Programa
Engenheiro de dados profissional Em Python
40 h
Os contratos de dados são a espinha dorsal da qualidade e do dimensionamento dos dados para soluções de dados distribuídos. Eles especificam o formato, o esquema e os protocolos que regem a troca entre as entidades do banco de dados. Esses acordos formais eliminam ambiguidades e suposições não documentadas sobre os dados.
Neste artigo, esclarecerei o conceito de contratos de dados, oferecendo técnicas básicas e avançadas para facilitar sua implementação efetiva.
Um único contrato de dados delineia os parâmetros precisos para a troca de dados entre dois modelos. Esses acordos formais garantem que não haja ambiguidades com relação ao formato e aos esquemas de dados.
As definições e a validação de contratos de dados são cruciais para a colaboração eficaz entre equipes.
Em resumo, um contrato de dados é um acordo formal entre o processo que altera o estado original de nossos dados (produtores) e os destinos (consumidores). É muito parecido com o funcionamento dos contratos comerciais. Eles representam obrigações entre fornecedores e consumidores de um produto comercial. Os contratos de dados fazem o mesmo com os produtos de dados, ou seja, tabelas, visualizações, modelos de dados etc.
O objetivo é reduzir as interrupções de downstream do pipeline de dados e tornar as transformações de dados estáveis e confiáveis.
Os principais componentes de um contrato de dados são o esquema (colunas e formatos), a parte da camada semântica (medidas, cálculos e restrições), os contratos de nível de serviço (SLAs) e a governança de dados.
Os benefícios dos contratos de dados incluem:
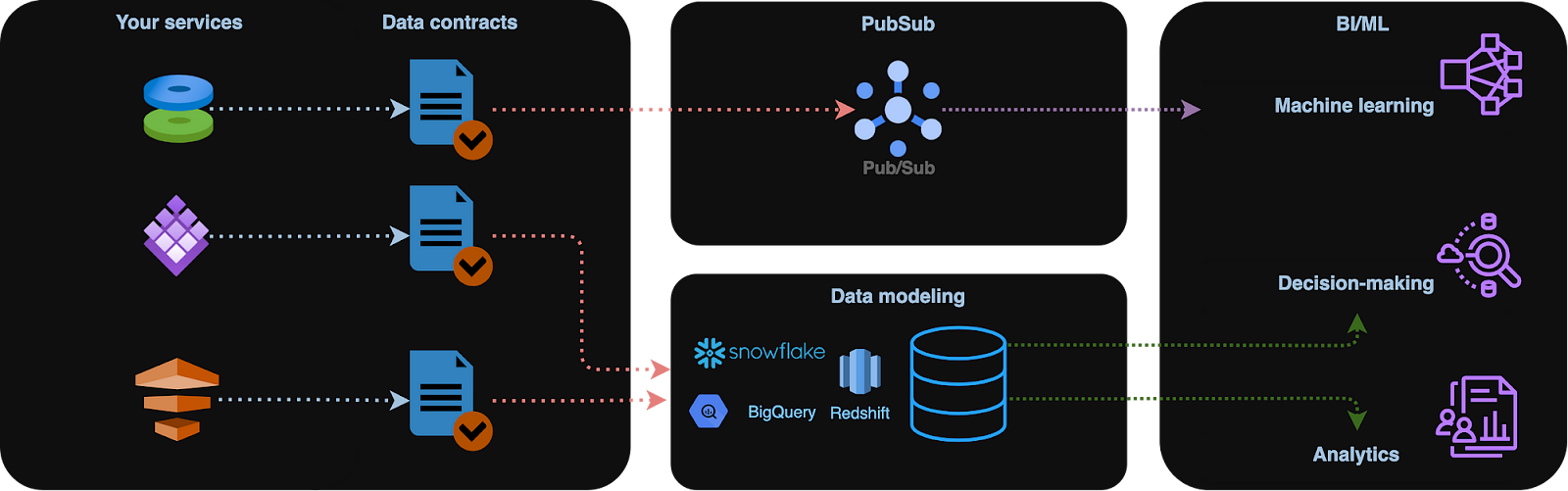
Contratos de dados. Imagem do autor.
Em um contrato de dados, os esquemas definem nomes de atributos, tipos de dados e se os atributos são obrigatórios. Eles também podem especificar o formato, o comprimento e os intervalos de valores aceitáveis para as colunas.
