
Curso
Entendendo o Microsoft Azure
3 h
47.1K
À medida que os aplicativos são escalonados globalmente, os bancos de dados tradicionais geralmente não são suficientes. O Azure Cosmos DB, o banco de dados multimodelo e globalmente distribuído da Microsoft, oferece acesso de baixa latência, vários modelos de consistência e dimensionamento contínuo entre regiões.
Este guia aborda conceitos-chave como contêineres, itens e APIs SQL, essenciais para qualquer engenheiro de nuvem que queira começar (e trabalhar) com o Azure e o Cosmos DB. Você terá uma visão geral prática de sua arquitetura e saberá por que ela é a melhor opção para aplicativos nativos da nuvem e de missão crítica.
O Azure Cosmos DB é um banco de dados NoSQL totalmente gerenciado no Microsoft Azure, criado para oferecer alta disponibilidade, baixa latência e escalabilidade global. Ele oferece suporte a vários modelos de dados, incluindo documento, valor-chave, gráfico e família de colunas, o que o torna flexível para diversos aplicativos.
Seu principal ponto forte é a distribuição global: Com alguns cliques, os dados podem ser replicados entre as regiões do Azure para que você tenha acesso rápido e local.
Os desenvolvedores também podem escolher entre vários modelos de consistência para equilibrar o desempenho e a precisão dos dados. Se você é novo no mundo do Azure, recomendo fortemente que leia o seguinte guia para iniciantes no Azure.
O Azure Cosmos DB oferece um poderoso conjunto de recursos adaptados para a criação de aplicativos escalonáveis e de alto desempenho:
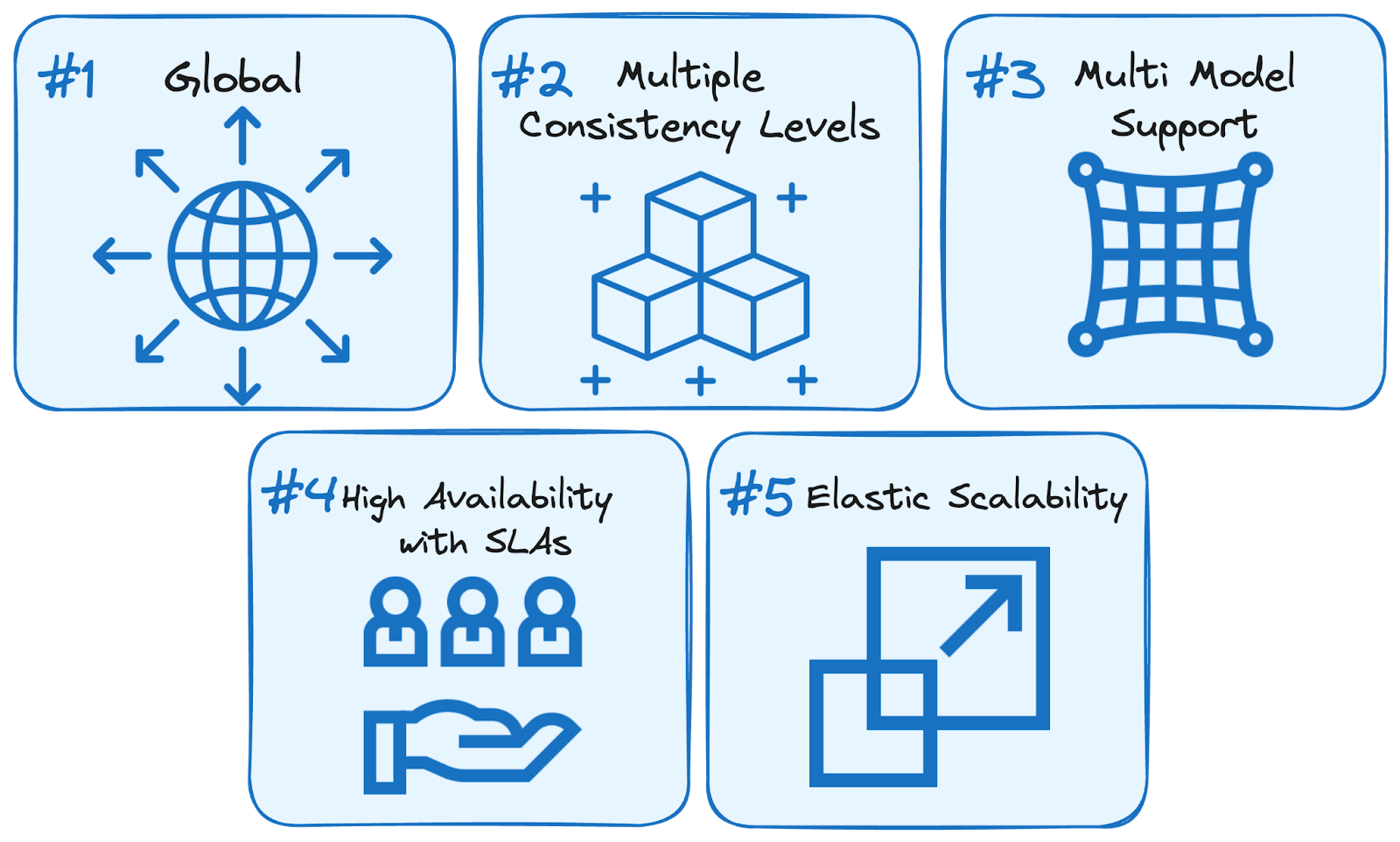
Imagem do autor. Por que usar o Cosmos DB?
