
Cours
Comprendre Microsoft Azure
3 h
47.1K
Azure Data Factory (ADF) est le service d'intégration de données basé sur le cloud de Microsoft, adapté aux organisations modernes. Il permet aux utilisateurs de concevoir, de gérer et d'automatiser les flux de travail qui traitent les tâches de déplacement et de transformation des données à l'échelle de l'entreprise.
ADF se distingue par son interface conviviale, sans code, qui permet aux utilisateurs techniques et non techniques de créer facilement des pipelines de données. Ses capacités d'intégration étendues prennent en charge plus de 90 connecteurs natifs, permettant la circulation des données entre diverses sources, y compris les systèmes sur site et les services basés sur le cloud.
Dans ce guide, j'offre une introduction complète à Azure Data Factory, couvrant ses composants et ses fonctionnalités et fournissant un tutoriel pratique pour vous aider à créer votre premier pipeline de données.
Azure Data Factory (ADF) est un service d'intégration de données basé sur le cloud, conçu pour orchestrer et automatiser les flux de données.
Il est utilisé pour collecter, transformer et fournir des données, en veillant à ce que les informations soient facilement accessibles pour l'analyse et la prise de décision.
Grâce à son architecture évolutive et sans serveur, ADF peut gérer des flux de travail de toute taille, qu'il s'agisse de simples migrations de données ou de pipelines de transformation de données complexes.
ADF comble le fossé entre les silos de données, permettant aux utilisateurs de déplacer et de transformer les données entre les systèmes sur site, les services cloud et les plateformes externes. Que vous travailliez avec des big data, des bases de données opérationnelles ou des API, Azure Data Factory fournit les outils nécessaires pour connecter, traiter et unifier les données de manière efficace.
Voici quelques-unes des principales caractéristiques de l'ADF.
Azure Data Factory prend en charge l'intégration avec plus de 90 sources de données, y compris des systèmes basés sur le cloud et sur site. Il inclut la prise en charge des bases de données SQL, des systèmes NoSQL, des API REST et des sources de données basées sur des fichiers, ce qui vous permet d'unifier les flux de travail des données, quelle que soit la source ou le format.

Connecteurs de données disponibles dans Azure Data Factory
L'interface "glisser-déposer" d'ADF simplifie la création de pipelines de données par les utilisateurs. Grâce à des modèles prédéfinis, à des assistants de configuration guidés et à un éditeur visuel intuitif, même les utilisateurs n'ayant aucune compétence en matière de codage peuvent concevoir des flux de travail complets de bout en bout.
Expérience de création sans code dans Azure Data Factory
Les outils de planification d'Azure Data Factory permettent d'automatiser les flux de travail. Les utilisateurs peuvent mettre en place des déclencheurs basés sur des conditions spécifiques, telles que l'arrivée d'un fichier dans le stockage cloud ou des intervalles de temps programmés. Ces options de planification éliminent le besoin d'interventions manuelles et garantissent une exécution cohérente et fiable des flux de travail.
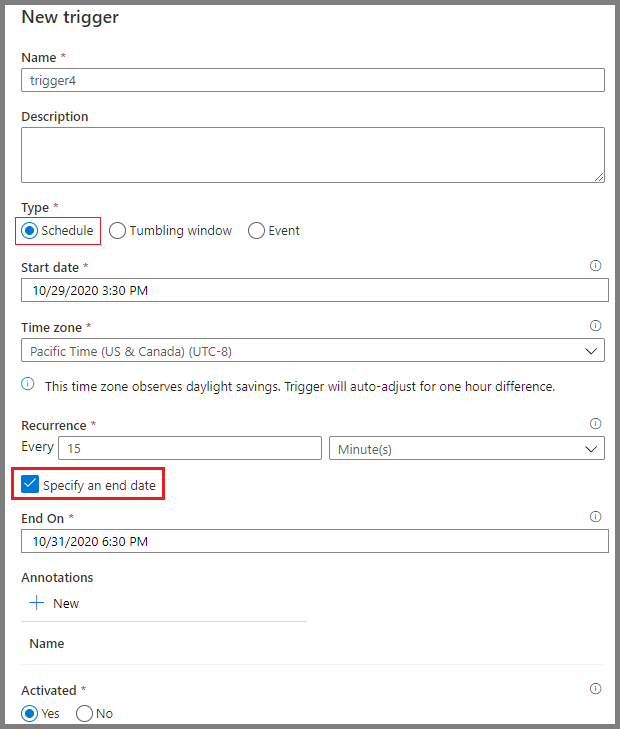
Programmation de pipelines dans Azure Data Factory
Il est essentiel de comprendre les composants de base d'Azure Data Factory pour créer des flux de travail efficaces.
