
Kurs
Microsoft Azure verstehen
3 Std.
47.1K
Azure Data Factory (ADF) ist Microsofts cloudbasierter Datenintegrationsdienst, der auf moderne Unternehmen zugeschnitten ist. Sie ermöglicht es den Nutzern, Workflows zu entwerfen, zu verwalten und zu automatisieren, die Datenbewegungen und -umwandlungen auf Unternehmensebene durchführen.
ADF zeichnet sich durch seine benutzerfreundliche, programmierfreie Oberfläche aus, die es sowohl technischen als auch nicht-technischen Nutzern ermöglicht, Datenpipelines einfach zu erstellen. Die umfangreichen Integrationsfunktionen unterstützen mehr als 90 native Konnektoren, die den Datenfluss über verschiedene Quellen hinweg ermöglichen, einschließlich lokaler Systeme und Cloud-basierter Dienste.
In diesem Leitfaden biete ich eine umfassende Einführung in die Azure Data Factory, in der ich auf die Komponenten und Funktionen eingehe und ein praktisches Tutorial anbiete, das dir hilft, deine erste Datenpipeline zu erstellen.
Azure Data Factory (ADF) ist ein Cloud-basierter Datenintegrationsdienst zur Orchestrierung und Automatisierung von Daten-Workflows.
Sie wird verwendet, um Daten zu sammeln, umzuwandeln und bereitzustellen und sicherzustellen, dass die Erkenntnisse für Analysen und Entscheidungen leicht zugänglich sind.
Mit seiner skalierbaren und serverlosen Architektur kann ADF Workflows jeder Größe bewältigen - von einfachen Datenmigrationen bis hin zu komplexen Datenumwandlungspipelines.
ADF überbrückt die Lücke zwischen Datensilos und ermöglicht es den Nutzern, Daten zwischen lokalen Systemen, Cloud-Diensten und externen Plattformen zu verschieben und zu transformieren. Ganz gleich, ob du mit Big Data, operativen Datenbanken oder APIs arbeitest, Azure Data Factory bietet die Werkzeuge, um Daten effizient zu verbinden, zu verarbeiten und zu vereinheitlichen.
Hier sind einige der wichtigsten Funktionen, die ADF bietet.
Azure Data Factory unterstützt die Integration von über 90 Datenquellen, darunter cloudbasierte und lokale Systeme. Sie unterstützt SQL-Datenbanken, NoSQL-Systeme, REST-APIs und dateibasierte Datenquellen und ermöglicht es dir, Datenworkflows unabhängig von der Quelle oder dem Format zu vereinheitlichen.

In Azure Data Factory verfügbare Datenkonnektoren
Die Drag-and-Drop-Schnittstelle von ADF vereinfacht die Erstellung von Datenpipelines. Mit vorgefertigten Vorlagen, geführten Konfigurationsassistenten und einem intuitiven visuellen Editor können auch Nutzer ohne Programmierkenntnisse umfassende End-to-End-Workflows erstellen.
Erfahrung mit No-Code-Authoring in Azure Data Factory
Die Planungswerkzeuge von Azure Data Factory ermöglichen die Automatisierung von Arbeitsabläufen. Du kannst Auslöser einrichten, die auf bestimmten Bedingungen basieren, z. B. dem Eintreffen einer Datei im Cloud-Speicher oder geplanten Zeitintervallen. Diese Planungsoptionen machen manuelle Eingriffe überflüssig und stellen sicher, dass die Arbeitsabläufe konsistent und zuverlässig ausgeführt werden.
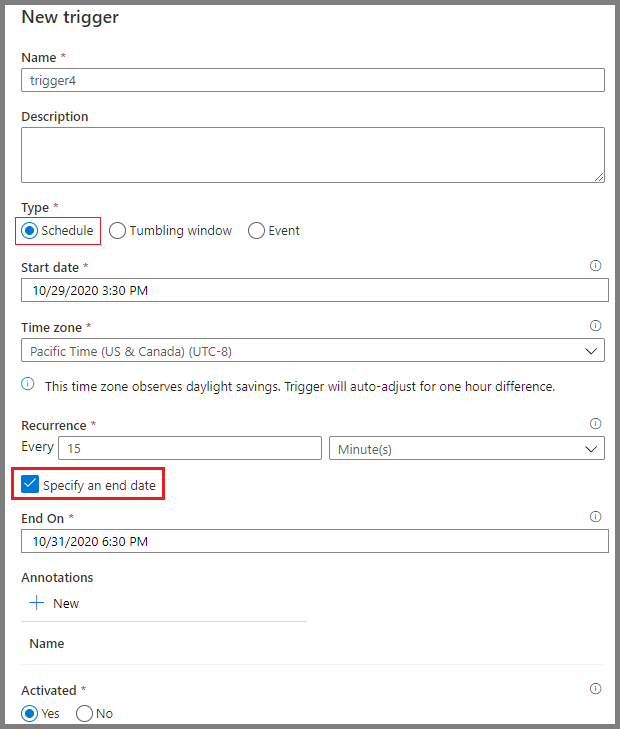
Planen von Pipelines in Azure Data Factory
Das Verständnis der Kernkomponenten von Azure Data Factory ist für den Aufbau effizienter Arbeitsabläufe unerlässlich.
Pipelines sind das Rückgrat der Azure Data Factory. Sie stellen datengesteuerte Workflows dar, die die Schritte definieren, die erforderlich sind, um Daten zu bewegen und umzuwandeln.
Jede Pipeline dient als Container für eine oder mehrere Aktivitäten, die sequentiell oder parallel ausgeführt werden, um den gewünschten Datenfluss zu erreichen.
Diese Pipelines ermöglichen es Dateningenieuren, End-to-End-Prozesse zu erstellen, z. B. Rohdaten aufzunehmen, sie in ein brauchbares Format umzuwandeln und sie in Zielsysteme zu laden.
