
Cursus
Microsoft Azure begrijpen
3 Hr
48.2K
Azure Data Factory (ADF) is Microsofts cloudgebaseerde data-integratieservice die is afgestemd op moderne organisaties. Het stelt gebruikers in staat om workflows te ontwerpen, beheren en automatiseren die taken voor dataverplaatsing en -transformatie op ondernemingsschaal afhandelen.
ADF onderscheidt zich door zijn gebruiksvriendelijke no-code-interface, waarmee zowel technische als niet-technische gebruikers eenvoudig datapijplijnen kunnen bouwen. Dankzij de uitgebreide integratiemogelijkheden met meer dan 90 native connectors kan data stromen tussen diverse bronnen, waaronder on-premises systemen en clouddiensten.
In deze gids geef ik een uitgebreide introductie tot Azure Data Factory, met de belangrijkste componenten en functies, plus een praktische tutorial om je te helpen je eerste datapijplijn te maken.
Azure Data Factory (ADF) is een cloudgebaseerde data-integratieservice die is ontworpen om dataworkflows te orkestreren en te automatiseren.
Het wordt gebruikt om data te verzamelen, te transformeren en te leveren, zodat inzichten direct beschikbaar zijn voor analytics en besluitvorming.
Met zijn schaalbare en serverloze architectuur kan ADF workflows van elk formaat aan—van eenvoudige datamigraties tot complexe datatransformatiepijplijnen.
ADF overbrugt datasilo’s en stelt gebruikers in staat data te verplaatsen en te transformeren tussen on-premises systemen, clouddiensten en externe platforms. Of je nu werkt met big data, operationele databases of API’s, Azure Data Factory biedt de tools om data efficiënt te koppelen, te verwerken en te uniformeren.
Hier zijn enkele van de belangrijkste functies die ADF biedt.
Azure Data Factory ondersteunt integratie met meer dan 100 native connectors, waaronder cloudgebaseerde en on-premises systemen. Het biedt ondersteuning voor SQL-databases, NoSQL-systemen, REST-API’s en bestandsgebaseerde databronnen, zodat je dataworkflows kunt verenigen ongeacht de bron of het formaat. Het is de fundamentele engine die ook de dataintegratiefuncties in Microsoft Fabric, Microsofts uniforme dataplatform, aandrijft.

Dataconnectors beschikbaar in Azure Data Factory
De drag-and-drop-interface van ADF vereenvoudigt het maken van datapijplijnen. Met vooraf gebouwde templates, begeleide configuratiewizards en een intuïtieve visuele editor kunnen zelfs gebruikers zonder codeerkennis end-to-endworkflows ontwerpen.
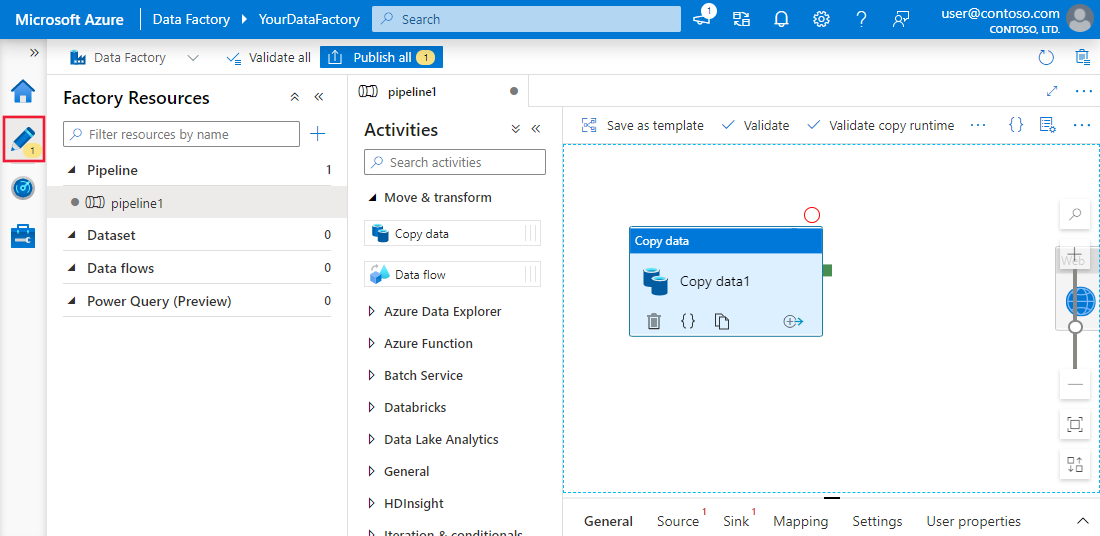
No-code authoring-ervaring in Azure Data Factory
De planningshulpmiddelen van Azure Data Factory bieden workflowautomatisering. Gebruikers kunnen triggers instellen op basis van specifieke voorwaarden, zoals de aankomst van een bestand in cloudopslag of geplande tijdsintervallen. Deze planningsopties maken handmatige interventies overbodig en zorgen ervoor dat workflows consistent en betrouwbaar worden uitgevoerd.
