
t.test() functie in R
De R-taal biedt ons een eenvoudige t.test ingebouwde functie voor éénsteekproef-, tweesteekproef- en gepaarde t-toetsen.
Er zijn twee manieren om de t.test-functie te gebruiken: de standaard- en de formulamethode.
Standaardmethode
Je geeft numerieke steekproeven op van de x-groep en de y-groep, waarbij je de alternative hypothese, de veronderstelde gemiddelde mu en het betrouwbaarheidsniveau van het interval specificeert. Bovendien kun je een gepaarde t-toets uitvoeren door het argument paired in te schakelen en een tweesteekproef t-toets met gelijke variantie door het argument var.equal te wijzigen.
t.test(x, y,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, ...)Formulamethode
Bij deze methode geef je de formule x~y op, waarbij x een numerieke vector of een kolom uit de data is, en y een binaire kolom met de typen groepen.
t.test(formula, data, subset, na.action, ...)Hoe voer je een éénsteekproef t-toets uit in R
De éénsteekproef t-toets is de statistische hypothese om te testen of er een significant verschil is tussen het steekproefgemiddelde en het hypothese- of veronderstelde populatiegemiddelde. De toets vergelijkt het steekproefgemiddelde met het hypothesegemiddelde, waarbij rekening wordt gehouden met de variabiliteit in de data.
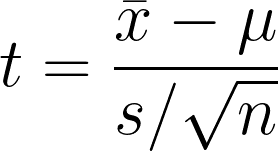
- x̄1 = Steekproefgemiddelde
- μ = Verondersteld populatiegemiddelde
- s = Steekproefstandaarddeviatie
- n = Steekproefgrootte
In deze tutorial gebruiken we de R-dataset Carbon Dioxide Uptake in Grass Plants voor codevoorbeelden van t-toetsen. De dataset heeft 84 rijen en 5 kolommen en is verzameld uit een experiment om de kouditolerantie van de grassoort Echinochloa crus-galli te testen. We zullen vooral de kolommen uptake, Treatment en Type gebruiken voor onze toetsen.
head(CO2)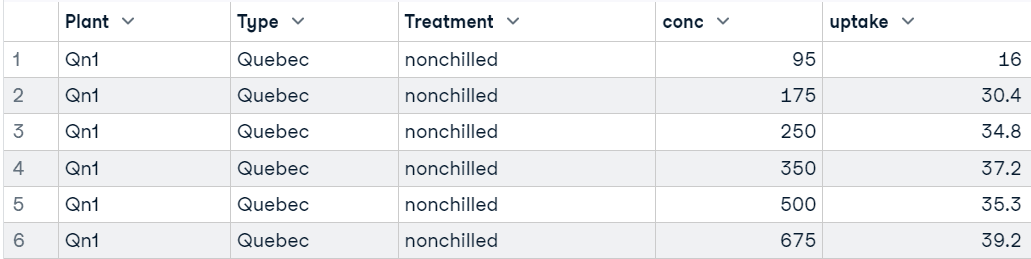
In het voorbeeld gebruiken we de kolom conc (kooldioxideconcentraties) uit de dataset.
We kunnen het gemiddelde, de verdeling en uitschieters bekijken met een boxplot.