Beispiel einer einfachen Pipeline in Azure Data Factory
Aktivitäten sind die funktionalen Bausteine von Pipelines, die jeweils einen bestimmten Vorgang ausführen. Sie werden grob in folgende Kategorien eingeteilt:
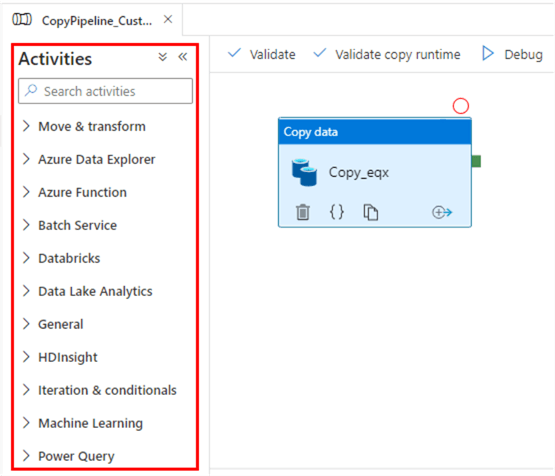
Aktivitäten in Azure Data Factory
Datensätze sind Darstellungen von Daten, die in Aktivitäten verwendet werden. Sie definieren das Schema, das Format und den Ort der Daten, die aufgenommen oder verarbeitet werden.
Ein Dataset kann zum Beispiel eine CSV-Datei in Azure Blob Storage oder eine Tabelle in einer Azure SQL-Datenbank beschreiben. Datensätze sind die Zwischenschicht, die die Aktivitäten mit den eigentlichen Datenquellen und -zielen verbindet.
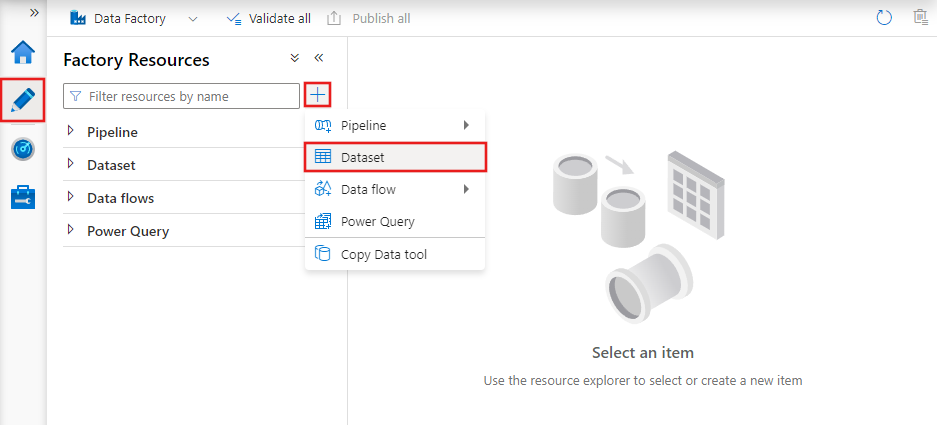
Datensätze in Azure Data Factory
Verknüpfte Dienste sind Verbindungsstränge, die es Aktivitäten und Datensätzen ermöglichen, auf externe Systeme und Dienste zuzugreifen.
Sie fungieren als Brücke zwischen Azure Data Factory und den externen Ressourcen, mit denen sie interagiert, wie Datenbanken, Speicherkonten oder Rechenumgebungen.
Ein verlinkter Dienst kann sich zum Beispiel mit einem lokalen SQL Server oder einem Cloud-basierten Data Lake verbinden.
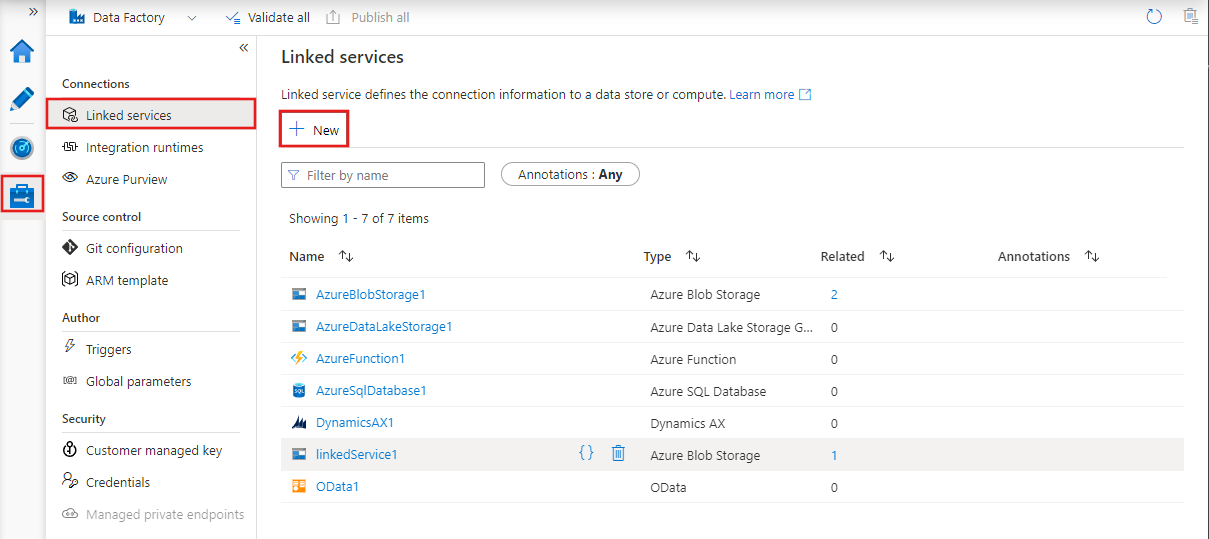
Verknüpfte Dienste in Azure Data Factory
Integration Runtimes (IRs) sind die Rechenumgebungen, die die Datenbewegung, -umwandlung und -ausführung in Azure Data Factory ermöglichen. ADF bietet drei Arten von Integrations-Laufzeiten:
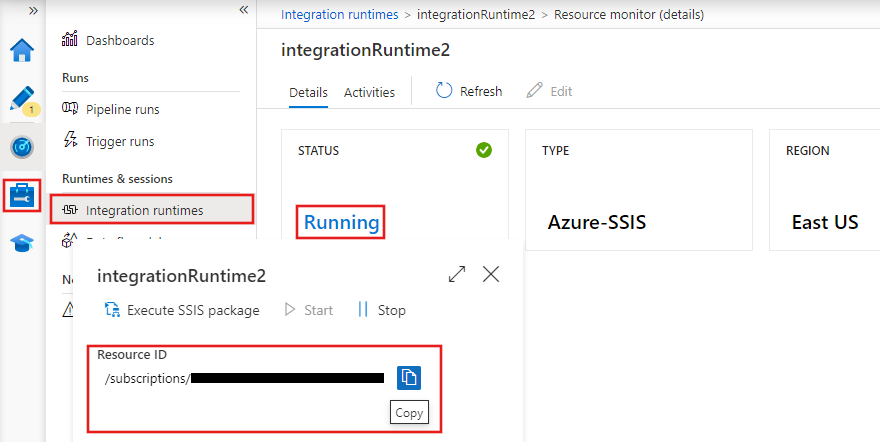
Integrations-Laufzeiten in Azure Data Factory
Kommen wir nun zum praktischen Teil dieses Leitfadens!
