
Funzione t.test() in R
Il linguaggio R fornisce una semplice funzione integrata t.test per i t-test a un campione, a due campioni e per campioni appaiati.
Ci sono due modi di usare la funzione t.test: metodo predefinito e metodo formula.
Metodo predefinito
Fornisci campioni numerici dal gruppo x e dal gruppo y, specificando l’ipotesi alternativa, la media ipotizzata mu e il livello di confidenza dell’intervallo. Inoltre, puoi eseguire il t-test per campioni appaiati attivando l’argomento paired e il t-test a due campioni con varianza uguale modificando l’argomento var.equal.
t.test(x, y,
alternative = c("two.sided", "less", "greater"),
mu = 0, paired = FALSE, var.equal = FALSE,
conf.level = 0.95, ...)Metodo formula
In questo metodo, fornisci la formula x~y, dove x è un vettore numerico o una colonna del data, e y è una colonna binaria contenente i tipi di gruppi.
t.test(formula, data, subset, na.action, ...)Come eseguire un t-test a un campione in R
Il t-test a un campione è l’ipotesi statistica per verificare se c’è una differenza significativa tra la media campionaria e la media ipotizzata o presunta della popolazione. Il test confronta la media del campione con la media ipotizzata, tenendo conto della variabilità nei dati.
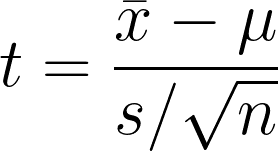
- x̄1 = Media campionaria
- μ = Media ipotizzata della popolazione
- s = Deviazione standard del campione
- n = Dimensione del campione
In questo tutorial useremo il dataset R Carbon Dioxide Uptake in Grass Plants per gli esempi di codice del t-test. Il dataset ha 84 righe e 5 colonne, ed è stato raccolto da un esperimento per testare la tolleranza al freddo della specie erbacea Echinochloa crus-galli. Considereremo principalmente le colonne uptake, Treatment e Type per i nostri test.
head(CO2)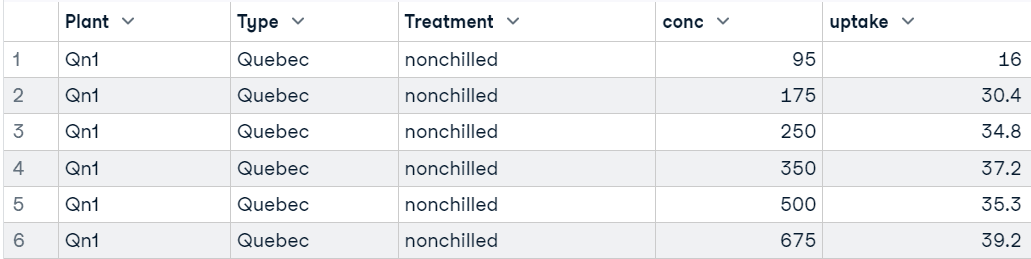
Nell’esempio useremo la colonna conc (concentrazioni di anidride carbonica) del dataset.
Possiamo osservare media, distribuzione e outlier usando un boxplot.