Vamos considerar um esquema de modelo dbt definido da seguinte forma em um arquivo YAML. Nosso esquema de tabela está definido em columns:
models:
- name: dim_orders
config:
materialized: table
contract:
enforced: true
columns:
- name: order_id
data_type: int
constraints:
- type: not_null
- name: order_type
data_type: stringAgora vamos imaginar que definimos nosso modelo dim_orders da seguinte forma:
select
'abc123' as order_id,
'Some order type' as order_typeSe você tiver um contract como enforced: true em nossa definição de modelo, ocorrerá o seguinte erro se tentarmos materializar dim_orders em uma tabela em nossa plataforma de dados:
20:53:45 Compilation Error in model dim_customers (models/dim_orders.sql)
20:53:45 This model has an enforced contract that failed.
20:53:45 Please ensure the name, data_type, and number of columns in your contract match the columns in your model's definition.
20:53:45
20:53:45 | column_name | definition_type | contract_type | mismatch_reason |
20:53:45 | ----------- | --------------- | ------------- | ------------------ |
20:53:45 | order_id | TEXT | INT | data type mismatch |
20:53:45
20:53:45
20:53:45 > in macro assert_columns_equivalent (macros/materializations/models/table/columns_spec_ddl.sql)O mesmo teria acontecido com colunas extras, verificações de SLA e metadados ausentes, caso tivéssemos optado por defini-los.
Um exemplo de dbt mais avançado conteria restrições de modelo aplicadas:
# models/schema.yaml
models:
- name: orders
# required
config:
contract:
enforced: true
# model-level constraints
constraints:
- type: primary_key
columns: [id]
- type: FOREIGN_KEY # multi_column
columns: [order_type, SECOND_COLUMN, ...]
expression: "OTHER_MODEL_SCHEMA.OTHER_MODEL_NAME (OTHER_MODEL_FIRST_COLUMN, OTHER_MODEL_SECOND_COLUMN, ...)"
- type: check
columns: [FIRST_COLUMN, SECOND_COLUMN, ...]
expression: "FIRST_COLUMN != SECOND_COLUMN"
name: HUMAN_FRIENDLY_NAME
- type: ...
columns:
- name: FIRST_COLUMN
data_type: DATA_TYPE
# column-level constraints
constraints:
- type: not_null
- type: unique
- type: foreign_key
expression: OTHER_MODEL_SCHEMA.OTHER_MODEL_NAME (OTHER_MODEL_COLUMN)
- type: …O fornecimento de uma definição de esquema como um conjunto de regras e restrições aplicadas às colunas de um conjunto de dados oferece informações muito importantes para o processamento e a análise de dados.
Os esquemas tendem a mudar com o tempo.
Esse é um cenário comum. Vamos imaginar que a nossa tabela de origem adicionou uma coluna contratada extra:
select
'abc123' as order_id,
'Some order type' as order_type,
'USD' as currencyÉ essencial considerar as alterações de esquema ao realizar atualizações incrementais porque, caso contrário, a saída do modelo incremental downstream invalidaria o contrato.
Isso pode ser resolvido adicionando on_schema_change: append à estratégia incremental dbt.
As validações de esquema podem ser explícitas ou implícitas.
Alguns formatos de arquivo de big data, como AVRO e Parquet, suportam definições de esquema integrado e implícito por padrão, portanto, não há necessidade de validação externa adicional.
Por outro lado, os formatos de arquivo de dados sem esquema, como o JSON, exigem validação externa do esquema. Algumas bibliotecas Python, como pydantic ou uma simples @dataclass, podem fazer isso:
from pydantic import BaseModel
class ConnectionDataRecord(BaseModel):
user: str
ts: int
record = ConnectionDataRecord(user="user1", ts=123456789)Se violarmos as regras e atribuirmos alguns valores que não correspondam aos nossos critérios, a exceção será lançada. Por exemplo, a exceção será levantada se tentarmos chamar ConnectionDataRecord('', 1).
Saiba mais sobre engenharia de dados com estes cursos!
Programa
Curso
Curso
blog
Moez Ali
11 min
blog
Zoumana Keita
12 min
blog
Matt Crabtree
10 min