1. Ein aktivese Azure-Abonnement.
2. Eine Ressourcengruppe zur Verwaltung vonAzure-Ressourcen.
1. Melde dich auf im Azure-Portal an.
2. Navigiere zu Ressource erstellen und wähle Data Factory.
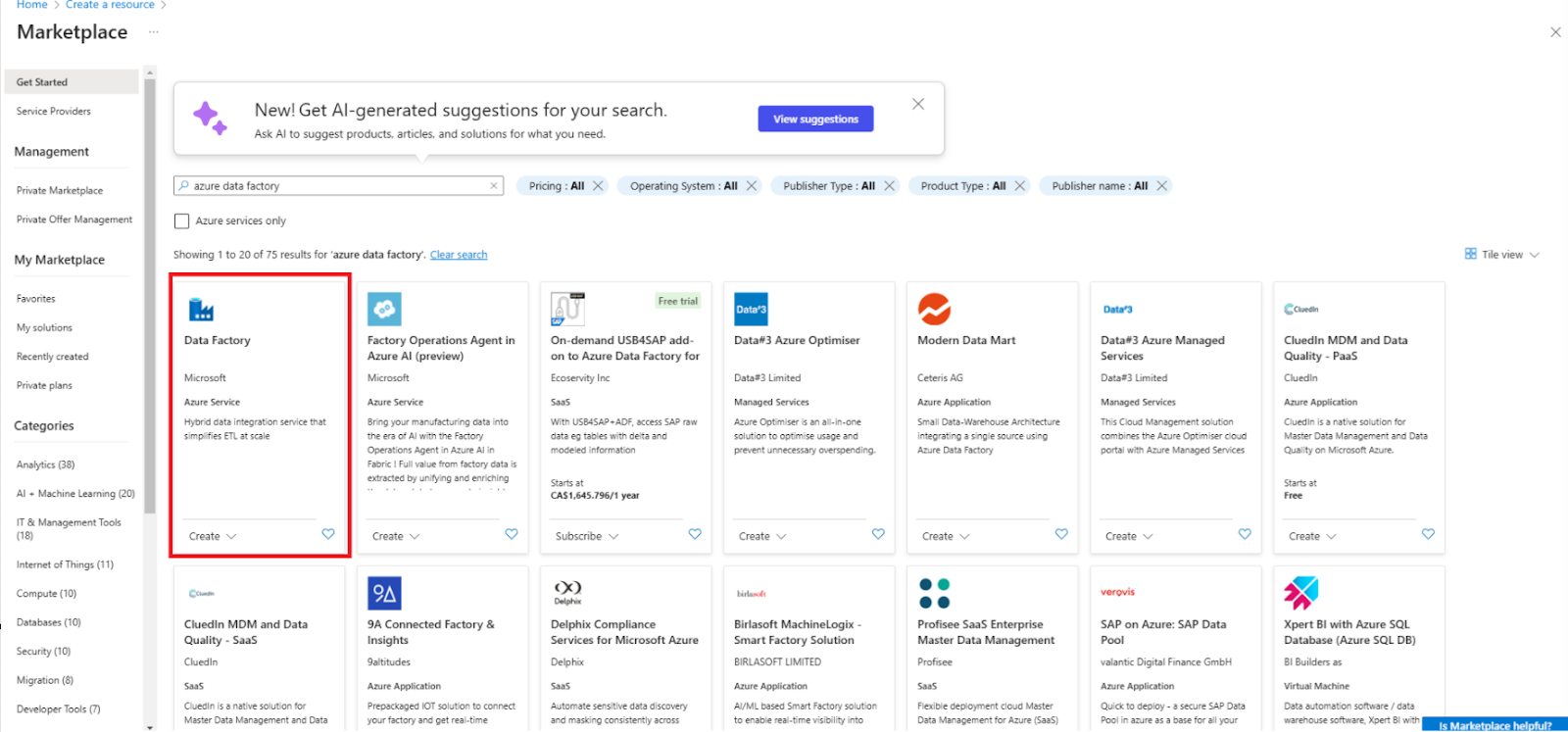
Erstelle eine neue Data Factory Ressource
3. Fülle die erforderlichen Felder aus, einschließlich Abonnement, Ressourcengruppe und Region.
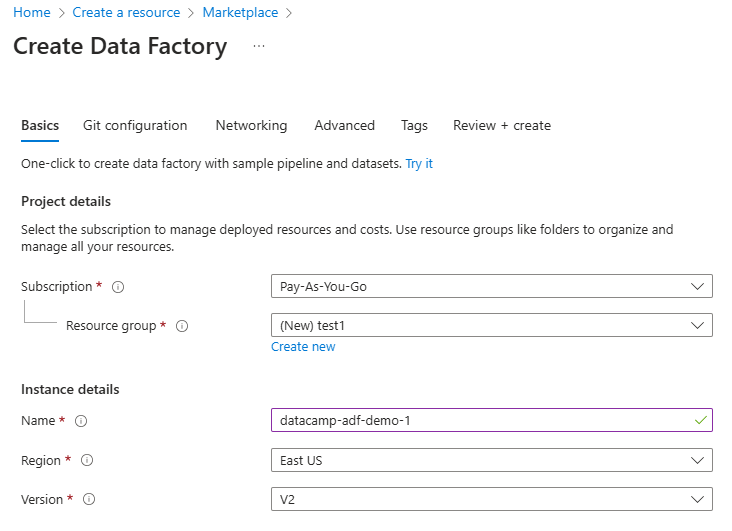
Data Factory Ressource konfigurieren
4. Überprüfe und erstelle die Instanz.
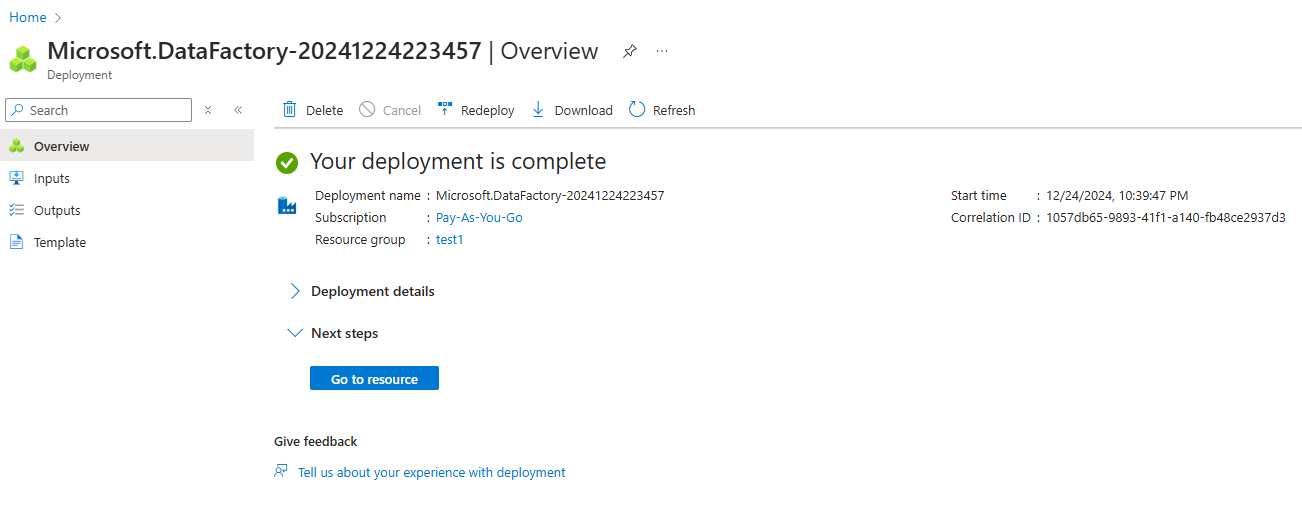
