
Curso
Entender Microsoft Azure
3 h
47.1K
Azure Data Factory (ADF) es el servicio de integración de datos basado en la nube de Microsoft diseñado para las organizaciones modernas. Permite a los usuarios diseñar, gestionar y automatizar flujos de trabajo que gestionan tareas de movimiento y transformación de datos a escala empresarial.
ADF destaca por su interfaz fácil de usar y sin código, que permite tanto a usuarios técnicos como no técnicos crear fácilmente canales de datos. Tus amplias capacidades de integración admiten más de 90 conectores nativos, lo que permite el flujo de datos entre diversas fuentes, incluidos sistemas locales y servicios basados en la nube.
En esta guía, ofrezco una introducción completa a Azure Data Factory, en la que se describen sus componentes y características y se proporciona un tutorial práctico para ayudarte a crear tu primera canalización de datos.
Azure Data Factory (ADF) es un servicio de integración de datos basado en la nube diseñado para coordinar y automatizar flujos de trabajo de datos.
Se utiliza para recopilar, transformar y entregar datos, garantizando que la información sea fácilmente accesible para el análisis y la toma de decisiones.
Gracias a su arquitectura escalable y sin servidor, ADF puede gestionar flujos de trabajo de cualquier tamaño, desde simples migraciones de datos hasta complejos procesos de transformación de datos.
ADF salva la brecha entre los silos de datos, permitiendo a los usuarios mover y transformar datos entre sistemas locales, servicios en la nube y plataformas externas. Tanto si trabajas con macrodatos, bases de datos operativas o API, Azure Data Factory te proporciona las herramientas necesarias para conectar, procesar y unificar datos de forma eficaz.
Estas son algunas de las características más importantes que ofrece ADF.
Azure Data Factory admite la integración con más de 100 conectores nativos, incluidos sistemas basados en la nube y locales. Incluye compatibilidad con bases de datos SQL, sistemas nosql, API REST y fuentes de datos basadas en archivos, lo que te permite unificar los flujos de trabajo de datos independientemente de la fuente o el formato. Es el motor fundamental que también impulsa las capacidades de integración de datos en Microsoft Fabric, la plataforma de datos unificada de Microsoft.

Conectores de datos disponibles en Azure Data Factory
La interfaz de arrastrar y soltar de ADF simplifica la forma en que ustedes crean canalizaciones de datos. Gracias a las plantillas prediseñadas, los asistentes de configuración guiados y un editor visual intuitivo, incluso los usuarios sin conocimientos de programación pueden diseñar flujos de trabajo completos de principio a fin.
Experiencia de creación sin código en Azure Data Factory
Las herramientas de programación de Azure Data Factory ofrecen automatización de flujos de trabajo. Los usuarios pueden configurar activadores basados en condiciones específicas, como la llegada de un archivo al almacenamiento en la nube o intervalos de tiempo programados. Estas opciones de programación eliminan la necesidad de intervenciones manuales y garantizan que los flujos de trabajo se ejecuten de forma coherente y fiable.
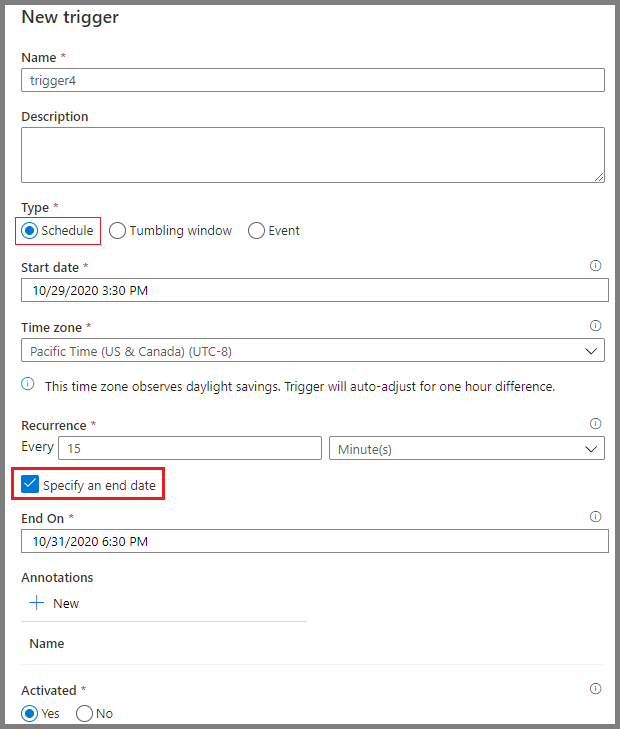
Programación de canalizaciones en Azure Data Factory
Comprender los componentes básicos de Azure Data Factory es esencial para crear flujos de trabajo eficientes.