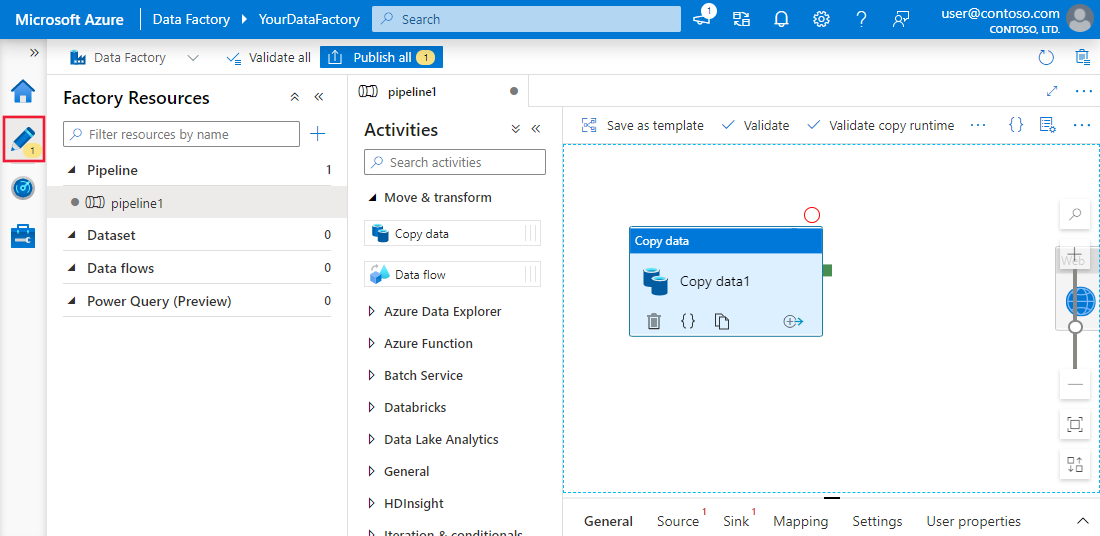
Les pipelines constituent l'épine dorsale d'Azure Data Factory. Ils représentent des flux de travail axés sur les données qui définissent les étapes nécessaires pour déplacer et transformer les données.
Chaque pipeline sert de conteneur pour une ou plusieurs activités, exécutées séquentiellement ou en parallèle, afin d'obtenir le flux de données souhaité.
Ces pipelines permettent aux ingénieurs de données de créer des processus de bout en bout, tels que l'ingestion de données brutes, leur transformation dans un format utilisable et leur chargement dans des systèmes cibles.
Exemple de pipeline simple dans Azure Data Factory
Les activités sont les éléments fonctionnels des pipelines, chacune effectuant une opération spécifique. Ils se répartissent en plusieurs catégories :
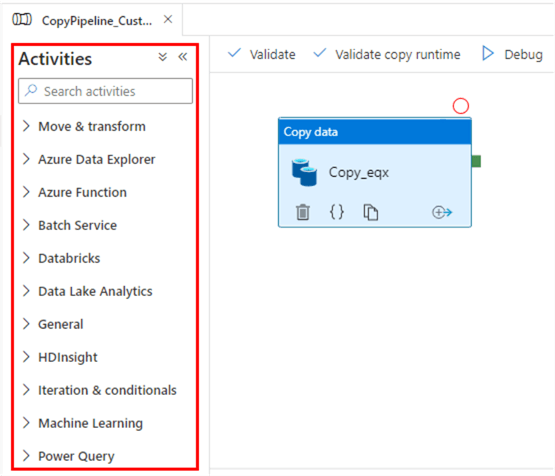
Activités dans Azure Data Factory
Les ensembles de données sont des représentations des données utilisées dans les activités. Ils définissent le schéma, le format et l'emplacement des données ingérées ou traitées.
Par exemple, un ensemble de données peut décrire un fichier CSV dans Azure Blob Storage ou un tableau dans une base de données Azure SQL. Les ensembles de données sont la couche intermédiaire qui relie les activités aux sources de données réelles et aux destinations.
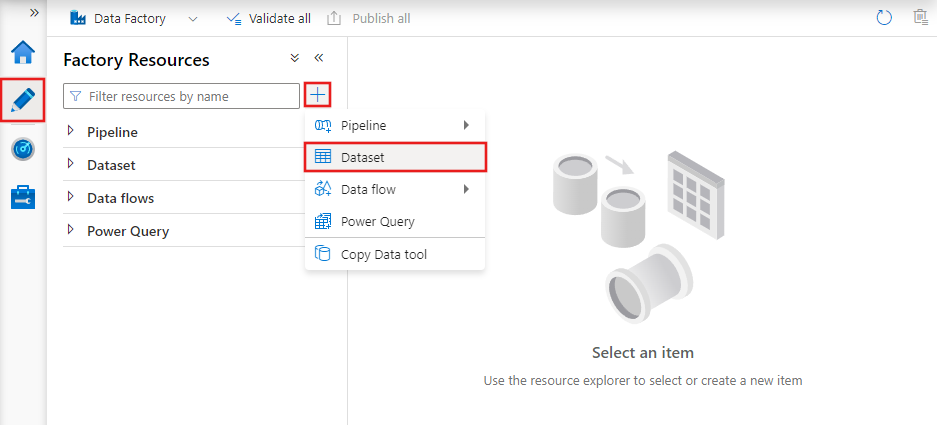
Ensembles de données dans Azure Data Factory
Les services liés sont des chaînes de connexion qui permettent aux activités et aux ensembles de données d'accéder à des systèmes et services externes.
Ils servent de passerelles entre Azure Data Factory et les ressources externes avec lesquelles il interagit, telles que les bases de données, les comptes de stockage ou les environnements informatiques.
Par exemple, un service lié peut se connecter à un serveur SQL sur site ou à un lac de données basé dans le cloud.
