
Cours
Modélisation de régression bayésienne avec rstanarm
4 h
7.1K
La régression par les MCO (moindres carrés ordinaires) vaut vraiment la peine d'être apprise, car elle constitue une part importante des statistiques et de l'apprentissage automatique. Elle est utilisée pour prédire les résultats ou analyser les relations entre les variables, et les applications de ces deux utilisations vont du test d'hypothèse à la prévision.
Dans cet article, je vous aiderai à comprendre les principes fondamentaux de la régression par les MCO, ses applications, ses hypothèses et la manière dont elle peut être mise en œuvre dans Excel, R et Python. Il y a beaucoup à apprendre, alors quand vous aurez terminé, suivez nos cours de régression désignés, comme Introduction à la régression en Python et Introduction à la régression en R, et lisez nos tutoriels, comme Régression linéaire dans Excel.
La régression MCO estime la relation entre une ou plusieurs variables indépendantes (prédicteurs) et une variable dépendante (réponse). Pour ce faire, il ajuste une équation linéaire aux données observées. Voici à quoi ressemble cette équation :
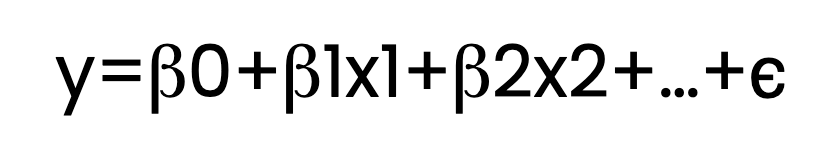
Ici :
Dans l'équation ci-dessus, je montre plusieurs termes β , comme β1 et β2. Mais pour être clair, l'équation de régression pourrait ne contenir qu'un seul terme β en plus de β0, auquel cas nous parlerions de régression linéaire simple. Avec deux prédicteurs ou plus, tels que β1 et β2 , on parle de régression linéaire multiple. Ces deux types de régression seraient considérés comme des MCO si l'on utilisait un estimateur des moindres carrés ordinaires.
Au cœur de la régression par les MCO se trouve un défi d'optimisation : trouver la ligne (ou l'hyperplan dans les dimensions supérieures) qui correspond le mieux aux données. Mais qu'entend-on par "meilleure adéquation" ? L'expression "meilleur ajustement" signifie ici la minimisation de la somme des carrés des résidus.
Permettez-moi d'essayer d'expliquer le problème de la minimisation tout en expliquant l'idée des résidus.
En minimisant la somme des carrés des résidus, la droite de régression devient une représentation précise de la relation entre les variables indépendantes et dépendantes. En fait, en minimisant la somme des carrés des résidus, notre modèle présente l'erreur globale la plus faible possible dans ses prédictions. Pour en savoir plus sur les résidus et la décomposition de la régression, lisez notre tutoriel, Comprendre la somme des carrés : Un guide pour les SST, SSR et SSE.
Dans le contexte de la régression, les estimateurs sont utilisés pour calculer les coefficients qui décrivent la relation entre les variables indépendantes et la variable dépendante. L'estimateur des moindres carrés ordinaires (MCO) est l'une de ces méthodes. Il trouve les valeurs de coefficient qui minimisent la somme des carrés des différences entre les valeurs observées et celles prédites par le modèle.
Je soulève cette question pour que les termes soient clairs. La régression peut être effectuée avec d'autres estimateurs, chacun offrant des avantages différents en fonction des données et des objectifs de l'analyse. Par exemple, certains estimateurs sont plus robustes aux valeurs aberrantes, tandis que d'autres permettent d'éviter l'ajustement excessif en régularisant les paramètres du modèle.
Pour déterminer les coefficients qui correspondent le mieux au modèle de régression, l'estimateur des MCO utilise des techniques mathématiques pour minimiser la somme des carrés des résidus. L'une des méthodes possibles est l'équation normale, qui fournit une solution directe en établissant un système d'équations basé sur les données et en résolvant les coefficients qui permettent d'obtenir la plus petite somme possible des différences quadratiques entre les valeurs observées et prédites.
Cependant, la résolution de l'équation normale peut s'avérer très exigeante en termes de calcul, en particulier pour les grands ensembles de données. Pour y remédier, une autre technique appelée décomposition QR est souvent utilisée. La décomposition QR décompose la matrice des variables indépendantes en deux matrices plus simples : une matrice orthogonale (Q) et une matrice triangulaire supérieure (R). Cette simplification rend les calculs plus efficaces et améliore la stabilité numérique.
Comment décider d'utiliser la régression par les MCO ? Pour prendre cette décision, nous devons à la fois évaluer les caractéristiques de notre ensemble de données et définir le problème spécifique que nous essayons de résoudre.