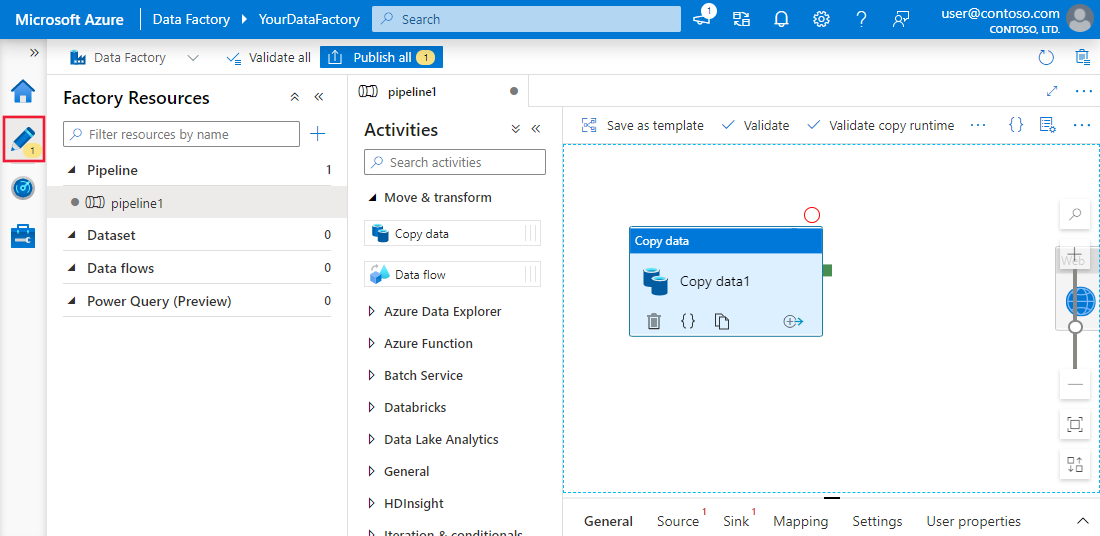
Las canalizaciones son la columna vertebral de Azure Data Factory. Representan flujos de trabajo basados en datos que definen los pasos necesarios para mover y transformar datos.
Cada canalización sirve como contenedor de una o varias actividades, ejecutadas de forma secuencial o en paralelo, para lograr el flujo de datos deseado.
Estas canalizaciones permiten a los ingenieros de datos crear procesos integrales, como la ingesta de datos sin procesar, su transformación a un formato utilizable y su carga en los sistemas de destino.
Ejemplo de canalización simple en Azure Data Factory
Las actividades son los componentes funcionales básicos de los procesos, y cada una de ellas realiza una operación específica. Se clasifican, en términos generales, en:
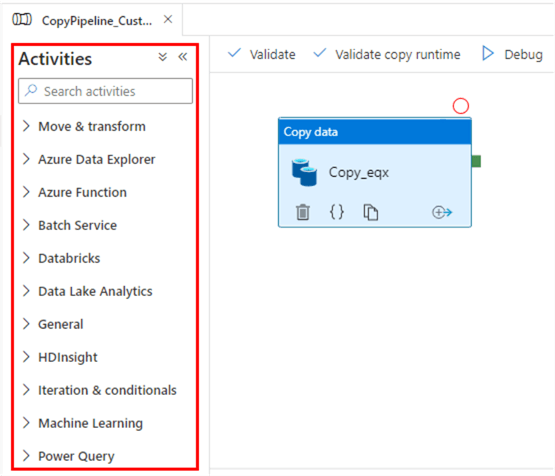
Actividades en Azure Data Factory
Los conjuntos de datos son representaciones de los datos utilizados en las actividades. Definen el esquema, el formato y la ubicación de los datos que se ingieren o procesan.
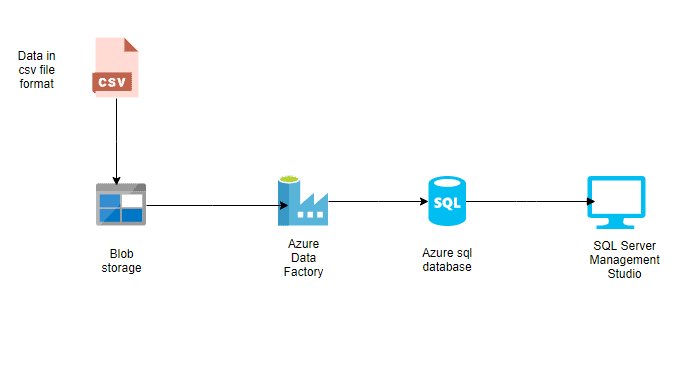
Por ejemplo, un conjunto de datos puede describir un archivo CSV en Azure Blob Storage o una tabla en una base de datos SQL de Azure. Los conjuntos de datos son la capa intermediaria que conecta las actividades con las fuentes y destinos reales de datos.
