
Corso
Capire Microsoft Azure
3 h
48.2K
Azure Data Factory (ADF) è il servizio di integrazione dati basato su cloud di Microsoft, pensato per le organizzazioni moderne. Consente di progettare, gestire e automatizzare workflow che gestiscono attività di movimento e trasformazione dei dati su scala enterprise.
ADF si distingue per un'interfaccia no-code semplice da usare, che permette sia agli utenti tecnici che non tecnici di creare pipeline di dati con facilità. Le sue ampie capacità di integrazione supportano oltre 90 connettori nativi, abilitando il flusso di dati tra fonti diverse, inclusi sistemi on-premise e servizi cloud.
In questa guida, ti offro un'introduzione completa ad Azure Data Factory, illustrandone componenti e funzionalità e fornendo un tutorial pratico per aiutarti a creare la tua prima pipeline di dati.
Azure Data Factory (ADF) è un servizio di integrazione dati basato su cloud progettato per orchestrare e automatizzare workflow di dati.
Viene usato per raccogliere, trasformare e distribuire dati, garantendo che le informazioni siano facilmente accessibili per analisi e decisioni.
Grazie alla sua architettura scalabile e serverless, ADF può gestire workflow di qualsiasi dimensione—dalle semplici migrazioni di dati a pipeline di trasformazione complesse.
ADF colma il divario tra silos di dati, consentendo di spostare e trasformare i dati tra sistemi on-premise, servizi cloud e piattaforme esterne. Che tu stia lavorando con big data, database operativi o API, Azure Data Factory offre gli strumenti per connettere, elaborare e unificare i dati in modo efficiente.
Ecco alcune delle funzionalità più importanti offerte da ADF.
Azure Data Factory supporta l'integrazione con oltre 100 connettori nativi, inclusi sistemi cloud e on-premise. Include il supporto per database SQL, sistemi NoSQL, API REST e fonti file-based, permettendoti di unificare i workflow di dati indipendentemente dalla sorgente o dal formato. È il motore di base che alimenta anche le capacità di integrazione dei dati in Microsoft Fabric, la piattaforma dati unificata di Microsoft.

Connettori dati disponibili in Azure Data Factory
L'interfaccia drag-and-drop di ADF semplifica la creazione di pipeline di dati. Con template predefiniti, procedure guidate di configurazione e un editor visivo intuitivo, anche chi non ha competenze di coding può progettare workflow end-to-end completi.
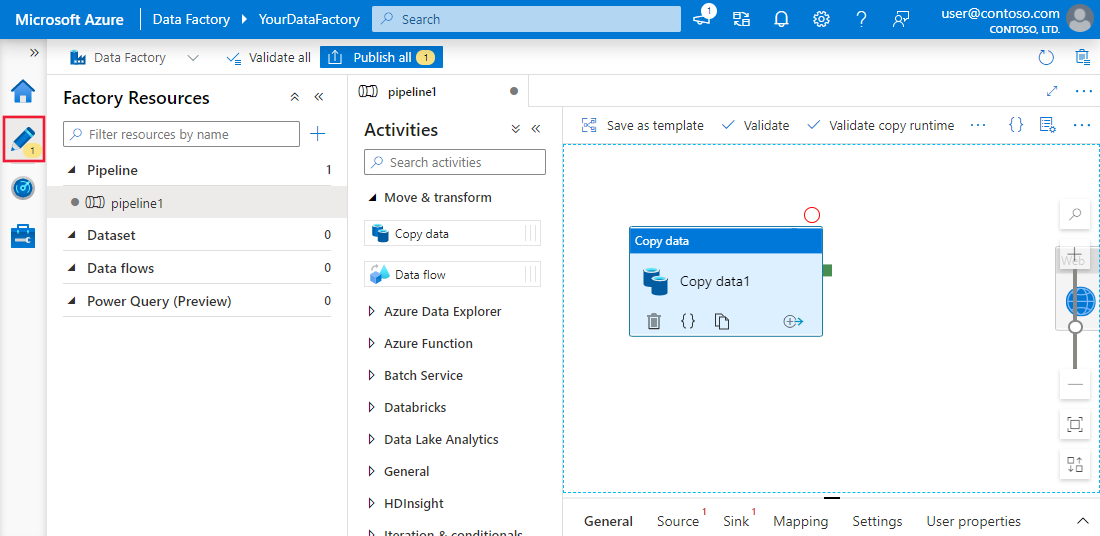
Esperienza di authoring no-code in Azure Data Factory
Gli strumenti di pianificazione di Azure Data Factory offrono automazione dei workflow. Puoi impostare trigger basati su condizioni specifiche, come l'arrivo di un file nello storage cloud o intervalli di tempo programmati. Queste opzioni eliminano la necessità di interventi manuali e garantiscono l'esecuzione dei workflow in modo coerente e affidabile.