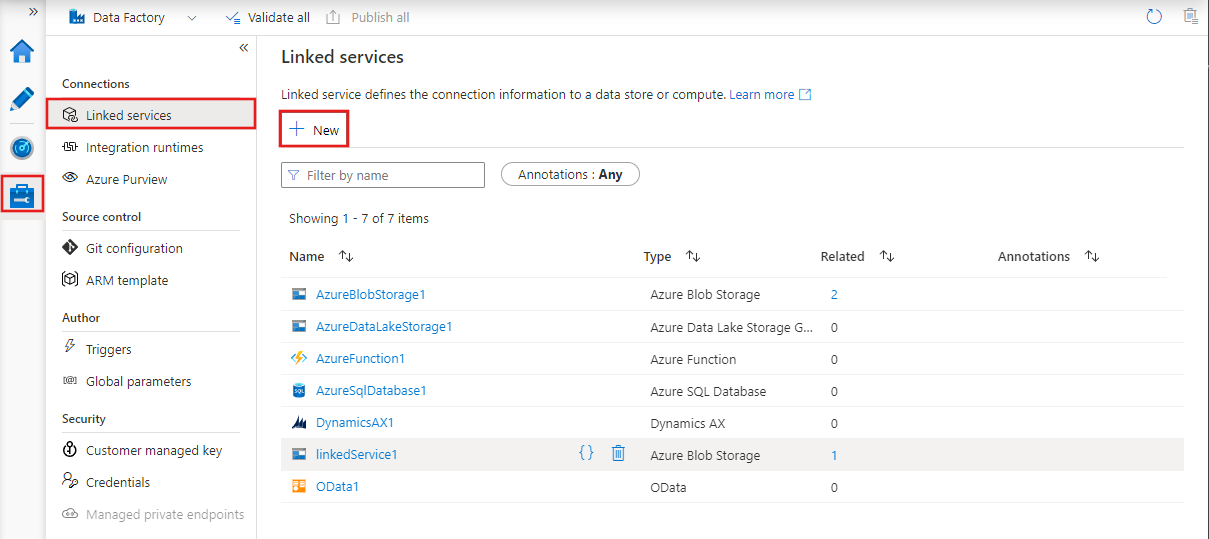
Services liés dans Azure Data Factory
Les runtimes d'intégration (IR) sont les environnements de calcul qui alimentent le mouvement des données, la transformation et l'exécution des activités au sein d'Azure Data Factory. ADF propose trois types d'exécution d'intégration :
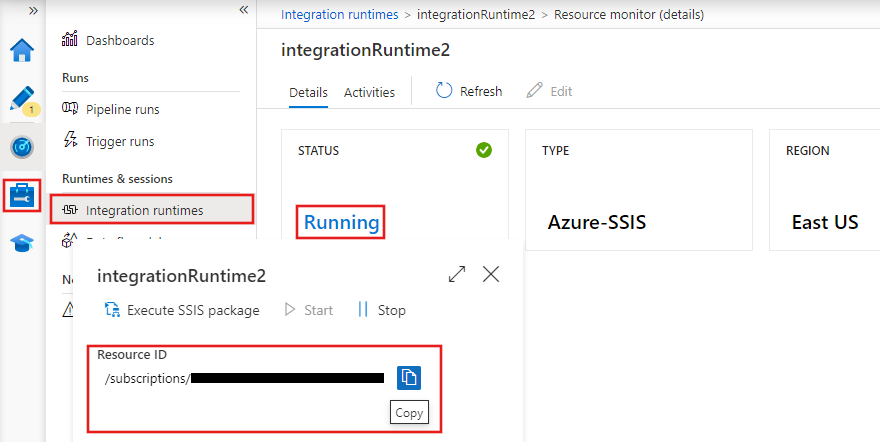
Exécutions d'intégration dans Azure Data Factory
Passons maintenant à la partie pratique de ce guide !
1. Un abonnement actif àe Azure.
2. Un groupe de ressources pour gérer lesressources Azure.
1. Connectez-vous à sur le portail Azure.
