Tracks
พื้นฐานของ AI Agent
6 ชม.
Google เพิ่งเปิดตัวรุ่นที่สองของโมเดลสร้างภาพ Nano Banana 2 เมื่อ Nano Banana เปิดตัวครั้งแรก ก็สร้างความฮือฮาและกลายเป็นโมเดลสร้างภาพ AI ที่ทั้งเร็วและยอดเยี่ยมที่สุดอย่างรวดเร็ว
ในบทความนี้ เราจะพาดำดิ่งสู่โมเดลใหม่ สำรวจฟีเจอร์ และเรียนรู้การใช้งานผ่าน API ด้วย Python
หากสนใจการสร้างภาพโดยรวม แนะนำให้อ่านคู่มือของโมเดลต่อไปนี้:
Nano Banana 2 หรือชื่อทางการว่า Gemini 3.1 Flash Image คือโมเดล AI สร้างและแก้ไขภาพรุ่นล่าสุดระดับแนวหน้าจาก Google DeepMind ที่ผสานความรู้โลกจริง คุณภาพ และการให้เหตุผลขั้นสูงของ Nano Banana Pro เข้ากับความเร็วระดับสายฟ้าของ Gemini Flash ทำให้การสร้างงานความเที่ยงตรงสูงและการปรับแก้ซ้ำอย่างรวดเร็วเกิดขึ้นได้ในเวิร์กโฟลว์เดียว
สรุปคุณสมบัติเด่นของ Nano Banana 2 มีดังนี้:
หากเพิ่งเริ่มใช้ Nano Banana อาจอยากอ่านบทความก่อนหน้าว่าด้วย Nano Banana Pro รุ่นแรกก่อน
บทความนี้จะอธิบายการใช้ Nano Banana 2 ผ่าน API ด้วย Python อย่างไรก็ดี โมเดลใหม่นี้มีให้ใช้ทั่วทั้งระบบนิเวศ Gemini:
ในบทความนี้ เราจะใช้ Nano Banana 2 ผ่าน API จึงไม่ต้องสมัครสมาชิกรายเดือน แต่จะจ่ายตามจำนวนภาพที่สร้าง
ตารางราคา ทางการ ดูเข้าใจยากเล็กน้อย ปกติโมเดลสร้างภาพ AI มักระบุราคาแบบตายตัวต่อภาพ
เพื่อให้เข้าใจง่ายขึ้น จึงคำนวณราคาโดยประมาณตามขนาดภาพ หมายเหตุว่าราคาไม่เป๊ะและอาจคลาดเคลื่อนได้เล็กน้อย
|
ขนาดภาพ |
ราคาต่อภาพ |
|
512px |
$0.045 |
|
1024px (1K) |
$0.067 |
|
2048px (2K) |
$0.101 |
|
4096px (4K) |
$0.151 |
Nano Banana 2 สามารถค้นเว็บเพื่อสร้างผลลัพธ์ที่แม่นยำขึ้น ฟีเจอร์นี้ดีมาก แต่ต้องคำนึงถึงราคาเพิ่ม เพราะการค้นหามีค่าใช้จ่ายเพิ่มเติม
คำค้น Google Search 5,000 ครั้งแรกต่อเดือนฟรีเมื่อใช้ grounding กับ Google Search หลังจากนั้นคิด $14 ต่อ 1,000 คำค้น
มาเริ่มต้นใช้งาน Nano Banana 2 กันเลย
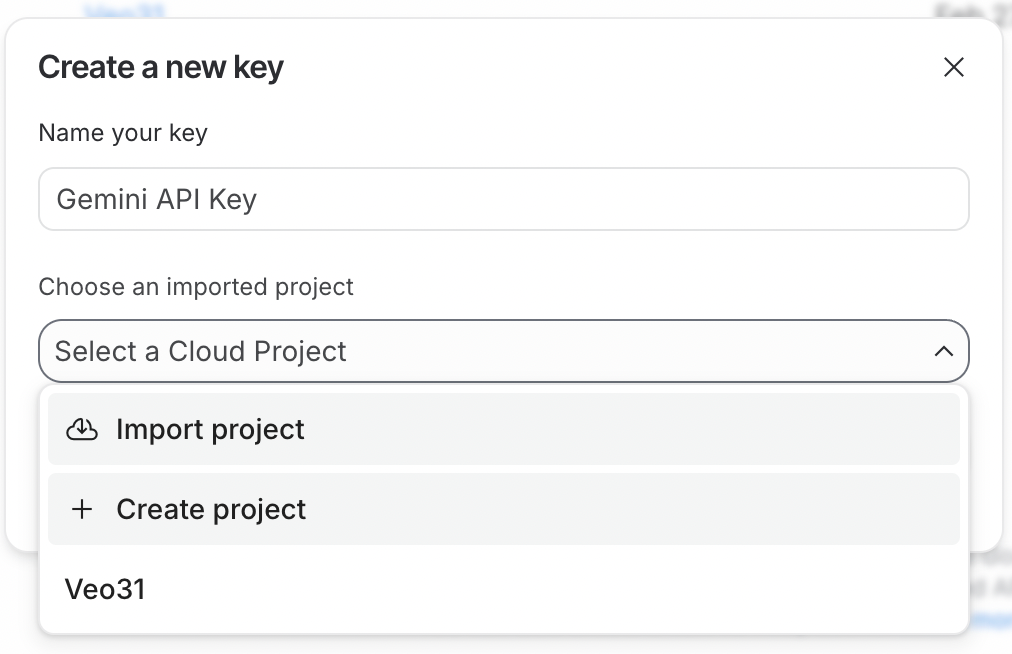
หากต้องการใช้ API ก่อนอื่นต้องสร้างคีย์ API โดยลงชื่อเข้าใช้ Google AI Studio ก่อน แล้วคลิกปุ่ม Create API Key มุมขวาบน
คีย์ API ต้องเชื่อมกับโปรเจกต์บน Google Cloud ซึ่ง Google AI Studio ทำให้ง่าย เพราะสามารถสร้างโปรเจกต์ใหม่ได้ระหว่างขั้นตอนสร้างคีย์
ในการใช้คีย์ API โปรเจกต์ Google Cloud ที่เชื่อมไว้ต้องเปิดการเรียกเก็บเงิน หากเพิ่งสร้างโปรเจกต์ใหม่ ให้เปิดใช้งานโดยคลิกปุ่ม Set up billing ถัดจากคีย์ API