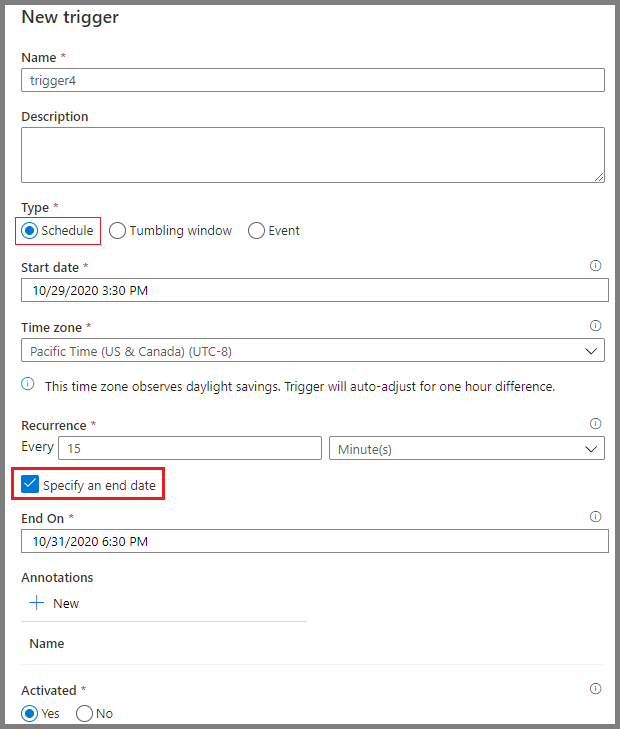
Pianificazione delle pipeline in Azure Data Factory
Comprendere i componenti principali di Azure Data Factory è essenziale per creare workflow efficienti.
Le pipeline sono la spina dorsale di Azure Data Factory. Rappresentano workflow guidati dai dati che definiscono i passaggi necessari per spostare e trasformare i dati.
Ogni pipeline funge da contenitore per una o più attività, eseguite in sequenza o in parallelo, per ottenere il flusso di dati desiderato.
Queste pipeline consentono ai data engineer di creare processi end-to-end, come l'ingestione di dati grezzi, la loro trasformazione in un formato utilizzabile e il caricamento nei sistemi di destinazione.
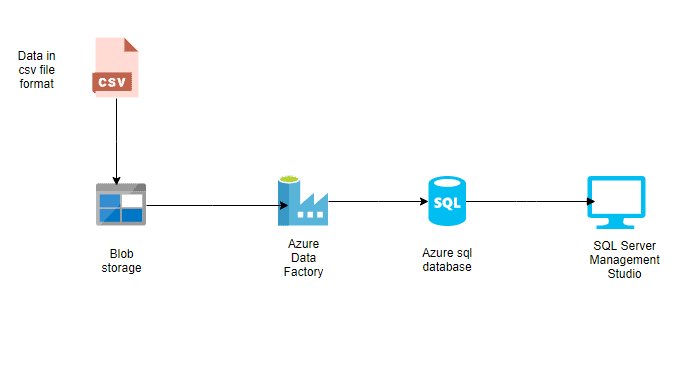
Esempio di pipeline semplice in Azure Data Factory
Le attività sono i blocchi funzionali delle pipeline, ognuna delle quali esegue un'operazione specifica. Si classificano ampiamente in:
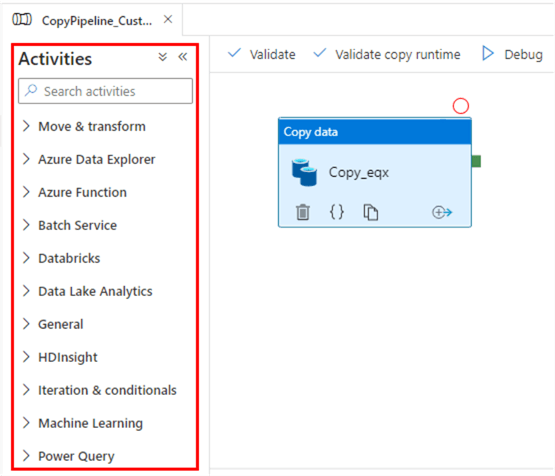
Attività in Azure Data Factory
I dataset sono rappresentazioni dei dati utilizzati nelle attività. Definiscono schema, formato e posizione dei dati acquisiti o elaborati.
Ad esempio, un dataset può descrivere un file CSV in Azure Blob Storage o una tabella in un Azure SQL Database. I dataset sono il livello intermedio che collega le attività alle effettive sorgenti e destinazioni dei dati.
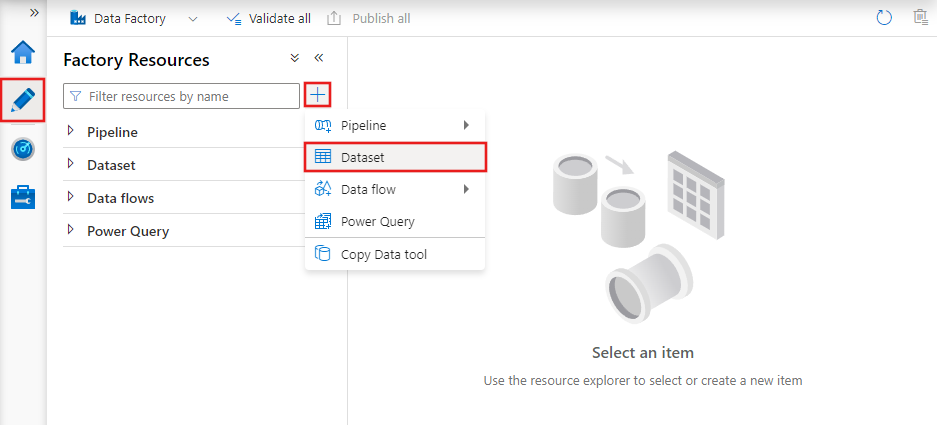
Dataset in Azure Data Factory
I servizi collegati sono stringhe di connessione che consentono ad attività e dataset di accedere a sistemi e servizi esterni.