2. Allez sur Créer une ressource et sélectionnez Data Factory.
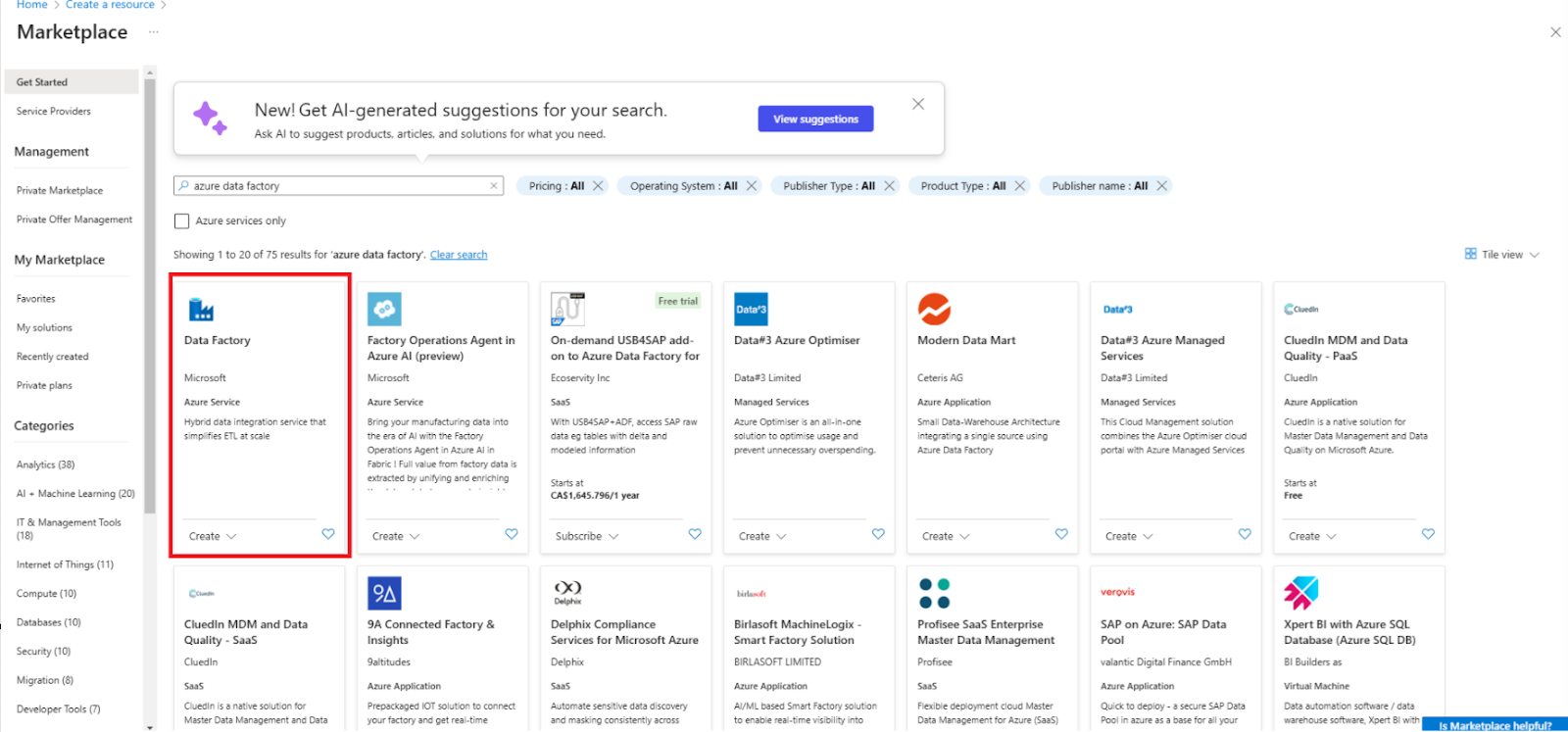
Créez une nouvelle ressource Data Factory
3. Remplissez les champs obligatoires, y compris l'abonnement, le groupe de ressources et la région.
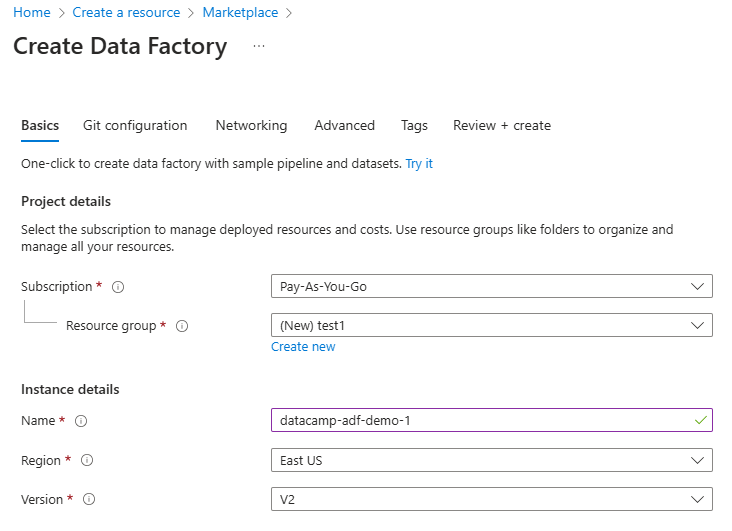
Configurer la ressource Data Factory
4. Examinez et créez l'instance.
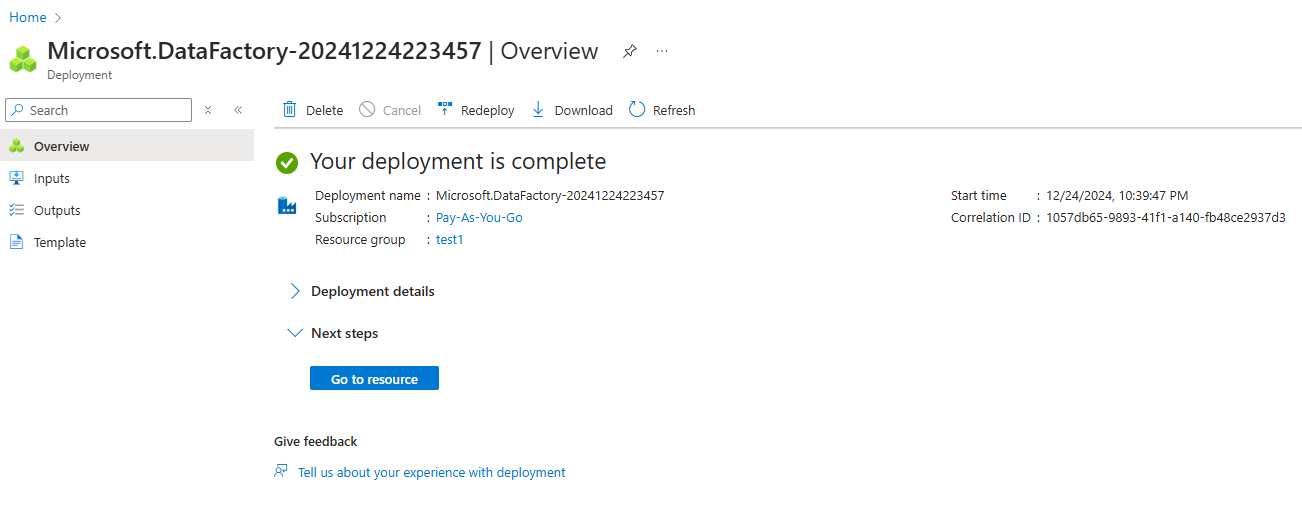
Création d'une instance Azure Data Factory
L'interface de l'ADF se compose des sections principales suivantes (accessibles par le menu de navigation de gauche)