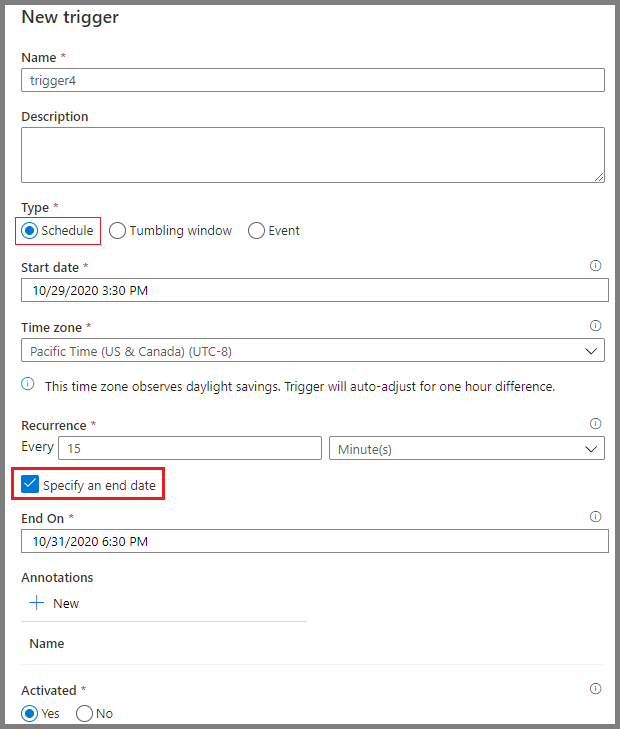
Pijplijnen plannen in Azure Data Factory
Inzicht in de kerncomponenten van Azure Data Factory is essentieel om efficiënte workflows te bouwen.
Pijplijnen vormen de ruggengraat van Azure Data Factory. Ze vertegenwoordigen datagedreven workflows die de stappen definiëren die nodig zijn om data te verplaatsen en te transformeren.
Elke pijplijn fungeert als container voor één of meer activiteiten, die sequentieel of parallel worden uitgevoerd om de gewenste datastroom te realiseren.
Met deze pijplijnen kunnen data engineers end-to-endprocessen creëren, zoals het inladen van ruwe data, het omzetten naar een bruikbaar formaat en het laden in doelsystemen.
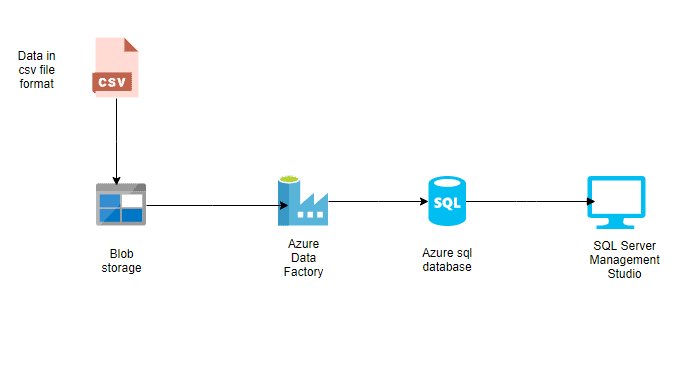
Voorbeeld van een eenvoudige pijplijn in Azure Data Factory
Activiteiten zijn de functionele bouwstenen van pijplijnen en voeren elk een specifieke bewerking uit. Ze zijn grofweg onderverdeeld in:
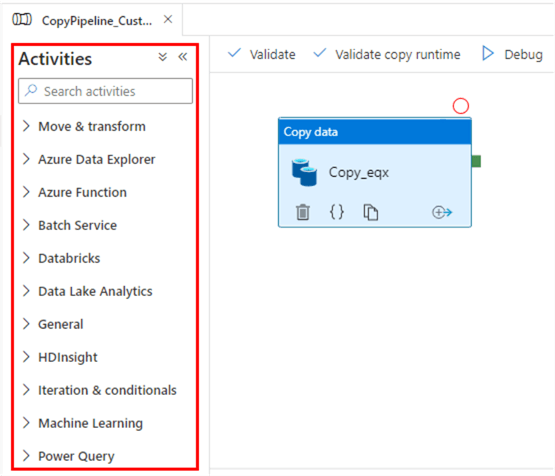
Activiteiten in Azure Data Factory
Datasets zijn representaties van de data die in activiteiten worden gebruikt. Ze definiëren het schema, het formaat en de locatie van de data die wordt binnengehaald of verwerkt.
Een dataset kan bijvoorbeeld een CSV-bestand in Azure Blob Storage beschrijven of een tabel in een Azure SQL Database. Datasets vormen de intermediaire laag die activiteiten verbindt met de daadwerkelijke databronnen en -bestemmingen.
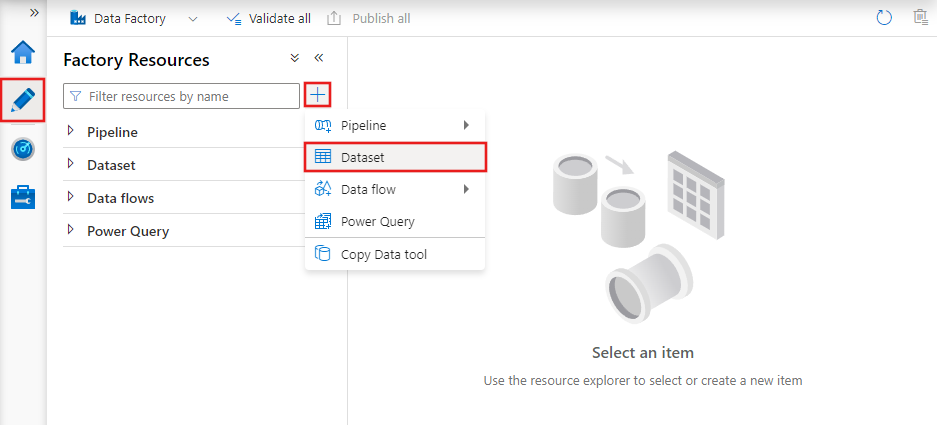
Datasets in Azure Data Factory
Gekoppelde services zijn verbindingsreeksen die activiteiten en datasets toegang geven tot externe systemen en services.