Agiscono da ponte tra Azure Data Factory e le risorse esterne con cui interagisce, come database, account di archiviazione o ambienti di calcolo.
Ad esempio, un servizio collegato può connettersi a un SQL Server on-premise o a un data lake nel cloud.
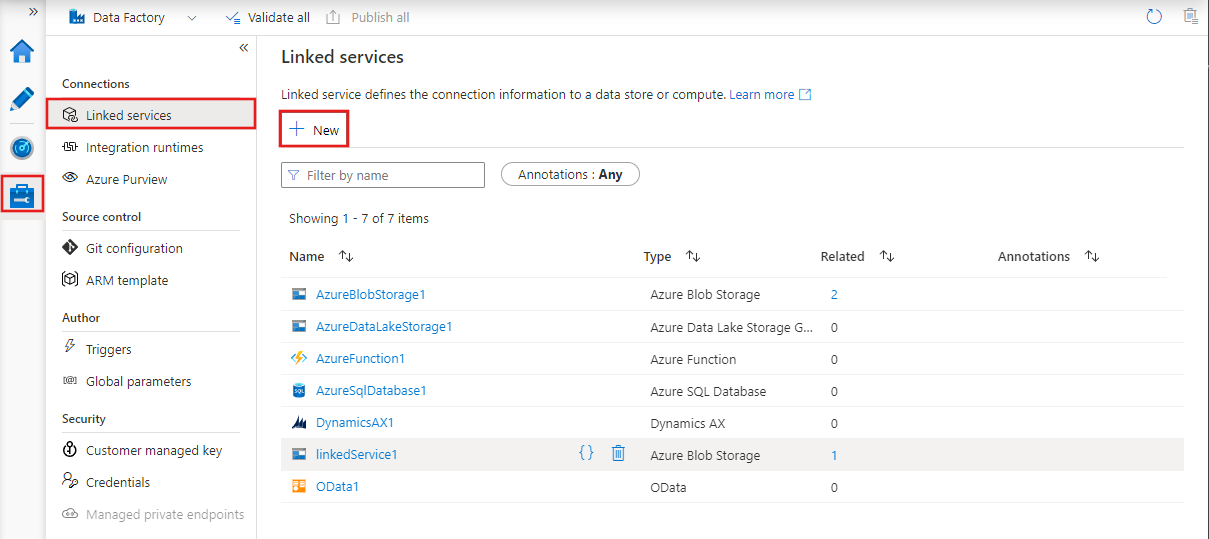
Linked services in Azure Data Factory
Gli integration runtime (IR) sono gli ambienti di calcolo che alimentano lo spostamento, la trasformazione e l'esecuzione delle attività all'interno di Azure Data Factory. ADF fornisce tre tipi di integration runtime:
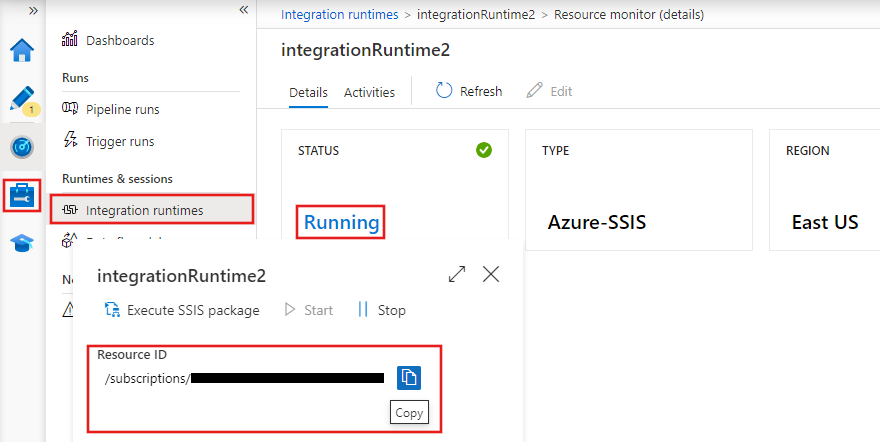
Integration runtime in Azure Data Factory
Passiamo ora alla parte pratica di questa guida!