คัดลอกคีย์ API แล้ววางลงไฟล์ชื่อ .env ด้วยรูปแบบดังนี้:
GEMINI_API_KEY=<paste_key_here>ไฟล์ .env ควรอยู่ในโฟลเดอร์เดียวกับสคริปต์ Python ที่จะเขียน
ถัดไป ติดตั้งไลบรารี Python ที่จำเป็นเพื่อใช้งาน Gemini API ด้วยคำสั่ง:
pip install google-genai python-dotenv pillowคำสั่งนี้ติดตั้งแพ็กเกจต่อไปนี้:
google-genai: แพ็กเกจ Generative AI อย่างเป็นทางการของ Google ใช้สร้างไคลเอนต์เพื่อเชื่อมต่อกับ Gemini API ได้สะดวก
python-dotenv: ยูทิลิตีสำหรับโหลดคีย์ API จากไฟล์ .env
pillow: ไลบรารีภาพ เพื่อให้ง่ายต่อการโหลดภาพเป็นอินพุตของ Nano Banana 2
นี่คือโค้ด Python แบบครบถ้วนสำหรับการสร้างภาพ:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Lego version of the empire state building being built.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")ผลลัพธ์มีดังนี้:

ในคำขอด้านบน เรากำหนดอัตราส่วนภาพด้วยพารามิเตอร์ aspect_ratio และความละเอียดด้วยพารามิเตอร์ image_size
Nano Banana 2 รองรับอัตราส่วนและความละเอียดหลากหลายตั้งแต่ 512 พิกเซลถึง 4K รายการค่าที่รองรับมีดังนี้:
aspect_ratio: "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
image_size (ความละเอียด): "512px", "1K", "2K", "4K"
เมื่อเซ็ตอัปเรียบร้อยและสร้างภาพแรกสำเร็จแล้ว ถึงเวลาทดสอบฟีเจอร์ตามที่โฆษณาไว้
เราสามารถส่งภาพเข้าโมเดลได้โดยโหลดด้วย PIL (ติดตั้งจากแพ็กเกจ pillow) แล้วใส่ลงในลิสต์ contents
หนึ่งในฟีเจอร์หลักของ Nano Banana 2 คือความสามารถในการคงตัวแบบเมื่อสร้างภาพ เมื่อลองโมเดลอื่น เช่นรุ่นก่อนของ Nano Banana หรือ GPT-Image มักพบว่าการสร้างภาพอิงจากตัวแบบในชีวิตจริงค่อนข้างยาก เพราะโมเดลมีแนวโน้มเปลี่ยนลักษณะให้ต่างออกไป
จากเอกสาร โมเดลรองรับตัวละครได้สูงสุดห้าตัว และวัตถุ 10 ชิ้น รวมเป็น 14 เรเฟอเรนซ์ แม้จะไม่ได้กำหนดนิยามของ “ตัวละคร” กับ “วัตถุ” ไว้ชัดเจน แต่โดยสัญชาตญาณหมายถึง โมเดลถูกฝึกให้สร้างฉากที่วางตัวแบบหลักได้สูงสุด 4 ตัว และวัตถุรองได้สูงสุด 10 ชิ้นที่ตัวแบบโต้ตอบด้วย
โมเดลไม่มีพารามิเตอร์เฉพาะสำหรับส่งภาพตัวละครหรือวัตถุ การอ้างอิงทำผ่านพรอมต์ ฉันตรวจโค้ดตัวอย่างของเดโมบางตัวเพื่อทำความเข้าใจโครงสร้างพรอมต์ที่ใช้อ้างถึงสิ่งเหล่านี้
เทมเพลตที่พบเป็นดังนี้:
<subject_name> (<Character #number>) = Image <#index>เช่น หากมีสองตัวละครชื่อ "Alice" และ "Bob" จะเป็น:
Subjects: Alice (Character 1) = Image 0, Bob (Character 2) = Image 1ตัวอย่างโค้ดเต็มด้านล่างแสดงการจัดท่าทางสัตว์เลี้ยงสองตัว คือสุนัขและแมว ให้อยู่ในภาพเดียวกัน
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
from PIL import Image
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Goldie and Wiskers are posing together.
Subjects: Goldie (Character 1) = Image 0, Wiskers (Character 2) = Image 1
Maintain strict subject consistency for characters.
Adjust the subject composition/pose as appropriate for the scene.
"""
dog = Image.open("dog.png")
cat = Image.open("cat.png")
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, dog, cat],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")
ดังที่กล่าว เทมเพลตนี้ไม่อยู่ในเอกสารทางการ โมเดลน่าจะเข้าใจได้จากพรอมต์และภาพ อย่างไรก็ดี หากสร้างแอปจริงที่ต้องการผลลัพธ์สม่ำเสมอ ควรระบุให้ชัดและใช้รูปแบบสม่ำเสมอในพรอมต์ จึงแนะนำให้ใช้เทมเพลตนี้
ตัวอย่างยังขยายเทมเพลตไปยังวัตถุ โดยแทนที่คำว่า "Character" ด้วย "Object" เพื่อบอกโมเดลว่าภาพอ้างถึงวัตถุไม่ใช่ตัวแบบหลัก
เพื่อสาธิต ลองให้สุนัขใส่แว่นกันแดดแบบเฉพาะ และให้แมวสวมหมวก โดยจัดวัตถุอ้างอิงสองชิ้น พรอมต์ที่ใช้คือ:
Goldie and Wiskers are posing together. Goldie is wearing the Glasses, and Wiskers is wearing the Hat.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1, Glasses (Object 1) = Image 3, Hat (Object 2) = Image 4.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.ผลลัพธ์มีดังนี้:
Nano Banana 2 ทำให้สามารถยึดโยงการสร้างภาพกับผลการค้นหาเพื่อให้ได้ผลลัพธ์ที่แม่นยำขึ้น มีประโยชน์มากเมื่อต้องสร้างภาพที่สอดคล้องกับความจริง เช่น สถานที่หรือสายพันธุ์สัตว์เฉพาะ
ฉันอาศัยอยู่ที่ไต้หวัน ไม่นานมานี้มีการจัดเดินป่า ซึ่งผู้จัดใช้ภาพที่สร้างด้วย Nano Banana เพื่อสื่อถึงสถานที่ แต่ภาพไม่ตรงความจริงเลย ทำให้ผู้คนผิดหวังเพราะดูต่างจากสถานที่จริงมาก
จึงเกิดความสงสัยว่า Nano Banana 2 จะรับมือสิ่งนี้ได้หรือไม่
เราสามารถเปิดใช้การค้นเว็บและค้นรูปด้วยพารามิเตอร์ tools ในคำขอสร้างภาพ
ตัวอย่างเต็มมีดังนี้:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Create an image of the Yinhe Cave (銀河洞) in Taiwan at golden hour.
