
Course
Understanding Microsoft Azure
3 hr
47.1K
As apps scale globally, traditional databases often fall short. Azure Cosmos DB, Microsoft’s globally distributed, multi-model database delivers low-latency access, multiple consistency models, and seamless scaling across regions.
This guide covers key concepts like containers, items, and SQL APIs, essentials for any cloud engineer who wants to get started (and work) with Azure and Cosmos DB. You'll gain a practical overview of its architecture and why it's a go-to choice for cloud-native, mission-critical apps.
Azure Cosmos DB is a fully managed NoSQL database on Microsoft Azure, built for high availability, low latency, and global scalability. It supports multiple data models, including document, key-value, graph, and column-family, making it flexible for diverse applications.
Its key strength is global distribution: With a few clicks, data can be replicated across Azure regions for fast, local access.
Developers can also choose from various consistency models to balance performance and data accuracy. If you are new to the Azure world, I strongly encourage you to read the following beginner’s guide to Azure.
Azure Cosmos DB offers a powerful set of features tailored for building scalable, high-performance applications:
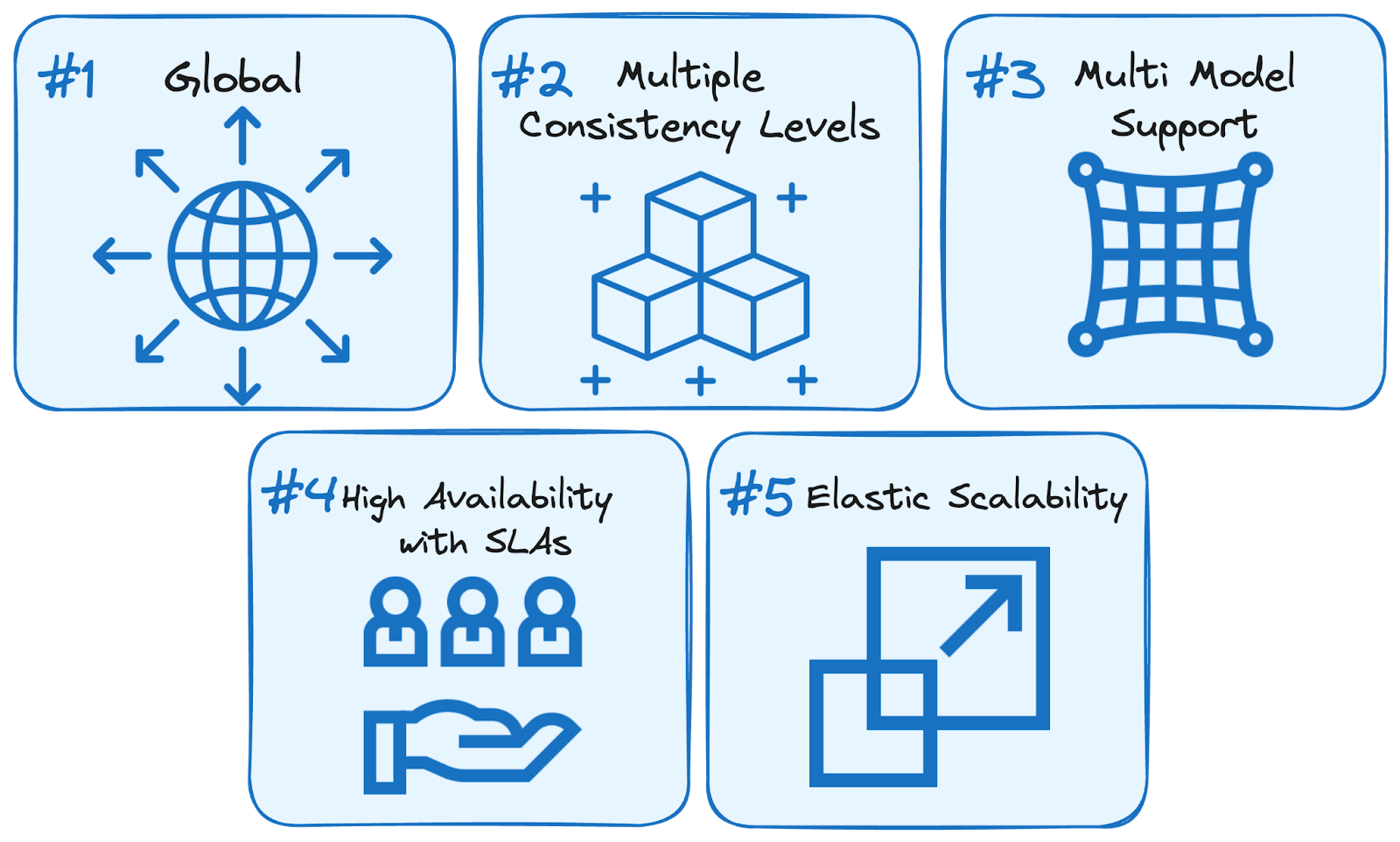
Image by Author. Why to use Cosmos DB
Together, these capabilities make Cosmos DB a strong foundation for globally distributed, cloud-native applications that demand real-time performance and resilience.
Azure Cosmos DB is a versatile choice for real-time, scalable applications across many industries. Its low-latency, globally distributed architecture makes it ideal for scenarios requiring high availability and fast data access. Here are some key use cases:
From powering online stores to enabling intelligent AI-driven apps, Cosmos DB delivers the speed, scale, and flexibility needed for modern cloud-native solutions. To better understand what you can do with Cosmos DB and Azure, you can go check the following Guide to Microsoft’s Cloud Offerings.
In this section, we will explore the core capabilities that enable developers to build fast, resilient, and intelligent applications, including data modeling strategies.
Azure Cosmos DB allows containers to store JSON documents without requiring a predefined schema, making it easy to adapt and evolve your data model over time.
Indexing in Cosmos DB is automatic by default, with every field indexed to support fast queries out of the box. However, this can lead to increased Request Unit (RU) consumption, especially in write-heavy workloads. To optimize, developers can define custom indexing policies. These policies allow disabling automatic indexing where unnecessary, specifying included paths for fields that should be indexed, and excluding fields that are not relevant.
Cosmos DB also includes a Change Feed feature, which captures inserts and updates in real time, making it ideal for building event-driven systems, triggering workflows, or streaming data downstream. Another useful feature is Time-to-Live (TTL), which enables automatic deletion of documents after a specified period.
