
Lernpfad
KI-Agent-Grundlagen
6 Std.
Google hat soeben die zweite Iteration seines Bildgenerierungsmodells, Nano Banana 2, veröffentlicht. Als Nano Banana erstmals erschien, sorgte es weltweit für Aufsehen und wurde schnell zum besten und schnellsten KI‑Bildmodell.
In diesem Artikel tauchen wir tief in das neue Modell ein, sehen uns die neuen Features an und lernen, wie wir es über die API mit Python einsetzen.
Wenn du dich generell für Bildgenerierung interessierst, schau dir auch unsere Guides zu folgenden Modellen an:
Nano Banana 2, auch bekannt als Gemini 3.1 Flash Image, ist das neueste Bildgenerierungs- und ‑bearbeitungsmodell von Google DeepMind. Es vereint das fortgeschrittene Weltwissen, die Qualität und das Reasoning von Nano Banana Pro mit der blitzschnellen Geschwindigkeit von Gemini Flash – so wird hochpräzise Kreation und schnelle Iteration im selben Workflow möglich.
Ein Überblick über die Kernfeatures von Nano Banana 2:
Wenn du neu bei Nano Banana bist, lies zuerst unseren Artikel zur ersten Iteration von Nano Banana Pro.
In diesem Artikel zeigen wir die Nutzung von Nano Banana 2 über die API mit Python. Die neuen Modelle sind allerdings im gesamten Gemini‑Ökosystem verfügbar:
In diesem Artikel nutzen wir Nano Banana 2 über die API. Du brauchst also kein Abo, sondern zahlst pro generiertem Bild.
Die offizielle Preistabelle fand ich etwas schwer zu lesen. Üblicherweise geben KI‑Bildmodelle einen Fixpreis pro Bild an.
Zur Vereinfachung habe ich die erwarteten Kosten je nach Bildgröße überschlagen. Beachte: Das sind Richtwerte, die leicht variieren können.
|
Bildgröße |
Kosten pro Bild |
|
512px |
$0.045 |
|
1024px (1K) |
$0.067 |
|
2048px (2K) |
$0.101 |
|
4096px (4K) |
$0.151 |
Nano Banana 2 kann Websuchen durchführen, um Ergebnisse noch genauer zu machen. Das ist ein starkes Feature, muss aber in die Kosten einberechnet werden, da die Suchen zusätzlich berechnet werden.
Die ersten 5.000 Google‑Suchanfragen pro Monat sind bei Nutzung des Groundings mit Google Search kostenlos. Danach kostet es $14 pro 1.000 Suchanfragen.
Los geht’s mit Nano Banana 2.
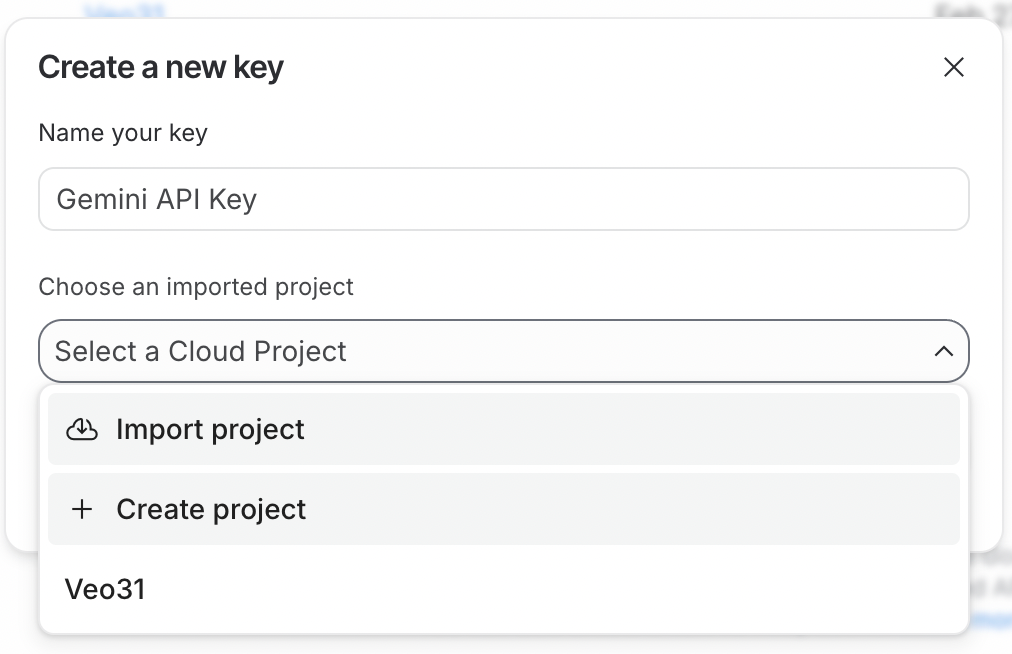
Um die API zu nutzen, brauchen wir zuerst einen API‑Schlüssel. Melde dich dazu bei Google AI Studio an. Klicke dann oben rechts auf Create API Key.
Der API‑Schlüssel muss einem Google‑Cloud‑Projekt zugeordnet sein. Google AI Studio macht es leicht, ein Projekt direkt im Erstellungsprozess anzulegen.
Damit der API‑Schlüssel funktioniert, muss im verknüpften Google‑Cloud‑Projekt die Abrechnung aktiviert sein. Wenn du gerade ein neues Projekt erstellt hast, aktiviere sie über den Button Set up billing neben dem API‑Schlüssel.

