Tracks
AIエージェントの基礎
6時間
Googleは画像生成モデルの第2世代、Nano Banana 2をリリースしました。初代のNano Bananaが登場したときは世界中で話題となり、最良かつ最速のAI画像生成モデルとして急速に支持を集めました。
本記事では新モデルを詳しく掘り下げ、追加された機能を紹介し、PythonからAPI経由での使い方を学びます。
画像生成に関心がある場合は、次のモデルに関するガイドもぜひご覧ください。
Nano Banana 2(別名 Gemini 3.1 Flash Image)は、Google DeepMindの最新鋭の画像生成・編集AIモデルです。Nano Banana Proの高度な世界知識・品質・推論力と、Gemini Flashの超高速性を融合し、高い忠実度のクリエイションと素早い反復を同一ワークフローで実現します。
Nano Banana 2の主な特徴は以下のとおりです。
Nano Bananaを初めて使う場合は、まず初代のNano Banana Proに関する前回の記事を読むことをおすすめします。
本記事では、PythonからAPIを使ってNano Banana 2を利用する方法を扱います。なお、新モデルはGeminiエコシステム全体で利用可能です。
本記事ではAPI経由でNano Banana 2を使用するため、サブスクリプションは不要で、生成する画像ごとに課金されます。
公式の料金表はややわかりにくいと感じました。多くのAI画像モデルは、通常、1画像あたりの固定価格を示しています。
そこで、画像サイズ別のおおよその予想価格を試算しました。これはあくまで目安で、多少の変動があり得る点にご注意ください。
|
画像サイズ |
画像あたりの費用 |
|
512px |
$0.045 |
|
1024px(1K) |
$0.067 |
|
2048px(2K) |
$0.101 |
|
4096px(4K) |
$0.151 |
Nano Banana 2は、より正確な結果を得るためにウェブ検索を実行できます。非常に便利な機能ですが、検索には追加コストが発生するため、料金計算に含める必要があります。
Google検索によるグラウンディングを使用する場合、月間最初の5,000件の検索クエリは無料です。それ以降は1,000件あたり$14かかります。
それでは、さっそくNano Banana 2を使ってみましょう。
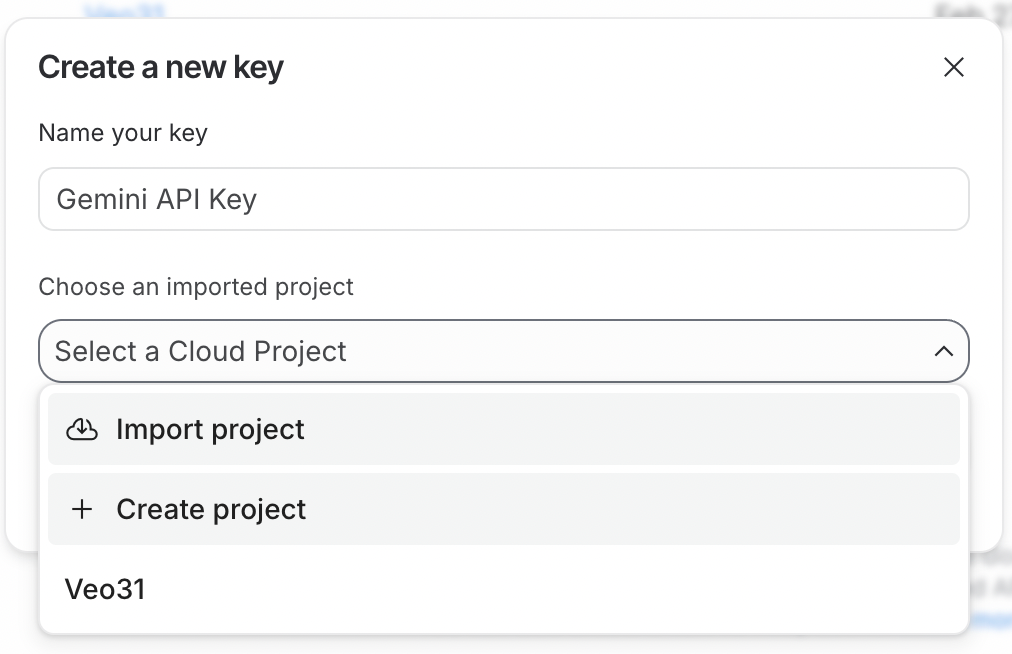
APIを使うには、まずAPIキーを作成する必要があります。まずGoogle AI Studioにサインインし、右上のCreate API Keyボタンをクリックします。
APIキーはGoogle Cloudプロジェクトに紐づける必要があります。Google AI Studioでは、APIキー作成フローの中で直接プロジェクトを作成できるため簡単です。
APIキーを使用するには、紐づくGoogle Cloudプロジェクトで課金を有効化する必要があります。新規にプロジェクトを作成した場合は、APIキーの横にあるSet up billing ボタンをクリックして有効化してください。