For write-heavy workloads, partition keys should have high cardinality and uniform distribution, such as user IDs, timestamps, or geographic regions, to prevent hot partitions and throttling. In read-heavy scenarios, it’s often more effective to group related data using partition keys like customer IDs, enabling efficient access for range or point queries. Poor partitioning can lead to uneven data distribution and performance degradation. Since each logical partition is limited to 20 GB, it's important to design partitioning strategies that avoid overloading any single key.
Query performance can be further improved by designing access patterns that target single partitions, as these are faster and more resource-efficient. Cross-partition queries, while supported, typically result in higher latency and greater RU consumption because they scan multiple partitions. To reduce query costs, developers should leverage indexing strategies (I'm thinking about composite indexes) and consider applying caching mechanisms for frequently accessed data.
In terms of throughput, Cosmos DB allows developers to configure Request Units at either the container or database level. This tunable throughput model helps ensure that your app maintains performance even when you’re experience some kind of peak load condition.
Azure Cosmos DB offers five tunable consistency levels. This is well beyond the typical eventual or strong consistency options found in most non-relational databases.
At the weakest level, eventual consistency provides the fastest and most available option but may return stale or out-of-order data as replicas gradually synchronize. Slightly stronger is a consistent prefix, which ensures that reads reflect the order of writes, though not necessarily the most recent ones, making it suitable when operation order matters more than freshness.
The default and most practical setting for many applications is session consistency, which guarantees that a client will always read its writes within a session. Bounded staleness goes a step further by allowing a controlled lag between writes and reads, defined either by a time interval (T) or several versions (K). For example, in a single region, the lag might be capped at 5 seconds or 10 versions, while in a multi-region setup, it can extend to 5 minutes or 100,000 versions.
