
Curso
Entendendo o Microsoft Azure
3 h
47.1K
O Azure Data Factory (ADF) é o serviço de integração de dados baseado em nuvem da Microsoft, feito sob medida para organizações modernas. Ele permite que os usuários projetem, gerenciem e automatizem fluxos de trabalho que lidam com tarefas de movimentação e transformação de dados em escala empresarial.
O ADF se destaca por sua interface amigável e sem código, que permite que usuários técnicos e não técnicos criem pipelines de dados com facilidade. Seus amplos recursos de integração suportam mais de 90 conectores nativos, permitindo o fluxo de dados entre diversas fontes, incluindo sistemas locais e serviços baseados na nuvem.
Neste guia, faço uma introdução abrangente ao Azure Data Factory, abordando seus componentes e recursos e fornecendo um tutorial prático para ajudar você a criar seu primeiro pipeline de dados.
O Azure Data Factory (ADF) é um serviço de integração de dados baseado em nuvem projetado para orquestrar e automatizar fluxos de trabalho de dados.
Ele é usado para coletar, transformar e fornecer dados, garantindo que os insights sejam prontamente acessíveis para análise e tomada de decisões.
Com sua arquitetura dimensionável e sem servidor, o ADF pode lidar com fluxos de trabalho de qualquer tamanho, desde simples migrações de dados até complexos pipelines de transformação de dados.
O ADF preenche a lacuna entre os silos de dados, permitindo que os usuários movam e transformem dados entre sistemas locais, serviços em nuvem e plataformas externas. Não importa se você está trabalhando com big data, bancos de dados operacionais ou APIs, o Azure Data Factory fornece as ferramentas para conectar, processar e unificar dados com eficiência.
Aqui estão alguns dos recursos mais importantes que o ADF oferece.
O Azure Data Factory oferece suporte à integração com mais de 90 fontes de dados, incluindo sistemas baseados na nuvem e no local. Ele inclui suporte para bancos de dados SQL, sistemas NoSQL, APIs REST e fontes de dados baseadas em arquivos, permitindo que você unifique os fluxos de trabalho de dados independentemente da fonte ou do formato.

Conectores de dados disponíveis no Azure Data Factory
A interface de arrastar e soltar do ADF simplifica a forma como os usuários criam pipelines de dados. Com modelos pré-criados, assistentes de configuração guiados e um editor visual intuitivo, até mesmo usuários sem experiência em codificação podem projetar fluxos de trabalho abrangentes de ponta a ponta.
Experiência de criação sem código no Azure Data Factory
As ferramentas de agendamento do Azure Data Factory oferecem automação do fluxo de trabalho. Os usuários podem configurar acionadores com base em condições específicas, como a chegada de um arquivo ao armazenamento em nuvem ou intervalos de tempo programados. Essas opções de agendamento eliminam a necessidade de intervenções manuais e garantem que os fluxos de trabalho sejam executados de forma consistente e confiável.
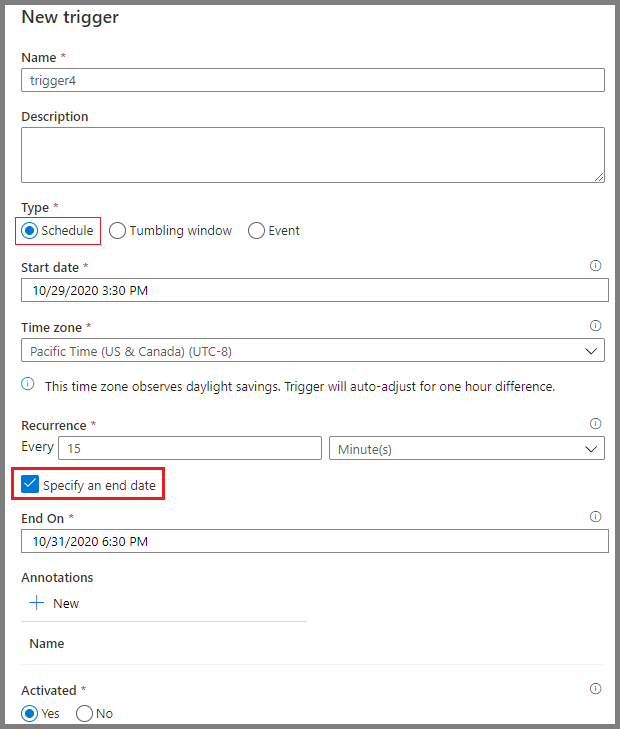
Agendamento de pipelines no Azure Data Factory
Compreender os principais componentes do Azure Data Factory é essencial para que você crie fluxos de trabalho eficientes.