最後にAPIキーをコピーし、次の形式で.envという名前のファイルに貼り付けます。
GEMINI_API_KEY=<paste_key_here>この.envファイルは、これからPythonスクリプトを書くのと同じフォルダに作成してください。
次に、Gemini APIとやり取りするために必要なPython依存パッケージをインストールします。以下のコマンドを実行してください。
pip install google-genai python-dotenv pillowこれにより、以下のパッケージがインストールされます。
google-genai:Googleの公式生成AIパッケージ。Gemini APIとやり取りするクライアントを簡単に作成できます。
python-dotenv:.envファイルからAPIキーを読み込むユーティリティ。
pillow:画像ライブラリ。Nano Banana 2への入力として画像を読み込むのに役立ちます。
画像を生成するための完全なPythonコードは次のとおりです。
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Lego version of the empire state building being built.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="16:9",
image_size="4K",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")結果は次のとおりです。

上記リクエストでは、aspect_ratioパラメータでアスペクト比を、image_sizeパラメータで解像度を指定しました。
Nano Banana 2は、512ピクセルから4Kまで、幅広いアスペクト比と解像度に対応しています。サポートされる値の一覧は以下のとおりです。
aspect_ratio:"1:1","1:4","1:8","2:3","3:2","3:4","4:1","4:3","4:5","5:4","8:1","9:16","16:9","21:9"
image_size(解像度):"512px", "1K", "2K", "4K"
環境構築が完了し、最初の画像も生成できたので、宣伝されている機能を実際に試してみましょう。
pillowパッケージでインストールしたPILを使って画像を読み込み、contentsリストに含めることでモデルに画像を提供できます。
Nano Banana 2の主な特徴の1つは、画像生成時に被写体の特徴を保てることです。以前のNano BananaやGPT-Imageなど他モデルを試した際には、実在の被写体を元に画像を作るのが難しく、見た目が変わってしまいがちでした。
ドキュメントによると、モデルは最大で5人のキャラクターと10個のオブジェクト、合計14の参照に対応します。キャラクターとオブジェクトの厳密な定義は示されていませんが、直感的には、最大4つの主要な被写体と、その被写体が関わる最大10の副次的なオブジェクトを同一シーンに配置できるように訓練されている、という意味合いです。
キャラクター画像やオブジェクトを渡すための専用パラメータはありません。プロンプト内で指定します。いくつかのデモのソースコードを確認し、参照方法として使われているプロンプト構造を調べました。
見つかったテンプレートは以下のとおりです。
<subject_name> (<Character #number>) = Image <#index>たとえば、キャラクターが「Alice」と「Bob」の2人なら次のようになります。
Subjects: Alice (Character 1) = Image 0, Bob (Character 2) = Image 1以下は、犬と猫という2匹のペットを一緒に写した写真を生成する完全なコード例です。
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
from PIL import Image
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Goldie and Wiskers are posing together.
Subjects: Goldie (Character 1) = Image 0, Wiskers (Character 2) = Image 1
Maintain strict subject consistency for characters.
Adjust the subject composition/pose as appropriate for the scene.
"""
dog = Image.open("dog.png")
cat = Image.open("cat.png")
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt, dog, cat],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")
前述のテンプレートは公式ドキュメントの一部ではありません。モデルはプロンプトと画像から各要素を理解できる可能性があります。しかし、実運用のアプリケーションで安定した結果を得るには、プロンプトをできるだけ正確かつ一貫させるのがベストプラクティスです。そのため、このテンプレートの使用を推奨します。
サンプルでは、オブジェクト参照に対しては「Character」を「Object」に置き換えるだけで、画像が主要被写体ではなくオブジェクトであることをモデルに伝えています。
これを示すために、犬に特定のサングラス、猫に帽子を被せるよう、2つのオブジェクト参照を与えてみます。使用したプロンプトは次のとおりです。
Goldie and Wiskers are posing together. Goldie is wearing the Glasses, and Wiskers is wearing the Hat.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1, Glasses (Object 1) = Image 3, Hat (Object 2) = Image 4.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.結果は次のとおりです。