At the strongest end of the spectrum is strong consistency, which ensures that all reads reflect the latest committed write across all replicas. This level offers the strictest guarantees, avoiding stale, dirty, or phantom reads, and closely resembles the behavior of traditional ACID-compliant systems.
One of its standout features of Azure Cosmos DB is multi-region write support through active-active (multi-master) replication. This allows applications to perform write operations in multiple regions simultaneously, significantly reducing latency for users around the world.
Cosmos DB also includes automatic global replication, ensuring that data is synchronized across Azure regions. In the event of a regional outage, the system triggers automatic failover to the next available region.
Although Cosmos DB handles the mechanics of sharding and data distribution automatically, developers must still choose a suitable partition key to support even distribution and effective horizontal scaling. This decision is especially important for large datasets that may exceed the 20 GB limit per logical partition. Planning partitioning early helps avoid bottlenecks and performance issues as the application grows.
Azure Cosmos DB pricing is based on Request Units (RUs), which reflect the resources used for reads, writes, and queries. A simple point read typically costs 1 RU.
Before working with Azure Cosmos DB, you’ll need to set up an account, choose your configuration, and create your first database and container. This step-by-step guide will walk you through the process using the Azure Portal.
Begin by signing in to the Azure Portal. In the global search bar at the top, type “Azure Cosmos DB” and select it from the results. From the Cosmos DB blade, click “Create” to start configuring your new instance.
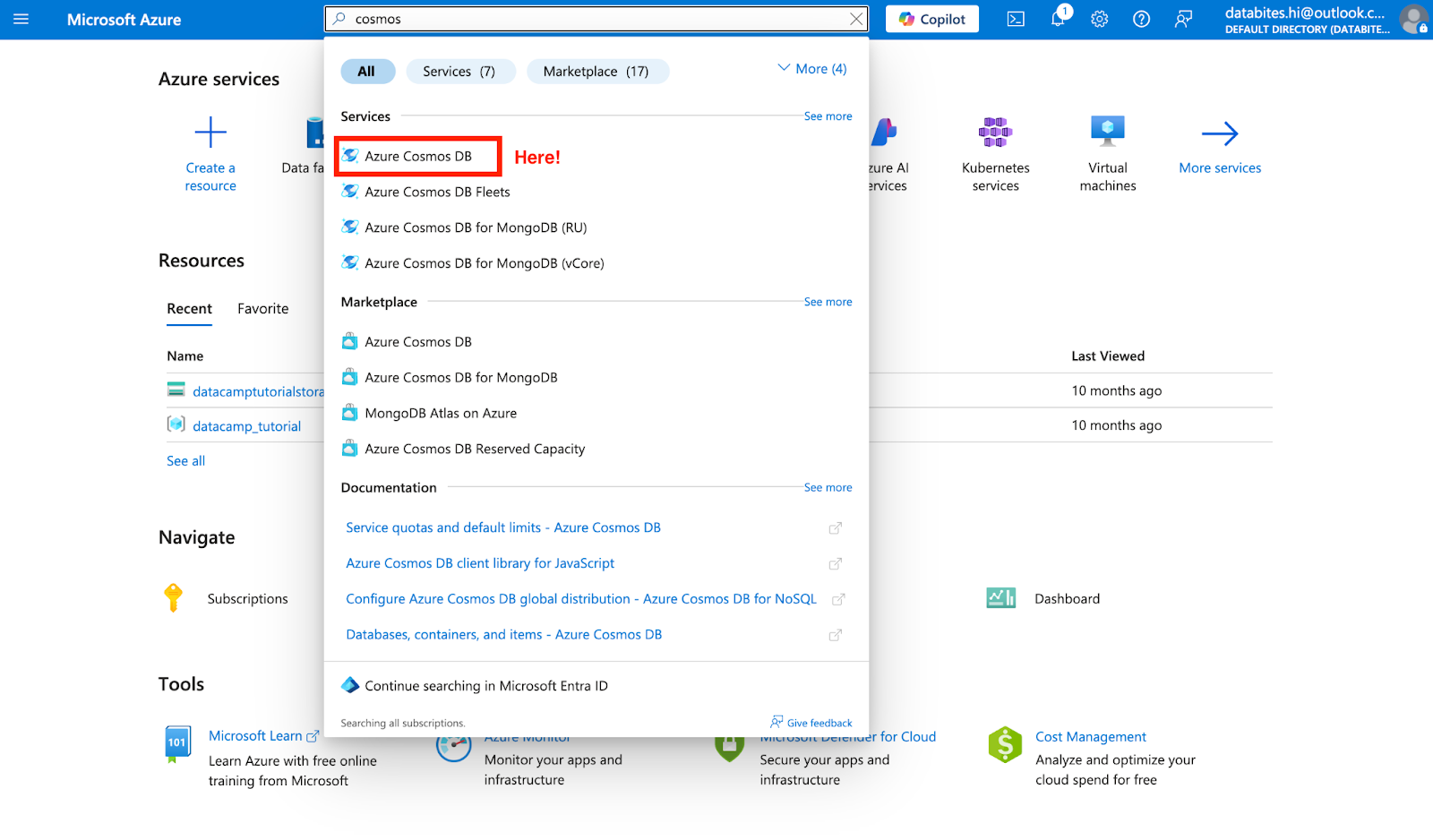
Screenshot of Azure main landing page
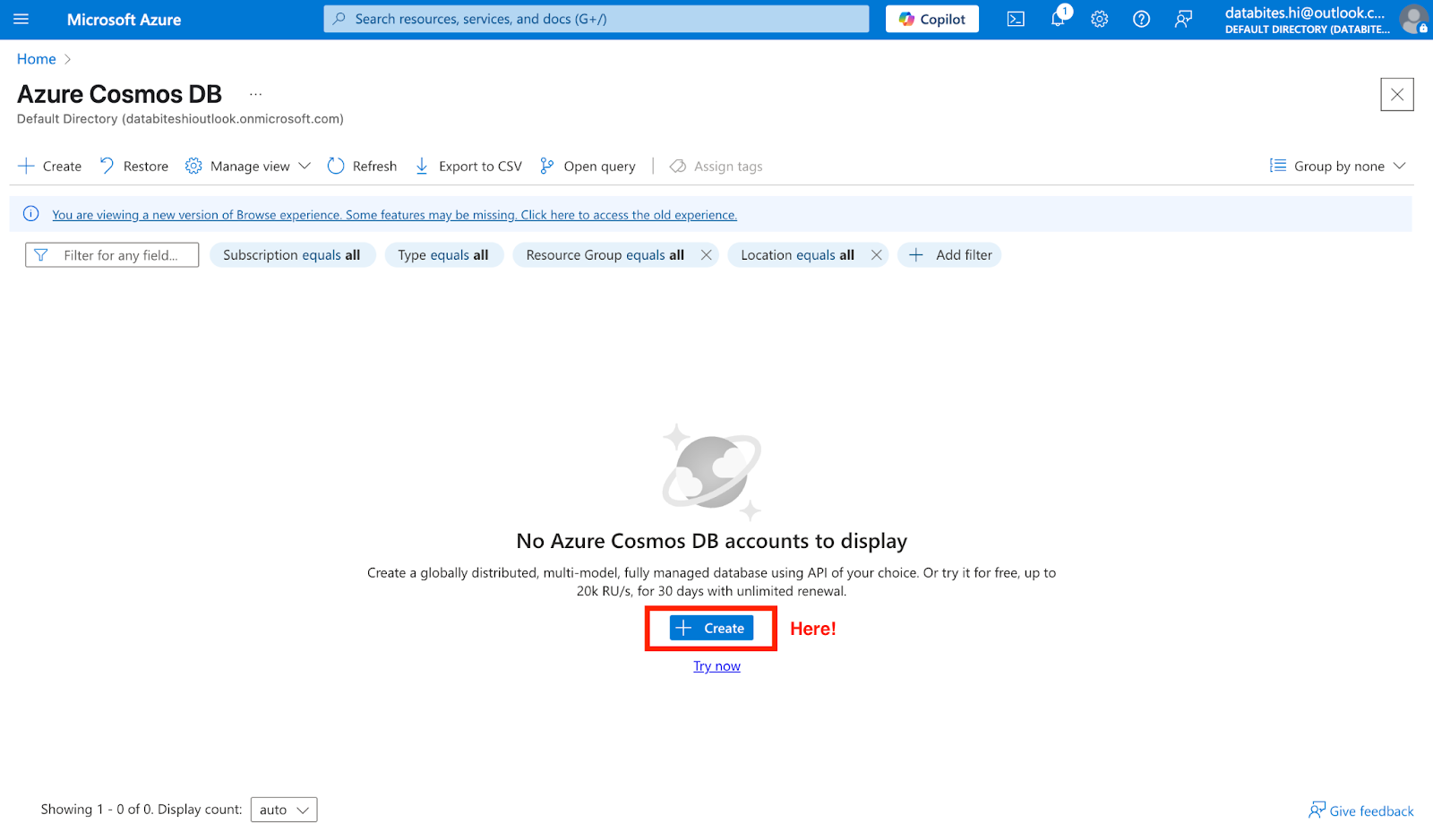
Screenshot of Azure Cosmos DB main landing page
Select Azure Cosmos DB for NoSQL as your API model (Core SQL API).