Ze fungeren als bruggen tussen Azure Data Factory en de externe resources waarmee het samenwerkt, zoals databases, opslagaccounts of compute-omgevingen.
Zo kan een gekoppelde service verbinding maken met een on-premises SQL Server of een cloudgebaseerde datalake.
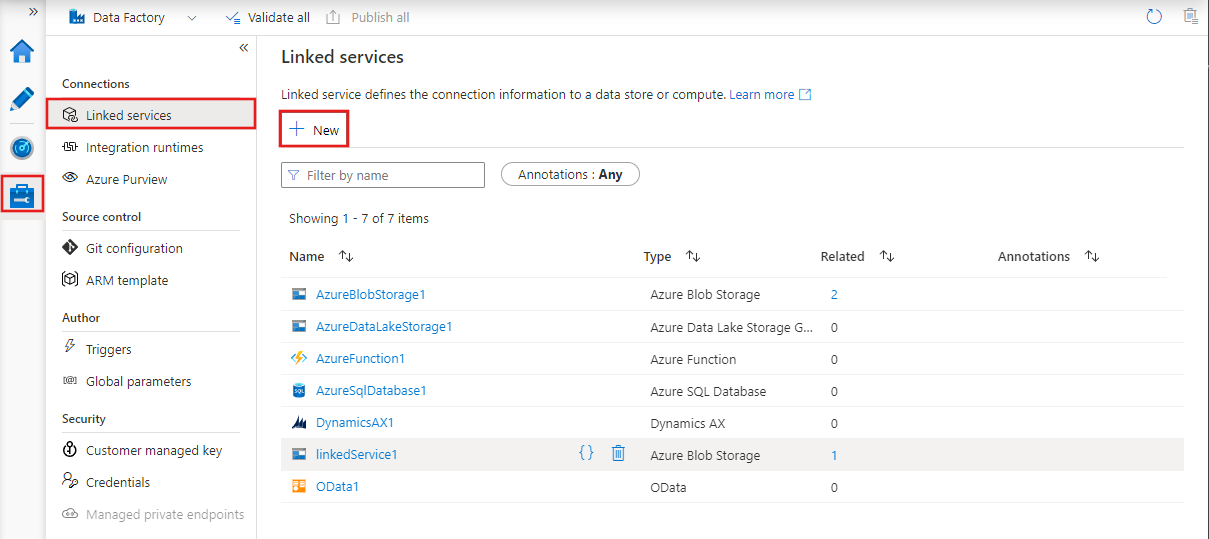
Gekoppelde services in Azure Data Factory
Integration runtimes (IR’s) zijn de compute-omgevingen die dataverplaatsing, transformatie en activiteituitvoering in Azure Data Factory aandrijven. ADF biedt drie typen integration runtimes:
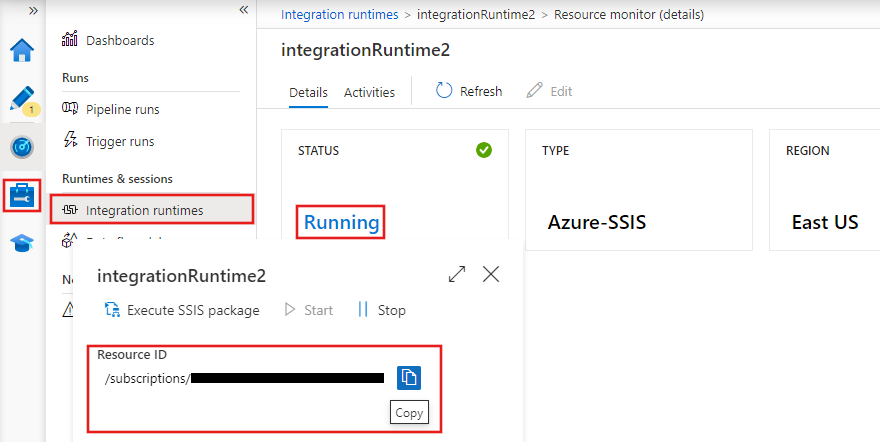
Integration runtimes in Azure Data Factory
Laten we nu naar het praktische deel van deze gids gaan!