boxplot(CO2$conc)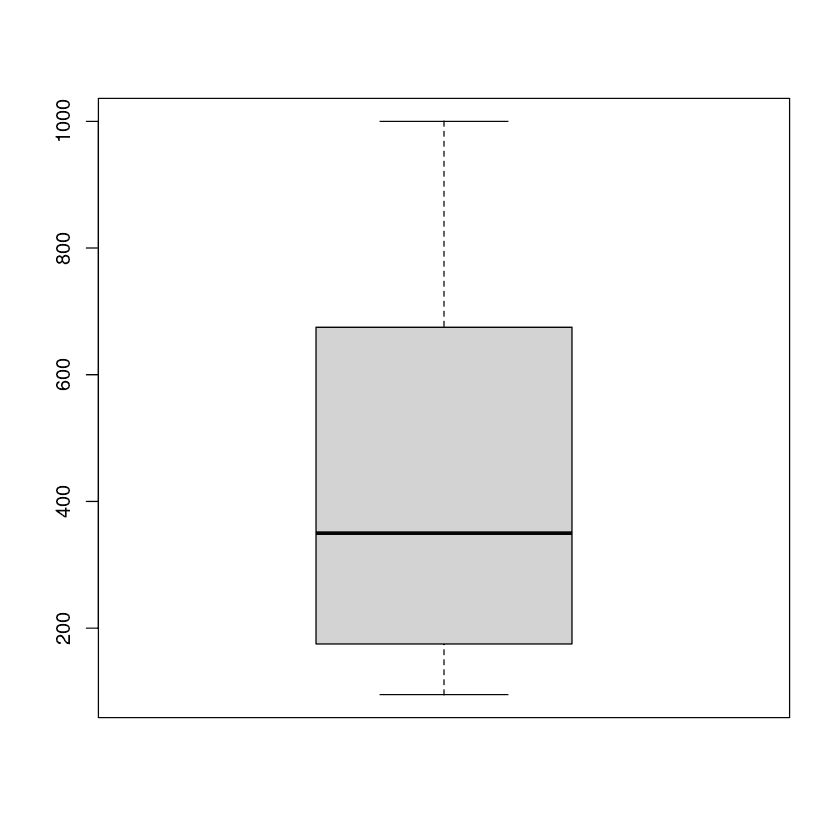
Per un t-test a un campione useremo `t.test(x,mu=0)`. Dove x è la variabile e mu è impostato dall’ipotesi nulla. Nel nostro caso è 550.
t.test(CO2$conc, mu = 550)Risultato:
La concentrazione di anidride carbonica non è uguale a 550 ed è significativamente inferiore alla media ipotizzata della popolazione.
One Sample t-test
data: CO2$conc
t = -3.5617, df = 83, p-value = 0.0006134
alternative hypothesis: true mean is not equal to 550
95 percent confidence interval:
370.7805 499.2195
sample estimates:
mean of x
435 Come eseguire un t-test a due campioni in R
Nei t-test a due campioni, confronteremo i tassi di assorbimento dell’anidride carbonica di due tipi di trattamento: non raffreddato e raffreddato.
Possiamo visualizzare la distribuzione dei due gruppi usando un boxplot.
plot(uptake ~ Treatment, data=CO2)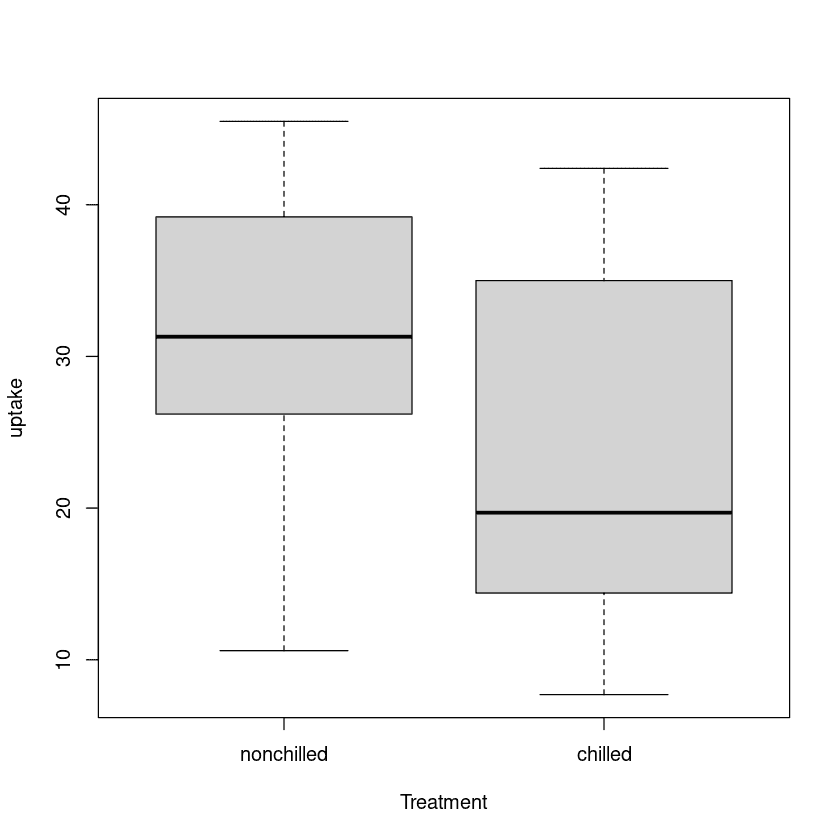
Welch Two Sample t-test
È un’ipotesi statistica che indaga se esiste una differenza significativa tra la media di due gruppi indipendenti che possono avere varianze diverse. Il test confronta le medie di due gruppi tenendo conto della variabilità all’interno di ciascun gruppo.