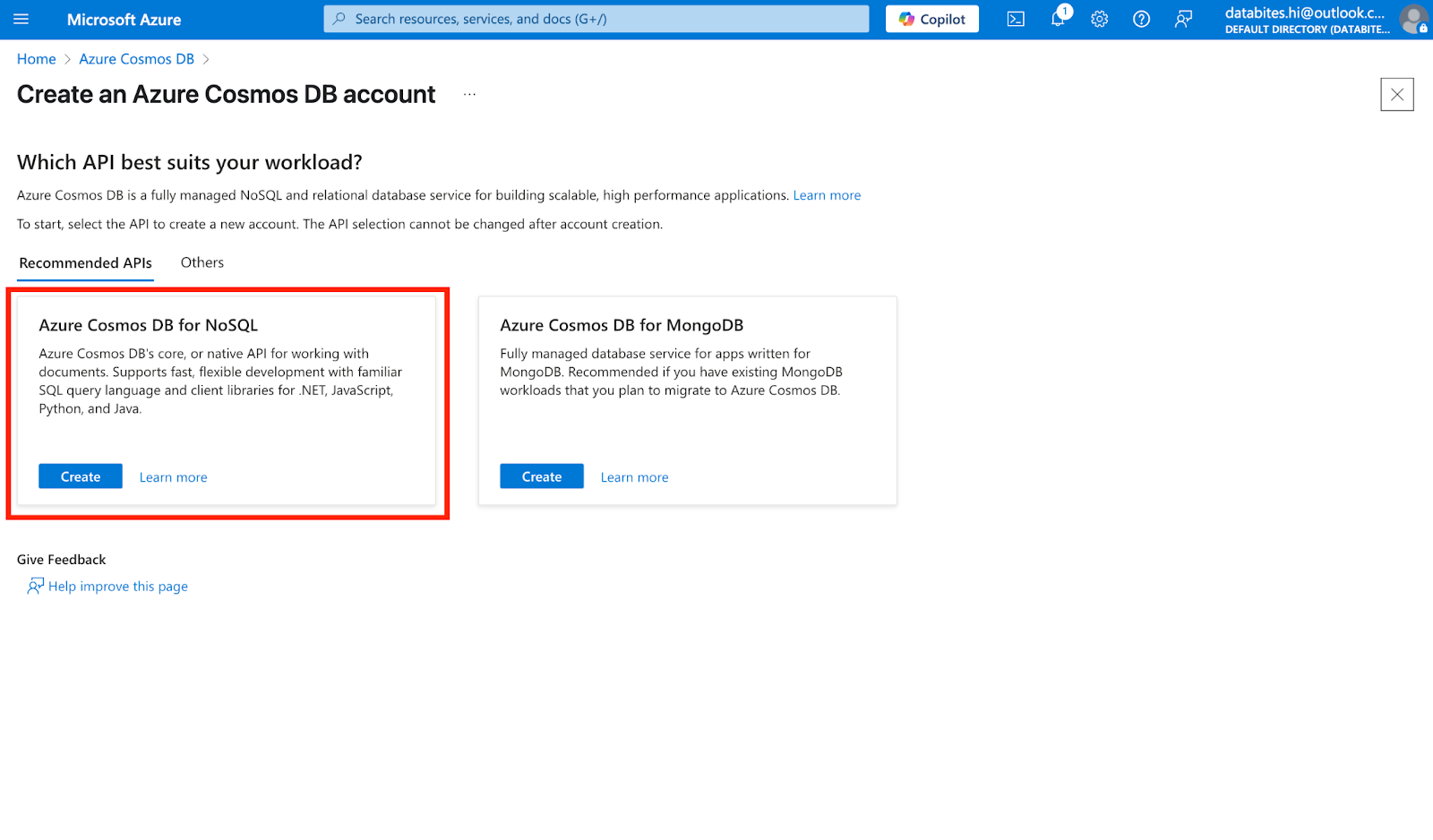
Screenshot of Azure Cosmos DB. Creating an instance
Then, in the Basics pane, enter your configuration details, including your Azure subscription, a resource group (either new or existing), a globally unique account name, and a preferred Azure region. Availability Zones can be left disabled. Cosmos DB offers two throughput modes—provisioned throughput for predictable workloads and serverless for variable or low-traffic scenarios. Choose the mode that best suits your application needs during setup. These options can also be adjusted later as your workload evolves.
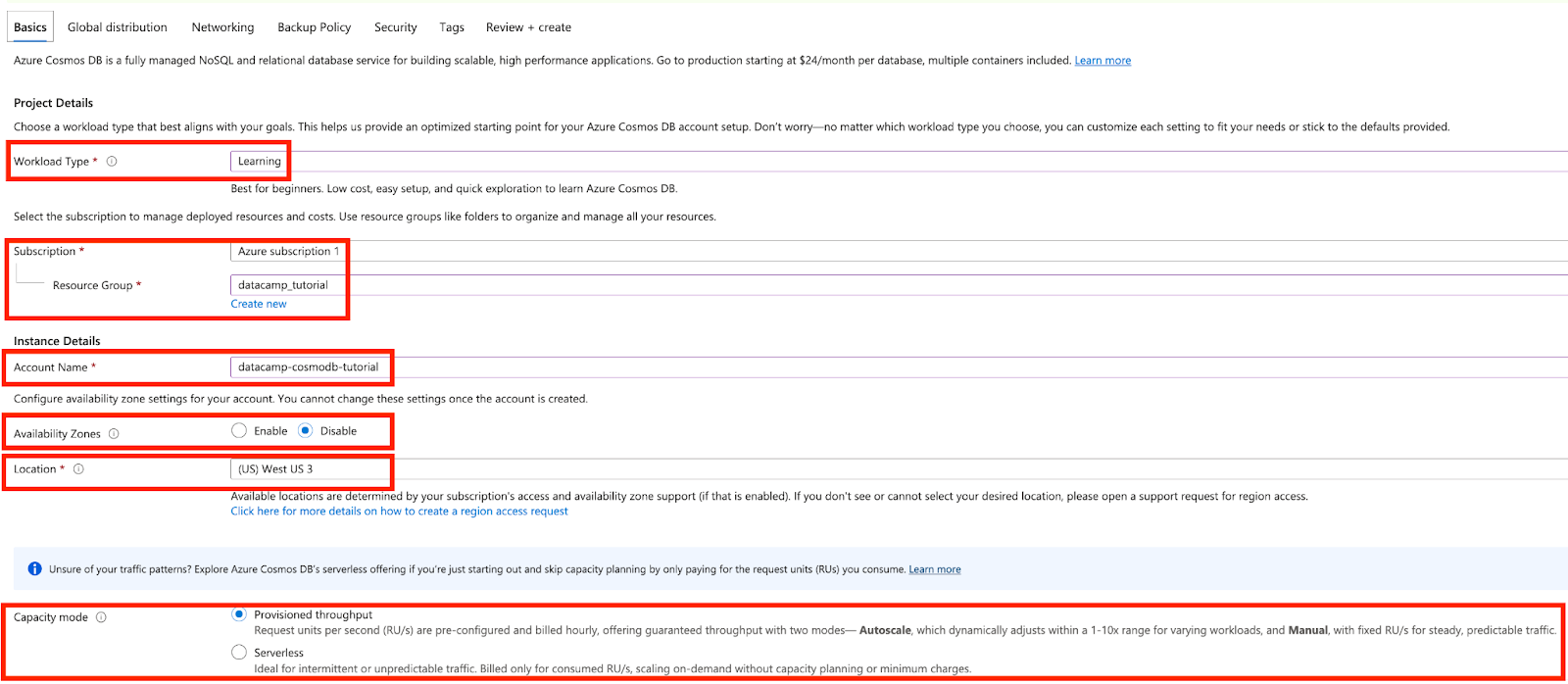
Screenshot of Azure Cosmos DB. Filling the details
Once complete, click Review + Create, and then confirm by clicking Create to begin deployment.