1. Een actieve Azure-abonnement.
2. Een resourcegroep voor het beheren van Azure-resources.
1. Log in op de Azure-portal.
2. Navigeer naar Een resource maken en selecteer Data Factory.
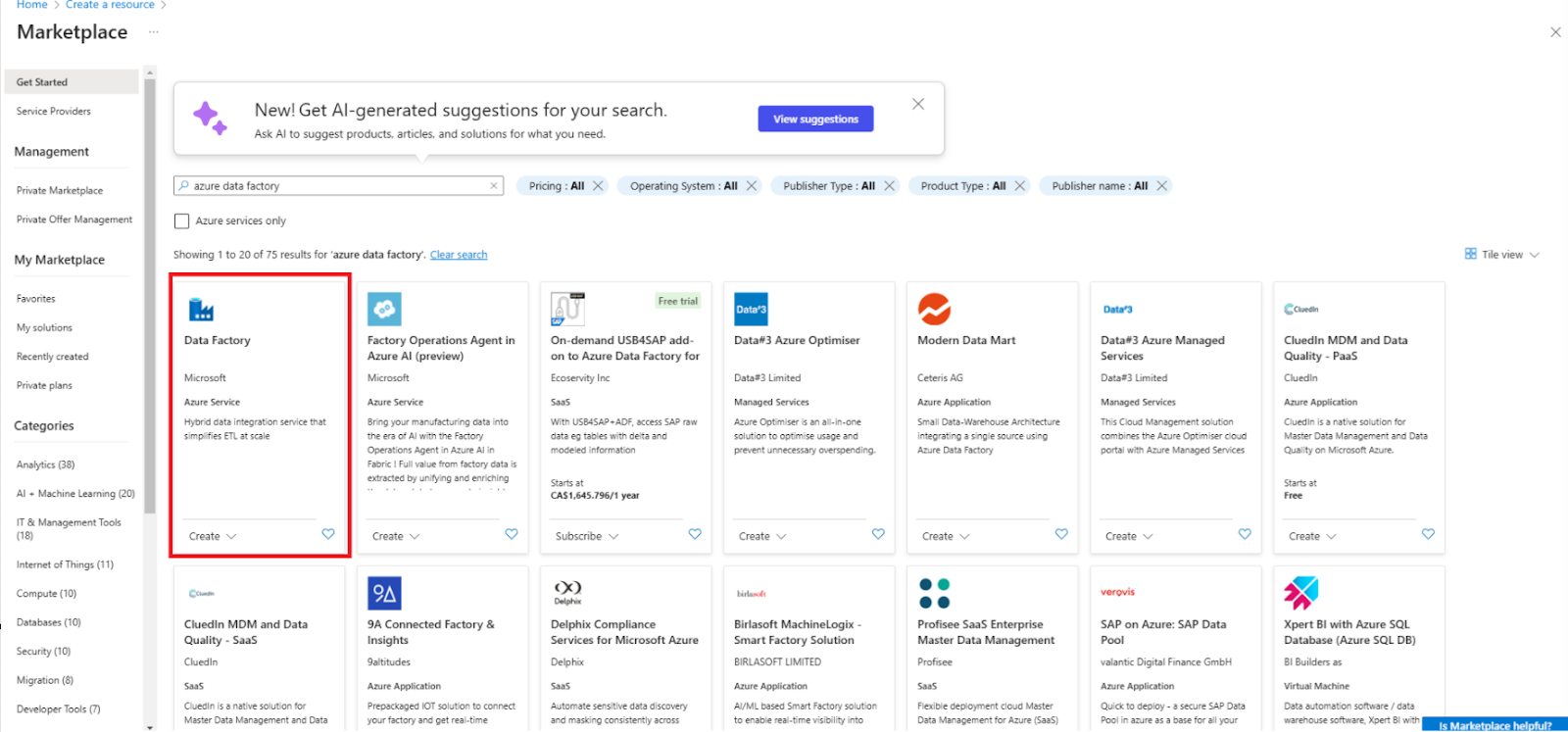
Maak een nieuwe Data Factory-resource
3. Vul de vereiste velden in, waaronder abonnement, resourcegroep en regio.
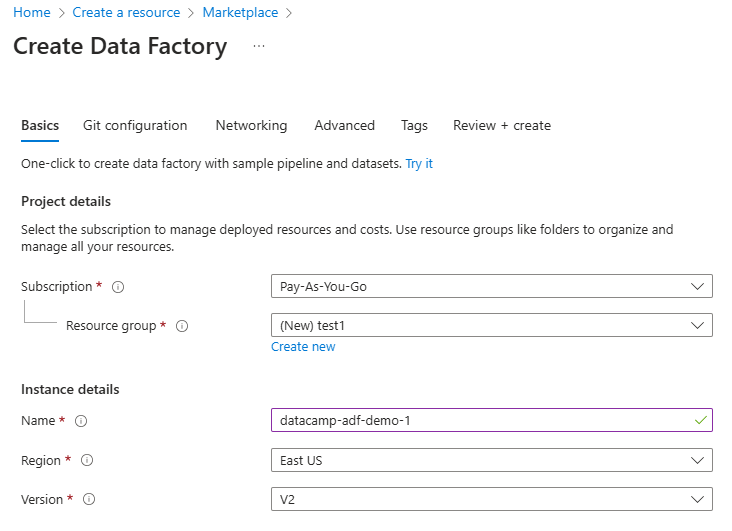
Configureer Data Factory-resource
4. Controleer en maak het exemplaar.
Azure Data Factory-exemplaar gemaakt
De ADF-interface bestaat uit de volgende hoofdsecties (toegankelijk via het navigatiemenu aan de linkerkant)
