
Programma
Nozioni di base sugli agenti AI
6 h
Google ha appena rilasciato la seconda iterazione del modello di generazione di immagini, Nano Banana 2. Quando Nano Banana è stato lanciato, ha fatto scalpore, diventando rapidamente il miglior e più veloce modello di generazione di immagini con AI.
In questo articolo, analizziamo nel dettaglio il nuovo modello, esploriamo le sue funzionalità e vediamo come usarlo tramite API con Python.
Se ti interessa in generale la generazione di immagini, ti consiglio di dare un’occhiata alle nostre guide sui seguenti modelli:
Nano Banana 2, noto anche come Gemini 3.1 Flash Image, è il più recente modello all’avanguardia di Google DeepMind per la generazione e modifica di immagini con AI. Unisce la conoscenza del mondo, la qualità e il ragionamento avanzati di Nano Banana Pro alla velocità fulminea di Gemini Flash, rendendo possibile creare contenuti ad alta fedeltà e iterare rapidamente all’interno dello stesso workflow.
Ecco una panoramica delle caratteristiche chiave di Nano Banana 2:
Se sei alle prime armi con Nano Banana, potresti voler leggere prima il nostro articolo sulla prima iterazione di Nano Banana Pro.
In questo articolo vediamo come usare Nano Banana 2 tramite la loro API con Python. Tuttavia, i nuovi modelli sono disponibili in tutto l’ecosistema Gemini:
In questo articolo useremo Nano Banana 2 con l’API, quindi non servirà un abbonamento: pagheremo ogni immagine generata.
Ho trovato la tabella prezzi ufficiale un po’ difficile da interpretare. Di solito i modelli di immagini AI indicano un prezzo fisso per immagine.
Per semplificare, ho fatto dei calcoli stimando il prezzo atteso in base alla dimensione dell’immagine. Nota che non sono prezzi esatti e possono variare leggermente.
|
Dimensione immagine |
Costo per immagine |
|
512px |
$0.045 |
|
1024px (1K) |
$0.067 |
|
2048px (2K) |
$0.101 |
|
4096px (4K) |
$0.151 |
Nano Banana 2 può effettuare ricerche sul web per generare risultati più accurati. È una funzione molto utile, ma va considerata nel prezzo, perché le ricerche comportano un costo aggiuntivo.
Le prime 5.000 query Google Search al mese sono gratuite quando si usa il grounding con Google Search. Dopo, il costo è di $14 per 1.000 query Google Search.
Bando alle ciance, iniziamo con Nano Banana 2.
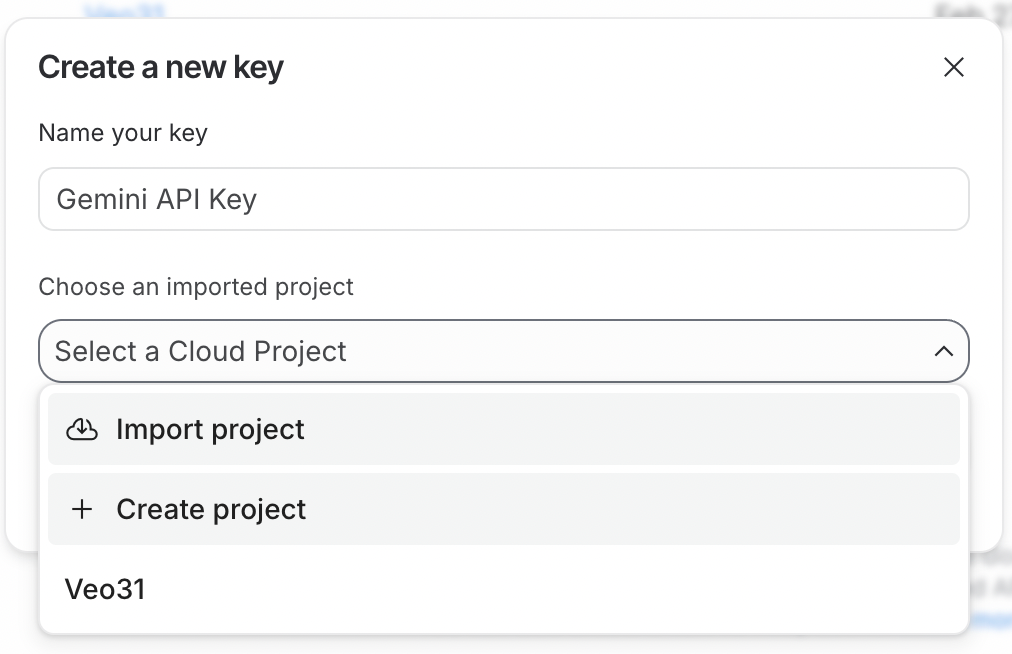
Per usare l’API, dobbiamo prima generare una chiave API. Per farlo, accedi a Google AI Studio. Poi fai clic sul pulsante Create API Key nell’angolo in alto a destra.
La chiave API deve essere collegata a un progetto Google Cloud. Google AI Studio semplifica il tutto permettendoci di creare un progetto direttamente nel processo di generazione della chiave API.
Per usare la chiave API, il progetto Google Cloud a cui è collegata deve avere la fatturazione attiva. Se hai appena creato un nuovo progetto, devi abilitarla facendo clic sul pulsante Set up billing accanto alla chiave API.