Juntos, esses recursos tornam o Cosmos DB uma base sólida para aplicativos nativos da nuvem distribuídos globalmente que exigem desempenho e resiliência em tempo real.
O Azure Cosmos DB é uma opção versátil para aplicativos escalonáveis e em tempo real em vários setores. Sua arquitetura distribuída globalmente e de baixa latência o torna ideal para cenários que exigem alta disponibilidade e acesso rápido aos dados. Aqui estão alguns casos de uso importantes:
Desde a alimentação de lojas on-line até a habilitação de aplicativos inteligentes orientados por IA, o Cosmos DB oferece a velocidade, a escala e a flexibilidade necessárias para soluções modernas nativas da nuvem. Para entender melhor o que você pode fazer com o Cosmos DB e o Azure, consulte o seguinte Guia de ofertas de nuvem da Microsoft.
Nesta seção, exploraremos os principais recursos que permitem que os desenvolvedores criem aplicativos rápidos, resilientes e inteligentes, incluindo estratégias de modelagem de dados.
O Azure Cosmos DB permite que os contêineres armazenem documentos JSON sem a necessidade de um esquema predefinido, facilitando a adaptação e a evolução do seu modelo de dados ao longo do tempo.
A indexação no Cosmos DB é automática por padrão, com todos os campos indexados para oferecer suporte a consultas rápidas prontas para uso. No entanto, isso pode levar a um aumento no consumo de unidades de solicitação (RU), especialmente em cargas de trabalho com muita gravação. Para otimizar, os desenvolvedores podem definir políticas de indexação personalizadas. Essas políticas permitem desativar a indexação automática quando desnecessária, especificando caminhos incluídos para campos que devem ser indexados e excluindo campos que não são relevantes.
O Cosmos DB também inclui o recursoChange Feed , que captura inserções e atualizações em tempo real, o que o torna ideal para a criação de sistemas orientados por eventos, acionando fluxos de trabalho ou transmitindo dados para o downstream. Outro recurso útil é o Time-to-Live (TTL), que permite a exclusão automática de documentos após um período especificado.
Para cargas de trabalho que exigem muita gravação, as chaves de partição devem ter alta cardinalidade e distribuição uniforme, como IDs de usuário, registros de data e hora ou regiões geográficas, para evitar partições quentes e limitação. Em cenários de leitura intensa, geralmente é mais eficaz agrupar dados relacionados usando chaves de partição, como IDs de clientes, permitindo acesso eficiente a consultas de intervalo ou ponto. Um particionamento ruim pode levar a uma distribuição desigual dos dados e à degradação do desempenho. Como cada partição lógica é limitada a 20 GB, é importante projetar estratégias de particionamento que evitem sobrecarregar uma única chave.
O desempenho da consulta pode ser aprimorado ainda mais com a criação de padrões de acesso direcionados a partições únicas, pois eles são mais rápidos e eficientes em termos de recursos. As consultas entre partições, embora suportadas, normalmente resultam em latência mais alta e maior consumo de RU, porque elas examinam várias partições. Para reduzir os custos de consulta, os desenvolvedores devem aproveitar as estratégias de indexação (estou pensando em índices compostos) e considerar a aplicação de mecanismos de cache para dados acessados com frequência.
Em termos de taxa de transferência, o Cosmos DB permite que os desenvolvedores configurem as Request Units no nível do contêiner ou do banco de dados. Esse modelo de taxa de transferência ajustável ajuda a garantir que seu aplicativo mantenha o desempenho mesmo quando você estiver passando por algum tipo de condição de pico de carga.
O Azure Cosmos DB oferece cinco níveis de consistência ajustáveis. Isso vai muito além das opções típicas de consistência eventual ou forte encontradas na maioria dos bancos de dados não relacionais.
No nível mais fraco, a consistência eventual oferece a opção mais rápida e mais disponível, mas pode retornar dados obsoletos ou fora de ordem à medida que as réplicas são sincronizadas gradualmente. Um pouco mais forte é o prefixo consistente, que garante que as leituras reflitam a ordem das gravações, embora não necessariamente as mais recentes, o que o torna adequado quando a ordem das operações é mais importante do que o frescor.
A configuração padrão e mais prática para muitos aplicativos é a consistência da sessão, que garante que um cliente sempre lerá suas gravações em uma sessão. A estanqueidade limitada vai um passo além, permitindo um atraso controlado entre gravações e leituras, definido por um intervalo de tempo (T) ou por várias versões (K). Por exemplo, em uma única região, o atraso pode ser limitado a 5 segundos ou 10 versões, enquanto em uma configuração de várias regiões, ele pode se estender a 5 minutos ou 100.000 versões.
Na extremidade mais forte do espectro está a consistência forte, que garante que todas as leituras reflitam a última gravação confirmada em todas as réplicas. Esse nível oferece as garantias mais rigorosas, evitando leituras obsoletas, sujas ou fantasmas, e se assemelha muito ao comportamento dos sistemas tradicionais compatíveis com ACID.
Um dos recursos de destaque do Azure Cosmos DB é o suporte de gravação em várias regiões por meio da replicação ativa-ativa (vários mestres). Isso permite que os aplicativos executem operações de gravação em várias regiões simultaneamente, reduzindo significativamente a latência para usuários de todo o mundo.