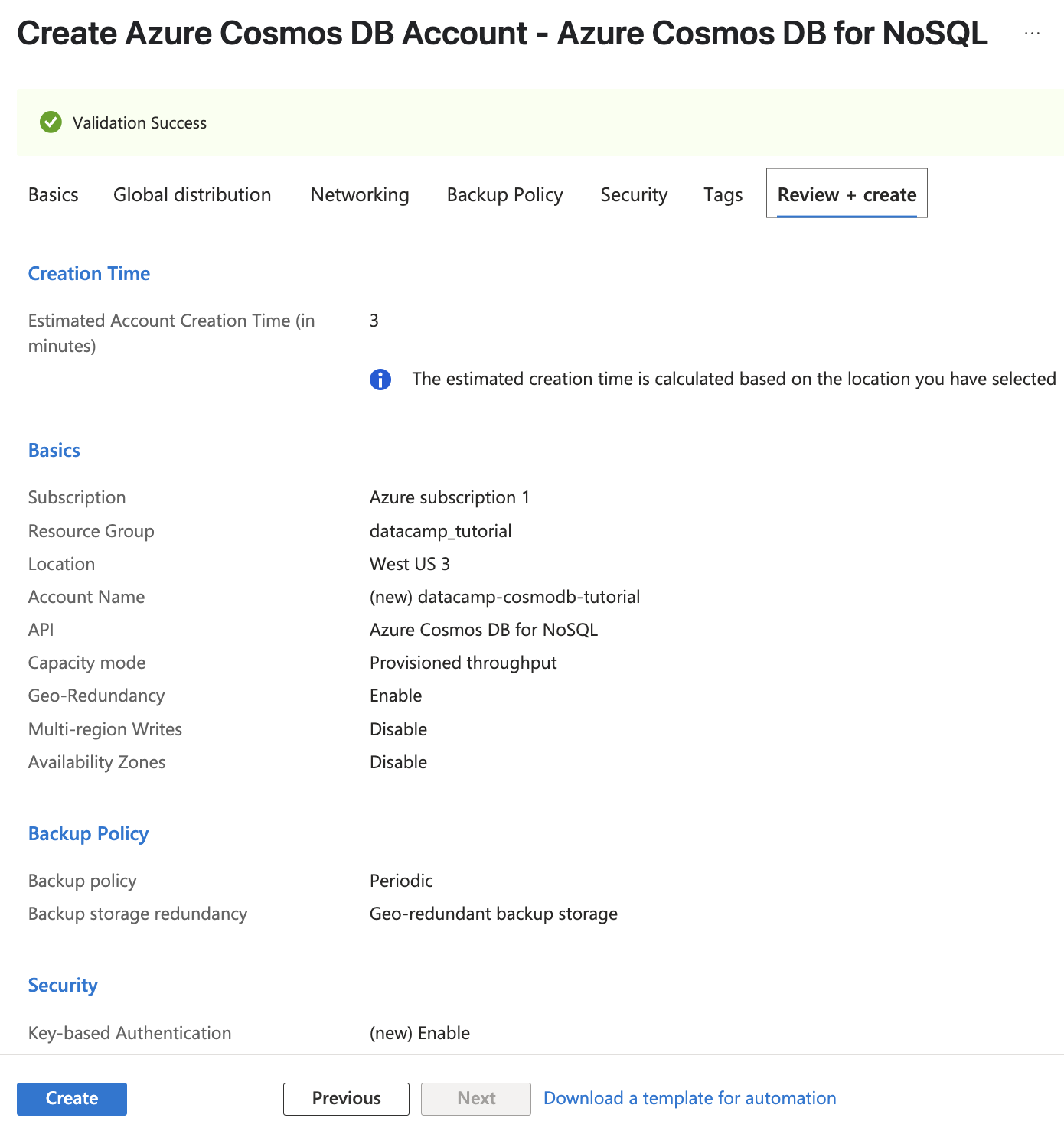
Screenshot of Azure Cosmos DB. Validating our instance
Once the deployment finishes, select Go to resource to access your new Cosmos DB account.
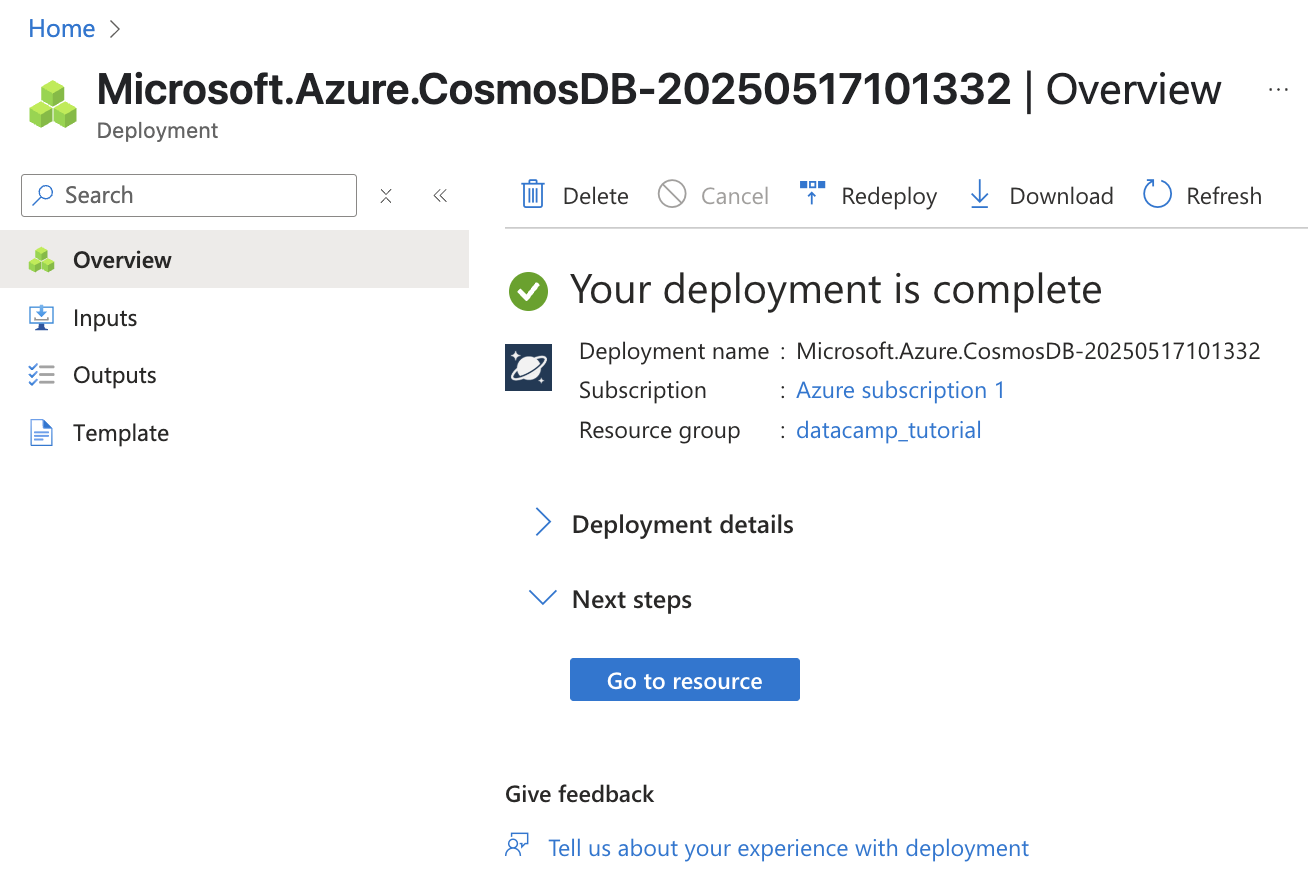