Infine, copia la chiave API e incollala in un file chiamato .env con il seguente formato:
GEMINI_API_KEY=<paste_key_here>Questo file .env va creato nella stessa cartella in cui scriveremo gli script Python.
Ora dobbiamo installare le dipendenze Python necessarie per interagire con la Gemini API. Esegui il seguente comando:
pip install google-genai python-dotenv pillowQuesto installa i seguenti pacchetti:
google-genai: Il pacchetto ufficiale di Google per l’AI generativa. Serve per creare facilmente un client per interagire con la Gemini API.
python-dotenv: Un pacchetto di utilità per caricare la chiave API dal file .env.
pillow: Una libreria di immagini per caricare facilmente le immagini da fornire come input a Nano Banana 2.
Ecco il codice Python completo per generare un’immagine:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Lego version of the empire state building being built.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Ecco il risultato:

Nella richiesta sopra, abbiamo specificato le proporzioni con il parametro aspect_ratio e la risoluzione con il parametro image_size.
Nano Banana 2 supporta un’ampia gamma di proporzioni e risoluzioni da 512 pixel fino al 4K. Ecco l’elenco completo dei valori supportati:
aspect_ratio: "1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
image_size (risoluzione): "512px", "1K", "2K", "4K"
Ora che abbiamo configurato tutto e creato con successo la nostra prima immagine, è il momento di mettere alla prova le funzionalità promesse.
Possiamo fornire immagini al modello caricandole con PIL (installato dal pacchetto pillow) e includendole nella lista contents.
Una delle principali caratteristiche di Nano Banana 2 è la capacità di preservare i soggetti durante la generazione di immagini. Provando altri modelli come la precedente iterazione di Nano Banana o GPT-Image, spesso ho rilevato che era difficile generare immagini basate su soggetti reali, perché il modello tendeva ad alterarne l’aspetto.
Dalla documentazione emerge che il modello supporta fino a cinque personaggi e 10 oggetti per un totale di 14 riferimenti. Non definiscono esplicitamente “personaggi” e “oggetti”, ma in modo intuitivo significa che il modello è stato addestrato per generare scene che possono includere fino a 4 soggetti principali e fino a 10 oggetti secondari con cui interagiscono.
Il modello non fornisce parametri espliciti per inviare immagini di personaggi e oggetti. Questo si fa invece nel prompt. Ho ispezionato il codice sorgente di alcune demo per capire come strutturano un prompt che faccia riferimento a questi elementi.
Il template che ho trovato è il seguente:
<subject_name> (<Character #number>) = Image <#index>Ad esempio, con due personaggi chiamati "Alice" e "Bob", sarebbe:
Subjects: Alice (Character 1) = Image 0, Bob (Character 2) = Image 1Di seguito un esempio completo di codice che mostra come far posare insieme due animali domestici, un cane e un gatto, in una foto.
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
from PIL import Image
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Goldie and Wiskers are posing together.
Subjects: Goldie (Character 1) = Image 0, Wiskers (Character 2) = Image 1
Maintain strict subject consistency for characters.
Adjust the subject composition/pose as appropriate for the scene.
"""
dog = Image.open("dog.png")
cat = Image.open("cat.png")
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, dog, cat],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")
Come detto sopra, questo template non fa parte della documentazione ufficiale. Probabilmente il modello riesce a comprendere ogni parte dal prompt e dalle immagini. Tuttavia, quando sviluppiamo un’app reale in cui vogliamo risultati coerenti, è buona pratica essere il più precisi e consistenti possibile nel prompt, quindi consiglio di usare questo template.
Nel loro esempio, il template viene esteso ai riferimenti agli oggetti semplicemente sostituendo "Character" con "Object" per far capire al modello che l’immagine si riferisce a un oggetto e non al soggetto principale.