Avant d'appliquer la régression par les MCO, nous devons nous assurer que nos données répondent aux hypothèses suivantes afin d'obtenir des résultats fiables :
De graves violations de ces hypothèses peuvent conduire à des estimations biaisées ou à des prédictions peu fiables. C'est pourquoi nous devons vraiment évaluer et résoudre tous les problèmes potentiels avant d'aller plus loin.
Une fois que les hypothèses sont satisfaites, la régression par les MCO peut être utilisée à différentes fins :
Voyons maintenant comment effectuer une régression par les MCO dans R, Python et Excel.
R fournit la fonction lm() pour la régression par les MCO. En voici un exemple :
# Let's create sample data
predictor_variable <- c(1, 2, 3, 4, 5)
response_variable <- c(2, 4, 5, 4, 5)
# We now fit the OLS regression model using the lm() function from base R
ols_regression_model <- lm(response_variable ~ predictor_variable)
# OLS regression model summary
summary(ols_regression_model)Remarquez qu'il n'est pas nécessaire d'importer d'autres paquets pour effectuer une régression par les MCO dans R.
Python propose des bibliothèques telles que statsmodels et scikit-learn pour la régression par les MCO. Prenons un exemple en utilisant statsmodels:
import statsmodels.api as sm
# We can create some sample data
ols_regression_predictor = [1, 2, 3, 4, 5]
ols_regression_response = [2, 4, 5, 4, 5]
# Adding a constant for the intercept
ols_regression_predictor = sm.add_constant(ols_regression_predictor)
# We now fit our OLS regression model
ols_regression_model = sm.OLS(ols_regression_response, ols_regression_predictor).fit()
# Summary of our OLS regression
print(ols_regression_model.summary())Excel permet également d'effectuer une régression par les MCO grâce à ses outils intégrés. Il vous suffit de suivre les étapes suivantes :
Organisez vos données en deux colonnes : une pour la ou les variables indépendantes et une pour la variable dépendante. Assurez-vous qu'il n'y a pas de cellules vides dans votre ensemble de données.
Allez dans Fichier > Options > Compléments. Dans la boîte Gérer, sélectionnez Excel Complémentspuis cliquez sur Cliquez sur. Cochez la case pour Analyse ToolPak et cliquez sur CLIQUEZ SUR OK..
Naviguez vers Données > Analyse des données et sélectionnez Régression dans la liste des options. Cliquez sur CLIQUEZ SUR OK.
Dans la boîte de dialogue Régression:
Nous avons maintenant créé un modèle de régression MCO. L'étape suivante consiste à vérifier son efficacité en examinant les diagnostics et les statistiques du modèle.
Nous pouvons évaluer un modèle de régression par les MCO en utilisant des outils visuels pour évaluer les hypothèses du modèle et la qualité de l'ajustement. Parmi les options, citons legraphique residuals vs. fitted values (valeurs ajustées), qui vérifie les schémas pouvant indiquer une non-linéarité ou une hétéroscédasticité, ou legraphique Q-Q, quivérifie les schémas pouvant indiquer une non-linéarité ou une hétéroscédasticité. graphique Q-Qqui examine si les résidus suivent une distribution comme une distribution normale.
Nous pouvons également évaluer notre modèle à l'aide de mesures statistiques qui donnent un aperçu des performances du modèle et de l'importance des prédicteurs. Les statistiques courantes sur les modèles comprennent le R -squared et le R-squared ajusté. R-carré ajustéqui mmesurent la proportion de variance expliquée par le modèle. Nous pouvons également examiner les statistiques F et les valeurs p, qui testent l'importance globale du modèle et des prédicteurs individuels sur le site .
Enfin, il convient de préciser que les analystes de données aiment également suivre un processus structuré pour valider les capacités prédictives d'un modèle. Cela comprend un processus de division des données, où les données sont divisées en sous-ensembles de formation et de test, un processus de formation pour ajuster le modèle, puis un processus de test pour évaluer la performance du modèle sur des données de test inédites. Ce processus peut également inclure des étapes de validation croisée, comme la validation croisée k-fold.
Maintenant que nous avons exploré les bases de la régression par les MCO, explorons quelques concepts plus avancés.
L'estimation du maximum de vraisemblance (MLE) est un autre concept dont on parle avec la régression par les MCO, et ce pour de bonnes raisons. Jusqu'à présent, nous avons passé du temps à expliquer comment les MCO minimisent la somme des carrés des résidus pour estimer les coefficients. Prenons un peu de recul pour parler du MLE.
L'EMV maximise la probabilité d'observer les données données dans le cadre de notre modèle. Il fonctionne en supposant une distribution de probabilité spécifique pour le terme d'erreur. Cette distribution de probabilité est généralement une distribution normale ou gaussienne. En utilisant notre distribution de probabilité, nous trouvons les valeurs des paramètres qui rendent les données observées les plus probables.
