
Course
Understanding Microsoft Azure
3 hr
47.1K
Azure Data Factory (ADF) is Microsoft’s cloud-based data integration service tailored for modern organizations. It empowers users to design, manage, and automate workflows that handle data movement and transformation tasks at an enterprise scale.
ADF stands out for its user-friendly, no-code interface, which allows both technical and non-technical users to build data pipelines easily. Its extensive integration capabilities support over 90 native connectors, enabling data flow across diverse sources, including on-premises systems and cloud-based services.
In this guide, I offer a comprehensive introduction to Azure Data Factory, covering its components and features and providing a hands-on tutorial to help you create your first data pipeline.
Azure Data Factory (ADF) is a cloud-based data integration service designed to orchestrate and automate data workflows.
It is used to collect, transform, and deliver data, ensuring that insights are readily accessible for analytics and decision-making.
With its scalable and serverless architecture, ADF can handle workflows of any size—from simple data migrations to complex data transformation pipelines.
ADF bridges the gap between data silos, enabling users to move and transform data between on-premises systems, cloud services, and external platforms. Whether you’re working with big data, operational databases, or APIs, Azure Data Factory provides the tools to connect, process, and unify data efficiently.
Here are some of the most important features that ADF offers.
Azure Data Factory supports integration with over 100 native connectors, including cloud-based and on-premises systems. It includes support for SQL databases, NoSQL systems, REST APIs, and file-based data sources, allowing you to unify data workflows regardless of the source or format. It is the foundational engine that also powers the data integration capabilities in Microsoft Fabric, Microsoft's unified data platform.

Data connectors available in Azure Data Factory
ADF’s drag-and-drop interface simplifies how users create data pipelines. With prebuilt templates, guided configuration wizards, and an intuitive visual editor, even users with no coding expertise can design comprehensive end-to-end workflows.
No-code authoring experience in Azure Data Factory
Azure Data Factory’s scheduling tools offer workflow automation. Users can set up triggers based on specific conditions, such as a file’s arrival in cloud storage or scheduled time intervals. These scheduling options eliminate the need for manual interventions and ensure workflows are executed consistently and reliably.
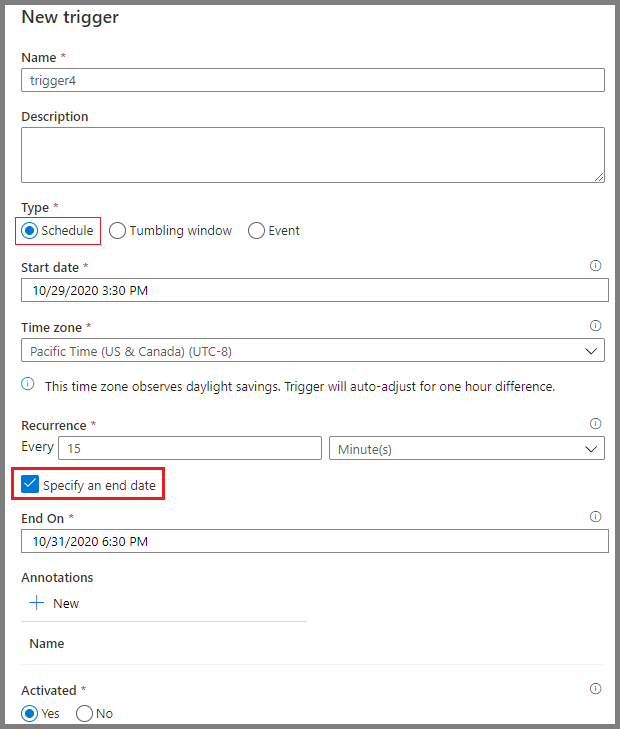
Scheduling pipelines in Azure Data Factory
Understanding the core components of Azure Data Factory is essential to building efficient workflows.
Pipelines are the backbone of Azure Data Factory. They represent data-driven workflows that define the steps required to move and transform data.
Each pipeline serves as a container for one or more activities, executed sequentially or in parallel, to achieve the desired data flow.
These pipelines enable data engineers to create end-to-end processes, such as ingesting raw data, transforming it into a usable format, and loading it into target systems.