Azure Data Factory Instanz erstellt
Die ADF-Oberfläche besteht aus den folgenden Hauptabschnitten (erreichbar über das linke Navigationsmenü)
1. Autor: Zum Erstellen und Verwalten von Pipelines.
2. Monitor: Um Lernpfade zu verfolgen und Probleme zu beheben.
3. Verwalte: Für die Konfiguration von verknüpften Diensten und Integrationslaufzeiten.
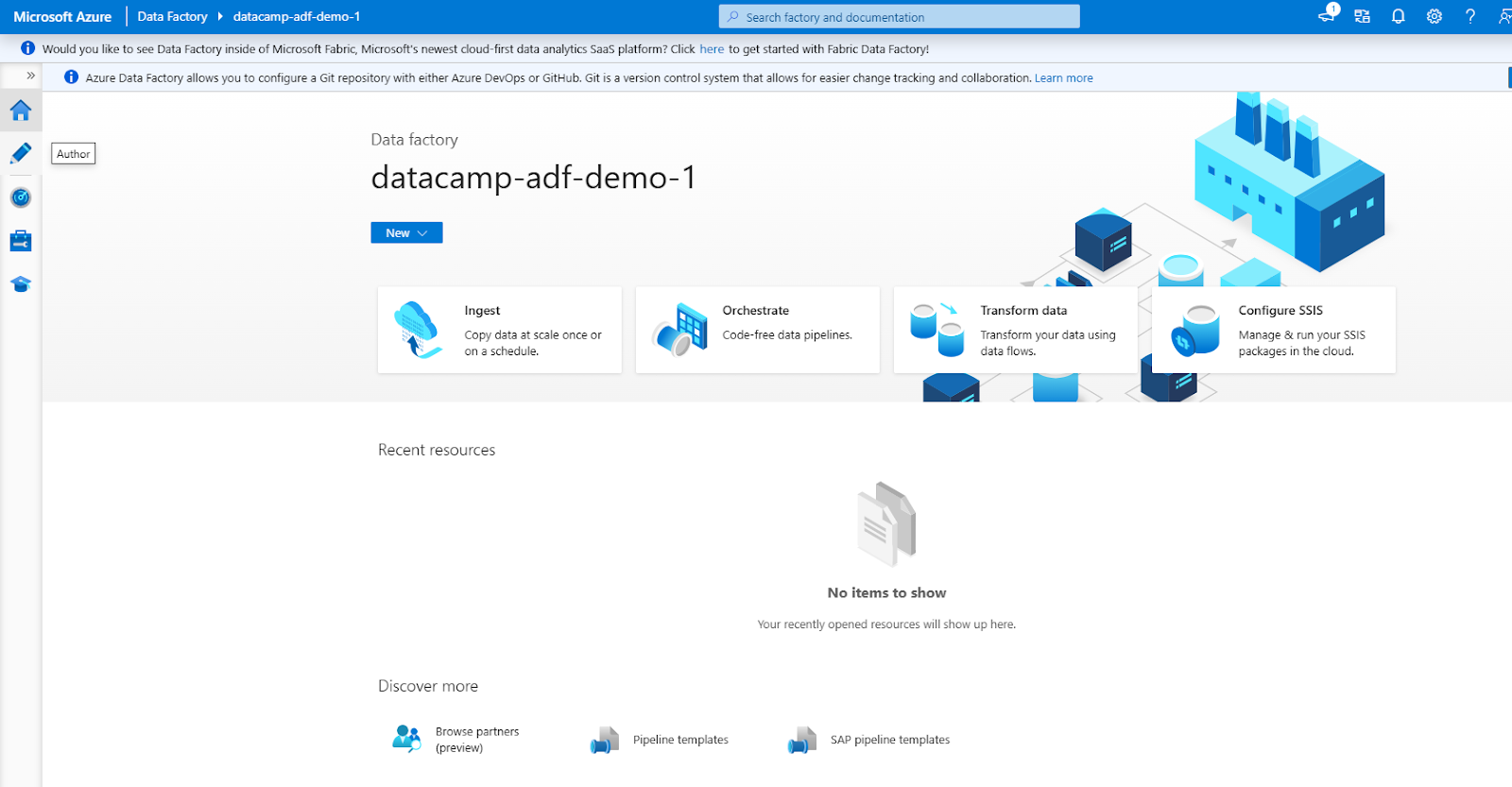
Azure Data Factory Interface
Gehen wir die Schritte durch, um eine einfache Datenpipeline zu erstellen.
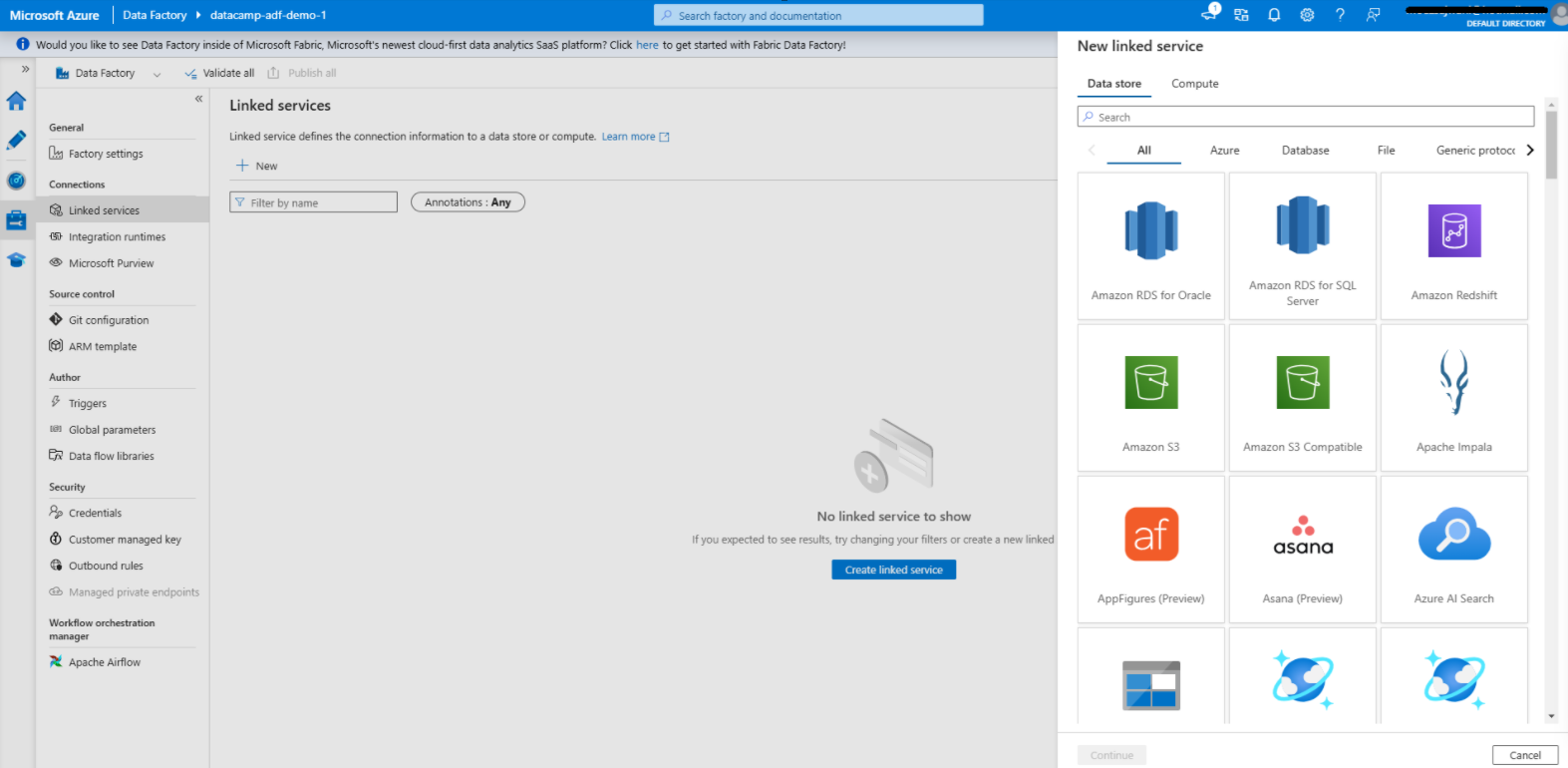