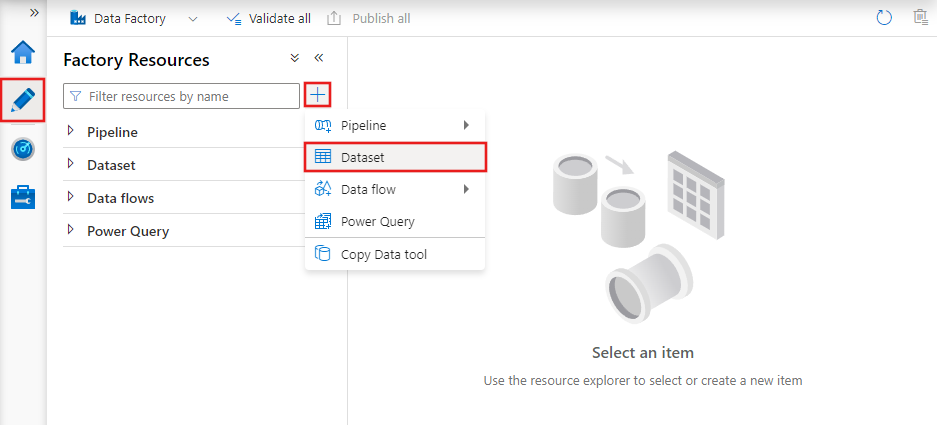
Conjuntos de datos en Azure Data Factory
Los servicios vinculados son cadenas de conexión que permiten a las actividades y los conjuntos de datos acceder a sistemas y servicios externos.
Actúan como puentes entre Azure Data Factory y los recursos externos con los que interactúa, como bases de datos, cuentas de almacenamiento o entornos informáticos.
Por ejemplo, un servicio vinculado puede conectarse a un servidor SQL local o a un lago de datos basado en la nube.
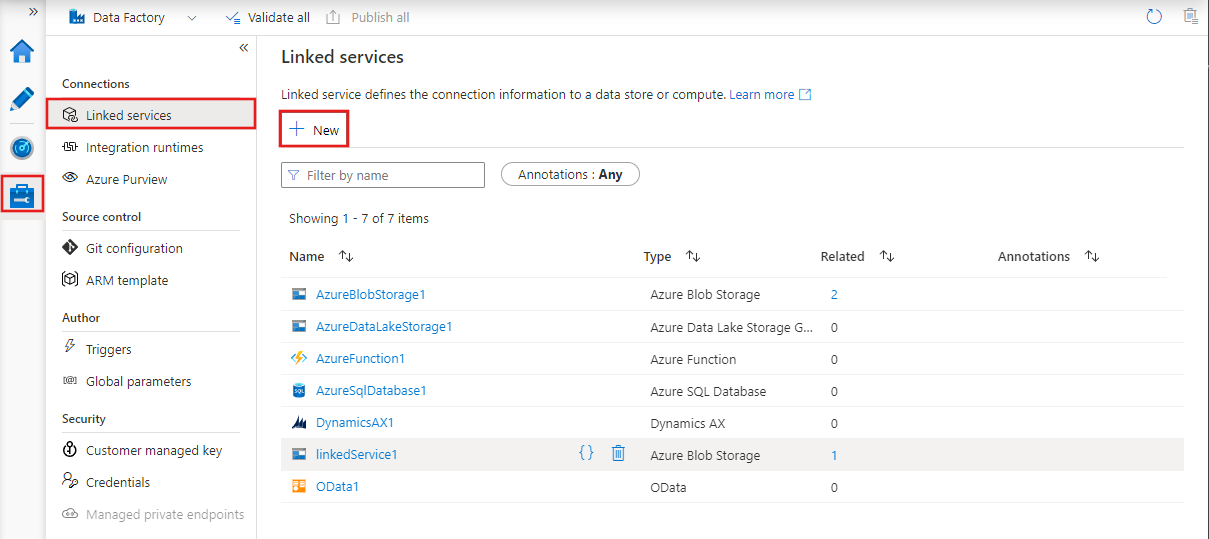
Servicios vinculados en Azure Data Factory
Los tiempos de ejecución de integración (IR) son los entornos informáticos que impulsan el movimiento de datos, la transformación y la ejecución de actividades dentro de Azure Data Factory. ADF ofrece tres tipos de entornos de ejecución de integración:
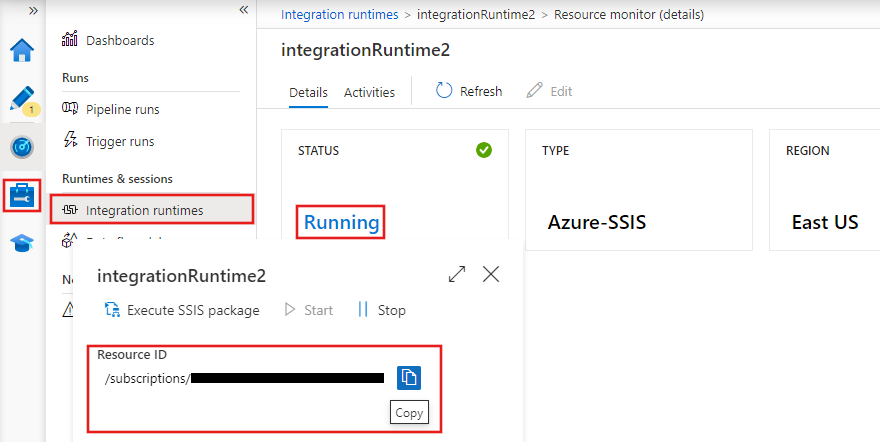
Tiempos de ejecución de integración en Azure Data Factory
Ahora, pasemos a la sección práctica de esta guía.