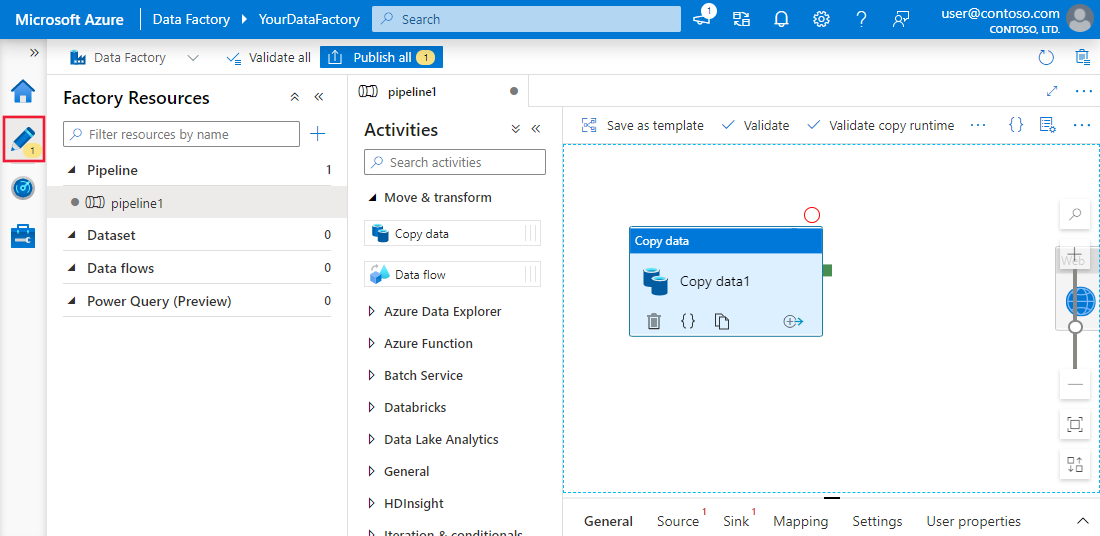
Example of simple pipeline in Azure Data Factory
Activities are the functional building blocks of pipelines, each performing a specific operation. They are broadly categorized into:
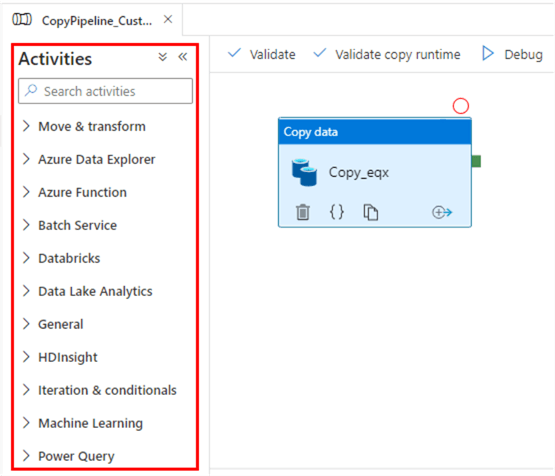
Activities in Azure Data Factory
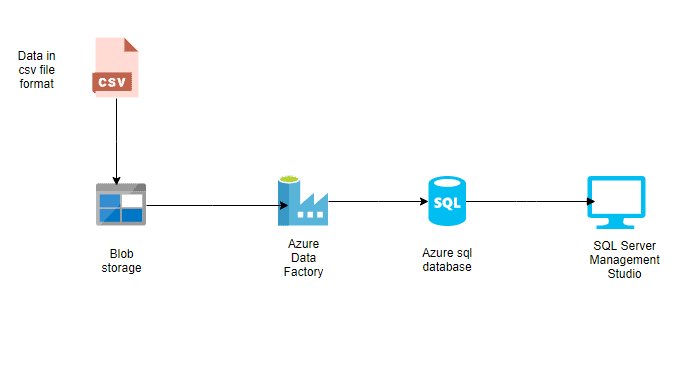
Datasets are representations of the data utilized in activities. They define the schema, format, and location of the data being ingested or processed.
For instance, a dataset might describe a CSV file in Azure Blob Storage or a table in an Azure SQL Database. Datasets are the intermediary layer connecting activities to the actual data sources and destinations.
