
Corso
Modellazione di regressione bayesiana con rstanarm
4 h
7.1K
La regressione OLS (ordinary least squares) vale davvero la pena di essere imparata perché è una parte enorme della statistica e del machine learning. Si usa per prevedere risultati o analizzare le relazioni tra variabili, e le applicazioni di questi due usi includono tutto, dai test d'ipotesi alle previsioni.
In questo articolo, ti aiuterò a capire i fondamenti della regressione OLS, le sue applicazioni, le assunzioni e come può essere implementata in Excel, R e Python. C'è molto da imparare, quindi quando avrai finito, segui i nostri corsi dedicati alla regressione come Introduzione alla regressione in Python e Introduzione alla regressione in R, e leggi i nostri tutorial, come Regressione lineare in Excel.
La regressione OLS stima la relazione tra una o più variabili indipendenti (predittori) e una variabile dipendente (risposta). Lo fa adattando un'equazione lineare ai dati osservati. Ecco come appare quell'equazione:
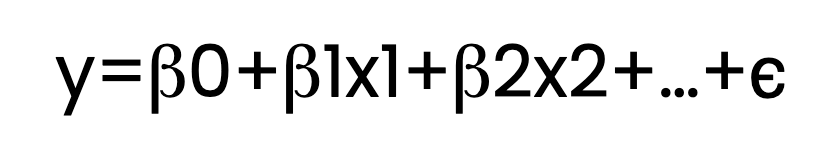
Qui:
Nell'equazione sopra mostro più termini β, come β1 e β2. Ma, per chiarezza, l'equazione di regressione potrebbe contenere un solo termine β oltre a β0; in tal caso la chiameremmo regressione lineare semplice. Con due o più predittori, come β1 e β2, la chiameremmo regressione lineare multipla. Entrambe rientrano nella regressione OLS se si usa un estimatore dei minimi quadrati ordinari.
Al cuore della regressione OLS c'è una sfida di ottimizzazione: trovare la retta (o l'iperpiano in dimensioni superiori) che meglio si adatta ai dati. Ma cosa significa "miglior adattamento"? Qui "miglior adattamento" significa minimizzare la somma dei residui al quadrato.
Provo a spiegare il problema di minimizzazione spiegando anche l'idea dei residui.
Minimizzando la somma dei residui al quadrato, la retta di regressione diventa una rappresentazione accurata della relazione tra variabili indipendenti e dipendente. Infatti, minimizzando la somma dei quadrati dei residui, il nostro modello ha l'errore complessivo più piccolo possibile nelle sue previsioni. Per approfondire residui e scomposizione della regressione, leggi il nostro tutorial Understanding Sum of Squares: A Guide to SST, SSR, and SSE.
Nel contesto della regressione, gli estimator vengono usati per calcolare i coefficienti che descrivono la relazione tra le variabili indipendenti e la variabile dipendente. L'estimatore dei minimi quadrati ordinari (OLS) è uno di questi metodi. Trova i valori dei coefficienti che minimizzano la somma delle differenze al quadrato tra i valori osservati e quelli previsti dal modello.
Ne parlo per chiarire i termini. La regressione può essere eseguita con altri estimator, ognuno con vantaggi diversi a seconda dei dati e degli obiettivi dell'analisi. Per esempio, alcuni estimator sono più robusti ai valori anomali, mentre altri aiutano a prevenire l'overfitting regolarizzando i parametri del modello.
Per determinare i coefficienti che meglio adattano il modello di regressione, l'estimatore OLS impiega tecniche matematiche per minimizzare la somma dei residui al quadrato. Un possibile metodo è l'equazione normale, che fornisce una soluzione diretta impostando un sistema di equazioni basato sui dati e risolvendo per i coefficienti che ottengono la somma più piccola possibile delle differenze al quadrato tra valori osservati e previsti.
Tuttavia, risolvere l'equazione normale può diventare oneroso dal punto di vista computazionale, soprattutto con dataset di grandi dimensioni. Per ovviare a ciò, si usa spesso un'altra tecnica chiamata decomposizione QR. La decomposizione QR scompone la matrice delle variabili indipendenti in due matrici più semplici: una matrice ortogonale (Q) e una matrice triangolare superiore (R). Questa semplificazione rende i calcoli più efficienti e migliora anche la stabilità numerica.
Come decidiamo di usare la regressione OLS? In quella decisione dobbiamo sia valutare le caratteristiche del nostro dataset sia definire il problema specifico che stiamo cercando di risolvere.