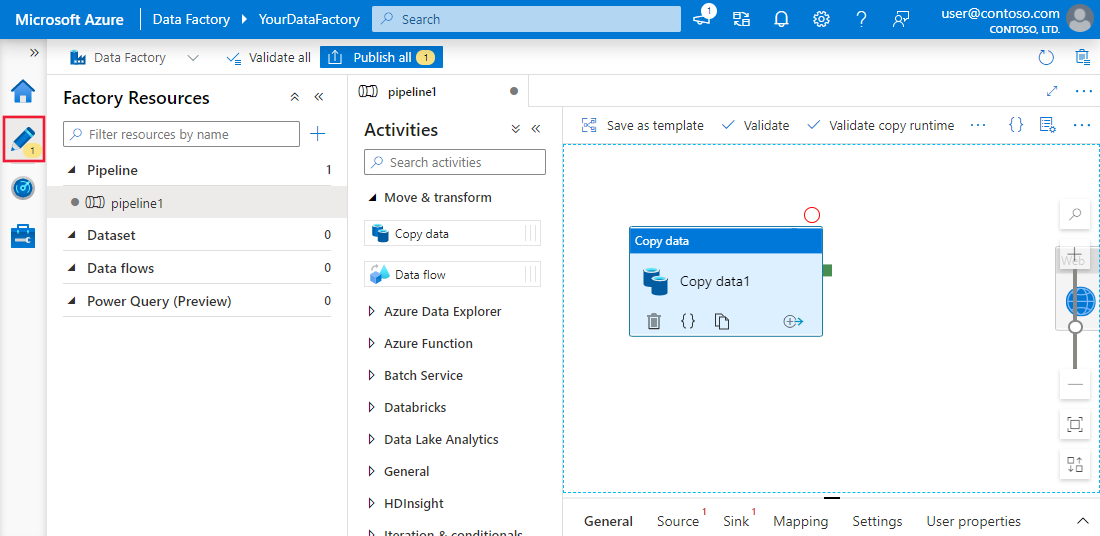
Os pipelines são a espinha dorsal do Azure Data Factory. Eles representam fluxos de trabalho orientados por dados que definem as etapas necessárias para mover e transformar dados.
Cada pipeline serve como um contêiner para uma ou mais atividades, executadas sequencialmente ou em paralelo, para obter o fluxo de dados desejado.
Esses pipelines permitem que os engenheiros de dados criem processos de ponta a ponta, como a ingestão de dados brutos, a transformação em um formato utilizável e o carregamento em sistemas de destino.
Exemplo de pipeline simples no Azure Data Factory
As atividades são os blocos de construção funcionais dos pipelines, cada um executando uma operação específica. Eles são amplamente categorizados em:
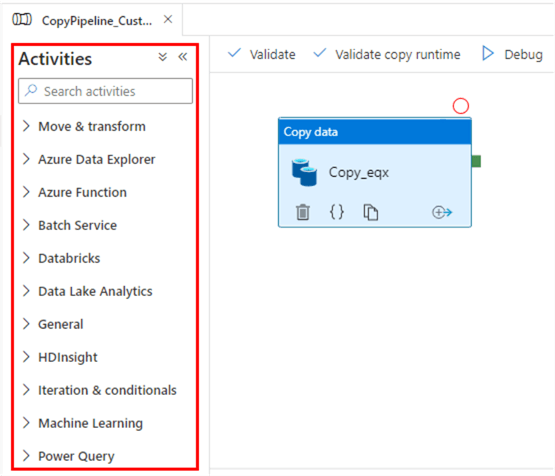
Atividades no Azure Data Factory
Os conjuntos de dados são representações dos dados utilizados nas atividades. Eles definem o esquema, o formato e o local dos dados que estão sendo ingeridos ou processados.
Por exemplo, um conjunto de dados pode descrever um arquivo CSV no Azure Blob Storage ou uma tabela em um banco de dados SQL do Azure. Os conjuntos de dados são a camada intermediária que conecta as atividades às fontes e aos destinos reais dos dados.
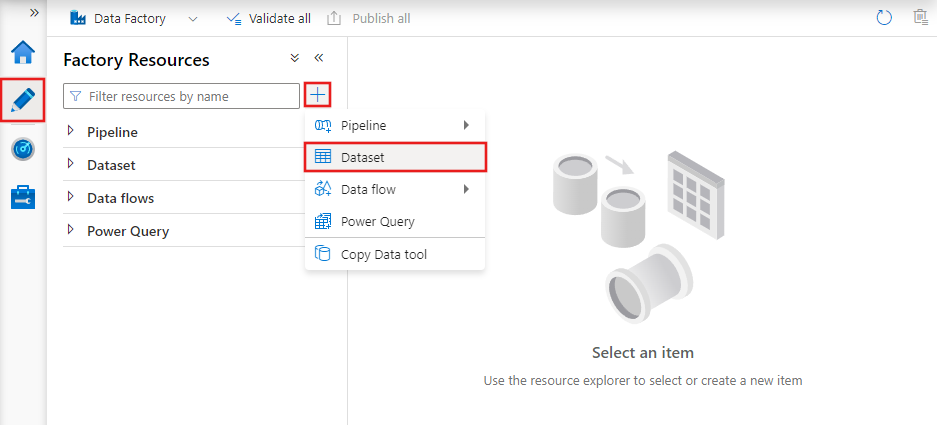
Conjuntos de dados no Azure Data Factory
Os serviços vinculados são cadeias de conexão que permitem que atividades e conjuntos de dados acessem sistemas e serviços externos.
Eles atuam como pontes entre o Azure Data Factory e os recursos externos com os quais ele interage, como bancos de dados, contas de armazenamento ou ambientes de computação.
Por exemplo, um serviço vinculado pode se conectar a um SQL Server local ou a um data lake baseado na nuvem.