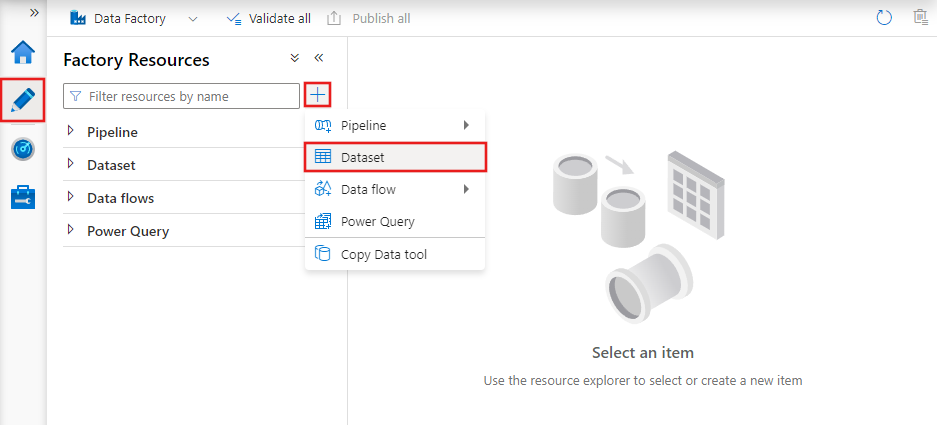
Datasets in Azure Data Factory
Linked services are connection strings that enable activities and datasets to access external systems and services.
They act as bridges between Azure Data Factory and the external resources it interacts with, such as databases, storage accounts, or compute environments.
For example, a linked service can connect to an on-premises SQL Server or a cloud-based data lake.
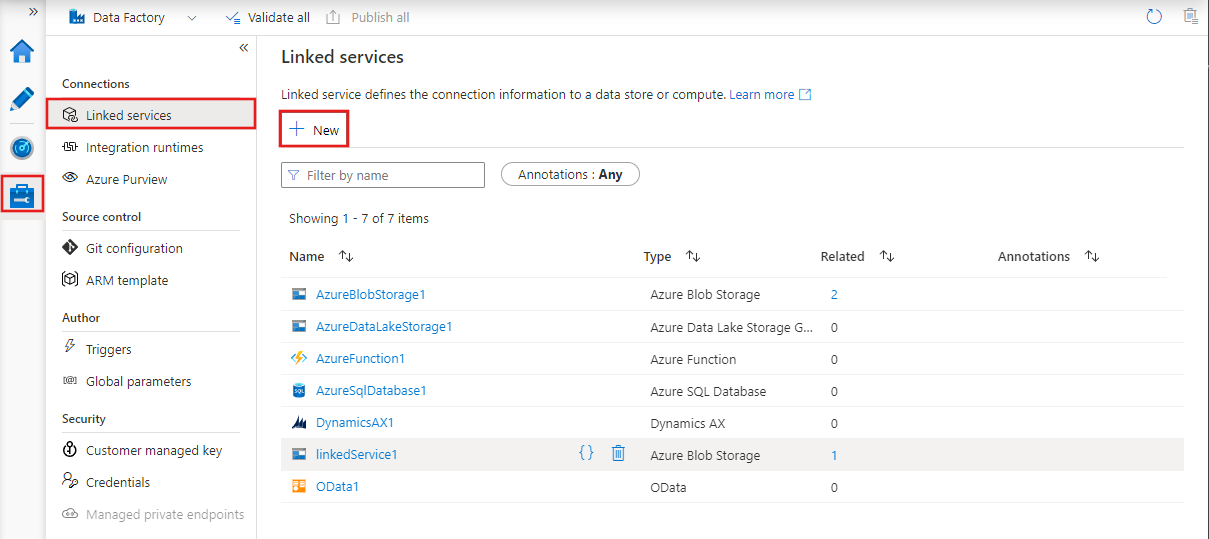
Linked services in Azure Data Factory
Integration runtimes (IRs) are the compute environments that power data movement, transformation, and activity execution within Azure Data Factory. ADF provides three types of integration runtimes:
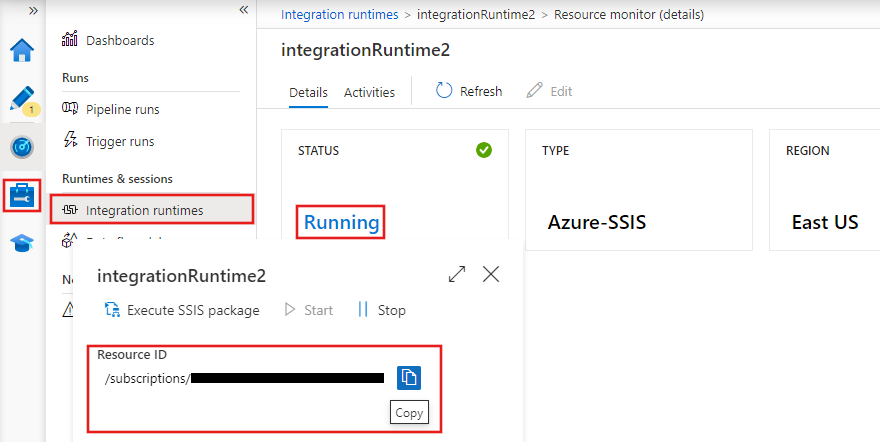
Integration runtimes in Azure Data Factory
Now, let’s move to the practical section of this guide!