O Cosmos DB também inclui replicação global automática, garantindo que os dados sejam sincronizados entre as regiões do Azure. No caso de uma interrupção regional, o sistema aciona o failover automático para a próxima região disponível.
Embora o Cosmos DB lide automaticamente com a mecânica de sharding e distribuição de dados, os desenvolvedores ainda precisam escolher uma chave de partição adequada para oferecer suporte à distribuição uniforme e ao dimensionamento horizontal eficaz. Essa decisão é especialmente importante para conjuntos de dados grandes que podem exceder o limite de 20 GB por partição lógica. O planejamento antecipado do particionamento ajuda a evitar gargalos e problemas de desempenho à medida que o aplicativo cresce.
O preço do Azure Cosmos DB é baseado em Unidades de Solicitação (RUs), que refletem os recursos usados para leituras, gravações e consultas. Uma simples leitura de ponto normalmente custa 1 RU.
Antes de trabalhar com o Azure Cosmos DB, você precisará criar uma conta, escolher sua configuração e criar seu primeiro banco de dados e contêiner. Este guia passo a passo guiará você pelo processo usando o Portal do Azure.
Comece fazendo login no Portal do Azure. Nabarra de pesquisa globalna parte superior, digite "Azure Cosmos DB" e selecione-o nos resultados. Na folha do Cosmos DB, clique em "Create" para começar a configurar sua nova instância.
Captura de tela da página de destino principal do Azure
Captura de tela da página de destino principal do Azure Cosmos DB
Selecione Azure Cosmos DB para NoSQL como seu modelo de API (API Core SQL).
Captura de tela do Azure Cosmos DB. Criando uma instância
Em seguida, no painel Básico, insira os detalhes da configuração, incluindo a assinatura do Azure, um grupo de recursos (novo ou existente), um nome de conta globalmente exclusivo e uma região preferida do Azure. As zonas de disponibilidade podem ser deixadas desativadas. O Cosmos DB oferece dois modos de taxa de transferência: taxa de transferência provisionada para cargas de trabalho previsíveis e sem servidor para cenários variáveis ou de baixo tráfego. Escolha o modo que melhor se adapta às necessidades de seu aplicativo durante a configuração. Essas opções também podem ser ajustadas posteriormente, conforme a evolução da carga de trabalho.
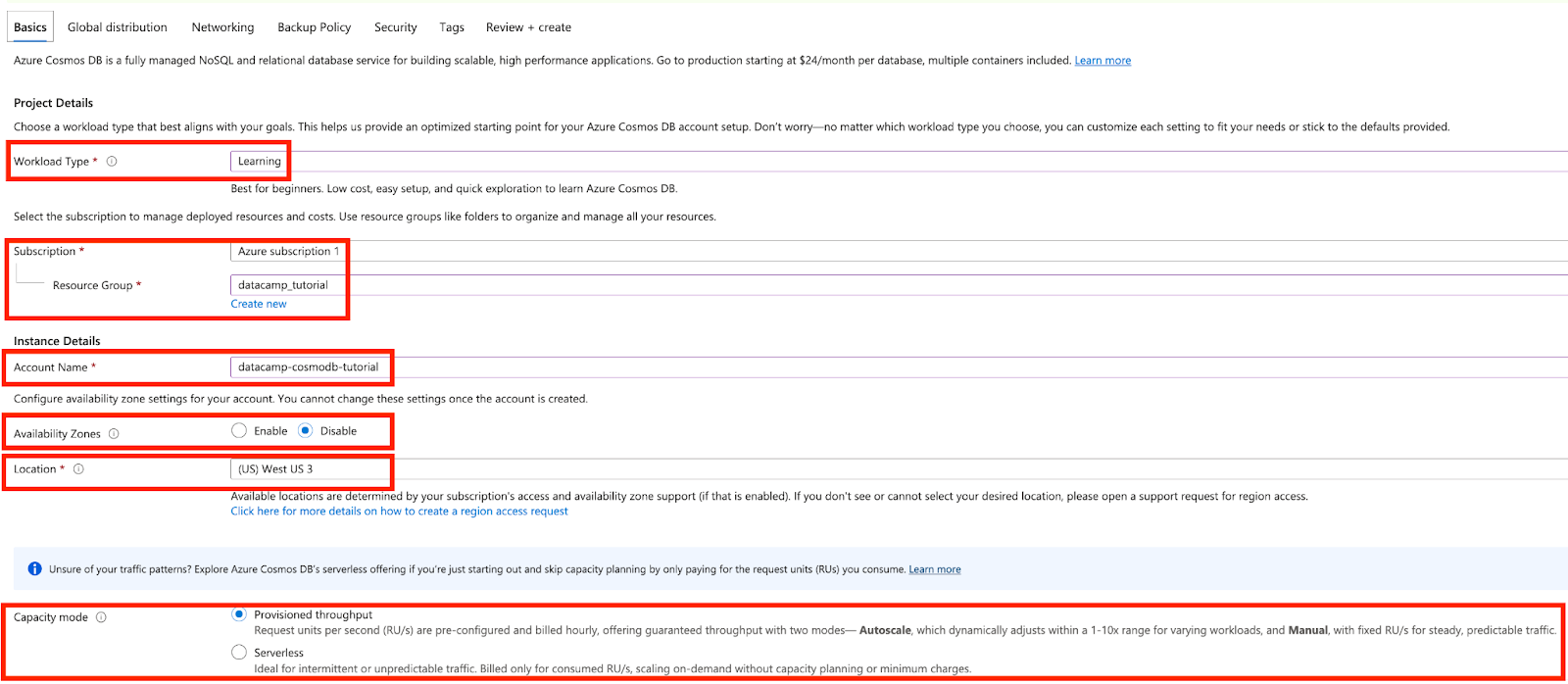
Captura de tela do Azure Cosmos DB. Preenchendo os detalhes
Depois de concluído, clique em Revisar + Criare, em seguida, confirme clicando em Criar para iniciar a implementação.
