
Cursus
Bayesiaanse regressiemodellering met rstanarm
4 Hr
7.1K
OLS (ordinary least squares) regressie is absoluut de moeite waard om te leren, omdat het een groot onderdeel is van statistiek en machine learning. Het wordt gebruikt om uitkomsten te voorspellen of relaties tussen variabelen te analyseren, en die toepassingen variëren van toetsen van hypothesen tot voorspellen.
In dit artikel help ik je de basisprincipes van OLS-regressie, de toepassingen, aannames en de implementatie in Excel, R en Python te begrijpen. Er valt veel te leren, dus volg na afloop onze gerichte regressiecursussen zoals Introduction to Regression in Python en Introduction to Regression in R, en lees onze tutorials, zoals Linear Regression in Excel.
OLS-regressie schat de relatie tussen één of meer onafhankelijke variabelen (predictoren) en een afhankelijke variabele (respons). Dit gebeurt door een lineaire vergelijking te fitten op geobserveerde data. Zo ziet die vergelijking eruit:
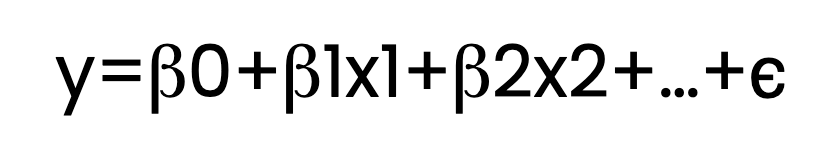
Hierbij:
In de bovenstaande vergelijking laat ik meerdere β-termen zien, zoals β1 en β2. Maar om het duidelijk te maken: de regressievergelijking kan ook slechts één β-term bevatten naast β0; in dat geval noemen we het eenvoudige lineaire regressie. Met twee of meer predictoren, zoals β1 en β2, spreken we van meervoudige lineaire regressie. Beide vallen onder OLS-regressie als er een ordinary least squares-schatting wordt gebruikt.
De kern van OLS-regressie is een optimalisatievraag: de lijn (of hypervlak in hogere dimensies) vinden die het best bij de data past. Maar wat betekent "best passend"? Hier betekent "best passend" het minimaliseren van de som van gekwadrateerde residualen.
Ik leg het minimalisatieprobleem uit en tegelijk het idee van residualen.
Door de som van de gekwadrateerde residualen te minimaliseren, wordt de regressielijn een nauwkeurige weergave van de relatie tussen de onafhankelijke en afhankelijke variabelen. Sterker nog, door die som te minimaliseren, heeft ons model de kleinst mogelijke totale fout in zijn voorspellingen. Wil je meer leren over residualen en regressie-decompositie, lees dan onze tutorial Understanding Sum of Squares: A Guide to SST, SSR, and SSE.
In de context van regressie worden schatters gebruikt om de coëfficiënten te berekenen die de relatie tussen onafhankelijke variabelen en de afhankelijke variabele beschrijven. De ordinary least squares (OLS)-schatter is zo'n methode. Die vindt de coëfficiëntwaarden die de som van de gekwadrateerde verschillen tussen de geobserveerde waarden en de waarden die het model voorspelt, minimaliseren.
Ik noem dit om de termen helder te houden. Regressie kan ook met andere schatters worden uitgevoerd, die elk andere voordelen bieden afhankelijk van de data en het analysetoel. Sommige schatters zijn bijvoorbeeld robuuster voor uitschieters, terwijl andere overfitting helpen voorkomen door de modelparameters te regulariseren.
Om de coëfficiënten te bepalen die het best bij het regressiemodel passen, gebruikt de OLS-schapper wiskundige technieken om de som van gekwadrateerde residualen te minimaliseren. Eén mogelijke methode is de normale vergelijking, die een directe oplossing biedt door een stelsel vergelijkingen op te stellen op basis van de data en op te lossen voor de coëfficiënten die de kleinst mogelijke som van gekwadrateerde verschillen tussen de geobserveerde en voorspelde waarden geven.
Het oplossen van de normale vergelijking kan echter rekenintensief worden, vooral bij grote datasets. Daarom wordt vaak een andere techniek gebruikt: QR-decompositie. QR-decompositie breekt de matrix van onafhankelijke variabelen op in twee eenvoudigere matrices: een orthogonale matrix (Q) en een boventriangulaire matrix (R). Deze vereenvoudiging maakt de berekeningen efficiënter en verbetert ook de numerieke stabiliteit.
Hoe beslissen we om OLS-regressie te gebruiken? Bij die beslissing moeten we zowel de kenmerken van onze dataset beoordelen als het specifieke probleem dat we willen oplossen definiëren.