1. Una sottoscrizione Azure attiva.
2. Un gruppo di risorse per gestire le risorse Azure.
1. Accedi al portale di Azure.
2. Vai a Create a resource e seleziona Data Factory.
Crea una nuova risorsa Data Factory
3. Compila i campi richiesti, inclusi sottoscrizione, gruppo di risorse e area geografica.
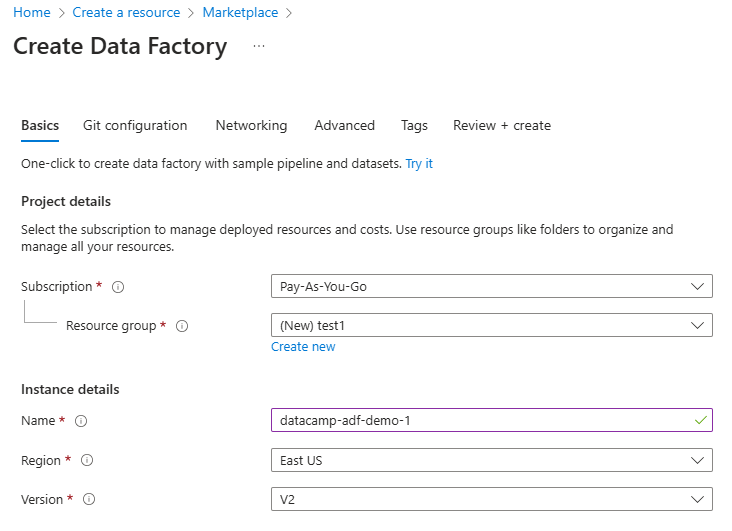
Configura la risorsa Data Factory
4. Verifica e crea l'istanza.
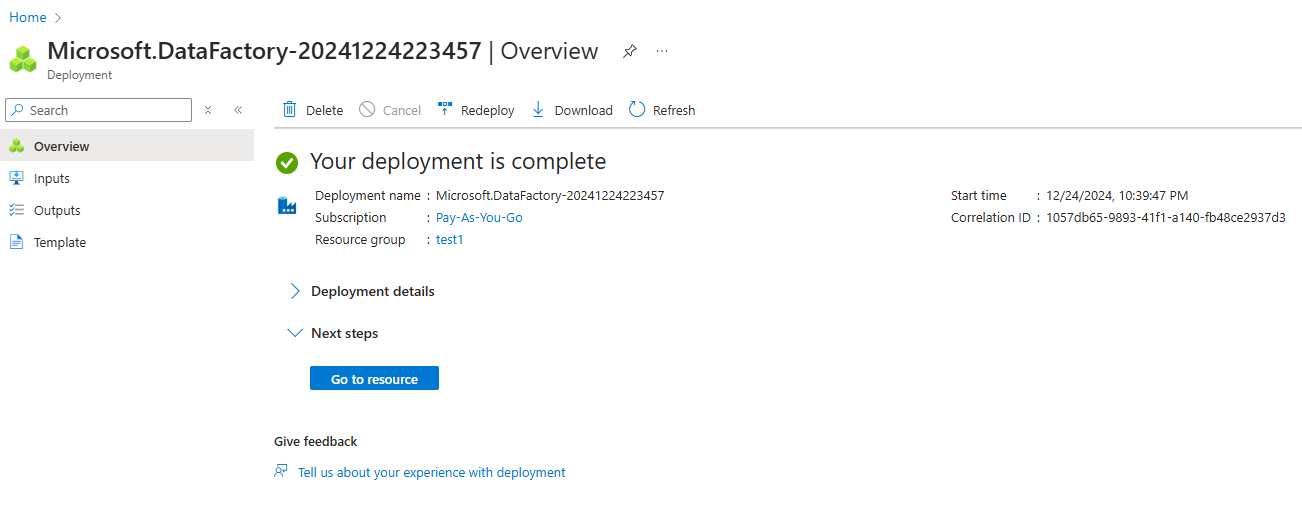
Istanza di Azure Data Factory creata
L'interfaccia di ADF è composta dalle seguenti sezioni principali (accessibili tramite il menu di navigazione a sinistra)