Kopiere anschließend den API‑Schlüssel und füge ihn in eine Datei namens .env in folgendem Format ein:
GEMINI_API_KEY=<paste_key_here>Lege die .env-Datei im gleichen Ordner an, in dem wir die Python‑Skripte schreiben.
Als Nächstes installieren wir die Python‑Abhängigkeiten für die Gemini API. Führe dazu folgenden Befehl aus:
pip install google-genai python-dotenv pillowDamit werden folgende Pakete installiert:
google-genai: Das offizielle generative KI‑Paket von Google. Damit erstellst du bequem einen Client für die Gemini API.
python-dotenv: Hilfspaket, um den API‑Schlüssel aus der .env‑Datei zu laden.
pillow: Bildbibliothek, mit der sich Eingabebilder für Nano Banana 2 einfach laden lassen.
Hier ist der vollständige Python‑Code, um ein Bild zu generieren:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Lego version of the empire state building being built.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Das Ergebnis:

In der obigen Anfrage haben wir das Seitenverhältnis über den Parameter aspect_ratio und die Auflösung über image_size festgelegt.
Nano Banana 2 unterstützt viele Seitenverhältnisse und Auflösungen von 512 Pixel bis 4K. Hier ist die vollständige Liste:
aspect_ratio: "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
image_size (Auflösung): "512px", "1K", "2K", "4K"
Nachdem Setup und erstem Bild testen wir nun die beworbenen Features in der Praxis.
Wir können dem Modell Bilder bereitstellen, indem wir sie mit PIL (aus dem Paket pillow) laden und in die contents-Liste aufnehmen.
Eines der Hauptfeatures von Nano Banana 2 ist die Fähigkeit, Motive bei der Bildgenerierung beizubehalten. Bei anderen Modellen wie der vorherigen Iteration von Nano Banana oder GPT-Image war es oft schwierig, reale Subjekte konsistent darzustellen, weil ihr Aussehen verändert wurde.
Laut Doku unterstützt das Modell bis zu fünf Charaktere und zehn Objekte – insgesamt also 14 Referenzen. „Charaktere“ und „Objekte“ sind nicht exakt definiert; intuitiv heißt das: Das Modell kann Szenen mit bis zu vier Hauptmotiven und bis zu zehn sekundären Objekten erzeugen, mit denen diese Motive interagieren.
Es gibt keine speziellen Parameter für Charakter‑ und Objektbilder. Die Zuordnung erfolgt im Prompt. Ich habe mir den Quellcode einiger Demos angesehen, um zu verstehen, wie die Prompts strukturiert sind.
Die Vorlage, die ich gefunden habe, lautet:
<subject_name> (<Character #number>) = Image <#index>Zum Beispiel mit zwei Charakteren „Alice“ und „Bob“:
Subjects: Alice (Character 1) = Image 0, Bob (Character 2) = Image 1Unten ein komplettes Codebeispiel, das zeigt, wie man zwei Haustiere – Hund und Katze – gemeinsam posieren lässt.
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
from PIL import Image
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Goldie and Wiskers are posing together.
Subjects: Goldie (Character 1) = Image 0, Wiskers (Character 2) = Image 1
Maintain strict subject consistency for characters.
Adjust the subject composition/pose as appropriate for the scene.
"""
dog = Image.open("dog.png")
cat = Image.open("cat.png")
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, dog, cat],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")
Wie oben erwähnt, ist diese Vorlage nicht offiziell dokumentiert. Das Modell versteht die Zuordnung meist auch ohne. Für produktive Anwendungen, in denen wir konsistente Ergebnisse brauchen, ist es aber Best Practice, im Prompt präzise und einheitlich zu sein – daher empfehle ich die Vorlage.
Im Beispiel wird die Vorlage für Objektreferenzen erweitert, indem „Character“ durch „Object“ ersetzt wird – so weiß das Modell, dass das Bild ein Objekt und nicht das Hauptmotiv beschreibt.