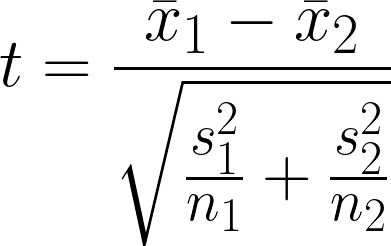
- x̄1 = Media campionaria del primo gruppo
- x̄2 = Media campionaria del secondo gruppo
- n1 = Dimensione campionaria del primo gruppo
- n2 = Dimensione campionaria del secondo gruppo
- s12 = Varianza campionaria del primo gruppo
- s22 = Varianza campionaria del secondo gruppo
Per impostazione predefinita, la funzione t.test() assume che la varianza dei due gruppi non sia uguale (var.equal=FALSE). Quindi, non dobbiamo apportare modifiche.
Usiamo il metodo formula per ottenere i risultati del t-test, dove uptake è un vettore numerico e Treatment è una colonna categorica binaria del dataset CO2.
t.test(uptake ~ Treatment, data = CO2)Risultato:
C’è una differenza significativa tra le medie dei due gruppi e il gruppo nonchilled ha un assorbimento più alto rispetto al gruppo chilled.
Welch Two Sample t-test
data: uptake by Treatment
t = 3.0485, df = 80.945, p-value = 0.003107
alternative hypothesis: true difference in means between group nonchilled and group chilled is not equal to 0
95 percent confidence interval:
2.382366 11.336682
sample estimates:
mean in group nonchilled mean in group chilled
30.64286 23.78333 T-test a due campioni con varianza uguale
Il t-test a due campioni è un test di ipotesi statistica per determinare se c’è una differenza significativa tra la media di due gruppi indipendenti assumendo che la varianza dei due gruppi sia uguale. Il test confronta le medie di due gruppi tenendo conto della variabilità all’interno di ciascun gruppo.
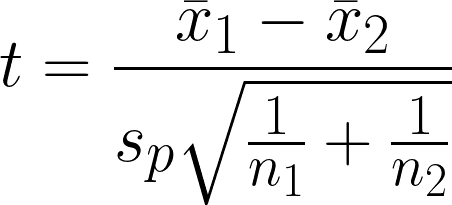
- x̄1 = Media campionaria del primo gruppo
- x̄2 = Media campionaria del secondo gruppo
- n1 = Dimensione campionaria del primo gruppo
- n2 = Dimensione campionaria del secondo gruppo
- sp = Deviazione standard combinata
Per eseguire t-test a due campioni con varianza uguale, dobbiamo impostare var.equal su TRUE ed eseguire nuovamente il test con la stessa formula e lo stesso dataset.
t.test(uptake ~ Treatment, data = CO2, var.equal = TRUE)Risultato:
Come possiamo vedere, abbiamo ottenuto risultati quasi simili: c’è una differenza significativa tra le medie dei due gruppi.