1. Author: per creare e gestire le pipeline.
2. Monitor: per tracciare le esecuzioni delle pipeline e risolvere i problemi.
3. Manage: per configurare i servizi collegati e gli integration runtime.
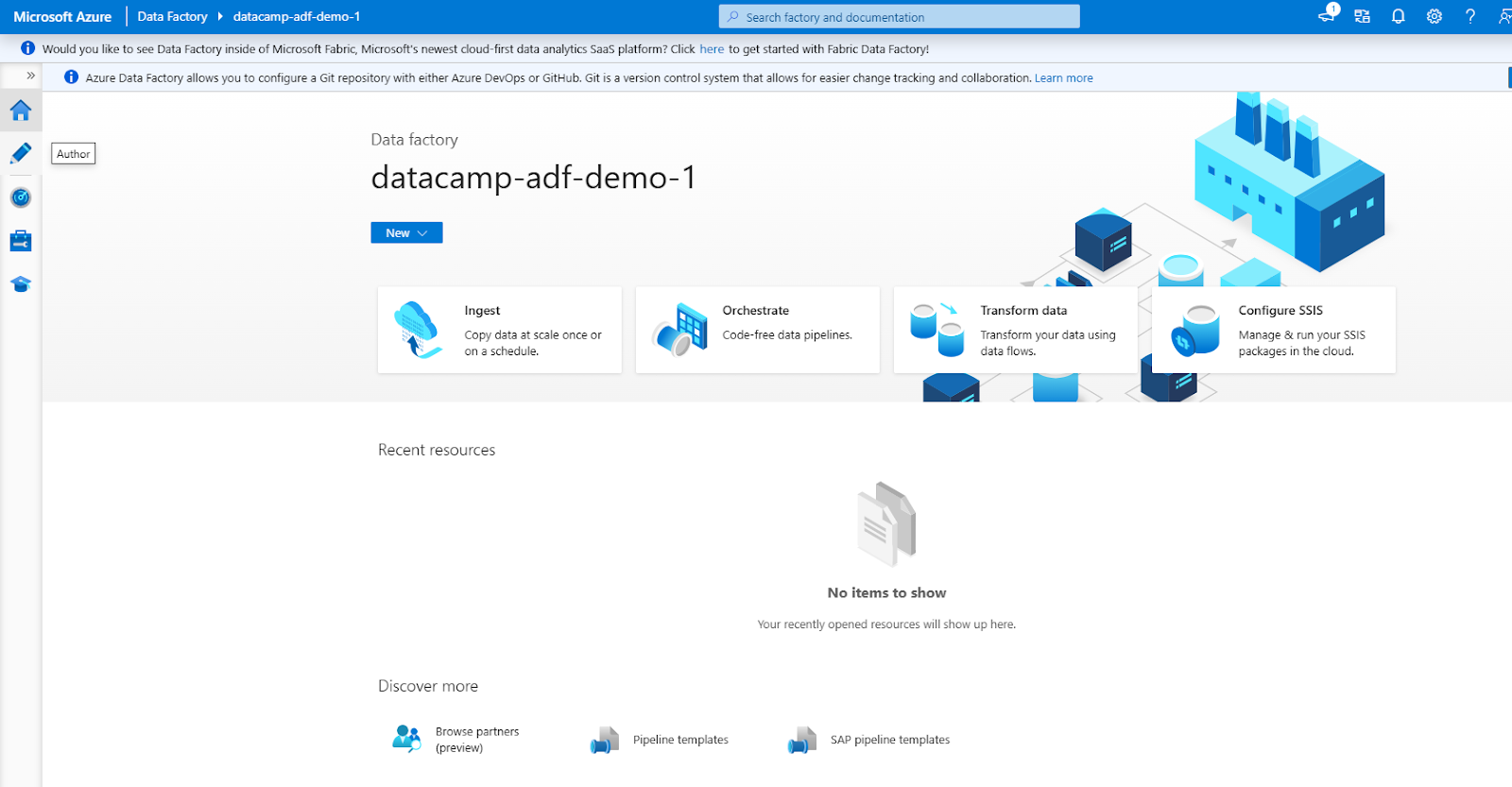
Interfaccia di Azure Data Factory
Vediamo i passaggi per creare una semplice pipeline di dati.
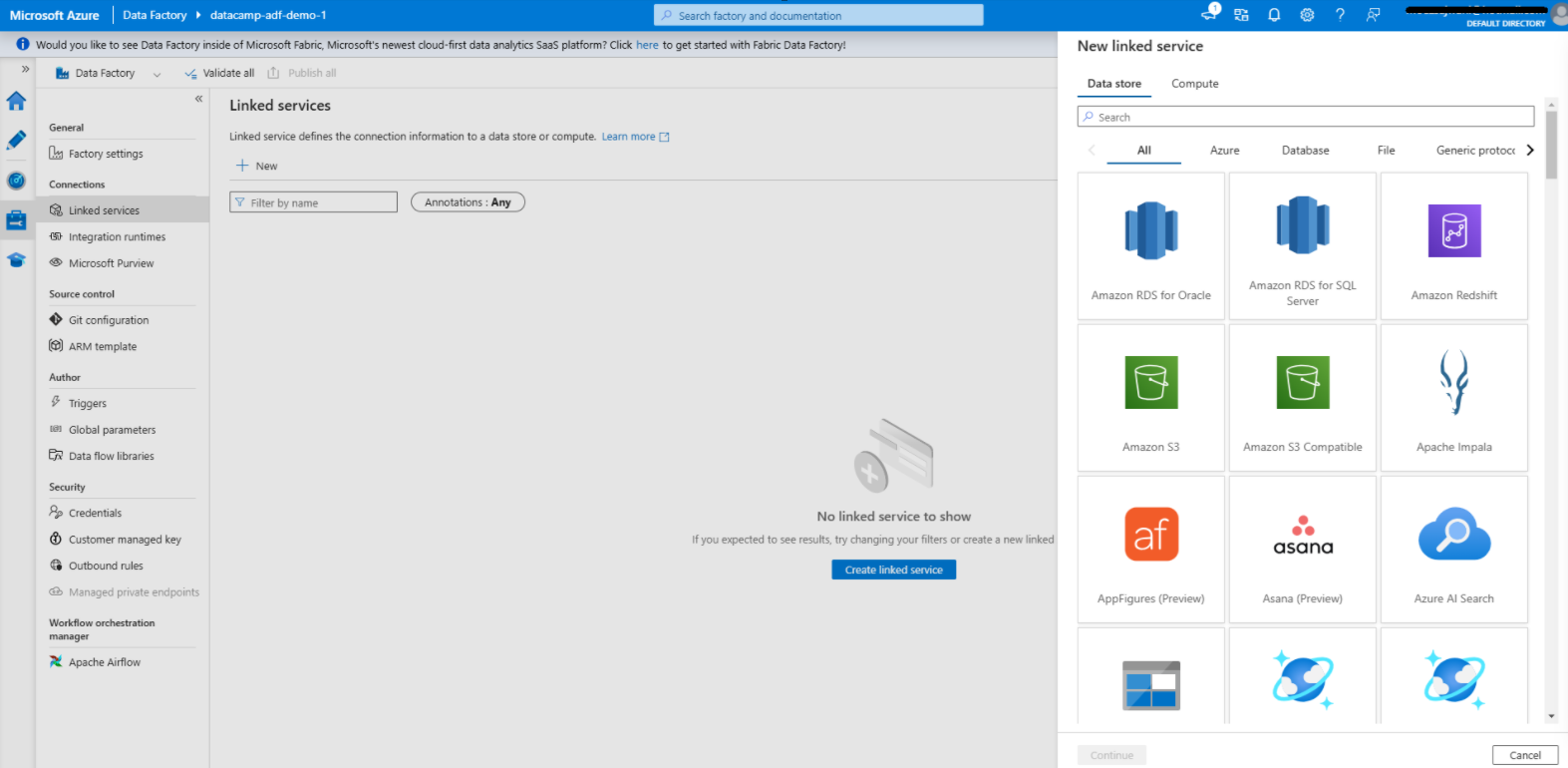
Creazione di un Linked service in Azure Data Factory
