track
Grunderna i AI-agenter
6 timmar
Google har precis släppt andra generationen av bildgenereringsmodellen, Nano Banana 2. När Nano Banana först lanserades tog den världen med storm och blev snabbt den bästa och snabbaste AI‑bildgenereringsmodellen.
I den här artikeln går vi på djupet i deras nya modell, utforskar dess nya funktioner och lär oss hur man använder den via API:et med Python.
Om du är allmänt intresserad av bildgenerering rekommenderar jag att du kollar in våra guider för följande modeller:
Nano Banana 2, även känd som Gemini 3.1 Flash Image, är Google DeepMinds senaste toppmoderna AI‑modell för bildgenerering och redigering. Den förenar den avancerade verklighetskunskapen, kvaliteten och resonemangsförmågan hos Nano Banana Pro med blixtsnabba Gemini Flash, vilket gör högfidelitetsskapande och snabb iteration möjliga i samma arbetsflöde.
Här är en översikt över de viktigaste funktionerna i Nano Banana 2:
Om du är ny till Nano Banana kan du först vilja läsa vår tidigare artikel om första generationen av Nano Banana Pro.
I den här artikeln går vi igenom hur man använder Nano Banana 2 via deras API med Python. De nya modellerna finns dock tillgängliga i hela Gemini‑ekosystemet:
I den här artikeln använder vi Nano Banana 2 med API:et, vilket betyder att vi inte behöver en prenumeration utan istället betalar per bild vi genererar.
Jag tyckte att den officiella prislistan var lite svår att förstå. Vanligtvis anger AI‑bildmodeller bara ett fast pris per bild.
För att göra det enklare gjorde jag beräkningar som uppskattar förväntat pris beroende på bildstorlek. Observera att detta inte är exakta priser eftersom de kan variera något.
|
Bildstorlek |
Kostnad per bild |
|
512px |
$0.045 |
|
1024px (1K) |
$0.067 |
|
2048px (2K) |
$0.101 |
|
4096px (4K) |
$0.151 |
Nano Banana 2 kan utföra webbsökningar för att generera mer exakta resultat. Det här är en riktigt smidig funktion, men den måste också tas med i prissättningen eftersom sökningarna medför en extra kostnad.
De första 5 000 Google‑sökningarna per månad är gratis när du använder grundning med Google Sök. Därefter kostar det $14 per 1 000 Google‑sökningar.
Utan vidare, låt oss komma igång med Nano Banana 2.
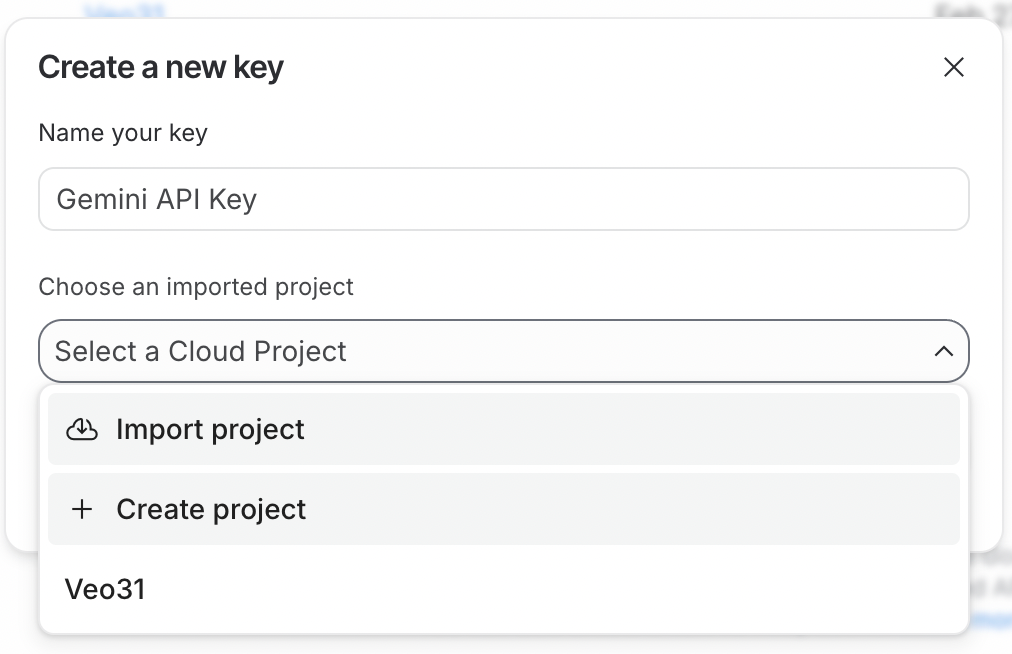
För att använda API:et behöver vi först skapa en API‑nyckel. För att göra det loggar du in på Google AI Studio. Klicka sedan på knappen Create API Key uppe till höger.
API‑nyckeln måste vara kopplad till ett Google Cloud‑projekt. Google AI Studio gör detta enkelt genom att låta oss skapa ett projekt direkt i processen för att generera API‑nyckeln.
För att använda API‑nyckeln måste Google Cloud‑projektet den är kopplad till ha fakturering aktiverad. Om du just skapade ett nytt projekt behöver du aktivera det genom att klicka på knappen Set up billing bredvid API‑nyckeln.

