
Cursus
Principes fondamentaux des agents IA
6 h
Google vient de publier la deuxième itération de son modèle de génération d’images, Nano Banana 2. Lors de la première sortie de Nano Banana, le modèle a créé l’événement, devenant très vite la référence en matière de génération d’images par l’IA, à la fois la plus rapide et la plus performante.
Dans cet article, nous passons le nouveau modèle au crible, explorons ses fonctionnalités et voyons comment l’utiliser via l’API avec Python.
Si la génération d’images vous intéresse en général, consultez aussi nos guides sur les modèles suivants :
Nano Banana 2, également appelé Gemini 3.1 Flash Image, est le tout dernier modèle de pointe de Google DeepMind pour la génération et l’édition d’images. Il combine les connaissances du monde réel, la qualité et les capacités de raisonnement de Nano Banana Pro avec la vitesse fulgurante de Gemini Flash, rendant possibles dans un même flux de travail une création haute fidélité et des itérations rapides.
Voici un aperçu des principaux atouts de Nano Banana 2 :
Si vous débutez avec Nano Banana, commencez par notre précédent article sur la première itération : Nano Banana Pro.
Dans cet article, nous expliquons comment utiliser Nano Banana 2 via leur API avec Python. Les nouveaux modèles sont toutefois disponibles dans tout l’écosystème Gemini :
Dans cet article, nous utiliserons Nano Banana 2 via l’API : inutile d’avoir un abonnement, la facturation se fait à l’image générée.
J’ai trouvé la grille tarifaire officielle un peu difficile à décrypter. En général, les modèles d’images IA indiquent un prix fixe par image.
Pour simplifier, j’ai effectué des calculs afin d’estimer le coût attendu selon la taille de l’image. Notez qu’il ne s’agit pas de prix exacts : ils peuvent légèrement varier.
|
Taille de l’image |
Coût par image |
|
512 px |
$0.045 |
|
1024 px (1K) |
$0.067 |
|
2048 px (2K) |
$0.101 |
|
4096 px (4K) |
$0.151 |
Nano Banana 2 peut effectuer des recherches web pour générer des résultats plus précis. Cette fonction est très pratique, mais elle doit être prise en compte dans la tarification, car les recherches entraînent un coût supplémentaire.
Les 5 000 premières requêtes Google Search par mois sont gratuites lorsque vous utilisez l’ancrage avec Google Search. Au-delà, le coût est de 14 $ par 1 000 requêtes.
Sans plus attendre, passons à la pratique avec Nano Banana 2.
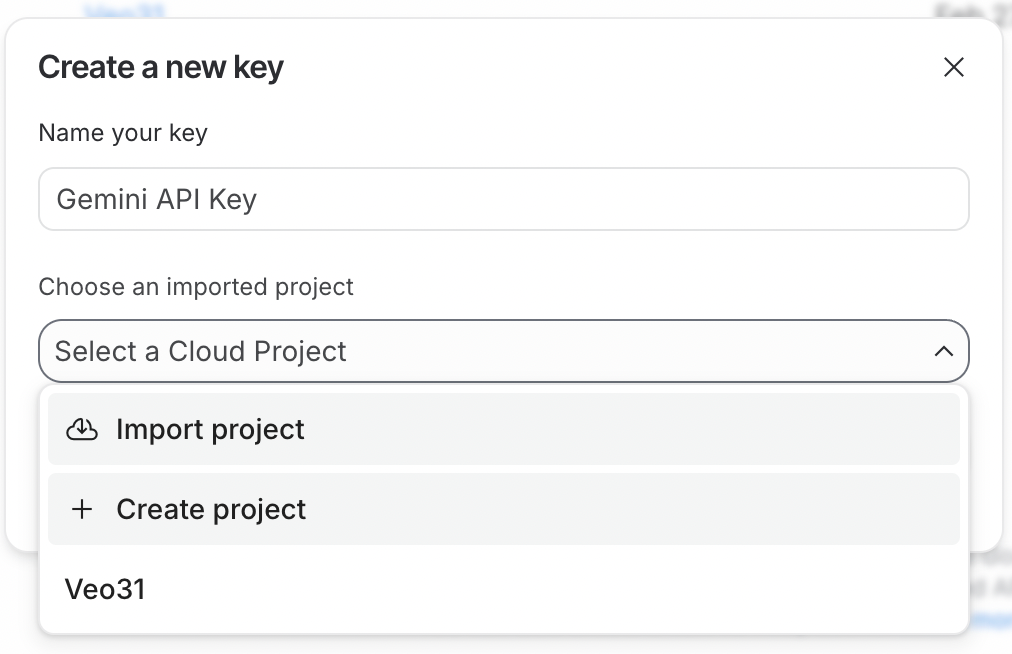
Pour utiliser l’API, nous devons d’abord générer une clé d’API. Pour cela, connectez-vous d’abord à Google AI Studio. Puis cliquez sur le bouton Create API Key en haut à droite.
La clé d’API doit être liée à un projet Google Cloud. Google AI Studio simplifie l’opération en permettant de créer un projet directement pendant la génération de la clé.
Pour utiliser la clé d’API, le projet Google Cloud associé doit avoir la facturation activée. Si vous venez de créer un nouveau projet, activez-la en cliquant sur le bouton Set up billing en face de la clé d’API.