1. An active Azure subscription.
2. A resource group for managing Azure resources.
1. Log in to the Azure portal.
2. Navigate to Create a resource and select Data Factory.
Create a new Data Factory resource
3. Fill out the required fields, including subscription, resource group, and region.
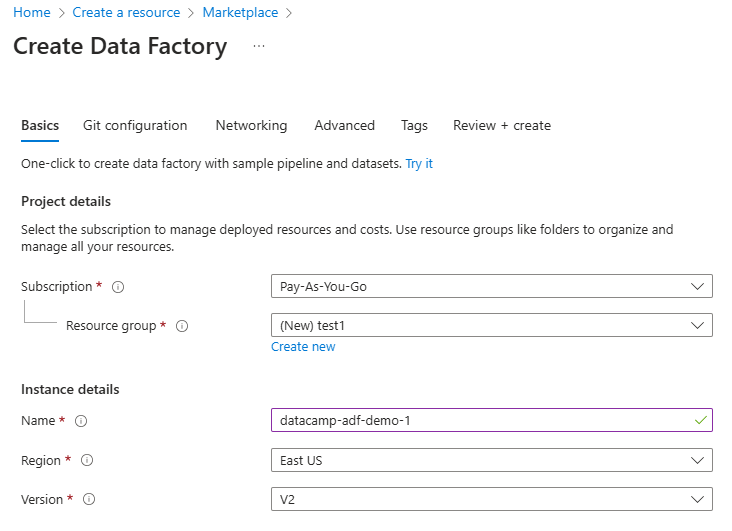
Configure Data Factory resource
4. Review and create the instance.
Azure Data Factory instance created