Nano Banana 2は、検索で生成をグラウンディングすることで、より正確な結果を得られます。場所や特定の動物種など、現実と整合する必要がある画像の生成に特に有用です。
私は台湾に住んでいるのですが、最近、主催者がハイキング場所のイメージとしてNano Bananaで生成した画像を使ったイベントがありました。しかし、その画像は実際とまったく異なっており、参加者は落胆しました。
これをきっかけに、Nano Banana 2でどこまで対応できるのか試してみました。
生成リクエストのtoolsパラメータで、ウェブ検索と画像検索の両方を有効にできます。
完全な例は次のとおりです。
from google import genai
from dotenv import load_dotenv
from google.genai import types
import time
# Load API key
load_dotenv()
client = genai.Client()
prompt = """
Create an image of the Yinhe Cave (銀河洞) in Taiwan at golden hour.
- Use Image Search to search for an image of the specified place.
- Keep the location and the view as close to the real reference as possible.
"""
# Make API request
response = client.models.generate_content(
model="gemini-3.1-flash-image-preview",
contents=[prompt],
config=types.GenerateContentConfig(
response_modalities=["Image"],
image_config=types.ImageConfig(
aspect_ratio="9:16",
),
tools=[
types.Tool(google_search=types.GoogleSearch(
search_types=types.SearchTypes(
web_search=types.WebSearch(), # Enables web search
image_search=types.ImageSearch() # Enables image search
)
))
]
)
)
# Save the image and display output text if any
for part in response.parts:
if part.text is not None:
print(part.text)
elif part.inline_data is not None:
image = part.as_image()
image.save(f"image_{int(time.time())}.png")以下に結果を示します。最初にGoogleフォトからの実際の画像、次に検索を使ってNano Banana 2が生成した画像、最後に検索なしで生成した画像です。検索を使うことで非常に正確になるのがわかります。

Geminiチームは、Window Viewというデモを作成し、窓から見える特定の場所を表示する小さなアプリとして、このアイデアを活用しています。モデルの実世界理解を示す好例です。
実在のロケーションを高精度に生成できるため、特定の被写体を現実の場所に配置できます。
台湾のある場所にGoldieとWiskersを配置してみます。世界的に有名ではない場所でも対応できるかを確認したかったため、この場所を選びました。
使用したプロンプトは次のとおりです。
Goldie and Wiskers are traveling across the Sanxiantai Arch Bridge in Taiwan.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.プロンプトで明示的に画像検索の実行を指示している点に注目してください。ツールを使う際は、プロンプトでも明確に指示する方がうまくいくと感じました。
2匹が一緒に旅をしている画像がこちらです。

さらに踏み込み、緯度・経度を指定して場所を与えてみたところ、うまくいきました。
Goldie and Wiskers are at the location with a latitude of 17.0621186 and a longitude of -96.7255102.
Subjects: Goldie (Pet 1) = Image 0, Wiskers (Pet 2) = Image 1
Use image search to find visual references of the location.
Maintain strict subject consistency for characters and objects.
Adjust the subject composition/pose as appropriate for the scene.
緯度・経度が完全一致ではなくても、その場所で見られる要素が画像に反映されており、非常に印象的です。
Nano Banana 2は、従来のFlash系画像モデルよりも一貫性が高く、信頼できるテキスト描画を提供します。
テキストは周囲のグラフィックと同等にシャープかつ正確に表示されます。さらに、画像内ローカライズに対応し、生成画像の中で複数言語へのテキスト作成・翻訳が可能になりました。
検証として、架空のVRヘッドセットブランド「Beyond Reality」のポスターを生成し、次のようなプロンプトで言語を変更してみました。
Change the language of the poster to Japanese.ポスターのテキストをフランス語、さらに日本語へと変更した結果がこちらです。