Enfin, copiez la clé d’API et collez-la dans un fichier nommé .env au format suivant :
GEMINI_API_KEY=<paste_key_here>Placez ce fichier .env dans le même dossier que vos scripts Python.
Installons maintenant les dépendances Python nécessaires pour interagir avec l’API Gemini. Exécutez la commande suivante :
pip install google-genai python-dotenv pillowCette commande installe les paquets suivants :
google-genai : Le package officiel de génération IA de Google. Il permet de créer facilement un client pour interagir avec la Gemini API.
python-dotenv : Un utilitaire pour charger la clé d’API depuis le fichier .env.
pillow : Une bibliothèque d’images pour charger aisément des visuels en entrée de Nano Banana 2.
Voici le code Python complet pour générer une image :
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Lego version of the empire state building being built.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Voici le résultat :

Dans la requête ci-dessus, nous avons spécifié le ratio via le paramètre aspect_ratio et la résolution via le paramètre image_size.
Nano Banana 2 prend en charge un large éventail de formats et de résolutions, de 512 pixels à 4K. Liste complète des valeurs acceptées :
aspect_ratio : "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
image_size (résolution) : "512px", "1K", "2K", "4K"
Maintenant que tout est en place et que nous avons généré une première image, testons les fonctionnalités annoncées.
Nous pouvons fournir des images au modèle en les chargeant avec PIL (installé via le package pillow) et en les ajoutant à la liste contents.
L’une des forces de Nano Banana 2 est de préserver les sujets lors de la génération. Avec d’autres modèles, comme la précédente itération de Nano Banana ou GPT-Image, j’ai souvent constaté qu’il était difficile de générer des images fidèles à partir de sujets réels, le modèle ayant tendance à altérer leur apparence.
D’après la documentation, le modèle gère jusqu’à cinq personnages et dix objets, soit 14 références au total. Les notions de personnages et d’objets ne sont pas définies explicitement, mais intuitivement, le modèle a été entraîné pour générer des scènes pouvant intégrer jusqu’à quatre sujets principaux et jusqu’à dix objets secondaires avec lesquels ces sujets interagissent.
Le modèle ne propose pas de paramètres spécifiques pour soumettre des images de personnages et d’objets : tout se fait dans le prompt. J’ai examiné le code source de certains de leurs démos pour comprendre la structure du prompt utilisée pour ces références.
Le gabarit que j’ai trouvé est le suivant :
<subject_name> (<Character #number>) = Image <#index>Par exemple, avec deux personnages nommés "Alice" et "Bob", :
Subjects: Alice (Character 1) = Image 0, Bob (Character 2) = Image 1Ci-dessous, un exemple complet montrant comment faire poser ensemble deux animaux de compagnie, un chien et un chat.
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
from PIL import Image
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Goldie and Wiskers are posing together.
Subjects: Goldie (Character 1) = Image 0, Wiskers (Character 2) = Image 1
Maintain strict subject consistency for characters.
Adjust the subject composition/pose as appropriate for the scene.
"""
dog = Image.open("dog.png")
cat = Image.open("cat.png")
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, dog, cat],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")
Comme indiqué plus haut, ce gabarit ne figure pas dans la documentation officielle. Le modèle est probablement capable de déduire chaque élément à partir du prompt et des images. Mais pour une application en production où l’on vise la répétabilité, mieux vaut être aussi clair et constant que possible dans le prompt : je recommande donc d’utiliser ce gabarit.
Dans leur exemple, on étend le gabarit aux objets en remplaçant simplement "Character" par "Object" pour indiquer que l’image réfère à un objet et non au sujet principal.