The ADF interface consists of the following main sections (accessible via the left-hand navigation menu)
1. Author: For creating and managing pipelines.
2. Monitor: To track pipeline runs and troubleshoot issues.
3. Manage: For configuring linked services and integration runtimes.
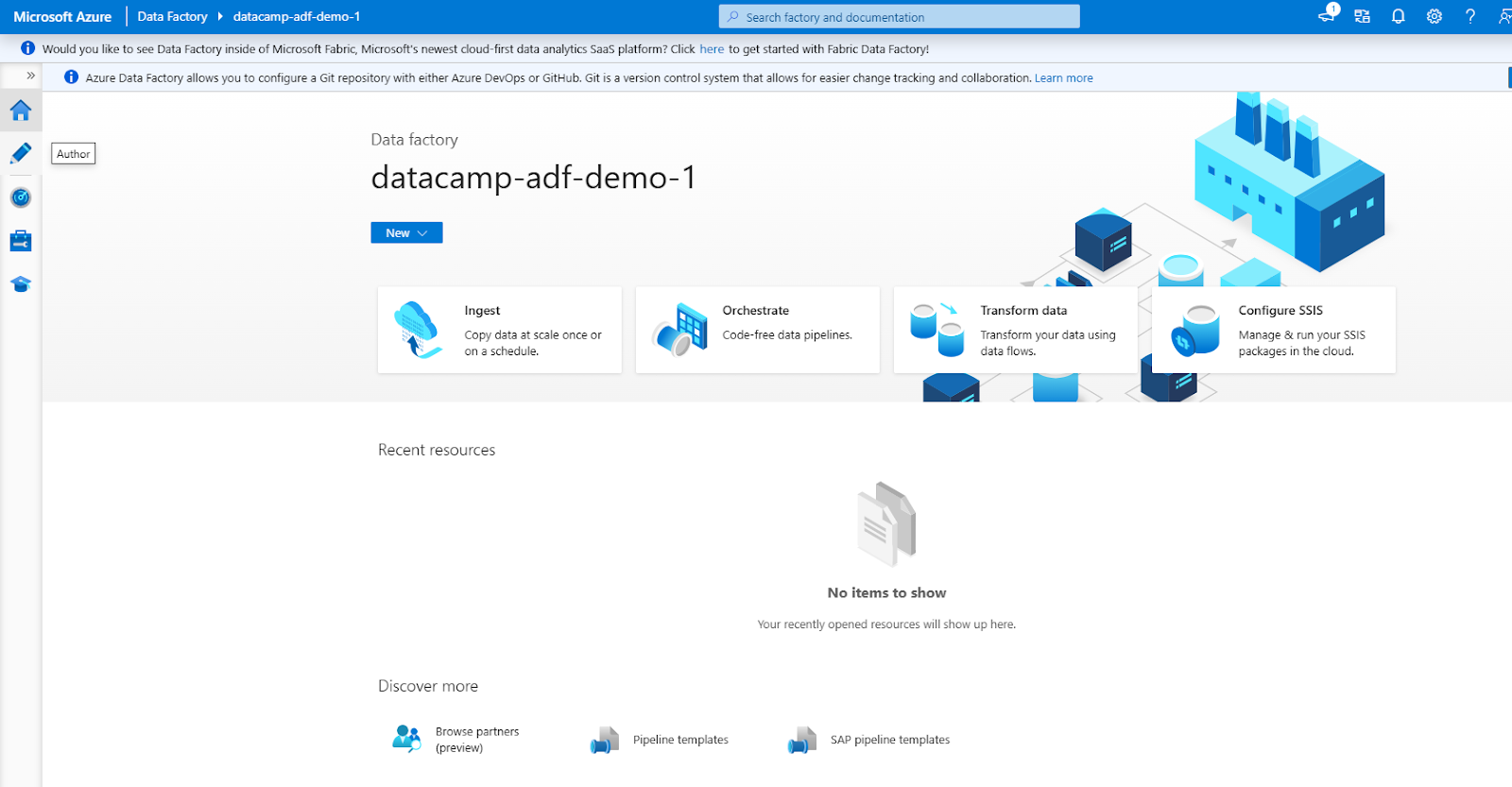
Azure Data Factory Interface
Let’s walk through the steps to create a simple data pipeline.