Prima di applicare la regressione OLS, dovremmo assicurarci che i nostri dati soddisfino le seguenti assunzioni così da ottenere risultati affidabili:
Violazioni gravi di queste assunzioni possono portare a stime distorte o previsioni inaffidabili. Quindi, dobbiamo davvero valutare e affrontare eventuali problemi prima di procedere.
Una volta soddisfatte le assunzioni, la regressione OLS può essere usata per diversi scopi:
Vediamo ora come eseguire una regressione OLS in R, Python ed Excel.
R fornisce la funzione lm() per la regressione OLS. Ecco un esempio:
# Let's create sample data
predictor_variable <- c(1, 2, 3, 4, 5)
response_variable <- c(2, 4, 5, 4, 5)
# We now fit the OLS regression model using the lm() function from base R
ols_regression_model <- lm(response_variable ~ predictor_variable)
# OLS regression model summary
summary(ols_regression_model)Nota come non dobbiamo importare alcun pacchetto aggiuntivo per eseguire la regressione OLS in R.
Python offre librerie come statsmodels e scikit-learn per la regressione OLS. Proviamo un esempio usando statsmodels:
import statsmodels.api as sm
# We can create some sample data
ols_regression_predictor = [1, 2, 3, 4, 5]
ols_regression_response = [2, 4, 5, 4, 5]
# Adding a constant for the intercept
ols_regression_predictor = sm.add_constant(ols_regression_predictor)
# We now fit our OLS regression model
ols_regression_model = sm.OLS(ols_regression_response, ols_regression_predictor).fit()
# Summary of our OLS regression
print(ols_regression_model.summary())Anche Excel offre un modo per eseguire la regressione OLS tramite i suoi strumenti integrati. Segui questi passaggi:
Organizza i dati in due colonne: una per la/le variabile/i indipendente/i e una per la variabile dipendente. Assicurati che non ci siano celle vuote nel dataset.
Vai su File > Opzioni > Componenti aggiuntivi. Nel riquadro Gestisci, seleziona Componenti aggiuntivi di Excel, quindi fai clic su Vai. Spunta la casella Strumenti di analisi e fai clic su OK.
Vai su Dati > Analisi dati e seleziona Regressione dall'elenco delle opzioni. Fai clic su OK.
Nella finestra di dialogo Regressione:
Abbiamo ora creato un modello di regressione OLS. Il passo successivo è verificarne l'efficacia osservando le diagnostiche e le statistiche del modello.
Possiamo valutare un modello OLS usando strumenti visivi per verificare le assunzioni del modello e la qualità dell'adattamento. Alcune opzioni includono il grafico residui vs. valori adattati, che controlla pattern che potrebbero indicare non linearità o eteroschedasticità, oppure il Q-Q plot, che esamina se i residui seguono una distribuzione come la distribuzione normale.
Possiamo anche valutare il modello con metriche statistiche che offrono informazioni sulle prestazioni del modello e sulla significatività dei predittori. Le statistiche comuni includono R-quadrato e R-quadrato aggiustato, che misurano la quota di varianza spiegata dal modello. Possiamo anche guardare le F-statistic e i p-value, che testano la significatività complessiva del modello e dei singoli predittori.
Infine, va detto che gli analisti dei dati seguono spesso un processo strutturato per convalidare le capacità predittive di un modello. Questo include uno split dei dati, in cui i dati sono divisi in sottoinsiemi di training e di test, un processo di training per adattare il modello e poi un test per valutare le prestazioni su dati di test non visti. Questo processo può includere anche passaggi di cross-validation come la k-fold cross-validation.
Ora che abbiamo esplorato le basi della regressione OLS, vediamo alcuni concetti più avanzati.
La stima di massima verosimiglianza (MLE) è un altro concetto spesso citato insieme alla regressione OLS, e a ragione. Finora abbiamo parlato di come l'OLS minimizzi la somma dei residui al quadrato per stimare i coefficienti. Facciamo ora un passo indietro per parlare della MLE.
La MLE massimizza la probabilità di osservare i dati forniti dal nostro modello. Funziona assumendo una distribuzione di probabilità specifica per il termine di errore. Questa distribuzione è solitamente una distribuzione normale, o gaussiana. Usando la nostra distribuzione di probabilità, troviamo i valori dei parametri che rendono i dati osservati più probabili.
Il motivo per cui cito ora la stima di massima verosimiglianza è che, nel contesto della regressione OLS, l'approccio MLE porta alle stesse stime dei coefficienti che otteniamo minimizzando la somma degli errori al quadrato, a patto che gli errori siano distribuiti normalmente.