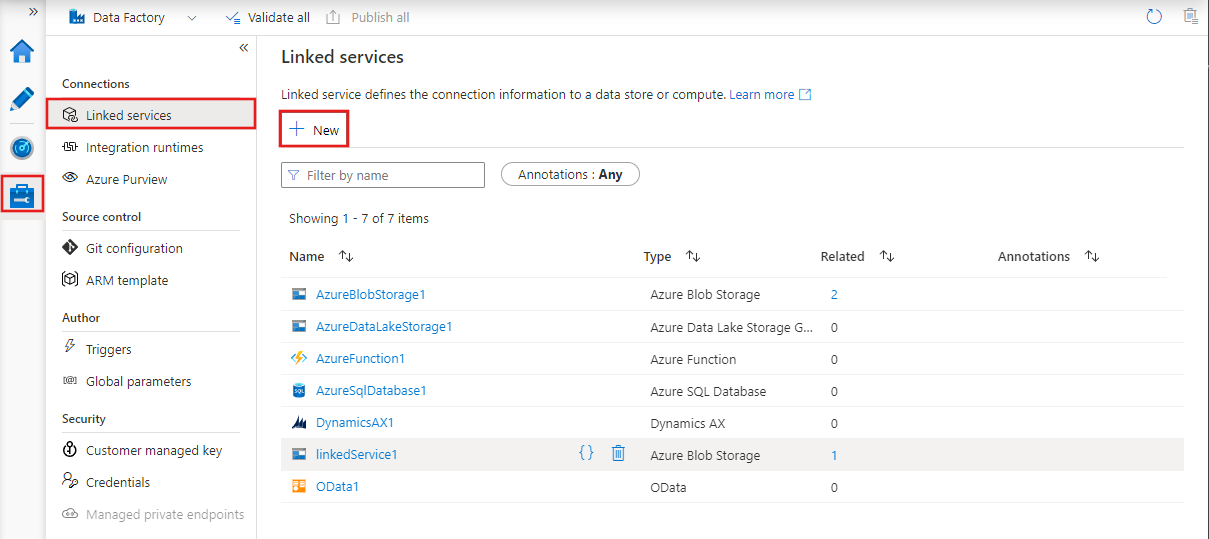
Serviços vinculados no Azure Data Factory
Os runtimes de integração (IRs) são os ambientes de computação que potencializam a movimentação de dados, a transformação e a execução de atividades no Azure Data Factory. O ADF oferece três tipos de tempos de execução de integração:
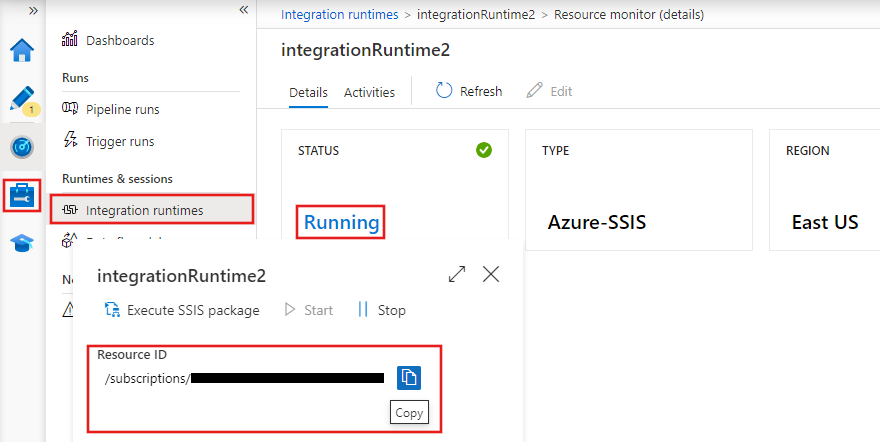
Tempos de execução de integração no Azure Data Factory
Agora, vamos passar para a seção prática deste guia!
1. Uma assinatura ativa doe do Azure.
2. Um grupo de recursos para gerenciaros recursos do Azure.