Pour illustrer, faisons porter des lunettes précises au chien et un chapeau au chat en fournissant deux références d’objets. Voici le prompt utilisé :
Goldie and Wiskers are posing together. Goldie is wearing the Glasses, and Wiskers is wearing the Hat.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1, Glasses (Object 1) = Image 3, Hat (Object 2) = Image 4.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Voici le résultat :
Nano Banana 2 permet d’ancrer la génération sur des résultats de recherche pour obtenir des visuels plus fidèles. C’est particulièrement utile pour des images qui doivent coller à la réalité, par exemple un lieu ou une espèce animale précise.
Je vis à Taïwan et, récemment, une randonnée organisée a utilisé une image générée avec Nano Banana pour illustrer le lieu. L’image était pourtant inexacte et les participants ont été déçus car le site ne ressemblait en rien à la réalité.
J’étais donc curieux de voir si Nano Banana 2 pouvait gérer ce cas.
Nous pouvons activer la recherche web et la recherche d’images via le paramètre tools dans la requête de génération.
Voici un exemple complet :
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Create an image of the Yinhe Cave (銀河洞) in Taiwan at golden hour.
- Use Image Search to search for an image of the specified place.
- Keep the location and the view as close to the real reference as possible.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(), # Enables web search
image_search=types.ImageSearch() # Enables image search
)
))
]
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Ci-dessous, nous présentons les résultats : d’abord la photo réelle issue de Google Photos, puis l’image générée par Nano Banana 2 avec recherche, et enfin sans recherche. On constate que la recherche améliore nettement la fidélité.

L’équipe Gemini a conçu une démo appelée Window View qui exploite cette idée pour proposer une petite application affichant des lieux spécifiques vus par une fenêtre. Une belle démonstration de la compréhension du monde réel par le modèle.
Puisque le modèle peut générer des lieux réels avec une grande précision, nous pouvons placer des sujets spécifiques dans ces décors réels.
Essayons de placer Goldie et Wiskers dans un lieu à Taïwan. J’ai choisi cet exemple pour vérifier si le modèle gère aussi des endroits moins célèbres.
Voici le prompt :
Goldie and Wiskers are traveling across the Sanxiantai Arch Bridge in Taiwan.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Notez que le prompt demande explicitement au modèle d’utiliser la recherche d’images. J’ai constaté que lorsqu’on active des outils, il est préférable de leur enjoindre explicitement de s’en servir dans le prompt.
Voici une image de nos deux personnages en voyage :

Pour aller plus loin, j’ai même spécifié un lieu via sa latitude et sa longitude : ça fonctionne !
Goldie and Wiskers are at the location with a latitude of 17.0621186 and a longitude of -96.7255102.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.
Même si l’emplacement ne correspond pas exactement aux coordonnées, les éléments visibles concordent avec ce que l’on observe sur place : c’est plutôt bluffant.
Nano Banana 2 améliore les précédents modèles d’images basés sur Flash avec un rendu de texte plus régulier et fiable.
Le texte peut désormais apparaître aussi net et exact que les éléments graphiques environnants. Nano Banana 2 permet aussi la localisation dans l’image, pour créer ou traduire du texte dans plusieurs langues directement au sein de l’image générée.
J’ai testé la localisation en générant une affiche pour une marque fictive de casque de réalité virtuelle nommée "Beyond Reality". J’ai ensuite simplement utilisé un prompt du type :
Change the language of the poster to Japanese.Voici les résultats après passage du texte de l’affiche en français puis en japonais :