Verknüpften Dienst in Azure Data Factory erstellen
1. Navigiere zur Registerkarte Verwalten
2. Füge einen verknüpften Dienst für die Datenquelle hinzu
3. Füge einen verknüpften Dienst für das Datenziel hinzu
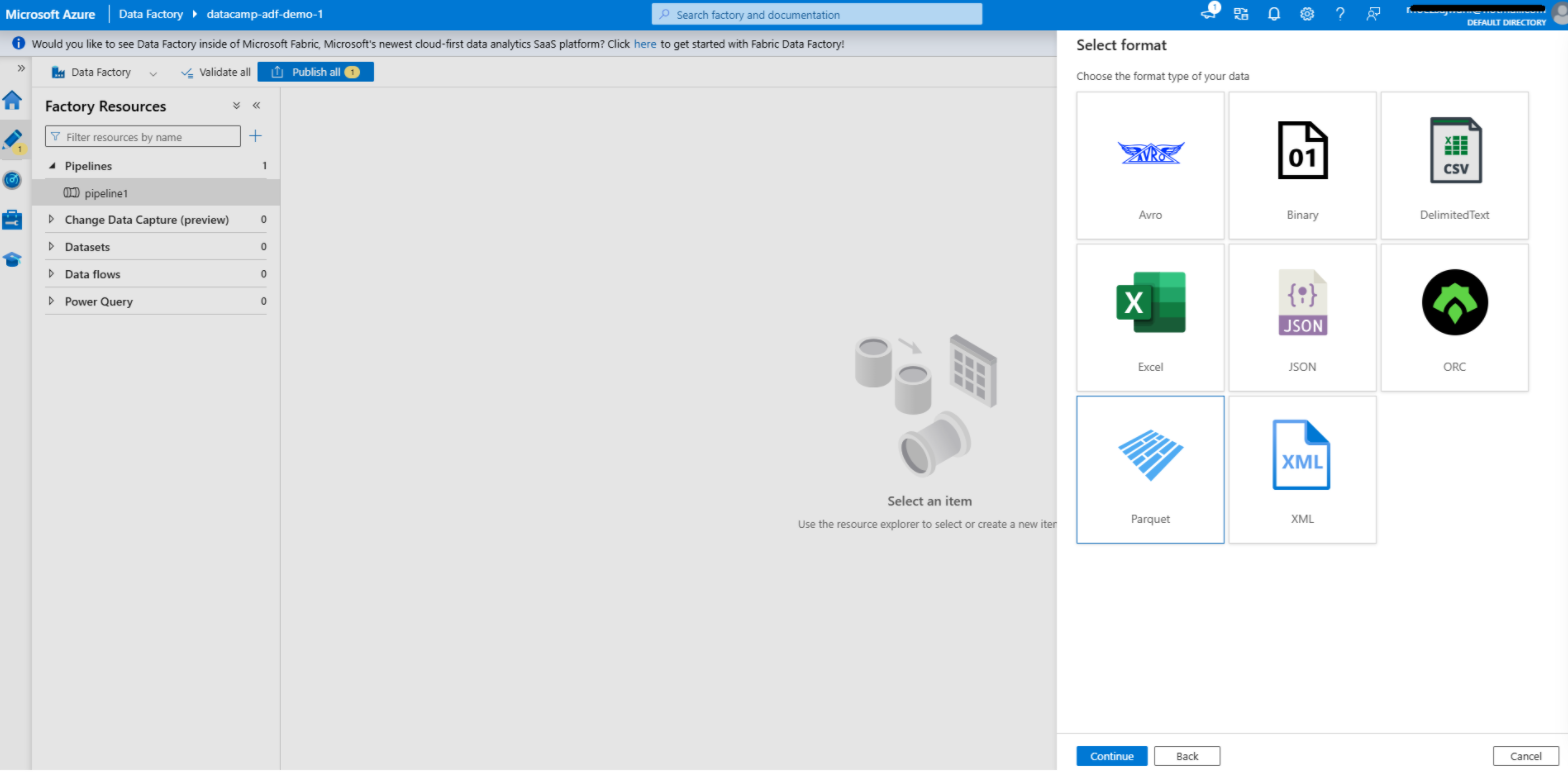
Erstellen eines Datensatzes in Azure Data Factory
1. Navigiere zur Registerkarte "Autor
2. Hinzufügen eines Datensatzes für die Quelle
3. Hinzufügen eines Datensatzes für das Ziel
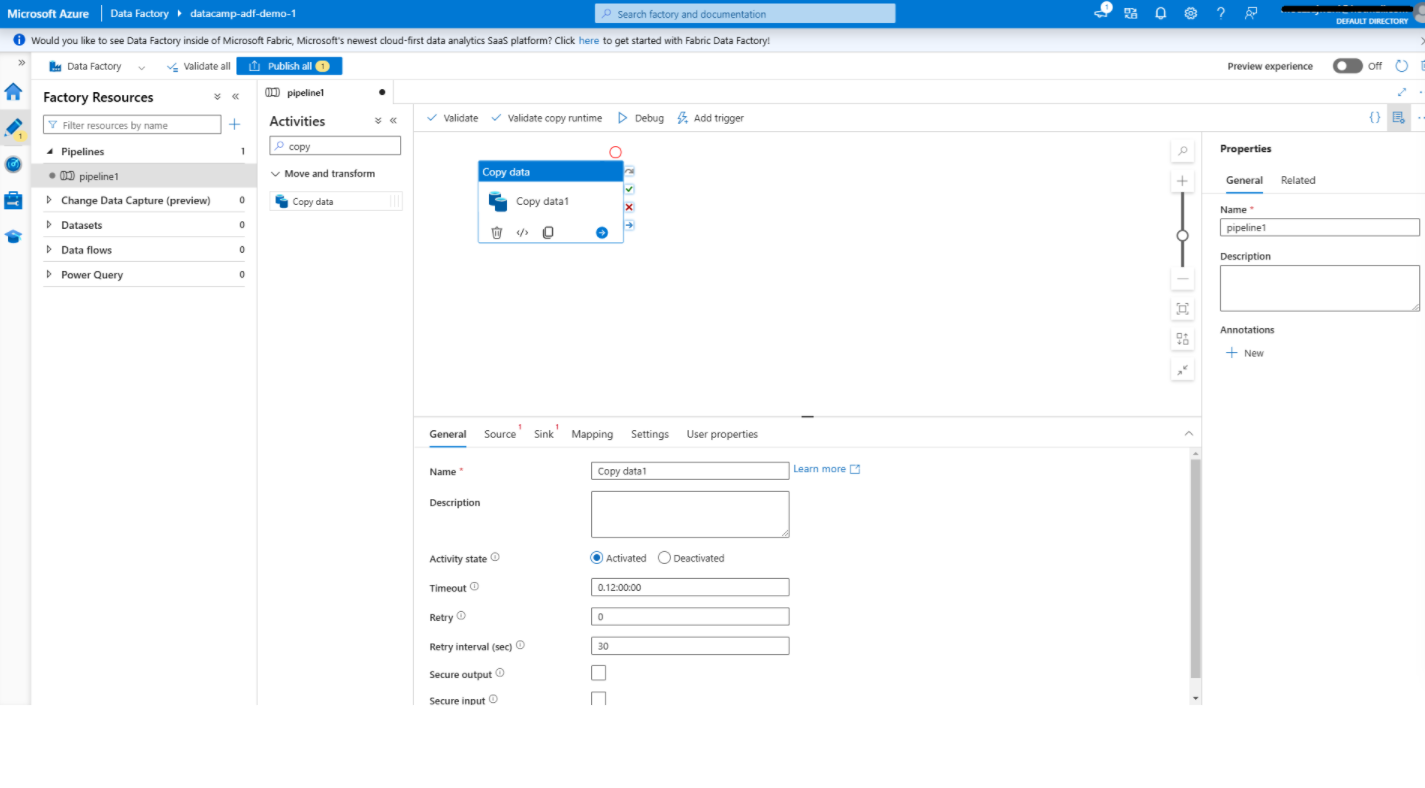
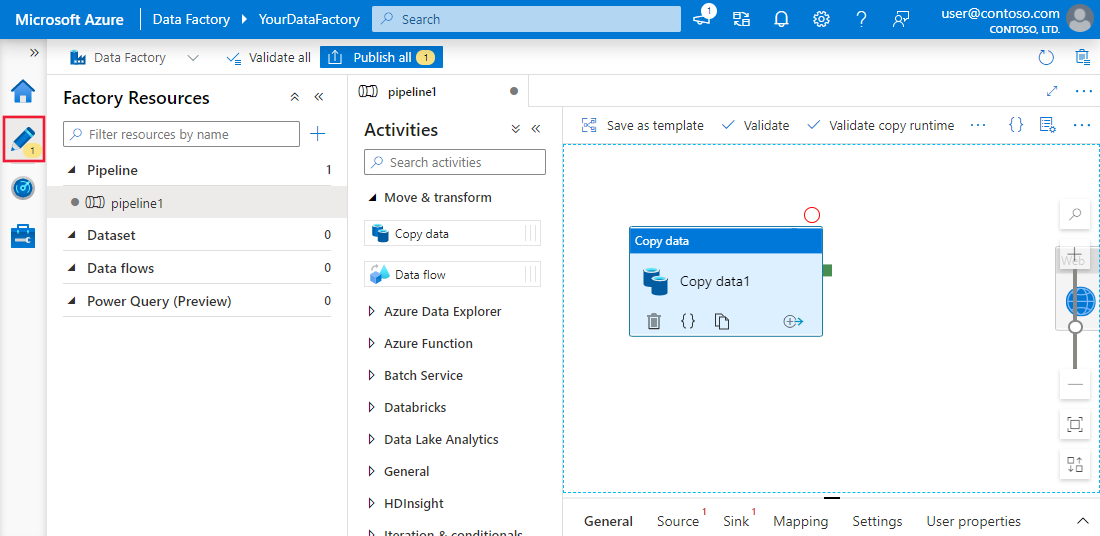
Hinzufügen einer Aktivität zum Kopieren von Daten in Azure Data Factory
1. Öffne den Pipeline-Editor
2. Füge die Aktivität Daten kopieren hinzu
3. Konfiguriere die Aktivität Daten kopieren
Veröffentlichung von Pipelines in Azure Data Factory
1. Veröffentliche deine Pipeline
2. Die Pipeline ausführen
Azure Data Factory bietet leistungsstarke Funktionen zur Datenintegration und -umwandlung, die komplexe Arbeitsabläufe vereinfachen und die Produktivität steigern. In diesem Abschnitt gehen wir auf diese Funktionen ein.
Data flows probietet eine visuelle Umgebung für die Definition von Transformationslogik, die es den Nutzern erleichtert, Daten zu manipulieren und zu verarbeiten, ohne komplexen Code schreiben zu müssen. Zu den üblichen Aufgaben, die mit Datenflüssen durchgeführt werden, gehören:
Datenflüsse unterstützen auch fortgeschrittene Operationen wie Spaltenableitungen, Datentypkonvertierungen und bedingte Transformationen, was sie zu vielseitigen Werkzeugen für den Umgang mit unterschiedlichen Datenanforderungen macht.