Als Demo lassen wir den Hund eine bestimmte Sonnenbrille und die Katze einen Hut tragen, indem wir zwei Objektreferenzen angeben. Der Prompt:
Goldie and Wiskers are posing together. Goldie is wearing the Glasses, and Wiskers is wearing the Hat.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1, Glasses (Object 1) = Image 3, Hat (Object 2) = Image 4.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Das Ergebnis:
Nano Banana 2 kann die Generierung auf Suchergebnissen grounden, um realitätsgetreuere Resultate zu liefern. Besonders hilfreich ist das bei Bildern, die mit der Realität übereinstimmen müssen – etwa Orte oder spezifische Tierarten.
Ich lebe in Taiwan. Kürzlich gab es eine organisierte Wanderung, bei der der Veranstalter ein mit Nano Banana erstelltes Bild des Ziels nutzte. Das Bild war jedoch ungenau, und viele waren enttäuscht, weil es vor Ort ganz anders aussah.
Das hat mich neugierig gemacht: Kann Nano Banana 2 das besser?
Wir können Web‑ und Bildsuche über den Parameter tools in der Generierungsanfrage aktivieren.
Ein vollständiges Beispiel:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Create an image of the Yinhe Cave (銀河洞) in Taiwan at golden hour.
- Use Image Search to search for an image of the specified place.
- Keep the location and the view as close to the real reference as possible.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(), # Enables web search
image_search=types.ImageSearch() # Enables image search
)
))
]
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Unten siehst du die Ergebnisse: Zuerst ein echtes Foto aus Google Photos, dann das mit Suche generierte Bild von Nano Banana 2, und schließlich das Bild ohne Suche. Man erkennt klar, wie stark die Suche die Genauigkeit erhöht.

Das Gemini‑Team hat mit Window View eine Demo gebaut, die Orte durch ein Fenster zeigt – ein schönes Beispiel für das Weltverständnis des Modells.
Wenn das Modell reale Orte präzise generieren kann, lassen sich spezifische Motive in reale Umgebungen setzen.
Probieren wir, Goldie und Wiskers an einen Ort in Taiwan zu platzieren. Ich habe bewusst eine weniger bekannte Location gewählt, um zu sehen, wie gut das Modell damit umgeht.
Der Prompt dazu:
Goldie and Wiskers are traveling across the Sanxiantai Arch Bridge in Taiwan.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Wichtig: Ich bitte das Modell explizit, die Bildsuche zu verwenden. Bei Tools habe ich die Erfahrung gemacht, dass ein expliziter Hinweis im Prompt die Nutzung verbessert.
Hier ein Bild unserer beiden Charaktere auf Reisen:

Ich bin noch weiter gegangen und habe den Ort per Breiten‑ und Längengrad angegeben – auch das hat funktioniert!
Goldie and Wiskers are at the location with a latitude of 17.0621186 and a longitude of -96.7255102.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.
Selbst wenn die Koordinaten nicht zu 100% übereinstimmen: Die Bildelemente passen zum Ort – ziemlich beeindruckend.
Nano Banana 2 verbessert die Textdarstellung gegenüber früheren Flash‑Modellen deutlich – konsistenter und verlässlicher.
Text wirkt nun so scharf und korrekt wie die umliegende Grafik. Außerdem ermöglicht Nano Banana 2 In‑Image‑Lokalisierung, sodass sich Text direkt im generierten Bild in mehrere Sprachen erstellen oder übersetzen lässt.
Ich habe das mit einem Poster für eine fiktive VR‑Headset‑Marke namens „Beyond Reality“ getestet und dann einfach den Prompt verwendet:
Change the language of the poster to Japanese.Hier die Ergebnisse nach der Umstellung erst auf Französisch und dann auf Japanisch:

Spannend: Das Modell hat die Marke nicht übersetzt, obwohl das nicht im Prompt stand.
Zum Schluss der Konversationsmodus. Die bisherigen Beispiele sind nicht interaktiv: Wir senden eine Anfrage und erhalten ein Ergebnis. Für Iterationen müssten wir jedes Mal eine neue Anfrage mit Bild und Änderungswunsch bauen.
Eleganter ist der Chat‑Modus. Dabei erstellen wir mit client.chats.create() einen Chat und schicken Nachrichten hin und her mit client.send_message(). So entsteht ein Chat‑Editing‑Workflow:
Hier ein vollständiges Skript für diesen Flow:
from google import genai
from google.genai import types
from dotenv import load_dotenv
from PIL import Image
import time
load_dotenv()
client = genai.Client()
# Initialize the chat session
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
# We keep track of the latest image object to send back as context
latest_image = None
while True:
user_input = input("\nPrompt: ")
if user_input.lower() in ['quit', 'exit', 'q']:
break
# Construct the message content
# If we have a previous image, we include it so the model knows what to edit
content = [user_input]
if latest_image:
content.append(latest_image)
try:
response = chat.send_message(content)
for part in response.parts:
# Handle Text Response
if part.text:
print(f"\nAI: {part.text}")
elif part.inline_data is not None:
image = part.as_image()
filename = f"image_{int(time.time())}.png"
image.save(filename)
print("Saved image", filename)
latest_image = Image.open(filename)
latest_image.show()
except Exception as e:
print(f"An error occurred: {e}")
print("Session ended.")Beim Ausführen kannst du Bilder iterativ direkt im Terminal editieren – so etwa:
Die Ergebnisse dieser Interaktion:

Die folgende Tabelle zeigt die wichtigsten Unterschiede zwischen den Nano‑Banana‑Modellen. Wie erwähnt, bringt die neue Version deutliche Verbesserungen bei Genauigkeit, Konsistenz und Auflösung – bei nur leicht längerer Laufzeit als die erste Iteration.

Die Tabelle wurde übrigens von Nano Banana 2 selbst generiert – basierend auf bereitgestellten Daten.
Auch wenn Nano Banana 2 der neue Standard ist, bleibt Nano Banana Pro für „Thinking“ und Spezialaufgaben verfügbar. Pro ist weiterhin eine gute Wahl für:
Nano Banana 2 wirkt wie ein echter Nachfolger: Iterationen driften deutlich weniger, du kannst einen Look „festzurren“ und zuverlässig über Szenen, Formate und Sprachen hinweg tragen.
Dank stärkerer Motivpersistenz, präziserer Befolgung von Anweisungen, suche‑geerdeter Realistik und dialogbasierten Edits, die feinjustieren statt neu zu zeichnen, bleibt Identität, Layout und Stil leichter erhalten – während du Varianten erkundest.
Produktionsreifes Textrendering hält Markenelemente konsistent, und flexible Seitenverhältnisse erleichtern das Skalieren einer Kampagne über Banner, Poster und Mobile‑Stories. Für Teams, die Storyboards, Produktshots oder mehrsprachige Creatives bauen, liefert es Wiederholbarkeit ohne Abstriche bei Tempo oder Qualität.
Nano Banana 2 schließt die Lücke zwischen Nano Banana und Nano Banana Pro: Es ist nahezu so schnell wie Nano Banana im Flash‑Tempo, während Fähigkeiten, visuelle Treue, präzise Anweisungsbefolgung, Motivkonsistenz und suche‑geerdete Realistik oft nahe an Nano Banana Pro heranreichen.
Wenn du mehr über die Konzepte hinter Tools wie Nano Banana 2 lernen willst, empfehle ich unseren Kurs Generative AI Concepts.
KI‑Kurse
Lernpfad
Kurs
Kurs
Tutorial
DataCamp Team
Tutorial
Laiba Siddiqui
Tutorial
DataCamp Team
Tutorial
Moez Ali
Tutorial
Sejal Jaiswal
