Track
Podstawy agentów AI
6 godz.
Google właśnie udostępniło drugą iterację modelu do generowania obrazów, Nano Banana 2. Gdy Nano Banana pojawił się po raz pierwszy, zrobił furorę, szybko stając się najlepszym i najszybszym modelem AI do generowania obrazów.
W tym artykule szczegółowo omawiamy nowy model, jego funkcje oraz to, jak używać go przez API w Pythonie.
Jeśli ogólnie interesuje Pana/Panią generowanie obrazów, polecam nasze przewodniki po następujących modelach:
Nano Banana 2, znany także jako Gemini 3.1 Flash Image, to najnowszy, zaawansowany model AI Google DeepMind do generowania i edycji obrazów. Łączy rozległą wiedzę o świecie, jakość i rozumowanie Nano Banana Pro z błyskawiczną szybkością Gemini Flash, umożliwiając tworzenie obrazów o wysokiej wierności i szybkie iteracje w tym samym procesie.
Oto przegląd najważniejszych funkcji Nano Banana 2:
Jeśli Nano Banana jest dla Pana/Pani nowością, warto najpierw przeczytać nasz wcześniejszy artykuł o pierwszej iteracji Nano Banana Pro.
W tym artykule omawiamy, jak korzystać z Nano Banana 2 przez ich API w Pythonie. Nowe modele są jednak dostępne w całym ekosystemie Gemini:
W tym artykule używamy Nano Banana 2 poprzez API, więc nie potrzebujemy abonamentu, a płacimy za każdy wygenerowany obraz.
Uznałem/am, że oficjalna tabela cen jest nieco trudna w interpretacji. Zwykle modele generujące obrazy podają stałą cenę za obraz.
Aby to uprościć, przygotowałem/am wyliczenia szacujące przewidywaną cenę w zależności od rozmiaru obrazu. Pamiętajmy, że nie są to dokładne ceny i mogą się nieznacznie różnić.
|
Rozmiar obrazu |
Koszt za obraz |
|
512px |
$0.045 |
|
1024px (1K) |
$0.067 |
|
2048px (2K) |
$0.101 |
|
4096px (4K) |
$0.151 |
Nano Banana 2 potrafi wykonywać wyszukiwania w sieci, aby generować dokładniejsze wyniki. To bardzo przydatna funkcja, ale wpływa też na cenę, ponieważ wyszukiwania wiążą się z dodatkowym kosztem.
Pierwsze 5000 zapytań Google Search miesięcznie jest bezpłatne przy użyciu uziemiania przez Google Search. Potem koszt wynosi $14 za 1000 zapytań Google Search.
Przejdźmy do rzeczy i zacznijmy pracę z Nano Banana 2.
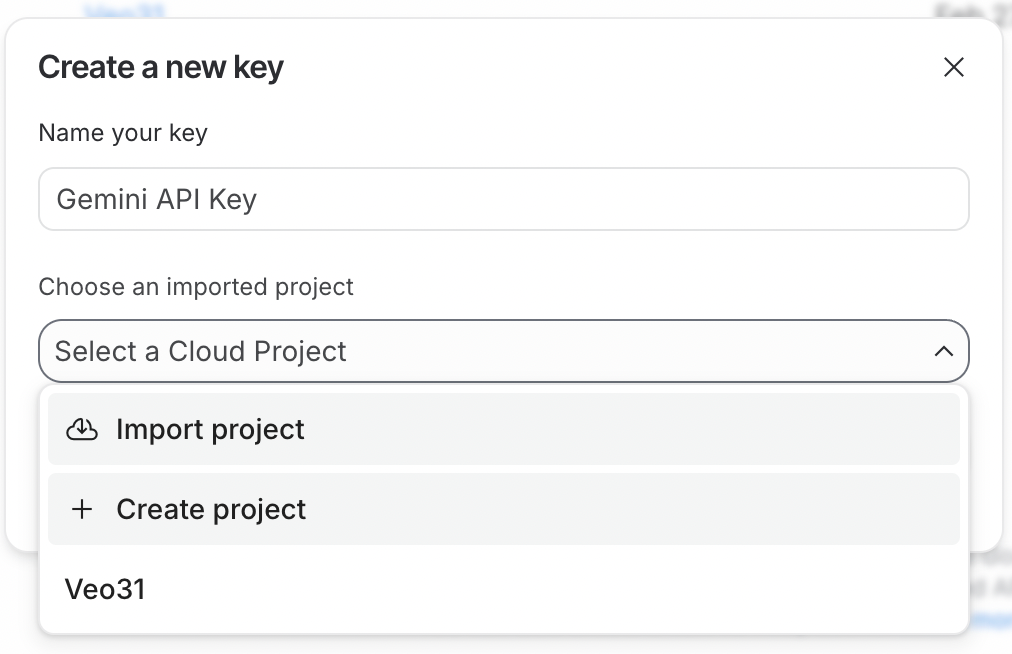
Aby korzystać z API, najpierw musimy wygenerować klucz API. W tym celu proszę zalogować się do Google AI Studio. Następnie kliknąć przycisk Create API Key w prawym górnym rogu.
Klucz API musi być powiązany z projektem Google Cloud. Google AI Studio ułatwia to, pozwalając utworzyć projekt bezpośrednio w procesie generowania klucza API.
Aby używać klucza API, w powiązanym projekcie Google Cloud musi być włączone rozliczanie. Jeśli właśnie utworzył/a Pan/Pani nowy projekt, należy je włączyć, klikając przycisk Set up billing obok klucza API.