1. Una suscripción activa ay Azure.
2. Un grupo de recursos para administrarrecursos de Azure.
1. Inicia sesión en el portal de Azure.
2. Ve a Crea un recurso y selecciona Data Factory.
Crear un nuevo recurso de Data Factory
3. Rellena los campos obligatorios, incluyendo la suscripción, el grupo de recursos y la región.
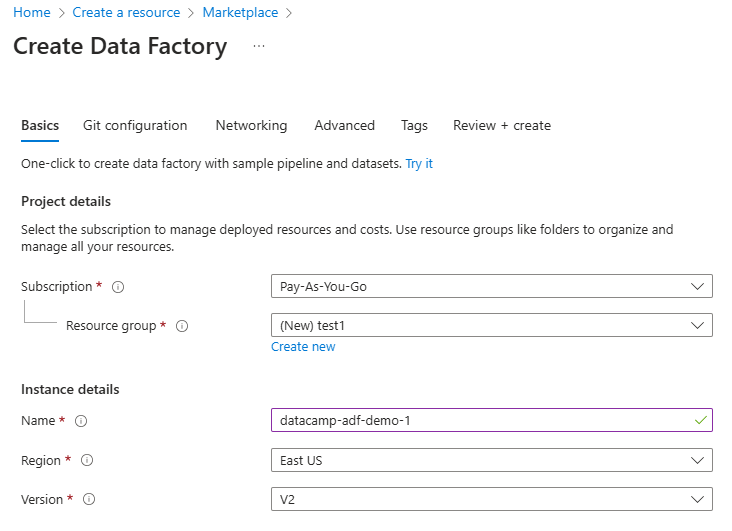
Configurar el recurso Data Factory
4. Revisa y crea la instancia.
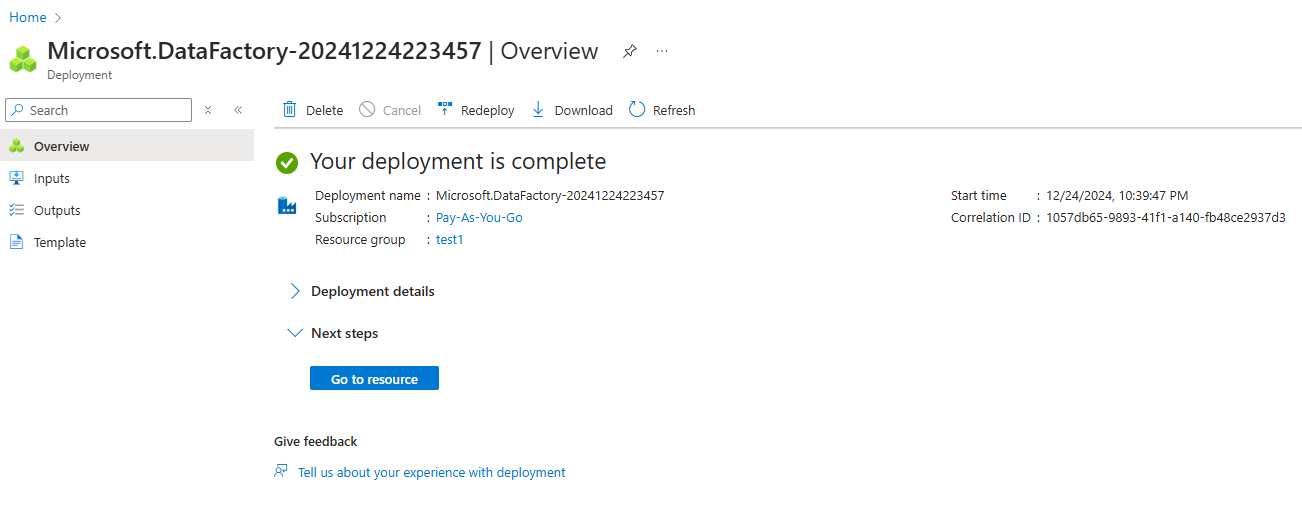
Instancia de Azure Data Factory creada
La interfaz ADF consta de las siguientes secciones principales (accesibles a través del menú de navegación de la izquierda)