Si j'évoque maintenant l'estimation du maximum de vraisemblance, c'est parce que, dans le contexte de la régression par les MCO, l'approche MLE conduit aux mêmes estimations de coefficients que celles que nous obtenons en minimisant la somme des carrés des erreurs, à condition que les erreurs soient normalement distribuées.
Une autre perspective fascinante de la régression par les MCO est son interprétation en tant que moyenne pondérée. Le professeur Andrew Gelman explique que les coefficients d'une régression par les MCO peuvent être considérés comme une moyenne pondérée des points de données observés, où les poids sont déterminés par la variance des prédicteurs et la structure du modèle.
Ce point de vue permet de comprendre comment fonctionne le processus de régression et pourquoi il se comporte comme il le fait, car La régression par les MCO donne en réalité plus de poids aux observations qui ont moins de variance ou qui sont plus proches des prédictions du modèle. Vous pouvez également tune dans notre épisode du podcast DataFrame, Election Forecasting and Polling, pour entendre ce que dit le professeur Gelman sur l'utilisation de la régression dans les sondages électoraux.
Plusieurs autres méthodes de régression portent des noms qui peuvent sembler similaires, mais ont des objectifs différents ou fonctionnent selon des hypothèses différentes. Jetons un coup d'œil à certains d'entre eux qui ont une consonance similaire :
Les MCO sont une extension des MCO qui attribue des poids différents à chaque point de données en fonction de la variance de leurs observations. Les MCO sont particulièrement utiles lorsque l'hypothèse de variance constante des résidus n'est pas respectée. En pondérant les observations inversement à leur variance, les MCO fournissent des estimations plus fiables lorsqu'ils traitent des données hétéroscédastiques.
La PLS combine les caractéristiques de l'analyse en composantes principales et de la régression multiple en extrayant des variables latentes qui capturent la covariance maximale entre les prédicteurs et la variable réponse. La méthode PLS est avantageuse en cas de multicolinéarité ou lorsque le nombre de prédicteurs est supérieur au nombre d'observations. Elle réduit la dimensionnalité tout en maximisant le pouvoir prédictif, ce que les MCO ne font pas intrinsèquement.
Comme les WLS, les GLS généralisent les MCO en permettant une variance corrélée et/ou non constante des résidus. Les MGS ajustent le processus d'estimation pour tenir compte des violations des hypothèses des MCO concernant les résidus, ce qui permet d'obtenir des estimations plus efficaces et sans biais dans de tels scénarios.
Également connue sous le nom de régression orthogonale, la TLS minimise les distances perpendiculaires entre les points de données et la droite de régression, plutôt que les distances verticales minimisées par les MCO. Les MTT sont utiles lorsqu'il y a des erreurs à la fois dans les variables indépendantes et dépendantes, alors que les MCO supposent que seule la variable dépendante présente une erreur de mesure.
Lorsque la relation entre les variables est complexe ou non linéaire, les méthodes de régression non paramétriques offrent des alternatives flexibles aux MCO en permettant aux données de déterminer la forme de la fonction de régression. Tous les exemples précédents (ceux qui se ressemblent) appartiennent à la catégorie des modèles paramétriques. Mais les modèles non paramétriques peuvent également être utilisés lorsque vous souhaitez modéliser des modèles sans les contraintes des hypothèses paramétriques.
| Méthode | Description | Avantages | Cas d'utilisation courants |
|---|---|---|---|
| Régression du noyau | Utilise des moyennes pondérées avec un noyau pour lisser les données. | Capture des relations non linéaires Lissage flexible |
Analyse exploratoire Relations entre variables inconnues |
| Régression locale | Ajuste des polynômes locaux à des sous-ensembles de données pour une courbe lisse. | Traite les motifs complexes Lissage adaptatif |
Visualisation des tendances Lissage des nuages de points |
| Arbres de régression | Divise les données en branches afin d'adapter des modèles simples à chaque segment. | Facile à interpréter Gère les interactions |
Segmenter les données Identifier des régimes de données distincts |
| Régression spline | Utilise des polynômes par morceaux avec continuité aux nœuds pour modéliser les données. | Modélisation de tendances non linéaires lisses Ajustement flexible |
Séries chronologiques Courbes de croissance |
La régression MCO est un outil fondamental pour comprendre les relations entre les données et faire des prédictions. En maîtrisant les MCO, vous construirez une base solide pour explorer des modèles et des techniques avancés. Explorez les cours de DataCamp sur la régression dans R et Python pour élargir vos compétences : Introduction à la régression avec statsmodels en Python et Introduction à la régression en R). Pensez également à notre très populaire cursus de carrière de scientifique en apprentissage automatique en Python.
Apprenez la régression par les MCO avec DataCamp
Cours
Cours
Cours
blog
Kurtis Pykes
15 min
Tutoriel
Aditya Sharma
Tutoriel
Stephen Gruppetta
Tutoriel
DataCamp Team
Tutoriel
Laiba Siddiqui
Tutoriel