Per mostrarlo, facciamo indossare al cane occhiali da sole specifici e al gatto un cappello, fornendo due riferimenti a oggetti. Questo è il prompt che ho usato:
Goldie and Wiskers are posing together. Goldie is wearing the Glasses, and Wiskers is wearing the Hat.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1, Glasses (Object 1) = Image 3, Hat (Object 2) = Image 4.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Ecco il risultato:
Nano Banana 2 consente di ancorare la generazione di immagini alla ricerca, così che i risultati siano più accurati. È particolarmente utile quando si generano immagini che devono essere coerenti con la realtà, ad esempio immagini di un luogo o di una specifica specie animale.
Vivo a Taiwan e recentemente c’è stata un’escursione organizzata in cui l’organizzatore ha usato un’immagine generata con Nano Banana per rappresentare il luogo. Tuttavia, l’immagine non era per nulla accurata e le persone sono rimaste deluse perché appariva del tutto diversa dal reale.
Questo mi ha incuriosito e ho voluto vedere se Nano Banana 2 fosse in grado di gestire la cosa.
Possiamo abilitare sia la ricerca web sia la ricerca di immagini usando il parametro tools nella richiesta di generazione.
Ecco un esempio completo:
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Create an image of the Yinhe Cave (銀河洞) in Taiwan at golden hour.
- Use Image Search to search for an image of the specified place.
- Keep the location and the view as close to the real reference as possible.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(), # Enables web search
image_search=types.ImageSearch() # Enables image search
)
))
]
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")Di seguito mostriamo i risultati. Prima, l’immagine reale presa da Google Foto, poi l’immagine generata da Nano Banana 2 usando la ricerca e infine l’immagine generata senza ricerca. Si vede che la ricerca rende i risultati molto accurati.

Il team di Gemini ha creato una demo chiamata Window View che usa questa idea per costruire una piccola app che mostra luoghi specifici attraverso una finestra. È un’ottima dimostrazione della capacità del modello di comprendere il mondo reale.
Dando al modello la capacità di generare luoghi reali con alta precisione, possiamo collocare soggetti specifici in location reali.
Proviamo a collocare Goldie e Wiskers in una località di Taiwan. Ho scelto questa location perché volevo vedere se il modello riesce a gestire luoghi non famosissimi.
Questo era il prompt:
Goldie and Wiskers are traveling across the Sanxiantai Arch Bridge in Taiwan.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.Nota che il prompt chiede esplicitamente al modello di effettuare una ricerca di immagini. Ho notato che, quando si usano strumenti, è sempre meglio richiederne esplicitamente l’uso nel prompt.
Ecco un’immagine dei nostri due personaggi in viaggio insieme:

Per spingerci oltre, ho persino provato a specificare la posizione fornendo latitudine e longitudine, e ha funzionato!
Goldie and Wiskers are at the location with a latitude of 17.0621186 and a longitude of -96.7255102.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.
Anche se la location non corrisponde esattamente a quelle coordinate, gli elementi dell’immagine corrispondono a ciò che si vede in quel luogo, il che è piuttosto impressionante secondo me.
Nano Banana 2 migliora i precedenti modelli di immagini basati su Flash offrendo una resa del testo più coerente e affidabile.
Ora il testo può apparire nitido e accurato quanto la grafica circostante. Nano Banana 2 abilita anche la localizzazione in‑image, rendendo possibile creare o tradurre testo in più lingue direttamente nell’immagine generata.
Ho testato la localizzazione generando un poster per un marchio fittizio di visori per realtà virtuale chiamato "Beyond Reality". Poi ho semplicemente usato un prompt come:
Change the language of the poster to Japanese.Ecco i risultati dopo aver cambiato la lingua del testo del poster prima in francese e poi in giapponese:

Interessante notare che il modello è stato abbastanza intelligente da non tradurre il nome del brand, anche se non era specificato nel prompt.
L’ultima funzione che esploriamo è la modalità conversazione. Gli esempi precedenti non sono interattivi. Inviamo una richiesta all’API e otteniamo un risultato. Se vogliamo iterare su quel risultato, dobbiamo costruire una nuova richiesta con quell’immagine e le modifiche desiderate.
Un modo migliore è usare la modalità chat. In modalità chat, creiamo una chat con la funzione client.chats.create(), poi inviamo messaggi avanti e indietro con la funzione client.send_message(). Possiamo usarla per implementare un workflow di editing in chat:
Ecco uno script completo che implementa questo flusso:
from google import genai
from google.genai import types
from dotenv import load_dotenv
from PIL import Image
import time
load_dotenv()
client = genai.Client()
# Initialize the chat session
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
# We keep track of the latest image object to send back as context
latest_image = None
while True:
user_input = input("\nPrompt: ")
if user_input.lower() in ['quit', 'exit', 'q']:
break
# Construct the message content
# If we have a previous image, we include it so the model knows what to edit
content = [user_input]
if latest_image:
content.append(latest_image)
try:
response = chat.send_message(content)
for part in response.parts:
# Handle Text Response
if part.text:
print(f"\nAI: {part.text}")
elif part.inline_data is not None:
image = part.as_image()
filename = f"image_{int(time.time())}.png"
image.save(filename)
print("Saved image", filename)
latest_image = Image.open(filename)
latest_image.show()
except Exception as e:
print(f"An error occurred: {e}")
print("Session ended.")Eseguendo questo script, possiamo modificare un’immagine iterativamente direttamente dal terminale così:
Ecco i risultati di questa interazione:

La tabella seguente evidenzia le principali differenze tra i modelli Nano Banana. Come detto, la nuova versione porta notevoli miglioramenti in accuratezza, coerenza e risoluzione, risultando solo leggermente più lenta della prima iterazione.

La tabella è stata in realtà generata da Nano Banana 2 fornendogli i dati.
Anche se Nano Banana 2 è il nuovo standard, Nano Banana Pro resta disponibile per attività “Thinking” e specialistiche. Potresti scegliere ancora Pro per:
Nano Banana 2 sembra un vero successore perché riduce drasticamente la “deriva” tra iterazioni, permettendoti di fissare uno stile e mantenerlo in modo affidabile tra scene, formati e lingue.
Tra una maggiore persistenza del soggetto, un’adesione più stretta alle istruzioni, un realismo ancorato alla ricerca e modifiche conversazionali che affinano invece di ridisegnare, è molto più semplice mantenere intatti identità, layout e stile mentre esplori variazioni.
Una resa del testo di livello produttivo aiuta a mantenere coerenti gli elementi di brand, e le proporzioni flessibili rendono fluida la scalabilità di una campagna tra banner, poster e storie mobile. Per i team che creano storyboard, foto prodotto o creatività multi‑locale, offre ripetibilità senza sacrificare velocità o fedeltà.
Nano Banana 2 colma nettamente il divario tra Nano Banana e Nano Banana Pro: la sua velocità è di fatto vicina al ritmo quasi istantaneo di Flash di Nano Banana, mentre capacità, fedeltà visiva, aderenza precisa alle istruzioni, coerenza del soggetto e realismo ancorato alla ricerca spesso si avvicinano a Nano Banana Pro.
Se vuoi approfondire i concetti alla base di strumenti come Nano Banana 2, ti consiglio il nostro corso Generative AI Concepts.
Corsi di AI
Programma
Corso
Corso
blog
Abid Ali Awan
15 min
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min