1. Autor: Para crear y gestionar canalizaciones.
2. Monitor: Para realizar un seguimiento de las ejecuciones de los procesos y solucionar problemas.
3. Gestionar: Para configurar servicios vinculados y tiempos de ejecución de integración.
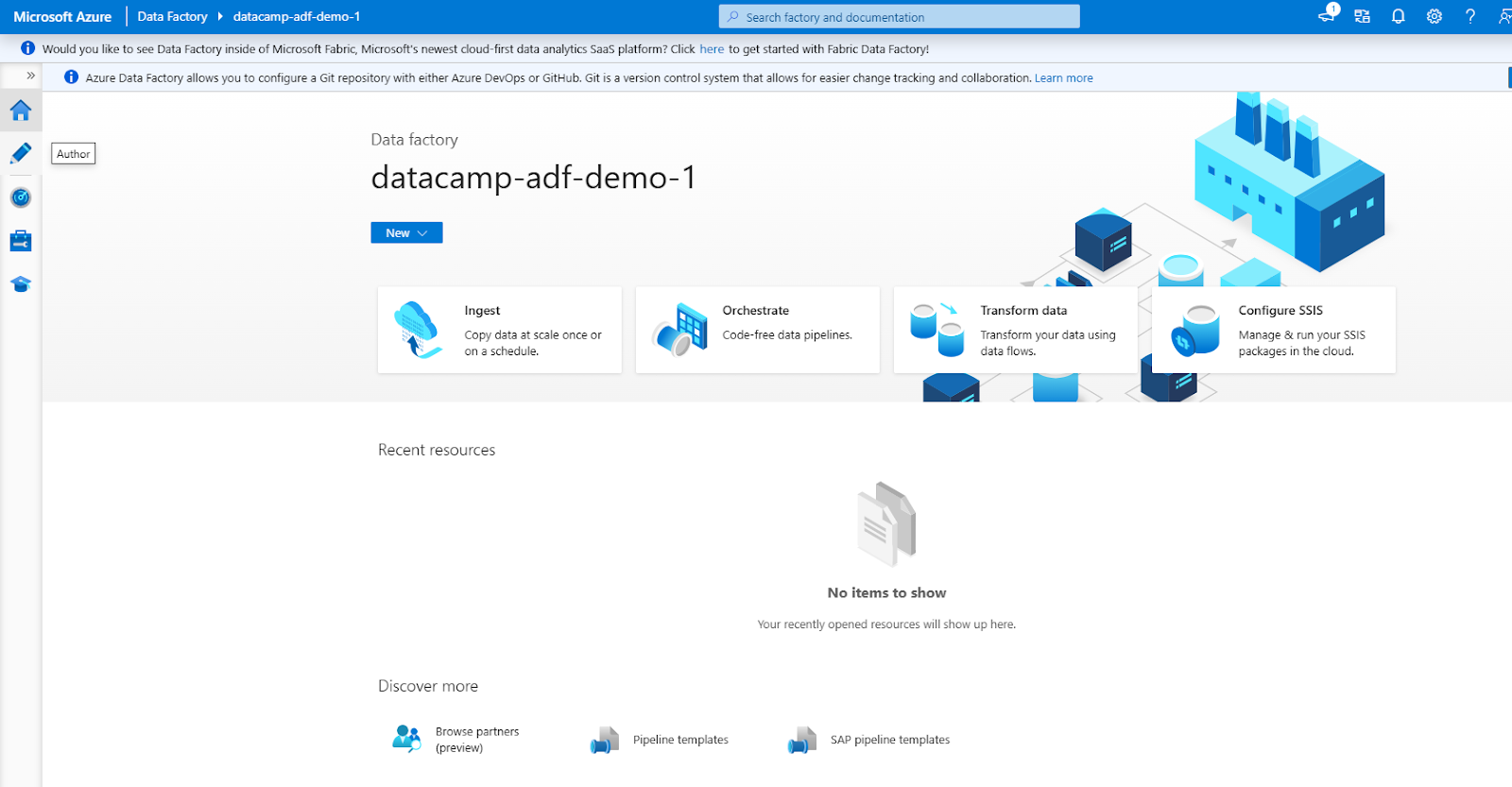
Interfaz de Azure Data Factory
Veamos los pasos para crear un canal de datos sencillo.