- Use Image Search to search for an image of the specified place.
- Keep the location and the view as close to the real reference as possible.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(), # Enables web search
image_search=types.ImageSearch() # Enables image search
)
))
]
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")ด้านล่างเป็นผลลัพธ์: ภาพจริงจาก Google Photos ตามด้วยภาพที่ Nano Banana 2 สร้างโดยใช้การค้นหา และภาพที่สร้างโดยไม่ใช้การค้นหา จะเห็นว่าการค้นหาทำให้ผลลัพธ์แม่นยำมาก

ทีม Gemini สร้างเดโมชื่อ Window View ที่ใช้แนวคิดนี้ทำเป็นแอปเล็ก ๆ ให้มองเห็นสถานที่เฉพาะผ่านหน้าต่าง เป็นตัวอย่างที่ดีของความสามารถของโมเดลในการเข้าใจโลกจริง
เมื่อโมเดลสร้างสถานที่จริงได้อย่างแม่นยำสูง ก็สามารถวางตัวแบบเฉพาะลงในสถานที่จริงได้
ลองวาง Goldie และ Wiskers ในสถานที่หนึ่งในไต้หวัน ตั้งใจเลือกสถานที่ที่ไม่ดังระดับโลกเพื่อดูว่าโมเดลจะรับมือได้หรือไม่
พรอมต์ที่ใช้คือ:
Goldie and Wiskers are traveling across the Sanxiantai Arch Bridge in Taiwan.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.สังเกตว่าพรอมต์ขอให้โมเดลทำ image search ชัดเจน พบว่าเมื่อใช้เครื่องมือ ควรบอกให้ชัดในพรอมต์เสมอ
นี่คือภาพของสองตัวละครกำลังเดินทางด้วยกัน:

เพื่อท้าทายยิ่งขึ้น ลองระบุสถานที่ด้วยละติจูดและลองจิจูด ปรากฏว่าใช้งานได้!
Goldie and Wiskers are at the location with a latitude of 17.0621186 and a longitude of -96.7255102.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.
แม้สถานที่จะไม่ตรงพิกัดเป๊ะ ๆ องค์ประกอบในภาพก็สอดคล้องกับสถานที่นั้น ซึ่งน่าประทับใจทีเดียว
Nano Banana 2 ปรับปรุงจากโมเดลภาพตระกูล Flash รุ่นก่อน ด้วยการเรนเดอร์ข้อความที่สม่ำเสมอและเชื่อถือได้มากขึ้น
ข้อความสามารถคมชัดและแม่นยำพอ ๆ กับกราฟิกโดยรอบ นอกจากนี้ยังรองรับการทำโลคัลไลซ์ในภาพ ทำให้สร้างหรือแปลข้อความเป็นหลายภาษาได้โดยตรงในภาพที่สร้าง
ฉันทดสอบการโลคัลไลซ์ด้วยการสร้างโปสเตอร์ของแบรนด์เฮดเซ็ต VR สมมติชื่อ "Beyond Reality" จากนั้นใช้พรอมต์ง่าย ๆ ว่า:
Change the language of the poster to Japanese.นี่คือผลลัพธ์หลังเปลี่ยนภาษาในโปสเตอร์เป็นฝรั่งเศส แล้วเป็นญี่ปุ่น:

ที่น่าสนใจคือ โมเดลฉลาดพอที่จะไม่แปลชื่อแบรนด์ แม้จะไม่ได้ระบุไว้ในพรอมต์
ฟีเจอร์สุดท้ายคือโหมดสนทนา ตัวอย่างก่อนหน้าไม่ใช่แบบโต้ตอบ เราส่งคำขอไปยัง API แล้วได้ผลลัพธ์ หากต้องการแก้ไข ต้องสร้างคำขอใหม่แนบภาพเดิมและการเปลี่ยนแปลงที่ต้องการ
วิธีที่ดีกว่าคือโหมดแชต ในโหมดนี้ เราสร้างแชตด้วยฟังก์ชัน client.chats.create() แล้วส่งข้อความโต้ตอบด้วยฟังก์ชัน client.send_message() ซึ่งใช้สร้างเวิร์กโฟลว์แก้ไขแบบแชตได้ดังนี้:
นี่คือสคริปต์เต็มที่ใช้เวิร์กโฟลว์นี้:
from google import genai
from google.genai import types