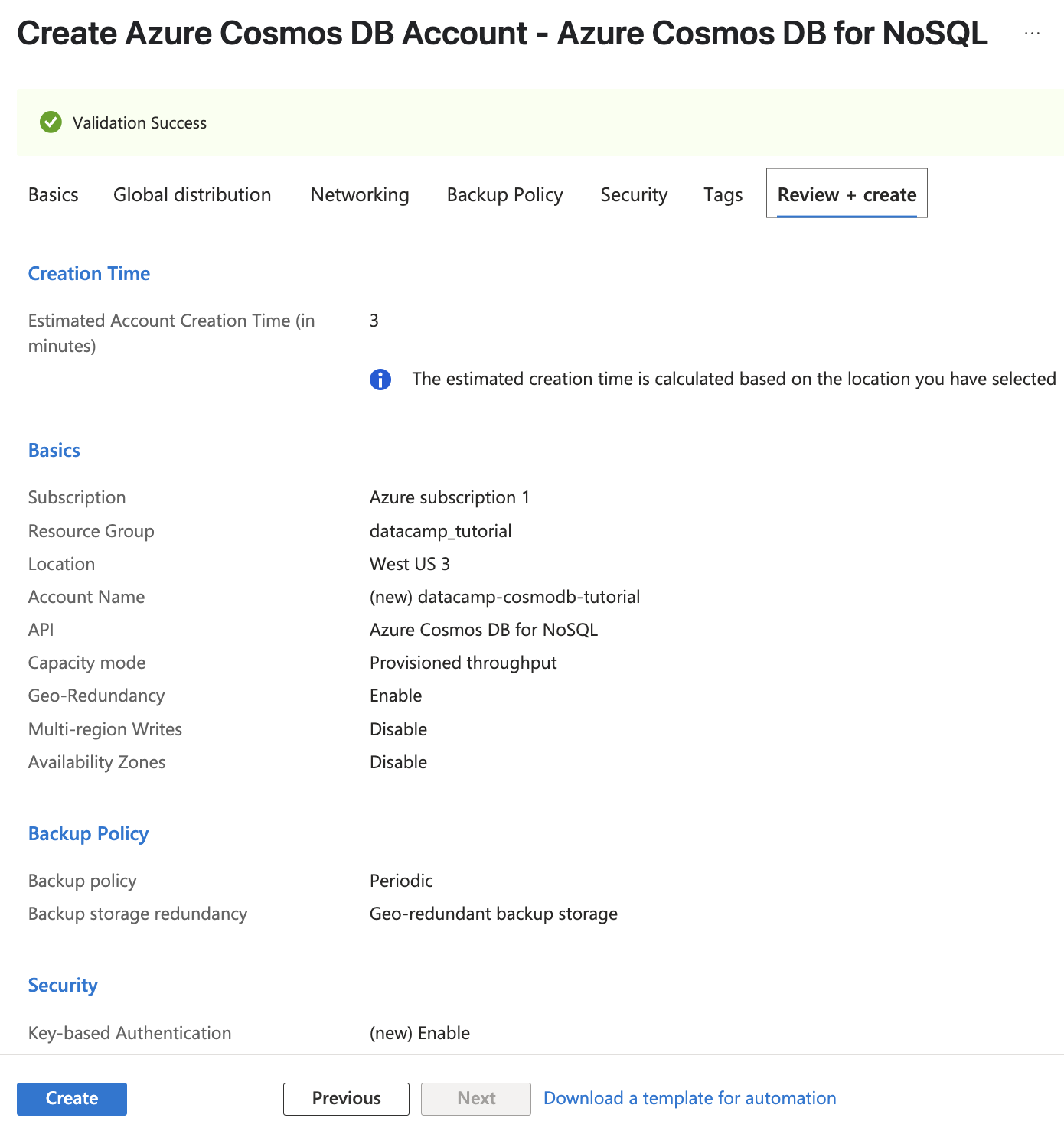
Captura de tela do Azure Cosmos DB. Validando nossa instância
Quando a implantação for concluída, selecione Ir para o recurso para acessar sua nova conta do Cosmos DB.