Screenshot of Azure Cosmos DB. Information about the resource we just created
Navigate to Data Explorer from the Cosmos DB account menu.
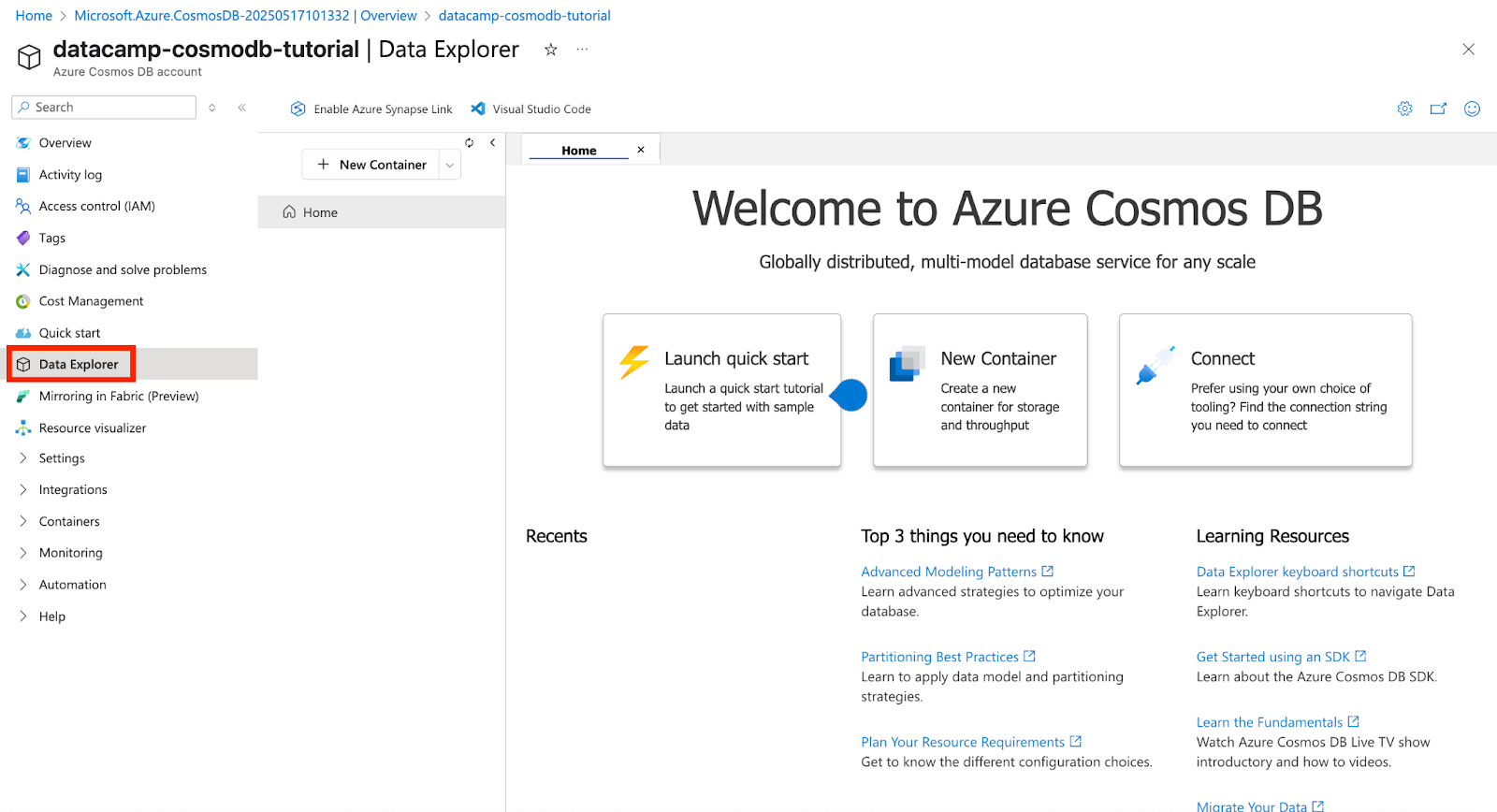
Screenshot of Azure Cosmos DB. Exploring our data
Click New Container to open the configuration dialog.