1. Auteur : Pour créer et gérer des pipelines.
2. Moniteur : Assurer le cursus du pipeline et résoudre les problèmes.
3. Gérer : Pour configurer les services liés et les runtimes d'intégration.
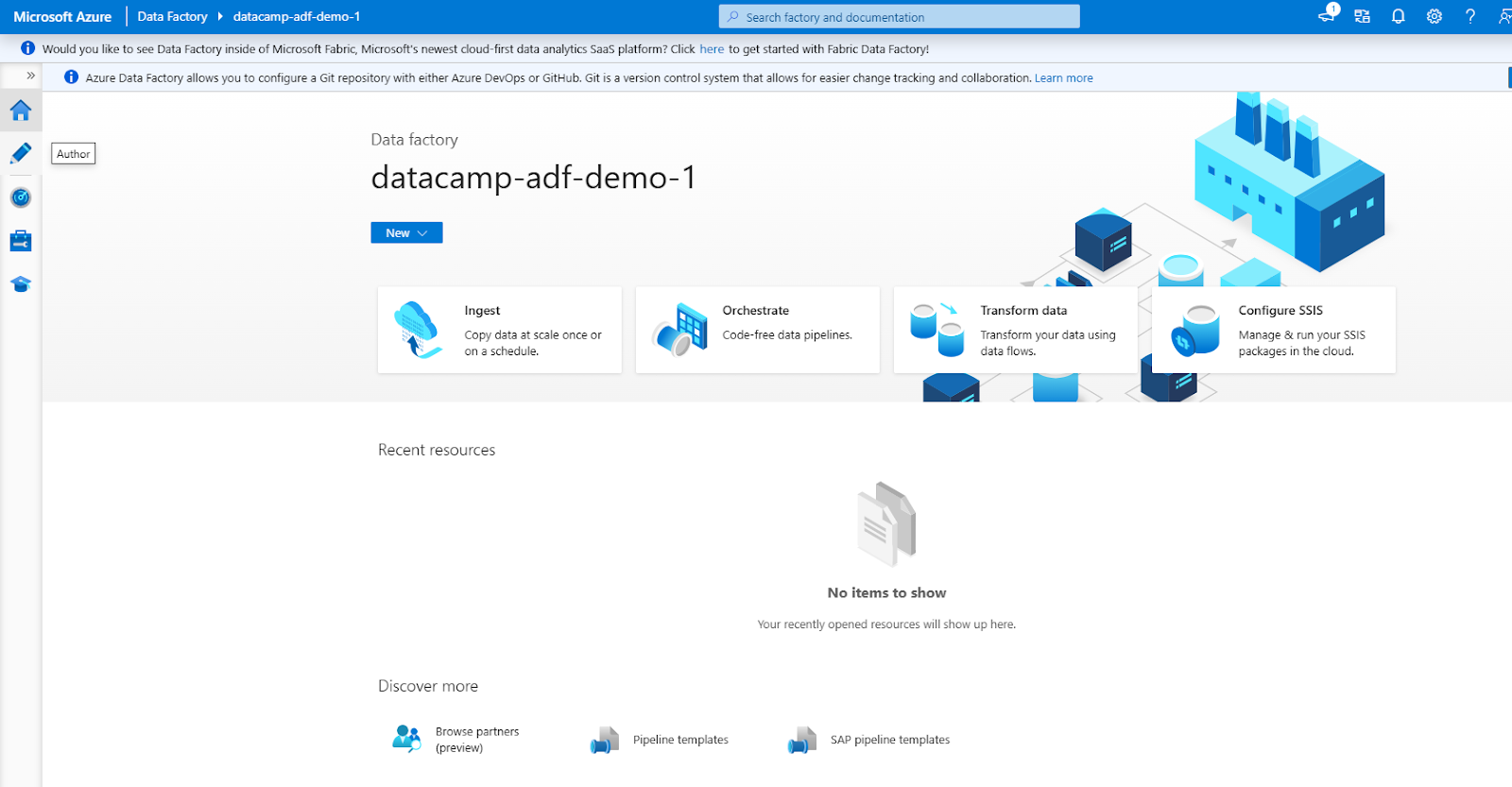
Interface Azure Data Factory
Voyons les étapes de la création d'un pipeline de données simple.