boxplot(CO2$conc)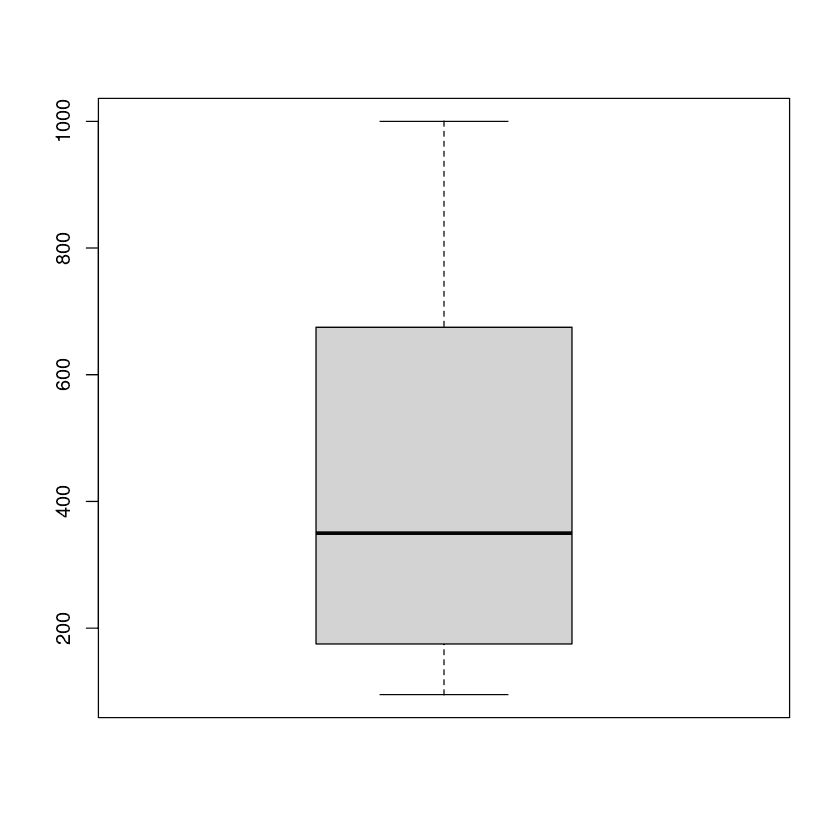
Voor een éénsteekproef t-toets gebruiken we `t.test(x,mu=0)`. Waarbij x de variabele is en mu is ingesteld door de nulhypothese. In ons geval is dat 550.
t.test(CO2$conc, mu = 550)Resultaat:
De concentratie kooldioxide is niet gelijk aan 550 en significant lager dan het veronderstelde populatiegemiddelde.
One Sample t-test
data: CO2$conc
t = -3.5617, df = 83, p-value = 0.0006134
alternative hypothesis: true mean is not equal to 550
95 percent confidence interval:
370.7805 499.2195
sample estimates:
mean of x
435 Hoe voer je een tweesteekproef t-toets uit in R
Bij de tweesteekproef t-toetsen vergelijken we de opnamesnelheden van kooldioxide van twee behandelingssoorten: niet gekoeld en gekoeld.
We kunnen de verdeling van de twee groepen visualiseren met een boxplot.
plot(uptake ~ Treatment, data=CO2)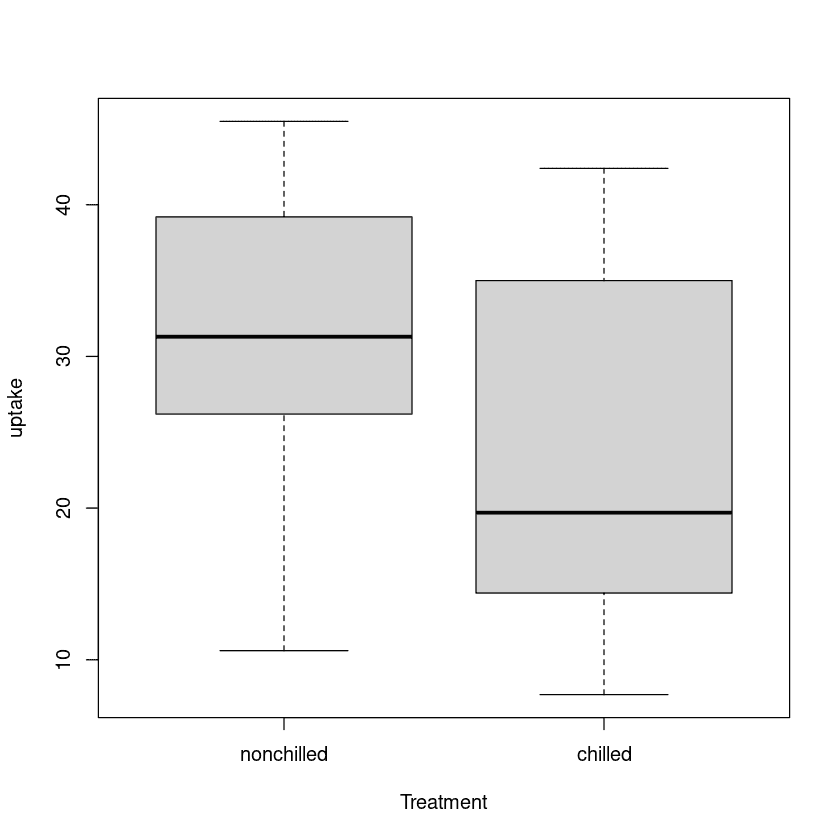
Welch tweesteekproef t-toets
Dit is een statistische hypothesetoets die onderzoekt of er een significant verschil is tussen het gemiddelde van twee onafhankelijke groepen die mogelijk ongelijke varianties hebben. De toets vergelijkt de gemiddelden van twee groepen, rekening houdend met de variabiliteit binnen elke groep.