Voordat we OLS-regressie toepassen, moeten we controleren of onze data aan de volgende aannames voldoet, zodat we betrouwbare resultaten krijgen:
Ernstige schendingen van deze aannames kunnen leiden tot vertekte schattingen of onbetrouwbare voorspellingen. Daarom moeten we echt eventuele problemen beoordelen en aanpakken voordat we verder gaan.
Zodra aan de aannames is voldaan, kan OLS-regressie voor verschillende doelen worden gebruikt:
Laten we nu kijken hoe je OLS-regressie uitvoert in R, Python en Excel.
R biedt de functie lm() voor OLS-regressie. Hier is een voorbeeld:
# Let's create sample data
predictor_variable <- c(1, 2, 3, 4, 5)
response_variable <- c(2, 4, 5, 4, 5)
# We now fit the OLS regression model using the lm() function from base R
ols_regression_model <- lm(response_variable ~ predictor_variable)
# OLS regression model summary
summary(ols_regression_model)Let op dat we geen extra packages hoeven te importeren om OLS-regressie in R uit te voeren.
Python biedt bibliotheken zoals statsmodels en scikit-learn voor OLS-regressie. Laten we een voorbeeld proberen met statsmodels:
import statsmodels.api as sm
# We can create some sample data
ols_regression_predictor = [1, 2, 3, 4, 5]
ols_regression_response = [2, 4, 5, 4, 5]
# Adding a constant for the intercept
ols_regression_predictor = sm.add_constant(ols_regression_predictor)
# We now fit our OLS regression model
ols_regression_model = sm.OLS(ols_regression_response, ols_regression_predictor).fit()
# Summary of our OLS regression
print(ols_regression_model.summary())Ook in Excel kun je OLS-regressie uitvoeren met ingebouwde tools. Volg gewoon deze stappen:
Zet je data in twee kolommen: één voor de onafhankelijke variabele(n) en één voor de afhankelijke variabele. Zorg dat er geen lege cellen in je dataset staan.
Ga naar Bestand > Opties > Invoegtoepassingen. Kies in het vak Beheren Excel-invoegtoepassingen en klik op Start. Vink het vakje aan bij Analysis ToolPak en klik op OK.
Ga naar Gegevens > Gegevensanalyse en selecteer Regressie in de lijst met opties. Klik op OK.
In het dialoogvenster Regressie:
We hebben nu een OLS-regressiemodel gemaakt. De volgende stap is nagaan of het effectief is door te kijken naar modeldiagnostiek en modelstatistieken.
We kunnen een OLS-regressiemodel beoordelen met visuele tools om aannames en de kwaliteit van de fit te toetsen. Enkele opties zijn een plot van residualen tegen gepaste waarden, die patronen controleert die kunnen wijzen op non-lineariteit of heteroscedasticiteit, of de Q-Q-plot, die bekijkt of residualen een verdeling volgen zoals een normale verdeling.
We kunnen ons model ook evalueren met statistische maatstaven die inzicht geven in de modelprestatie en de significantie van predictoren. Veelgebruikte modelstatistieken zijn R-kwadraat en gecorrigeerd R-kwadraat, die het aandeel verklaarde variantie door het model meten. We kunnen ook kijken naar de F-statistiek en p-waarden, die de algemene significantie van het model en van afzonderlijke predictoren toetsen.
Tot slot is het goed om te zeggen dat data-analisten ook graag een gestructureerd proces volgen om de voorspellende capaciteiten van een model te valideren. Dit omvat het splitsen van de data in trainings- en testsets, een trainingsfase om het model te fitten en vervolgens een testfase om de prestaties op onzichtbare testdata te evalueren. Dit proces kan ook kruisvalideringsstappen bevatten zoals k-fold cross-validatie.
Nu we de basis van OLS-regressie hebben verkend, gaan we enkele meer geavanceerde concepten bekijken.
Maximum likelihood-schatting (MLE) is een ander concept dat vaak samen met OLS-regressie wordt besproken, en met goede reden. Tot nu toe hebben we besproken hoe OLS de som van gekwadrateerde residualen minimaliseert om coëfficiënten te schatten. Laten we nu een stap terug doen en MLE bespreken.
MLE maximaliseert de waarschijnlijkheid om de gegeven data te observeren onder ons model. Het werkt door een specifieke kansverdeling voor de foutterm aan te nemen. Deze kansverdeling is meestal een normale, of Gaussische, verdeling. Met die kansverdeling zoeken we parameterwaarden die de geobserveerde data zo waarschijnlijk mogelijk maken.
De reden dat ik maximum likelihood-schatting nu aanhaal, is dat in de context van OLS-regressie de MLE-aanpak tot dezelfde coëfficiëntschattingen leidt als die welke we krijgen door de som van kwadratische fouten te minimaliseren, mits de fouten normaal verdeeld zijn.
