
programa
Fundamentos de agentes de IA
6 h
Google acaba de lanzar la segunda iteración de su modelo de generación de imágenes, Nano Banana 2. Cuando se publicó Nano Banana por primera vez, arrasó: se convirtió rápidamente en el mejor y más veloz modelo de generación de imágenes con IA.
En este artículo, profundizamos en el nuevo modelo, exploramos sus novedades y aprendemos a usarlo desde la API con Python.
Si te interesa en general la generación de imágenes, te recomiendo revisar nuestras guías de estos modelos:
Nano Banana 2, también conocido como Gemini 3.1 Flash Image, es el último modelo de IA de Google DeepMind para generación y edición de imágenes con tecnología de vanguardia. Combina el conocimiento del mundo real, la calidad y la capacidad de razonamiento de Nano Banana Pro con la velocidad ultrarrápida de Gemini Flash, haciendo posible la creación de alta fidelidad y la iteración rápida en el mismo flujo de trabajo.
Resumen de las principales capacidades de Nano Banana 2:
Si es tu primera vez con Nano Banana, quizá te interese leer antes nuestro artículo sobre la primera iteración, Nano Banana Pro.
En este artículo, vemos cómo usar Nano Banana 2 mediante su API con Python. No obstante, los nuevos modelos están disponibles en todo el ecosistema Gemini:
En este artículo usaremos Nano Banana 2 con la API, así que no necesitaremos suscripción: pagaremos por cada imagen generada.
La tabla oficial de precios me pareció un poco difícil de interpretar. Normalmente, los modelos de imagen con IA dan un precio fijo por imagen.
Para simplificar, hice unos cálculos estimando el precio esperado según el tamaño de la imagen. Ten en cuenta que no son precios exactos y pueden variar ligeramente.
|
Tamaño de imagen |
Coste por imagen |
|
512px |
$0.045 |
|
1024px (1K) |
$0.067 |
|
2048px (2K) |
$0.101 |
|
4096px (4K) |
$0.151 |
Nano Banana 2 puede realizar búsquedas en la web para generar resultados más precisos. Es una función fantástica, pero hay que tenerla en cuenta en el coste, ya que las búsquedas generan un cargo adicional.
Las primeras 5.000 consultas de Google Search al mes son gratuitas cuando usas grounding con Google Search. A partir de ahí, cuesta 14 $ por cada 1.000 consultas de Google Search.
Sin más, vamos a ponernos manos a la obra con Nano Banana 2.
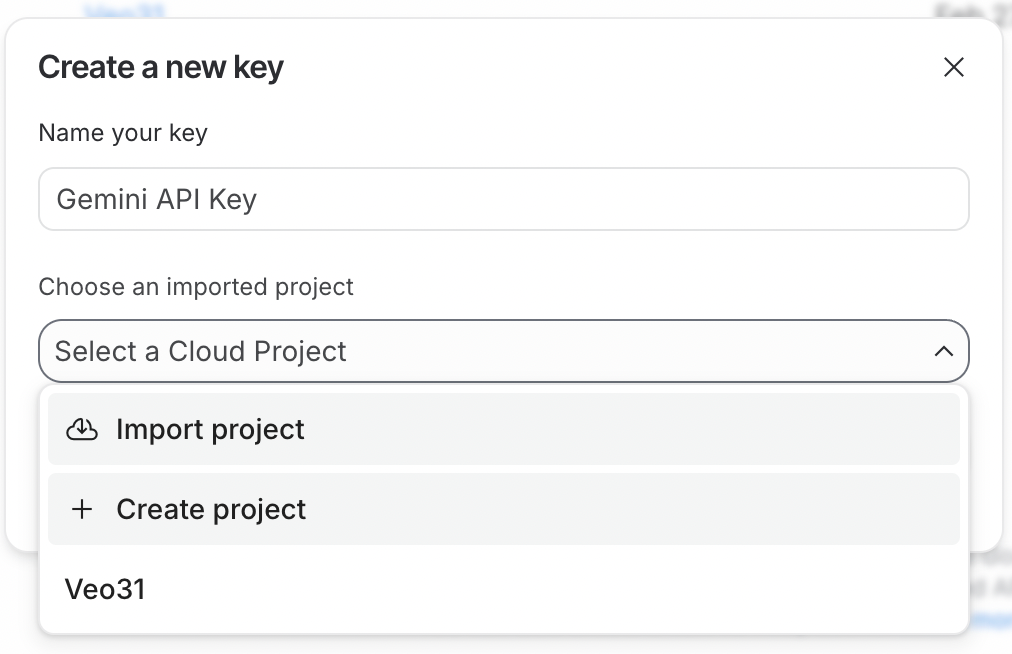
Para usar la API, primero necesitamos generar una clave. Para ello, inicia sesión en Google AI Studio. Después, haz clic en Create API Key en la esquina superior derecha.
La clave de API debe vincularse a un proyecto de Google Cloud. Google AI Studio lo facilita permitiendo crear un proyecto directamente durante la generación de la clave.
Para usar la clave, el proyecto de Google Cloud vinculado debe tener la facturación activada. Si acabas de crear un proyecto nuevo, actívala haciendo clic en Set up billing junto a la clave de API.