Two Sample t-test
data: uptake by Treatment
t = 3.0485, df = 82, p-value = 0.003096
alternative hypothesis: true difference in means between group nonchilled and group chilled is not equal to 0
95 percent confidence interval:
2.38324 11.33581
sample estimates:
mean in group nonchilled mean in group chilled
30.64286 23.78333Come eseguire un t-test per campioni appaiati in R
Il t-test per campioni appaiati è un’ipotesi statistica usata per determinare se c’è una differenza significativa tra le medie di due campioni correlati o appaiati. Calcola il valore del t-test confrontando le differenze tra le osservazioni appaiate, tenendo conto della variabilità all’interno della differenza.
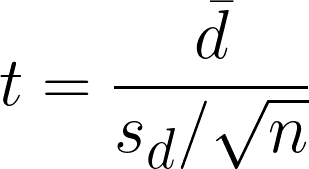
- dࠡ = differenze delle medie nelle osservazioni appaiate
- sd = deviazione standard delle differenze campionarie
- n = numero di coppie
Per eseguire un t-test per campioni appaiati in R, dobbiamo impostare l’argomento paired su TRUE ed eseguire nuovamente il test con la stessa formula e lo stesso dataset.
t.test(uptake ~ Treatment, paired = TRUE, data = CO2)Risultato:
C’è una differenza statisticamente significativa tra le medie dei due gruppi, considerando il valore t e il p-value.
Paired t-test
data: uptake by Treatment
t = 7.939, df = 41, p-value = 8.051e-10
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
5.114589 8.604458
sample estimates:
mean difference
6.859524 Nel secondo esempio, considereremo il tasso di assorbimento per due tipi della stessa pianta. Una originaria del Quebec e un’altra del Mississippi.
plot(uptake ~ Type, data=CO2)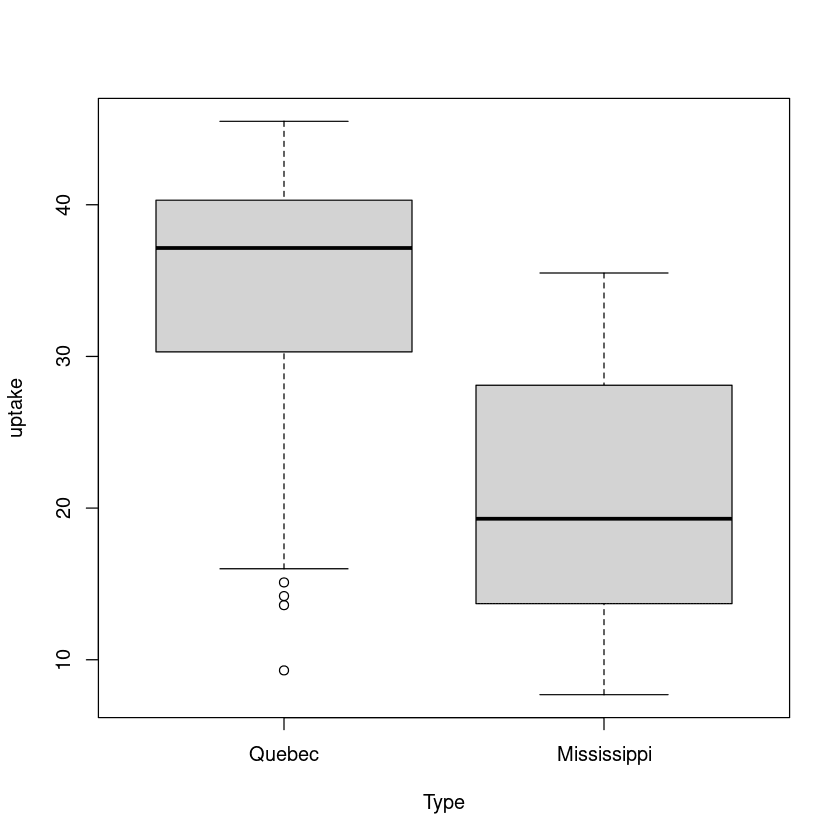
Vediamo i risultati del t-test per campioni appaiati sostituendo Treatment con Type nella formula.