Un'altra prospettiva interessante sulla regressione OLS è la sua interpretazione come media ponderata. Il prof. Andrew Gelman discute l'idea che i coefficienti in una regressione OLS possano essere visti come una media ponderata dei punti dati osservati, dove i pesi sono determinati dalla varianza dei predittori e dalla struttura del modello.
Questa visione offre qualche intuizione su come funziona il processo di regressione e perché si comporta in quel modo, perché la regressione OLS, in realtà, dà più peso alle osservazioni che hanno meno varianza o che sono più vicine alle previsioni del modello. Puoi anche sintonizzarti sul nostro episodio del podcast DataFramed, Election Forecasting and Polling, per ascoltare cosa dice il professor Gelman sull'uso della regressione nei sondaggi elettorali.
Diversi altri metodi di regressione hanno nomi che possono suonare simili ma servono a scopi diversi o operano sotto assunzioni differenti. Diamo un'occhiata ad alcuni di quelli dal nome simile:
La WLS è un'estensione dell'OLS che assegna pesi diversi a ciascun punto dati in base alla varianza delle loro osservazioni. La WLS è particolarmente utile quando l'assunzione di varianza costante dei residui è violata. Ponderando le osservazioni in modo inverso rispetto alla loro varianza, la WLS fornisce stime più affidabili quando si lavora con dati eteroschedastici.
La PLS combina caratteristiche dell'analisi delle componenti principali e della regressione multipla estraendo variabili latenti che catturano la massima covarianza tra predittori e variabile risposta. La PLS è vantaggiosa in situazioni con multicollinearità o quando il numero di predittori supera il numero di osservazioni. Riduce la dimensionalità massimizzando al contempo il potere predittivo, cosa che l'OLS non affronta intrinsecamente.
Simile alla WLS, la GLS generalizza l'OLS consentendo varianze dei residui correlate e/o non costanti. La GLS adegua il processo di stima per tenere conto delle violazioni delle assunzioni OLS riguardo ai residui, fornendo stime più efficienti e non distorte in tali scenari.
Conosciuta anche come regressione ortogonale, la TLS minimizza le distanze perpendicolari dai punti dati alla retta di regressione, piuttosto che le distanze verticali minimizzate dall'OLS. La TLS è utile quando c'è errore sia nelle variabili indipendenti sia in quella dipendente, mentre l'OLS assume che solo la variabile dipendente abbia errori di misurazione.
Quando la relazione tra variabili è complessa o non lineare, i metodi di regressione non parametrici offrono alternative flessibili all'OLS consentendo ai dati di determinare la forma della funzione di regressione. Tutti gli esempi precedenti (quelli dal "nome simile") appartengono alla categoria dei modelli parametrici. Ma i modelli non parametrici possono essere usati anche quando vuoi modellare pattern senza i vincoli delle assunzioni parametriche.
| Metodo | Descrizione | Vantaggi | Casi d'uso comuni |
|---|---|---|---|
| Regressione kernel | Usa medie ponderate con un kernel per levigare i dati. | Cattura relazioni non lineari Levigatura flessibile |
Analisi esplorativa Relazioni tra variabili sconosciute |
| Regressione locale | Adatta polinomi locali a sottoinsiemi di dati per una curva levigata. | Gestisce pattern complessi Levigatura adattiva |
Visualizzazione dei trend Smoothing degli scatterplot |
| Alberi di regressione | Divide i dati in rami per adattare modelli semplici in ciascun segmento. | Facili da interpretare Gestiscono le interazioni |
Segmentazione dei dati Identificazione di regimi di dati distinti |
| Regressione spline | Usa polinomi a tratti con continuità nei nodi per modellare i dati. | Modella trend non lineari e regolari Adattamento flessibile |
Serie temporali Curve di crescita |
La regressione OLS è uno strumento fondamentale per comprendere le relazioni nei dati e fare previsioni. Padroneggiando l'OLS, costruirai basi solide per esplorare modelli e tecniche avanzate. Esplora i corsi di DataCamp sulla regressione in R e Python per ampliare le tue competenze: Introduction to Regression with statsmodels in Python e Introduction to Regression in R). Considera anche il nostro gettonatissimo percorso professionale Machine Learning Scientist in Python.
Impara la regressione OLS con DataCamp
Corso
Corso
Corso
blog
Tim Lu
12 min
blog
Abid Ali Awan
10 min
blog
Abid Ali Awan
15 min