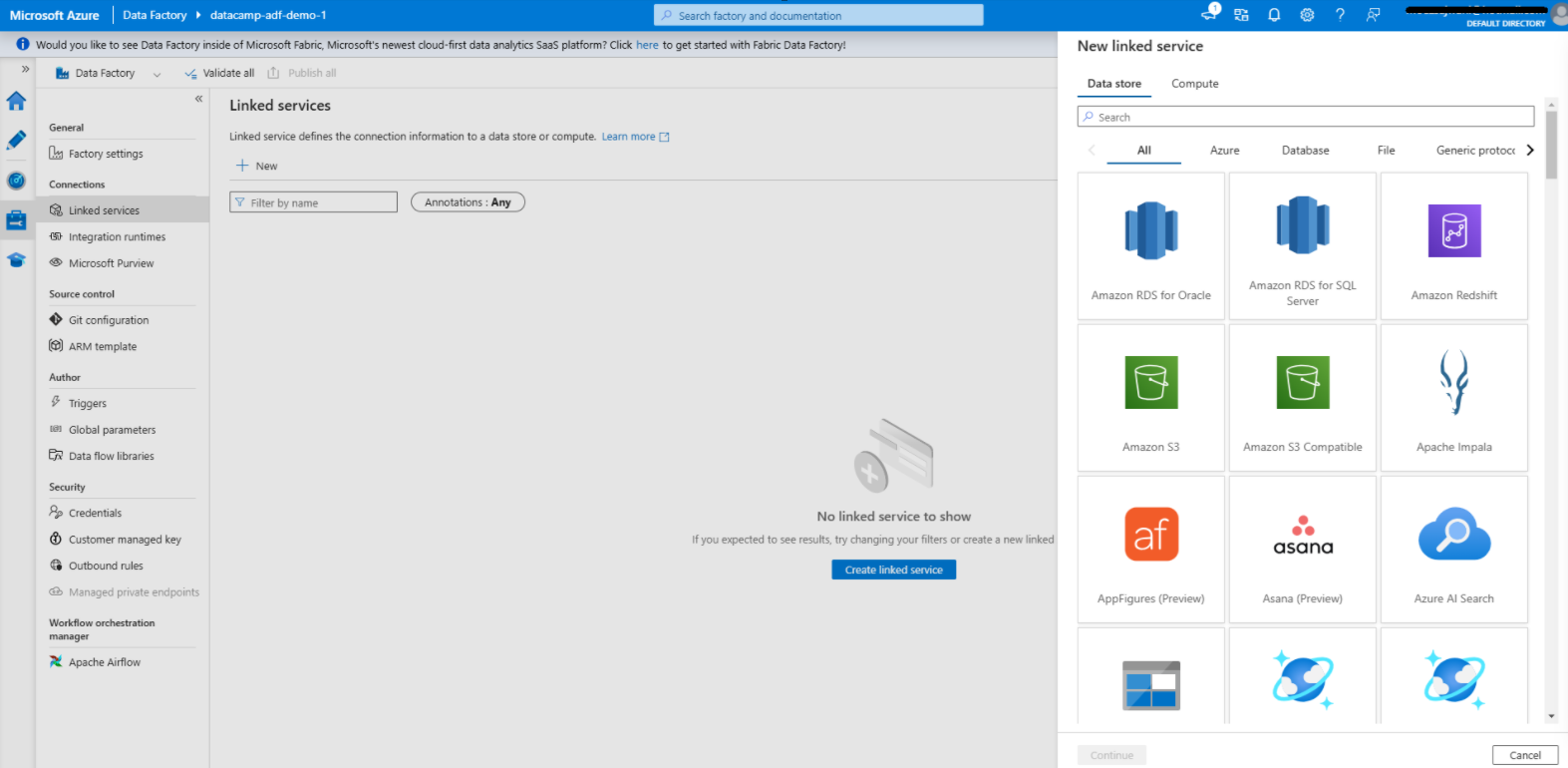
Création d'un service lié dans Azure Data Factory
1. Naviguez vers l'onglet Gérer
2. Ajouter un service lié pour la source de données
3. Ajouter un service lié pour la destination des données
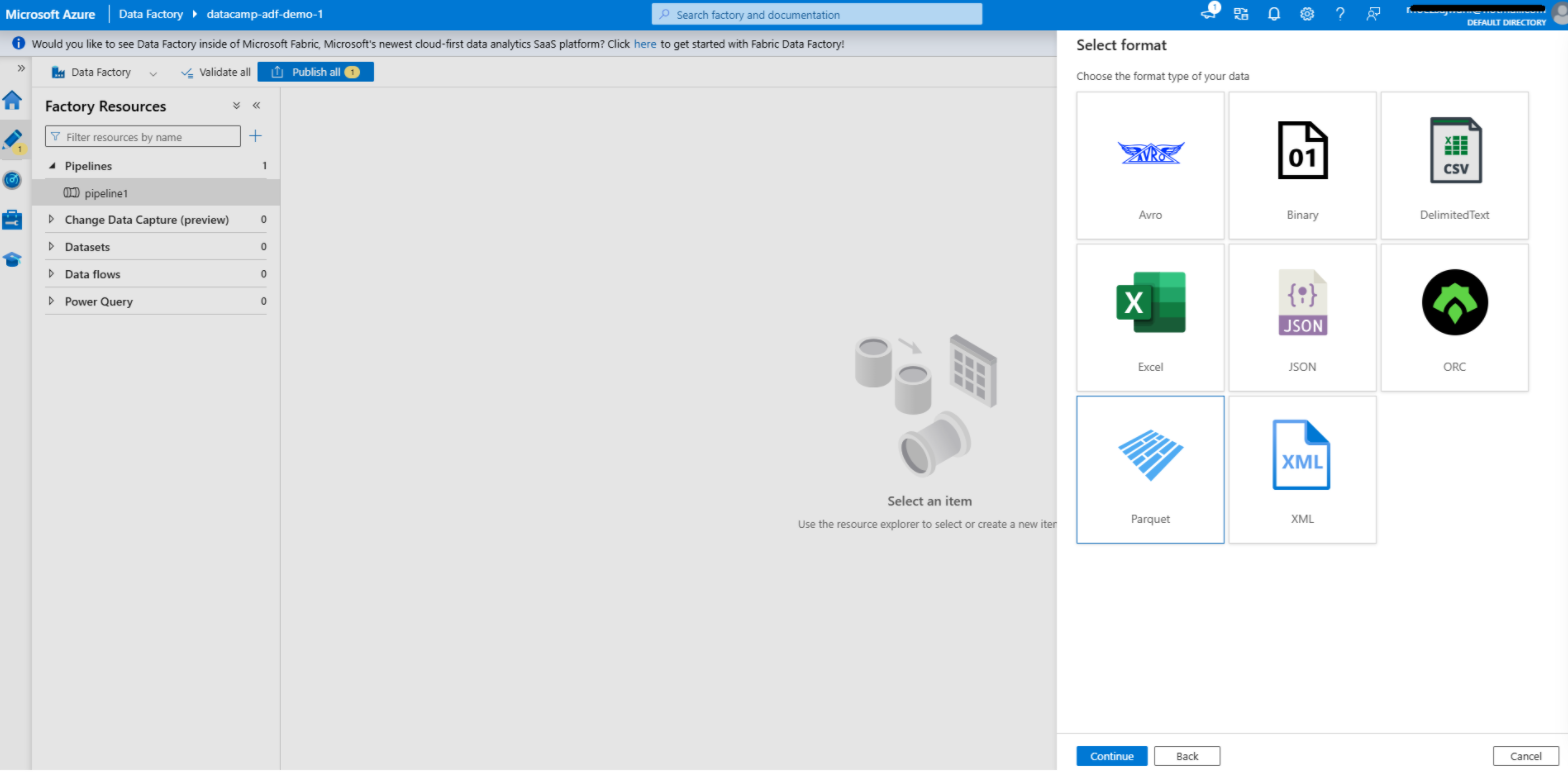
Création d'un jeu de données dans Azure Data Factory
1. Accédez à l'onglet Auteur
2. Ajouter un jeu de données pour la source
3. Ajouter un jeu de données pour la destination
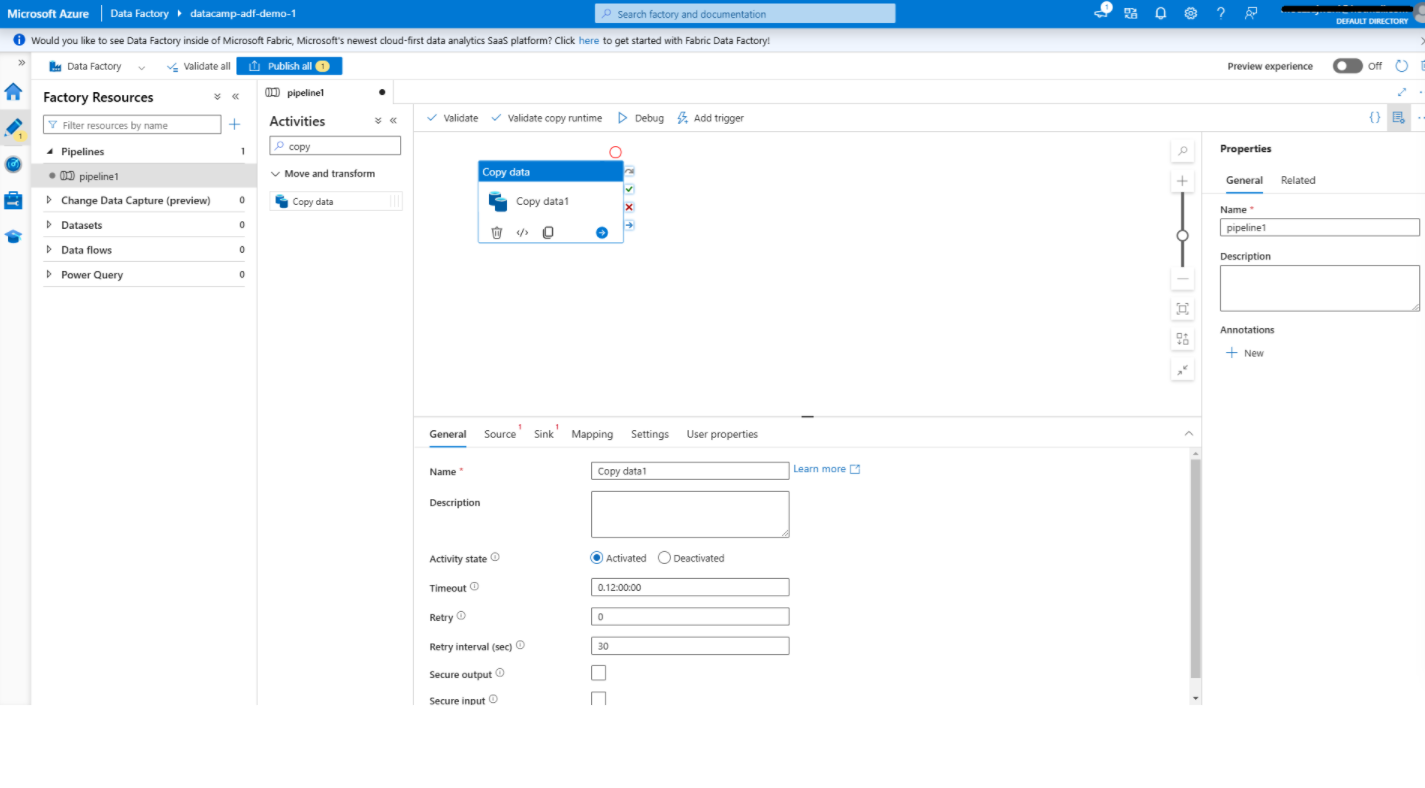
Ajouter une activité de copie de données dans Azure Data Factory
1. Ouvrez l'éditeur de pipeline
2. Ajoutez l'activité de copie de données
3. Configurer l'activité de copie des données
Publier des pipelines dans Azure Data Factory
1. Publier votre pipeline
2. Exécuter le pipeline
Azure Data Factory offre de puissantes fonctionnalités d'intégration et de transformation des données qui simplifient les flux de travail complexes et améliorent la productivité. Dans cette section, nous allons passer en revue ces caractéristiques.