1. Vai alla scheda Manage
2. Aggiungi un servizio collegato per la sorgente dati
3. Aggiungi un servizio collegato per la destinazione dati
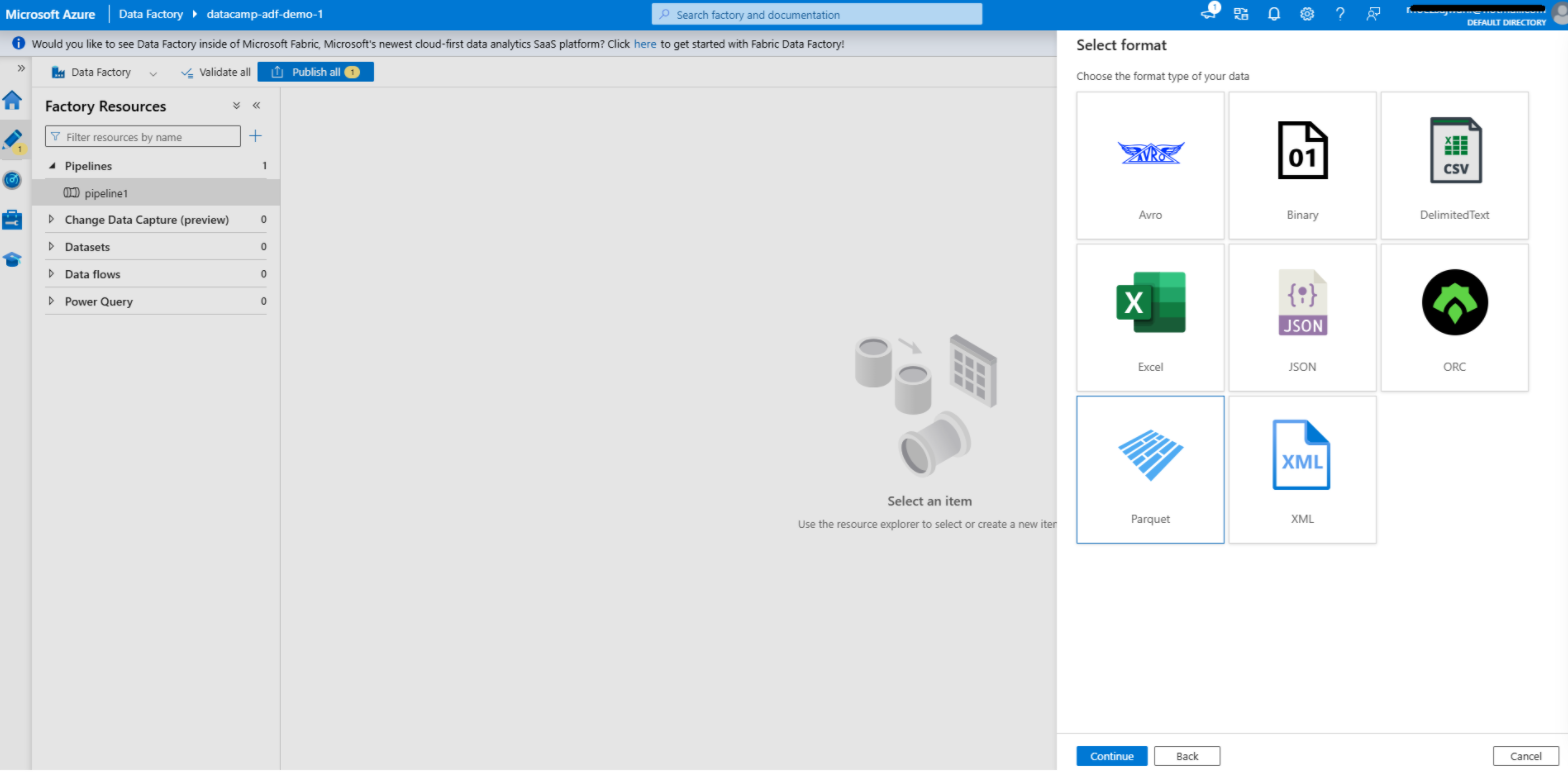
Creazione di un dataset in Azure Data Factory
1. Vai alla scheda Author
2. Aggiungi un dataset per la sorgente
3. Aggiungi un dataset per la destinazione
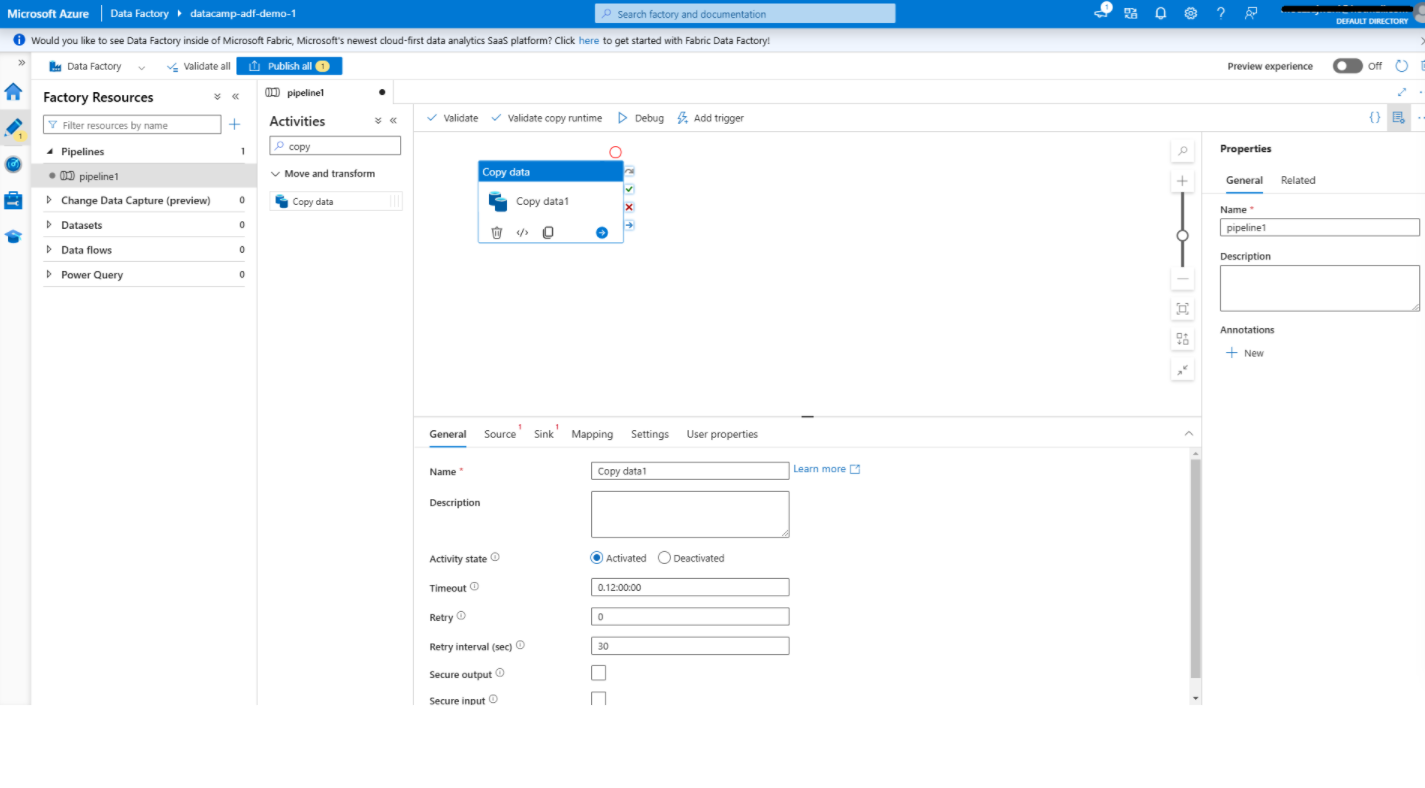
Aggiunta di un'attività copy data in Azure Data Factory
1. Apri l'editor delle Pipeline
2. Aggiungi l'attività copy data
3. Configura l'attività copy data
Pubblicazione delle pipeline in Azure Data Factory
1. Pubblica la tua pipeline
2. Esegui la pipeline
Azure Data Factory offre potenti funzionalità di integrazione e trasformazione dei dati che semplificano workflow complessi e migliorano la produttività. In questa sezione, esamineremo queste funzionalità.