Na koniec proszę skopiować klucz API i wkleić go do pliku o nazwie .env w następującym formacie:
GEMINI_API_KEY=<paste_key_here>Ten plik .env należy utworzyć w tym samym folderze, w którym będziemy pisać skrypty w Pythonie.
Następnie musimy zainstalować zależności Pythona wymagane do komunikacji z Gemini API. W tym celu proszę uruchomić następujące polecenie:
pip install google-genai python-dotenv pillowTo polecenie instaluje następujące pakiety:
google-genai: Oficjalny pakiet Google do generatywnej AI. Ułatwia tworzenie klienta do komunikacji z Gemini API.
python-dotenv: Narzędzie do wczytywania klucza API z pliku .env.
pillow: Biblioteka obrazów ułatwiająca wczytywanie obrazów przekazywanych jako wejście do Nano Banana 2.
Oto kompletny kod w Pythonie do wygenerowania obrazu:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Lego version of the empire state building being built.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Oto wynik:

W powyższym żądaniu określiliśmy proporcje obrazu parametrem aspect_ratio oraz rozdzielczość parametrem image_size.
Nano Banana 2 obsługuje szeroki zakres proporcji i rozdzielczości od 512 pikseli do 4K. Oto pełna lista obsługiwanych wartości:
aspect_ratio: "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
image_size (rozdzielczość): "512px", "1K", "2K", "4K"
Skoro mamy już wszystko skonfigurowane i pomyślnie stworzyliśmy pierwszy obraz, czas przetestować reklamowane funkcje.
Możemy przekazać obrazy do modelu, ładując je za pomocą PIL (z pakietu pillow) i dołączając je do listy contents.
Jedną z głównych funkcji Nano Banana 2 jest zdolność do zachowania postaci podczas generowania obrazów. Przy próbach z innymi modelami, jak poprzednia iteracja Nano Banana czy GPT-Image, często zauważałem/am, że trudniej było tworzyć obrazy na podstawie rzeczywistych postaci, bo model miał tendencję do zmieniania ich wyglądu.
Z dokumentacji wynika, że model obsługuje do pięciu postaci i 10 obiektów, łącznie 14 odniesień. Nie definiują dokładnie postaci i obiektów, ale intuicyjnie oznacza to, że model został wytrenowany do generowania scen z maksymalnie 4 głównymi postaciami i do 10 drugoplanowymi obiektami, z którymi te postacie wchodzą w interakcję.
Model nie udostępnia jawnych parametrów do przekazywania obrazów postaci i obiektów. Zamiast tego robi się to w promptach. Przejrzałem/am kod źródłowy niektórych ich demonstracji, aby zrozumieć, jak strukturyzują prompt odwołujący się do tych elementów.
Znaleziony przeze mnie szablon był następujący:
<subject_name> (<Character #number>) = Image <#index>Na przykład, dla dwóch postaci o imionach „Alice” i „Bob” wyglądałoby to tak:
Subjects: Alice (Character 1) = Image 0, Bob (Character 2) = Image 1Poniżej pełny przykład kodu pokazujący, jak ustawić dwa zwierzaki, psa i kota, razem na zdjęciu.
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
from PIL import Image
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Goldie and Wiskers are posing together.
Subjects: Goldie (Character 1) = Image 0, Wiskers (Character 2) = Image 1
Maintain strict subject consistency for characters.
Adjust the subject composition/pose as appropriate for the scene.
"""
dog = Image.open("dog.png")
cat = Image.open("cat.png")
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, dog, cat],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")
Jak wspomniano wyżej, ten szablon nie jest częścią oficjalnej dokumentacji. Model prawdopodobnie potrafi zrozumieć każdy element z promptu i obrazów. Jednak przy tworzeniu aplikacji, w której zależy nam na spójnych wynikach, najlepszą praktyką jest możliwie precyzyjne i konsekwentne formułowanie promptów, dlatego polecam korzystanie z tego szablonu.
Ich przykład rozszerza szablon o odniesienia do obiektów, po prostu zastępując „Character” słowem „Object”, aby model wiedział, że obraz odnosi się do obiektu, a nie głównej postaci.