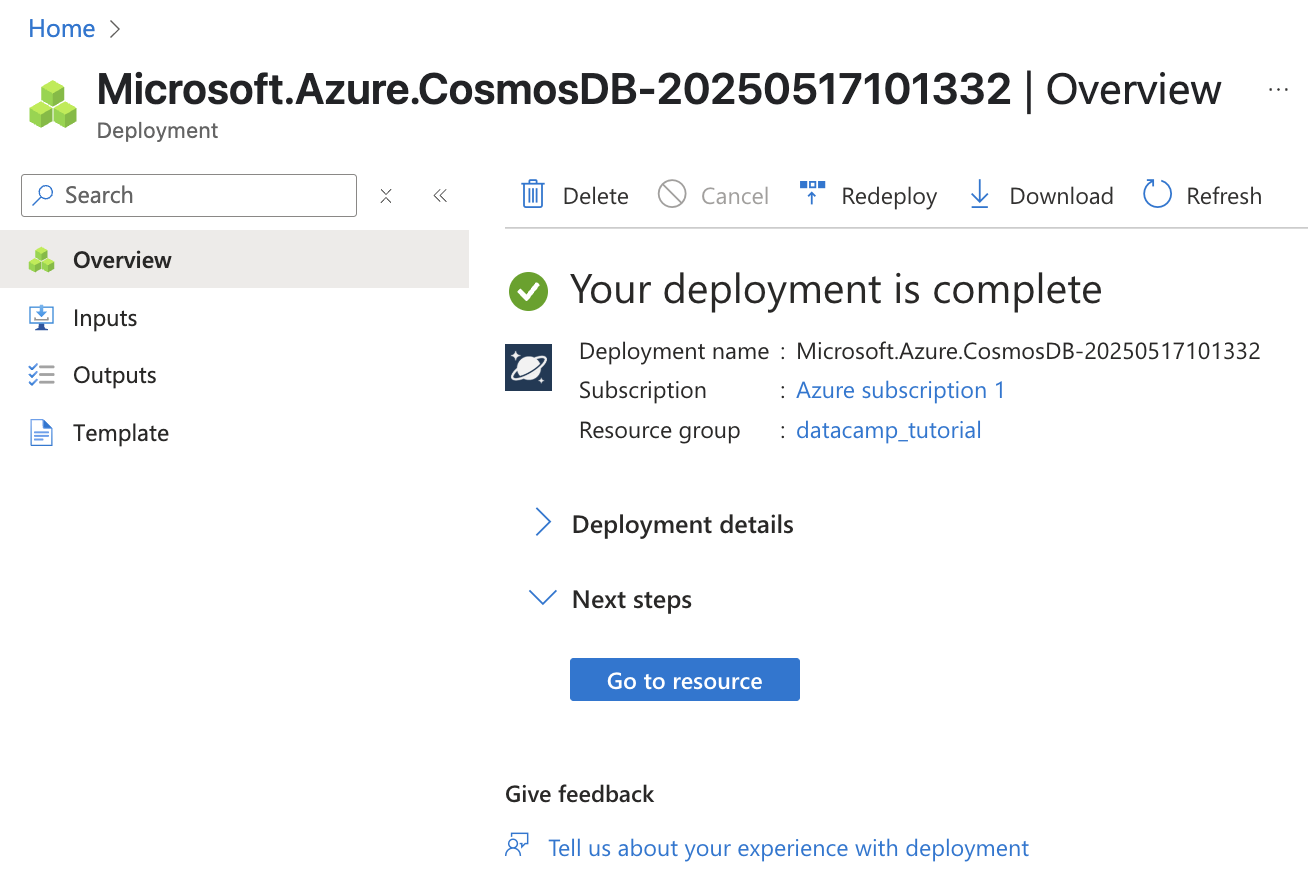
Captura de tela do Azure Cosmos DB. Informações sobre o recurso que acabamos de criar
Navegue até o Explorador de dados a partir do Cosmos DB menu da conta.
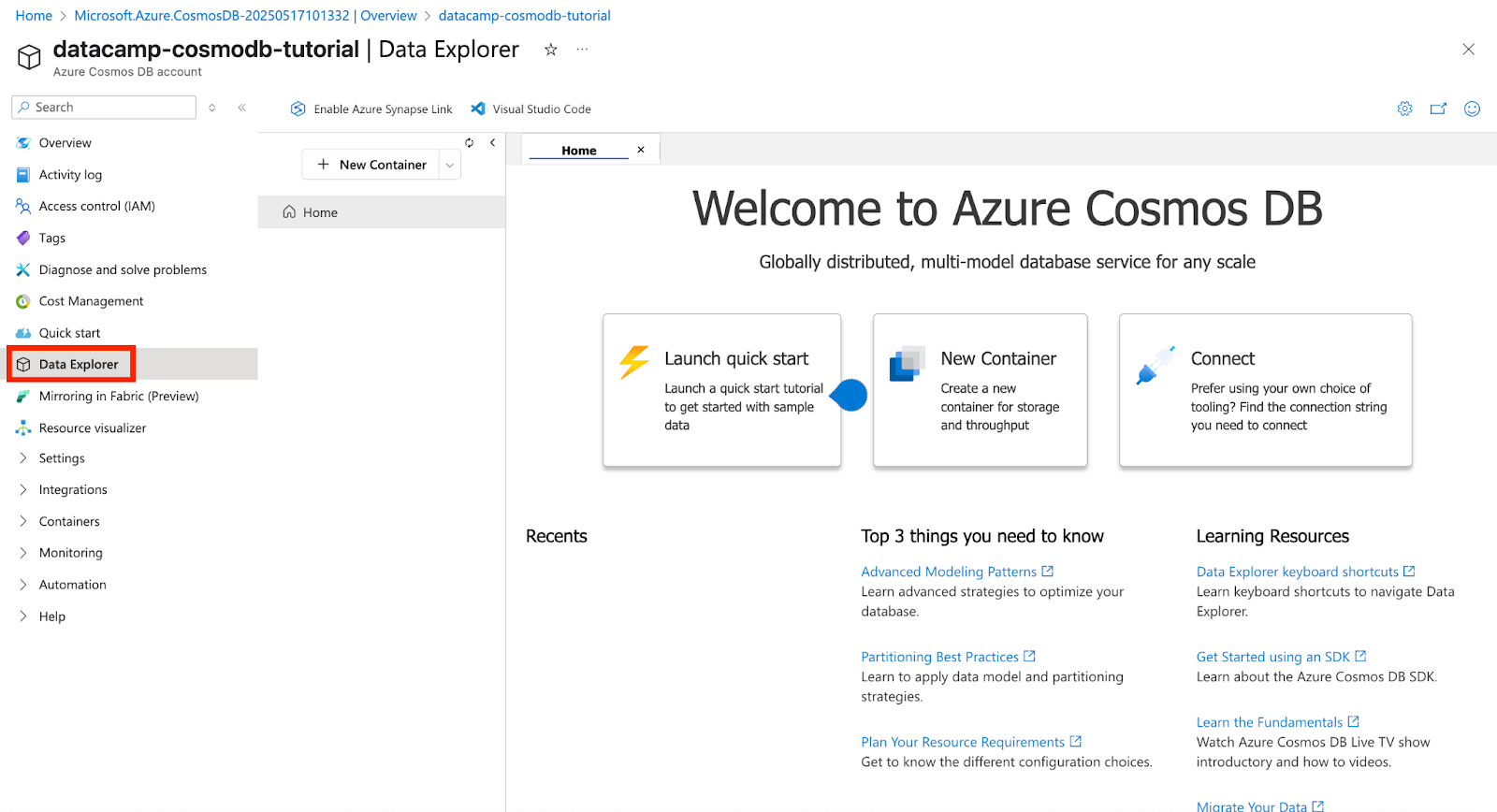
Captura de tela do Azure Cosmos DB. Explorando nossos dados
Clique em New Container ( Novo contêiner ) para abrir a caixa de diálogo de configuração.