1. Author: Voor het maken en beheren van pijplijnen.
2. Monitor: Om pijplijnruns te volgen en problemen op te lossen.
3. Manage: Voor het configureren van gekoppelde services en integration runtimes.
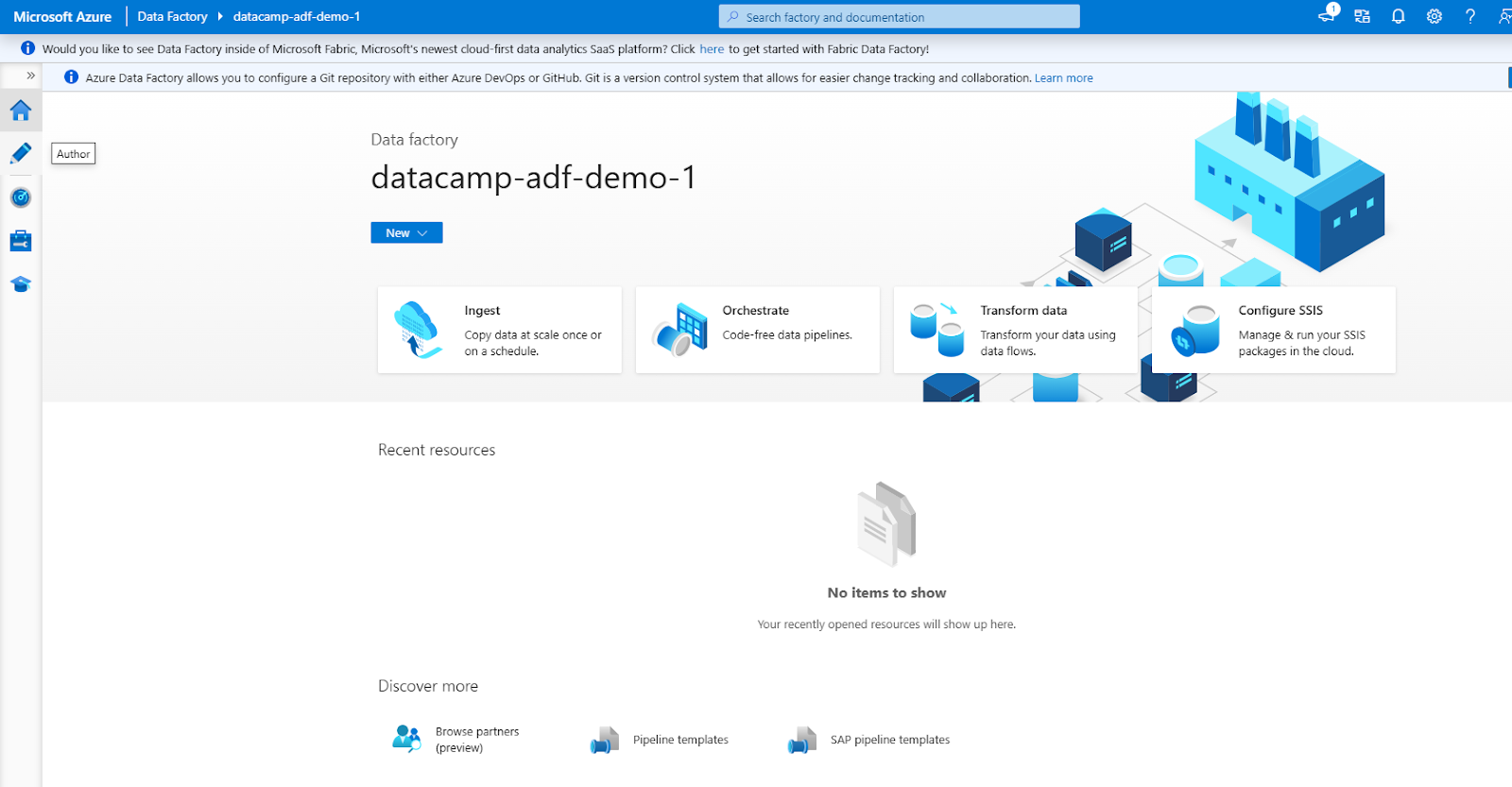
Azure Data Factory-interface
Laten we de stappen doorlopen om een eenvoudige datapijplijn te maken.
