem, híbrido, no local |
Estamos em um momento em que há um boom no setor de MLOps. Toda semana você vê novos desenvolvimentos, novas startups e novas ferramentas sendo lançadas para resolver o problema básico de converter notebooks em aplicativos prontos para produção. Até mesmo as ferramentas existentes estão expandindo o horizonte e integrando novos recursos para se tornarem ferramentas super MLOps.
Neste blog, aprendemos sobre as melhores ferramentas de MLOps para várias etapas do processo de MLOps. Essas ferramentas ajudarão você durante os estágios de experimentação, desenvolvimento, implementação e monitoramento.
Se você é novo no aprendizado de máquina e deseja dominar as habilidades essenciais para conseguir um emprego como cientista de aprendizado de máquina, experimente fazer nosso curso de carreira de Cientista de Aprendizado de Máquina com Python.
Se você é um profissional e deseja saber mais sobre as práticas padrão de MLOps, leia nosso artigo sobre as melhores práticas de MLOps e como aplicá-las e confira nossa trilha de habilidades MLOps Fundamentals .
Saiba mais sobre MLOps com estes cursos!
Curso
Curso
Curso
blog
Abid Ali Awan
9 min
blog
Javier Canales Luna
9 min
blog
Joleen Bothma
12 min
blog
Javier Canales Luna
13 min
blog
Matt Crabtree
10 min
blog
Javier Canales Luna
13 min