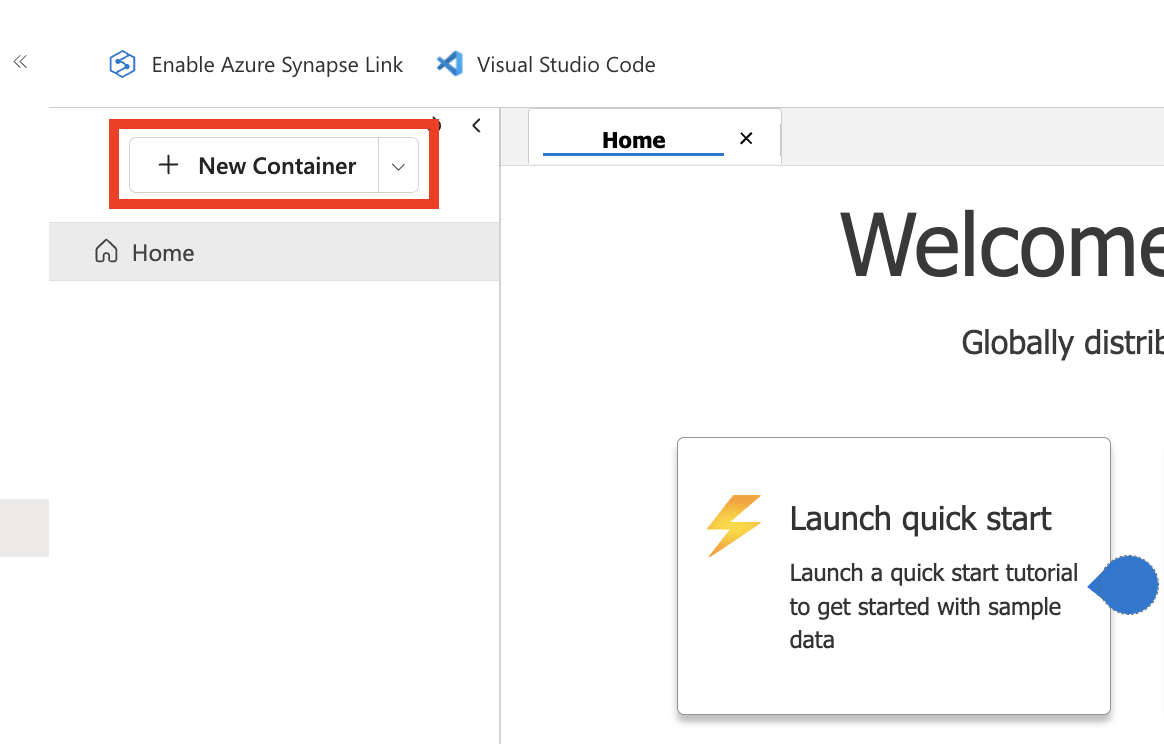
Captura de tela do Azure Cosmos DB. Criando um novo contêiner
Defina um novo nome de banco de dados e um nome de contêiner e, o mais importante, especifique uma chave de partição para garantir a distribuição uniforme dos dados e o desempenho ideal. Clique em OK para criar o banco de dados e o contêiner .