1. Faça login em no portal do Azure.
2. Navegue até Criar um recurso e selecione Data Factory.
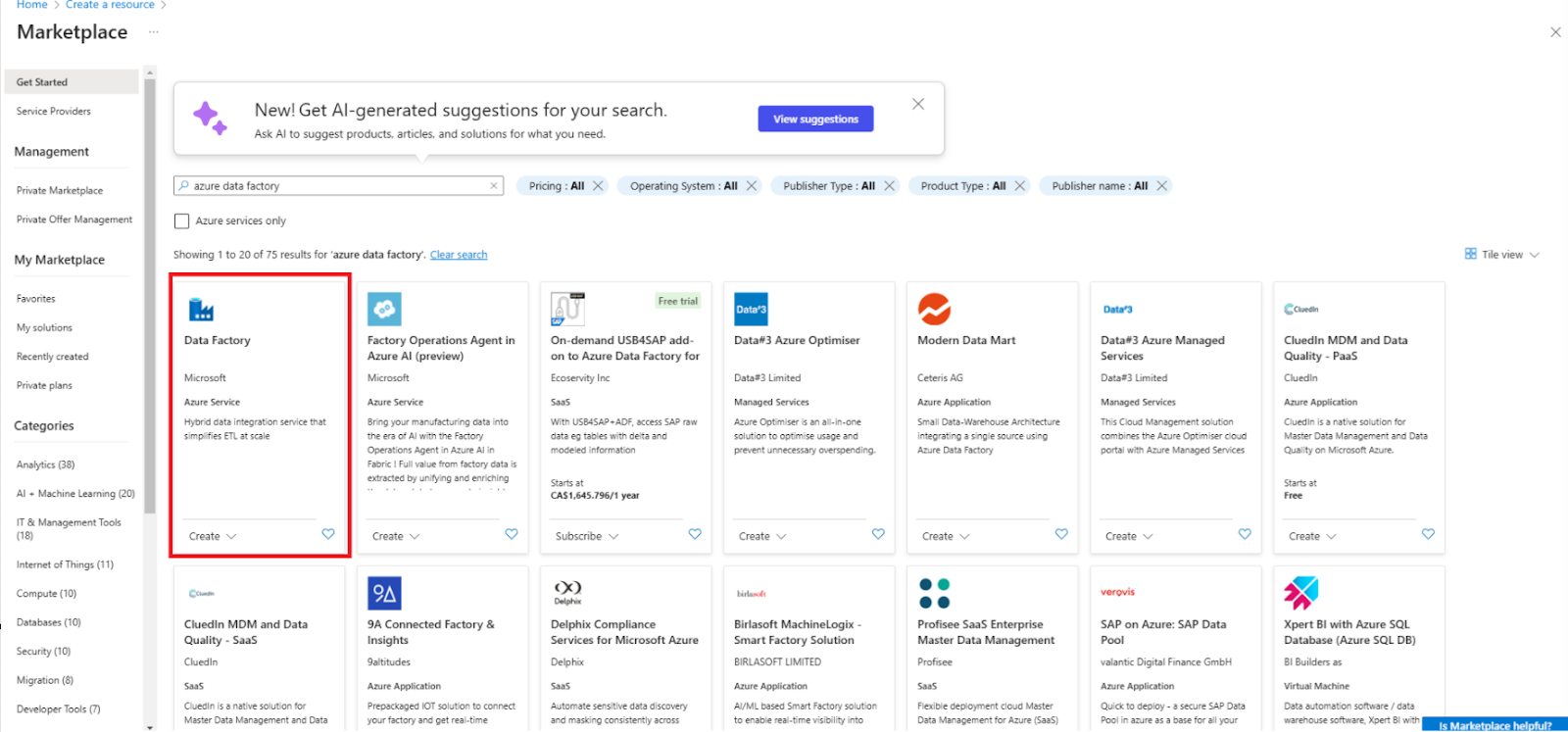
Criar um novo recurso do Data Factory
3. Preencha os campos obrigatórios, incluindo assinatura, grupo de recursos e região.
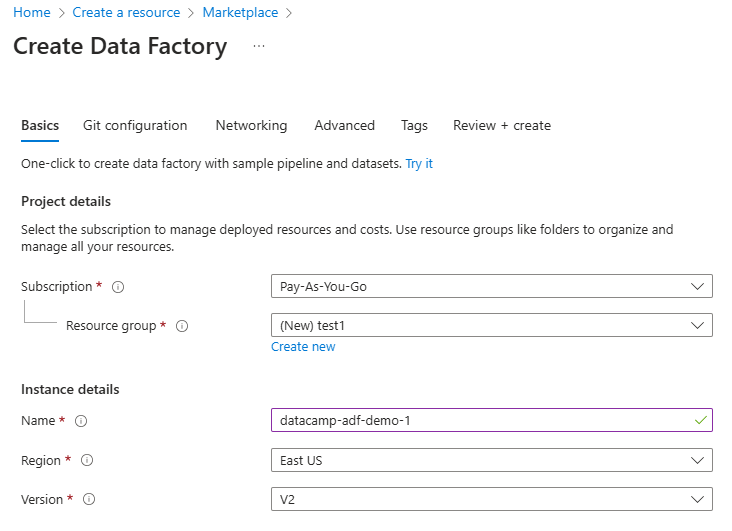
Configurar o recurso Data Factory
4. Revise e crie a instância.
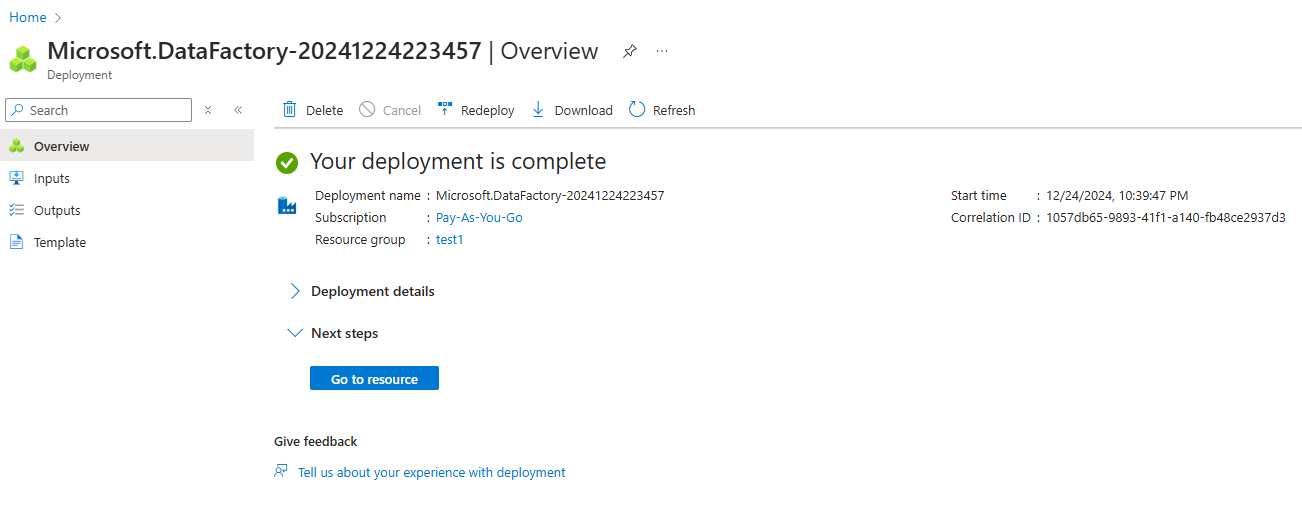
Instância do Azure Data Factory criada
A interface do ADF consiste nas seguintes seções principais (acessíveis pelo menu de navegação à esquerda)