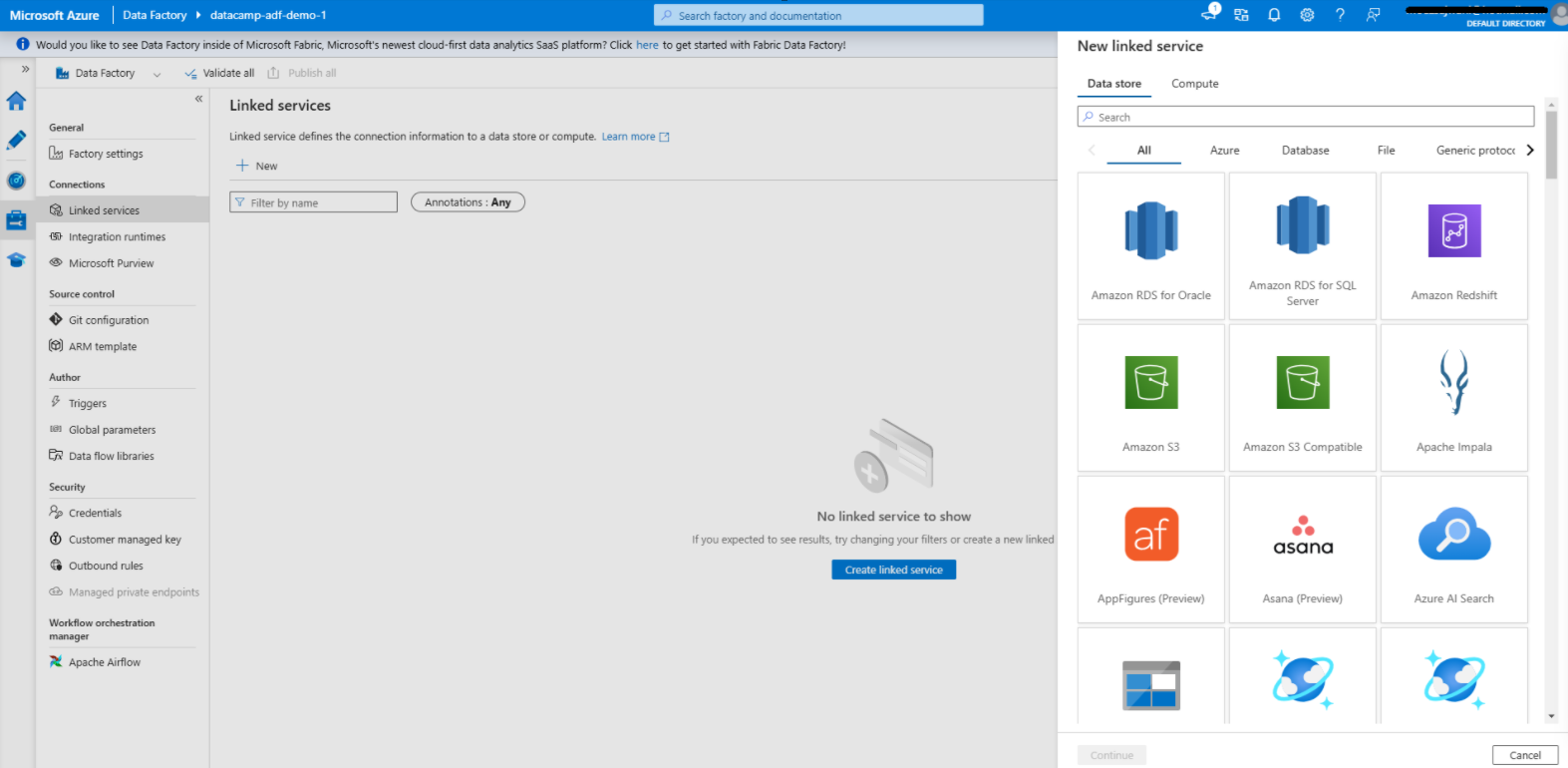
Een gekoppelde service maken in Azure Data Factory
1. Ga naar het tabblad Manage
2. Voeg een gekoppelde service toe voor de bron
3. Voeg een gekoppelde service toe voor de bestemming
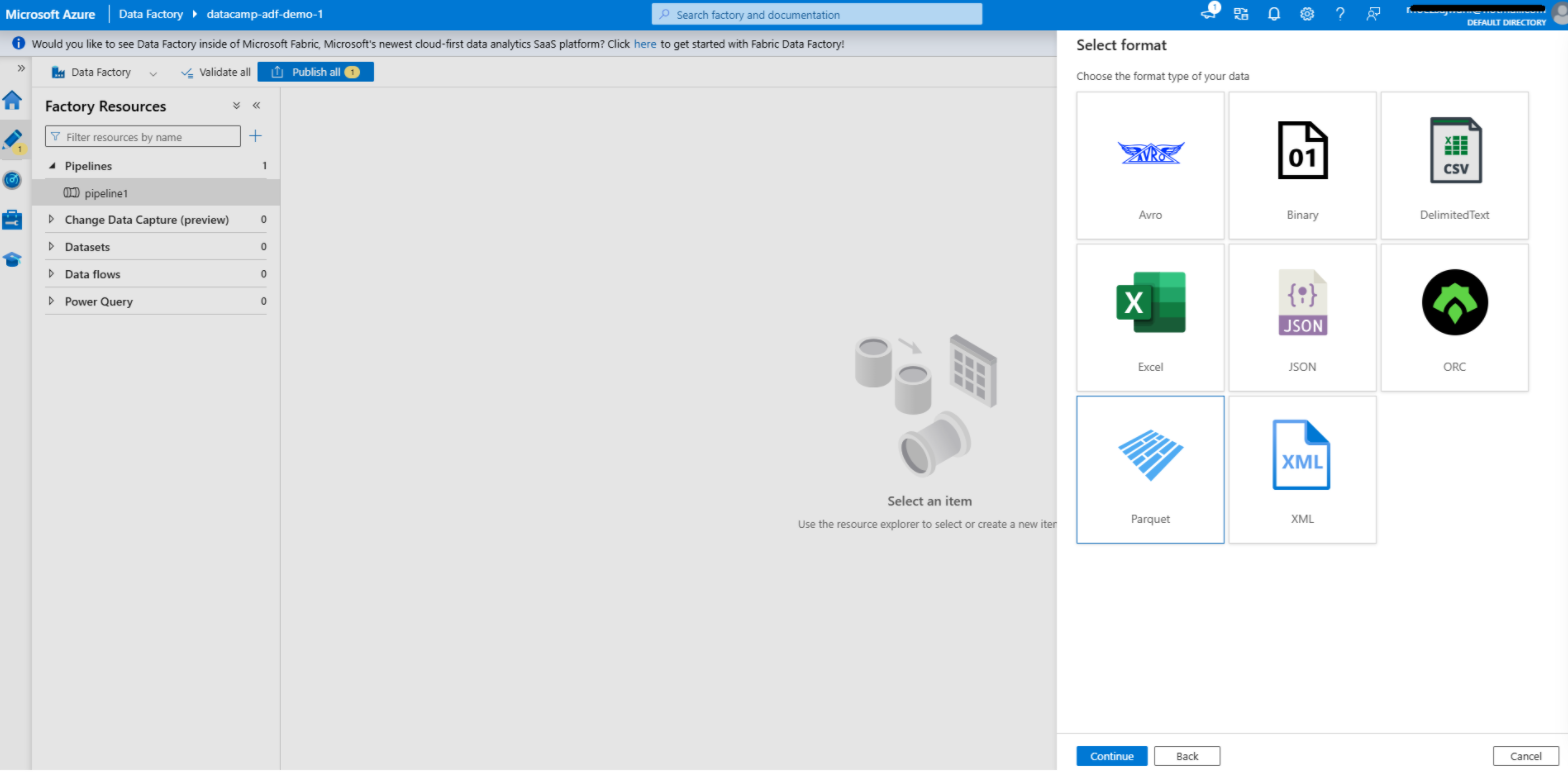
Een dataset maken in Azure Data Factory
1. Ga naar het tabblad Author
2. Voeg een dataset toe voor de bron
3. Voeg een dataset toe voor de bestemming
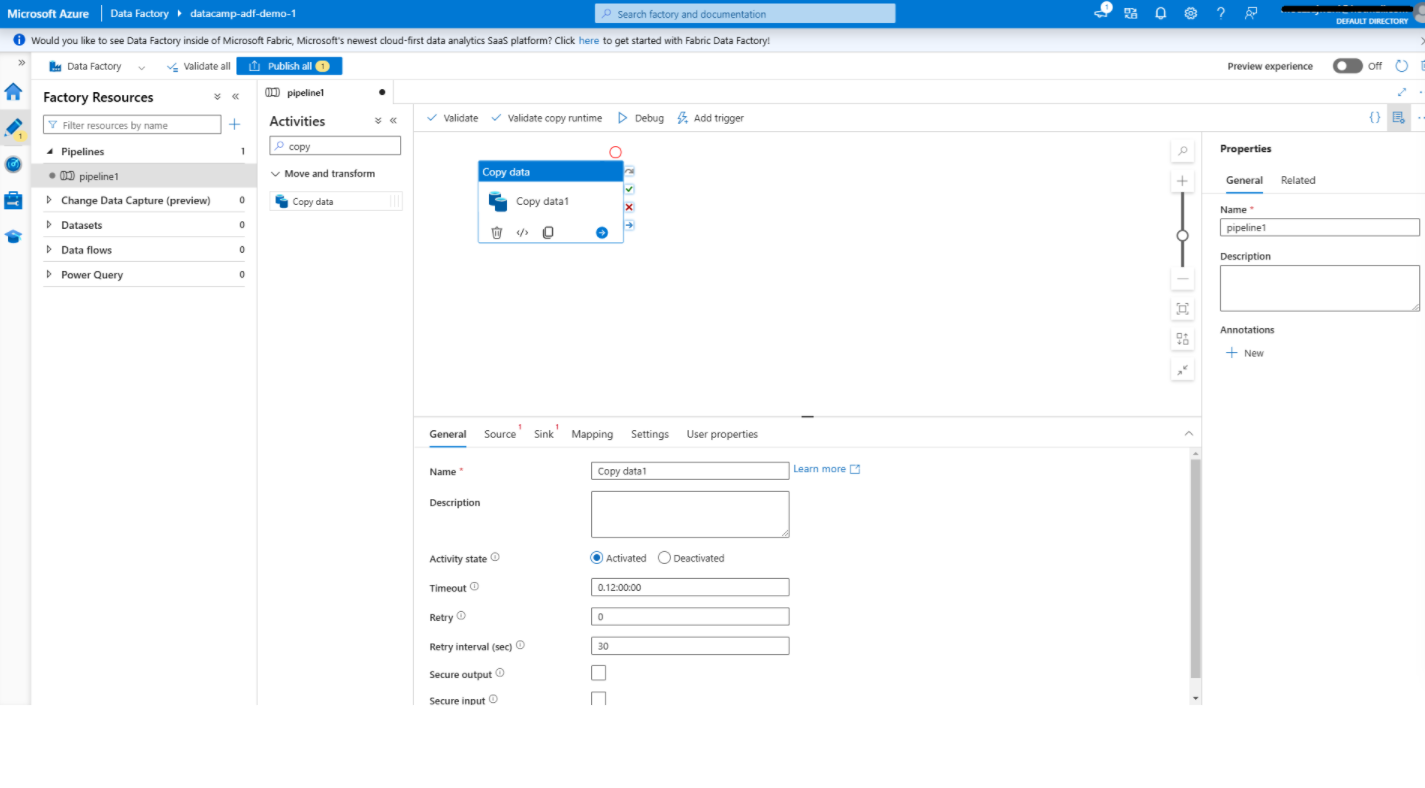
Een Copy data-activiteit toevoegen in Azure Data Factory
1. Open de Pipeline-editor
2. Voeg de Copy data-activiteit toe
3. Configureer de Copy data-activiteit
Pijplijnen publiceren in Azure Data Factory
1. Publiceer je pijplijn
2. Voer de pijplijn uit
Azure Data Factory biedt krachtige dataintegratie- en transformatiefuncties die complexe workflows vereenvoudigen en de productiviteit verhogen. In dit onderdeel bespreken we deze functies.