t.test(uptake ~ Type, paired = TRUE, data = CO2)Risultato:
Anche in questo caso c’è una differenza significativa tra la media del gruppo Quebec e quella del gruppo Mississippi.
Paired t-test
data: uptake by Type
t = 11.374, df = 41, p-value = 2.937e-14
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
10.41177 14.90727
sample estimates:
mean difference
12.65952 Prova il t-test in R DataLab Workbook. Include sorgenti di codice e risultati. Puoi anche duplicare il workbook e iniziare a praticare con esempi diversi.
Nota: avere una solida base di statistica ti sarà utile in qualsiasi settore. La statistica è la spina dorsale dell’IA moderna: inizia il tuo percorso con lo skill track Fondamenti di statistica con R.
Come interpretare i risultati del t-test in R
Stiamo generando i risultati, ma cosa significano df, p-value, ipotesi alternativa o stime campionarie? In questa sezione vedremo come interpretare i risultati del t-test in R.
Iniziamo creando due gruppi usando la funzione rnorm ed eseguiamo i t-test a due campioni.
set.seed(125)
group1 <- c(rnorm(100, mean = 24, sd = 3))
group2 <- c(rnorm(100, mean = 43, sd = 2.4))
t.test(group1, group2)Output:
Welch Two Sample t-test
data: group1 and group2
t = -47.765, df = 179.99, p-value < 2.2e-16
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
-19.51569 -17.96722
sample estimates:
mean of x mean of y
24.30063 43.04208 - data: i dati usati nel t-test a due campioni (group1 e group2)
- t: statistica del t-test. Il valore t negativo di -47.765 indica che la media campionaria di group1 è significativamente più piccola di quella di group2.
- df: i gradi di libertà associati al valore del t-test.
- p-value: indica la significatività statistica del risultato. Il p-value è 2.2e-16, inferiore ad alpha (0,005), indicando che la probabilità di ottenere per caso una differenza così grande tra i due gruppi è molto piccola.
- alternative hypothesis: possiamo impostare l’ipotesi alternativa. Nel nostro caso, era impostata per verificare se la vera differenza tra le medie è diversa da zero.
- 95 percent confidence interval: siamo al 95% fiduciosi che la vera differenza tra le medie di popolazione dei due gruppi cada nell’intervallo -19.51569, -17.96722.
- sample estimates: riporta le medie campionarie di ciascun gruppo, dove group1 e group2 sono rispettivamente 24.30063 e 43.04208. Significa che, in media, group2 ha un valore più alto di group1.
Ci sono due ipotesi per il t-test:
- H0: µ1 = µ2: le due medie di popolazione sono uguali.
- HA: µ1 ≠µ2: le due medie di popolazione non sono uguali.
In conclusione, i risultati del Welch Two Sample t-test suggeriscono che ci sono forti evidenze di una differenza statisticamente significativa tra group1 e group2.
Conclusione
In questo tutorial abbiamo visto i t-test a un campione, a due campioni e per campioni appaiati con esempi in R e come interpretarne i risultati.
Il t-test è uno dei molti strumenti statistici usati nei test di ipotesi; se vuoi imparare tutto sul tema, segui il corso interattivo Hypothesis Testing in R. Il corso copre t-test, ANOVA, test sulle proporzioni e test chi-quadro.
Puoi anche spingerti oltre e iscriverti al nostro career track Statistician with R per padroneggiare le competenze essenziali e trovare lavoro come statistico.