1. Autor: Para criar e gerenciar pipelines.
2. Monitor: Acompanhar as execuções do pipeline e solucionar problemas.
3. Gerencie: Para configurar serviços vinculados e tempos de execução de integração.
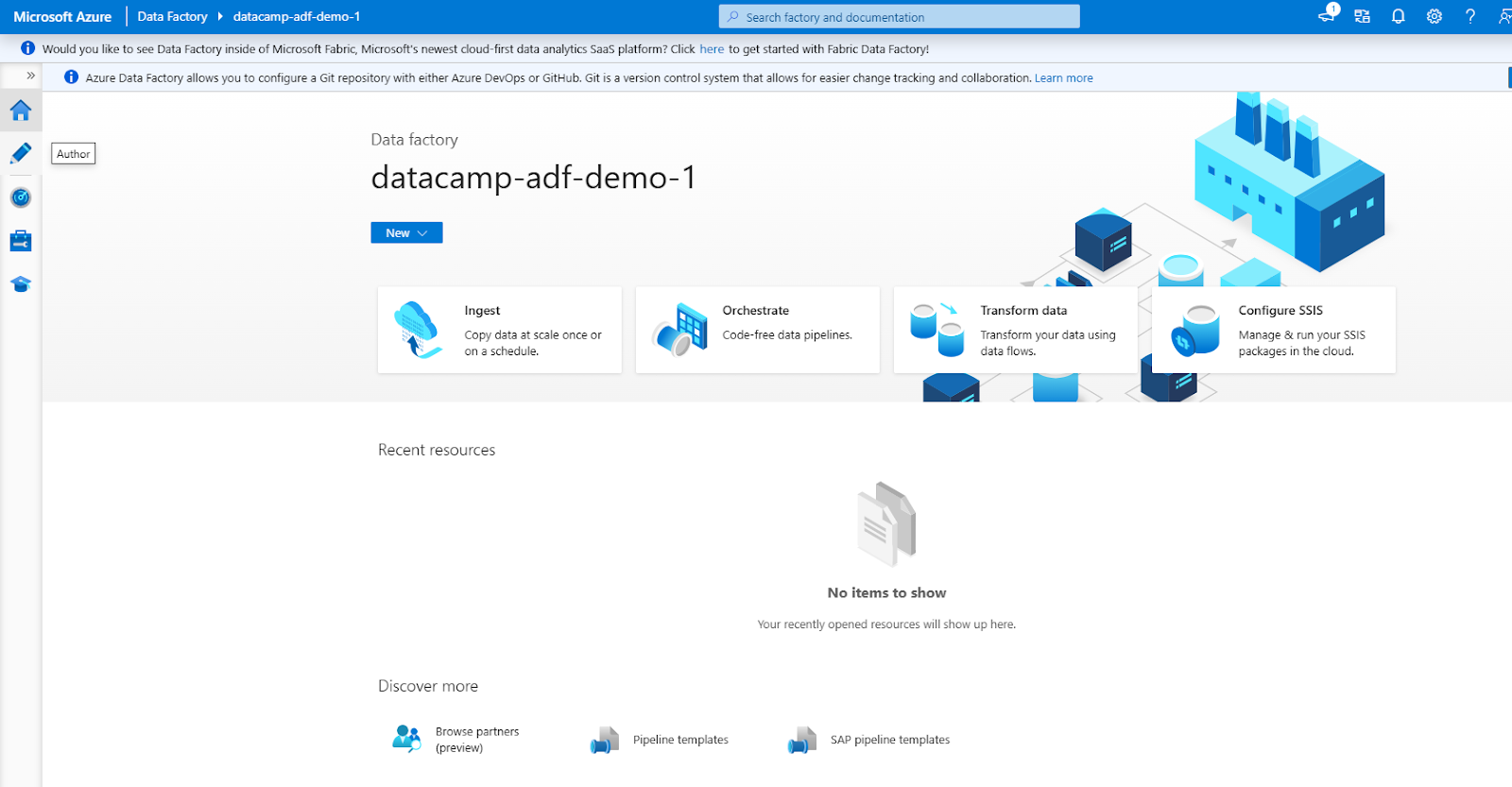
Interface do Azure Data Factory
Vamos examinar as etapas para criar um pipeline de dados simples.