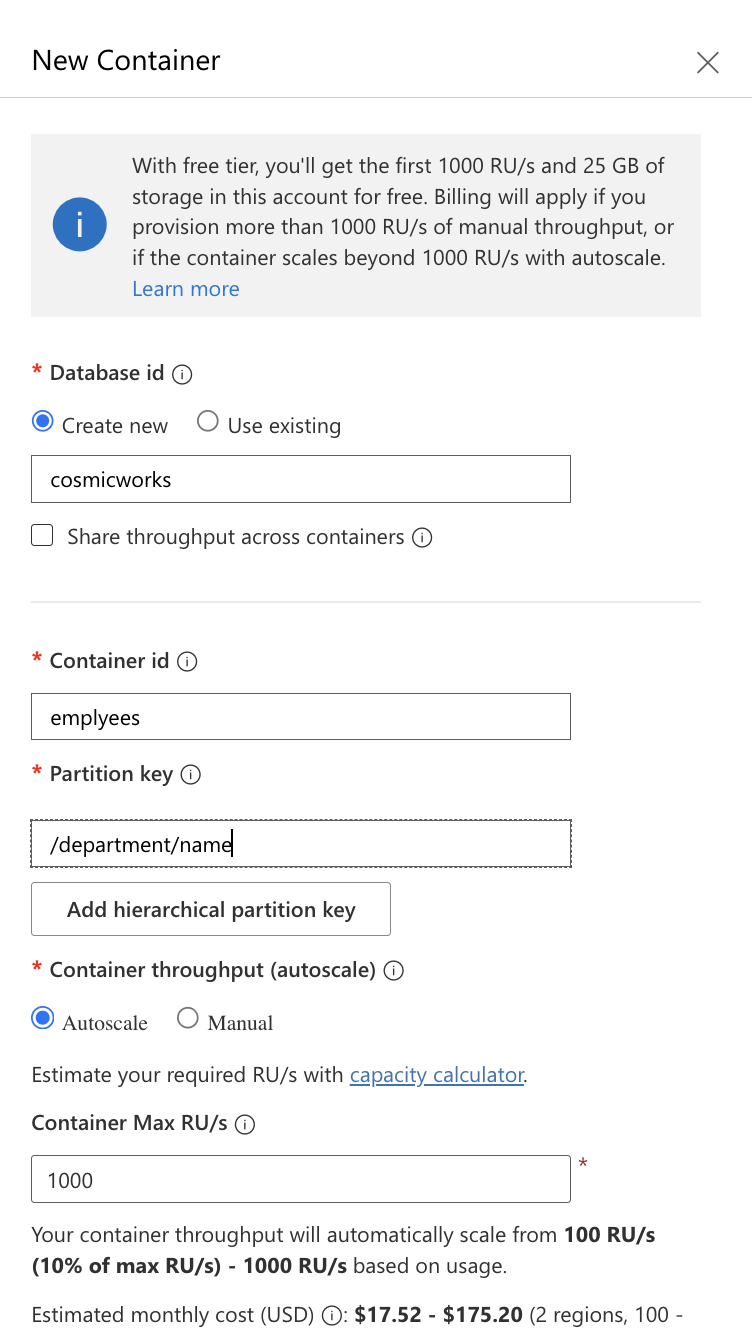
Captura de tela do Azure Cosmos DB. Preenchendo as características do nosso contêiner.
Depois de criados, você verá ambos listados na hierarquia do Data Explorer.
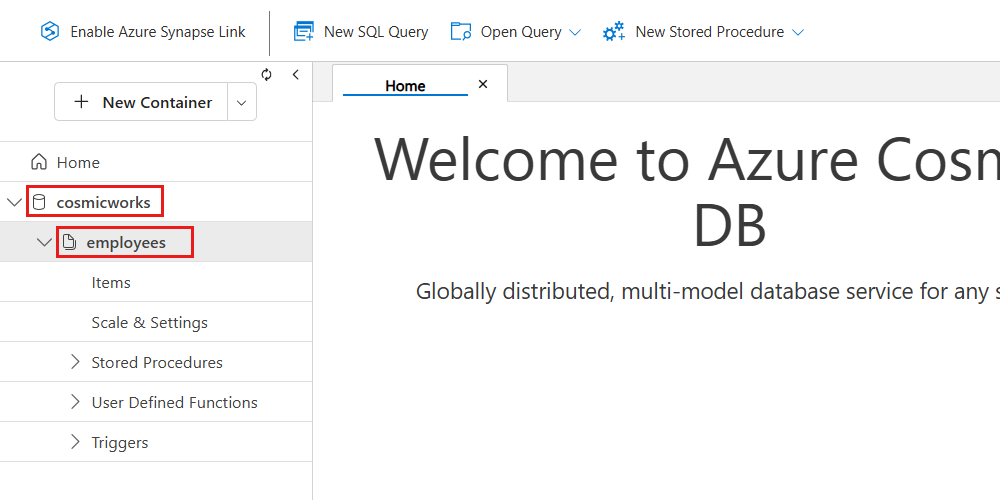
Captura de tela do Azure Cosmos DB. Verificação da hierarquia de dados.
No contêiner recém-criado (funcionários), expanda a exibição em árvore e selecione Itens.