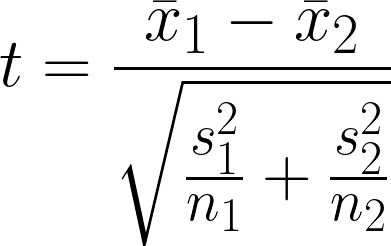
- x̄1 = Steekproefgemiddelde van de eerste groep
- x̄2 = Steekproefgemiddelde van de tweede groep
- n1 = Steekproefgrootte van de eerste groep
- n2 = Steekproefgrootte van de tweede groep
- s12 = Steekproefvariantie van de eerste groep
- s22 = Steekproefvariantie van de tweede groep
Standaard gaat de functie t.test() ervan uit dat de varianties van de twee groepen ongelijk zijn (var.equal=FALSE). We hoeven dus niets aan te passen.
We gebruiken de formulamethode om t-toetsresultaten te verkrijgen, waarbij uptake een numerieke vector is en Treatment een binaire categoriekolom van de CO2-dataset is.
t.test(uptake ~ Treatment, data = CO2)Resultaat:
Er is een significant verschil in de gemiddelden van de twee groepen, en de niet-gekoelde groep heeft een hogere opname dan de gekoelde groep.
Welch Two Sample t-test
data: uptake by Treatment
t = 3.0485, df = 80.945, p-value = 0.003107
alternative hypothesis: true difference in means between group nonchilled and group chilled is not equal to 0
95 percent confidence interval:
2.382366 11.336682
sample estimates:
mean in group nonchilled mean in group chilled
30.64286 23.78333 Tweesteekproef t-toets met gelijke variantie
De tweesteekproef t-toets is een statistische hypothesetoets om te bepalen of er een significant verschil is tussen het gemiddelde van twee onafhankelijke groepen, onder de aanname dat de varianties van de twee groepen gelijk zijn. De toets vergelijkt de gemiddelden van twee groepen, rekening houdend met de variabiliteit binnen elke groep.
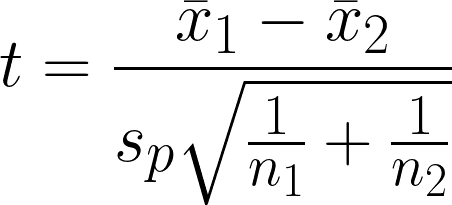
- x̄1 = Steekproefgemiddelde van de eerste groep
- x̄2 = Steekproefgemiddelde van de tweede groep
- n1 = Steekproefgrootte van de eerste groep
- n2 = Steekproefgrootte van de tweede groep
- sp = Gepoolde standaarddeviatie
Om een tweesteekproef t-toets met gelijke variantie uit te voeren, moeten we var.equal op TRUE zetten en de toets opnieuw uitvoeren met dezelfde formule en dataset.
t.test(uptake ~ Treatment, data = CO2, var.equal = TRUE)Resultaat:
Zoals we zien, krijgen we vrijwel dezelfde resultaten: er is een significant gemiddeld verschil tussen de twee groepen.