Data flows provide un environnement visuel pour définir la logique de transformation, ce qui facilite la manipulation et le traitement des données par les utilisateurs sans qu'ils aient à écrire un code complexe. Les tâches courantes effectuées avec les flux de données sont les suivantes
Les flux de données prennent également en charge des opérations avancées telles que les dérivations de colonnes, les conversions de types de données et les transformations conditionnelles, ce qui en fait des outils polyvalents permettant de répondre à diverses exigences en matière de données.
ADF s'intègre de manière transparente à Azure Synapse Analytics, ce qui permet de créer une plateforme unifiée pour le traitement des données volumineuses et l'analyse avancée (). Cette intégration permet aux utilisateurs de :
Cette synergie entre ADF et Synapse permet de rationaliser les flux de travail et de réduire la complexité de la gestion d'outils distincts pour l'intégration et l'analyse des données.
Après un examen approfondi des caractéristiques et des composants de l'ADF, voyons à quoi il peut servir.
L'ADF est un outil puissant pour la migration des données des systèmes sur site vers des plateformes basées sur le cloud. Il simplifie les migrations complexes en automatisant le déplacement des données, en garantissant l'intégrité des données et en minimisant les temps d'arrêt.
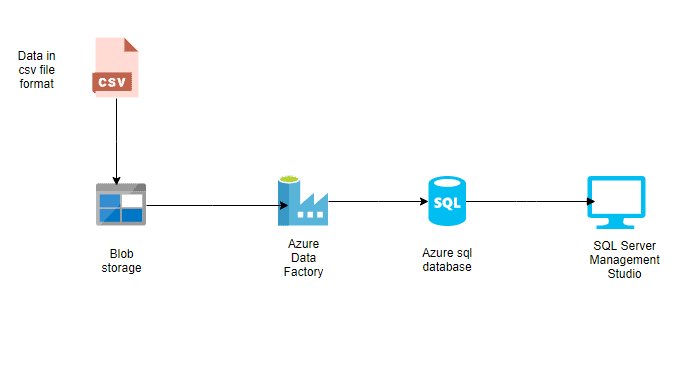
Par exemple, vous pouvez utiliser ADF pour migrer des données d'un serveur SQL sur sitevers une base de données SQL Azure avecune intervention manuelle minimale. En s'appuyant sur des connecteurs intégrés et des runtimes d'intégration, ADF garantit un processus de migration sécurisé et efficace, prenant en charge les données structurées et non structurées.
Les processus d'extraction, de transformation et de chargement (ETL) sont au cœur des entrepôts de données modernes. Azure Data Factory rationalise ces flux de travail en intégrant des données provenant de sources multiples, en appliquant une logique de transformation et en les chargeant dans un entrepôt de données.
Par exemple, ADF peut consolider les données de vente de différentes régions, les transformer dans un format unifié et les charger dans Azure Synapse Analytics. Ce processus rationalisé vous permet de conserver des données actualisées et de haute qualité pour l'établissement de rapports et la prise de décision.
|
Découvrez les 23 meilleurs outils ETL en 2024 et pourquoi les choisir. |
Les lacs de données servent de référentiel central pour divers ensembles de données, permettant des analyses avancées et l'apprentissage automatique. ADF facilite l'ingestion de données provenant de diverses sources dans Azure Data Lake Storage, en prenant en charge les scénarios de traitement par lots et en continu.
Par exemple, vous pouvez utiliser ADF pour collecter des fichiers journaux, des flux de médias sociaux et des données de capteurs IoT dans un lac de données unique. En fournissant des outils de transformation et d'intégration des données, ADF s'assure que le lac de données est bien organisé et prêt pour les charges de travail d'analyse et d'IA en aval.
Enfin, il convient de passer en revue les meilleures pratiques pour utiliser efficacement l'ADF.
Pour créer des flux de travail maintenables et évolutifs, concevez des pipelines avec des composants réutilisables. La conception modulaire facilite le débogage, les essais et la mise à jour des différentes sections de la canalisation. Par exemple, au lieu d'intégrer une logique de transformation des données dans chaque pipeline, créez un pipeline réutilisable qui peut être invoqué dans plusieurs flux de travail. Cela permet de réduire les redondances et d'améliorer la cohérence entre les projets.
En quoi Azure Data Factory est-il différentde Databricks ? Si vous êtes curieux et souhaitez découvrir les différences entre Azure Data Factory et Databricks, consultez Azure Data Factory vs Databricks : Une comparaison détaillée blog.
Azure Data Factory simplifie le processus de création, de gestion et de mise à l'échelle des pipelines de données dans le cloud. Il s'agit d'une plateforme intuitive qui s'adresse à la fois aux utilisateurs techniques et non techniques, leur permettant d'intégrer et de transformer efficacement des données provenant de différentes sources.
En tirant parti de ses fonctionnalités, telles que la création de pipelines sans code, les capacités d'intégration et les outils de surveillance, les utilisateurs peuvent facilement créer des flux de travail évolutifs et fiables.
Pour en savoir plus sur Azure Data Factory, je vous recommande de consulter le Top 27 Azure Data Factory Interview Questions and Answers.
Si vous souhaitez explorer l'épine dorsale d'Azure, y compris des sujets tels que les conteneurs, les machines virtuelles, et plus encore, je vous recommande ce cours gratuit extraordinaire sur la compréhension de l'architecture et des services Microsoft Azure.
Apprenez-en plus sur Microsoft Azure avec ces cours !
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
blog
Zoumana Keita
15 min
Tutoriel
Tutoriel
Matt Crabtree
Tutoriel
Sejal Jaiswal
Tutoriel
Moez Ali