Intéressant : le modèle a compris de lui-même qu’il ne fallait pas traduire le nom de la marque, sans que cela soit précisé dans le prompt.
Dernier point : le mode conversation. Les exemples précédents ne sont pas interactifs : on envoie une requête à l’API et on récupère un résultat. Pour itérer, il faut construire une nouvelle requête avec l’image obtenue et les modifications souhaitées.
Une approche plus fluide consiste à utiliser le mode chat. En mode chat, on crée une conversation via client.chats.create(), puis on échange des messages avec client.send_message(). On peut ainsi mettre en place un flux d’édition en chat :
Voici un script complet implémentant ce flux :
from google import genai
from google.genai import types
from dotenv import load_dotenv
from PIL import Image
import time
load_dotenv()
client = genai.Client()
# Initialize the chat session
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
# We keep track of the latest image object to send back as context
latest_image = None
while True:
user_input = input("\nPrompt: ")
if user_input.lower() in ['quit', 'exit', 'q']:
break
# Construct the message content
# If we have a previous image, we include it so the model knows what to edit
content = [user_input]
if latest_image:
content.append(latest_image)
try:
response = chat.send_message(content)
for part in response.parts:
# Handle Text Response
if part.text:
print(f"\nAI: {part.text}")
elif part.inline_data is not None:
image = part.as_image()
filename = f"image_{int(time.time())}.png"
image.save(filename)
print("Saved image", filename)
latest_image = Image.open(filename)
latest_image.show()
except Exception as e:
print(f"An error occurred: {e}")
print("Session ended.")En exécutant ce script, on peut éditer une image de manière itérative directement dans le terminal, comme ceci :
Voici les résultats de cette interaction :

Le tableau ci-dessous met en avant les principales différences entre les versions de Nano Banana. Comme mentionné plus haut, la nouvelle version apporte des progrès majeurs en précision, cohérence et résolution, tout en étant seulement un peu plus lente que la première itération.

Ce tableau a d’ailleurs été généré par Nano Banana 2 à partir des données fournies.
Bien que Nano Banana 2 soit le nouveau standard, Nano Banana Pro reste disponible pour les tâches de type « Thinking » et les besoins spécialisés. Vous pourrez encore préférer Pro pour :
Nano Banana 2 tient son rang d’héritier : il réduit nettement la « dérive » entre itérations, ce qui permet de figer un style et de le conserver de façon fiable au fil des scènes, formats et langues.
Entre une meilleure persistance des sujets, un suivi des consignes plus strict, un réalisme ancré par la recherche et des éditions conversationnelles qui ajustent plutôt que de tout redessiner, il est bien plus simple de préserver identité, mise en page et style tout en explorant des variantes.
Un rendu de texte de niveau production aide à garder des éléments de marque cohérents, et les formats flexibles facilitent le déploiement d’une campagne sur bannières, affiches et stories mobiles. Pour les équipes qui conçoivent des storyboards, des packshots ou des créatifs multi-pays, on gagne en répétabilité sans sacrifier la vitesse ni la fidélité.
Nano Banana 2 comble clairement l’écart entre Nano Banana et Nano Banana Pro : la vitesse reste proche du rythme quasi instantané de Flash, tandis que les capacités, la fidélité visuelle, le suivi précis des consignes, la cohérence des sujets et le réalisme ancré par la recherche se rapprochent régulièrement de Nano Banana Pro.
Pour en savoir plus sur les concepts derrière des outils comme Nano Banana 2, nous vous recommandons notre cours Generative AI Concepts.
Cours d’IA
Cursus
Cours
Cours
blog
Kurtis Pykes
9 min
Tutoriel
Tutoriel
Satyabrata Pal
Tutoriel
DataCamp Team
Tutoriel
Adel Nehme
Tutoriel
Moez Ali