ADF lässt sich nahtlos in Azure Synapse Analyticsintegrieren und bieteteine einheitliche Plattform für die Verarbeitung von Big Data und erweiterte Analysen. Diese Integration ermöglicht es den Nutzern,:
Diese Synergie zwischen ADF und Synapse trägt dazu bei, Arbeitsabläufe zu rationalisieren und die Komplexität der Verwaltung separater Tools für die Datenintegration und -analyse zu verringern.
Nach einem ausführlichen Überblick über die Funktionen und Komponenten von ADF wollen wir sehen, wofür wir es verwenden können.
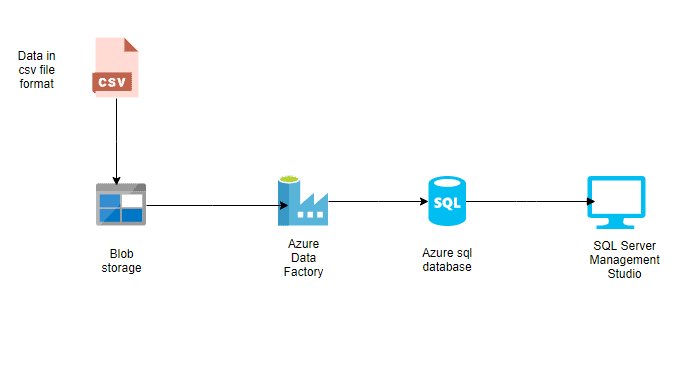
ADF ist ein leistungsfähiges Werkzeug für die Migration von Daten aus lokalen Systemen auf cloudbasierte Plattformen. Es vereinfacht komplexe Migrationen, indem es die Datenbewegung automatisiert, die Datenintegrität sicherstellt und Ausfallzeiten minimiert.
Du kannst ADF zum Beispiel nutzen, um Daten von einem lokalen SQL Serverzu einer Azure SQL-Datenbank zu migrieren, und zwar mith minimalem manuellen Eingriff. Durch die Nutzung von integrierten Konnektoren und Integrationslaufzeiten gewährleistet ADF einen sicheren und effizienten Migrationsprozess, der sowohl strukturierte als auch unstrukturierte Daten berücksichtigt.
Extrahier-, Transformier- und Ladeprozesse (ETL) sind das Herzstück des modernen Data Warehousing. Azure Data Factory rationalisiert diese Arbeitsabläufe, indem es Daten aus verschiedenen Quellen integriert, Transformationslogik anwendet und sie in ein Data Warehouse lädt.
ADF kann zum Beispiel Verkaufsdaten aus verschiedenen Regionen konsolidieren, in ein einheitliches Format umwandeln und in Azure Synapse Analytics laden. Dieser optimierte Prozess ermöglicht es dir, aktuelle und hochwertige Daten für die Berichterstattung und Entscheidungsfindung zu erhalten.
|
Schau dir die 23 besten ETL-Tools im Jahr 2024 an und erfahre, warum du sie wählen solltest. |
Data Lakes dienen als zentraler Speicher für verschiedene Datensätze und ermöglichen erweiterte Analysen und maschinelles Lernen. ADF erleichtert das Einlesen von Daten aus verschiedenen Quellen in Azure Data Lake Storage und unterstützt Batch- und Streaming-Szenarien.
Du kannst ADF zum Beispiel nutzen, um Logdateien, Social Media Feeds und IoT-Sensordaten in einem einzigen Data Lake zu sammeln. Durch die Bereitstellung von Datenumwandlungs- und Integrationswerkzeugen stellt ADF sicher, dass der Data Lake gut organisiert und für nachgelagerte Analysen und KI-Workloads bereit ist.
Zu guter Letzt lohnt es sich, einige Best Practices für den effektiven Einsatz von ADF zu besprechen.
Um wartbare und skalierbare Workflows zu erstellen, solltest du Pipelines mit wiederverwendbaren Komponenten entwerfen. Der modulare Aufbau erleichtert das Debuggen, Testen und Aktualisieren einzelner Pipelineabschnitte. Anstatt beispielsweise die Logik zur Datenumwandlung in jede Pipeline einzubetten, solltest du eine wiederverwendbare Pipeline erstellen, die über mehrere Workflows hinweg aufgerufen werden kann. Das reduziert Redundanzen und verbessert die Konsistenz zwischen den Projekten.
Was ist der Unterschied zwischen Azure Data Factoryund Databricks? Wenn du neugierig bist und die Unterschiede zwischen Azure Data Factory und Databricks kennenlernen möchtest, schau dir Azure Data Factory vs. Databricks an: Ein detaillierter Vergleich blog.
Azure Data Factory vereinfacht den Aufbau, die Verwaltung und die Skalierung von Datenpipelines in der Cloud. Sie bietet eine intuitive Plattform, die sowohl technische als auch nicht-technische Nutzer/innen anspricht und es ihnen ermöglicht, Daten aus verschiedenen Quellen effizient zu integrieren und umzuwandeln.
Durch die Nutzung seiner Funktionen, wie z. B. die Erstellung von Pipelines ohne Code, Integrationsfunktionen und Überwachungswerkzeuge, können Nutzer/innen leicht skalierbare und zuverlässige Workflows erstellen.
Wenn du mehr über Azure Data Factory erfahren möchtest, empfehle ich dir die Top 27 Azure Data Factory Interview Fragen und Antworten.
Wenn du das Rückgrat von Azure erkunden willst, einschließlich Themen wie Container, virtuelle Maschinen und mehr, empfehle ich dir diesen tollen kostenlosen Kurs " Understanding Microsoft Azure Architecture and Services".
Erfahre mehr über Microsoft Azure mit diesen Kursen!
Kurs
Kurs
Kurs
Blog
Zoumana Keita
15 Min.
Blog
Nathaniel Taylor-Leach
4 Min.
Tutorial
Mark Pedigo
Tutorial
Sejal Jaiswal
Tutorial
Sejal Jaiswal
Tutorial
Matt Crabtree