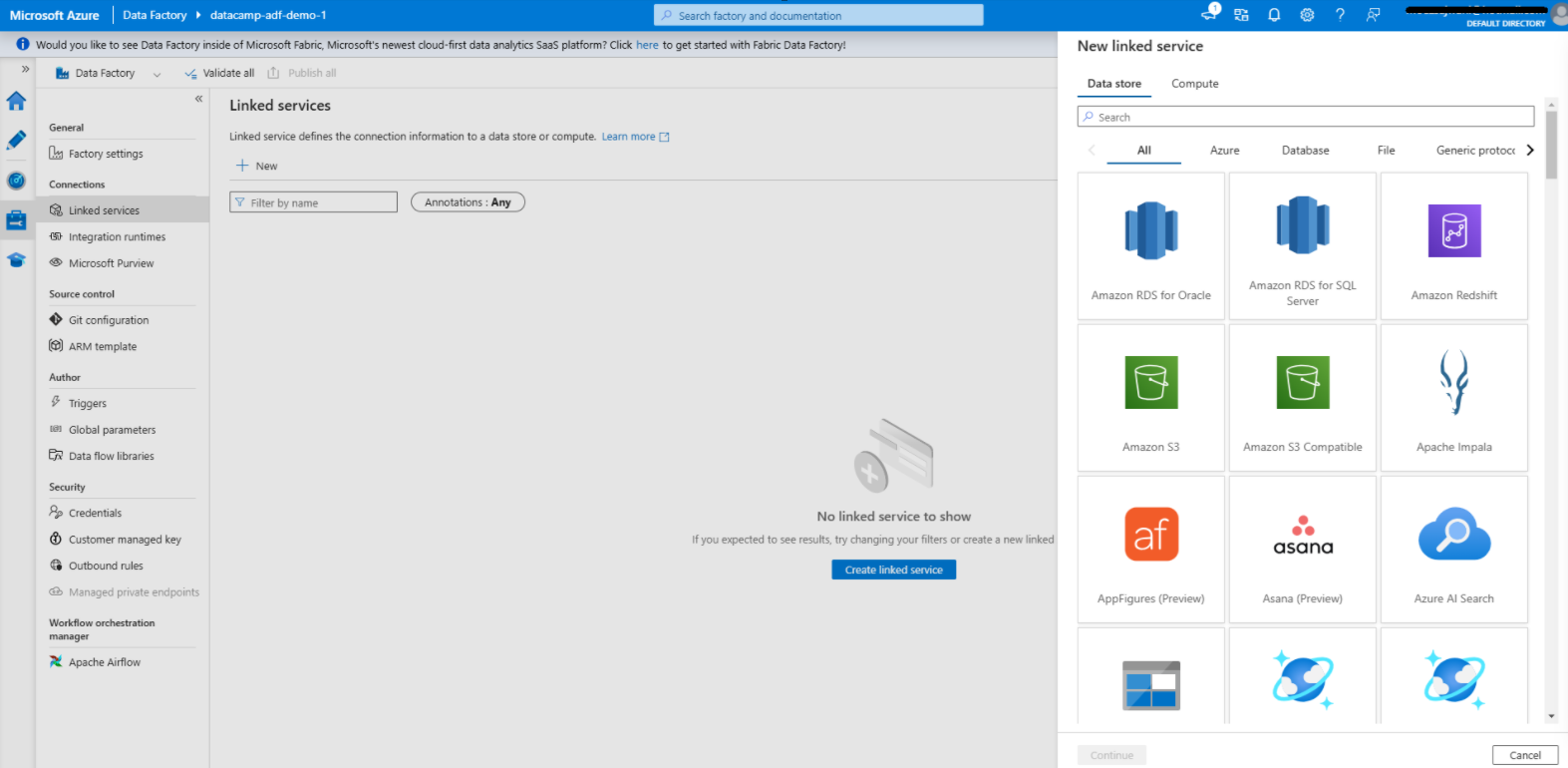
Creating Linked service in Azure Data Factory
1. Navigate to the Manage tab
2. Add a linked service for the data source
3. Add a linked service for the data destination
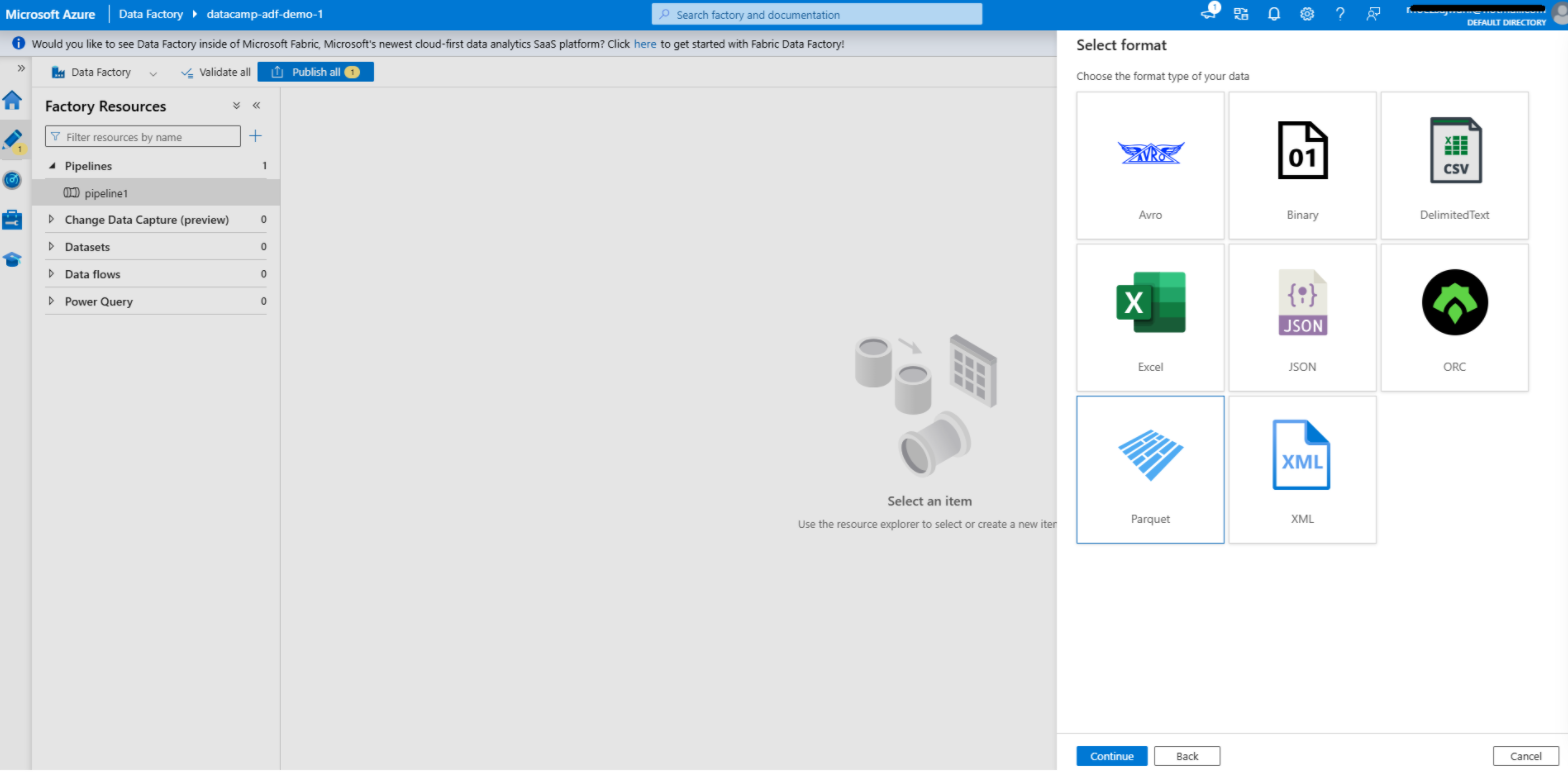
Creating dataset in Azure Data Factory
1. Navigate to the Author tab
2. Add a dataset for the source
3. Add a dataset for the destination
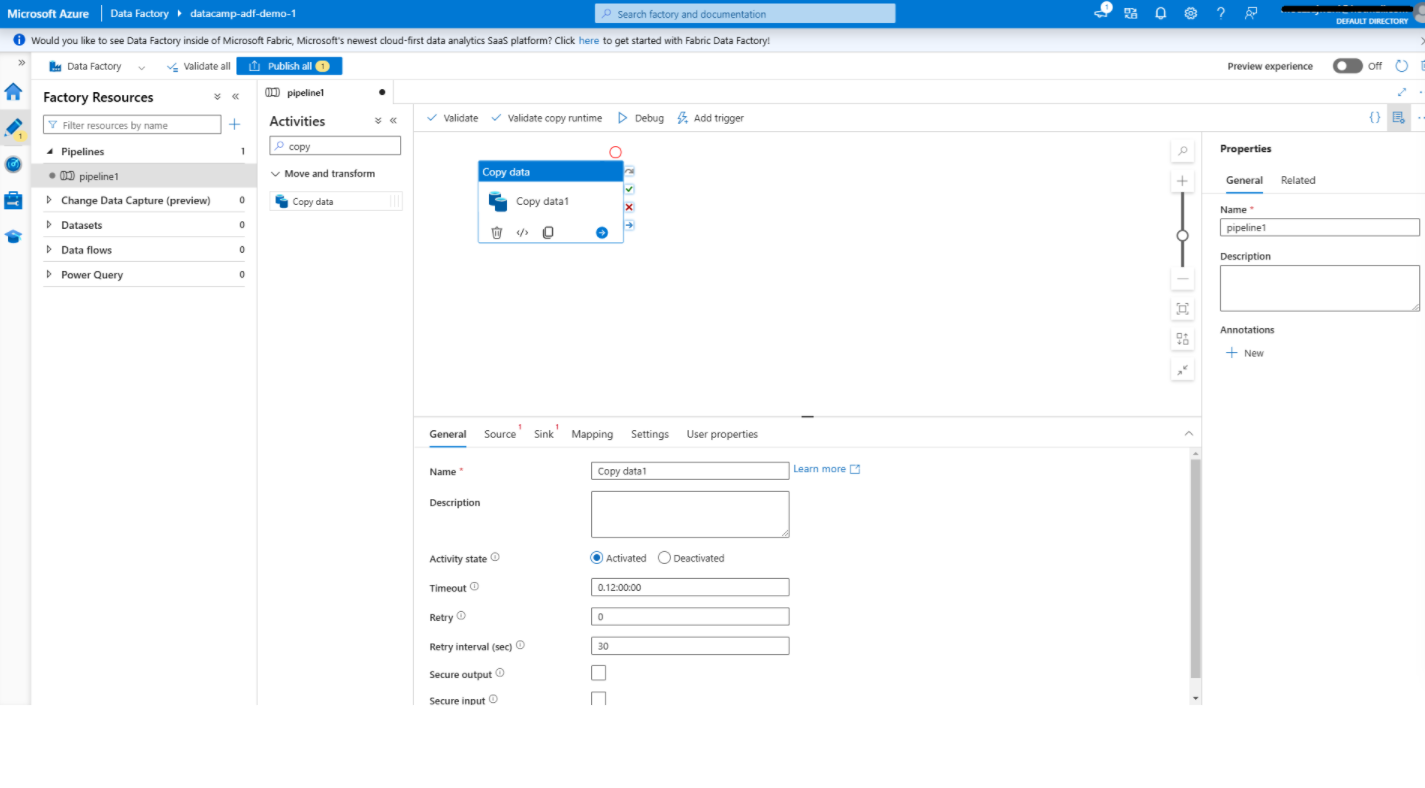
Adding a copy data activity in Azure Data Factory
1. Open the Pipeline editor
2. Add the copy data activity
3. Configure the copy data activity
Publishing pipelines in Azure Data Factory
1. Publish your pipeline
2. Run the pipeline
Azure Data Factory offers powerful data integration and transformation features that simplify complex workflows and enhance productivity. In this section, we will review these features.