Por último, copia la clave de API y pégala en un archivo llamado .env con este formato:
GEMINI_API_KEY=<paste_key_here>Este archivo .env debe crearse en la misma carpeta en la que escribiremos los scripts de Python.
A continuación, instalamos las dependencias de Python necesarias para interactuar con la Gemini API. Ejecuta este comando:
pip install google-genai python-dotenv pillowEsto instala los siguientes paquetes:
google-genai: Paquete oficial de IA generativa de Google. Se usa para crear fácilmente un cliente que interactúe con la Gemini API.
python-dotenv: Paquete para cargar la clave de API desde el archivo .env.
pillow: Librería de imágenes para cargar y manipular imágenes como entrada a Nano Banana 2.
Aquí tienes el código completo en Python para generar una imagen:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Lego version of the empire state building being built.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Este es el resultado:

En la solicitud anterior, indicamos la relación de aspecto con el parámetro aspect_ratio y la resolución con image_size.
Nano Banana 2 admite una amplia gama de relaciones de aspecto y resoluciones, desde 512 píxeles hasta 4K. Estos son los valores compatibles:
aspect_ratio: "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
image_size (resolución): "512px", "1K", "2K", "4K"
Ahora que ya tenemos todo listo y hemos creado nuestra primera imagen, toca poner a prueba las funciones anunciadas.
Podemos proporcionar imágenes al modelo cargándolas con PIL (instalado con el paquete pillow) e incluyéndolas en la lista contents.
Una de las funciones principales de Nano Banana 2 es su capacidad para preservar los sujetos al generar imágenes. Al probar otros modelos como la iteración anterior de Nano Banana o GPT-Image, a menudo me encontré con que era difícil generar imágenes basadas en sujetos reales, porque el modelo tendía a alterar su aspecto.
Según su documentación, el modelo puede manejar hasta cinco personajes y 10 objetos, para un total de 14 referencias. No definen explícitamente personajes y objetos, pero de forma intuitiva significa que el modelo está entrenado para generar escenas con hasta 4 sujetos principales y hasta 10 objetos secundarios con los que interactúan.
El modelo no ofrece parámetros específicos para enviar imágenes de personajes y objetos: se hace en el prompt. Inspeccioné el código fuente de algunas demos para entender cómo estructuran el prompt para referirse a ellos.
La plantilla que encontré es la siguiente:
<subject_name> (<Character #number>) = Image <#index>Por ejemplo, con dos personajes llamados "Alice" y "Bob", sería:
Subjects: Alice (Character 1) = Image 0, Bob (Character 2) = Image 1A continuación, tienes un ejemplo completo que muestra cómo colocar a dos mascotas, un perro y un gato, posando juntos en una foto.
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
from PIL import Image
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Goldie and Wiskers are posing together.
Subjects: Goldie (Character 1) = Image 0, Wiskers (Character 2) = Image 1
Maintain strict subject consistency for characters.
Adjust the subject composition/pose as appropriate for the scene.
"""
dog = Image.open("dog.png")
cat = Image.open("cat.png")
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, dog, cat],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")
Como se mencionó, esta plantilla no forma parte de la documentación oficial. Probablemente el modelo pueda entender cada parte a partir del prompt y las imágenes. Sin embargo, al implementar una aplicación real en la que queremos resultados consistentes, lo mejor es ser lo más precisos y consistentes posible en el prompt, así que recomiendo usar esta plantilla.
En su ejemplo, amplían la plantilla para referencias de objetos simplemente sustituyendo "Character" por "Object" para indicar al modelo que la imagen corresponde a un objeto y no al sujeto principal.