Two Sample t-test
data: uptake by Treatment
t = 3.0485, df = 82, p-value = 0.003096
alternative hypothesis: true difference in means between group nonchilled and group chilled is not equal to 0
95 percent confidence interval:
2.38324 11.33581
sample estimates:
mean in group nonchilled mean in group chilled
30.64286 23.78333Hoe voer je een gepaarde t-toets uit in R
De gepaarde t-toets is een statistische hypothese die wordt gebruikt om te bepalen of er een significant verschil is tussen de gemiddelden van twee gerelateerde of gepaarde steekproeven. De t-waarde wordt berekend door de verschillen tussen de gepaarde observaties te vergelijken, rekening houdend met de variabiliteit binnen het verschil.
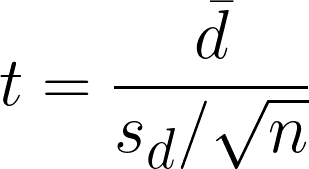
- dࠡ = verschillen van het gemiddelde in gepaarde observaties
- sd = verschillen van standaarddeviatie van de steekproef
- n = aantal paren
Om een gepaarde t-toets in R uit te voeren, moeten we het paired-argument op TRUE zetten en de toets opnieuw uitvoeren met dezelfde formule en dataset.
t.test(uptake ~ Treatment, paired = TRUE, data = CO2)Resultaat:
Er is een statistisch significant verschil tussen de gemiddelden van de twee groepen, gezien de t- en p-waarde.
Paired t-test
data: uptake by Treatment
t = 7.939, df = 41, p-value = 8.051e-10
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
5.114589 8.604458
sample estimates:
mean difference
6.859524 In het tweede voorbeeld betrekken we de opnamesnelheid voor twee typen van dezelfde plant. Eén afkomstig uit Quebec en een andere uit Mississippi.
plot(uptake ~ Type, data=CO2)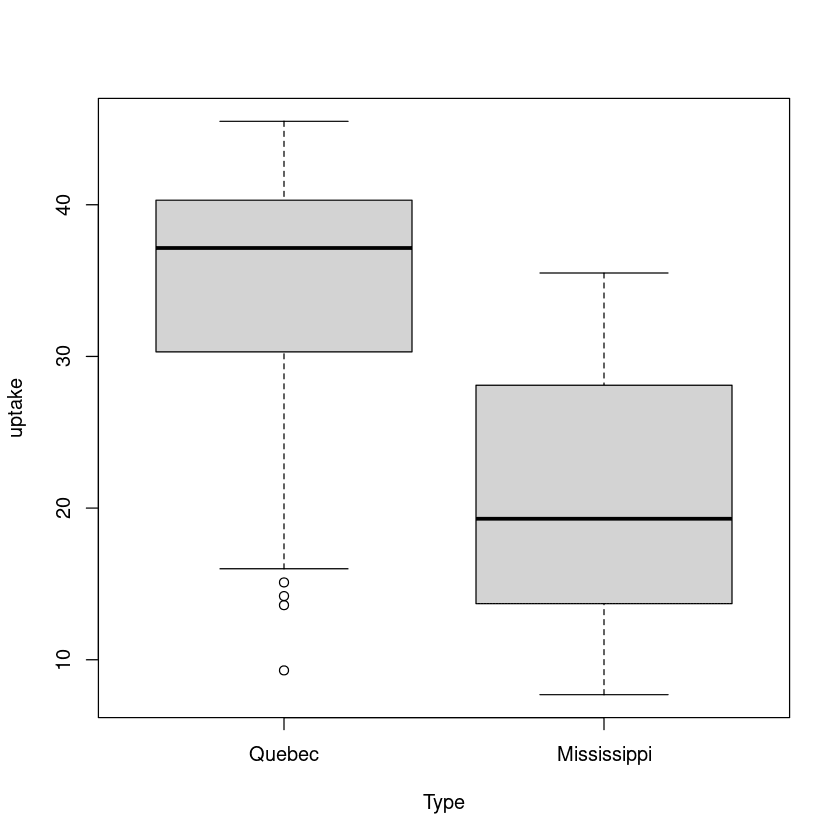
Laten we de resultaten van de gepaarde t-toets bekijken door in de formule Treatment te vervangen door Type.
t.test(uptake ~ Type, paired = TRUE, data = CO2)Resultaat:
Opnieuw is er een significant verschil tussen het gemiddelde van de Quebec- en de Mississippi-groep.