Aby to zademonstrować, sprawmy, by pies miał na sobie konkretne okulary przeciwsłoneczne, a kot – czapkę, przekazując dwa odniesienia do obiektów. Oto prompt, którego użyłem/am:
Goldie and Wiskers are posing together. Goldie is wearing the Glasses, and Wiskers is wearing the Hat.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1, Glasses (Object 1) = Image 3, Hat (Object 2) = Image 4.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Oto wynik:
Nano Banana 2 umożliwia oparcie generowania obrazu na wyszukiwaniu, aby wyniki były dokładniejsze. Jest to szczególnie przydatne przy generowaniu obrazów, które muszą być zgodne z rzeczywistością, np. obrazy lokalizacji lub konkretnego gatunku zwierząt.
Mieszkam na Tajwanie i niedawno odbył się zorganizowany wypad w góry, gdzie organizator użył obrazu wygenerowanego Nano Banana do zobrazowania miejsca. Niestety obraz był zupełnie nietrafiony, a uczestnicy byli rozczarowani, bo wyglądał zupełnie inaczej niż w rzeczywistości.
To wzbudziło moją ciekawość, by sprawdzić, czy Nano Banana 2 sobie z tym poradzi.
Możemy włączyć zarówno wyszukiwanie w sieci, jak i wyszukiwanie obrazów, używając parametru tools w żądaniu generowania.
Oto pełny przykład:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Create an image of the Yinhe Cave (銀河洞) in Taiwan at golden hour.
- Use Image Search to search for an image of the specified place.
- Keep the location and the view as close to the real reference as possible.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(), # Enables web search
image_search=types.ImageSearch() # Enables image search
)
))
]
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Poniżej pokazujemy wyniki. Najpierw prawdziwe zdjęcie z Google Photos, potem obraz wygenerowany przez Nano Banana 2 z użyciem wyszukiwania, a na końcu obraz wygenerowany bez wyszukiwania. Widać, że wyszukiwanie znacznie zwiększa dokładność.

Zespół Gemini zbudował demo o nazwie Window View, które wykorzystuje tę ideę do stworzenia małej aplikacji pokazującej konkretne miejsca za oknem. To dobre pokazanie zdolności modelu do rozumienia rzeczywistego świata.
Skoro model potrafi z dużą precyzją generować rzeczywiste lokalizacje, możemy umieszczać konkretne postaci w realnym świecie.
Spróbujmy umieścić Goldie i Wiskersa w lokalizacji na Tajwanie. Wybrałem/am to miejsce, bo chciałem/am sprawdzić, czy model poradzi sobie z lokalizacjami, które nie są powszechnie znane na świecie.
To był prompt:
Goldie and Wiskers are traveling across the Sanxiantai Arch Bridge in Taiwan.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Proszę zauważyć, że prompt wprost prosi model o wyszukiwanie obrazów. Z mojego doświadczenia wynika, że przy używaniu narzędzi zawsze lepiej jest wyraźnie poprosić model o ich użycie w promptach.
Oto obraz naszych dwóch bohaterów w podróży:

Poszedłem/poszłam o krok dalej i podałem/am nawet lokalizację przez szerokość i długość geograficzną — i zadziałało!
Goldie and Wiskers are at the location with a latitude of 17.0621186 and a longitude of -96.7255102.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.
Nawet jeśli lokalizacja nie odpowiada dokładnie tym współrzędnym, elementy obrazu odpowiadają temu, co widzimy w tym miejscu — co, moim zdaniem, robi duże wrażenie.
Nano Banana 2 udoskonala wcześniejsze modele obrazowania Flash, oferując bardziej spójne i niezawodne renderowanie tekstu.
Tekst może teraz wyglądać równie ostro i poprawnie jak otaczająca grafika. Nano Banana 2 umożliwia też lokalizację bezpośrednio w obrazie, dzięki czemu można tworzyć lub tłumaczyć tekst na wiele języków w generowanym obrazie.
Przetestowałem/am lokalizację, generując plakat dla fikcyjnej marki gogli VR o nazwie „Beyond Reality”. Następnie użyłem/am prostego promptu w stylu:
Change the language of the poster to Japanese.Oto wyniki po zmianie języka tekstu plakatu najpierw na francuski, a potem na japoński:

Co ciekawe, model był na tyle „inteligentny”, by nie tłumaczyć nazwy marki, choć nie było to wskazane w promptach.
Ostatnią funkcją, którą omawiamy, jest tryb konwersacji. Poprzednie przykłady nie są interaktywne. Wysyłamy żądanie do API i otrzymujemy wynik. Jeśli chcemy iterować nad tym wynikiem, musimy zbudować nowe żądanie z tym obrazem i pożądanymi zmianami.
Lepszym sposobem jest użycie trybu czatu. W trybie czatu tworzymy konwersację funkcją client.chats.create(), a następnie wymieniamy wiadomości funkcją client.send_message(). Możemy to wykorzystać do wdrożenia przepływu edycji w czacie:
Oto pełny skrypt implementujący ten przepływ:
from google import genai
from google.genai import types
from dotenv import load_dotenv
from PIL import Image
import time
load_dotenv()
client = genai.Client()
# Initialize the chat session
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
# We keep track of the latest image object to send back as context
latest_image = None
while True:
user_input = input("\nPrompt: ")
if user_input.lower() in ['quit', 'exit', 'q']:
break
# Construct the message content
# If we have a previous image, we include it so the model knows what to edit
content = [user_input]
if latest_image:
content.append(latest_image)
try:
response = chat.send_message(content)
for part in response.parts:
# Handle Text Response
if part.text:
print(f"\nAI: {part.text}")
elif part.inline_data is not None:
image = part.as_image()
filename = f"image_{int(time.time())}.png"
image.save(filename)
print("Saved image", filename)
latest_image = Image.open(filename)
latest_image.show()
except Exception as e:
print(f"An error occurred: {e}")
print("Session ended.")Uruchamiając ten skrypt, możemy iteracyjnie edytować obraz bezpośrednio w terminalu w taki sposób:
Oto wyniki tej interakcji:

Poniższa tabela podkreśla główne różnice między modelami Nano Banana. Jak wspomniano, nowa wersja przynosi istotne ulepszenia w dokładności, spójności i rozdzielczości, działając tylko nieznacznie wolniej niż pierwsza iteracja.

Tabelę faktycznie wygenerowało Nano Banana 2 na podstawie dostarczonych danych.
Choć Nano Banana 2 to nowy standard, Nano Banana Pro pozostaje dostępny dla zadań „Thinking” i specjalistycznych. Warto wybrać Pro, gdy potrzebne są:
Nano Banana 2 to prawdziwy następca, bo znacząco redukuje „dryf” między iteracjami, pozwalając utrwalić wygląd i wiarygodnie przenosić go przez sceny, formaty i języki.
Dzięki silniejszej trwałości postaci, lepszemu przestrzeganiu instrukcji, realizmowi opartemu na wyszukiwaniu i konwersacyjnym edycjom, które dopracowują zamiast rysować od nowa, znacznie łatwiej zachować tożsamość, układ i styl przy eksplorowaniu wariantów.
Renderowanie tekstu na poziomie produkcyjnym pomaga utrzymać spójność elementów marki, a elastyczne proporcje ułatwiają skalowanie kampanii na banery, plakaty i relacje mobilne. Dla zespołów tworzących storyboardy, zdjęcia produktowe czy kreacje wielojęzyczne, model zapewnia powtarzalność bez poświęcania szybkości ani wierności.
Nano Banana 2 zdecydowanie wypełnia lukę między Nano Banana a Nano Banana Pro: pracuje z prędkością zbliżoną do błyskawicznego tempa Flash Nano Banana, a jego możliwości, wierność wizualna, precyzyjne wykonywanie instrukcji, spójność postaci i realizm oparty na wyszukiwaniu często zbliżają się do Nano Banana Pro.
Jeśli chce Pan/Pani dowiedzieć się więcej o koncepcjach stojących za narzędziami takimi jak Nano Banana 2, polecamy nasz kurs Generative AI Concepts.
Kursy AI
Track
course
course