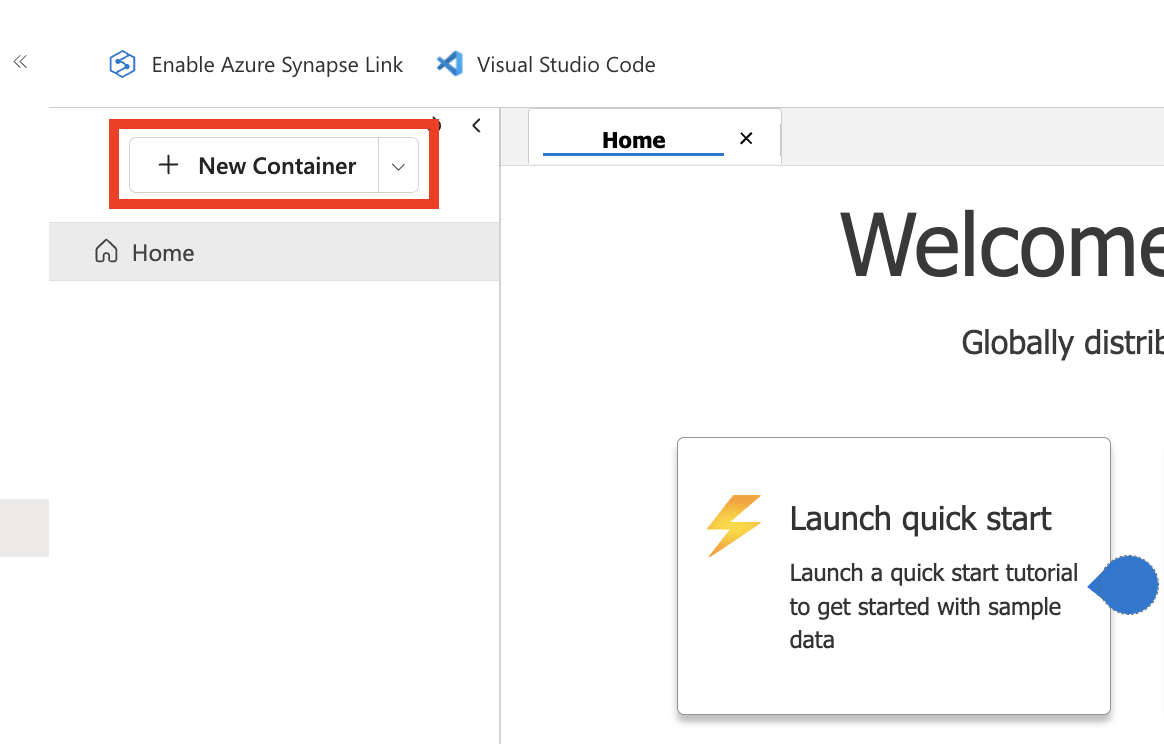
Screenshot of Azure Cosmos DB. Creating a new container
Define a new database name and a container name, and importantly, specify a partition key to ensure even data distribution and optimal performance. Click OK to create the database and container.
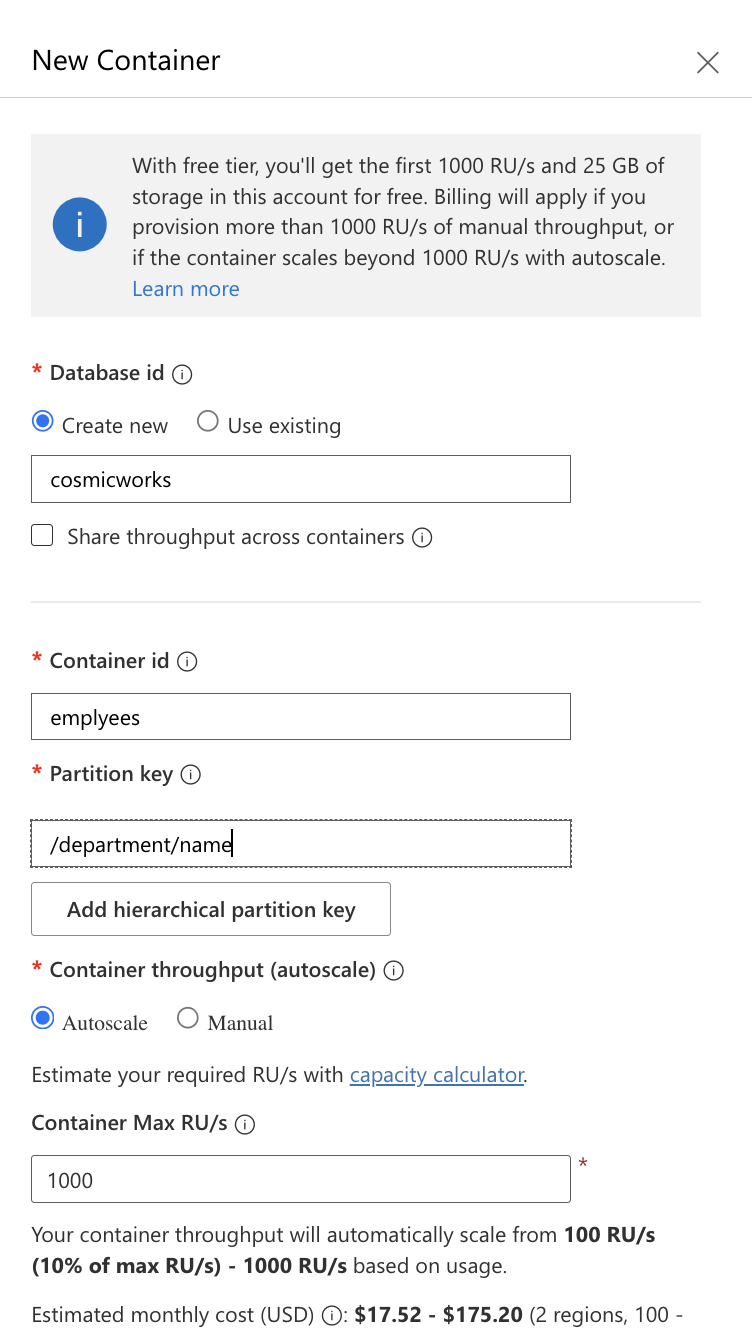
Screenshot of Azure Cosmos DB.Filling the characteristics of our container.
Once created, you’ll see both listed in the Data Explorer’s hierarchy.