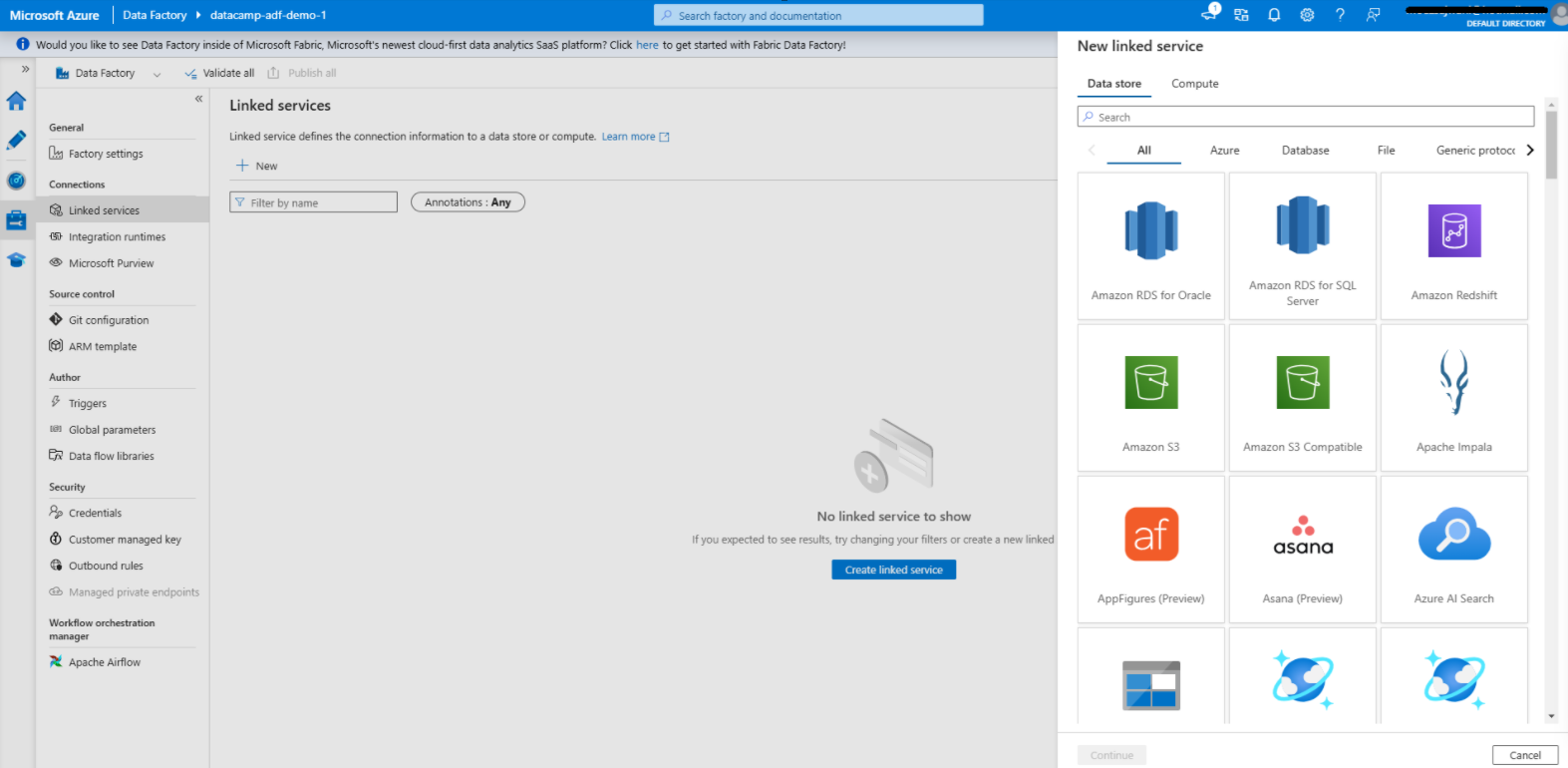
Creación de un servicio vinculado en Azure Data Factory
1. Ve a la pestaña Administrar.
2. Añadir un servicio vinculado para el origen de datos
3. Añadir un servicio vinculado para el destino de los datos
Creación de un conjunto de datos en Azure Data Factory
1. Ve a la pestaña Autor.
2. Añadir un conjunto de datos para la fuente
3. Añadir un conjunto de datos para el destino
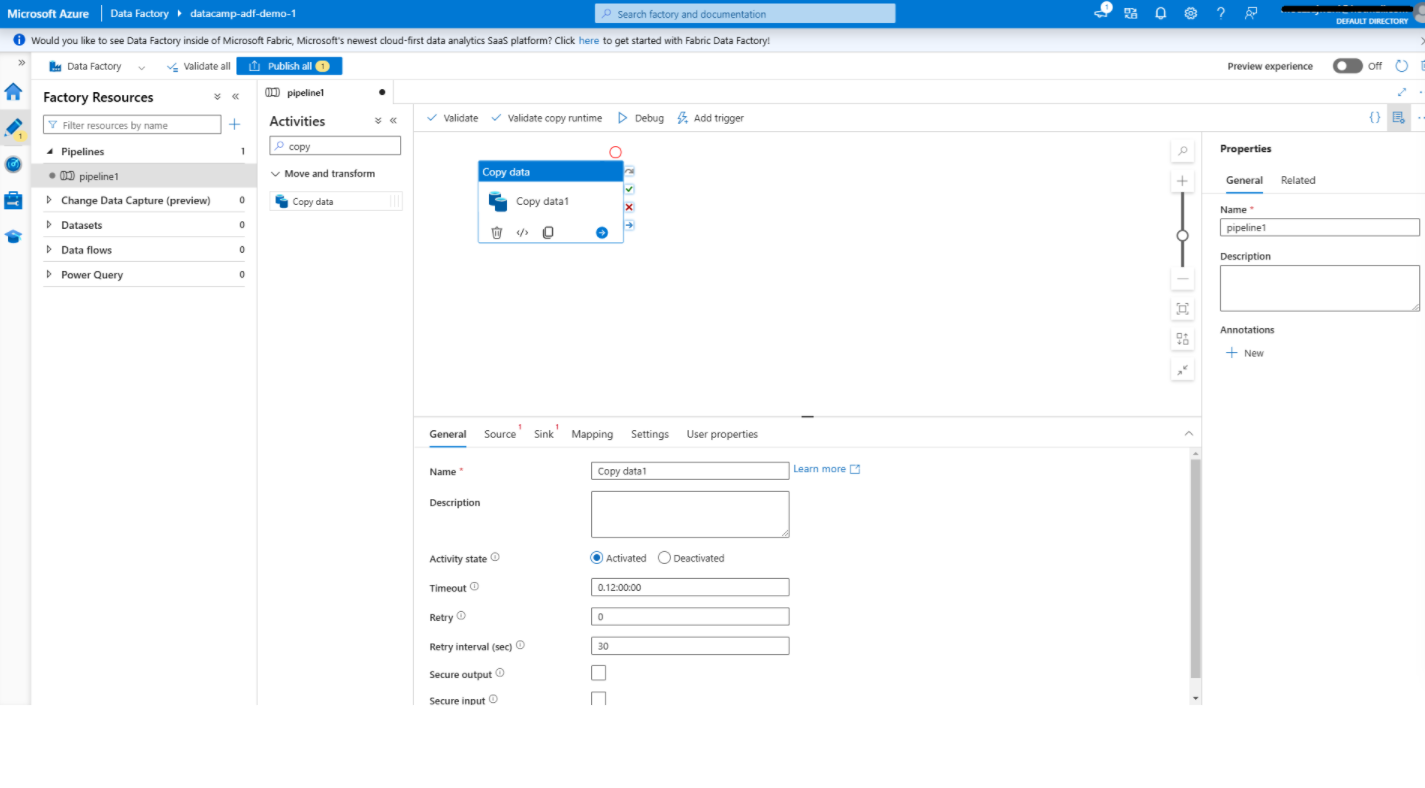
Agregar una actividad de copia de datos en Azure Data Factory
1. Abre el editor de canalizaciones.
2. Añadir la actividad de copia de datos
3. Configura la actividad de copia de datos.
Publicar canalizaciones en Azure Data Factory
1. Publica tu canalización
2. Ejecuta el proceso.
Azure Data Factory ofrece potentes funciones de integración y transformación de datos que simplifican los flujos de trabajo complejos y mejoran la productividad. En esta sección, repasaremos estas características.
Data Flows Proporciona un entorno visual para definir la lógica de transformación, lo que facilita a los usuarios la manipulación y el procesamiento de datos sin necesidad de escribir código complejo. Las tareas comunes que se realizan con los flujos de datos incluyen:
Los flujos de datos también admiten operaciones avanzadas como derivaciones de columnas, conversiones de tipos de datos y transformaciones condicionales, lo que los convierte en herramientas versátiles para manejar diversos requisitos de datos.
ADF se integra perfectamente con Azure Synapse Analytics, lo que proporcionauna plataforma unificada para el procesamiento de big data y el análisis avanzado. Esta integración permite a los usuarios:
Esta sinergia entre ADF y Synapse ayuda a optimizar los flujos de trabajo y reduce la complejidad de gestionar herramientas independientes para la integración y el análisis de datos.