Een andere interessante kijk op OLS-regressie is de interpretatie als een gewogen gemiddelde. Prof. Andrew Gelman bespreekt het idee dat de coëfficiënten in een OLS-regressie kunnen worden gezien als een gewogen gemiddelde van de geobserveerde datapunten, waarbij de gewichten worden bepaald door de variantie van de predictoren en de structuur van het model.
Deze kijk geeft inzicht in hoe het regressieproces werkt en waarom het zich gedraagt zoals het doet, omdat OLS-regressie in feite meer gewicht geeft aan observaties met minder variantie of die dichter bij de voorspellingen van het model liggen. Je kunt ook in onze DataFramed-podcastaflevering Election Forecasting and Polling luisteren naar wat professor Gelman zegt over het gebruik van regressie bij verkiezingspeilingen.
Er zijn verschillende andere regressiemethoden met namen die misschien vergelijkbaar klinken, maar andere doelen dienen of onder andere aannames werken. Laten we enkele van die vergelijkbaar klinkende methoden bekijken:
WLS is een uitbreiding van OLS die verschillende gewichten toekent aan elk datapunt op basis van de variantie van hun observaties. WLS is vooral nuttig wanneer de aanname van constante variantie van residualen wordt geschonden. Door observaties omgekeerd evenredig aan hun variantie te wegen, levert WLS betrouwbaardere schattingen op bij heteroscedastische data.
PLS combineert kenmerken van principal component analysis en meervoudige regressie door latente variabelen te extraheren die de maximale covariantie tussen predictoren en de responsvariabele vastleggen. PLS is voordelig in situaties met multicollineariteit of wanneer het aantal predictoren groter is dan het aantal observaties. Het reduceert dimensionaliteit en maximaliseert tegelijk de voorspellende kracht, iets wat OLS niet inherent doet.
Net als WLS veralgemeniseert GLS OLS door gecorreleerde en/of niet-constante variantie van de residualen toe te staan. GLS past het schattingsproces aan om schendingen van de OLS-aannames over de residualen te ondervangen en levert in zulke gevallen efficiëntere en onpartijdigere schattingen.
Ook wel orthogonale regressie genoemd, minimaliseert TLS de loodrechte afstanden van de datapunten tot de regressielijn, in plaats van de verticale afstanden die OLS minimaliseert. TLS is nuttig wanneer er fouten zitten in zowel de onafhankelijke als de afhankelijke variabelen, terwijl OLS ervan uitgaat dat alleen de afhankelijke variabele meetfouten heeft.
Wanneer de relatie tussen variabelen complex of niet-lineair is, bieden niet-parametrische regressiemethoden flexibele alternatieven voor OLS door de data de vorm van de regressiefunctie te laten bepalen. Alle voorgaande voorbeelden (de "vergelijkbaar klinkende") vallen in de categorie parametrische modellen. Maar niet-parametrische modellen kunnen ook worden gebruikt wanneer je patronen wilt modelleren zonder de beperkingen van parametrische aannames.
| Methode | Beschrijving | Voordelen | Veelvoorkomende use-cases |
|---|---|---|---|
| Kernregressie | Gebruikt gewogen gemiddelden met een kernel om data te gladstrijken. | Vangt niet-lineaire relaties Flexibel gladstrijken |
Verkennende analyse Onbekende variablerelaties |
| Lokale regressie | Fit lokale polynomen op subsets van data voor een vloeiende curve. | Kan complexe patronen aan Adaptieve gladheid |
Trendvisualisatie Spreidingsdiagram gladstrijken |
| Regressiebomen | Splitst data in takken om in elk segment eenvoudige modellen te fitten. | Makkelijk te interpreteren Gaat goed om met interacties |
Data segmenteren Verschillende dataregimes identificeren |
| Splineregressie | Gebruikt stuksgewijze polynomen met continuïteit op knopen om data te modelleren. | Modelleert vloeiende niet-lineaire trends Flexibele fitting |
Tijdreeksen Groeicurves |
OLS-regressie is een fundamenteel hulpmiddel om relaties in data te begrijpen en voorspellingen te doen. Door OLS onder de knie te krijgen, leg je een solide basis voor het verkennen van geavanceerde modellen en technieken. Bekijk DataCamp’s cursussen over regressie in R en Python om je skillset uit te breiden: Introduction to Regression with statsmodels in Python en Introduction to Regression in R). Overweeg ook onze zeer populaire Machine Learning Scientist in Python career track.
Leer OLS-regressie met DataCamp
Cursus
Cursus
Cursus
blog
Adel Nehme
15 min