Dataflows bieden een visuele omgeving voor het definiëren van transformatielogica, waardoor het voor gebruikers eenvoudiger wordt om data te manipuleren en te verwerken zonder complexe code te schrijven. Veelvoorkomende taken met dataflows zijn:
Dataflows ondersteunen ook geavanceerde bewerkingen zoals kolomafleidingen, datatypconversies en conditionele transformaties, waardoor het veelzijdige tools zijn voor uiteenlopende data-eisen.
ADF integreert naadloos met Azure Synapse Analytics en biedt een uniform platform voor big dataverwerking en geavanceerde analytics. Deze integratie stelt gebruikers in staat om:
Deze synergie tussen ADF en Synapse helpt workflows te stroomlijnen en vermindert de complexiteit van het beheren van afzonderlijke tools voor dataintegratie en analyse.
Na een grondige review van de functies en componenten van ADF, kijken we waar we het voor kunnen gebruiken.
ADF is een krachtig hulpmiddel voor het migreren van data van on-premises systemen naar cloudplatforms. Het vereenvoudigt complexe migraties door dataverplaatsing te automatiseren, dataintegriteit te waarborgen en downtime te minimaliseren.
Zo kun je met ADF data migreren van een on-premises SQL Server naar een Azure SQL Database met minimale handmatige interventie. Door gebruik te maken van ingebouwde connectors en integration runtimes zorgt ADF voor een veilig en efficiënt migratieproces, voor zowel gestructureerde als ongestructureerde data.
Extract, transform, and load (ETL)-processen vormen de kern van modern datawarehousing. Azure Data Factory stroomlijnt deze workflows door data uit meerdere bronnen te integreren, transformatielogica toe te passen en deze te laden in een datawarehouse.
Zo kan ADF verkoopdata uit verschillende regio’s consolideren, omzetten naar een uniform formaat en laden in Azure Synapse Analytics. Dit gestroomlijnde proces zorgt voor actuele, hoogwaardige data voor rapportage en besluitvorming.
|
Bekijk 23 beste ETL-tools in 2024 en waarom je ervoor zou kiezen. |
Datalakes fungeren als centrale opslagplaats voor diverse datasets en maken geavanceerde analytics en machine learning mogelijk. ADF faciliteert het inladen van data uit verschillende bronnen in Azure Data Lake Storage, met ondersteuning voor batch- en streamingscenario’s.
Zo kun je met ADF logbestanden, socialmediafeeds en IoT-sensordata in één datalake verzamelen. Met transformatie- en integratietools zorgt ADF ervoor dat het datalake goed is georganiseerd en klaar is voor downstream analytics en AI-workloads.
Tot slot is het de moeite waard om enkele best practices te bekijken voor effectief gebruik van ADF.
Ontwerp pijplijnen met herbruikbare componenten om onderhoudbare en schaalbare workflows te creëren. Een modulair ontwerp maakt het eenvoudiger om afzonderlijke onderdelen te debuggen, testen en bijwerken. Maak bijvoorbeeld een herbruikbare pijplijn voor transformatielogica in plaats van die in elke pijplijn op te nemen. Dit vermindert redundantie en verhoogt de consistentie over projecten heen.
Hoe verschilt Azure Data Factory dan van Databricks? Als je nieuwsgierig bent en de verschillen tussen Azure Data Factory en Databricks wilt ontdekken, bekijk dan de blog Azure Data Factory vs Databricks: A Detailed Comparison.
Terwijl je Azure Data Factory onder de knie krijgt, is het cruciaal om de evolutie ervan te begrijpen: Microsoft Fabric.
Hoewel Azure Data Factory (ADF) een robuuste, zelfstandige Platform-as-a-Service (PaaS)-oplossing blijft die breed wordt gebruikt in enterprises, heeft Microsoft Fabric geïntroduceerd als de toekomst van zijn data-ecosysteem. Fabric is een alles-in-één SaaS-platform dat Data Factory, Synapse Analytics en Power BI samenbrengt in één omgeving.
Moet je ADF of Fabric gebruiken?
Let op: ADF-pijplijnen en Fabric Data Factory-pijplijnen lijken sterk op elkaar, dus de skills die je vandaag in ADF leert, zijn direct overdraagbaar naar Fabric. Je kunt onze Introduction to Microsoft Fabric-cursus volgen om meer te leren.
Azure Data Factory vereenvoudigt het bouwen, beheren en opschalen van datapijplijnen in de cloud. Het biedt een intuïtief platform voor zowel technische als niet-technische gebruikers, waarmee ze data uit verschillende bronnen efficiënt kunnen integreren en transformeren.
Door gebruik te maken van functies zoals codevrije pipeline-authoring, integratiemogelijkheden en monitoringtools, kunnen gebruikers eenvoudig schaalbare en betrouwbare workflows creëren.
Wil je meer leren over Azure Data Factory? Bekijk dan de Top 27 Azure Data Factory Interview Questions and Answers.
Als je de ruggengraat van Azure wilt verkennen, inclusief onderwerpen als containers, virtuele machines en meer, raad ik deze geweldige gratis cursus aan: Understanding Microsoft Azure Architecture and Services.
Leer meer over Microsoft Azure met deze cursussen!
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