Paired t-test
data: uptake by Type
t = 11.374, df = 41, p-value = 2.937e-14
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
10.41177 14.90727
sample estimates:
mean difference
12.65952 Probeer de t-toets in R DataLab-werkmap. Deze bevat codebronnen en resultaten. Je kunt de werkmap ook dupliceren en beginnen met oefenen op verschillende voorbeelden.
Opmerking: een sterke basis in statistiek is in elke sector waardevol. Statistiek is de ruggengraat van moderne AI, en je kunt je reis starten met de skill track Statistics Fundamentals with R.
Hoe interpreteer je t-toetsresultaten in R
We genereren de resultaten, maar wat betekenen df, p-waarde, alternatieve hypothese of sample estimates? In dit onderdeel leren we hoe je de t-toetsresultaten in R interpreteert.
Laten we beginnen met het maken van twee groepen met de functie rnorm en de tweesteekproef t-toets uitvoeren.
set.seed(125)
group1 <- c(rnorm(100, mean = 24, sd = 3))
group2 <- c(rnorm(100, mean = 43, sd = 2.4))
t.test(group1, group2)Output:
Welch Two Sample t-test
data: group1 and group2
t = -47.765, df = 179.99, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-19.51569 -17.96722
sample estimates:
mean of x mean of y
24.30063 43.04208 - data: de data die in de tweesteekproef t-toets zijn gebruikt (group1 en group2)
- t: t test-statistic. De negatieve t-waarde van -47,765 geeft aan dat het steekproefgemiddelde van group1 significant kleiner is dan dat van group2.
- df: de vrijheidsgraden die horen bij de t-toetswaarde.
- p-value: geeft de statistische significantie van het resultaat aan. De p-waarde is 2,2e-16, wat lager is dan alfa (0,005), wat aangeeft dat de kans om zo’n groot verschil tussen de twee groepen toevallig te verkrijgen zeer klein is.
- alternative hypothesis: we kunnen de alternatieve hypothese instellen. In ons geval was die ingesteld om te controleren of het werkelijke verschil in gemiddelden niet gelijk is aan nul.
- 95 percent confidence interval: 95% zeker dat het ware populatiegemiddelde verschil tussen de twee groepen binnen het bereik van -19,51569 tot -17,96722 ligt.
- sample estimates: geeft de steekproefgemiddelden van elke groep, waarbij group1 en group2 respectievelijk 24,30063 en 43,04208 zijn. Dit betekent dat group2 gemiddeld een hogere waarde heeft dan group1.
Er zijn twee hypothesen voor de t-toets:
- H0: µ1 = µ2: de twee populatiegemiddelden zijn gelijk.
- HA: µ1 ≠µ2: de twee populatiegemiddelden zijn niet gelijk.
Concluderend suggereren de resultaten van de Welch tweesteekproef t-toets dat er sterk bewijs is voor een statistisch significant verschil tussen group1 en group2.
Conclusie
In deze tutorial hebben we geleerd over éénsteekproef-, tweesteekproef- en gepaarde t-toetsen met R-programmeervoorbeelden en hoe je het resultaat interpreteert.
De t-toets is een van de vele statistische tools die in hypothesetoetsing worden gebruikt. Wil je alles leren over hypothesetoetsing, volg dan de interactieve cursus Hypothesis Testing in R. De cursus behandelt t-toetsen, ANOVA, proportietoetsen en chi-kwadraattoetsen.
Je kunt ook een stap verder gaan en je inschrijven voor onze carrièreroute Statistician with R om de essentiële vaardigheden te beheersen en een baan als statisticus te bemachtigen.