Kopiera slutligen API‑nyckeln och klistra in den i en fil med namnet .env med följande format:
GEMINI_API_KEY=<paste_key_here>Den här .env-filen ska skapas i samma mapp där vi kommer att skriva Python‑skripten.
Därefter behöver vi installera de Python‑beroenden som krävs för att interagera med Gemini API. Kör följande kommando:
pip install google-genai python-dotenv pillowDetta installerar följande paket:
google-genai: Googles officiella paket för generativ AI. Används för att enkelt skapa en klient för att interagera med Gemini API.
python-dotenv: Ett verktygspaket som används för att läsa in API‑nyckeln från .env‑filen.
pillow: Ett bildbibliotek som gör det enkelt att läsa in bilder att ge som input till Nano Banana 2.
Här är den kompletta Python‑koden för att generera en bild:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Lego version of the empire state building being built.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Här är resultatet:

I begäran ovan angav vi bildformat via parametern aspect_ratio och upplösning via parametern image_size.
Nano Banana 2 stöder ett brett spann av bildformat och upplösningar från 512 pixlar till 4K. Här är en komplett lista med stödda värden:
aspect_ratio: "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
image_size (upplösning): "512px", "1K", "2K", "4K"
Nu när vi har satt upp allt och lyckats skapa vår första bild är det dags att sätta de utlovade funktionerna på prov.
Vi kan ge modellen bilder genom att läsa in dem med PIL (installerat via paketet pillow) och inkludera dem i listan contents.
En av huvudfunktionerna i Nano Banana 2 är dess förmåga att bevara motiv när den genererar bilder. När jag testade andra modeller som den tidigare versionen av Nano Banana eller GPT‑Image upplevde jag ofta att det var svårt att generera bilder baserade på verkliga motiv, eftersom modellen tenderade att ändra hur de såg ut.
I dokumentationen nämns att modellen kan stödja upp till fem karaktärer och 10 objekt, totalt 14 referenser. De definierar inte uttryckligen karaktärer och objekt, men intuitivt betyder det att modellen är tränad för att kunna generera scener med upp till 4 huvudmotiv och upp till 10 sekundära objekt som dessa motiv interagerar med.
Modellen erbjuder inte uttryckliga parametrar för att skicka in bilder på karaktärer och objekt. I stället görs detta i prompten. Jag granskade källkoden till några av deras demoprogram för att förstå hur de strukturerar en prompt för att hänvisa till dessa.
Mallen jag hittade var följande:
<subject_name> (<Character #number>) = Image <#index>Till exempel, med två karaktärer vid namn ”Alice” och ”Bob”, blir det:
Subjects: Alice (Character 1) = Image 0, Bob (Character 2) = Image 1Nedan finns ett komplett kodexempel som visar hur man poserar två husdjur, en hund och en katt, tillsammans på ett foto.
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
from PIL import Image
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Goldie and Wiskers are posing together.
Subjects: Goldie (Character 1) = Image 0, Wiskers (Character 2) = Image 1
Maintain strict subject consistency for characters.
Adjust the subject composition/pose as appropriate for the scene.
"""
dog = Image.open("dog.png")
cat = Image.open("cat.png")
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, dog, cat],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")
Som nämnts ovan är den här mallen inte del av den officiella dokumentationen. Modellen kan troligen förstå varje del från prompten och bilderna. Men när man bygger en riktig applikation där vi vill ha konsekventa resultat är det bästa att vara så precis och konsekvent som möjligt i prompten, så jag rekommenderar att använda den här mallen.
Deras exempel utökar mallen till objektreferenser genom att helt enkelt ersätta ”Character” med ”Object” för att låta modellen veta att bilden avser ett objekt och inte huvudmotivet.