I data flow forniscono un ambiente visivo per definire la logica di trasformazione, rendendo più semplice per gli utenti manipolare ed elaborare i dati senza dover scrivere codice complesso. Le attività comuni eseguite con i data flow includono:
I data flow supportano anche operazioni avanzate come derivazioni di colonne, conversioni di tipi di dati e trasformazioni condizionali, rendendoli strumenti versatili per gestire esigenze di dati eterogenee.
ADF si integra perfettamente con Azure Synapse Analytics, offrendo una piattaforma unificata per l'elaborazione di big data e l'analisi avanzata. Questa integrazione consente di:
Questa sinergia tra ADF e Synapse aiuta a semplificare i workflow e riduce la complessità di gestire strumenti separati per integrazione e analisi dei dati.
Dopo un'analisi approfondita delle funzionalità e dei componenti di ADF, vediamo per cosa possiamo usarlo.
ADF è uno strumento potente per migrare i dati da sistemi on-premise a piattaforme cloud. Semplifica migrazioni complesse automatizzando lo spostamento dei dati, garantendo l'integrità e riducendo al minimo i tempi di inattività.
Ad esempio, puoi usare ADF per migrare i dati da un SQL Server on-premise a un Azure SQL Database con un intervento manuale minimo. Sfruttando i connettori integrati e gli integration runtime, ADF assicura un processo di migrazione sicuro ed efficiente, supportando sia dati strutturati che non strutturati.
Estrarre, trasformare e caricare (ETL) sono processi alla base del moderno data warehousing. Azure Data Factory semplifica questi workflow integrando dati da più sorgenti, applicando logiche di trasformazione e caricandoli in un data warehouse.
Ad esempio, ADF può consolidare i dati di vendita di diverse regioni, trasformarli in un formato unificato e caricarli in Azure Synapse Analytics. Questo processo snello ti consente di mantenere dati aggiornati e di alta qualità per reportistica e decisioni.
|
Dai un'occhiata a 23 migliori strumenti ETL nel 2024 e ai motivi per sceglierli. |
I data lake fungono da repository centrale per dataset eterogenei, abilitando analisi avanzate e machine learning. ADF facilita l'ingestione di dati da varie sorgenti in Azure Data Lake Storage, supportando scenari batch e streaming.
Ad esempio, puoi usare ADF per raccogliere file di log, feed social e dati da sensori IoT in un unico data lake. Grazie agli strumenti di trasformazione e integrazione, ADF assicura che il data lake sia ben organizzato e pronto per analisi e carichi di lavoro di AI a valle.
Infine, vale la pena rivedere alcune best practice per usare ADF in modo efficace.
Per creare workflow manutenibili e scalabili, progetta pipeline con componenti riutilizzabili. Il design modulare consente debug, test e aggiornamenti più semplici delle singole sezioni di pipeline. Ad esempio, invece di inserire la logica di trasformazione in ogni pipeline, crea una pipeline riutilizzabile che possa essere richiamata in più workflow. Questo riduce la ridondanza e migliora la coerenza tra i progetti.
Quindi, in cosa Azure Data Factory è differente da Databricks? Se sei curioso e vuoi scoprire le differenze tra Azure Data Factory e Databricks, dai un'occhiata al blog Azure Data Factory vs Databricks: un confronto dettagliato.
Man mano che padroneggi Azure Data Factory, è fondamentale capirne l'evoluzione: Microsoft Fabric.
Sebbene Azure Data Factory (ADF) rimanga una soluzione PaaS (Platform-as-a-Service) robusta e autonoma ampiamente utilizzata in ambito enterprise, Microsoft ha introdotto Fabric come il futuro del suo ecosistema dati. Fabric è una piattaforma SaaS all-in-one che unifica Data Factory, Synapse Analytics e Power BI in un unico ambiente.
Dovresti usare ADF o Fabric?
Nota: le pipeline di ADF e le pipeline di Fabric Data Factory sono molto simili, quindi le competenze che acquisisci in ADF oggi sono direttamente trasferibili a Fabric. Puoi seguire il nostro corso Introduction to Microsoft Fabric per saperne di più.
Azure Data Factory semplifica il processo di creazione, gestione e scalabilità delle pipeline di dati nel cloud. Fornisce una piattaforma intuitiva adatta sia agli utenti tecnici che non tecnici, permettendo di integrare e trasformare dati da varie sorgenti in modo efficiente.
Sfruttando le sue funzionalità, come l'authoring delle pipeline senza codice, le capacità di integrazione e gli strumenti di monitoraggio, puoi creare workflow scalabili e affidabili con facilità.
Per saperne di più su Azure Data Factory, ti consiglio di consultare le Top 27 domande e risposte per colloqui su Azure Data Factory.
Se vuoi esplorare l'ossatura di Azure, inclusi argomenti come container, macchine virtuali e altro, il mio consiglio è questo fantastico corso gratuito su Understanding Microsoft Azure Architecture and Services.
Scopri di più su Microsoft Azure con questi corsi!
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min