Para ilustrarlo, hagamos que el perro lleve unas gafas concretas y el gato un sombrero aportando dos referencias de objetos. Este es el prompt que usé:
Goldie and Wiskers are posing together. Goldie is wearing the Glasses, and Wiskers is wearing the Hat.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1, Glasses (Object 1) = Image 3, Hat (Object 2) = Image 4.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Aquí tienes el resultado:
Nano Banana 2 permite fundamentar la generación de imágenes en la búsqueda para que los resultados sean más fieles a la realidad. Es especialmente útil al generar imágenes que deban ser coherentes con el mundo real, como imágenes de una localización o de una especie concreta de animal.
Vivo en Taiwán y, recientemente, en una ruta organizada el organizador usó una imagen generada con Nano Banana para ilustrar el lugar. La imagen no era nada precisa y la gente acabó decepcionada porque no se parecía en nada al sitio real.
Esto me dio curiosidad por comprobar si Nano Banana 2 podía manejarlo.
Podemos activar tanto la búsqueda web como la búsqueda de imágenes usando el parámetro tools en la petición de generación.
Aquí tienes un ejemplo completo:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Create an image of the Yinhe Cave (銀河洞) in Taiwan at golden hour.
- Use Image Search to search for an image of the specified place.
- Keep the location and the view as close to the real reference as possible.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(), # Enables web search
image_search=types.ImageSearch() # Enables image search
)
))
]
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Abajo mostramos los resultados. Primero, la foto real tomada de Google Photos; después, la imagen generada por Nano Banana 2 usando búsqueda; y por último, la imagen generada sin búsqueda. Se ve que la búsqueda vuelve los resultados mucho más precisos.

El equipo de Gemini creó una demo llamada Window View que usa esta idea para construir una pequeña app que muestra lugares concretos a través de una ventana. Es una buena demostración de la capacidad del modelo para entender el mundo real.
Si el modelo puede generar ubicaciones reales con alta precisión, podemos colocar sujetos específicos en localizaciones reales.
Probemos a situar a Goldie y Wiskers en una localización de Taiwán. Elegí este lugar porque quería ver si el modelo podía con ubicaciones que no son mundialmente famosas.
Este fue el prompt:
Goldie and Wiskers are traveling across the Sanxiantai Arch Bridge in Taiwan.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Observa que el prompt pide explícitamente al modelo que haga una búsqueda de imágenes. Cuando uso herramientas, he comprobado que siempre es mejor solicitarlo de forma explícita en el prompt.
Aquí tienes una imagen de nuestros dos personajes de viaje:

Para ir más allá, incluso probé a especificar la ubicación con latitud y longitud, ¡y funcionó!
Goldie and Wiskers are at the location with a latitude of 17.0621186 and a longitude of -96.7255102.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.
Aunque la localización no sea exactamente esas coordenadas, los elementos de la imagen corresponden a lo que vemos en ese lugar, lo cual me parece bastante impresionante.
Nano Banana 2 mejora los modelos de imagen anteriores basados en Flash ofreciendo un renderizado de texto más consistente y fiable.
Ahora el texto puede aparecer tan nítido y preciso como los gráficos que lo rodean. Nano Banana 2 también habilita la localización dentro de la imagen, lo que permite crear o traducir texto a varios idiomas directamente en la imagen generada.
Probé la localización generando un póster para una marca ficticia de auriculares de realidad virtual llamada "Beyond Reality". Luego simplemente usé un prompt como:
Change the language of the poster to Japanese.Estos son los resultados tras cambiar el idioma del texto del póster primero a francés y luego a japonés:

Curiosamente, el modelo fue lo bastante inteligente como para no traducir el nombre de la marca, aunque no se lo indicamos en el prompt.
La última función que exploramos es el modo conversación. Los ejemplos anteriores no son interactivos: enviamos una petición a la API y obtenemos un resultado. Si queremos iterar sobre ese resultado, tenemos que construir una nueva petición con esa imagen y los cambios deseados.
Una forma mejor es usar el modo chat. En modo chat, creamos una conversación con la función client.chats.create() y luego enviamos y recibimos mensajes con client.send_message(). Podemos usarlo para implementar un flujo de edición por chat:
Aquí tienes un script completo que implementa este flujo:
from google import genai
from google.genai import types
from dotenv import load_dotenv
from PIL import Image
import time
load_dotenv()
client = genai.Client()
# Initialize the chat session
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
# We keep track of the latest image object to send back as context
latest_image = None
while True:
user_input = input("\nPrompt: ")
if user_input.lower() in ['quit', 'exit', 'q']:
break
# Construct the message content
# If we have a previous image, we include it so the model knows what to edit
content = [user_input]
if latest_image:
content.append(latest_image)
try:
response = chat.send_message(content)
for part in response.parts:
# Handle Text Response
if part.text:
print(f"\nAI: {part.text}")
elif part.inline_data is not None:
image = part.as_image()
filename = f"image_{int(time.time())}.png"
image.save(filename)
print("Saved image", filename)
latest_image = Image.open(filename)
latest_image.show()
except Exception as e:
print(f"An error occurred: {e}")
print("Session ended.")Al ejecutar este script, podemos editar una imagen de forma iterativa directamente en la terminal así:
Estos son los resultados de esta interacción:

La tabla siguiente destaca las principales diferencias entre los modelos Nano Banana. Como comentábamos, la nueva versión aporta mejoras importantes en precisión, consistencia y resolución, y solo es ligeramente más lenta que la primera iteración.

De hecho, la tabla fue generada por el propio Nano Banana 2 a partir de los datos.
Aunque Nano Banana 2 es el nuevo estándar, Nano Banana Pro sigue disponible para tareas de "Thinking" y casos especializados. Puedes seguir eligiendo Pro para:
Nano Banana 2 se siente como un verdadero sucesor porque reduce drásticamente la "deriva" entre iteraciones, permitiéndote fijar un estilo y mantenerlo de forma fiable a lo largo de escenas, formatos e idiomas.
Entre su mayor persistencia de sujetos, el seguimiento más estricto de instrucciones, el realismo fundamentado en búsqueda y las ediciones conversacionales que ajustan en lugar de redibujar, es mucho más fácil conservar identidad, maquetación y estilo mientras exploras variaciones.
El renderizado de texto a nivel de producción ayuda a mantener la consistencia de la marca, y las relaciones de aspecto flexibles facilitan escalar una campaña entre banners, pósteres e historias móviles. Para equipos que crean storyboards, fotos de producto o creatividades multirregión, aporta repetibilidad sin sacrificar velocidad ni fidelidad.
Nano Banana 2 cierra claramente la brecha entre Nano Banana y Nano Banana Pro: su velocidad está prácticamente a la altura del ritmo casi instantáneo de Flash de Nano Banana, mientras que sus capacidades, fidelidad visual, seguimiento preciso de instrucciones, consistencia de sujetos y realismo basado en búsqueda suelen acercarse mucho a Nano Banana Pro.
Si quieres aprender más sobre los conceptos detrás de herramientas como Nano Banana 2, te recomendamos nuestro curso Generative AI Concepts.
Cursos de IA
programa
Curso
Curso