Data flows provide a visual environment for defining transformation logic, making it easier for users to manipulate and process data without needing to write complex code. Common tasks performed with data flows include:
Data flows also support advanced operations like column derivations, data type conversions, and conditional transformations, making them versatile tools for handling diverse data requirements.
ADF integrates seamlessly with Azure Synapse Analytics, providing a unified platform for big data processing and advanced analytics. This integration enables users to:
This synergy between ADF and Synapse helps streamline workflows and reduces the complexity of managing separate tools for data integration and analysis.
After an in-depth review of ADF’s features and components, let’s see what we could use it for.
ADF is a powerful tool for migrating data from on-premises systems to cloud-based platforms. It simplifies complex migrations by automating data movement, ensuring data integrity, and minimizing downtime.
For instance, you can use ADF to migrate data from an on-premises SQL Server to an Azure SQL Database with minimal manual intervention. By leveraging built-in connectors and integration runtimes, ADF ensures a secure and efficient migration process, accommodating both structured and unstructured data.
Extract, transform, and load (ETL) processes are at the heart of modern data warehousing. Azure Data Factory streamlines these workflows by integrating data from multiple sources, applying transformation logic, and loading it into a data warehouse.
For example, ADF can consolidate sales data from different regions, transform it into a unified format, and load it into Azure Synapse Analytics. This streamlined process enables you to maintain up-to-date, high-quality data for reporting and decision-making.
|
Check out 23 Best ETL Tools in 2024 and why to choose them. |
Data lakes serve as a central repository for diverse datasets, enabling advanced analytics and machine learning. ADF facilitates ingesting data from various sources into Azure Data Lake Storage, supporting batch and streaming scenarios.
For instance, you can use ADF to collect log files, social media feeds, and IoT sensor data into a single data lake. By providing data transformation and integration tools, ADF ensures the data lake is well-organized and ready for downstream analytics and AI workloads.
Lastly, it’s worth reviewing some best practices for using ADF effectively.
To create maintainable and scalable workflows, design pipelines with reusable components. Modular design allows for easier debugging, testing, and updating of individual pipeline sections. For example, instead of embedding data transformation logic in every pipeline, create a reusable pipeline that can be invoked across multiple workflows. This reduces redundancy and enhances consistency across projects.
So, how is Azure Data Factory different from Databricks? If you are curious and want to discover the differences between Azure Data Factory and Databricks, check out Azure Data Factory vs Databricks: A Detailed Comparison blog.
As you master Azure Data Factory, it is critical to understand its evolution: Microsoft Fabric.
While Azure Data Factory (ADF) remains a robust, standalone Platform-as-a-Service (PaaS) solution widely used in enterprise, Microsoft has introduced Fabric as the future of its data ecosystem. Fabric is an all-in-one SaaS platform that unifies Data Factory, Synapse Analytics, and Power BI into a single environment.
Should you use ADF or Fabric?
Note: ADF pipelines and Fabric Data Factory pipelines are highly similar, so the skills you learn in ADF today are directly transferable to Fabric. You can take our Introduction to Microsoft Fabric course to learn more.
Azure Data Factory simplifies the process of building, managing, and scaling data pipelines in the cloud. It provides an intuitive platform that caters to both technical and non-technical users, enabling them to integrate and transform data from various sources efficiently.
By leveraging its features, such as code-free pipeline authoring, integration capabilities, and monitoring tools, users can easily create scalable and reliable workflows.
To learn more about Azure Data Factory, I recommend checking out the Top 27 Azure Data Factory Interview Questions and Answers.
If you want to explore Azure's backbone, including topics like containers, virtual machines, and more, my recommendation is this amazing free course on Understanding Microsoft Azure Architecture and Services.
Learn more about Microsoft Azure with these courses!
Course
Course
Course
blog
Gus Frazer
12 min
blog
Josep Ferrer
14 min
blog
Kurtis Pykes
15 min
Tutorial
Emmanuel Akor
Tutorial
Florin Angelescu
Tutorial
Kofi Glover