from dotenv import load_dotenv
from PIL import Image
import time
load_dotenv()
client = genai.Client()
# Initialize the chat session
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
# We keep track of the latest image object to send back as context
latest_image = None
while True:
user_input = input("\nPrompt: ")
if user_input.lower() in ['quit', 'exit', 'q']:
break
# Construct the message content
# If we have a previous image, we include it so the model knows what to edit
content = [user_input]
if latest_image:
content.append(latest_image)
try:
response = chat.send_message(content)
for part in response.parts:
# Handle Text Response
if part.text:
print(f"\nAI: {part.text}")
elif part.inline_data is not None:
image = part.as_image()
filename = f"image_{int(time.time())}.png"
image.save(filename)
print("Saved image", filename)
latest_image = Image.open(filename)
latest_image.show()
except Exception as e:
print(f"An error occurred: {e}")
print("Session ended.")เมื่อรันสคริปต์นี้ เราสามารถแก้ไขภาพแบบวนซ้ำได้จากเทอร์มินัลโดยตรงดังนี้:
ผลลัพธ์จากการโต้ตอบนี้มีดังนี้:

ตารางด้านล่างสรุปความแตกต่างหลักระหว่างโมเดล Nano Banana ตามที่กล่าวไว้ รุ่นใหม่ปรับปรุงความแม่นยำ ความสม่ำเสมอ และความละเอียดอย่างมาก โดยทำงานช้ากว่ารุ่นแรกเพียงเล็กน้อย

ที่จริงตารางนี้สร้างโดย Nano Banana 2 โดยป้อนข้อมูลให้
แม้ Nano Banana 2 จะเป็นมาตรฐานใหม่ แต่ Nano Banana Pro ยังคงมีให้ใช้สำหรับโหมด “Thinking” และงานเฉพาะทาง อาจเลือกใช้ Pro เมื่อ:
Nano Banana 2 เป็นทายาทตัวจริง เพราะลด “ดริฟท์” ระหว่างการแก้ไขซ้ำได้มาก ทำให้ล็อกลุคและคงไว้ได้อย่างเชื่อถือผ่านฉาก ฟอร์แมต และภาษา
ด้วยความคงทนของตัวแบบที่ดีขึ้น การทำตามคำสั่งที่แม่นยำ ความสมจริงจากการยึดโยงการค้นหา และการแก้ไขแบบสนทนาที่ “ปรับ” มากกว่า “วาดใหม่” ทำให้รักษาเอกลักษณ์ เลย์เอาต์ และสไตล์ได้ง่ายขึ้นระหว่างการสำรวจรูปแบบต่าง ๆ
การเรนเดอร์ข้อความระดับโปรดักชันช่วยให้เอกลักษณ์แบรนด์คงที่ และอัตราส่วนที่ยืดหยุ่นทำให้สเกลแคมเปญข้ามแบนเนอร์ โปสเตอร์ และสตอรีมือถือได้อย่างลื่นไหล สำหรับทีมที่ทำสตอรีบอร์ด ภาพสินค้า หรือครีเอทีฟหลายโลแคล มอบความทำซ้ำได้โดยไม่เสียความเร็วหรือความเที่ยงตรง
Nano Banana 2 เชื่อมช่องว่างระหว่าง Nano Banana และ Nano Banana Pro ได้อย่างตรงจุด: ความเร็วแทบเทียบเท่า Flash ของ Nano Banana ขณะที่ความสามารถ ความเที่ยงตรงเชิงภาพ การทำตามคำสั่งที่แม่นยำ ความสม่ำเสมอของตัวแบบ และความสมจริงจากการค้นหา มักเข้าใกล้ Nano Banana Pro อย่างสม่ำเสมอ
หากต้องการเรียนรู้แนวคิดเบื้องหลังเครื่องมืออย่าง Nano Banana 2 แนะนำคอร์ส Generative AI Concepts ของเรา
คอร์ส AI
Tracks
Courses
Courses