ブランド名を翻訳しないという判断を、プロンプトで明示していないにもかかわらず、モデルが適切に行った点は興味深いところです。
最後に取り上げるのは会話モードです。これまでの例はインタラクティブではありません。APIにリクエストを送り、結果を受け取るだけで、結果を反復したい場合は、その画像と変更点を含む新しいリクエストを組み立てる必要がありました。
より良い方法はチャットモードを使うことです。チャットモードでは、client.chats.create()でチャットを作成し、client.send_message()でメッセージをやり取りします。これを使えば、次のようなチャット編集ワークフローを実装できます。
このフローを実装する完全なスクリプトは次のとおりです。
from google import genai
from google.genai import types
from dotenv import load_dotenv
from PIL import Image
import time
load_dotenv()
client = genai.Client()
# Initialize the chat session
chat = client.chats.create(
model="gemini-3.1-flash-image-preview",
config=types.GenerateContentConfig(
response_modalities=['TEXT', 'IMAGE'],
tools=[{"google_search": {}}]
)
)
# We keep track of the latest image object to send back as context
latest_image = None
while True:
user_input = input("\nPrompt: ")
if user_input.lower() in ['quit', 'exit', 'q']:
break
# Construct the message content
# If we have a previous image, we include it so the model knows what to edit
content = [user_input]
if latest_image:
content.append(latest_image)
try:
response = chat.send_message(content)
for part in response.parts:
# Handle Text Response
if part.text:
print(f"\nAI: {part.text}")
elif part.inline_data is not None:
image = part.as_image()
filename = f"image_{int(time.time())}.png"
image.save(filename)
print("Saved image", filename)
latest_image = Image.open(filename)
latest_image.show()
except Exception as e:
print(f"An error occurred: {e}")
print("Session ended.")このスクリプトを実行すると、ターミナル上で画像を段階的に編集できます。
このやり取りの結果は次のとおりです。

以下の表は、Nano Banana各モデルの主な違いを示します。前述のとおり、新バージョンは精度・一貫性・解像度が大幅に向上し、初代よりわずかに遅い程度で動作します。

この表は、データを与えてNano Banana 2に生成させたものです。
Nano Banana 2が新たな標準ではあるものの、Nano Banana Proは「Thinking」や専門的なタスク向けに引き続き利用可能です。次のような場合はProを選ぶのがよいでしょう。
Nano Banana 2は、反復を重ねても見た目がぶれにくく、好みのスタイルを固定してシーンやフォーマット、言語をまたいで安定して適用できる、真の後継モデルだと感じられます。
被写体の持続性の強化、指示追従の厳密化、検索に根ざした現実整合、そして「描き直し」ではなく微調整していく会話型編集により、バリエーションを探ってもアイデンティティ、レイアウト、スタイルを保ちやすくなりました。
本番レベルのテキスト描画によりブランド要素の一貫性が保ちやすく、柔軟なアスペクト比によってバナー、ポスター、モバイルストーリーへのスケーリングもスムーズです。ストーリーボード、商品写真、多言語クリエイティブを制作するチームにとって、スピードや忠実度を犠牲にせず再現性をもたらします。
Nano Banana 2は、Nano BananaとNano Banana Proのギャップを的確に埋めます。速度はほぼNano BananaのFlash並みに近く、能力、視覚的忠実度、正確な指示追従、被写体の一貫性、検索に根ざした現実整合は、しばしばNano Banana Proに迫ります。
Nano Banana 2の背後にある考え方をさらに学びたい場合は、Generative AI Conceptsコースをおすすめします。
AI講座
Tracks
Courses
Courses