För att illustrera detta låter vi hunden bära specifika solglasögon och katten en hatt genom att tillhandahålla två objektreferenser. Detta är prompten jag använde:
Goldie and Wiskers are posing together. Goldie is wearing the Glasses, and Wiskers is wearing the Hat.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1, Glasses (Object 1) = Image 3, Hat (Object 2) = Image 4.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Här är resultatet:
Nano Banana 2 gör det möjligt att grunda bildgenereringen i sökningar så att resultaten blir mer korrekta. Detta är särskilt användbart när man genererar bilder som behöver vara överensstämmande med verkligheten, som bilder av en plats eller en viss djurart.
Jag har bott i Taiwan och nyligen anordnades en vandring där arrangören använde en bild genererad med Nano Banana för att skildra vandringsplatsen. Bilden var dock inte alls korrekt, och folk blev besvikna eftersom den såg helt annorlunda ut än den verkliga.
Detta gjorde mig nyfiken på att testa om Nano Banana 2 kan hantera detta.
Vi kan aktivera både webbsök och bildsök via parametern tools i genereringsbegäran.
Här är ett komplett exempel:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Create an image of the Yinhe Cave (銀河洞) in Taiwan at golden hour.
- Use Image Search to search for an image of the specified place.
- Keep the location and the view as close to the real reference as possible.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(), # Enables web search
image_search=types.ImageSearch() # Enables image search
)
))
]
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Nedan visar vi resultaten. Först den verkliga bilden hämtad från Google Photos, sedan bilden som genererats av Nano Banana 2 med sökning, och slutligen bilden som genererats utan sökning. Vi ser att sökning gör resultaten mycket träffsäkra.

Gemini‑teamet byggde en demo som heter Window View som använder denna idé för att bygga en liten app som visar specifika platser genom ett fönster. Det är en bra demonstration av modellens förmåga att förstå den verkliga världen.
Genom att ge modellen förmågan att generera verkliga platser med hög precision kan vi placera specifika motiv i verkliga miljöer.
Låt oss försöka placera Goldie och Wiskers på en plats i Taiwan. Jag valde den här platsen för att se om modellen kan hantera platser som inte är världskända.
Detta var prompten:
Goldie and Wiskers are traveling across the Sanxiantai Arch Bridge in Taiwan.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Observera att prompten uttryckligen ber modellen att göra en bildsökning. Jag har märkt att när man använder verktyg är det alltid bättre att uttryckligen be modellen att använda dem i prompten.
Här är en bild av våra två karaktärer som reser tillsammans:

För att tänja gränserna provade jag till och med att ange platsen genom att tillhandahålla latitud och longitud, och det fungerade!
Goldie and Wiskers are at the location with a latitude of 17.0621186 and a longitude of -96.7255102.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.
Även om platsen inte är exakt samma latitud och longitud, motsvarar elementen i bilden det vi ser på den platsen, vilket enligt mig är ganska imponerande.
Nano Banana 2 förbättrar tidigare Flash‑baserade bildmodeller genom mer konsekvent och pålitlig textrendering.
Text kan nu framstå lika skarp och korrekt som omgivande grafik. Nano Banana 2 möjliggör även lokalisering i bilden, vilket gör det möjligt att skapa eller översätta text till flera språk direkt i den genererade bilden.
Jag testade lokalisering genom att generera en poster för ett påhittat varumärke för VR‑headset vid namn ”Beyond Reality”. Sedan använde jag helt enkelt en prompt som:
Change the language of the poster to Japanese.Här är resultaten efter att ha ändrat språk i postertexten till franska och sedan till japanska:

Intressant nog var modellen tillräckligt smart för att inte översätta varumärkesnamnet, trots att detta inte angavs i prompten.
Den sista funktionen vi utforskar är konversationsläge. De tidigare exemplen är inte interaktiva. Vi skickar en begäran till API:et och får ett resultat. Om vi vill iterera på det resultatet måste vi bygga en ny begäran med den bilden och de önskade ändringarna.
Ett bättre sätt är att använda chatläge. I chatläge skapar vi en chatt med funktionen client.chats.create() och skickar sedan meddelanden fram och tillbaka med funktionen client.send_message(). Det kan vi använda för att implementera ett chattbaserat redigeringsflöde:
Här är ett komplett skript som implementerar detta flöde:
from google import genai
from google.genai import types
from dotenv import load_dotenv
from PIL import Image
import time
load_dotenv()
client = genai.Client()
# Initialize the chat session
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
# We keep track of the latest image object to send back as context
latest_image = None
while True:
user_input = input("\nPrompt: ")
if user_input.lower() in ['quit', 'exit', 'q']:
break
# Construct the message content
# If we have a previous image, we include it so the model knows what to edit
content = [user_input]
if latest_image:
content.append(latest_image)
try:
response = chat.send_message(content)
for part in response.parts:
# Handle Text Response
if part.text:
print(f"\nAI: {part.text}")
elif part.inline_data is not None:
image = part.as_image()
filename = f"image_{int(time.time())}.png"
image.save(filename)
print("Saved image", filename)
latest_image = Image.open(filename)
latest_image.show()
except Exception as e:
print(f"An error occurred: {e}")
print("Session ended.")När vi kör detta skript kan vi redigera en bild iterativt direkt i terminalen så här:
Här är resultaten från den här interaktionen:

Tabellen nedan lyfter fram de största skillnaderna mellan Nano Banana‑modellerna. Som nämnts tidigare ger den nya versionen betydande förbättringar i noggrannhet, konsekvens och upplösning, samtidigt som den bara är något långsammare än första generationen.

Tabellen genererades faktiskt av Nano Banana 2 genom att den matades med data.
Även om Nano Banana 2 är den nya standarden, finns Nano Banana Pro kvar för ”Thinking” och specialiserade uppgifter. Du kan fortfarande välja Pro för:
Nano Banana 2 känns som en riktig efterträdare eftersom den dramatiskt minskar ”drift” mellan iterationer, så att du kan låsa en look och pålitligt bära den genom scener, format och språk.
Med starkare motivpersistens, tajtare instruktionsefterlevnad, sökgrundad realism och konversationella redigeringar som justerar snarare än ritar om är det mycket lättare att hålla identitet, layout och stil intakta medan du utforskar variationer.
Textrendering i produktionsklass hjälper varumärkeselement att förbli konsekventa, och de flexibla bildformaten gör det sömlöst att skala en kampanj över banners, affischer och mobilstories. För team som bygger storyboard, produktbilder eller flerspråkiga kreativa levererar den repeterbarhet utan att offra hastighet eller trohet.
Nano Banana 2 överbryggar tydligt gapet mellan Nano Banana och Nano Banana Pro: hastigheten ligger i praktiken på Nanos nära‑omedelbara Flash‑tempo, medan kapacitet, visuell trohet, exakt instruktionsefterlevnad, motivkonsekvens och sökgrundad realism ofta ligger nära Nano Banana Pro.
Om du vill lära dig mer om koncepten bakom verktyg som Nano Banana 2 rekommenderar jag vår kurs Generative AI Concepts.
AI‑kurser
track
course
course