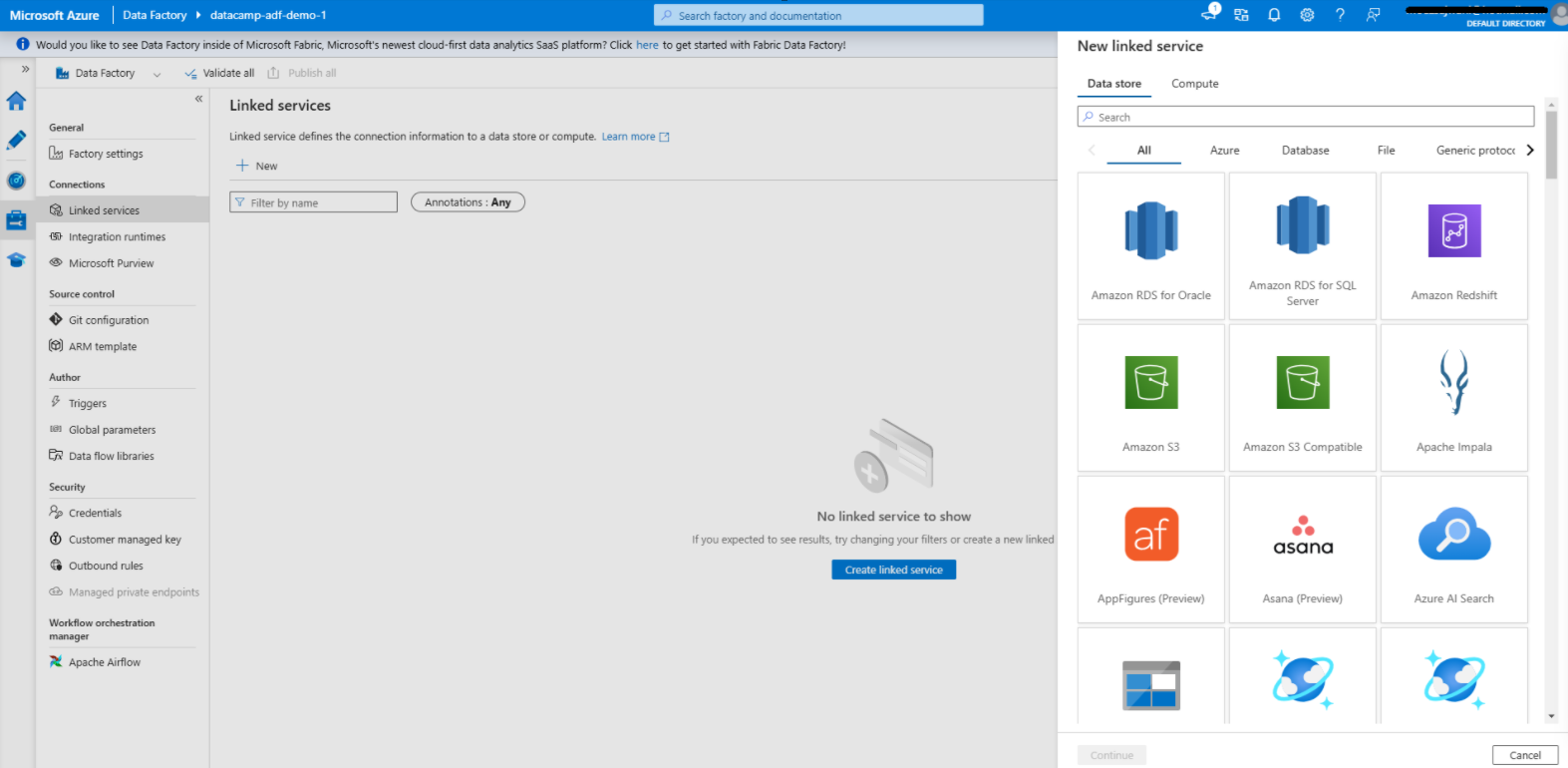
Criando um serviço vinculado no Azure Data Factory
1. Navegue até a guia Gerenciar
2. Adicionar um serviço vinculado para a fonte de dados
3. Adicionar um serviço vinculado para o destino dos dados
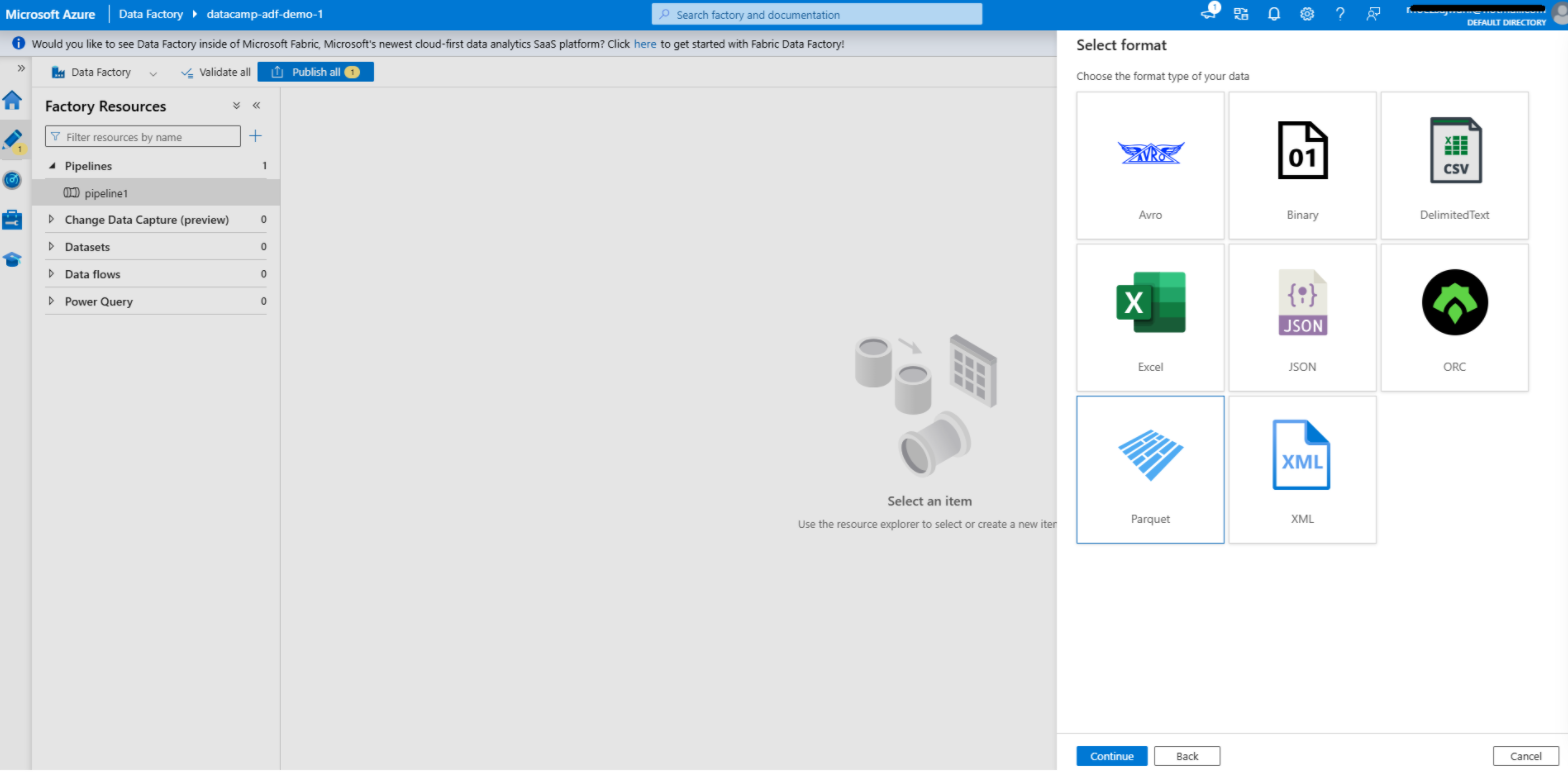
Criar um conjunto de dados no Azure Data Factory
1. Navegue até a guia Author (Autor)
2. Adicionar um conjunto de dados para a fonte
3. Adicionar um conjunto de dados para o destino
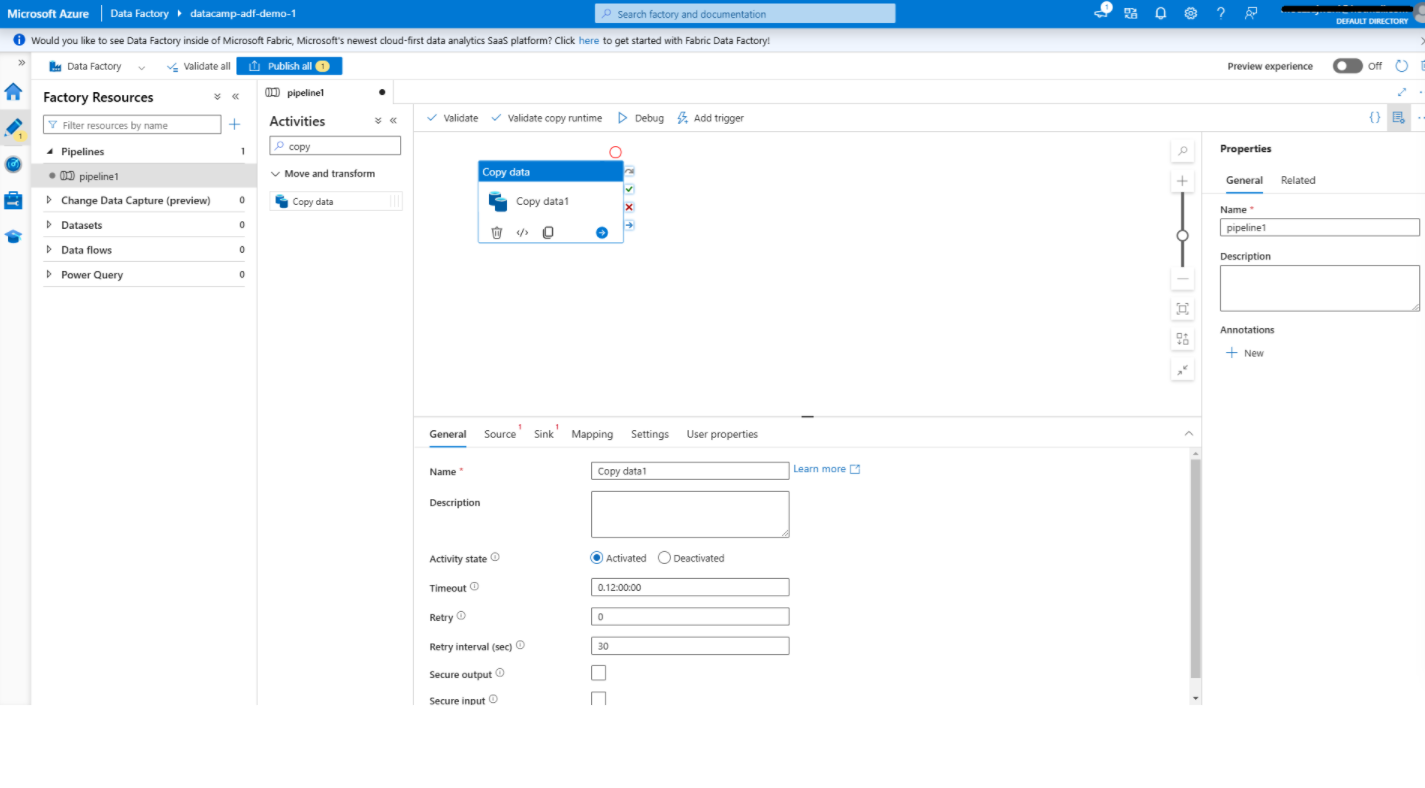
Adição de uma atividade de cópia de dados no Azure Data Factory
1. Abra o editor de pipeline
2. Adicione a atividade de cópia de dados
3. Configurar a atividade de cópia de dados
Publicação de pipelines no Azure Data Factory
1. Publique seu pipeline
2. Executar o pipeline
O Azure Data Factory oferece recursos avançados de integração e transformação de dados que simplificam fluxos de trabalho complexos e aumentam a produtividade. Nesta seção, analisaremos esses recursos.