Tras un análisis en profundidad de las características y componentes de ADF, veamos para qué se puede utilizar.
ADF es una potente herramienta para migrar datos de sistemas locales a plataformas basadas en la nube. Simplifica las migraciones complejas al automatizar el movimiento de datos, garantizar la integridad de los datos y minimizar el tiempo de inactividad.
Por ejemplo, puedes utilizar ADF para migrar datos desde un servidor SQL locala una base de datos SQL de Azure con una intervención manual mínima. Al aprovechar los conectores integrados y los tiempos de ejecución de integración, ADF garantiza un proceso de migración seguro y eficiente, que admite tanto datos estructurados como no estructurados.
Los procesos de extracción, transformación y carga (ETL) son el núcleo del almacenamiento de datos moderno. Azure Data Factory optimiza estos flujos de trabajo mediante la integración de datos de múltiples fuentes, la aplicación de lógica de transformación y la carga en un almacén de datos.
Por ejemplo, ADF puede consolidar datos de ventas de diferentes regiones, transformarlos a un formato unificado y cargarlos en Azure Synapse Analytics. Este proceso optimizado te permite mantener datos actualizados y de alta calidad para la elaboración de informes y la toma de decisiones.
|
Echa un vistazo a las 23 mejores herramientas ETL de 2024 y descubre por qué elegirlas. |
Los lagos de datos sirven como repositorio central para diversos conjuntos de datos, lo que permite realizar análisis avanzados y machine learning. ADF facilita la ingesta de datos de diversas fuentes en Azure Data Lake Storage, y admite escenarios por lotes y de transmisión.
Por ejemplo, puedes utilizar ADF para recopilar archivos de registro, fuentes de redes sociales y datos de sensores IoT en un único lago de datos. Al proporcionar herramientas de transformación e integración de datos, ADF garantiza que el lago de datos esté bien organizado y listo para el análisis posterior y las cargas de trabajo de IA.
Por último, vale la pena repasar algunas prácticas recomendadas para utilizar ADF de forma eficaz.
Para crear flujos de trabajo mantenibles y escalables, diseña canalizaciones con componentes reutilizables. El diseño modular facilita la depuración, las pruebas y la actualización de secciones individuales del proceso. Por ejemplo, en lugar de incorporar la lógica de transformación de datos en cada canalización, crea una canalización reutilizable que se pueda invocar en múltiples flujos de trabajo. Esto reduce la redundancia y mejora la coherencia entre los proyectos.
Entonces, ¿en qué se diferencia Azure Data Factoryde Databricks? Si tienes curiosidad y quieres descubrir las diferencias entre Azure Data Factory y Databricks, echa un vistazo a Azure Data Factory frente a Databricks: Un blog con una comparación detallada.
A medida que domines Azure Data Factory, es fundamental comprender su evolución: Microsoft Fabric.
Aunque Azure Data Factory (ADF) sigue siendo una solución robusta e independiente de plataforma como servicio (PaaS) muy utilizada en las empresas, Microsoft ha presentado Fabric como el futuro de tu ecosistema de datos. Fabric es una plataforma SaaS todo en uno que unifica Data Factory, Synapse Analytics y Power BI en un único entorno.
¿Deberías usar ADF o Fabric?
Nota: Las canalizaciones de ADF y las canalizaciones de Fabric Data Factory son muy similares, por lo que los conocimientos que adquieras hoy en ADF se pueden transferir directamente a Fabric. Puedes realizar nuestro curso Introducción a Microsoft Fabric para obtener más información.
Azure Data Factory simplifica el proceso de creación, administración y escalado de canalizaciones de datos en la nube. Proporciona una plataforma intuitiva que se adapta tanto a usuarios técnicos como no técnicos, permitiéndoles integrar y transformar datos de diversas fuentes de manera eficiente.
Al aprovechar sus características, como la creación de canalizaciones sin código, las capacidades de integración y las herramientas de supervisión, los usuarios pueden crear fácilmente flujos de trabajo escalables y fiables.
Para obtener más información sobre Azure Data Factory, te recomiendo que consultes las 27 preguntas y respuestas más frecuentes en las entrevistas sobre Azure Data Factory.
Si deseas explorar la estructura básica de Azure, incluyendo temas como contenedores, máquinas virtuales y mucho más, te recomiendo este fantástico curso gratuito sobre Comprensión de la arquitectura y los servicios de Microsoft Azure.
¡Aprende más sobre Microsoft Azure con estos cursos!
Curso
Curso
Curso
Tutorial
Moez Ali
Tutorial
Anneleen Rummens
Tutorial
Anneleen Rummens
Tutorial
Joleen Bothma
Tutorial
DataCamp Team
Tutorial
Tim Lu