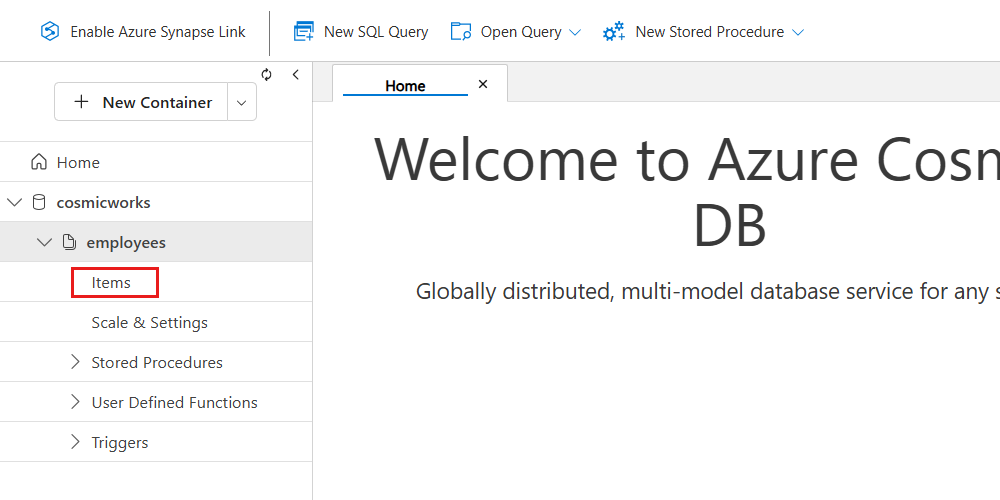
Captura de tela do Azure Cosmos DB. Verificação do contêiner
Clique em Novo item.
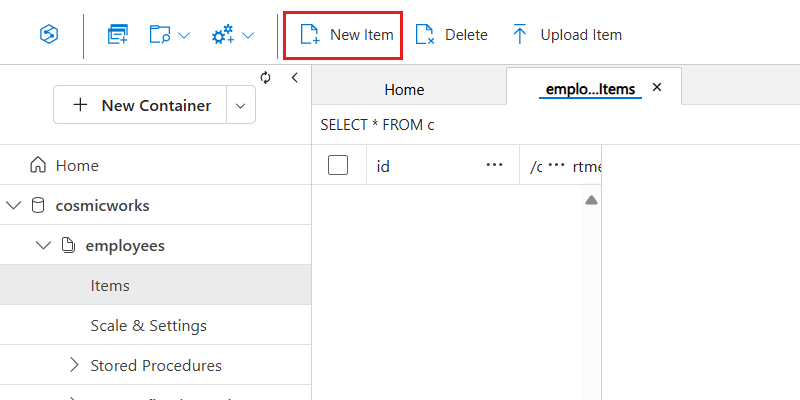
Captura de tela do Azure Cosmos DB. Criando um novo item
Insira a amostra de JSON a seguir e clique em Salvar:
{
"id": "aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb",
"name": {
"first": "Josep",
"last": "Ferrer"
},
"email": "<jferrers@datacampdummy.com>",
"department": {
"name": "Data Science"
}
}Para testar uma consulta, selecione Nova consulta SQL no menu e digite a seguinte consulta NoSQL, que realiza uma pesquisa sem distinção entre maiúsculas e minúsculas para os funcionários do departamento Logistics.
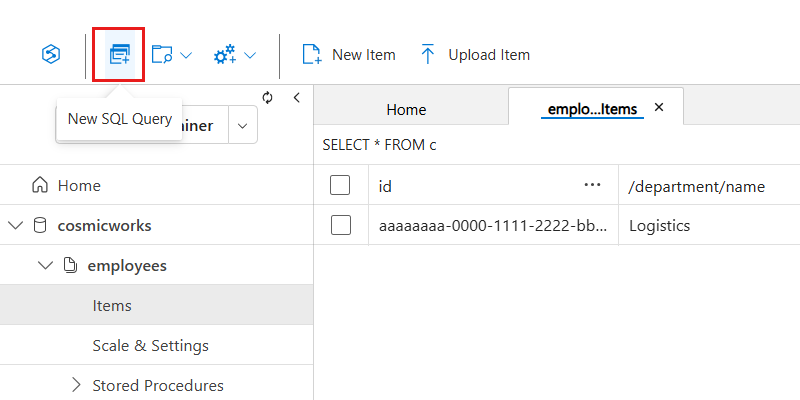
Captura de tela do Azure Cosmos DB. Verificação do contêiner.
SELECT VALUE {
"name": CONCAT(e.name.last, " ", e.name.first),
"department": e.department.name,
"emailAddresses": [
e.email
]
}
FROM
employees e
WHERE
STRINGEQUALS(e.department.name, "logistics", true)Agora clicamos para executar a consulta. Ele retorna uma saída estruturada:
[
{
"name": "Josep Ferrer",
"department": "Logistics",
"emailAddresses": [
"jferrers@datacampdummy.com"
]
}
]E isso é tudo!
O Azure Cosmos DB é um banco de dados NoSQL robusto e distribuído globalmente, criado para aplicativos modernos e nativos da nuvem. Com seu suporte a vários modelos, replicação ativa-ativa e níveis de consistência ajustáveis, ele se destaca em cenários que exigem alta disponibilidade, capacidade de resposta em tempo real e escalabilidade elástica, como sistemas orientados por IA, plataformas de comércio eletrônico e soluções de IoT.
Sua infraestrutura totalmente gerenciada, a modelagem de dados flexível e o rico ecossistema de APIs fazem dele uma excelente opção para desenvolvedores e arquitetos. Dito isso, as equipes devem considerar cuidadosamente as possíveis limitações, como as lacunas de recursos do SQL e o custo em escala, ao planejar as cargas de trabalho de produção.
Se você quiser continuar aprimorando suas habilidades, aqui estão alguns outros bons recursos:
Aprenda com a DataCamp
Curso
Curso
Curso
blog
Zoumana Keita
12 min
blog
Mike Shakhomirov
11 min
blog
Kurtis Pykes
10 min
Tutorial
Tim Lu
Tutorial
Zoumana Keita