Fluxos de dados provide um ambiente visual para definir a lógica de transformação, facilitando aos usuários a manipulação e o processamento de dados sem a necessidade de escrever códigos complexos. As tarefas comuns realizadas com fluxos de dados incluem:
Os fluxos de dados também suportam operações avançadas, como derivações de colunas, conversões de tipos de dados e transformações condicionais, o que os torna ferramentas versáteis para lidar com diversos requisitos de dados.
O ADF se integra perfeitamente ao Azure Synapse Analytics, providenciando uma plataforma unificada para processamento de big data e análise avançada. Essa integração permite que os usuários:
Essa sinergia entre o ADF e o Synapse ajuda a otimizar os fluxos de trabalho e reduz a complexidade do gerenciamento de ferramentas separadas para integração e análise de dados.
Depois de uma análise detalhada dos recursos e componentes do ADF, vamos ver para que ele pode ser usado.
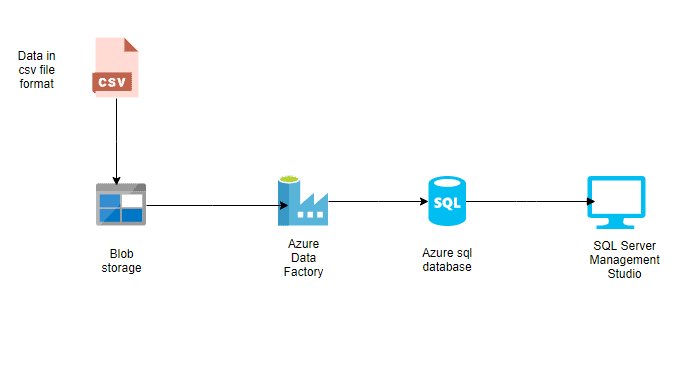
O ADF é uma ferramenta poderosa para migrar dados de sistemas locais para plataformas baseadas na nuvem. Ele simplifica migrações complexas, automatizando a movimentação de dados, garantindo a integridade dos dados e minimizando o tempo de inatividade.
Por exemplo, você pode usar o ADF para migrar dados de um SQL Server localpara um banco de dados SQL do Azure com o mínimo de intervenção manual. Ao aproveitar os conectores integrados e os tempos de execução de integração, o ADF garante um processo de migração seguro e eficiente, acomodando dados estruturados e não estruturados.
Os processos de extração, transformação e carregamento (ETL) estão no centro do armazenamento de dados moderno. O Azure Data Factory simplifica esses fluxos de trabalho integrando dados de várias fontes, aplicando a lógica de transformação e carregando-os em um data warehouse.
Por exemplo, o ADF pode consolidar dados de vendas de diferentes regiões, transformá-los em um formato unificado e carregá-los no Azure Synapse Analytics. Esse processo simplificado permite que você mantenha dados atualizados e de alta qualidade para relatórios e tomada de decisões.
|
Confira as 23 melhores ferramentas de ETL em 2024 e por que você deve escolhê-las. |
Os data lakes funcionam como um repositório central para diversos conjuntos de dados, permitindo análises avançadas e aprendizado de máquina. O ADF facilita a ingestão de dados de várias fontes no armazenamento do Azure Data Lake, oferecendo suporte a cenários de fluxo contínuo e em lote.
Por exemplo, você pode usar o ADF para coletar arquivos de log, feeds de mídia social e dados de sensores de IoT em um único data lake. Ao fornecer ferramentas de transformação e integração de dados, o ADF garante que o data lake esteja bem organizado e pronto para análises downstream e cargas de trabalho de IA.
Por fim, vale a pena revisar algumas práticas recomendadas para usar o ADF de forma eficaz.
Para criar fluxos de trabalho manuteníveis e dimensionáveis, projete pipelines com componentes reutilizáveis. O design modular facilita a depuração, o teste e a atualização de seções individuais do pipeline. Por exemplo, em vez de incorporar a lógica de transformação de dados em cada pipeline, crie um pipeline reutilizável que possa ser invocado em vários fluxos de trabalho. Isso reduz a redundância e aumenta a consistência entre os projetos.
Então, qual é a diferença entre o Azure Data Factorye o Databricks? Se você estiver curioso e quiser descobrir as diferenças entre o Azure Data Factory e o Databricks, consulte Azure Data Factory vs Databricks: Uma comparação detalhada blog.
O Azure Data Factory simplifica o processo de criação, gerenciamento e dimensionamento de pipelines de dados na nuvem. Ele fornece uma plataforma intuitiva que atende a usuários técnicos e não técnicos, permitindo que eles integrem e transformem dados de várias fontes com eficiência.
Ao aproveitar seus recursos, como criação de pipeline sem código, recursos de integração e ferramentas de monitoramento, os usuários podem criar facilmente fluxos de trabalho dimensionáveis e confiáveis.
Para saber mais sobre o Azure Data Factory, recomendo que você confira as 27 principais perguntas e respostas da entrevista sobre o Azure Data Factory.
Se você quiser explorar a espinha dorsal do Azure, incluindo tópicos como contêineres, máquinas virtuais e muito mais, minha recomendação é este incrível curso gratuito sobre Entendendo a arquitetura e os serviços do Microsoft Azure.
Saiba mais sobre o Microsoft Azure com estes cursos!
Curso
Curso
Curso
Tutorial
Tim Lu
Tutorial
DataCamp Team
Tutorial
Zoumana Keita
Tutorial
Vidhi Chugh
Tutorial
Zoumana Keita
Tutorial
Bex Tuychiev