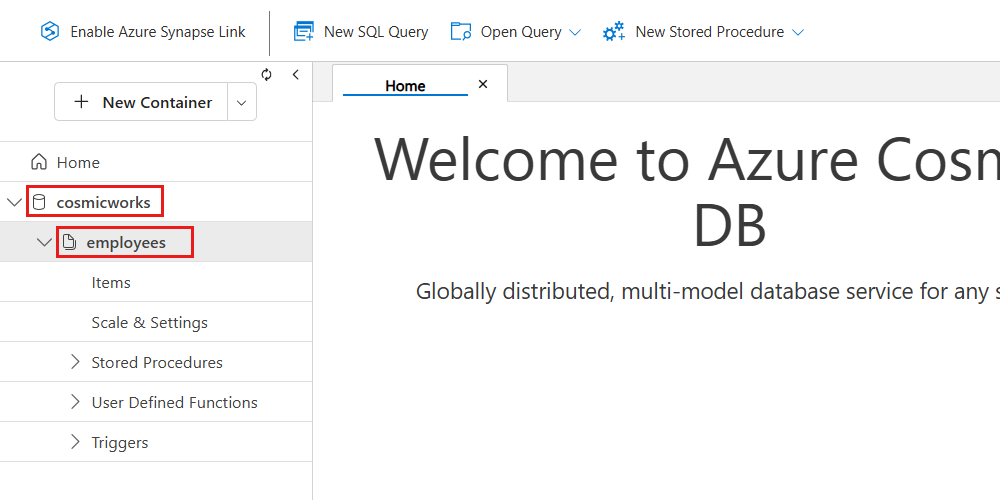
Screenshot of Azure Cosmos DB. Checking the data hierarchy.
Within the newly created container (employees), expand the tree view and select Items.
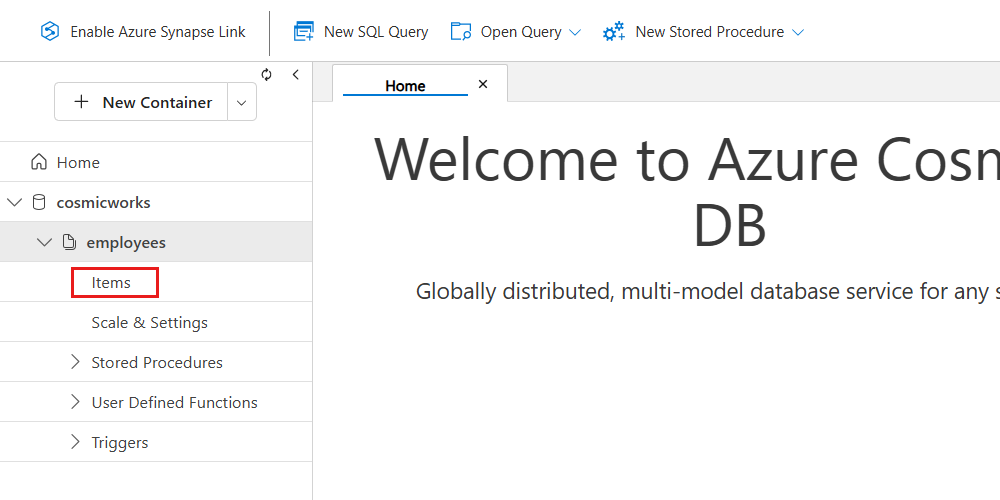
Screenshot of Azure Cosmos DB. Checking the container
Click New Item.
Screenshot of Azure Cosmos DB. Creating a new item
Insert the following sample JSON, then click Save:
{
"id": "aaaaaaaa-0000-1111-2222-bbbbbbbbbbbb",
"name": {
"first": "Josep",
"last": "Ferrer"
},
"email": "<jferrers@datacampdummy.com>",
"department": {
"name": "Data Science"
}
}To test a query, select New SQL Query in the menu and enter the following NoSQL query, which performs a case-insensitive search for employees in the Logistics department.
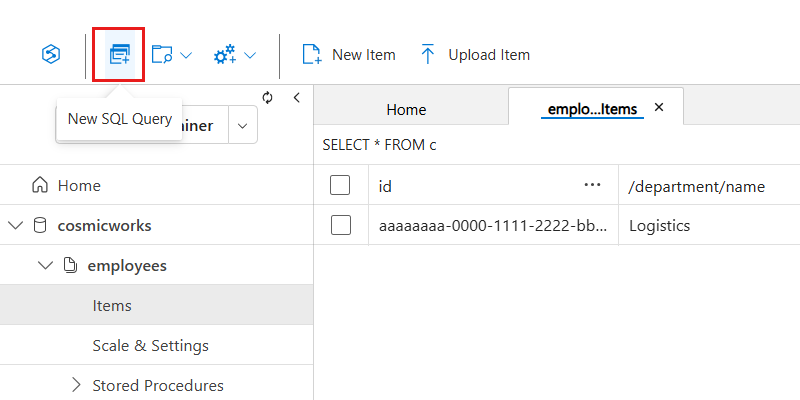
Screenshot of Azure Cosmos DB. Checking the container.
SELECT VALUE {
"name": CONCAT(e.name.last, " ", e.name.first),
"department": e.department.name,
"emailAddresses": [
e.email
]
}
FROM
employees e
WHERE
STRINGEQUALS(e.department.name, "logistics", true)Now we click to execute the query. It returns structured output:
[
{
"name": "Josep Ferrer",
"department": "Logistics",
"emailAddresses": [
"jferrers@datacampdummy.com"
]
}
]And that would be all!
Azure Cosmos DB is a robust, globally distributed NoSQL database built for modern, cloud-native applications. With its multi-model support, active-active replication, and tunable consistency levels, it excels in scenarios requiring high availability, real-time responsiveness, and elastic scalability, such as AI-driven systems, e-commerce platforms, and IoT solutions.
Its fully managed infrastructure, flexible data modeling, and rich API ecosystem make it a strong choice for developers and architects. That said, teams should carefully consider potential limitations, such as SQL feature gaps and cost at scale, when planning production workloads.
If you want to keep improving your skills, here are some other good resources:
Learn with DataCamp
Course
Course
Course
blog
Laiba Siddiqui
15 min
blog
Josep Ferrer
14 min
podcast
Tutorial
Anneleen Rummens
Tutorial
Kofi Glover
Tutorial
Iheb Gafsi
